
残差密集注意力网络多模态MR图像超分辨率重建
2023-02-18 03:07刘羽朱文瑜成娟陈勋
中国图象图形学报 2023年1期
刘羽,朱文瑜,成娟,陈勋
1.合肥工业大学生物医学工程系,合肥 230009;2.中国科学技术大学电子工程与信息科学系,合肥 230026
0 引 言
影像技术在现代医疗系统中发挥着越来越重要的作用,不同模态的医学图像能够表达不同的生理信息。磁共振成像(magnetic resonance imaging,MRI)由于技术的安全性和反映信息的全面性在临床医学中得到了非常广泛的应用。MRI系统可以通过使用不同的成像参数生成多种模态的图像,如T1加权、T2加权和质子密度加权等。不同模态的MR图像能够反映不同的生理信息,例如T1加权图像能够较好地反映解剖结构信息,而T2加权图像通常适用于体现组织的病变信息。空间分辨率是影响MR图像质量的一个重要因素,高分辨率(high-resolution,HR)的MR图像可以更加清晰准确地反映出结构和病变信息。然而,由于硬件配置、扫描时间和信噪比等因素的限制,原始MR图像的分辨率可能无法满足相关应用的需求。
图像超分辨率(重建)技术旨在从一幅或多幅低分辨率(low-resolution,LR)图像重建得到一幅高分辨率图像。该技术通过图像处理算法实现图像分辨率的提升,相对于依靠硬件的方式成本大幅降低,在医学图像处理领域具有重要的应用价值。众所周知,图像超分辨率实际上是一个高度病态的逆问题,也是图像处理领域的一个难点问题。在很多应用场合,往往输入只有一幅低分辨率图像,进一步增加了问题的不适定性。近年来,基于单幅图像的超分辨率方法研究受到广泛关注,多种多样的方法不断提出,这些方法通常分为基于插值、基于重构和基于学习的方法3类。基于最近邻、双线性和双三次等插值算法的超分辨率方法具有运行速度很快、实现简单等优点,但这类方法结果中容易出现块效应和边缘模糊等问题;基于重构的方法通过构建包含图像先验的优化模型,提高超分辨率质量。Shi等人(2015)提出了一种低秩全变分(low-rank and total variation,LRTV)模型用于MR图像的超分辨率重建,是一种典型的基于模型的医学图像超分辨率方法;基于学习的方法通过大量匹配的HR和LR样本来学习低分辨率图像到高分辨率图像的映射关系,从而实现图像的超分辨率。常用的机器学习模型包括稀疏表示、随机森林等。该类方法往往可以取得质量更高的重建结果,但是算法的计算效率有时较低。
随着深度学习理论技术的快速发展,基于深度学习的超分辨率方法相继提出。Dong等人(2014)首次提出一种用于自然图像超分辨率的3层全卷积神经网络模型(super resolution with convolutional neural network,SRCNN),相对于传统方法取得了明显的性能提升。随后,越来越多基于深度学习的超分辨方法陆续提出,并应用于医学图像超分辨率问题。Shi等人(2019)提出一种基于跳跃连接的宽残差网络(fixed skip connection-based wide residual network,FSCWRN)模型用于MR图像超分辨率。Chen等人(2020)在反馈网络(Li等,2019)的启发下,提出一种结合密集块和反馈机制的网络框架(feedback adaptive weighted dense network,FAWDN)用于医学图像超分辨率。
值得指出的是,当前医学图像超分辨率研究还存在一些不足之处。首先,现有超分辨率方法主要针对单一模态的医学图像进行设计。事实上,在磁共振成像技术的大多数应用场合,通常需要采集不同成像参数下的多模态MR图像,如T1加权、T2加权等。此时,针对单一模态的超分辨率方法没有利用不同模态MR图像之间的关联信息,很大程度上限制了重建性能,且对不同模态图像的超分辨率任务各自进行模型训练也会导致计算资源与存储资源的浪费。其次,现有大多数超分辨率方法通常采用加深网络深度的策略来获得较好的重建结果,随着网络的加深,网络需要学习的参数量也随之增加,导致计算效率降低和存储消耗增加,影响方法的实用性。针对上述问题,本文提出一种基于轻量级残差密集卷积网络的多模态MR图像超分辨率方法,主要创新点包括:1)与现有单一模态医学图像超分辨率方法不同,本文方法以一个统一的网络模型同时实现两种模态MR图像的超分辨率重建,能够充分利用不同模态图像之间的关联信息,提升超分辨率质量;2)提出了一个轻量级的超分辨率网络模型,与现有性能相当的网络相比,参数量低于对比模型的10%,方法实用性更强。
1 相关工作
卷积神经网络由于强大的特征提取与表达性能,在图像超分辨率这个不适定问题中获得了十分优异的结果。Dong等人(2014)首次将卷积神经网络引入图像超分辨率领域,提出一个端到端的3层卷积神经网络SRCNN,该网络参考稀疏表示的原理,通过学习低分辨率图像块与高分辨率图像块之间的映射关系,获得了超越当时其他大多数方法的优异效果。之后,Kim等人(2016a)提出了一个深度更大的超分辨率网络(very deep convolutional networks for super-resolution,VDSR)模型,通过加深网络深度以获得更加优秀的重建结果,并利用残差学习和梯度裁剪来解决梯度爆炸和梯度消失的问题,使深度网络变得易于训练。随后,进一步结合VDSR的优势提出一种基于深度递归卷积神经网络(deeply-recursive convolutional network,DRCN)的超分辨率模型(Kim等,2016b),采用递归监督的学习策略成功减少了模型参数,大幅提升了网络的计算速度,节省了计算和存储资源。这些方法虽然相较于以往的超分辨率方法在重建性能方面都有一定提升,但是都使用插值后的LR图像作为输入图像,不仅会因为在高分辨率空间中进行多次卷积操作而增加大量的计算量,而且也无法真正建立从原始LR图像到HR图像的映射。
为了解决这一问题,Dong等人(2016)利用转置卷积作为上采样,提出一个快速超分辨率卷积神经网络(fast super-resolution convolutional neural network,FSRCNN)模型,采用原始LR图像作为整个网络的输入,在不降低重建质量的情况下,显著缩小了网络的参数量并提升了网络的计算速度。Shi等人(2016)提出高效亚像素卷积神经网络(efficient sub-pixel convolutional network,ESPCN)模型,采用一种高效亚像素卷积层作为上采样,与转置卷积相比具有精度更高的优势。该卷积层在后续许多工作中都得以应用,例如改良型深度超分辨率网络(enhanced deep super-resolution,EDSR)(Lim等,2017)、基于特征精炼模块的超分辨率网络(coarse-to-fine super-resolution,CFSRCNN)(Tian等,2021)等。这些上采样方式使超分辨过程中的特征提取和加工步骤在LR空间中进行,不仅节省了计算资源和训练时间,使网络更加容易收敛,而且真正建立了原始LR图像与HR图像的之间端到端的映射关系。之后,Tong等人(2017)提出一种用于超分辨率的密集网络(super-resolution via dense network,SRDenseNet),采用跳跃连接和密集块来达到重建良好质量的高分辨率图像。在此基础上,Zhang等人(2018)提出了残差密集网络(residual dense network,RDN)模型,通过级联多个残差密集块的方式重建出了高质量的高分辨率图像。在RDN启发下,应自炉和龙祥(2019)为充分提取LR图像的特征信息,采用不同大小的卷积核对LR图像进行卷积,提出一种多尺度密集残差网络。程德强等人(2021)在RDN的基础上,引入多通道交叉学习策略获得较为理想的结果。沈明玉等人(2019)为克服链式结构网络容易丢失低频信息的问题,提出一种多阶段融合网络并成功取得良好结果。佟骏超等人(2019)采用递归学习的策略,提出了递归式多阶段融合网络,使网络在不断加深的同时获得质量优异的超分辨率图像。随着注意力机制在计算机视觉任务中的广泛应用,雷鹏程等人(2020)融合空间注意力机制和分层特征融合机制,提出一种轻量级的超分辨率网络,在使用较少参数情况下获得了理想的重建结果。周波等人(2021)提出一种改良的通道注意力机制,并将其应用于深度残差密集网络,在重建性能方面有所提升。
近年来,医学图像在临床实践中大量应用。但高分辨率的医学图像由于成像设备的限制常常难以获得,于是许多超分辨方法应用于医学图像领域。Xue等人(2020)提出一种渐进子频段残差超分辨率网络(progressive sub-band residual super-resolution network,PSR-SRN),使重建出的高分辨率MR图像具有更多的细节信息。Chen等人(2020)基于递归神经网络(recursive neural network,RNN)的原理,利用反馈机制提出用于医学图像的超分辨模型,该网络在多次循环中不断修正之前步骤产生的误差。Zeng等人(2018)提出一种结合T1加权和T2加权两种模态MR图像关联信息的超分辨率网络,但其中T2加权图像只是用于辅助T1加权图像的超分辨率重建。上述算法虽然取得了良好的重建效果,但依然存在不足。首先,目前医学图像超分辨率方法通常只针对单一模态的图像进行重建,忽视了不同模态图像之间存在的关联信息,不利于充分提升超分辨率质量;其次,网络结构复杂且深度通常较大,导致需要消耗较多的计算与存储资源,影响方法的实用性。针对这些问题,本文提出了一种基于轻量级密集残差注意力网络的多模态MR图像超分辨方法。
2 方 法
2.1 网络整体结构
图1是本文提出的多模态MR图像超分辨率方法的网络结构示意图,该网络主要由浅层特征提取、特征精炼和图像重建3部分构成。网络以低分辨率的两种模态MR图像对ILR1和ILR2作为输入,最终输出相应的超分辨率图像ISR1和ISR2。

图1 本文提出的多模态MR图像超分辨率方法的网络结构示意图
2.1.1 浅层特征提取
为了利用不同模态图像之间的关联信息,将两个模态的MR图像堆叠在一起后,输入一个卷积核大小为3×3的卷积层提取浅层特征,该过程可表达为
Finit=frelu(Conv(Cat(ILR1,ILR2)))
(1)
式中,Cat表示堆叠操作,Conv表示卷积核大小为3×3的卷积层,frelu(·)表示ReLU激活函数,Finit表示提取到的浅层特征图,通道数默认设置为64。
2.1.2 特征精炼
在特征精炼部分,浅层特征被输入到K个级联的残差密集注意力模块进行进一步的特征加工。残差密集注意力模块由1个残差密集块(residual dense block,RDB)和1个高效通道注意力(efficient channel attention,ECA)模块构成。每个残差注意力模块均输出64通道的特征图,将K个残差密集注意力模块的输出堆叠获得64×K通道的特征图后进行全局特征融合。全局特征融合由1个卷积核大小为1×1的卷积层和1个卷积核大小为3×3的卷积层完成,前者用于将64×K通道特征降低为64通道特征图并进行初步特征融合,后者用来进一步融合特征。获得融合特征后,再将浅层特征与融合特征相加,得到最终的低分辨率空间特征,形成全局残差学习,该过程可表达为
(2)
(3)
(4)
FR=frelu(Conv(frelu(Conv1×1(FC))))+Finit
(5)

2.1.3 图像重建
图像重建部分的输入是特征精炼部分得到的低分辨率特征图FR。首先,使用亚像素卷积层将特征图上采样到高分辨率空间。亚像素卷积层是一种在图像超分辨领域广泛使用的上采样层,与同样具有上采样功能的转置卷积相比,亚像素卷积层不引入待学习参数,仅通过重新排列不同通道的特征图来达到上采样的目的,且在上采样前不需进行零填充。然后,将上采样后的特征图分别输入到两个对称的高分辨率特征重建支路,每条支路包含2个卷积核大小为3 × 3的卷积层,前者输出64通道的特征图,后者重建得到不同模态的单通道残差图。最后,将两个模态的残差图分别与对应的低分辨率图像双三次插值结果相加,得到超分辨率图像。上述过程可表达为
ISR1=fbi(ILR1)+Conv(frelu(Conv(fup(FR))))
(6)
ISR2=fbi(ILR2)+Conv(frelu(Conv(fup(FR))))
(7)
式中,fup(·)表示亚像素卷积操作,fbi(·)表示双三次插值操作。
2.2 残差密集注意力模块
残差密集注意力模块是网络特征精炼部分的核心单元,由1个残差密集块(RDB)和1个高效通道注意力(ECA)模块级联而成。
2.2.1 残差密集块
RDB的网络结构如图2所示。1个RDB由若干个卷积核大小为3×3的卷积层和1个卷积核大小为1×1的卷积层构成。在3×3卷积层之间采用密集连接,允许浅层特征不断传输到更深层网络中,使浅层特征能够不断复用。这里,每个3×3卷积层输出特征图的通道数称为增长率,即每次级联后特征图增加的数量。卷积层数量和增长率越大,网络的表示能力就越强。本文方法中,每个RDB中默认包含6个3×3卷积层,增长率设置为32,由于输入特征通道数量为64,故6个级联操作后的特征图的数量分别为96、128、160、192、224和256。1×1卷积层有两个作用,一是降低特征图的通道数(降为输入特征通道数量64),减少计算与存储代价;二是将密集连接产生的特征进行融合。最后,输入的特征图通过一个跳跃连接与获得的特征图相加,形成一个局部的残差学习机制,能够将浅层特征信息传递到深层网络,可以有效避免网络在不断提取深度特征时丢失浅层特征,同时加速梯度流动,避免梯度消失导致网络难以训练。
2.2.2 高效通道注意力模块
在每个RDB之后,采用ECA模块(Wang等,2020)对RDB得到的特征进一步精炼。ECA模块的结构如图3所示。该模块首先对输入的特征图进行一次全局平均池化(global average pooling,GAP),综合全局信息,然后将获得的特征向量输入到一个卷积核大小可以自适应调节的1维卷积层中,得到的特征向量再经过softmax操作获得权重向量,最后将该权重向量与输入特征图相乘,得到加权后的输出特征图。该注意力机制模块使网络能够自适应地对不同通道特征图的权重进行调节,增大对重建效果有重要影响通道的权重,提升网络的特征学习能力。此外,采用可自适应调节大小的卷积核有助于提高模型的计算效率。

图3 高效通道注意力模块结构示意图
2.3 损失函数

(8)

3 实 验
3.1 实验设置
3.1.1 数据集
实验采用MICCAI(medical image computing and computer assisted intervention)BraTS(brain tumor segmentation)2019 数据集中的T1加权和T2加权MR图像进行方法的有效性验证。该数据集包含457组大小为240 × 240 × 155的T1加权和T2加权 MR图像对,实验时,将其随机分为3份,训练集417组、验证集20组、测试集20组。从每组3D图像数据中选取10幅切片(从第60个切片开始每隔5个切片选取一幅)作为原始高分辨率图像,共获得4 570对T1加权和T2加权MR图像。其中,训练集4 170对、验证集200对、测试集200对。
3.1.2 训练细节
为了控制网络的参数量,在特征精炼部分采用3个残差密集注意力模块,即参数K设置为3。实验中,训练3个不同放大因子的网络(×2、×3、×4)。网络训练的总轮次设置为300轮,学习率采用动态调整策略,前100轮学习率为1 × 10-4,之后降为1 × 10-5,使用Adam优化器实现网络参数优化。实验在PyTorch深度学习框架下实现,GPU为NVIDIA GeForce GTX TITAN,网络训练大约需要9 h。
3.1.3 性能评价
使用峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity,SSIM)作为客观评价指标。PSNR是超分辨率研究中最为常用的性能评价指标,该指标数值越大,表明图像重建质量越好,但某些情况下PSNR并不能完全反映图像的重建质量。SSIM是用来评价两幅图像结构相似性的指标,图像重建质量越高,SSIM值越接近于1。
3.2 消融实验
为了验证网络各主要部分的作用,设计了两组消融实验。1)为了验证不同模态MR图像之间的关联信息对超分辨率重建性能的提升作用,设计了两个针对单一模态图像的超分辨率网络,分别命名为T1-Net和T2-Net,其网络结构与完整版网络(Full-Net)的不同之处仅在于只输入单一模态的MR图像(T1加权或T2加权),并且在图像重建模块仅有一个重建分支;2)为了验证高效通道注意力模块对网络性能的提升作用,设计了一个取消该注意力模块的网络模型,命名为NA-Net。上述消融实验均在相同实验设置下进行训练,不同放大因子下的客观评价结果如表1—表3所示。可以发现,在各个放大因子(×2,×3,×4)下,完整网络Full-Net在PSNR和SSIM上都明显优于仅针对单一模态的超分辨率模型,体现出不同模态图像之间的关联信息对超分辨率重建是有益的。同时,注意力机制模块的使用也可以显著提升超分辨率质量,有助于在不过度增加网络深度的情况下获得较好的性能。需要指出的是,注意力机制模块的影响相对更为明显,这可能是由于网络模型的深度较小,导致增加注意力机制模块能够使网络表示能力获得显著提升。
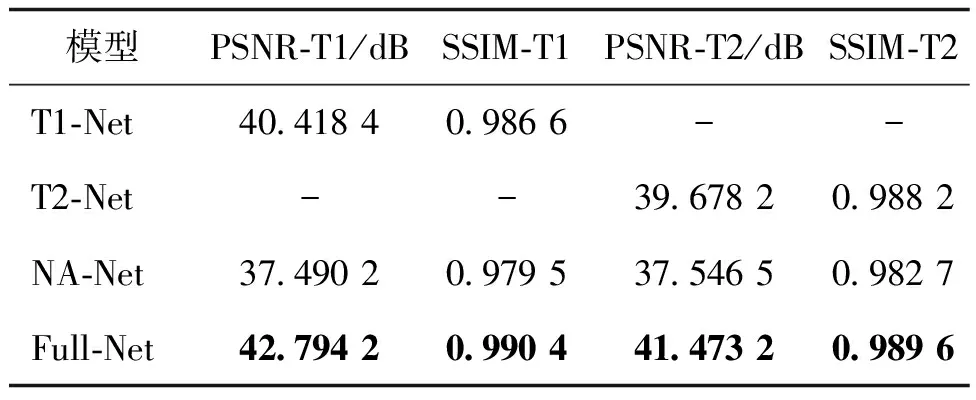
表1 放大因子为×2时的消融实验结果

表2 放大因子为×3时的消融实验结果

表3 放大因子为×4时的消融实验结果
3.3 对比实验
为了验证本文方法的性能,与双三次插值法(Bicubic)、LRTV(Shi等,2015)、EDSR(Lim等,2017)、VDSR(Kim等,2016a)、FSRCNN(Dong等,2016)、FAWDN(Chen等,2020)、CFSRCNN(Tian等,2021)和RDN(Zhang等,2018)等有代表性的超分辨率方法进行对比。公平起见,所有针对自然图像的超分辨率方法都在本文使用的数据集上分别对T1加权和T2加权两种模态进行重新训练,保证其针对医学图像的性能。
表4—表6给出了不同放大因子下各种方法的客观评价结果。由表4可以看出,放大因子为×2时,本文方法的T1加权和T2加权两种模态超分辨率结果的PSNR均为最优,比次优方法RDN分别提高了0.109 8 dB和0.415 5 dB;本文方法的T1加权超分辨率结果的SSIM与RDN相同,均为最优,T2加权超分辨率结果的SSIM为最优,与次优的RDN相比,提高了0.000 4。由表5可以看出,放大因子为×3时,本文方法的T1加权图像超分辨率结果的PSNR和SSIM均为次优,与最优的RDN相比,仅分别下降0.064 6 dB和0.000 3,T2加权图像超分辨率结果的PSNR和SSIM则均为最优,比次优的RDN分别提高0.295 9 dB和0.000 6。由表6可以看出,放大因子为×4时,本文方法的T1加权和T2加权两种模态超分辨率结果的PSNR均为最优,比次优方法RDN分别提高0.269 3 dB和0.042 9 dB;本文方法的T1加权图像超分辨率结果的SSIM为次优,与最优的RDN相比,下降了0.000 4,T2加权图像超分辨率结果的SSIM为最优,与次优的RDN相比提高了0.000 9。总体来看,在3种放大因子下,本文方法的客观评价结果均优于对比方法。与传统方法Bicubic和LRTV相比,优势非常明显;与除RDN外的深度学习方法相比,在PSNR和SSIM指标上也明显占优;与RDN方法的性能较为接近(本文方法占优情形相对更多一些),但本文网络模型参数量少得多。

表5 放大因子为×3时不同方法的客观评价结果

表6 放大因子为×4时不同方法的客观评价结果
图4—图6分别展示了不同放大因子下各种方法的超分辨率重建结果,每幅图的第1行是T1加权MR图像,第2行是T2加权MR图像。为便于对比,每个结果中均给出了两个局部放大区域。相对于其他方法,本文方法可以更好地保持图像细节信息。例如,观察图4中的放大区域,可以发现本文方法能够获得与参考图像(GT)更为接近的重建效果,双三次插值法在T1加权和T2加权的重建图像中均丢失边缘细节信息,其他对比方法中,重建效果较好的RDN和CFSRCNN对T1加权模型的超分辨率效果较好,但在T2加权超分辨率图像中丢失了一些细节信息。

图4 放大因子为×2时不同方法的一组超分辨率结果图

图5 放大因子为×3时不同方法的一组超分辨率结果图
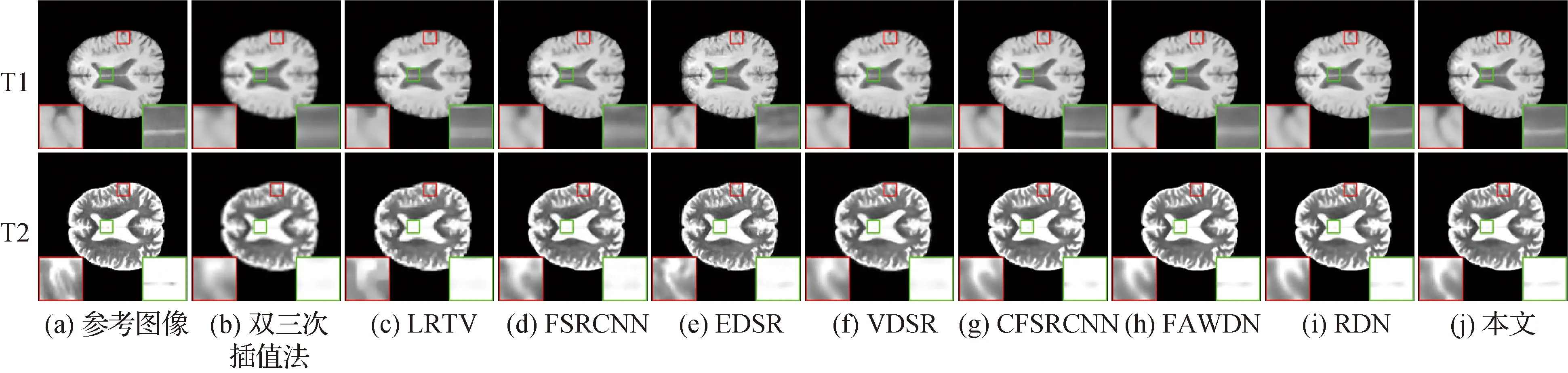
图6 放大因子为×4时不同方法的一组超分辨率结果图
3.4 网络模型参数量与运行时间比较
一般而言,网络模型的计算时间和存储消耗与网络的参数量成正相关,故本文通过比较不同网络中的可训练参数量来衡量网络的复杂度。
图7展示了深度学习对比方法的网络模型参数量。可以看出,FSRCNN(Dong等,2016)因为网络结构过于简单,含有参数量最少,但重建出的高分辨率图像质量也较低。VDSR(Kim等,2016a)也只含有较少参数量,但重建图像质量与本文方法相比也较低。CFSRCNN(Tian等,2021)与本文方法含有的参数量相当,但超分辨率性能低于本文方法。RDN(Zhang等,2018)的超分辨率重建质量与本文方法接近,但参数量约为本文方法的17倍。
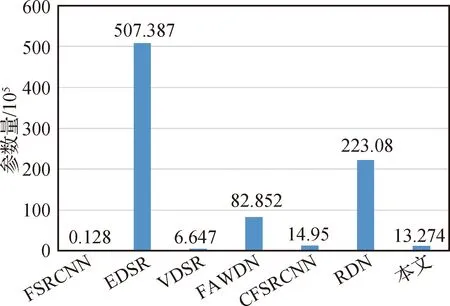
图7 不同超分辨率网络的可训练参数量
表7给出了不同深度学习超分辨率方法重建一幅图像的平均运行时间(通过测试200组图像取平均得到)。可以看出,网络运行时间与参数量基本成正相关关系。需要指出的是,虽然FAWDN参数量不大但运行时间最长,这是由于该网络采用反馈设计思路获得,需要多次重建中间图像。RDN在参数量上少于EDSR,但该网络大量使用密集连接的方式提取特征,使得网络的宽度较大,导致运行时间较长。本文方法能够获得较高的计算效率,运行时间仅为RDN方法的1/16左右。综上,本文方法可以在参数量较低和运行时间较少的情况下获得较为理想的超分辨率性能。

表7 不同超分辨率网络重建单幅图像的平均运行时间
4 结 论
针对当前医学图像超分辨率方法主要面向单一模态图像设计的问题,本文提出了一种基于轻量级残差密集卷积网络的多模态MR图像超分辨率方法。该方法能够在一个统一的网络模型下同时实现两种模态图像的超分辨率重建,充分利用不同模态图像之间的关联信息,帮助提升超分辨率重建质量。在网络结构中,主要利用残差密集块和高效通道注意力模块组成的残差密集注意力模块实现多模态特征的提取与精炼,再通过亚像素卷积层进行上采样,最终分别重建不同模态的高分辨率图像。
实验结果表明,本文提出的超分辨率方法在主观视觉效果方面能够重建出具有较多细节信息、较少伪影的高分辨率图像;在客观评价方面,本文方法在PSNR和SSIM两种常用客观评价指标上能够取得优于8种代表性对比方法的性能。此外,本文网络具有较小的参数规模与较高的计算效率,与性能接近的残差密集网络(RDN)方法相比,网络参数量低于RDN的10%。
需要指出的是,受计算与存储代价等因素的限制,本文方法目前是针对2D图像切片进行设计。考虑到现实中MR图像具有3D体数据结构,采用逐切片的方式进行3D图像超分辨率势必会丢失切片之间的关联信息,影响重建质量。因此,未来拟研究面向3D体数据的多模态医学图像超分辨率方法,进一步提升方法性能。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
数学物理学报(2019年3期)2019-07-23
家庭影院技术(2018年9期)2018-11-02
制造技术与机床(2017年7期)2018-01-19
传媒评论(2017年3期)2017-06-13
自动化学报(2017年5期)2017-05-14
第二课堂(课外活动版)(2016年2期)2016-10-21
