
基于CenterNet的半监督起落架自动标注
2023-05-04 02:43闫文君张婷婷
兵器装备工程学报 2023年4期
方 伟,汤 淼,闫文君,张婷婷
(海军航空大学, 山东 烟台 264001)
0 引言
飞机降落的安全性是世界各国高度关注的问题之一,容易受到天气、设备、自身完好性、飞行员操纵时机等多个方面因素的影响。其中,起落架收放状态的好坏也会对降落的安全性产生不可估量的影响。因此,对起落架收放状态进行自动检测能有效地提高降落的安全性。
由于深度学习需要大量的标记样本进行训练,而关于飞机起落架检测缺乏相关的训练样本,需要人工标注数据集,但利用标注软件进行人工标注费时费力并且效率很低。半监督学习通过使用由标签数据和无标签数据混合而成的训练数据来对相关模型进行训练,可以较好地解决图像自动标注问题。
目标检测模型是半监督图像标注的核心和基础。近年来,基于深度学习的目标检测算法因能够自动地从图像中提取目标的特征,具有学习能力强且识别速度快、精度高等优点,已得到大量广泛应用。目前,流行的目标检测算法主要有两大类:基于有锚框的检测算法和无锚框的检测算法。基于锚框的方法主要有Faster R-CNN[1],SSD[2]和YOLO[3]系列算法。Faster R-CNN检测精确度最高,但检测速度很慢,不能满足实时性的要求;SSD算法的检测性能最低,但在目标定位上效果较好;YOLOv2[4]检测精度和速度都超过了上一代,但检测精度的提升并不明显;YOLOv3[5]在检测精度和速度之间取得了平衡;YOLOv4[6]拥有较高的精确度而且检测速度也没有下降。基于无锚框的方法主要采用关键点来估计目标信息,移除掉了锚框,减少了超参数,增加了网络的灵活性,检测精度也很高,典型的算法主要有CornerNet[7]、CenterNet[8]。CenterNet针对CornerNet的部分缺陷,进行了相关的改进,检测速度和精度都有了一定水平的提高。在半监督图像标注领域,谢禹等[9]提出基于SSD算法与半监督学习协同训练的方法提高了车辆检测中车辆标注的效率;王保成等[10]提出了基于LDA和卷积神经网络的半监督图像标注方法,并通过加入注意力机制和改进损失函数对卷积神经网络进行优化使标注更加精确。税留成等[11]提出基于生成式对抗网络的图像标注技术解决图像语义标注问题,但不能直接用于目标检测任务。本文将CenterNet目标检测算法与半监督学习的思想结合起来对飞机的起落架进行自动标注,检测得到的标注结果可直接转化为xml文件构建VOC数据集,用于目标检测任务。
1 基于CenterNet的自动标注
1.1 CenterNet网络
CenterNet是一种端到端的无锚框的目标检测算法,利用关键点估计的方法来找到目标物体的中心点,并回归到其他目标属性。CenterNet用到的编解码网络主要有沙漏网络(hourglass network[12])、深层特征融合网络(deep layer aggregation network[13])以及卷积残差网络(ResNet[14])。网络结构如图1所示。

图1 CenterNet网络结构Fig.1 The network structure of CenterNet

1.2 嵌入通道注意力机制
通道注意力机制能够根据通道间的依赖性,自适应地分配给各通道权重,强化重要特征图对结果的影响,弱化非重要特征的负面作用,结构简单,效果较好。本文主要采用了ResNet50作为主干特征提取网络,并嵌入了通道注意力SE(Squeeze-and-Excitation)[17]模块,模块结构图如图2所示。

图2 SE-ResNet网络架构Fig.2 The network of SE-ResNet
对于输入特征图X,通道空间大小为H×W,通道数为C,将SE单元模块嵌入到残差块的分支上,通过全局平均池化操作将通道空间大小挤压为1×1,然后经过第一个全连接层操作后特征图的维度变为1×1×C/r,再通过ReLU激活函数和又一个全连接层重新回到原来的维度,这有利于减少参数量和运算量;经过sigmoid层完成对特征图的激励操作后得到各通道之间的归一化权重,输出的特征图维度为1×1×C;最后通过Scale操作将归一化权重与原图像相乘,将每个通道赋予新的权重,得到的最终特征图的维度为H×W×C。这样在主干特征提取网络上嵌入SE单元模块,能够提高主干网络对图像重要特征的提取,抑制无关特征,得到更高质量的特征图,提升整个网络对飞机起落架的检测精度。
1.3 损失函数
CenterNet的损失函数[18-19]由3个部分组成,分别是目标中心的损失函数、目标中心的偏置损失、目标大小的损失。中心损失函数的整体思想和Focal Loss[20]类似,表示为:

(1)

由于主干特征提取网络对图像进行了R倍的下采样,该操作得到的特征图在重新映射到原始图像后会产生细节丢失,因此,采用中心点偏置值来对每个中心点进行补偿。目标中心的偏置损失表示如下:
(2)

目标大小的损失是通过回归热力图与特征图,最终得到每个目标的长宽值,计算公式为
(3)

总损失如下:
Ldet=Lk+λsizeLsize+λoffLoff
(4)
式中:λsize为目标大小预测损失权重,取0.1;λoff为目标中心点偏移损失权重,取1。
2 半监督学习
目标检测模型需要用到大量标注数据进行训练,而对飞机起落架的检测由于缺少相关的标注数据集,需要进行大量的人工标注。半监督学习[21]在目标检测领域可以使用少量有标注的样本数据训练目标检测器,利用无标注数据来辅助训练模型,从而达到提高模型性能的效果。因此,本文将半监督学习与计算机视觉中的目标检测模型结合起来完成对大量无标签数据的自动标注。
本文采用的标注方法如图3所示。

图3 自动标注流程Fig.3 The process of automatic labeling
步骤1对含有起落架的飞机图像进行处理,把其中一部分图像的起落架通过LabelImg标注工具进行手工标注矩形框,自动生成包含类别和位置信息的xml文件,构建目标检测数据集,数据集采用VOC2007数据集格式。
步骤2将部分人工标注的飞机起落架图像作为训练数据输入,通过训练得到飞机起落架目标检测模型,此时该模型的检测能力较低,泛化能力也较弱。
步骤3将未标注的飞机起落架图像输入到得到的目标检测模型中进行检测,得到自动标注的起落架图像,判断得到标注图像的置信度,对得到的问题标注数据(包括漏标记、标记错误、标记框位置不准确和标记置信度低于0.4的样本)进行人工修正,得到修正后正确的标注结果,典型问题样本如图4所示。图4(a)、图4(b)、图4(c)中前起落架均未被检测出来,图4(b)中将飞机尾钩误检测为起落架,图4(c)中左侧起落架与尾钩误检测为同一目标。

图4 典型问题样本Fig.4 Typical problem sampl
步骤4将问题样本的xml文件中的起落架位置信息人工修正后与相对应的图像组成数据集加入到已标注的数据集中开始训练新的目标检测模型,起到监督训练的效果,该模型的检测精确率会有所更高,泛化能力也应该更强。
步骤5重复步骤3、步骤4的操作,不断更新数据集训练得到新的目标检测模型,直到全部未标注的飞机起落架图像都迭代进模型中完成检测时或精确率达到95%同时平均准确率达到90%终止迭代,此时检测的平均准确率达到最高的模型为最终的检测模型。
步骤6将网络上随机选取的飞机起落架图像输入到最终得到的检测模型中去,验证检测效果。
3 实验过程与结果分析
本文采用的数据集是飞机降落过程中含起落架的图像数据,共有1 800张图片,其中800张图片进行了手动标注,1 000张图片未经过手动标注,再从网络中随机选取飞机起落架图片对模型效果进行测试。
3.1 实验环境
本文采用CPU为Intel core i9处理器,32 GB的内部存储器,GPU处理器为NVIDIARTX 3080Ti;实验平台为Windows 10;软件环境是Python 3.7,Anaconda 3,CUDA11.0。输入图像尺寸统一为512×512像素,训练参数设置为每次迭代训练样本数为4,最小学习率为0.000 01,最大学习率为0.001,训练次数设为100次,置信度设为0.4。
3.2 评价指标
本文采用精确率(Precision)、召回率(Recall)、平均精确度(mAP)来评价起落架检测模型的性能。精确率与召回率的公式为:
(5)
(6)
其中:TP表示被正确预测为起落架的正样本的数量;FP表示被预测为起落架,但实际上为假样本的样本数量;FN表示被预测为假样本,但实际为正样本起落架的样本数量。精确率表示模型检测出来的起落架并且真正为起落架的数量占模型检测为起落架的比例,体现了模型检测的准确性。召回率表示模型检测出真实为起落架的数量占所有真实为起落架的比例,体现了模型识别真实起落架的能力;但是,精确率与召回率相互制约,很难同时提高,因此,引入了更具说服力的平均精确率mAP来评价算法的检测性能,mAP越高,性能越好。
3.3 实验结果分析
为了更好地评估Se-CenterNet网络模型的检测效果,分别选用了YOLOv3、YOLOv4、CenterNet三种目标检测模型进行对比实验,训练数据集为800张人工标注的飞机起落架图像,图像尺寸为512×512像素,不同模型得到的检测结果如表1所示。

表1 不同检测模型的检测结果Table 1 Test results of different test models
由表1可知,模型Se-CenterNet与YOLOv3、YOLOv4网络相比的召回率较低,但检测精确率高达94.62%,平均准确率mAP也达到了86.19%;YOLOv3、YOLOv4虽然召回率更高,但检测精度与平均准确率相差较大,无法满足需求。与原CenterNet模型相比,嵌入SE模块后,mAP提高了3.6%。综合来看,相比于其他几种检测模型,模型Se-CenterNet在对起落架的检测上检测效果更好。
为了验证SE模块在本文数据集中对CenterNet网络检测精度的提升效果,特设计消融实验将其与CBMA、ECA两种注意力机制进行对比,实验结果如表2所示。实验结果表明,在本文数据集中,嵌入SE模块后得到的mAP为86.19%,比嵌入CBMA、ECA两个模块的mAP分别提升了2.8%、1.7%,检测效果较好。因此,后续实验中将采用Se-CenterNet模型来对起落架进行自动标注。
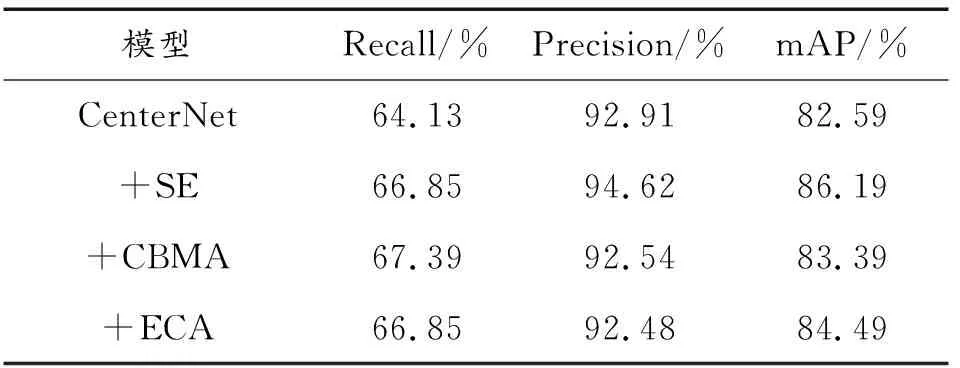
表2 不同注意力模型检测结果比较Table 2 Comparison of test results of different attention models
在上述实验的基础上对迭代模型的训练效果进行分析,将1 000张未标记的飞机起落架图像平均分成5个部分,每个部分200张图像。将由800张标记图像组成的数据集1训练得到的检测模型记为模型1;将200张图像输入到模型1中进行测试,对测试结果中不准确的标记信息手动修正后组成1 000张图像的数据集2重新训练得到新的检测模型记为模型2;将数据集2+200张手动修正图像组成数据集3在模型2的基础上训练得到模型3;将数据集3+200张手动修正图像组成数据集4在模型3的基础上训练得到模型4;以此类推,分别得到模型5与模型6。实验过程中,发现在模型5时精确率达到95.29%、mAP达到92.16%,满足迭代终止条件。因此,模型5为最终得到的目标检测模型。每个模型输出的准确率与mAP如表3所示。

表3 不同模型的精确率与mAPTable 3 Precision and mAP of different models
随着迭代次数的增加,模型的精确率与平均准确率mAP都呈现上升趋势,达到了很高的水平,起到了监督训练的效果,对飞机起落架的检测效果也不断增强,满足预期的设想。
为评估最终得到的目标检测模型的性能,从网上选取一张飞机图像对起落架进行标注,标注效果如图5所示。从图5中可以看出,模型对各个起落架的检测概率不同,这主要是由于背景遮挡的不同引起的,前起落架背景遮挡较为严重,检测概率仅为51%,左侧起落架次之,检测概率为59%,右侧起落架效果较好,检测概率为75%。从标注的整体效果看,没有发生错误标注和漏标注的情况,细微的偏差也不会影响起落架的标注结果,都可以准确地定位到飞机的3个起落架,达到了自动标注的目的,说明采用嵌入通道注意力机制的CenterNet目标检测模型与半监督学习相结合的方法可以完成对飞机起落架的自动标注。

图5 标注效果Fig.5 Annotation effect
4 结论
本文针对人工标注飞机起落架费时费力的问题,提出了嵌入通道注意力机制的CenterNet目标检测算法并比较了几种检测算法和注意力模块的性能,实验结果表明该模型具有较好的检测性能;将其与半监督学习结合起来解决自动标注问题,通过标注数据训练模型,无标注数据用于检测,测试结果用来生成xml文件,每次模型训练都叠加手动修改的问题样本扩充数据集,起到监督训练的效果,经过不断地迭代训练,模型的精确率与平均准确率不断上升,迭代5次后精确率达到95.29%,平均准确率达到92.16%,对飞机起落架的检测达到了较好的效果,为后续大量飞机起落架数据集的制作提供了算法基础。下一步工作将继续优化算法,提高算法对背景遮挡较为严重的飞机起落架的检测能力,并将其应用于起落架标注工作中去,为提升飞机降落的安全性提供一定的参考。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
环球时报(2022-05-30)2022-05-30
中原商报·科教研究(2021年6期)2021-05-13
百科探秘·航空航天(2020年8期)2020-07-29
作文小学中年级(2020年6期)2020-07-24
军民两用技术与产品(2019年12期)2020-01-19
当代陕西(2019年11期)2019-06-24
作文周刊·小学一年级版(2017年9期)2017-06-20
小学生导刊(低年级)(2016年8期)2016-09-24
自然资源遥感(2014年3期)2014-02-27
