
基于MS-PLNet和高光谱图像的绿豆叶斑病病级分类
2023-05-08 06:10余骥远高尚兵李士丛张浩淼袁星星
江苏农业科学 2023年6期
余骥远, 高尚兵, 李 洁, 陈 新, 李士丛, 张浩淼, 袁星星, 唐 琪
(1.淮阴工学院,江苏淮安 223001; 2.江苏省农业科学院经济作物研究所,江苏南京 210014)
针对目前绿豆叶部病害分类研究较少的现状,本研究以国内外其他农作物叶部病害的分类案例为基础展开对绿豆叶部病害的分类研究。Lowe等利用高光谱图像分析技术对植物病害和胁迫早期发作进行分类与检测[5]。吕梦棋等提出一种改进的ResNet模型对玉米种子进行分类,对大、中、小种子的识别率分别达到96.4%、93.5%、92.3%[6]。王美华等改进了注意力CBAM模块,提高了模型的分类准确率[7]。黄英来等采用改进残差网络对玉米叶片病害进行分类,提高了玉米叶片病害图像分类准确率[8]。闫建伟等利用改进的RetinaNet模型对刺梨果实进行识别,平均识别率为94.86%[9]。赵志焱等通过研究玉露香梨叶虫害图像,提出一种自动识别的TACNN网络,取得了81.18%的分类准确率[10]。宋余庆等提出了多层次增强高效空间金字塔(extremely efficient spatial pyramid,简称EESP)卷积深度学习模型,在植物病虫害图像尺寸不同的情况下达到88.4%的分类准确率[11]。Gao等提出一种双分支、高效、通道注意力(DECA)的作物病害识别模型,在公开数据集PlantVillage 上得到了99.74%的疾病识别准确率[12]。尚静等使用高光谱成像仪对猕猴桃成熟度进行无损检测[13]。谢鹏尧等利用Mask-RCNN模型对水稻冠层进行检测,检测准确率达到94.30%[14]。Hussain等使用EfficientNetV2模型对豆蔻病害进行检测,病害检测准确率为98.26%[15]。Bhujel等通过结合不同的注意力模块设计的轻量级卷积神经网络对番茄叶病进行分类,分类准确率达到99.69%[16]。刘庆飞等提出一种基于深度可分离卷积的逐像素分类方法,实现作物、杂草和土壤的逐像素分类,平均准确率为94.99%[17]。闫壮壮等利用VGG16卷积神经网络模型对大豆豆荚进行识别,准确率可以达到98.41%[18]。
虽然使用卷积神经网络在农作物叶部病害分类方面已经取得了丰富的成果,但大多数情况下由于每种农作物病害机理不同,因此并不能直接使用已有的其他农作物的叶片分类方法。本研究以绿豆叶片高光谱图像为研究对象,研究有关绿豆叶斑病的分类问题,提出了一种基于MS-PLNet的绿豆叶斑病分类方法,对5种不同叶斑病抗性等级的叶斑病图像进行分类,在保证本研究设计的MS-PLNet具有较小参数量的前提下,分类平均准确率达到97.4%。
1 图像采集与预处理
1.1 图像来源
于2020年4—6月在江苏省农业科学研究院开展相关试验,挑选颗粒饱满,相似大小的绿豆种子备用,抗叶斑病精准鉴定在具备良好的试验室环境的抗病材料室中进行。试验的材料采取随机排列的方法,每份材料种植在10 cm×10 cm的花盆中,每个花盆种4株苗,一共种植12株。每10份材料设置1组已知抗病或者感病材料进行对照,常用的对照材料为V1197(感)、V4718(抗),在实验中如果鉴定出植株出现抗、感自交系统生长排异的情况,就在原有对照试验组的情况下,添加适合试验环境并具有稳定抗感性的新对照组材料。
先把存储在实验室的致病力较强的变灰尾孢菌株置于V8培养基,然后将培养基放入28°C培养箱中约7 d,菌种活化后,将其接种在新的V8培养基上进行病原体大量扩繁,约7~10 d菌丝布满整个平板。在材料室接种的当天,继续使用直径为5 mm的无菌穿孔器在菌种和菌落的生长边缘打孔,以更好地接种。在接种期间,在绿豆的第1组复叶展开后,收集完全展开的复叶,用水洗涤未折叠的复叶并放在吸水纸上,将吸水纸放入盒子中,然后在待接种复叶上使用刀片造成4 mm的小伤口并继续接种5 mm的菌饼,并将接种盒敷上保鲜膜。在25 ℃条件下保持黑暗36 h后,再使用与上述室温和光周期一致的条件使叶子发病。1个品种做3个重复试验和1个对照试验,每个重复试验采用1组复叶进行,对照为不接菌叶片。接种7 d后进行调查,检测病斑的大小,根据斑点的大小,确定绿豆叶的叶斑病抗性水平,即高抗病性、抗病性、中抗病性、中感病性、感病性和高感病性,以上抗性类型分别标记为HR、R、MR、MS、S、HS等6种,由于HS型的叶片在本实验中基本不发生,故在下文的绿豆叶斑病分类中只采用HR、R、MR、MS、S等5种叶片。
使用单反相机(型号:Canon EOS 550D;光圈值:f/5;曝光时间:0.5 s;ISO速度:ISO-200;焦距:45 mm;测光模式:图案;闪光灯模式:无闪光,强制)从相同角度获取实验室培养的所有绿豆叶片图像。共采集到绿豆叶片图像1 000幅。部分图像如图1所示。
神经网络的形式是单隐层的BP网络。输入层设有200个PE,它们输入采集的加速度幅值谱值,输出层的3个PE代表建筑各层层间柱子构件,其活性值取在0~1之间,0代表完全破坏,1代表无损坏,中间的数值代表以构件刚度降低百分数表达的损坏程度。
1.2 数据预处理
1.2.1 绿豆叶片高光谱图像转化 使用Specim高光谱成像仪获取绿豆叶片高光谱图像,该成像仪由取景器摄像机、聚焦环、聚焦摄像机组成。首先将单反相机拍摄的RGB图像传入IQ Studio,然后将IQ Studio处理后的图像导入Specim, 获取本研究使用的高光谱图像,部分高光谱数据如图2所示。

1.2.2 图像裁剪 由于本试验中进行图像分类是对单个图片中的单个叶片进行抗性分类,然而转换的高光谱图像中包括很多叶片。因此首先需要对图像进行裁剪,将图像中聚集在一起的多个叶片分割为便于观察的单个叶片。首先使用LabelImg标注图像,相同抗性类别的绿豆叶片图像标注为同一类别,然后导出XML标注文件并使用python进行原图裁剪和分辨率调整。经过裁剪的不同抗性绿豆叶片图像如图3所示。


1.2.3 数据增强 在图像分类任务中,如果用来训练模型的数据越多,通常训练出来的模型精度也会越高,鲁棒性和泛化性也会越强,数据增强是深度学习中常用的数据扩充方法[19]。本研究使用上下翻转、左右翻转、随机对比度变换,最后进行归一化操作[20]。在模型测试的时候进行双线性插值和归一化操作来保证测试结果的稳定性[21]。经过处理后的部分图像如图4所示。

2 搭建MS-PLNet图像分类模型
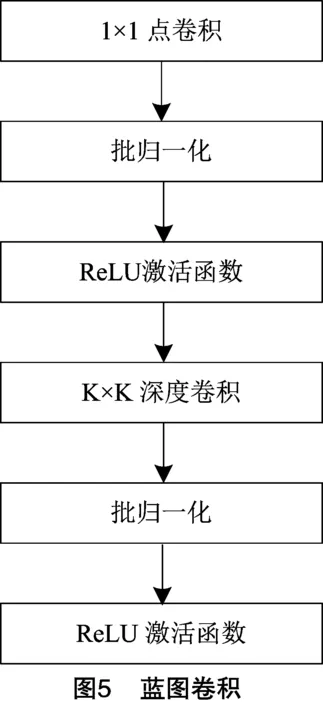
2.1 蓝图卷积
与深度可分离卷积的不同之处在于,深度可分离卷积首先逐个通道卷积,然后将深度方向上的特征图加权在一起,而蓝图卷积(blueprint separable convolution)如图5所示,先对深度方向上的特征图加权,然后再进行卷积[22]。
蓝图卷积参数量大小为:
PBS=K×K×N+C×N。
(1)
蓝图可分离卷积计算量大小为:
FBS=K×K×N×H×W+C×H×W。
(2)
式中:N和C的含义和深度可分离卷积相反,N为输入特征图通道数,C为卷积核数量或者输出特征图通道数。
深度可分离卷积隐式地假设了一个用于所有内核的三维蓝图,而蓝图卷积则是依赖于每个内核的单独二维蓝图。研究表明,单个内核的内部相关性有更大的潜力进行有效分离。
2.2 SE模块
卷积神经网络中的注意力机制(attention mechanism)分为软注意力(soft-attention)和强注意力(hard-attention)[23]。本研究选择基于通道注意力的压缩和激活模块(squeeze-and-excitation block)重新组合特征[24]。
函数 U 首先执行挤压运算,该运算将特征映射集成到空间维度上以生成通道描述符。然后将生成的通道描述符嵌入到通道中,帮助网络在较低层利用来自全局感受野的有用信息。然后执行激活操作,通过基于通道间依赖性的自门控机制确定通道间依赖的程度。当2次操作完成后,重新加权的特征图作为SE模块的输出进入到后续层中参与训练,如图6所示,其中AvgPooling表示全局平均池化,FC1和FC2表示特征图,ReLU和Sigmoid表示激活函数。
卷积过程可以表示为:
(3)
式中:uc表示一个通道输出的特征图;vc表示卷积过程;X表示输入和输出的所有通道特征图,其中输入特征图X∈RH×W×C,输出特征图X∈UH×W×C,H、W、C分别表示特征图的高和宽以及通道数。

2.3 分类流程与MS-PLNet网络结构
本研究基于卷积神经网络对绿豆叶斑病进行分类,首先加载绿豆叶斑病数据集,对该数据集进行数据预处理,然后将处理后的图像送入本研究构建的MS-PLNet模型进行训练,最后通过Softmax函数对获取的特征进行分类。
2.3.1 MS-PLNet网络结构 构建MS-PLNet叶斑病识别网络,如图7所示,总共包括了3个分支的特征提取模块、一个SE Block特征融合模块和分类器模块。首先将高光谱图像输入特征提取模块,然后构建3个尺度的特征提取模块,特征提取模块使用普通卷积和蓝图卷积搭建,在搭建过程中每个尺度的特征提取模块中使用3步蓝图卷积模块,其中第1步蓝图卷积用来增加通道数,第2步蓝图卷积用来减少通道数,第3步蓝图卷积用来增加通道数,最后将3个尺度的特征提取模块计算得到的特征图输入到SE Block通道注意力模块。在获得特征融合的特征图后,通过由全局平均池化层和全连接层组成的分类器进行绿豆叶斑病的分类。
在MS-PLNet网络搭建的过程中使用的多尺度特征(multi-scale feature)能改善图像分类的效果,本研究使用的是多尺度特征提取中典型的特征金字塔结构[25]。从图像的每一层中提取不同比例的特征,得到特征图,通过逐层降低分辨率和下采样,在达到卷积停止状态后才停止采样。通过不断的下采样操作,相应的图像越小,分辨率越低。
在特征提取阶段,第1个分支经过上采样后输入图像为256像素×256像素,特征提取模块一共有18层,包括16个卷积层、2个反卷积层[26]。其中包括5个由1×1的点卷积和7×7的组卷积构成的蓝图卷积,每个蓝图卷积的输入通道数和输出通道数均不同。第2个分支输入图像为128像素×128像素,特征提取模块一共有17层,包括15个卷积层,2个反卷积层,其中包括5个由1×1的点卷积和5×5的组卷积构成的蓝图卷积。最后一个分支经过下采样后输入图像为64像素×64像素,特征提取模块一共20层,包括16个卷积层、3个反卷积层、1个最大池化层,其中包括4个由1×1的点卷积和3×3的组卷积构成的蓝图卷积。搭建的MS-PLNet网络的具体参数如表1所示。

表1 MS-PLNet特征提取模块参数
3 结果与分析
3.1 算法运行环境
本研究进行绿豆叶斑病图像分类采用的算法运行平台为深度学习服务器,配置为Intel® Xeon® Silver 4210R CPU @ 2.40 GHz、显卡Quadro RTX 4000、内存DDR4 8G。使用Xshell 7下的Pytorch 1.10深度学习框架和CUDA11.3计算架构。
3.2 训练过程与结果
采用Pytorch官方权重参数,结合本研究的绿豆叶斑病具体分类要求,调整MS-PLNet模型的训练参数。具体的参数设置如表2所示。

表2 训练参数
将5个抗性类型的绿豆叶斑病类别每个类别的2 000张叶斑病图像输入MS-PLNet模型训练,并且在训练过程中通过卷积、池化和反向传播不断更新MS-PLNet模型的权重,多次迭代后,使得搭建的卷积神经网络误差趋近于零、准确率达到拟合,得到权重最优的模型。另外采用8:2的比例去划分训练集和验证集,其中8 000张图片被用于训练,每个抗性类别分别占1 600张;2 000张图片被用于验证,每个抗性类别分别占400张。为与本研究所提出的图像分类方法进行比较,在所有试验参数设置相同的情况下,分别对比了使用瓶颈结构为主搭建的轻量级模型MobileNet-V2、MobileNet-V3,使用MBConv结构为主搭建的EfficientNet-B0,使用SandGlass模块为主搭建的MobileNeXt[27-30],以及和没有使用深度可分离卷积思想搭建的其他深度卷积神经网络模型ResNet50、VGG16、DenseNet121进行了广泛的比较[31-33]。
训练结果如表3所示,给出5种抗性类别下的绿豆叶斑病图像在以上模型和本研究搭建的 MS-PLNet 模型上的验证准确率、训练损失值和模型训练时间。表4给出了所有模型的计算量、模型大小、模型参数数量以及模型深度。
由表3可知,与其他先进方法相比,本研究所提出的MS-PLNet方法达到了最好的训练结果。经过300个迭代和1 000个迭代的训练,所提出的方法分别实现了96.8%、98.4%的验证准确率,而且训练1 000次后损失值已经降到了0.052。另外,也可以看出MS-PLNet训练300次和训练1 000次所花费的时间远远低于其他模型。MobileNet-V2训练300次后验证准确率为96.6%,仅比MS-PLNet低0.2百分点,但是比MS-PLNet要多花费近154%的训练时间;EfficientNet-B0训练1 000次后验证准确率达到98.3%,仅比MS-PLNet低0.1百分点,但是却比MS-PLNet要多花费近127%的训练时间。
图8为MS-PLNet训练300次和训练1 000次的验证准确率图和训练损失图。可以看到,随着训练次数的不断增加,模型的验证集准确率在不断上升,训练集损失在不断下降,当训练到第300次的时候,不管是准确率还是损失都没有到达拟合点,在第1 000次训练的时候,模型仍然还有上升的空间,但已经拟合。从图8还可以看到,训练过程中,曲线基本上不表现噪声,整个上升和下降的过程总体上非常平滑,这也证明本研究搭建的MS-PLNet卷积神经网络模型具有较好的鲁棒性,非常适合本试验中提供的绿豆叶斑病高光谱图片的分类。
由表3、表4可知,本研究提出的MS-PLNet在综合考虑了模型大小、参数数量和计算量开销的前提下,优于其他先进方法的性能。本研究的MS-PLNet模型计算量仅仅比MobileNet-V2大0.07 GMac,比MobileNet-V3大0.31 GMac,能够高效地利用内存空间和GPU资源,提高了算法的运算效率。

表3 模型性能对比

表4 模型大小与计算速度

3.3 评价指标
考虑到具体分类过程中准确识别和错误识别的统计数据,本研究MS-PLNet方法的性能以及本研究中讨论的其他最先进的方法是用不同的指标来衡量的。使用分类准确率(Accuracy)、精度(Precision)、召回率(Recall)和F1得分(F1-Score)来对MS-PLNet方法的图像分类效果进行评价。其中,Accuracy是在全部预测样本中正确预测的样本所占的比例;Precision是在全部阳性预测样本中,正确预测的样本所占的比例;Recall是正确识别的阳性样本在所有真阳性样本中所占的比例;F1-Score同时考虑了假阴性和假阳性。更具体地说,评价指标使用(4)~(7)进行计算。
(4)
(5)
(6)
(7)
式中:TP(真阳性)为正确分类的阳性样本数量;FN(假阴性)为分类错误的阳性样本数量;FP(假阳性)为被错误分类为阳性类别的阴性样本数量;TN(真阴性)为准确分类的负数样本数量。
3.4 绿豆叶斑病分类结果
由表5可知5种抗性类型的绿豆叶片在本研究搭建的MS-PLNet模型上面的分类准确率、分类精度、召回率和F1-分数等分类评价指标结果,其中每个抗性类别的图片选择200张,一共使用1 000张图片进行测试。所提方法区分了5种不同的绿豆叶斑病抗性类型,并达到了97.4%的平均准确率、95.0%的平均分类精度、99.9%的平均召回率和97.4%的平均F1-分数,能够有效地对绿豆叶部病害进行分类。

表5 不同绿豆叶片的分类结果
4 结论与讨论
对本研究MS-PLNet方法所得结果的可靠性解释是注意力机制将基于位置的柔性注意力机制集成到模型中,这增加了模型提取绿豆叶斑病图像中微小病变特征的能力。MS-PLNet采用多尺度特征提取能够提取到绿豆叶片不同尺度的更加丰富的病斑特征。另外,在模型训练中应用了三阶段的蓝图卷积,使模型获得了最优权重参数,并且尽可能地减小了模型大小,节省了训练过程中的内存开销。这种从粗到细再到粗的模型搭建策略使模型首先感知到粗略的特征,然后将注意力转移到精细的细节上,最后再次关注已经得到的特征图的全局信息,以防止模型忽略其他重要的细节特征,从而提高模型的识别准确性。本研究提出的MS-PLNet网络结构克服了传统卷积神经网络模型参数量大、模型运算量高的不足,既能有较好的叶斑病分类准确率,又能使模型具有较小的参数量,实现叶斑病的快速识别和统计分析。
本研究提出的卷积神经网络模型用于对绿豆叶斑病高光谱图像和抗性等级进行分类和评估,通过构建MS-PLNet模型,与MobileNet-V2、MobileNet-V3、EfficientNet-B0、ResNet50等现有的先进模型进行比较。本研究提出的MS-PLNet模型在达到最高验证准确率的同时,训练300次仅需要1个小时49分钟,其中验证准确率较高的MobileNet-V2比MS-PLNet要多花费近154%的训练时间;训练1 000次仅需要10个小时26分钟,其中验证准确率较高的EfficientNet-B0比MS-PLNet要多花费近127%的训练时间。MS-PLNet是所有进行对比的模型中训练花费时间最少的,极大地节省了模型的推理时间和训练资源,方便部署。
它通过构建多尺度的特征提取模块,在3个分支的特征提取模块中输入高光谱图像以及采用3个尺度的卷积核进行特征提取,在降低了模型参数的前提下,训练出来的模型达到了较高的分类精度,能够实现绿豆叶斑病的快速识别。
为实现对绿豆叶斑病的精准快速分类,本研究提出一种基于MS-PLNet卷积神经网络结构和高光谱图像的绿豆叶斑病分类方法。MS-PLNet网络训练1 000次能够达到98.4%的验证准确率,并且该方法对HR、R、MR、MS、S等5种抗性类型的绿豆叶斑病图片的分类平均精度为95.0%,可用于实验室条件下的绿豆叶斑病和其他农作物叶斑病的快速分类,识别准确率高,且具有较好的鲁棒性与广泛的应用价值。本研究使用的绿豆叶斑病数据集为实验室收集得到,下一步将收集真实大田环境下的数据,验证本研究搭建的MS-PLNet模型在复杂环境下的分类准确率。
猜你喜欢
中国农业科学(2022年16期)2022-09-19
科学大众(2020年23期)2021-01-18
华人时刊(2018年15期)2018-11-18
电子制作(2018年19期)2018-11-14
启蒙(3-7岁)(2018年8期)2018-08-13
自动化学报(2017年11期)2017-04-04
小学生作文(低年级适用)(2016年17期)2016-02-28
噪声与振动控制(2015年4期)2015-01-01
湖南农业科学(2014年5期)2014-02-27
轴承(2010年2期)2010-07-28
