
基于地方志非结构化文本数据特征的模型设计要素探究
2023-02-22 05:45任璀洛
史志学刊 2023年6期
任璀洛
(湖南省地方志编纂院 湖南省地方文献研究所,湖南 长沙 410003)
一、引言
(一)政策背景
中国共产党第二十次全国代表大会上的报告提出,实施国家文化数字化战略,健全现代公共文化服务体系,创新实施文化惠民工程。2023 年2 月,党中央、国务院印发《数字中国建设整体布局规划》(以下简称《规划》),强调打造自信繁荣的数字文化,要求推进文化数字化发展,深入实施国家文化数字化战略,建设国家文化大数据体系,形成中华文化数据库。地方志工作应该适应新时代的发展需要,主动融入宏大的“数字中国”图景,推动数字技术在地方志领域全过程的融合应用,坚持守正与创新的辩证统一,进一步转型升级传统地方志的传承、编纂、传播、利用方式,提升地方志数据的质量、可靠性和安全性,有效地支撑政府决策和社会服务。
(二)研究概况
地方志文本内容的数据处理已有较多研究,但针对地方志的数据模型研究仍比较少。鲁丹、李欣研究整合地方志数据遇到的五个方面问题,讨论了核心数据的映射关系表,但对地方志中的文本数据提取未做相关研究[1]鲁丹,李欣.数字人文环境下异构方志元数据整合策略[J].图书馆论坛,2019,(04).(P158-165)。温永宁等基于GIS(地理信息系统)的方法,研究了家谱信息系统设计与实现,但仅支持人员、地点、时间等信息建模,与地方志文本内容的数据处理复杂度有较大差别[2]温永宁,闾国年,陈旻,等.华夏家谱GIS的数据组织与系统架构[J].地球信息科学学报,2010,(02).(P2235-2241)。赵思渊以“中国地方历史文献数据库”为例,讨论了引入文献数据库结构和分析工具的目的、意义以及规范等[3]赵思渊.地方历史文献的数字化、数据化与文本挖掘:以《中国地方历史文献数据库》为例[J].清史研究,2016(4).(P26-35)。欧阳剑提出了古籍文本可视化思路,包括以时间轴为主线的微观散点图分析、以时间轴为主线的宏观曲线分析、空间信息展示、词频分析、词语首见年代考证等方式,未涉及具体的数据架构[4]欧阳剑.面向数字人文研究的大规模古籍文本可视化分析与挖掘[J].中国图书馆学报,2016,(02).DOI:10.13530/j.cnki.jlis.160011(P66-80)。王锐等基于GIS(地理信息系统)的方法,将地方志信息划分为空间信息、时间信息和多媒体信息三类,提出将地方志信息融入空间基础地理信息,构建了概括式的要素类,以及要素的空间、时间、主题、多媒体模型,将实体的坐标数据、拓扑数据和属性数据存放在关系数据库[5]王锐,马德涛,袁家勇,等.基于GIS的地方志信息与空间基础地理信息融合方法的研究[C]//中国地理信息系统协会.2009'中国地理信息产业论坛暨第二届教育论坛就业洽谈会论文集.[出版者不详],2009.(P280-285)。徐蒙蒙总结归纳出时空数据的语言描述特征,研究了地方志时空数据组织的方法和信息抽取方法,设计了地名对象数据库表[6]徐蒙蒙. 地方志时空数据组织与应用[D].南京师范大学,2014.。徐晨飞以《方志物产》云南卷为例,分析了地方志物产领域的语义和组织,提出构建地方志物产知识库,并探讨了知识库的应用[7]徐晨飞.数字人文视域下方志物产知识库构建研究[D].南京农业大学,2020.DOI:10.27244/d.cnki.gnjnu.2020.002530.。相关研究都是从其他学科的知识架构出发,从地方志中抽取数据,满足其学科研究范式,而全面系统分析地方志文本的数据特征,并相应提出如何充分利用数据的研究成果仍较为罕见。
(三)研究方法和意义
本研究运用计算机科学的相关原理,分析地方志文本数据特征,设计地方志数据模型,提出模型的规范架构、分类方式和应用场景,主要采用了文献分析方法、现状分析和问题定义方法、软件工程方法、数据治理方法、实证研究方法。
研究地方志模型的设计和构建,可以探索挖掘和利用地方志资源宝库的方式,达成地方志工作者的数据共识,完善地方志理论体系,反馈促进编纂工作,指导地方志编纂过程的数据资源收集,拓展地方志信息化前进之路,更便于调研、分析、界定社会公众对地方志的数据需求,提供更加灵活和高效的数据访问方式,丰富地方志文化内涵,开拓地方志多元化应用场景,提升地方志服务的能力和价值。
二、地方志文本数据特征
地方志文本数据特征不是指地方志的资料性、全面系统性、地域性等本体特征,强调的是在数据治理过程中的特点。从数据应用角度分析,地方志数据具有明显的数据源复杂且差异明显、数据格式多样化、数据以非结构化文本为主、覆盖面广但颗粒度不足、数据产生速度较慢但仍具有一定价值等特点。
(一)数据源复杂且差异明显
中国地方志工作办公室公布的2021 年度数据统计结果显示,全国有省级地方志工作机构33个[1]23个省、5个自治区、4个直辖市和新疆生产建设兵团,香港、澳门、台湾未统计在内。,地市级地方志工作机构349 个,县区级地方志工作机构2621 个。部分地区的省志和市志存在分志,某些地区还出版了乡镇志和村志。地方志数据源呈现层级多样化、地域特色化的特点。3000 个地方志工作机构组织编纂的地方志虽然在体例和风格上基本相似,但是篇目框架和篇幅内容有着巨大的差异。显而易见,省、市、县不同层级的地方志对地情要素的关注重点是迥然不同的,综合志书、地方年鉴等不同类型的地方志篇幅内容是差异较大的。
同层级、同类型但不同区域的地方志,框架篇目的结构和顺序也有一定差异,所包含的地情要素各有特点。例如《长沙县志》(1995 年10 月版)分33 篇,《洪江市志》(1994 年6 月版)分23 篇,两者同为湖南省的县级行政区域、出版时间相近、出版社相同,仅有“建置”“自然环境”“人口”“工业”“商业”“交通 邮电”“人物”这七个篇目名称一致,框架篇目的分类包含关系和排列顺序则大相径庭,篇目下记载的地情要素更加难以比较。编纂地方志时间跨度大,涉及行业广,需要众多人员的直接参加或间接参与直接写稿、提出修改意见、反复审改加工等环节。不同区域和不同年代的资料搜集人员在资料的取舍上存在差异。在地方志编纂过程中,因各环节的参与人员学历文化水平和地情认知差异,需要记录的地情要素没有统一标准。因此,同层级、同类型但不同区域的地方志记载的数据多有出现“你有我无”“我有你无”的现象。
即使是同层级、同类型、同区域的地方志,框架篇目和记载的地情要素也存在大同小异和随社会发展不断调整的情况。各省的年鉴一年一卷,大多创刊在30 年以上,但较少有某一个要素数据记录30 年以上,很多数据都是记载了三五年之后,后续卷再也找不到相关记载。例如,从1985-1993 年《湖南年鉴》各卷中寻找对全省金融机构数量的记载,得出结果如下表所示。这个金融机构数量数据连续记载9 年,从1994 年以后,《湖南年鉴》中不再记载。这个随意抽检的一个数据要素可以证实,层级、空间、时间和客体的变动,都会导致地方志数据的多源差异化。贵阳方志云的数据比对功能效果不佳,可能就是由多源差异化原因所造成。各种地方志记载的同一地情要素指标的数据因书籍章节排列的差异,分布在书内的不同位置,加上要素名称的同义多名现象,给地方志数据分析整理增加了相当大的难度。
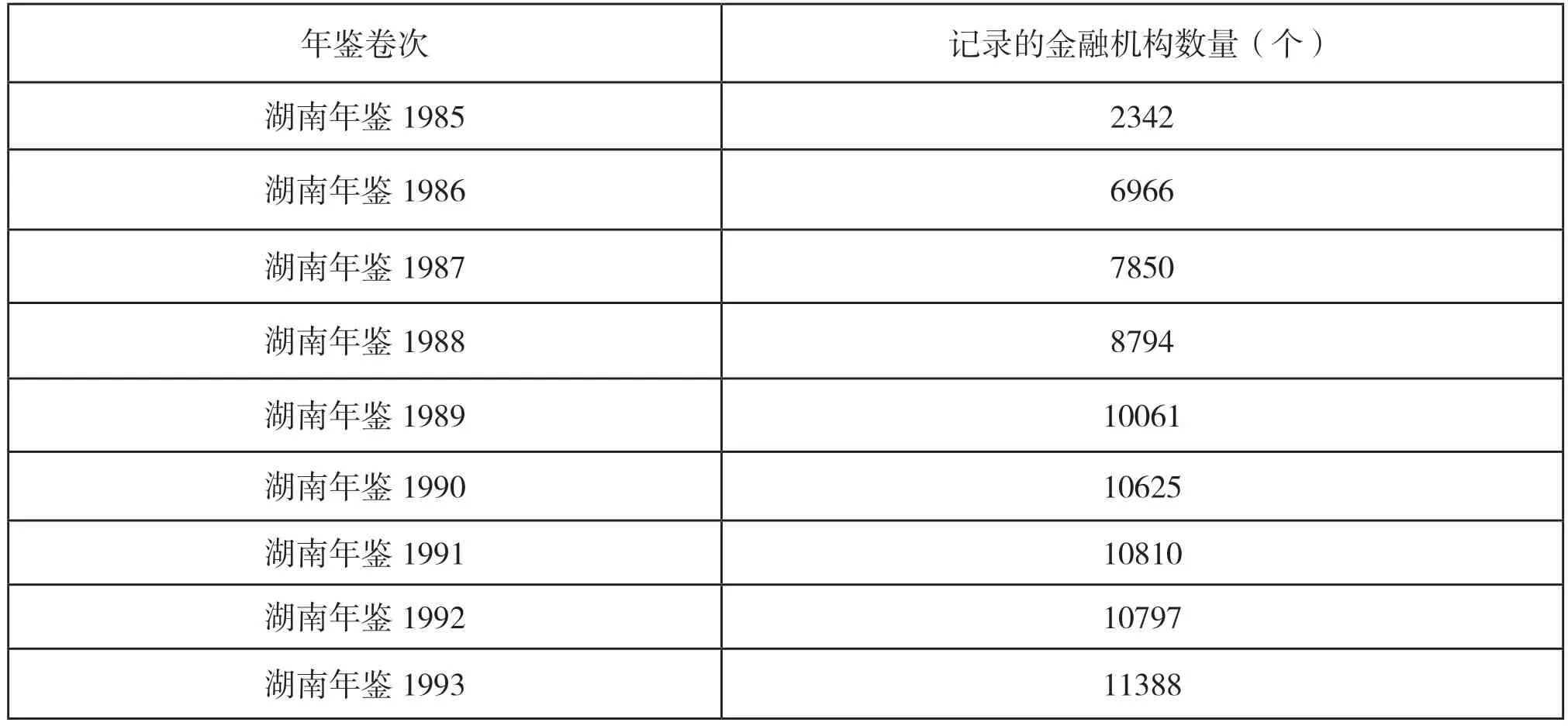
1985-1993 年《湖南年鉴》各卷次记录的金融机构数量(个)
(二)数据格式多样化
目前,全国多个数字方志馆或数据库已经建成投入使用,为地方志数据模型的设计和构建提供了一定的资源基础,但各省地方志数据存储采用的数据库类型版本,以及文本表现形式是多样化的。2019 年10 月,参照国家图书馆的数字资源元数据标准和数据加工规范制定的《国家数字方志馆资源元数据规范(征求意见稿)》《国家数字方志馆资源数据加工规范(征求意见稿)》,两个规范在征求意见时,多个省级地方志工作机构已按各自标准建设了本省的数字方志项目,这些项目存在规范标准不统一的现象。例如在志鉴文本数字化加工模式方面,双层PDF 模式、纯文本模式、图片和文本对照模式均存在一定份额的拥趸(如右图所示)。
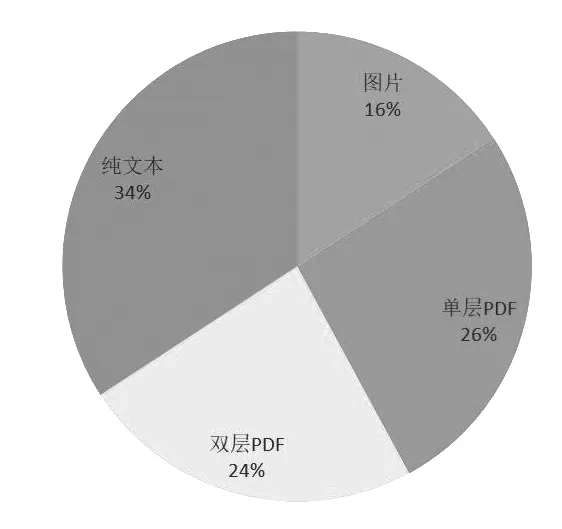
已开展数字方志工作省份志鉴数字化方式比例(注:部分省份使用多种方式数字化)
根据各省地方志工作机构网站2023 年4 月前的公开数据统计,4 个省级地方志工作机构选择双层PDF 格式,5 个省级地方志工作机构选择纯文本格式,3 个省级地方志工作机构选择双层PDF 格式和纯文本格式混用,还有些省份采用单层PDF 格式或多种格式混用。即使是同一省份内的地方志工作机构之间,建设数字方志项目采用的格式和标准也不尽相同。不少省份已完成了较大数据量的加工,短期内难以按照新规范标准重新加工数据。数据格式多样化,在一定程度上增加了数据采集和集成的难度,影响数据模型的设计和构建。
(三)数据以非结构化文本为主
人类生产生活所产生的信息数据天然地具有非结构化的特性,结构化的数据是经过人工干预形成的,地方志数据自然也以非结构化为主。地方志内容虽然有不少表格和枚举文字,但在未进行数据处理前,表格和枚举式的文字同样属于非结构化文本。非结构化数据具有易扩展、易运维、易管理的特点,但是在面临深度数据分析时则力有不逮,需要对数据进行结构化处理。
此处所称的非结构化限定为地方志文本内容,而不是地方志作品本体。全国范围内的数字方志项目,大部分对地方志作品本体进行了结构化存储。其数据结构是针对某一本地方志作品本体的元数据标准,即元数据为该书的分类、书名、出版时间、书号、断限等书籍信息,对于地方志中蕴含的各类地情要素,没有深度分析数据属性,没有定义数据规则,没有进行合理化的数据建模,不同地方志中的数据之间没有建立关联,书中由多方搜集凝练的宝贵数据仍处于非结构化状态,杂乱无章。《国家数字方志馆资源元数据规范(征求意见稿)》定义的元数据规范也是基于地方志作品本体的数据结构,按照规范进行加工形成的地方志数字化文本数据库,只能满足按章节或页码展示原书、书籍内容全文检索的数据需求。可见,对非结构化文本类数字方志地情要素的数据模型研究,同时就是对数字方志发展方向的探索。
(四)覆盖面广但颗粒度不足
地方志虽全面系统地记述了行政区域内的历史与现状,却是一种高度精炼和概括的文献,决不能将其类比于前信息时代的“数据库”。数据库是实时记录数据细节,而地方志是各方面的经过时间沉淀后的凝练数据。因篇幅限制,地方志不可能穷举一地所有情况,即使是篇幅最大的省志,洋洋洒洒五千万字,也无法面面俱到、事无巨细录入全省所有数据,只能对关键且重要内容加以记载,摘录关系重大的统计数据。统计过程中数据的细节是没有办法得以体现,数据库的优势即在数据细节,而地方志的数据深度是不足的。地方志只是从各部门的成分不同的数据水桶中获取一滴,按一定顺序点在一个面板上。这一特征,注定了地方志数据可以为绝大部分领域的工作提供一定的参考,但因颗粒度不足,无法深度参与某一特定工作。地方志数据模型的价值大小即受限于这一因素,这在设计和构建地方志数据模型时需要重点平衡斟酌。
(五)数据产生速度较慢但仍具有一定价值
地方志书每20 年左右编修一次,地方综合年鉴一年编修一次。虽然地方志书中可能会包含多年的详细数据,但一般情况也是年度统计数据。因此可知地方志数据产生的时间间隔在一年以上。相比于某些互联网应用每秒钟产生成千上万条数据,特别是阿里巴巴的数据应用在“双十一”期间每秒的消息处理甚至高达40 亿条,地方志的数据产生的速度是极慢的。通常情况下,以这种速度产生的数据其挖掘的价值较小。地方志数据具有一定的特殊性,数据覆盖面广且官修属性使得其数据的权威性较高、可靠性较强,具有一定的参考价值和跨领域关联价值。
三、地方志数据模型应用案例分析
从本世纪初开始,全国各省地方志工作机构在数字方志建设方面进行了有益探索。迄今为止,数字方志已经成为了数字文化发展的重要组成部分,例如全国智慧图书馆体系建设项目,地方志就是其中数字化的一个重要方面。但这些探索主要限制在使用OCR(光学字符识别)对地方志文本加工处理后实现全文的检索。分析地方志数据结构,设计数据模型的应用仍比较少见。列举分析以下几个地方志数据模型的推广和应用案例。
(一)全粤村情数据平台的村情专题指标体系
全粤村情数据平台采用了数字方志和地理信息系统(GIS)技术相结合的方式,围绕乡村振兴战略构建村情专题指标体系,以广东省自然村落历史人文普查为基础,整理、分析广东省13 万多个自然村落的历史人文普查数据;建立数据库,对村情数据进行深入挖掘、全面分析,形成村情专题分析报告;通过地图、图表等方式展示和分析数据,直观化展示广东省内乡村的历史、文化、风土人情等方面信息,提高了地方志数据的可视化程度;提供自然村落普查数据展示、自然村情可视化统计分析、自然村情专题分析等服务,通过“粤智助”平台向公众全方位展示村落乡情,在古村活化、古驿道保护与修复利用、旅游开发、地理标志产品申报、服务乡村振兴战略等方面均起到一定积极作用。
(二)贵阳方志云的数据对比功能
贵阳方志云主要收录了贵阳市各个地方的地情历史文献,该项目的特色是数据对比功能。用户可以选择区域、时间、指标进行数据对比和分析,对比不同区域在不同历史时期的文化和社会发展变化情况,生成报表、图表、数据地图。但实际的比对效果未能达到预期,其功能实现的底层逻辑原理没有相关资料难以定论。
(三)中国历史地理信息系统的数据可视化
复旦大学和哈佛大学联合研发的“中国历史地理信息系统”(CHGIS)项目的“晚明松江地区历史地理信息系统数据库”,利用《嘉庆一统志》为核心资料,复原了1820 年行政区划的基础地理信息,建立寺庙、学校、商路、渡头、人口、赋税数据等多个图层[1]张晓虹. GIS与中国历史地理信息平台建设[N].光明日报,2023-09-25.。该系统以历史地理学知识架构为基础,对1949 年以前的传统方志数据模型的构建能提供一定的参考价值。
四、地方志数据模型相比非结构化文本的积极意义
现阶段全国范围内的数字方志成果,包括北京爱如生数字化技术研究中心的中国方志库、北京籍古轩图书数字技术有限公司的中国数字方志库等商业性质的数字方志文本,相比传统纸质地方志,大部分能够实现全文检索,为研究人员和爱好者提供了相当程度的便利,但对更深一层的信息化路径没有突破。非结构化文本类的数字方志,在地方志的开发和利用方面只是一项基础工作,数据模型的作用是在此基础上设计一栋高楼。地方志数据模型可以将一个区域的物体和活动抽象概况成为实体,定义清晰的实体属性,相比非结构化文本类的数字方志,具有五个方面的优势。
(一)统一规范性
通过数据模型在各区域之间的共享使用,可以促进建立统一的区域元数据体系,促使各区域按照统一的地情要素编写地方志,并能有效识别过往的地方志缺失数据。经过一定时间的规范发展,统一的地方志数据将有利于简化数据处理和共享程序,降低数据加工成本,提高数据支撑决策能力。
(二)高度连续性
连续性是在规范性基础上发展而来的特性,有了统一的区域元数据体系,使得地方志的内容必须根据模型的所有实体属性数据进行完善,年鉴等连续出版物对区域信息的记载将保证数据在时间和空间上的连续和一致。经过一定时间的规范发展,统一的地方志数据将有利于减少数据出现断层和异常波动的情况,提高数据的质量和可信度,反映区域的整体趋势和规律,有助于更好地理解区域的特征和变化情况,在一定程度上有利于地方志编辑人员判断数据的人为因素干扰和误差,提高数据的准确性和可靠性。
(三)信息可视化
地方志数据模型可以借助信息技术和可视化手段,将信息转化为可视化的图表、地图等,呈现更丰富、更生动的地情信息,能更加直观地展示一个地区的状况,有利于提升地方志传播效益、增强地方志文化影响力。非结构化文本类的数字方志在不进行数据处理的情况下难以实现可视化。
(四)高效可复用
对地方志数据模型进行训练,模型的数据(即训练数据)就可以用于对新的、类似的数据进行分类或预测,可以在不同平台、不同领域、不同项目之间实现高效的数据分析和研究,使地方志数据具有更广泛的应用价值。非结构化文本类的数字方志则需要每次重新进行检索和信息整合。
(五)丰富编纂方法和形式
地方志数据模型不仅可以作为一种数据模型使用,而且提供了一种模板式的简志编纂方法和展现形式,对数字方志和信息方志的工具和边界是有益的扩充。非结构化文本类的数字方志只是将地方志的存储形式由纸质变为电子,在结构内容和编纂方法上没有开创新面貌。
五、设计和构建地方志数据模型的步骤解析
非结构化文本类的数字方志在读志用志方面发挥了一定的积极作用,但也面临着多方面的局限和挑战。为构建地方志的核心竞争力,推动地方志文化的创造性转化、创新性发展,应积极尝试前沿数据治理手段和地方志的结合,加强政策支持、规则制定、人才培养、资金支持、数据共享和交流等方面的工作,逐步消除各种限制,推广和普及全国地方志数据模型,提升地方志数据赋能水平。设计和构建数据模型的具体步骤如下。
(一)加强非结构化文本类数字方志的标准化建设
全国数字方志项目建设存在顶层设计不足、标准多样的问题,大部分处于加工数字文本的基础阶段,必须按照统一的内容展示和存储格式,推动数字方志建设和普及,持续对地方志作品尤其是历代旧志进行数字加工,扩大数字方志规模,提高数字方志规范程度,筑牢地方志数据资源基础。标准化建设需要在必要时采取一定的行政手段,加强数字方志建设的指导和支持,制定全流程的数字方志工作标准,包括数字方志的编纂、存储、标引、加工、发布、导入导出、数据接口等各方面全周期工作标准,优先制定数字方志建设文本加工规范和标准,向基层地方志工作机构提供数字方志建设的技术咨询和技术支持,鼓励基层地方志工作机构开展地方志数字加工,以利于非结构化文本类的数字方志的高效数据提取。
(二)定义数据规则,统筹考虑构建元模型
一般的数据治理过程,会先提取数据和对数据预处理,然后进行数据元模型的定义。地方志作品中纷繁复杂的数据,难以按照常规的步骤进行,须先定义元模型,才能被准确和广泛地提取数据。定义地方志数据规则和构建元模型,确保地方志数据治理过程有章可循,促使各地方志作品的异构数据同构化、同构数据关联化,需要全国各级地方志工作机构的共同努力。为了构建一套长期可用的、准确概括一个地域的各方面属性的元模型,需要承担地方志编纂的各工作部门协同参与。
地方志数据元模型分为两种类型,即通用型的元模型和分级分类的元模型,它们各有优劣之处。
1.通用型元模型
通用型元模型的优点在于模型构建速度较快,只需要选择某特定行政区域的关键基础数据和统计数据即可,即选取该行政区域地方志文本数据的“最大公约数”,具有一定的通用性和可扩展性,且基本不用进行数据补充。它的缺点在于通用状态下,必须抛弃大量有效数据。举例来说,假设省志的字数篇幅在5 千万字左右,县志的字数篇幅在200 万字左右,省志中记载了25 万条有效数据,县志中记载了1 万条有效数据,而通用型元模型只选取一个地域最关键、核心、普适的数据,元模型下可能只有1 千个数据属性,那么省志中24 万9 千条数据和县志中9 千条数据在后期就得不到结构化提取,势必造成数据浪费。通用型元模型虽然普适性较好,但也做不到无限通用,能在省市县三级通用的元模型如果套用在乡镇、村、社区、小区时,因为地域结构或统计口径等多方面差异,会造成大量的数据空值。
2.分级分类的元模型
分层级、分作品类型建立不同的元模型,其优点在于元模型数据属性可以较为广泛、覆盖面广、颗粒度更加细腻,能更加充分利用地方志中的数据,模型实用性更强,但相对来说建模速度较慢,需要建立多个元模型,增加了工作难度和复杂度。同时在建立每个元模型后,在数据提取过程中,需要从多个同级别行政区划的地方志文本求取“最大公倍数”,并对所有行政区划的地方志中缺项漏项的数据进行调查和补充。
地方志数据元模型建立要根据实际需求和人力、财力、物力的配置情况综合考量,也可以采取混合模式,先建立通用型元模型,在通用型基础上,再构建分级分类元模型。同时,元模型的属性应该注意结构分明,以大类统小类,例如可以分基础信息类、资源生态类、基础设施类、社会经济类、文体艺术类、政治组织类等大类,基础信息大类下又可统摄地名、地理位置、地形地势、行政区划面积等信息。元模型的建立,仍要采取“众手成志”的模式,征求各相关行业专业人士意见。通用型元模型的数据属性应以简约而不漏重要项为原则,分级分类元模型则应尽可能做到数据属性充分而不冗余。无论是哪一种元模型,都必须充分考虑属性的可延续性。这些数据属性需要在时代发展趋势下保持大范围的稳定性,在未来较长时间之内,仍然是社会公众所需要、愿意且能够统计的数据。
(三)开展数据提取和数据预处理
根据地方志覆盖面广的数据特征,采取由下而上的方式开展数据处理较为合适。各地方志工作机构应根据定义的数据规则,分工对本区域的地方志进行数据提取,逐层向上一级数据仓库汇总。针对元模型的每项属性,通过文本挖掘技术,从地方志数据中提取关键词和主题,查询检索到地方志中的对应数据,形成数据仓库。数据仓库的形式可以是基于数据库的平台,也可以是按照一定格式排列的文档。有条件的地方,应开展元模型数据标记和元模型数据索引。形成数据仓库的过程,要根据地方志记载的数据情况,对元模型的准确性和科学度进行分析和评估,并将分析和评估情况向上一级地方志工作机构反馈。
从地方志中提取的数据,可能出现数据重复、数据单位不一致、数值有差异等诸多情况。一般情况下,数据清洗是数据加工不可省略的重要环节,完整构建地方志数据模型必须在提取地方志数据以后进行数据清洗。通过逻辑判断、纵横比对等方式,判断数据的准确度,删除重复数据、转换不一致的数据,舍弃不合理数据并补充缺失数据,消除在应用中造成使用者信息误判的可能性。
地方志的数据预处理中最重要的环节就是缺失数据的补充。根据地方志数据源复杂且差异明显的数据特征,可以判断预处理阶段必然存在不少数据缺失。这些数据缺失是地方志编纂过程的先天缺陷。过多的数据缺失将造成模型的不完整性,导致后续的数据挖掘失败。必须邀请参与地方志编纂的各单位给予配合支持,将数据补充完善。一般来说,数据清洗和数据预处理工作使用计算机完成,但对于地方志的数据模型构建来说,数据预处理阶段可能需要大量人工干预。
(四)数据挖掘和数据可视化
通过元模型和数据的正式匹配,即可初步构建地方志数据模型。模型建立之后,需进行广泛的宣传和推广,并使之能反作用于地方志编纂。即要求地方志作品在编纂中,建立数据模型索引,标注清楚模型的属性对应到书籍的页数和行数等位置信息,以利于成书之后的数据能在较短时间内高效利用。同时,也需要积极探索模型的相关应用。
1.模型内容的分类、聚类,强化供给价值
要充分利用庞杂的地方志数据,必须先对数据进行分类,这是前人探索的有效经验。例如竺可桢摘取各类方志记载的植物分布及花开花落时间的变化加以汇总研究,在《中国近五千年来气候变迁的初步研究》中提出“方志时期”(1400—1900 年)。北京天文台从众多旧志中摘录了数百万字的天文资料,汇编成《中国天文资料汇编》。还有《中国古铜矿录》《中国地震历史资料汇编》等书的汇录。这些案例都是通过分类、聚类的方式对地方志文本数据进行提取。可以根据地理位置、时间、行业、领域、主题等因素制定分类方法,建立一整套分类框架,包括分类目录、分类指南,同时鼓励引导多学科参与其中,加强跨学科合作,整理和分类地方志数据模型中的内容,以提高数据模型的应用价值。
2.建立数据关联,打造多形态的地方志数据模型应用
通过关联规则挖掘技术,寻找地方志数据中各个数据之间的联系和规律。通过模型数据,分析数据之间的因果关系、时序关系、频繁模式关系、分类关系、依赖关系。将数据挖掘结果以图形、图像和动画等形式呈现,直观展示数据特征和规律。运用地理信息系统(GIS)技术,将空间数据可视化,是目前已探索出成果的应用方式。同时,丰富地方志数据模型应用还需要拓展地方志数据模型应用传播渠道,在线上综合呈现多媒体可视化的数据分析结果,对接外部链接和数据,满足不同用户的需求,提升数字方志的互动性和用户参与度,深化模型的应用价值,及时获得公众的反馈,便于进一步调整优化模型。
六、结论
全国地方志非结构化文本的数据模型设计与构建的探索、研究处在萌芽状态,是地方志信息化发展中具有前瞻意义的研究课题,对于地方志事业高质量发展具有重要作用和意义。在模型设计的探索过程中,发现了一些理论问题和难点,需要结合地方志数据的特征,加以克服和解决,特别是要尽快解决地方志文本数据无规则、数据无结构的问题,不断改进数据关联能力,提高数据可视化。结构化和智能化的地方志数据模型,将作为重要数据元素载体,极大丰富地方志资源开发利用的形式和内容,融合数字文化等领域的发展,推动地方志事业的创新和转型,为实施国家文化数字化战略、加强精神文明建设贡献“志”慧,为推进文化自信自强、铸就社会主义文化新辉煌贡献“志”力。
猜你喜欢
Plasma Science and Technology(2022年5期)2022-06-01
书法赏评(2019年2期)2019-07-02
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
创新作文(5-6年级)(2018年11期)2018-04-23
电子测试(2017年12期)2017-12-18
西藏研究(2017年1期)2017-06-05
南风窗(2016年19期)2016-09-21
小天使·六年级语数英综合(2014年3期)2014-03-15
测绘科学与工程(2013年1期)2013-03-11
