
基于CsBiLSTM的中文影评情感分析
2023-04-06 14:04赵赛仙张元琴周顺江覃勇孙大旭龚维印
电脑知识与技术 2023年5期
关键词:情感分析
赵赛仙 张元琴 周顺江 覃勇 孙大旭 龚维印

关键词:CBiLSTM;影评;情感分析
近年来,随着多媒体技术的飞速发展和智能设备的普及,每天都会产生源源不断的互联网数据,很多用户会在社交平台上发布大量的影视作品评论[1-2]。比如购物评价、QQ音乐、短视频评论等。许多带有用户情感的文本将作为研究用户情感、立场和观点的依据。现在很多用户一边观看一边进行综合评分,一些用户在影视下方发出的评论常常被忽略,这种现象达不到一个很好的参考价值。影视投资人不仅要知道用户评价的情感走向,还应当将用户的情感变化和诸多影响用户评价的因素考虑到其中[3]。
情感分析旨在对带有情感色彩的主观性文本进行分析、处理、归纳、推理的过程,其常应用于消费决策、舆情分析、电子商务等领域,具有较高的商业应用价值[4]。本文由情感分类算法为切入点介绍了当前流行的情感分析方法,进而提出了基于CsBiLSTM的情感分类方法。采用情感分析方法,可以通过主观描述来自动判断自然语言文本的积极和消极的情绪倾向,并得出相应的结论。
1 相关工作
1.1 数据预处理
首先通过爬虫技术获取实验数据;然后获取数据中的星级和具体的评论内容,将三星级的内容去除,将一、二星级标注为-1,四、五星级标注为1作为实验数据的标签;最后利用正则表达式去除评论中存在的西文字体,再采用Jieba分词工具进行分词处理。
1.2 词嵌入向量
文本信息无法直接输入进行特征提取,需要将文本转换为具体的向量进行表示,从而方便计算机的处理[5]。早期使用的one-hot编码方式中,词与词之间相互独立,忽略了词与词之间的逻辑性以及无法区分词的相似性。为了较好地克服传统词向量存的不足,本文使用分布式进行连续性表示,将文本中的词从高维空间映射到低维空间。本文词向量使用Word2Vec训练词向量。
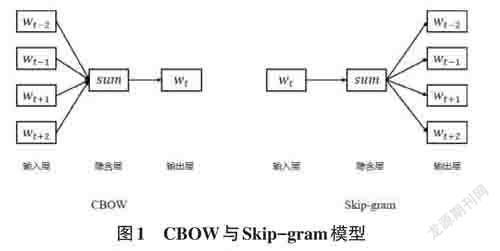
开源词向量工具包Word2Vec于2013被Google推出[6]。Mikolov团队因神经网络模型采用两个非线性变换,网络参数较多,训练速度延迟且不利用于大语料的特点而简化了它,并实现了Word2Vec词向量模型。它具有简易、卓效的优点,从而十分适用于从庞大及巨型语料中获取高精度的词向量表示。Word2Vec 主要包含CBOW 和Skip-gram 组成[7],具体如图1所示。
CBOW模型用一个隐层预测中心词t,即通过中心词附近的n 个词预测中心词t的概率。如“我”“很”“喜欢”“这部”“电影”,就是通过周围词“我”“很”“这部”“电影”预测中心词“喜欢”;Skip-gram模型用一个隐含层预测周围词,即通过中心词t预测周围n 个词的概率,如“這部”“电影”“演员”“演技”“不行”,就是通过中心词“演员”预测周围词“这部”“电影”“演技”“不行”。本文使用Skip-gram模型训练维度为50的词向量。
2 模型介绍
本文的实验模型包括输入层、嵌入层、卷积神经网络、双向长短期记忆网络、K-最近邻,具体的模型如图2所示。
2.1 卷积神经网络
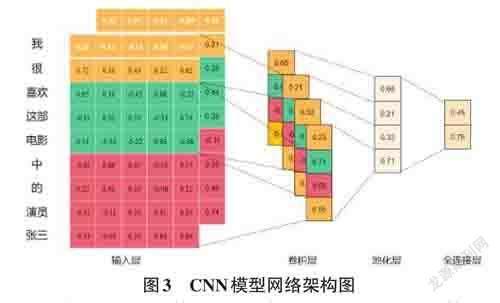
卷积神经网络主要用于图像识别、语音识别、自然语言处理等领域[8]。Kim于2014年首次将卷积神经网络用于自然语言处理[9]。卷积神经网络(Convolu?tional Neural Network,CNN) 是具有深度结构的前馈神经网络,主要包括卷积计算,其网络模型基本结构有输入层、卷积层、池化层、全连接层和输出层[10]。CNN模型的架构图如图3所示。
输入层:在图像处理领域,为0~255之间具体的像素。在本文中将句子或者文本表示成向量矩阵。
卷积层:通过局部连接和权值共享完成卷积运算。在深度神经网络中,卷积层中每个单元都有一个独立的权值,因此需要对整个网络进行控制以实现最优的网络结构。本文通过不同尺寸的卷积核进行卷积,提取输入数据中深层次的特征。
池化层:主要对卷积层输出的结果进一步提取特征,在保留最大特征的同时,降低特征的维度。
全连接层:主要根据概率值对所提取的特征进行分类,然后输出最终的情感分析结果。
2.2 LSTM 和BiLSTM
LSTM 是循环神经网络的变形。循环神经网络(Recurrent Neural Network,RNN) 对具有序列特性的数据非常有效,能够挖掘数据中的时序信息以及语义信息,能够利用之前的信息影响后面信息的输出,但是RNN 存在无法记忆长距离的信息、梯度消失等问题[11]。为解决以上问题,在RNN基础上添加了“门控装置”,即输入门、遗忘门和输出门,形成LSTM。
为进一步充分利用上下文的内容,将具有正向序列学习特征的LSTM模型进行变形,通过正反向序列提取上下文信息,综合考虑上下文内容,得到双向长短期记忆网络模型BiLSTM,由此判断每个样本评论的情感倾向[12],具体如图4所示。
BiLSTM模型具体的学习流程如下:
1) xt - 1,xt,xt + 1 是输入的具体的词,经过词嵌入将输入的词转换为固定维度的词向量。
2) 输入的词经过词嵌入后转换为固定维度的词向量,然后输入BiLSTM模型,经过正向传播和反向传播训练得到词向量,将正向传播获取的特征和反向传播获取的特征进行融合,有效地提取数据的特征。
3) 将获取的数据特征通过分类器进行预测分类,判断影评数据的情感倾向,即该影评的情感是积极还是消极。
3 实验方案和结果
3.1 实验数据
本文通过网络爬虫技术获取豆瓣网站共计50部电影影评作为实验数据,经过处理共获取影评数据共3万条,其中训练数据2.4万条,测试数据0.6万条。按照星级将实验数据归为积极和消极两类,积极类用1表示,消极类用-1表示。
3.2 评价指标
本实验评价分类结果的好坏用准确率(Accu?racy) 、精确率、召回率和F1 作为指标。Positive表示积极评论,Negative表示消极评论,影评分析混淆矩阵如表1所示。
其中,准确率表示影评分析中被分对的样本与所有样本的数的比;精确率表示影评分析中被识别为积极类的样本中,确实为积极类别的比例;召回率表示在所有积极类别样本中,被正确识别为积极类别的比例;F1表示通过精确率和召回率对影评的综合分析。
3.3 实验设置
本实验在Windows10上,使用Python编程语言,基于Anaconda环境,利用深度学习框架TensorFlow2.0完成整个实验代买的编写。通过Word2Vec中skipgram训练维度为50的词向量进行词嵌入。在CsBiL?STM中,具体的实验参数设置如下:首先使用卷积层中使用32个卷积核,尺寸大小为2,3,4的窗口进行卷积;其次使用窗口大小为3,移动步长为1的最大池化方式进行池化;再其次将多尺寸卷积核获取的特征进行融合;最后将融合的特征使用双向LSTM进一步提取影评数据特征。
3.4 实验结果及分析
为了证明本实验模型的有效性,将CsBiLSTM模型与CNN、LSTM、BiLSTM进行对比实验,输出层使用sigmoid进行分析,通过准确率进行评价,实验结果如表2所示。
通过CsBiLSTM模型提取影评数据特征,输出层使用K-最近邻算法进行影评分析,为保证实验结果的有效性,将实验数据进行5折交叉验证,同时通过网格搜索寻找最佳参数,并与CNN、LSTM、BiLSTM进行对比,最后通过准确率、精确率、召回率和F1 进行评价,实验结果如表3所示。
从表2和表3可以分析得出,CsBiLSTM融合模型在特征提取方面优于单一的CNN、LSTM、BiLSTM。输出层使用sigmoid和K-最近邻进行情感分析,其K-最近邻整体优于sigmoid。同时也能得到BiLSTM能够充分利用前向和后向的特征進行分类,充分体现出其网络在时序信息方面具有的独特性。
4 结束语
融合多尺寸CNN 和BiLSTM 得到的模型CsBiL?STM模型用于中文影评分析优于单一的网络模型,如CNN、LSTM、BiLSTM;同时也能够解决CNN无法充分利用上下文信息的问题。但是在实验的过程中,也体现出实验存在的问题:第一,模型训练时间长。尽管单一模型在准确率上低于CsBiLSTM,但是在消耗的时间上优于CsBiLSTM;第二,数据量偏少。实验过程中使用的数据量少,模型训练过程中存在学习不够充分。在今后的工作中,除了解决以上两个问题外,还需进一步加强算法模型优化以及数据预处理的研究。
