
一种基于立体注意力机制的立体图像超分辨算法
2023-03-07 10:00罗传未张子慧贺子婷周孟颖
电视技术 2023年1期
罗传未,张子慧,贺子婷,周孟颖,马 健
(安徽大学 互联网学院,安徽 合肥 2 300001)
0 引 言
随着双目成像技术的发展,双目相机和双目摄像头在手机和自动驾驶上的应用越发流行,立体图像超分辨(Stereo Image Super-Resolution)领域逐渐被人们关注。立体图像应用发展的同时,立体图像超分辨任务也面临着涉及图像处理、计算机视觉、立体视觉等领域的基本问题。
基于现有的图像超分辨率研究成果,领域内学者从不同角度对其进行了总结[1-3]。JEON等[4]提出一种基于视差先验的立体图像超分辨重建算法。该算法将右图水平移动不同像素,生成64张副本图像,将其与左图级联后送入网络重建。WANG等[5]提出基于视差注意力机制的立体图像超分辨算法,将self-attention引入到双目视觉中,并通过设计valid mask解决左右图遮挡问题。ZHANG等[6]提出用于立体图像超分辨率的循环交互网络(RISSRnet)来学习视图间依赖关系。YING等[7]提出一个通用的立体注意力模块(Stereo Attention Module,SAM),将其安插至预训练好的单图超分辨率(Single-Image-Super-Resolution,SISR)网络中(如SRCNN[8])并在双目图像数据集Flickr1024上进行微调,结合左右图互补信息的同时保持对单图信息的充分利用,进一步提升了超分辨性能。ZHU等[9]提出了一种基于交叉视点信息捕获的立体图像超分辨算法。DAI等[10]提出一种基于视差估计的反馈网络,可同时进行立体图像超分辨重建和视差估计。
(1)双目图像中,视差的巨大变化使得左右图互补信息难以被充分捕捉;
(2)在捕捉到左右图的关联后,如何充分利用双目图像提供的信息也具有挑战性;
(3)双目图像超分辨在结合左右图的互补信息的同时,还要充分利用一幅图内的信息。
基于以上问题,本文主要研究了基于立体注意力机制的立体图像超分辨方法。为获得更好的立体图像超分辨重建效果,本文对单图超分辨率模型提出进一步改进,在模型的损失函数中加入平滑损失项,使模型在立体图像对中获得更好的一致性。通过对改进前后的算法进行实验结果比较,验证了改进策略的有效性。改进策略明显提高了立体图像超分辨重建后的图像质量。
1 基于立体注意力机制的立体图像超分辨算法
1.1 网络模型结构
基于注意力机制的立体图像超分辨算法的总体框架如图1所示。首先,将立体图像对(包括左视角图像和右视角图像)送入两个SISR网络中,提取左右图的特征,并生成特征矩阵。其次,在两个SISR网络之间插入立体注意力模块。该模块将两个SISR网络提取的左右视角信息进行交互,通过卷积的方式,将单个视角图像内部的信息与不同视角间的互补信息充分融合。最后,通过双路的SISR网络耦合重建高分辨率的立体图像。

图1 基于立体注意力机制的立体图像超分辨算法网络总体框架
1.2 立体注意力模块结构
SISR网络会对输入的左右视角图像进行特征提取。经过立体注意力模块时,立体注意力模块将SISR网络产生的这些立体特征作为输入,捕获立体对应关系,在立体图像超分辨过程的多个阶段交互图像对的左右视角信息。该算法中的立体注意力模块结构如图2所示。
6.3 后期管护(1)用手轻推树干,看苗木根系与土壤是否结合良好,若有明显的裂缝或松动,则说明栽植不到位,应及时补救。(2)观察树坑。土壤疏松有利于根系的萌发,为此,一方面看树坑有无积水,另一方面看浇水后是否松土、有无裂缝要处理。
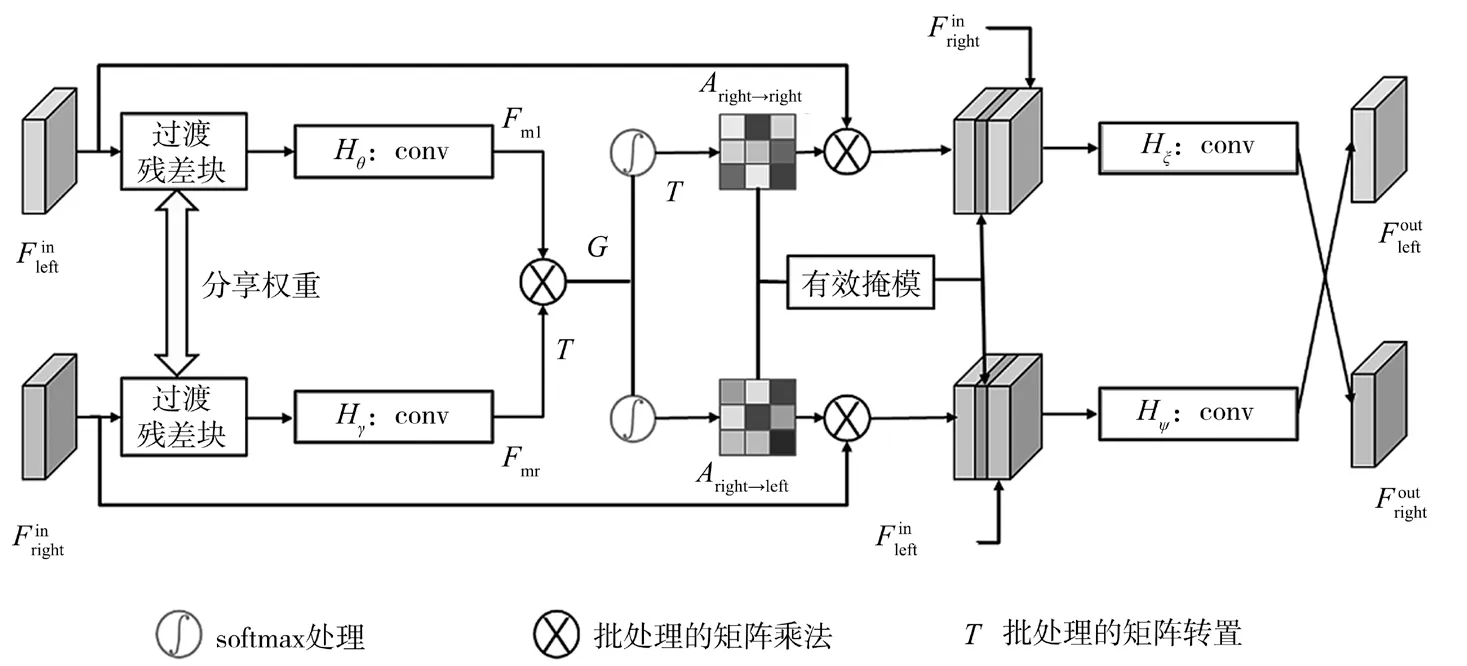
图2 立体注意力模块的内部结构
该算法网络可看作一个多任务网络,既可学习立体图像间的立体对应,也可学习图像的超分辨。在多个任务中,使用共享的图像特征来学习不同任务。输入的左右视角特征和C分别为特征图的高度、宽度和通道数)先输入过渡残差块Hresidual中,以避免多任务学习产生的训练冲突,然后分别经过处理对应视角的1×1卷积层Hθ和Hγ生成对应的特征映射Fm1和Fmr(Fm1,Fmr∈RH×W×C)。
为了生成立体注意力图,先将Fmr转置为在与Fm1之间执行批量的矩阵乘法,生成初始的注意力得分图G∈RH×W×C。然后应用softmax分类,对G和GT进行归一化处理,将多分类的输出结果转化为0到1之间的概率分布,分别生成Aright→left和Aleft→right的立体注意力图。
为了将特征信息从一个视角转移到另一个视角,并得到经过交互的对应视角特征,分别用生成的立体注意力图Aright→left和Aleft→right乘上输入模块初始视角特征,构造视角信息经过交互后的特征Fleft→right和Fright→left(Fleft→right,Fright→left∈RH×W×C)。这一过程的具体表示如下:
式中:⊗表示批处理的矩阵乘法。
由于在遮挡区域中立体图像间相对应区域的左右一致性不成立,被遮挡区域无法从另一侧视角图像中获得额外信息。为处理遮挡问题,使用遮挡检测的方法来生成有效的掩膜(Mask),引导特征的融合。观察到遮挡区域中的像素通常有较小的权重,可用如下计算方法获取该注意力模块的上部分分支的有效掩膜Mleft→right:
式中:W是立体图像的宽度,τ为阈值,根据实验经验设为0.1。因为左视角图像中的被遮挡像素无法在右视角图像中搜索到它们的对应,所以它们的Mleft→right(i,j)值通常较低,于是该网络将这些区域作为遮挡区域。左视角图像中的遮挡区域无法从右视角图像中获得附加的场景信息,因此有效的掩膜Mleft→right(i,j)可以进一步用于引导图像特征的融合。同理,使用类似的方法生成该注意力模块的下部分分支的有效的掩膜Mright→left。
为了将交互的不同视角间的互补信息与单个视角下图像内部的信息整合起来,该模块将输入的左视角特征和经视角间对应交互得到的右视角特征Fright→left以及有效掩膜Mleft→right三者相级联,通过一个卷积层整合,得到特征即为该模块输出到网络中的左视角特征。输出的右视角特征也用相似的方法生成。这一过程可表示如下:
式中:cas(·,·,·)表示级联操作,Hψ和Hξ分别表示对应的视角处理线路上的卷积操作,该操作将交互后的视角特征信息与原输入特征信息以及有效掩膜整合到一起。
1.3 损失函数设置
该算法主要使用了两项损失来训练网络,分别是超分辨损失和光度一致性损失。网络的总损失函数定义为
式中:μ为正则化权值,根据经验设置为0.01;n为网络中注意力模块的个数。LSR表示超分辨损失,定义为超分辨重建后的左视角图像与左视角图像高分辨率主观值之间的均方误差(Mean Square Error,MSE):
Lphotometric表示光度一致性损失,*表示同阶矩阵乘法,Ileft和Iright分别表示输入的左视角图像和右视角图像。该损失定义为
1.4 算法改进策略
本小节在加入立体注意力机制的SISR方法基础上,对本文的算法网络做出一个改进,以实现更好的立体图像超分辨性能。
在本算法中,如果立体注意力图更加平滑,梯度更小,则可以获得更好的立体图像超分辨效果。在当前损失函数的基础上,本节引入平滑损失(Smoothness Loss)函数,将平滑损失定义在立体注意力图Aleft→right和Aright→left上,具体定义如下:
式(9)的第一项用于实现图像垂直方向的注意一致性,第二项用于实现水平方向的注意一致性。加入该平滑损失,可以在弱纹理区域中产生更加准确且具有一致性的注意力,对图像起到平滑的作用。
加入平滑损失后,该算法网络的总损失函数定义如下:
式中:λ经过多次实验测试得出设置为0.002 5的效果最好,此处设置为0.002 5;n为网络中立体注意力模块的个数,其他项详见第2.3节中对于损失函数的描述。
2 实验及结果分析
本节首先介绍了数据集和实验设置,然后对改进前后的基于立体注意力机制的立体图像超分辨算法进行对比实验和分析。
2.1 数据集选择及实验设置
本文使用Flickr1024数据集[11]作为训练集。在实验中,考虑到计算资源的有限,本文仅选择Flickr1024数据集中的400张图像进行网络模型的训练,同时对该数据集进行了训练数据的增强。
在对模型的测试中,本实验使用来自Middlebury数据集[12]的5对立体图像,来自KITTI 2012数据集[13]的20对立体图像和来自KITTI 2015数据集[14]的20对立体图像作为测试数据集,用于检验和选择出最好的模型。此外,还从该数据集中选择了另外50对立体图像作为验证集,以挑选出最优的模型结构。
在算法改进的对比实验设置上,本文选择合适的SISR网络,对改进前后的基于立体注意力机制的立体图像超分辨算法进行对比实验和分析,以探究此项改进的有效性。
2.2 算法改进的对比实验与分析
本文仅针对4倍的超分辨网络应用此项平滑损失的改进。首先对比了SRCNN模型和SRResNet模型改进前后的4倍超分辨结果。其中,“SA_smooth”表示使用该注意力模块且加入平滑损失的算法。实验结果如表1所示。引入平滑损失后,SRCNN和SRResNet模型的峰值信噪比(Peak Signal to Noise Ratio,PSNR)值和结构相似性(Structural Similarity,SSIM)值总体比之前有所提高,其中SRResNet模型的改进较多,PSNR的平均值增益有0.103 dB。由此可得,本节对于算法网络的损失函数的改进加强了对图像中信息的利用,增进了其超分辨效果。

表1 改进前后SRCNN和SRResNet模型的4倍超分辨效果对比
由于此改进策略在SRResNet模型上的表现效果较好,本文继续在该网络上深入分析所提出改进的作用。图3展示了Flickr1024数据集的图像块0543_001的两张立体注意力图的灰度图可视化。图3(a)由无平滑损失的网络生成,图3(b)由加入平滑损失的网络生成。从图3的红框区域可以看出,图3(a)存在梯度不均匀的情况,不加平滑损失的网络梯度较大。而加入该项损失后,得出的图3(b)的梯度明显更加均匀,这使得重建后的立体图像更加光滑,具有更好的质量。

图3 改进前后训练样本0543_001的注意力图的灰度图可视化
梯度流向图可以清晰直观地呈现模型网络中的梯度流向,反映出梯度下降的情况,对于调整模型网络具有重要意义。图4展示了训练样本图像块0001_001在两个网络中的梯度流向图。其中,图4(a)是不使用平滑损失生成的流向图,图4(b)是加入平滑损失生成的流向图。观察改进前后生成的流向图可以看到,加入平滑损失后,梯度显著减小了,说明其立体注意力图更加光滑,证明平滑损失对于图像质量提升有重要的作用。

图4 改进前后训练样本0001_001的梯度流向图
本文还分别计算了改进前后SRResNet网络的L1loss,以探究此项改进对梯度定量值的影响。随机选择训练集中的10个图像块,分别计算它们在未引入平滑损失和引入平滑损失后训练时的L1loss,结果记录在表2中。如表2数据显示,加入平滑损失后,L1loss的数值均比之前减小了,加快了收敛的速度。由于L1loss容易受极端值影响,导致梯度方向偏离正常水平的点,因此可以用来衡量图像的光滑程度。改进后L1loss变小,也说明加入平滑损失可以赋予梯度更合理的惩罚权重,视觉效果也会更加自然。

表2 改进前后SRResNet网络处理部分图像块的L1loss
通过上述对加入了注意力机制的SRResNet模型上平滑损失的影响的深入分析,可以证明加入平滑损失后,立体注意力图的光滑性会增强。当然,由于映射关系,重建后的立体图像也会更加光滑,这是提升图像质量的一个部分。同时,平滑损失函数相当于训练的正则项,加入之后可以有效地避免一些过拟合问题的产生。因此,平滑损失函数的加入是有必要的,本文对于该基于立体注意力机制的立体图像超算法损失函数部分的改进具有一定的有效性和必要性。
3 结 语
本文提出了一种基于立体注意力机制的立体图像超分辨重建改进算法。通过在损失函数中引入平滑项,实验验证了改进前后高分辨率立体图像质量得到了明显的提高。同时,现有的立体图像数据集总体质量处于弱势,限制了立体图像的重建算法发挥更好的作用。未来的研究中可以考虑构建图像数量更多、场景更为丰富、图像质量更好的立体图像数据集,训练出更高效的立体图像超分辨模型。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通·3-4年级(2021年5期)2021-07-16
小哥白尼(趣味科学)(2020年3期)2020-07-27
今日农业(2019年15期)2019-01-03
军营文化天地(2018年2期)2018-04-20
传媒评论(2017年3期)2017-06-13
创新作文(小学版)(2016年10期)2016-11-11
第二课堂(课外活动版)(2016年2期)2016-10-21
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
