
一种基于自适应集成学习代理模型的结构可靠性分析方法
2023-03-14 10:08潘慧雨李忠献
工程力学 2023年3期
李 宁,潘慧雨,李忠献
(1.天津大学建筑工程学院,天津 300350;2.滨海土木工程结构与安全教育部重点实验室(天津大学),天津 300350;3.中国地震局地震工程综合模拟与城乡抗震韧性重点实验室(天津大学),天津 300350)
工程结构和系统的可靠性分析在工程上有着重要意义,常用评估结构或系统的安全储备。而不确定性在实际工程中广泛存在,通常来自于结构系统本身或环境相关的固有随机性变化,如:材料特性、几何尺寸、外部载荷等,对结构或系统的性能及其可靠性有不可避免的影响。因此,考虑结构或系统本身以及环境的不确定性,分析工程结构的可靠性十分重要。
考虑不确定性影响的结构可靠性分析常需要通过大量的确定性分析来实现,而复杂结构每一次确定性分析都需要大量计算时间。这导致可靠性分析方法,如:近似解析法(FORM、SORM[1]等)、抽样仿真方法(蒙特卡洛模拟(MCS)、重要抽样法(IS)[2]、子集模拟法[3]等)均存在对非线性问题求解精度低且只适用于显式功能函数、效率低、样本量大等问题。
因此,利用代理模型来近似功能函数计算结构的可靠性分析方法快速发展起来,如:Kriging模型[4-5]、支持向量机[6-7](SVM)、人工神经网络[8- 9]等。而代理模型方法一般采用无规则选点,导致选点过多且精度无法保证。主动学习代理模型方法,通过自适应学习函数加点的方式,选择性添加样本点构建代理模型,可以实现有限设计点构建代理模型,替代复杂且耗时的原模型。
目前,可通过改变选取不同的代理模型或采用新的学习函数改进上述方法,其中自适应集成策略的可靠性分析方法是目前研究热点之一。鉴于Kriging 模型[10]可提供预测点响应的均值及方差,有学者基于Kriging 模型提出自适应序列采样方法,如:KOH 等[11]提出EFF函数选择距极限状态最近的点作为新增样本点(AK-MCS+EFF);ECHARD等[12]提出U 函数来衡量待测样本的误分概率,并将U 值最小点定义为最佳样本点(AK-MCS+U);LÜ等[13]提出期望风险函数(ERF)和H 函数[5]分别在Kriging模型的极限状态面附近搜索预测误差大、信息熵大的点作为新增点;而后SUN 等[14]开发了最小改进函数(least improvement function,LIF),提高了新样本加入到训练样本集后估计失效概率的准确性。而Kriging 的特点是将计算模型输出的局部变化作为邻近实验设计点的函数进行插值,缺少全局性。SCHÖBI等[15]将多项式混沌展开式(polynomialchaosexpansion,PCE)和Kriging 相结合,提出PCKriging 模型(polynom ial-chaos Krigingmodel),采用一组稀疏的标准正交多项式逼近计算模型的全局行为,Kriging 控制模型输出的局部可变性,并基于PC-Kriging 提出一种新的可靠性分析方法[16]。
上述基于代理模型的可靠性分析方法都有着较高的准确度和效率,属于基于单一代理模型的可靠性分析方法。由于每种代理模型各有优势与缺点,而对具有隐式功能函数的情形,在设计前难以了解其特性,如何选取合适的代理模型是一个难题。因此,CHENG等[17]提出了一种基于PCE、SVM、Kriging 的集成可靠性分析方法。该方法基于三种代理模型与集成模型计算新的样本点时,需额外计算预测点的统计信息,引入了集成误差,可能导致失效边界拟合不佳。对此,本文提出基于自适应集成学习代理模型(Kriging 模型与PC-Kriging模型)的结构可靠性分析方法。在代理模型能提供预测点统计特征基础上,拟合失效边界,提升可靠性分析的准确性与效率,并通过3个算例予以验证。
1 代理模型
Kriging 和PC-Kriging 模型均在结构可靠性分析方法中经过验证,且在预测过程中均能提供预测点的期望与方差,为学习函数构建提供更多信息,本文选用这两种模型集成可以避免其他组合方法由于额外计算所增加的不确定性影响。
1.1 Kriging 模型
Kriging[18]起源于地质统计学,是一种半参数的高效插值方法,也称高斯过程回归,使用最佳线性无偏预测估计给定点的值,解决了非参数方法的局限性,可表示为:
其中:
式中:ηT(x)为基函数,β 为对应的回归系数向量,则ηT(x)β 表示GKRG(x)的均值;z(x)是均值为0、方差为的高斯过程;过程空间样本点x i与x j的协方差可表示为:
表示回归过程中的广义均方误差。R(x i,x j,δ)为由参数δ 定义的相关性函数,描述样本与样本间的相关性。Kriging 采用高斯相关函数:
式中:K为样本数量;、分别为向量x i与x j的第k个分量;可利用极大似然估计或交叉验证求解超参数δ。
假设初始试验设计X={x1,x2,…,x K}及其对应的极限状态Y={y1,y2,…,yK},通过极大似然估计方法可以估计β 与:
式中,E是K×1阶元素皆为1的向量。
考虑任意输入样本x及其预测的响应值y服从正态分布N(μ,σ2),其预测值如下式:
其方差为:
式中:
根据该模型,接近已知训练点的点的响应预测比远离已知训练点的点的响应预测具有更高的置信度。Kriging 模型提供的概率信息,可以更有效地用在可靠性估计中选择下一个样本点。
1.2 PC-Kriging 模型
上述Kriging 模型的特点,是将计算模型输出的局部变化作为邻近的试验设计点的函数进行插值,相比之下,PCE[19]则使用一组正交多项式来逼近全局行为。PC-Kriging[15]则将Kriging模型的回归基函数采用多项式混沌展开进行替代,增加模型全局性,利用高斯过程捕获模型的局部变异性,可表示为:
对于每一个x i,(i=1,2,···)为希尔伯特空间L2R,fXm的完全正交基,其与输入分布相干的正交性可以表示为:
式中:λij为1(i=j)或0(i≠j);fXm(x)为x的第m个边缘概率密度函数。
本文采用最优PC-Kriging 模型,假设输入随机变量x服从各分量独立的多元标准正态分布,采用最小角回归(LAR)[20]理论确定函数的基函数集个数,构建回归基函数的最优多项式数量集,采用Akaike 信息准则(AIC)[21]来确定最优的截断集合。得到的模型根据它们各自的全局留一(leave-one-out,LOO)交叉验证误差进行排序,并选择具有最小LOO误差的代理模型作为最优PCKriging 模型。
2 代理模型集成学习策略
不同的代理模型各有优劣,当缺乏描述响应和输入变量之间关系的信息时,工程师很难判断选择何种代理模型是最佳代理模型,且代理模型的精度依赖于训练数据集中的设计点数以及响应的形式(线性、非线性、噪声、平滑等)。GOEL等[22]指出,代理模型预测存在不确定性,因此选择合适的学习策略,对适应性较广的不同代理模型进行集成,由此得到的集成学习代理模型利用了独立代理模型的预测能力,可提高响应预测的准确性。
本文利用Kriging 模型和PC-Kriging 模型共同具备预测点响应的均值及方差的能力,对以上两种代理模型进行集成,具体表述为:
式中:GW(x)为集成学习代理模型的预测响应;VW(x)为集成学习代理模型对预测点的响应方差;型在样本点x相关联的集成系数,具体表述为:N为不同代理模型的数量,本文N=2;(x)为第i个代理模型的预测响应;ϑi(x)为与第i个代理模
式中,eLOO,i为第i个代理模型的全局留一(Leaveone-out,LOO)交叉验证误差。在本文中,设α=0.05和β=1[22],较小α 和较大β 赋予最优代理模型高权重,将相对平均的系数分配给每个代理模型,因此,具有小eLOO的代理模型在自适应集成模型中起主导作用。
3 自适应集成学习代理模型方法
在本节中,基于集成学习代理模型提出了一种新的可靠性分析方法。
3.1 学习函数
学习函数是将候选样本池的样本点进行排序,筛选新的样本点以丰富当前训练样本集,从而达到提高代理模型精度的目的。本文利用Kriging 和PC-Kriging模型可提供预测点均值与方差的特性,以U 函数为基础,构建一种新的加权学习函数:
当x越接近失效边界,即|GW(x)|越小越接近于0时,或当VW(x)较大即存在较大的预测误差时,UW(x)值越小,因此可以通过计算侯选样本池中样本点的UW,取其中最小值对应的样本点x添加到当前训练样本集中,以优化加权代理模型。
3.2 收敛准则
在本文中,依照加权代理模型特性,采用基于方差与失效概率的收敛准则,取ε0=0.05,且满足连续2 次迭代成立即收敛,定义失效概率停止收敛准则如下:
式中:
本文中设置置信度k=2。
3.3 本文提出算法流程
为所提出方法的流程如图1所示。步骤如下:
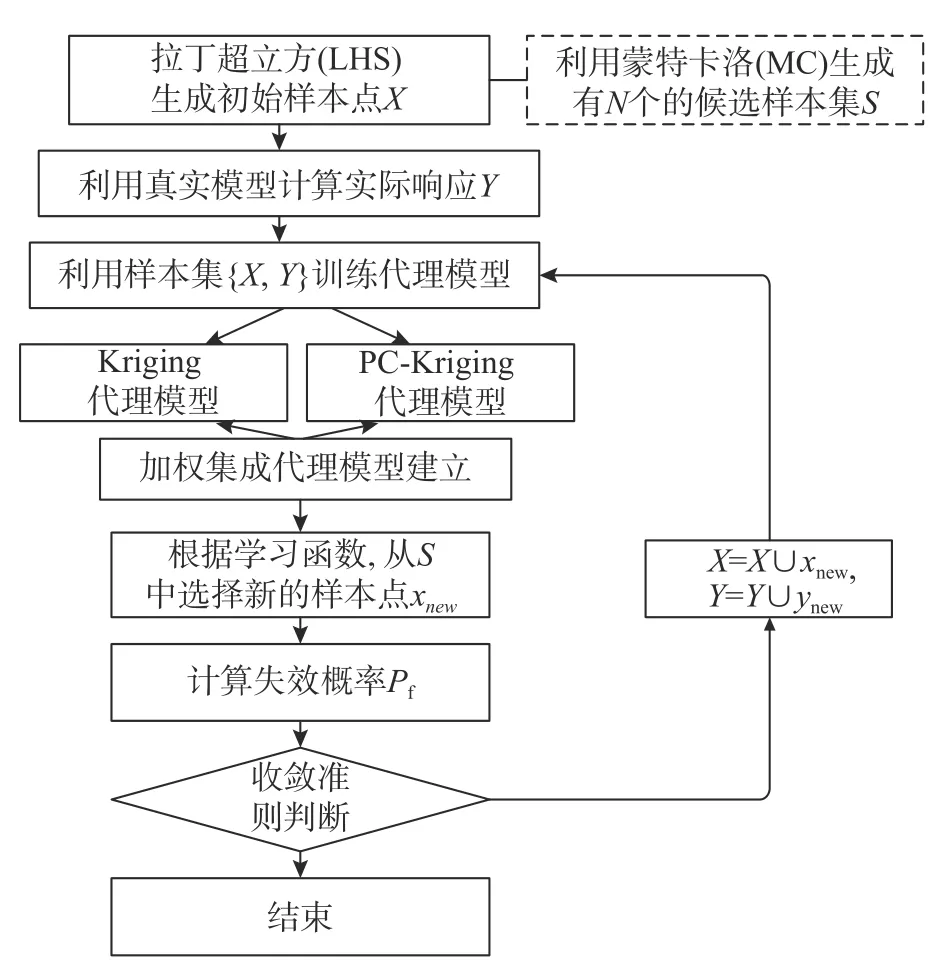
图1 所提结构可靠性分析方法流程图Fig.1 The flowchart of the proposed structure reliability analysis method
步骤1.采用拉丁超立方(LHS)生成少量的初始样本点训练集X=[x1,x2,x3,···,xn];
步骤2.利用真实模型或函数计算相应响应值Y;
步骤3.利用样本集{X,Y}同时训练Kriging 模型和PC-Kriging 模型,并计算两种模型全局留一交叉验证误差eLOO,通过式(19)计算各模型加权集成系数,构建加权代理模型,构建两种代理模型采用Matlab工具UQLAB[23];
步骤4.取式(20)计算侯选样本集S对应学习函数值UW,取UW最小值的点作为新样本点xnew,真实模型或功能函数计算相应响应值ynew=GW(xnew),添加至初始样本集中,X=X∪xnew,Y=Y∪xnew;
步骤5.通过式(23)利用已构建代理模型计算失效概率Pf;
步骤6.重复步骤3~步骤5,直到满足收敛准则式,停止并计算失效概率。
4 算例分析
本节采用极限状态函数的非线性程度、随机变量维数、复杂程度不同的算例[12, 24-25]进行可靠性分析。
4.1 二随机变量算例
该算例是一个四边界串联系统[12,24],其具有很强的非线性行为,该系统表达为:
其中,x1和x2的分布服从正态分布,如表1所示。

表1 四边界串联系统的分布参数特征Table1 Distributed parameter characteristics of four boundary series systems
采用MCS方法根据参数分布生成106随机样本作为侯选样本池S,采用拉丁超立方抽样的方法生成20个侯选样本点。执行所提出的学习算法,并通过所提出的学习函数依次添加新样本,直到满足停止标准。运算结果如表2所示。
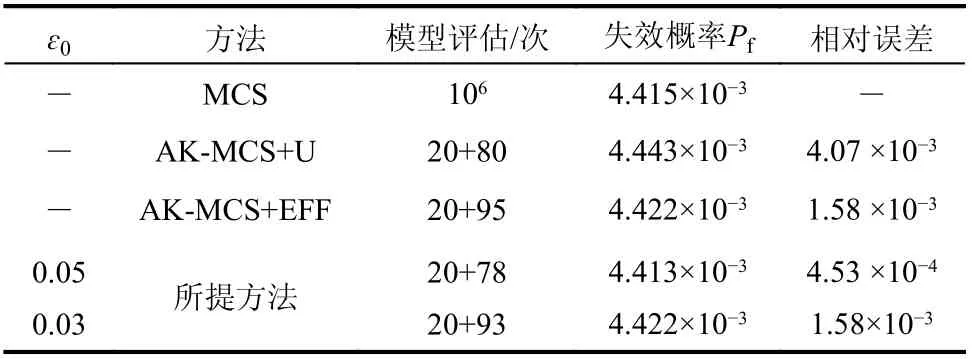
表2 四边界串联系统的计算结果Table2 Calculation resultsof four boundary series system
表2可知,所提方法与基于U 学习函数的AK-MCS方法和基于EFF学习函数的AK-MCS方法比较。结果表明,所提方法能够显著减少系统模型下对其性能函数的调用次数,迭代20次时,逐渐收敛至真实失效概率。以106次MCS结果作为结构可靠性分析结果的参考解,在相同初始试验设计条件下,取停止阈值为0.05时,所提方法调用性能函数97次,比AK-MCS+U 和AK-MCS+EFF在调用次数上降低2%和14.8%,在精确程度上提升88.9%和71.3%;当取停止阈值为0.03时,所提方法调用性能函数113次,在调用次数上大致相同,在精确程度上分别提升61.2%和0%。图2表示所提方法在迭代过程的集成系数变化和失效概率收敛过程。
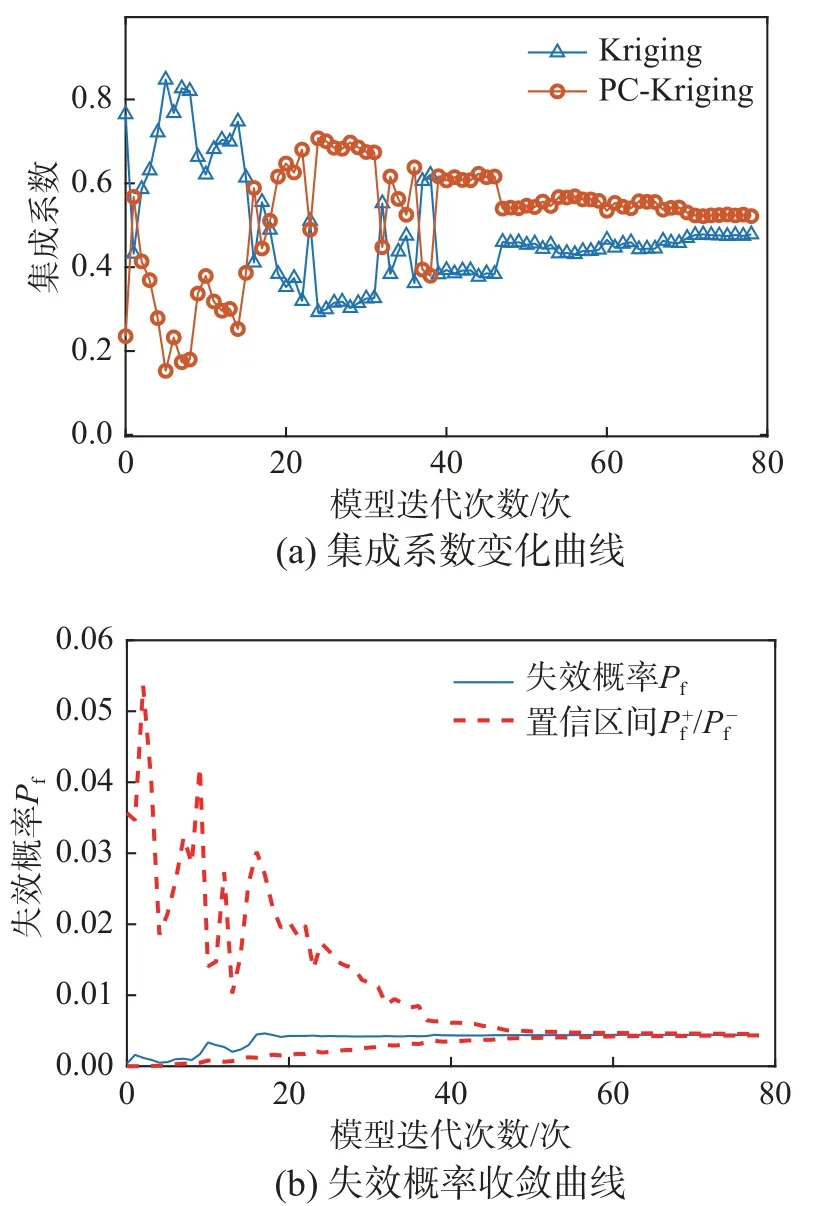
图2 所提方法:集成系数变化曲线和失效概率收敛曲线Fig.2 The proposed method:Ensemble coefficient variation curve and failure probability convergence curve
图3和图4分别给出了AK-MCS+U 与所提方法拟合模型失效边界的过程,在增加样本点25次时,AK-MCS+U 方法仅拟合一条失效边界,而所提方法可实现大致拟合四条失效边界,提升收敛效率。在满足收敛准则后,较AK-MCS+U,所提方法拟合边界更精确、迭代次数更少。
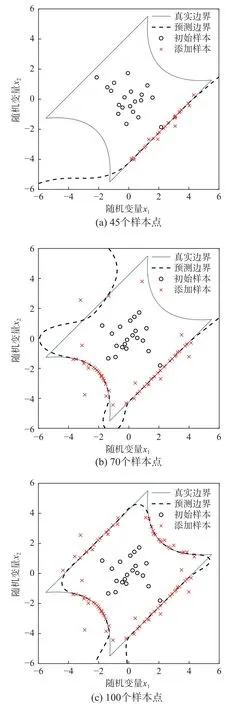
图3 失效边界拟合过程:AK-MCS+UFig.3 Failure boundary fitting process:AK-MCS+U

图4 失效边界拟合过程:所提方法Fig.4 Failure boundary fitting process:The proposed method
4.2 六随机变量算例
六随机变量算例是一个高非线性振子系统[12,25],该系统如图5所示。
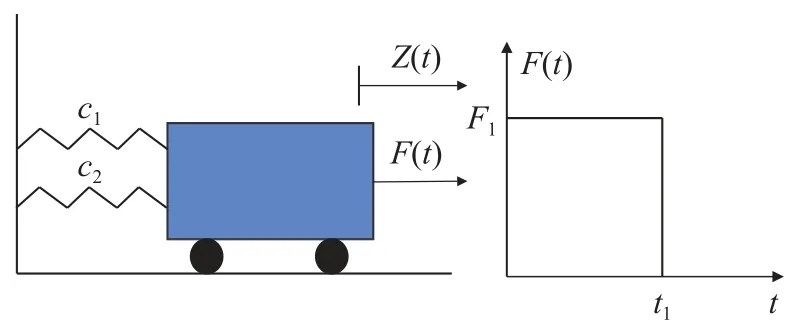
图5 高非线性振子系统Fig.5 Highly nonlinear vibration subsystem
算例中采用MCS生成样本数为106的计算结果为标准,进行对比分析,其极限状态函数(功能函数)为:

表3 高非线性振子系统的参数分布特征Table 3 Parameter distribution of highly nonlinear vibration subsystem
表4将非线性振子系统中所提方法与AKMCS+U 方法和AK-MCS+EFF方法结果进行了比较。结果表明,所提方法能够显著减少模型对其性能函数的调用次数,以106次MCS结果作为结构可靠性分析结果的参考解,在相同初始试验设计条件下,取停止阈值为0.05、0.03时,所提方法调用性能函数次数分别为36、56,分别比AKMCS+U 和AK-MCS+EFF在调用次数上降低69.2%和79.8%,52.1%和68.5%。取停止阈值为0.3时,所提方法在精确程度上均提升100%。图6表明,所提方法在迭代过程的集成系数变化和失效概率收敛过程,经历10次迭代时,预测值开始接近参考解。表5比较不同方法CPU 计算时间,所提方法计算效率较优。综上,所提方法适用于非线性系统结构。

表5 高非线性振子系统的CPU 计算时间Table5 CPU calculation time of highly nonlinear vibration subsystem
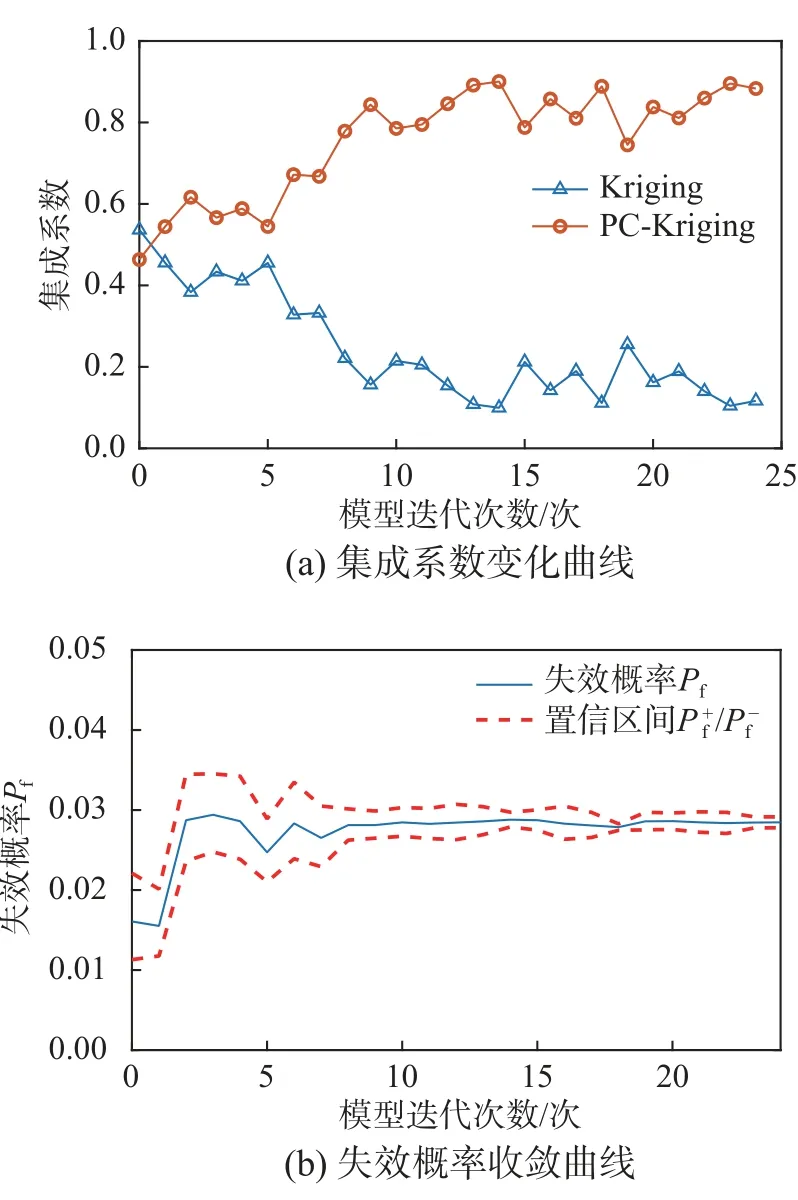
图6 所提方法:集成系数变化曲线和失效概率收敛曲线Fig.6 The proposed method:Ensemble coefficient variation curve and failure probability convergence curve
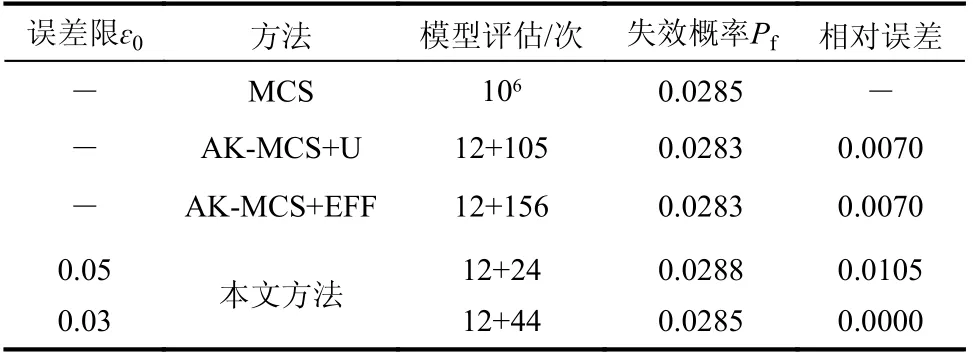
表4 高非线性振子系统的计算结果Table 4 Calculation resultsof highly nonlinear vibration subsystem
4.3 九自由度模型算例
如图7所示,该算例为一个悬臂圆筒结构[24-25]的九个变量问题,对悬臂结构施加3个外力和1个扭转。为包含一组不同的随机变量,本文考虑三种类型的分布情况:正态分布、Gumbel 分布和均匀分布,具体参数如表6所示。其功能函数定义如下:
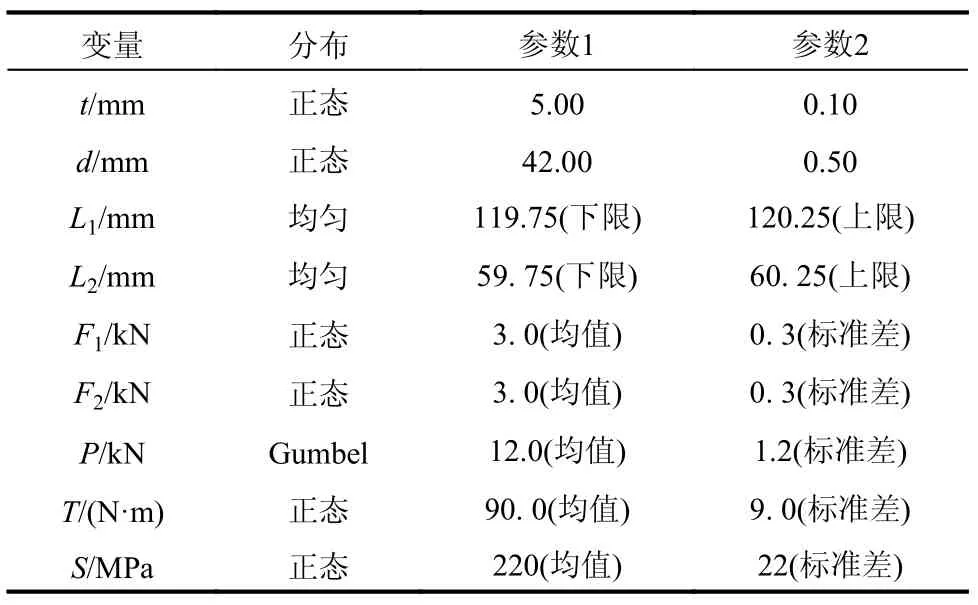
表6 悬臂式圆筒结构的分布参数特征Table 6 Distribution parameter characteristicsof cantilever cylinder structure
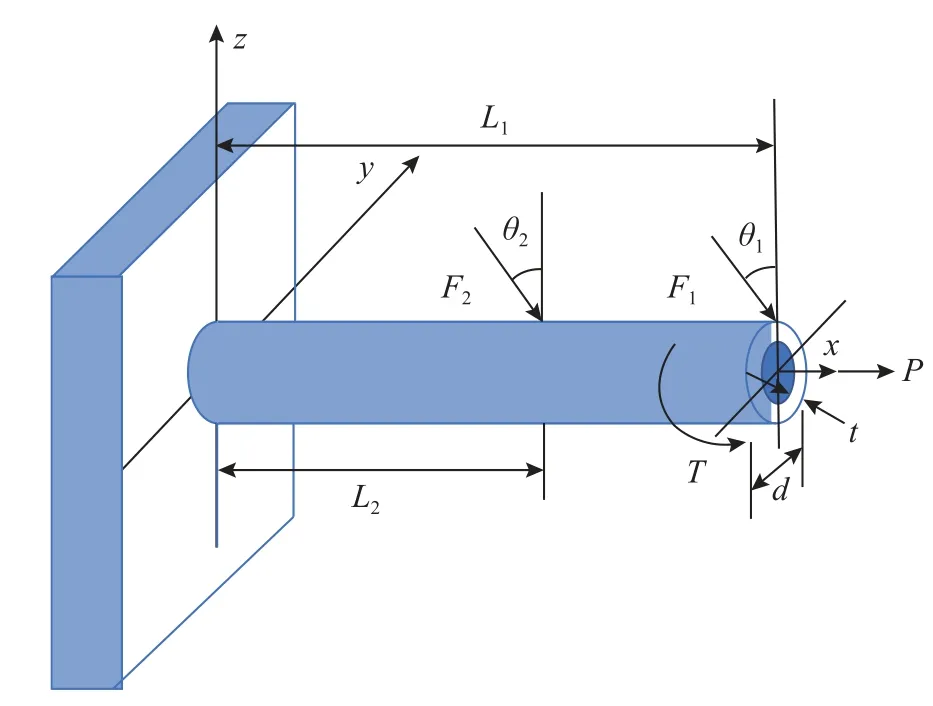
图7 悬臂式圆筒结构Fig.7 Cantilever cylinder structure
式中:S表示为结构屈服强度;σmax为结构在原点所受最大应力,表示为:其中:θ1=5°,θ2=10°,A=[d2-(d-2t)2]π/4是管的截面面积;M=F1L1cosθ1+F2L2cosθ2为所受弯矩;I=[d4-(d-2t)4]π/64为截面惯性矩;τzx为扭转应力,τzx=Td/2J,J=2I;c=d/2为圆筒半径。
该结构可靠性分析计算结果如表7与图8所示,表8比较各方法的CPU 计算效率。所提算法在迭代21次失效概率收敛于MCS参考值,计算效率较高。在给定的阈值下,所有考虑的方法的候选设计样本S和初始训练点保持相同。结果表明,所提方法是求解高维问题有效的方法。实际上,与AK-MCS+U 和AK-MCS+EFF方法相比,所提方法对功能函数的调用次数分别减少了54%和36%,47%和29%。在停止阈值为0.05时,调用次数与预测真实的失效概率效果最好,可能是过拟合所致。综上结果,证明了所提方法在非线性程度和随机变量维数不同复杂性系统中的适用性。
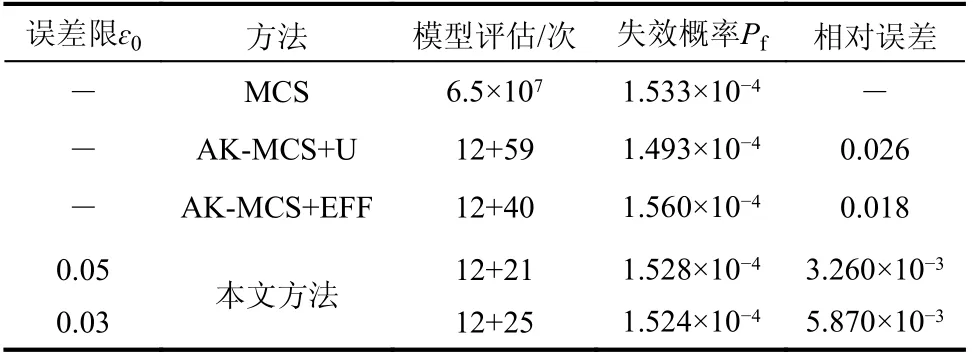
表7 悬臂式圆筒结构的计算结果Table7 Calculation resultsof cantilever cylinder structure

表8 悬臂式圆筒结构的CPU 计算时间Table 8 CPU calculation time of highly nonlinear vibration subsystem
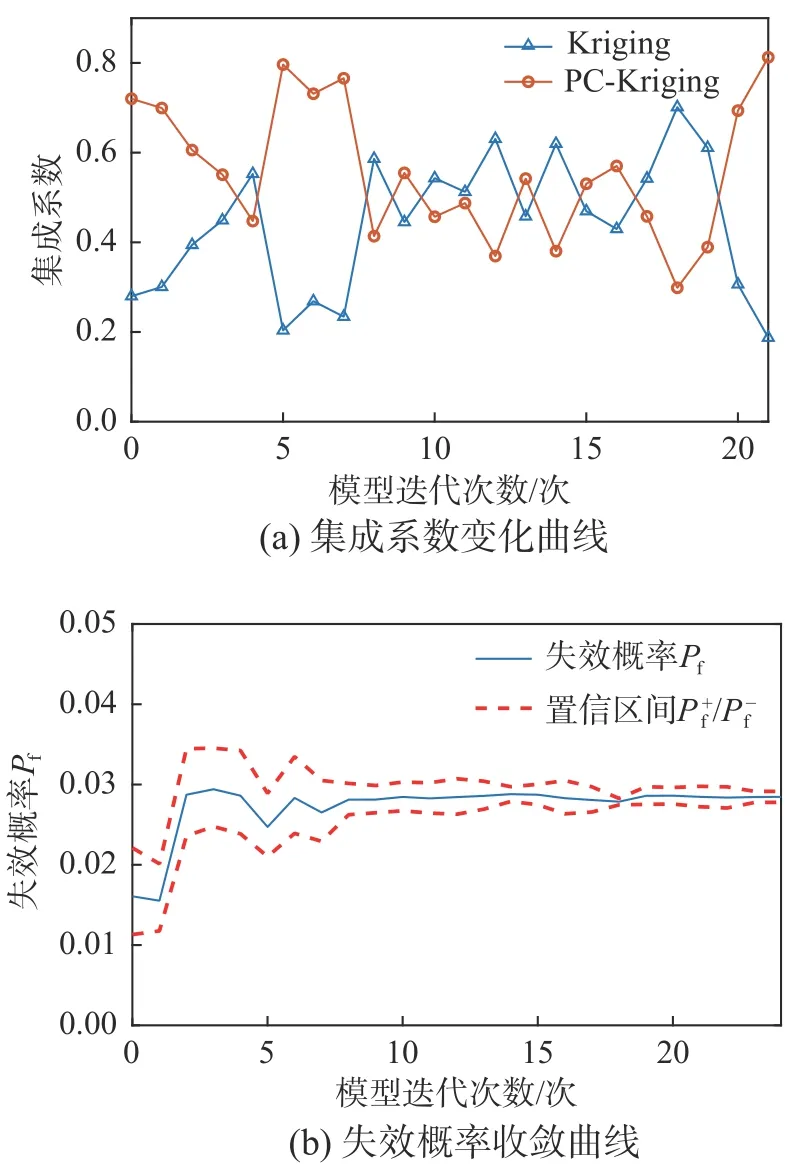
图8 所提方法:集成系数变化曲线和失效概率收敛曲线Fig.8 The proposed method:Ensemble coefficient variation curveand failure probability convergence curve
5 结论
本文提出基于自适应集成学习代理模型的结构可靠性分析方法,并用算例验证了该方法的合理性,具体如下:
(1)将Kriging 模型与PC-Kriging模型进行留一交叉验证,建立集成学习代理模型。综合两种模型的优势,应用于结构可靠性分析。
(2)利用Kriging 模型与PC-Kriging 模型提供的预测点的统计特征,基于U学习函数,提出一种新的学习函数UW。该算法提高了选点的效率。
(3)通过3个非线性数值算例,对本文提出的基于自适应集成学习代理模型的结构可靠性分析方法,大幅减少了对功能函数的调用次数,以及准确地估计失败概率,减少错误率。
需要说明的是,本文方法在建模、计算中没有对结构功能函数的非线性形式、随机变量数量做特定假设。因此,理论上,该方法能够应用于工程中非线性程度较高、随机变量复杂的情况。且通常情况下,真实结构或系统模型较代理模型的拟合过程要远远费时,构造多个代理模型所产生的额外计算量很小,并不会影响算法计算效率。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
重型机械(2020年2期)2020-07-24
上海质量(2019年8期)2019-11-16
中国航海(2019年2期)2019-07-24
趣味(数学)(2018年12期)2018-12-29
电子制作(2018年23期)2018-12-26
现代营销(创富信息版)(2018年8期)2018-09-08
北京航空航天大学学报(2017年6期)2017-11-23
电子制作(2017年2期)2017-05-17
中国火炬(2014年1期)2014-07-24
