
手绘草图到服装图像的跨域生成
2023-02-16 06:35杨聪聪刘军平何儒汉梁金星
纺织学报 2023年1期
陈 佳,杨聪聪,刘军平,何儒汉,梁金星
(1.武汉纺织大学 计算机与人工智能学院,湖北 武汉 430200;2.湖北省服装信息化工程技术研究中心,湖北 武汉 430200)
服装设计是将设计美学和自然美应用于服装及其配饰的技艺,它追求实用美,是一种以人体为对象,以材料为基础,与各种机能性相结合的创造性行为。服装设计师不仅要对大众的生活方式和客户的需求有很好的了解,还要能够清晰地表达自己的想法。最重要的是,他们必须非常具有原创性,并有创新的想法。其中服装草图是设计师创作意图的集中体现,设计师首先通过构思画出服装草图,然后在服装草图基础上设计出服装效果图;但这需要消耗设计师大量的时间和精力,因此,本文将研究通过深度学习技术来实现将缺少颜色和细节的服装草图自动生成服装效果图。
传统的由草图到图像的生成主要采用图像检索方法, 如Chen等[1]提出的Sketch2Photo系统以及Eitz等[2]提出的PhotoSketcher系统等。首先从大量的图像数据库中搜索相关的图像,然后从相关图像中提取出对应的图像块,最后将这些图像块重新融合成新的图像。此类方法很难设计特征表示,且后处理过程非常繁杂[3]。
近几年,随着深度学习的不断发展,生成对抗网络(generative adversarial networks,GANs)在服装图像生成领域展现出巨大的潜力,其通过使用一个判别器来区分生成器生成的图像和真实图像,从而迫使生成器生成更加真实的图像[4]。这种基于深度学习的方法在训练过程中需要标记大量的数据集,而现实世界中成对的服装草图-图像数据集比较稀缺且制作起来耗时耗力。Zhu等[5]提出的循环一致生成式对抗网络(cycle-consistent generative adversarial networks,CycleGAN)越来越多被应用在草图到图像的生成过程中,这种方法主要侧重于学习图像域之间的映射,而忽略了其它关键语义信息,难以相应规范训练过程。如果不考虑高级语义信息,会误导模型建立不相关的翻译模式,生成的图像可能会出现严重的伪影甚至是不正确的图像属性。
本文提出一种基于循环生成对抗网络的属性引导服装图像生成方法,即AGGAN(CycleGAN-based method for attribute-guided garment synthesis),其将服装属性融入到生成器中以生成忠实于该属性的服装图像。同时,考虑到服装设计草图的稀疏性,本文引入注意力机制来引导生成器更多地关注笔画密集的区域,并提出将像素值这种低层图像数据和服装属性这种高层语义信息结合到生成模型中,以减少图像映射的模糊性。
1 服装图像生成模型
1.1 AGGAN框架
本文所提出的服装图像生成模型如图1所示。从草图域X={x1,x2,…,xn}开始,在属性向量集合C={c1,c2,…,cn}的指导下完成目标服装图像域Y={y1,y2,…,yn}的转换。为保证服装属性的一致性,本文将输入的服装属性作为条件信息融入到具有深度敏感注意力机制的生成器G和鉴别器Dy中。通过将服装草图X输入到生成器G中,同时将服装属性通过One-hot编码之后输入到多层感知机中得到AdaIN[6]参数,然后将其融入到生成对抗网络网络生成器的残差层中,以此生成具有相应属性的卷积特征图,最后通过生成器解码得到目标服装图像。鉴别器则用于区分生成服装图像与真实服装图像。

图1 正向的AGGAN框架
1.2 属性融入模块
服装图像具有丰富的语义属性以及视觉细节,其中,颜色、袖长和纹理是最主要的视觉特征,因此本文提取服装属性(颜色、袖长和纹理)进行探索。当AGGAN接收到任意服装属性标签时,所有属性都可同时学习,服装属性由一个One-hot向量表示,该向量用于区分目标属性和其它属性,One-hot向量一般可用来表示没有大小关系的类别特征,在One-hot向量中,属性向量表示为Ci=(0,1)N。其中:N为所添加的属性个数;Ci表示将N个(0,1)连接起来的第i个属性向量。只有对应于标签的元素被设置为1,而其它元素被设置为0。分别将颜色、袖长和纹理3种属性集合进行编码得到的One-hot向量矩阵输入到多层感知机中,并展开到高维空间作为AdaIN样式参数。AdaIN操作能够对齐内容特征与样式特征的二阶统计数据,将AdaIN参数插入到生成器G中的残差层中并与卷积特征图融合,可产生相关属性样式的内容特征。假设经过生成器G的残差层产生t∈RHt×Wt×Ct的特征图,其中:R为实数集;Ht为特征图t的高;Wt为特征图t的宽;Ct为特征图t的通道数。AdaIN操作为
式中:tc∈RHt×Wt,为输入的特征图;C为属性特征参数;μ(tc)和σ(tc)分别表示特征图tc的均值和标准差;μ(C)和σ(C)分别表示服装属性特征的均值和标准差。
1.3 生成器和鉴别器
生成器G的网络结构如图1所示。首先使用多个下采样卷积层学习高层特征映射,然后通过多个上采样卷积层生成输出图像。与一般的GAN不同之处在于,本文在上采样层前学习仿射变换,以便通过AdaIN操作将服装属性融入到生成器中。该服装属性通过One-hot编码到二进制向量C(C∈R1×1×N)中,且每个分量是属性的状态。将其融入生成器的残差层后经过注意力模块,使模型能够选择信息最丰富的属性来分类和区分相似的类,对于第i个属性,将其聚焦于图像不同区域的关注度定义为
式中:sij为图像隐含特征和潜在属性特征的内积;βj,i表示对应用softmax函数计算出的关注度;CTi为属性向量集中的第i个属性向量;g(xj)为图像第j个子区域的隐含特征;oj为注意力层的最终输出。
生成器G包含下采样层、残差层、注意力模块和上采样层。下采样层分别是步长为1的7×7卷积层,2个步长为2的3×3卷积层,每个Convolution卷积层后是BatchNorm归一化层,激活函数为ReLU。为了让生成器网络能够接收服装属性信息,本文将残差块的BatchNorm归一化层更改为AdaIN自适应归一化层。服装草图输入用作AdaIN的内容输入,服装属性的AdaIN参数则作为样式输入,以确保网络学习正确的属性信息。上采样层分别为2个步长为1的3×3反卷积层,每个卷积层后是BatchNorm归一化层,激活函数为ReLU,最后一个输出层则是步长为1的7×7卷积层使用tanh激活函数来确保归一化生成的图像位于范围[-1,1]内。
鉴别器Dy根据输入的Y域图像和1组属性向量C={c1,c2,…,cn}来计算概率D(Y,C)。该鉴别器包含了5个下采样层组成的卷积神经网络,这些卷积神经网络的结构是由Convolution-BatchNorm-LeakyReLU层构建的,在最后一层之后,应用全连接层,然后是Sigmoid函数,第1层不采用BatchNorm归一化层。
1.4 损失函数
生成器和鉴别器之间的对抗性过程促使生成图像更具真实性,此外还需要在对抗过程中融入属性条件信息来保证生成图像属性上的一致性。鉴别器Dy的输入为Y域服装图像以及相对应的属性。研究目标是使得鉴别器Dy能够区分生成的服装效果图和真实的服装图像,并判断输入的服装图像是否包含所需的属性。在训练鉴别器网络的过程中,将真实服装图像数据对(Y,C)作为正样本,而生成的服装图像(G(X,C),C)及其属性C的数据对则被定义为负样本,其中X为输入生成器的服装草图。训练鉴别器网络的目标函数分别为用于检验属性一致性的Latt和用于判别图像真实性的Lauth,因此鉴别器Dy的对抗性损失为
LDy=λ1Latt+Lauth
λ1初始化为0,在后面的训练过程中逐渐增大,使得鉴别器Dy能够首先注重于鉴别真假图像,然后逐渐注重于属性一致性检查,Latt与Lauth计算公式分别为:
Latt=-E(Y,C)~Pdata(Y,C)lnDy(Y,C)+
Lauth=-E(Y,C)~Pdata(Y,C)lnDy(Y,C)+
E(X,C)~Pdata(X,C)lnDy(G(X,C),C)

AGGAN的生成器G与鉴别器Dy对抗损失为
式中,ln(1-Dy(G(X,C)))表示判别器的优化目标。该值越大,Dy(G(X,C))的值越小。
与生成器G的网络结构不同,重建过程的生成器F没有服装属性条件的引导,将生成图像恢复至服装草图F(G(X)),在没有属性回归约束的情况下,则生成器F与鉴别器Dx的对抗损失为
式中:Pdata(X)和Pdata(Y)分别表示服装草图和服装图像的数据分布;EX~Pdata(X)和EY~Pdata(Y)分别表示从服装草图数据分布获取的期望以及从服装图像数据分布获取的期望;F(Y)表示输入为服装图像Y时,生成器F生成的草图。
重建草图的内容与原始输入草图通过L1损失在像素级对齐,则循环一致性损失公式为
式中:F(G(X,C))表示重建服装草图;G(F(Y))表示输入为服装草图时生成的服装图像。
综上所述,最终的目标函数为
L=LGAN(G,Dy,X,Y,C)+LGAN(F,Dx,Y,X)+Lcycle
式中:LGAN(G,Dy,X,Y,C)为生成过程生成器G与鉴别器Dy的对抗损失;LGAN(F,Dx,Y,X)为重建过程生成器F与判别器Dx的对抗损失;Lcycle为循环一致性损失。
2 实验部分
2.1 数据集与实验设置
本文对所提出的网络模型进行了验证,并在带有属性向量的VITON数据集[7]上对其性能进行了评估。该数据集包括14 221个图像和22个相关属性,数据集中的每个条目都由1个来自VITON的图像和1个属性向量组成。由于服装图像中上衣图像相较于其它品类的服装图像其视觉特征更为丰富,更具有代表性,因此本文选择上衣图像作为研究对象。训练过程中先将其转换为服装草图,再进行基于服装草图的图像生成任务。本文设置所有数据被训练的总轮数为200,初始学习率是0.000 2,并且使用Adam优化器,批次大小为8,输入图像的大小为256像素×256像素。
实验环境设置:使用Windows10的64位操作系统,采用Pytorch1.2.0深度学习框架,CPU为3.70 GHz Intel(R)Core(TM)i5-9600KF,GPU为NVIDIA GeForce GTX1080Ti。
2.2 评价指标
本文使用初始分数IS、弗雷切特初始距离FID[8]以及平均意见分数MOS[9]3个指标来评价生成服装图像的质量。IS和FID是GAN模型的典型图像评价指标,分别关注生成图像的多样性和生成图像与真实图像之间的特征距离,而MOS量化指标则是用来评价图像的生成效果。
初始分数IS通过将生成器输出的图像输入到训练好的Inception V3[10]中,从而得到一个概率分布的多维向量,其计算公式为
IS(G)=exp(Ex~pgKL(p(y|x)||p(y)))
式中:pg为生成数据的分布;x为从分布pg中采样的图像;Ex~pg表示从分布pg上获取的数学期望,KL表示KL散度[11];p(y|x)表示输入到Inception V3网络中并输出的分类向量;p(y)为生成图片在所有类别上的边缘分布。
弗雷切特初始距离FID是通过Inception V3提取出特征向量,没有采用原Inception V3的输出层,而是让其网络倒数第2个全连接层成为新的输出层。FID值越小,它们之间的相似程度越高。FID计算公式如下:
式中:μr和Cr分别为真实样本在输出层的均值和协方差矩阵;μg和Cg别为生成样本输出层的均值和协方差矩阵;Tr为矩阵的迹。
平均意见分数MOS是一种从主观角度对生成图像质量评估的方法,该方法需要受试者给出对所观察图像质量的评分,然后将所有受试者给出的评分汇总在一起计算出平均意见分数。MOS值为一个有理数,通常在1~5的范围内,其中1是最低感知质量,5是最高感知质量。
2.3 对比实验
为验证本文所提方法AGGAN的性能,进行了一系列对比实验。图2分别示出输入草图,真实图像,CycleGAN[5]、MUNIT[12]、USPS[13]以及AGGAN的生成图像结果。可以看出,MUNIT在本文服装图像生成任务上存在图像模糊,图像边缘难以分辨的问题,在训练期间,生成器学习生成与特定属性相对应的有限数量图像样本,所生成的图像不足以欺骗鉴别器,因此生成器和鉴别器网络没有得到充分优化。CycleGAN生成的图像较为模糊且颜色单一,图像缺乏真实感。最先进的基于草图生成图像方法USPS从视觉效果上生成可信的服装图像,但生成的服装图像颜色单一且质量不高。与其它方法相比,本文所提出的AGGAN不仅可生成多种颜色的服装图像,而且在视觉效果上更接近真实情况,同时AGGAN产生的图像极大地缓解了失真现象,这主要是由于模型融入了服装属性,在训练阶段学习更好的条件数据分布,此外,在所提出的AGGAN中使用注意力机制也有助于提升模型的性能。

图2 AGGAN与其它方法生成服装图像结果对比
本文使用IS、FID来进一步定量评估模型,结果如表1所示。可见:本文方法所生成的服装图像IS值为1.253,相较于CycleGAN提高了13.8%,且高于其它方法;其FID值为139.634,相较于CycleGAN降低了26.2%,且低于其它方法。除了上述2个评价指标外,本文还采用了MOS量化指标来评价各方法生成的服装图像质量,通过在校园线下分发问卷的方式进行调研。实验中,评分人员被要求在数秒内从上述4种方法所生成的服装图像中选择出他们喜欢的服装图像并依次对各方法生成的结果进行评分,设置的评分区间为1~5分,每种方法所生成的服装图像取出100张作为评价样本,最后取各方法得分的平均值作为MOS值,从表1可看到,本文方法的MOS值为4.352分,高于其它图像生成方法。
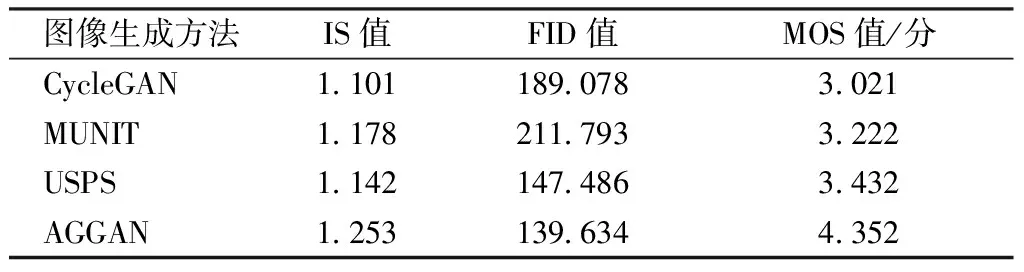
表1 AGGAN与其它方法比较结果
2.4 不同属性控制生成的实验结果
服装图像具有非常丰富的高级语义特征,而上述对比实验中的现有方法都不能很好地控制服装属性的生成,没有引入服装属性的生成结果往往不能满足需求,因此本文探究了属性控制的服装图像生成。
2.4.1 袖长属性控制的实验结果
袖长属性是服装的重要视觉特征,袖长属性控制的实验结果如图3所示。其中生成图像从左至右分别为无袖、短袖、盖肩袖、中袖、七分袖和长袖的生成结果。与真实图像相比,生成的服装图像袖长部分变化非常明显,而且似乎没有违和感;同时生成图像与输入图像之间的差异明显,且图像分辨率相对较高,注重对目标袖长属性的处理,生成的结果符合直觉逻辑;但“中袖”与“七分袖”生成效果比较接近,区别不明显,主要是因为现有模型还不足以支撑如此精确的属性操作。

图3 袖长属性控制的生成结果
2.4.2 颜色属性控制的实验结果
除了袖长属性外,本文还探讨了颜色属性对生成服装图像的影响,如图4所示,生成图像从左至右分别为红色、粉色、黄色、绿色、蓝色和黑色的生成结果。可看到AGGAN在颜色属性的控制下几乎能够生成任何相应颜色的服装图像,这是由于在生成器网络输入服装草图的同时融入了颜色属性作为颜色提示输入,在颜色细节生成方面能生成多样化且高保真度的结果。

图4 颜色属性控制的生成结果
2.4.3 纹理属性控制的实验结果
除以上2种属性外,纹理也是服装图像最直观和最主要的视觉特征,纹理属性控制的实验结果如图5所示,生成图像从左至右分别为横纹、粗纹、竖纹、波浪纹、栅格纹和印花的生成结果。
从图5可以看出,横纹、波浪纹、栅格纹与印花这4列的生成结果较为明显,基本上可以生成所需要的纹理,但其在真实感上还需改进。粗纹、竖纹这2列的生成结果则不明显,主要是由于拥有该属性的服装数据集较为稀少,在这种情况下,生成器在学习从草图域生成图像域时,生成的服装图像倾向于在某种程度上忽略融入属性的影响。

图5 纹理属性控制的生成结果
3 结 论
本文研究利用One-hot向量编码服装属性以及多层感知机构建了属性融入模块,通过属性融入模块、注意力机制和循环生成对抗网络建立了基于手绘草图的服装图像生成模型,并以此提出了手绘草图到服装图像的跨域生成方法。该方法结合了生成对抗网络与条件图像生成方法的优势,服装属性被用作条件以增加服装图像生成过程的可控性。实验结果表明,所提方法相较于图像生成方法CycleGAN的初始分数IS值提高了13.8%,弗雷切特初始距离FID值降低了26.2%,本文研究方法具有可行性与有效性。
本文研究仍有不足,例如:生成的服装图像存在轮廓模糊;纹理属性生成效果不明显;研究的服装属性较少等。后期将深入探索如何提升生成图像轮廓的清晰度以及生成属性的效果,同时还将研究更多种类的服装属性生成。
猜你喜欢
通信学报(2022年10期)2023-01-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
国防科技大学学报(2019年4期)2019-07-29
电子制作(2019年11期)2019-07-04
意林(2019年12期)2019-06-30
北京航空航天大学学报(2018年1期)2018-04-20
系统工程与电子技术(2016年5期)2016-11-02
福建中学数学(2016年4期)2016-10-19
小学生导刊(中年级)(2014年3期)2014-05-09
