
基于Bert模型的文本多分类应用研究
2023-03-24 01:25昌磊王依伦陈艳平
电脑知识与技术 2023年4期
昌磊 王依伦 陈艳平
关键词:BERT;文本分类;迁移学习
1 概述
随着互联网的发展越来越发达,教育领域也因教育信息化而发生了巨大变革,通过搜索引擎和在线答题平台咨询学习问题已逐渐成为学生及老师学习的一种方式[1]。在咨询过程中,问答系统会对用户提出问题的类别进行准确区分,如题目的学科或题目考查的知识点。知识点在教育教学过程中起着重要的作用,可对题库根据知识点进行分类,然后根据学生的学习情况,有针对地将习题推荐给学生,老师也能根据学生的做题情况有针对地进行拔高训练,为学生设计阶段性学习方案,学生能更快速地掌握知识点,学习效率能得到快速提升。
传统上,教师或教研人员需要人工判断习题的题型,浪费时间和精力,而且过程十分消耗耐心。在设计建立试题库,问答系统等场景下,就可以利用文本分类的方法对题目进行试题分类,即机器代替人工实现题型分类提高了教师的工作效率。同时也能使得试题和试卷的管理更高效而便捷,大大节省了教师的工作时间,便于教师有更多时间和精力致力于教学方法的研究,毕竟合理的教学方法也同样影响着学生的成绩。
题型分类属于自然语言处理短文本分类任务,需要对相关文本进行处理,得到文本的向量化表示。近年来,深度学习方法渐渐兴起,目前主要是采用词嵌入的方式获得文本的特征表示,如利用word2vec 模型学习文本中词向量的表示,也可以用预训练模型BERT得到文本的语义表示完成文本分类[2]。
基于转换器的双向编码表征BERT是2018年由Google 推出的,在多项NLP 任务中取得了卓越的效果[3]。使用預训练模型BERT,能够解决一词多义问题,而且对中文文本语义的获取BERT 预训练模型有更好的效果。对于不同的下游任务,BERT的结构可能会有不同的轻微变化。
2 相关研究
2.1Bert 模型
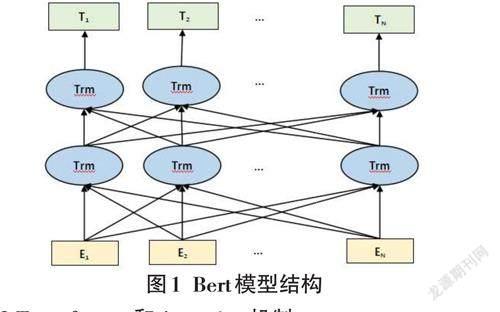
BERT模型是基于Transformer模型的一种双向多头自注意力编码器组成的深层预训练模型。双向的意思是该模型能通过某些数据便可以获取这个句子在上下文语义的功能[4]。BERT模型示意图如图1所示,可以很清楚地看到BERT采用了Transformer En? coder block进行连接,但舍弃了Decoder模块, 这样最终使其拥有了双向编码能力和强大的特征提取能力。
2.2 Transformer 和Attention 机制
多层Transformer 组装成了Bert模型。而Atten? tion 机制又是Transformer中最关键的部分,它表示了各个词语之间的联系程度。Self-Attention就是一种可以考虑全局信息的机制。Multi-head Self-Attention 获取输入文本中每个不同的字基于不同题型的语义向量,然后进行线性组合,最终得到的特征向量和输入向量长度相同,利用的就是不同的注意力机制。在Multi Head Self-Attention基础上添加残差连接和层归一化及线性转换。而Bert 模型就是由多个Trans?former Encoer堆叠起来得到的[5]。
3 基于BERT-CNN 的K12 教育题库的题型分类模型
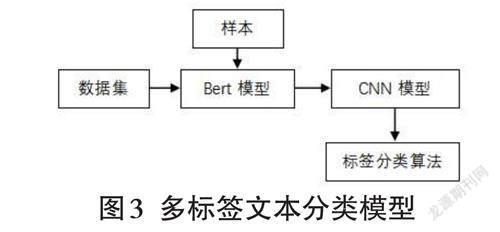
本文是基于K12教育题库的题型多分类问题,采用基于样本的迁移学习方法,其分类模型如图3所示。
3.1 算法流程
本文提出一种基于BERT-CNN的K12教育题库的题型分类模型,其具体的算法流程如下。
4 实验结果及分析
4.1 实验数据集
本文数据集采用K12教育题库长文本20000个题目,根据对应的不同知识点,一共将文本分为6个类别,分别是:二次函数与反比例、三角函数、生理与健康、科学、设计及生物。每个题目的平均文本字符长度为20~30,训练集、验证集、测试集的比例为:8:1:1。
4.2 实验环境
本次实验编程软件使用的是Pycharm 社区版,操作系统为Windows10,GPU 为NVIDIA RTX3060。基于Python3.8,使用Anaconda 编程平台,选择Pytorch 作为深度学习框架。
4.3 参数设置
预训练模型采用Google 发布的中文BERT-Base,基于64 个多头自注意力机制和12层双向Transfomer 编码器对K12教育数据短文本进行动态字向量训练。并根据数据集的特点微调BERT,以提升BERT 的下游任务的效果[7]。由于电脑显存限制, batch _size设置为64,Epoch 设置为3, learning_rate 设置为3e-5,num_classes 表示类别总数设置为6。
4.4 实验结果
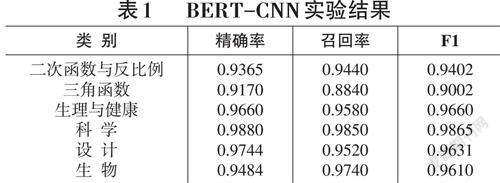
本实验使用“提前停止”技术,这可以更好地避免过拟合问题。对于文本分类的效果采用精确率(Preci? sion) 、召回率(Recall) 和F1值3个指标进行评价[8],实验结果如表1所示。
5 结论
从表1可看出识别的标签不同,评价体系得分也不同,所有标签平均得分为0.95. 准确率也是0.95。
从实验结果可以看出,该模型实现了K12教育题库类中文文本的多分类,并且Bert- cnn在各项评测指标中的表现也令人满意。但由于习题科目及知识点种类繁多,关系复杂,所以数据集的构造还需要烦琐的工作,想要继续提升准确性,还需要优化数据集并优化各种模型及参数。
猜你喜欢
现代交际(2017年18期)2017-09-11
振动工程学报(2017年1期)2017-04-21
计算机应用(2016年12期)2017-01-13
现代电子技术(2015年14期)2015-07-22
