
数据驱动的农作物遥感分类地面样本点布设
2023-05-15 05:27吴清滢余强毅段玉林吴文斌
农业工程学报 2023年6期
吴清滢,余强毅,段玉林,吴文斌
·土地保障与生态安全·
数据驱动的农作物遥感分类地面样本点布设
吴清滢,余强毅※,段玉林,吴文斌
(中国农业科学院农业资源与农业区划研究所/农业农村部农业遥感重点实验室,北京 100081)
地面样本点是农作物遥感分类模型训练的基础,样本点数量和质量是影响模型分类精度的2个主要因素。该研究构建了数据驱动的样本点布设方法,利用待分类影像的光谱、植被指数等特征构造分层抽样底图,结合分层随机抽样方法进行地面样本点布设,并分析不同抽样策略对农作物遥感分类结果的影响。采取基于-means聚类分析的数据驱动方法,考虑6景哨兵2号影像提取的共78个分类特征,生成同一个最优的聚类结果图;设计等量分配和按面积比分配2种样本量分配方式,样本点数量为25、49、100、169、225的5个总样本量;基于不同抽样策略获取地面样本点信息,利用同一个支持向量机模型对待分类影像进行监督分类,并通过与139个样本点的理论总样本量和400个样本点的传统方式总样本量对比分析,定量解析不同抽样策略对分类精度的影响。结果表明:1)在数据驱动非监督聚类生成的底图上进行抽样(按面积比分层抽样法、等量分层抽样法)获得的样本点质量和分类精度明显优于没有该底图的抽样策略(简单随机抽样法、系统抽样法);2)当总样本量低于理论总样本量时,等量分层抽样法能获取比按面积比分层抽样法更高的分类精度。例如,当理论样本量为139时,总样本量为25、49和100时等量分层抽样法的分类精度均值(75.5%、80.5%和86.0%)均明显高于按面积比分层抽样法的分类精度均值(48.4%、69.0%和83.0%),而当总样本量为169和225时,两种分层抽样的分类精度均值都在90.0%左右;3)当满足总体精度需求时,分层抽样法所需的实际总样本量小于理论样本量,可极大提高抽样效率。例如,等量分层抽样法的实际样本量为理论样本量的约70%便可满足85.0%的总体精度需求;当分类精度与人工选取方式分类精度相同时(97.5%),等量分层抽样法的实际样本量仅为传统方式样本量的约90%。研究结果印证了分类精度及稳定性随着总样本量的增加而增加这一普遍认识,但当总样本量超过一定值时,精度增长速度变慢。该方法可以获取类间均衡、类内多样化的样本集,为农作物遥感地面样本点布设、快速高效分类提供参考。
农业;遥感;作物分类;样本点布设;抽样底图;聚类分析
0 引 言
地面样本点信息是训练遥感分类模型的基础,样本点的数量和质量是影响模型分类效果的2个主要因素[1-2]:高质量的样本点可以显著提高遥感分类精度[3],相反,样本点的代表性弱[4]或样本点数量不足[5]会增加分类误差。有研究通过样本点迁移[6]、特征提取[7]等方式来解决样本点问题,但这类方法依然需要一小部分高质量地面样本点信息作为基础输入。现有高质量样本点数据集一般通过专业人员目视解译得到[8],解译成本与专业性要求高,导致现有高质量样本点数据集大多仅针对特定区域[9],地面真实训练样本点数量不足、代表性差的问题依然未能得到彻底解决。
实地调查可更大程度保证地面样本点信息的质量。近年来,将空间分层抽样理论结合遥感技术用于指导地面样本点获取[10],为遥感影像变化检测[11]、空间数据产品精度验证[12]等研究中样本点“去哪采”的难题提供了科学支撑。其中,制作底图是抽样设计的关键,好的底图能大大提高分层抽样调查效率。例如,以接近反映地物真实分布的遥感影像分类结果为底图,能减少农作物种植面积调查研究中外推估算面积的精度误差[13-15]。当分类对象变化不频繁时,通常可直接利用其历史分布数据作为分类调查研究的抽样底图[3],例如WICKHAM等[8,16]利用历史的土地利用数据产品作为当年土地利用分类抽样调查的分层依据。
然而,在农作物遥感分类研究中,频繁的农户田间活动导致田块大小变动和种植作物种类更换,将历史作物空间分布数据产品[17-18]作为当季作物遥感分类的分层抽样底图是具有较大不确定性的[3]。一些学者在缺乏有效的当季农作物分布数据时,会采用复杂规则并综合各种辅助信息数据来间接构造分层底图,此时分层抽样效率的高低往往取决于辅助信息数据选择的好坏。例如FOODY等[19]根据土壤类型分布信息来约束农田和作物类型制图训练样本点采集区域。也有研究表明相对于按行政区划分层[20],利用历史信息提取的作物种植频率[21]可以更有效率的构造分层抽样底图。然而,土壤类型和行政区划数据与作物分布的相关性较弱;由作物种植频率构建的底图难以摆脱对历史信息完整性的依赖,并且对新作物和新种植模式的识别具有滞后性。以数据作为驱动力的方法脱离了对专家知识的依赖,能够“自下而上”地刻画特征变量之间复杂的线性与非线性关系[22-23],因此,相较于利用辅助信息,通过挖掘和构建遥感影像数据内在关系,获得能直接反映当季调查作物的分布信息,从而大大减轻构造分层底图的工作量,获取高质量样本点,提高抽样效率。
在没有可直接使用的当季作物分布数据前提下,本研究尝试构建数据驱动的样本点布设方法体系,利用传统的基于数据驱动的无监督聚类算法,生成可用于直接支撑抽样的分层抽样底图;并验证此分层抽样底图与不同抽样策略结合后的样本点获取效果,及其对遥感分类精度和效率的影响,以期通过“事前优化”科学获取类内代表性和类间均衡性均较高的训练样本点,降低遥感作物分类样本点信息冗余,提出提高抽样方法效率的最佳抽样策略。
1 试验区域及研究数据
1.1 试验区域
为测试生成的分层抽样底图对分类精度的提升效果,本研究以辽宁省铁岭市开原市的一个典型农区为研究区,研究区总面积为111.4 km2。开原市(123°43'43''E~124°48'55''E,42°6'55''N~42°53'23''N)位于铁岭市的东北部。冬季严寒干燥,夏季温热多雨,四季分明,气候属中温带大陆性季风气候。全市耕地面积1 183.72 km2,土地肥沃,主要种植一年一熟制玉米、大豆、水稻等农作物,是国家重点产粮区和商品粮基地。

图1 研究区位置
1.2 数据来源及预处理
1)鉴于多个研究表明中国自然资源部组织制作和发布的免费使用的全球30 m地表覆盖数据产品(GlobeLand30)[24]在中国局部空间精度评价中精度较高[25],本研究选择了此数据产品2020年耕地数据。
2)遥感影像数据来自欧洲航天局生产的哨兵2号卫星遥感数据,哨兵2号是高分辨率多光谱成像卫星,地面分辨率分别为10、20和60 m,两颗卫星互补的重访周期为5 d,可提供植被、土壤和水覆盖等图像,已经被作为主要数据源应用于作物分类研究。在Google Earth Engine(GEE)平台[26]上筛选出2021年1—9月覆盖研究区的云量较少的哨兵2号卫星遥感数据作为试验数据,并对影像进行云掩膜、缺失值填补。最终研究选取了作物生育期内所有可用的遥感影像数据,时间点分别为2021年4月18日、5月18日、6月7日、6月12日、7月7日、9月10日。
3)验证地面样本点来自于同步开展的地面调查。整个地面调查中发现该典型研究区的耕地分布集中,地块规整,以一个县需要2 000个样本点为数量参考,筛选获得研究区内均位于地块中心的80个真实地面样本点,其中水稻、大豆和玉米样本点个数分别为30、20和30。
为排除非耕地像元对作物分类调查研究的影响[27],首先借助2020年GlobeLand30数据集提供的耕地分布(类型编号10)作为掩膜文件并重采样到10 m,使其空间分辨率与哨兵2号遥感影像空间分辨率一致,对影像进行掩膜得到农田植被的总体分布数据,在此基础上进行耕地作物抽样底图制作、作物识别和分类。
1.3 分类特征构建和提取
利用哨兵2号影像数据的光谱信息、以及不同波段的组合指数信息提取作物信息,研究中使用的波段详细数据及植被指数为:波段B2~B4为可见光波段;波段B5~B7常被用于监测植被健康信息[28];波段B8和B8A分别为近红外波段(宽)和近红外波段(窄);波段B11~B12为短波红外波段;归一化差值植被指数(normalized difference vegetation index,NDVI)[29]、归一化植被水分指数(normalized difference water index,NDWI)[30]、归一化建筑指数(normalized difference built-up index,NDBI)[31],分别对植被、水体和建筑物体敏感。最后基于6景哨兵2号影像选取的原始光谱波段和植被指数的特征组合作为非监督分类的分类特征。
2 研究方法
分层抽样方法在一定程度上可提高抽样效率,它是将总体划分为不同层,以增加某一类总体的代表性。以数据为驱动力的非监督聚类算法可以根据数据本身特征,将数据划分为不同的聚类簇。本研究在没有可直接使用的当季作物分布数据前提下,将预处理后的待分类遥感影像和提取到的分类特征作为先验知识引入抽样底图设计,通过影像特征聚类的方法构造分层抽样底图,以减轻抽样设计工作量并提高遥感作物分类的效率,图2所示主要步骤包括:1)基于已有先验知识,采用非监督聚类算法和手肘法实现研究区的空间最优分层,并生成最佳抽样底图。2)给定总样本量后,在同一分层抽样底图上为每种样本分配方式创建了200个具有相同大小的不同样本布设方案,以避免层内随机抽样的偏差。3)使用同一个监督分类器对每个抽样策略的200个样本布设方案所获样本点进行训练,并建立不同抽样策略与同一套验证地面样本点的各精度评价指标对应关系,以探究实际总样本量和理论总样本量之间的关联,并对样本质量进行评价。
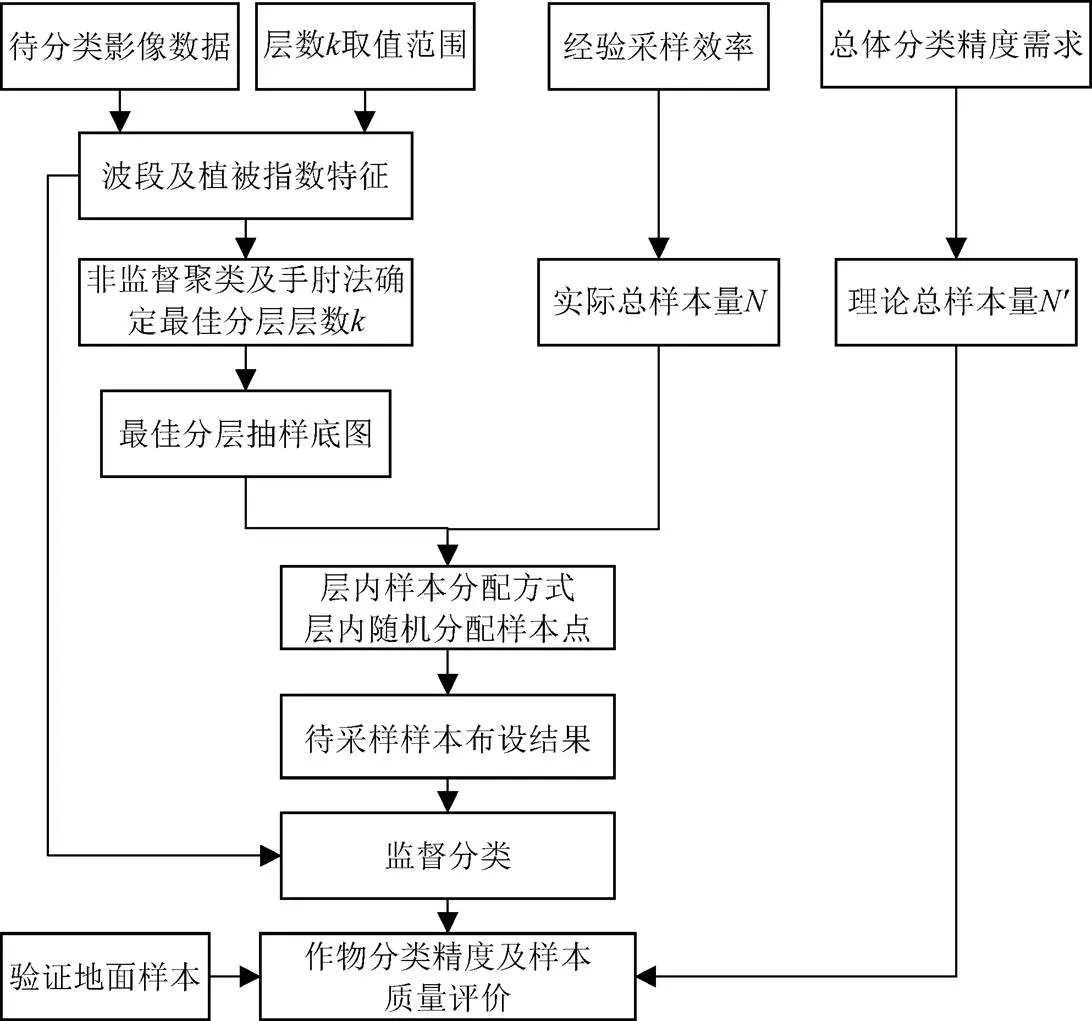
图2 基于遥感影像的地面样本点布设框架图
2.1 分层抽样底图生成方法
一般来说,分层数目越多,层内差异越小,但分层层数过多会形成层数冗余。为得到最佳分层层数及其对应的最佳抽样底图,本研究基于-means聚类分析的数据驱动方法,利用光谱波段值和植被指数创建了聚类特征空间,在每轮聚类结束后,将误差平方和数值作为反馈,形成“-means算法聚类-计算误差平方和-修改聚类数值”的闭环,直至值达到最大取值范围停止,其中,通过手肘法判定的最优值为聚类类别数,利用最优值聚类生成的原始土地覆盖簇来构造抽样最佳抽样底图。此时,最优值对应的聚类类别数被认为是最优层数,每一个像素所属的聚类类别即为分层抽样中的所属层。
2.1.1 构造分层抽样底图
对于没有类别标签的数据,可以通过无监督聚类算法将数据划分为不同的簇[22]。-means算法[32]算法思想简单,在对大规模数据集进行聚类分析时聚类效果较好且收敛速度较快,通常以欧式距离作为衡量数据对象间相似度的指标,相似度与数据对象间的距离成反比,即对象间距离越小,则相似度越大。在遥感分类中,种植同种作物的区域表现出高空间相关性,种植不同作物的两个相邻区域表现出高空间异质性。本研究基于哨兵2号提取的78个光谱特征和植被指数特征,采用-means聚类的方式获得分层抽样底图,其中聚类类别数量为地层数量,每一类簇所含的像元为每层的对象。
2.1.2 确定分层层数
根据聚类性能评估方法,误差平方和代表该聚类中心对于所有在该类中的数据的偏差程度,通常该值越小代表聚类效果越好[33]。手肘法利用误差平方和与值的关系图来确定最优值[34],该算法的核心思想是随着聚类数值不断增大,每个分组(簇)的聚合程度会不断地提高,误差平方和逐渐减小:当值小于真实聚类数时,随着值的增大,误差平方和值的变化比较大,关系图显示两点之间的连线会比较陡峭;当大于真实聚类数时,随着值的增大,误差平方和值的变化较小,关系图显示两点之间的连线会比较平缓。因此,可以在二维平面直角坐标系中作两者间曲线并寻找斜率变化率最大时的拐点来确定最佳值[35],误差平方和S计算式如下:

式中C是第个簇,是C中的样本点特征,m是C的质心(C中所有样本点的均值)。
2.2 总样本量和层内样本分配方式
理论上,样本量越大,遥感影像的分类精度越高,但样本大小往往受收集样本数据的资源经济成本限制。已有研究将抽样理论公式应用于遥感分类精度评价中,并将此评价样本点作为新的训练样本点去训练分类器[2]。
针对简单随机抽样的预期总体精度根据COCHRAN[36]方法计算:
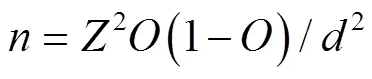
式中为总样本量;是预期总体精度;是置信区间的期望半宽度;是标准正态分布的百分位。
为了方便与不同抽样策略进行对照试验,实际总样本量取决于对照试验中系统抽样法的总样本量,以理论总样本量作为参考值,来探讨实际总样本量、理论总样本量和总体精度之间的关系。
确定总样本量后,分别采用两种层内样本分配方式进行对比试验:1)面积比分配方式,即将总样本点数量按各层层像元面积比例分配得到各层的样本点数量;2)等量分配方式,即将总样本点数量平均分配到各层中,使各层分配得到样本点数量相同。
对于每一层,采用简单随机抽样的方法来获取每一目标类别的样本点,这不仅最大限度的保障样本点间类别均衡,还保障了类内每一点被抽取的概率相等。样本点真实地类属性通过目视解译的方式确定。
2.3 遥感影像分类及其精度评价
支持向量机(support vector machine,SVM)在解决小样本的非线性分类中有特别的优势[37]。因此,将分层样本集作为训练样本集,将每个样本对应的分类特征输入到SVM分类器进行监督分类,并输出监督分类结果图。
本研究使用独立于训练样本集的真实地面样本集,通过混淆矩阵计算作物识别总体精度(overall accuracy,OA)、不同作物的制图精度(producer accuracy,PA)和用户精度(user accuracy,UA)[2],用于对抽样策略效率进行定量评价,并分析总样本量和层内样本分配方式对分类结果产生的影响。
2.4 样本质量评价
样本点质量对作物分类精度起积极作用。代表性可以衡量训练样本点集能否很好地反映全局其余数据的特征,具体指样本点在光谱空间中对其他待分类像素点的反映程度。本研究采用MOUNTRAKIS等[38]提出的基于训练集信息密度计算样本集内任一样本点的代表性值C的计算方法。该方法已被WALDNER等[39]在农田制图采样研究中证实了分类精度与样本数据集的总体代表性值global之间是正向线性关系。本研究以代表性值来对样本集进行质量评价,为了在独立于任何分类情景下量化每种抽样策略所获样本集总体代表性值global,将样本集内所有样本点的代表性值C求和取平均。
3 结果与分析
3.1 最佳分层抽样底图
将预处理后遥感影像内的所有像元作为输入,将取值范围(2~10)作为循环条件,对每个值进行聚类分析并绘制和误差平方和及二者间斜率变化率关系图。从图3可以看出,随着的增加,误差平方和呈下降趋势,但是肘部并不明显,故通过斜率变化率来定量判断拐点肘部值。发现第一肘部对应的值为4,第二肘部对应的值为7。
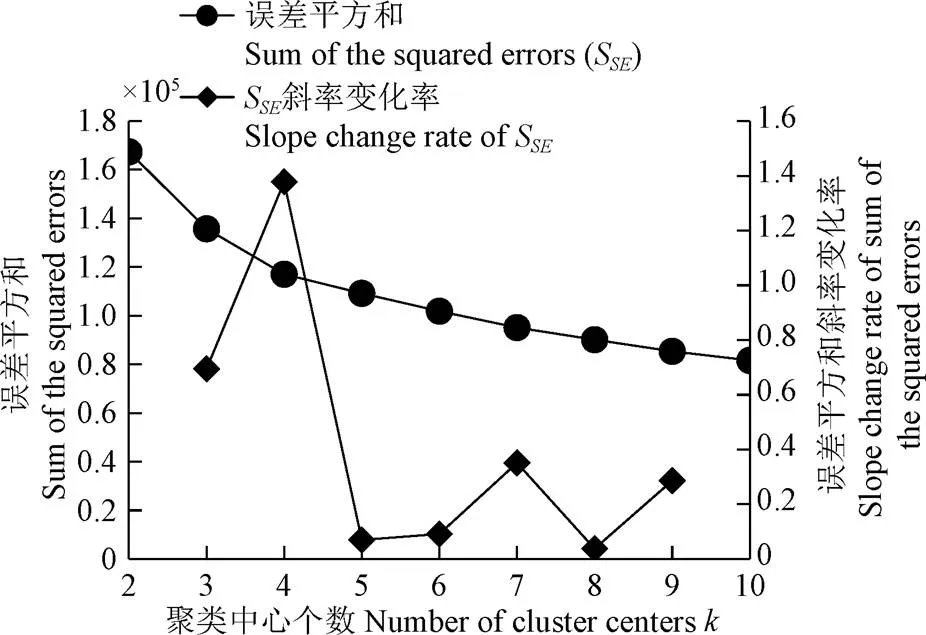
图3 聚类中心个数k值对应分析结果
不同类型地物的光谱反射时序曲线特征不同。非植被地表的居民地道路裸地及河流湖泊的NDVI数值往往常年低于0.3;林草类植被由于没有人工干预收割,全年的NDVI时序曲线呈平稳的上升和下降;一年一熟制作物地类通常在3—5月份播种,NDVI时序曲线在6 —9月有比较高的数值,随后在人工收割的干预下,NDVI数值会出现骤降。
第一肘部和第二肘部不同聚类类别的NDVI时序变化图见图4,从图4a可以看出,第一肘部仅有两个聚类类别的NDVI曲线呈作物生长曲线,另外两类为非作物类型NDVI曲线;图4b则表明第二肘部有5个聚类类别的NDVI曲线呈作物生长曲线,另外两类为非作物类型NDVI曲线。因此,为了避免因聚类数过少或因引入的耕地数据精度误差而导致部分特征不突出的作物被漏分,不选择第一肘部,而是选取第二个肘部对应值的聚类结果作为最佳层数。
3.2 样本点数量
根据式(2)可得,在置信水平为90%、取置信区间期望半宽度为0.05时,计算简单随机抽样预期总体精度为0.85时的理论总样本量为139。
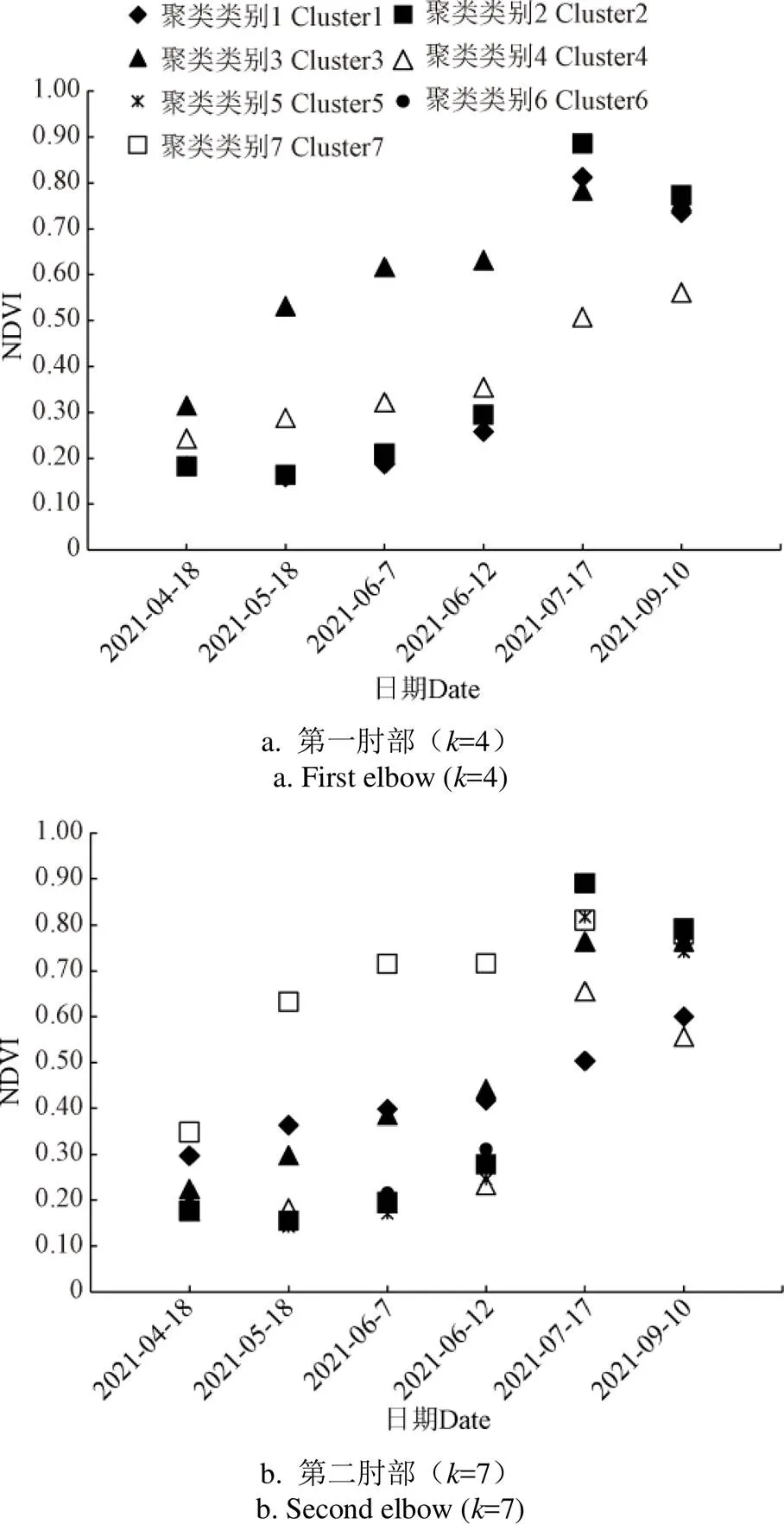
图4 第一肘部(k=4)和第二肘部(k=7)不同聚类类别的NDVI时序变化图
将本研究方法和系统抽样法、简单随机抽样法的分类精度做对比,实际的总样本量由系统抽样法的5×5、7×7、10×10、13×13和15×15个格网点确定,分别为25、49、100、169和225。相应的,按面积比分配和等量分配方式分别得到的层样本量见表1。可以看出,而当总样本量为25时,面积占比最小的第七层所按面积比分配到的样本点数量为1,第四层至第六层按面积比所分配到的样本点数量为2,层间样本数量具有明显的不均衡性,进而影响了分类效果和样本点获取质量。
3.3 遥感影像作物分类结果及其精度评价
3.3.1 遥感影像作物分类结果图
根据实地调查经验,人工选取400个样本点得到传统方式的分类精度,其中训练样本点和验证样本点的比例为8:2(总体精度:97.5%;kappa系数:0.96)。在研究区内选择一个地块较为破碎的局部地区以更好地对比不同抽样策略的分类效果,传统方式的整体及局部地区的分类结果见图5。
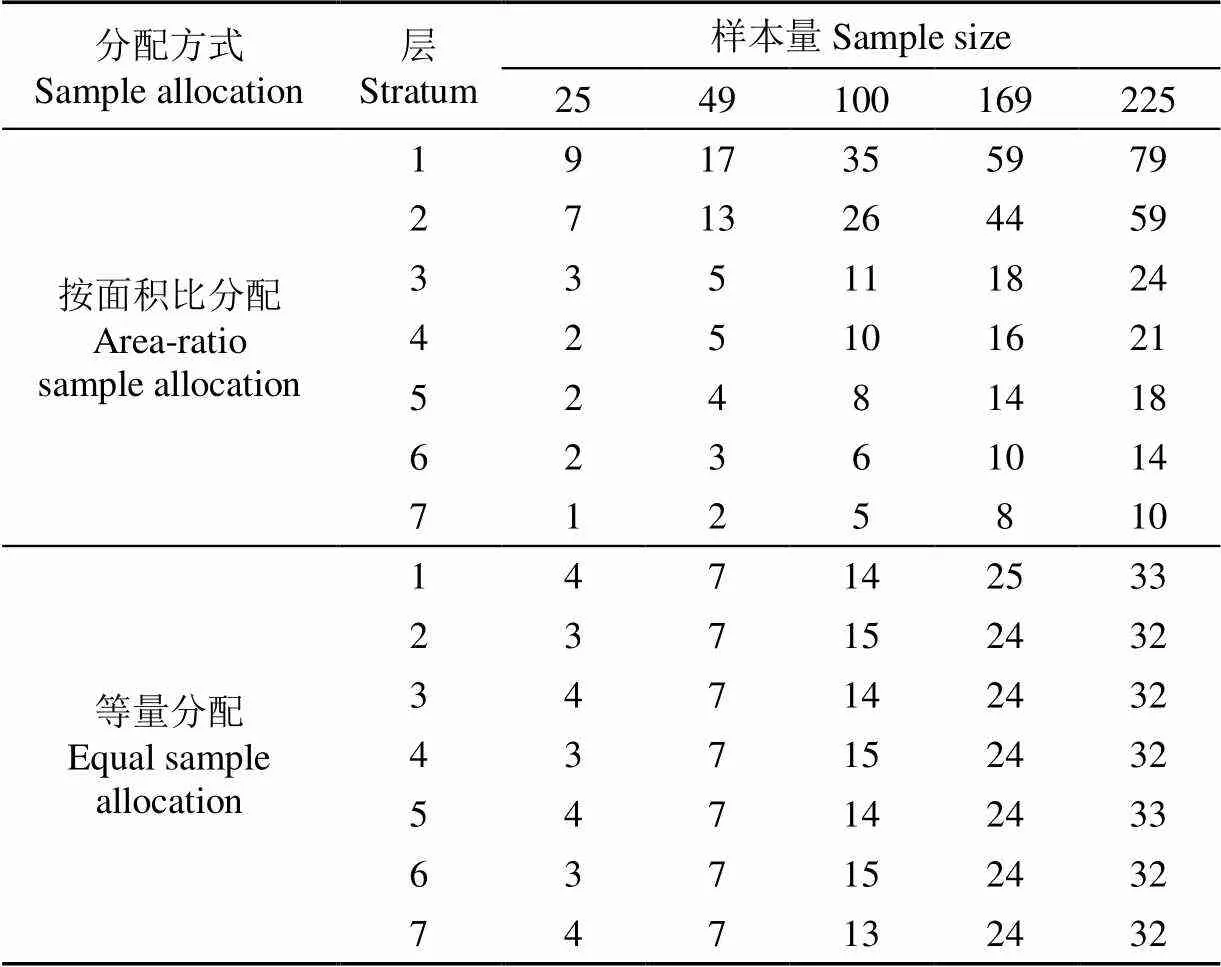
表1 分层抽样层内样本分配方式
注:按面积比分配方式中1~7层面积占比分别为0.35、0.26、0.11、0.09、0.08、0.06、0.05。
Note: Area ratios of stratum 1-7 are 0.35, 0.26, 0.11, 0.09, 0.08, 0.06, 0.05 in area-ratio sample allocation, respectively.
将本研究方法和系统抽样法、简单随机抽样法的分类精度做对比。除已经固定样本点位置的系统抽样法外,记录每个抽样策略的200个样本布设方案所获样本点,并绘制各抽样策略能达到最高分类精度的局部地区分类结果见图6。
图5 传统方式分类结果
从图6可以看出,除了总样本量为25的系统抽样法,其他抽样策略在最高精度时均能明显识别出玉米、水稻和大豆类,不同抽样策略之间的差距主要体现在大豆类的识别上。当总样本量小于100时,等量分层抽样法能识别出局部地区内分布破碎的大豆类,而简单随机抽样和按面积比分层抽样法则仅识别出种植规模较大、分布较集中的大豆田块;当总样本量大于等于100时,除系统抽样法外的3种抽样方法能达到的最高分类精度均十分接近传统方式的分类精度。

注:图中n为总样本数量。图6范围为图5中的局部放大图。
为了定量反映不同抽样策略的分类精度及其稳定性,每个抽样策略样本布设方案的总体精度箱线图见图 7。可以看出,随着总样本量越多,3种抽样方法的平均分类精度依次递增,分类精度平均值和中位数之间的差距越小,上下边缘之间的差距也越来越小,这表明随着总样本量增加,不同抽样方法的抽样效率和稳定性增加,方法间的差异性减小。等量分层抽样法的箱体较短,分类精度中位数较高,表示总体精度分布较为集中且都处于较高的精度水平上,当理论样本量为139时,总样本量为25、49和100时等量分层抽样法的分类精度均值(75.5%、80.5%和86.0%)均明显高于按面积比分层抽样法的分类精度均值(48.4%、69.0%和83.0%),按面积比分层抽样法和简单随机抽样法在总样本量为25和49时的箱体较长,分类精度中位数出现偏态现象且都偏向下四分位数,异常值较多,表示总体精度分布不均匀且数值较低。因此,增加总样本量对总体精度的提高是起积极作用但影响有限的,本研究在总样本量达到169时开始趋于稳定。相比之下,不同抽样策略对总体精度的影响更大。
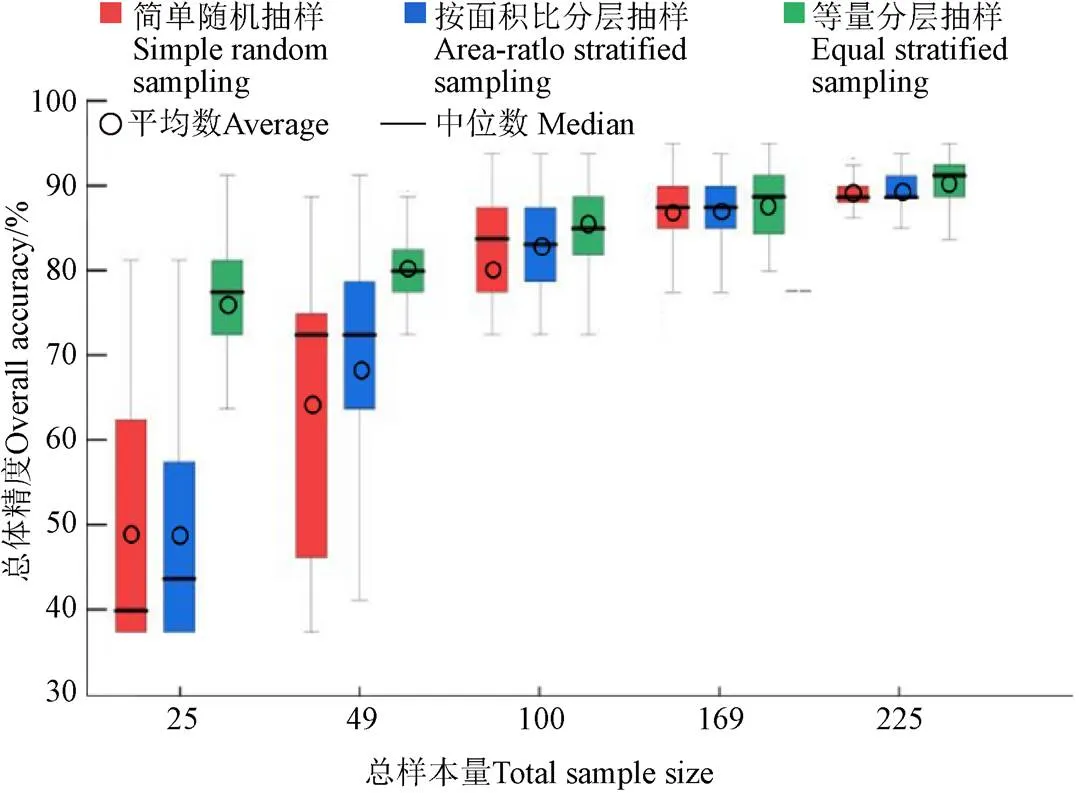
图7 各抽样策略作物分类总体精度评价
Fig7 Crop classification overall accuracy assessment of each sampling method
做精度85.0%和97.5%的水平线与各抽样策略的平均分类精度的连线相交。记录精度为85.0%时水平线相交纵坐标对应的总样本量分别为152、138和96,是简单随机抽样理论总样本量139的109.4%、99.3%和69.1%;记录精度为97.5%水平线相交纵坐标对应的总样本量分别为438、418和374,是传统人工选取方法样本量400的109.5%、104.5%、93.5%。
3.3.2 各作物类用户精度和制图精度
为了探究分层抽样样本分配方式对总体精度的影响,各抽样策略单一作物类别的用户精度(UA)、制图精度(PA)、用户精度方差(UA)和制图精度方差(PA)见表2。可以看出不论总样本量为多少,简单随机抽样法的水稻类的UA和PA小于0.08、UA和PA均值小于20.0%,等量分层抽样法UA和PA均值均大于85.0%,UA和PA小于0.05,说明简单随机抽样法的水稻分类效果总是很差,等量分层抽样法的水稻分类效果表现优异,当总样本量小于100时,按面积比分层抽样法的UA和PA均值较低,UA和PA较大,而当总样本量增至100时,UA和PA均值超过90.0%,UA和PA小于0.01,这表明当水稻获取足够样本量时,就能有较高分类精度;不论总样本量为多少,简单随机抽样法的大豆分类效果均好于分层抽样法,其中,在总样本量少于等于100时,两种分层抽样法的UA和PA均值都低于70.0%,UA和PA较大,而当总样本量增长至100时,等量分层抽样法的大豆类精度和稳定性显著提高,至169时,按面积比分层抽样法的大豆类精度和稳定性显著提高并与等量分层抽样法相当,说明获得的样本点数量和分类特征都是影响大豆分类精度的重要原因;随总样本量增长,3种抽样方法的玉米类UA和PA增长趋势一致,两种分层抽样法的UA和PA几乎都小于0.05,简单随机抽样法的UA和PA几乎都大于0.05,说明分层抽样法的分类效果较简单随机抽样更为稳定,且层内样本分配方式对玉米类的分类效果影响较弱。
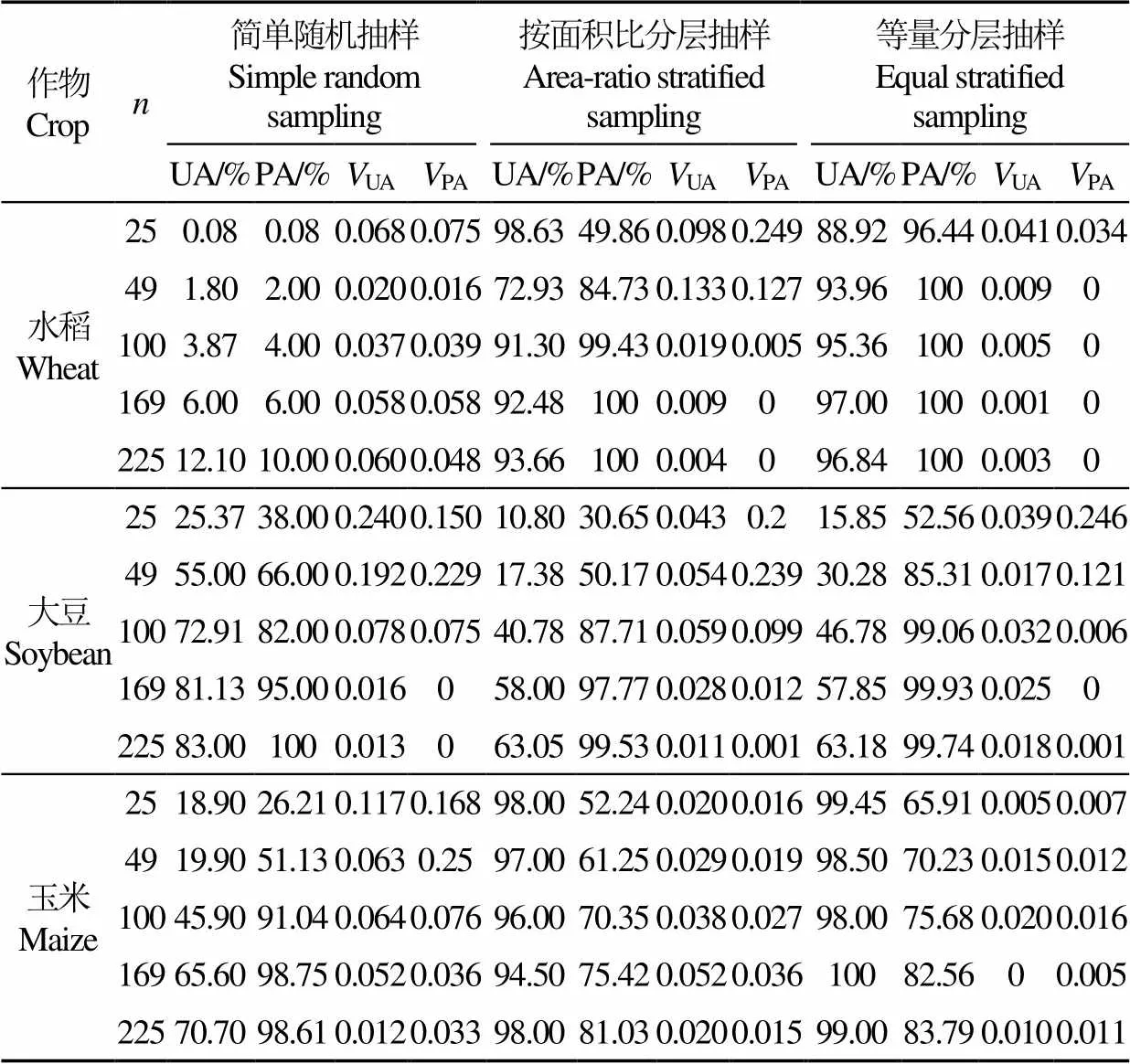
表2 各抽样策略单一作物类别精度评价
注:PA、UA 分别代表制图精度、用户精度。UAPA分别代表PA、UA方差。
Note: PA and UA represent the producer's accuracy and the user's accuracy.UAandPArepresent the variance of UA and the variance of PA.
结合3种作物类的分类结果,可以得到简单随机抽样法在3种作物分类效果上表现不稳定,且影响总体精度的主要因素是水稻和大豆被分配的样本量:等量分层抽样法能够使研究区内面积占比较小的类别获得足够的数量,而当总样本量足够多时,两种分层抽样法的差异并不明显。
3.4 各抽样方法所获样本点质量评价
以总样本量为225的等量分层抽样法为例,针对200个样本布设方案的单一作物类型,以全部代表性值Cglobal为自变量,以对应制图精度PA为因变量建立线性回归模型结果见表3。从表中可以看出,global与PA之间的正向关系与已有研究的结论一致[38-39]:3个线性回归模型的回归系数大于0,值在0.05水平上显著,决定系数R偏低,这是因为一次抽样可能得到如高代表性玉米与低代表性水稻、大豆的样本点组合,从而影响了单一作物类别的制图精度。
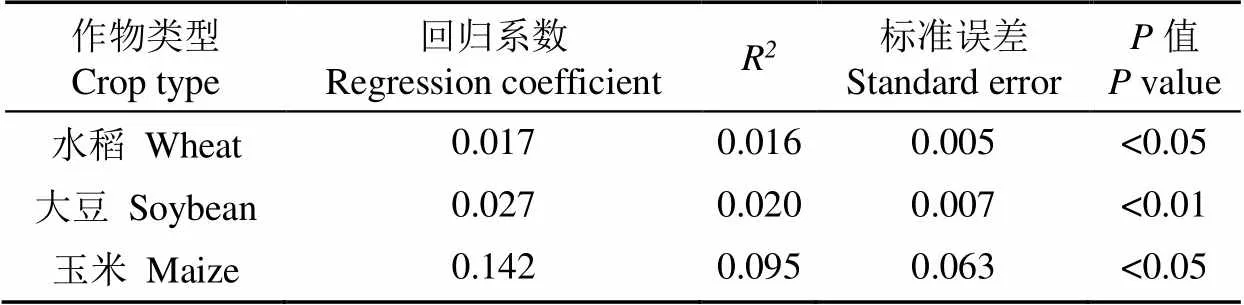
表3 单一作物类型代表值与制图精度的回归分析结果
样本点代表性与样本点数量和特征有关,由于每个布设方案的同一类别样本点数量均不同,对每个作物类型的global取平均值,通过均值代表性mean比较各抽样方法的样本获取整体效果,结果见表4。从表4可以看出,在实际采样过程中采集到的其他类样本点由于其真实地类型复杂,mean小于0;不论总样本量为多少,等量分层抽样法大豆类和玉米类的mean一直处于较高水平,说明等量分层抽样法的大豆和玉米样本点质量较好,其次是按面积比分层抽样法,且不同抽样方法的样本点mean差距随实际总样本量的增加逐渐减小,与分类精度差距随实际总样本量增长而逐渐减小的趋势一致;随总样本量的增加,所有类别的样本点mean逐渐向0趋近,这可能是因为样本量的增大提高了样本点的多样性,降低了单个样本点的代表性C,从而降低了样本点集的global;对于面积占比很小的水稻地类,global计算受样本点数量影响较大:当实际样本量非常小时,3种抽样方法只能获得极个别甚至没有水稻样本点,难以计算mean,而不论总样本量多少,随机抽样获得的水稻样本点均远小于其他两种分层抽样方法,导致该水稻样本点集的多样性小,随机抽样法的mean比分层抽样法高,等量分层抽样法的mean高于按面积比分层抽样法的mean。
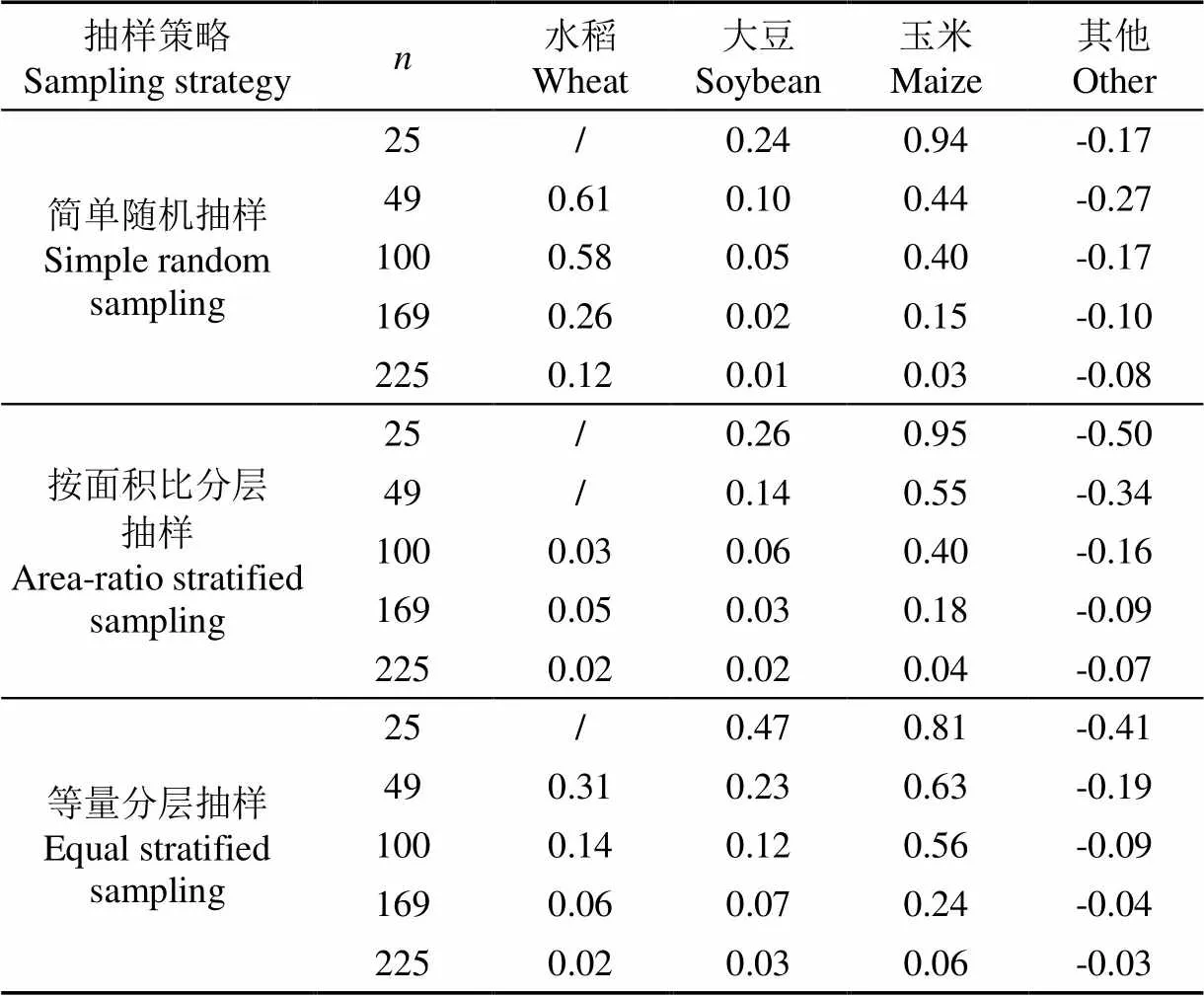
表4 各抽样策略的单一作物类别均值代表性Cmean
4 讨 论
本研究以开原市的一个典型农区试验区为例,分析遥感影像数据本身特征,利用聚类算法和手肘法确定分层层数,获得能反映不均匀数据分布的抽样底图以科学指导样本点的采集。
数据驱动生成的抽样底图可以通过提高样本点类内代表性来提高分类精度。由于作物种植区域、生长状态不统一及遥感信息的不确定性,遥感影像上的“同物异谱”的现象反映在分层抽样底图中就是一个作物类别对应多个地层。通过分析遥感影像数据本身特征,聚类生成的抽样底图将总体划分为不同类别,该底图能反映类别的真实分布情况,减少分类特征和空间混淆。相比于简单随机和系统抽样,在每个地层内抽取一定数量的样本点能最大限度地保障样本点类内多样性,提高分类效率。
在生成抽样底图的基础上,不同分层抽样样本分配方式对类间均衡性产生不同的影响,进一步影响了分类效率。多数分类研究会按面积比例获取训练样本点[40]。然而在少样本时,稀少类会因其极低的占比而缺乏足够的样本点,这可能会出现总体精度较高而稀少类分类精度较低的情况。等量分配样本点数量能增加每个面积占比较小类别的样本量,使分布破碎且占比较少的作物类别在分类中得到更多的信息,增加类间的均衡性,通过提高面积占比较小类别的精度以获取较高总体精度;随着总样本量增大,每个类别提取了更丰富的信息,不同样本分配方式之间的差异变小,此时所有抽样方法都具有可比性。由于增加样本量对分类精度提高是有限的,基于此,在确定抽样底图后,有必要根据总样本量和聚类类别占比去权衡样本分配方式。
分类精度误差来源通常包括使用的分类器性能、验证数据集、训练样本点质量等。研究结论是在使用SVM分类器的基础上得出的,为探究研究结论在不同分类器之间是否具有普适性,仅将SVM分类器更改为随机森林(forest random,RF)分类器,以相同的步骤进行新一轮试验并作箱线图见图8,可看出改变分类器后的总体分类精度和稳定性随总样本量增加而增加,呈现出与使用SVM分类器相同的变化趋势;验证样本点受实际采集条件制约,大多分布在道路两侧,根据这些样本点验证得到的分类精度可能与真实分类精度有偏差;除样本点的特征,样本点代表性还与样本点数量有关,本研究是在特定总样本量下去计算不同作物类型的代表性,每个样本布设方案采集到的各类型作物样本点数量均不相同,虽然研究使用的是均值代表性,但该步骤仍可能存在偏差。基于此,在评估多种抽样方法样本量和分类精度间关系的研究基础上,未来还可尝试评估样本点代表性和分类精度、类别代表性和对应样本量之间的关系。
在作物制图应用中,实际野外调查往往还要考虑通行成本和道路交通可达性等问题,沿道路收集训练数据是一种常见的方式。然而,路边随机抽样会降低了研究区的空间探索水平,对样本点代表性的需求更高,已有研究证明未分层的传统路边采集方式的分类精度和稳定性均低于全局随机抽样方式[39]。基于此,未来研究可以探究引入分层抽样底图对路边抽样策略分类效率的影响,并制定一个科学样本点采集路线。
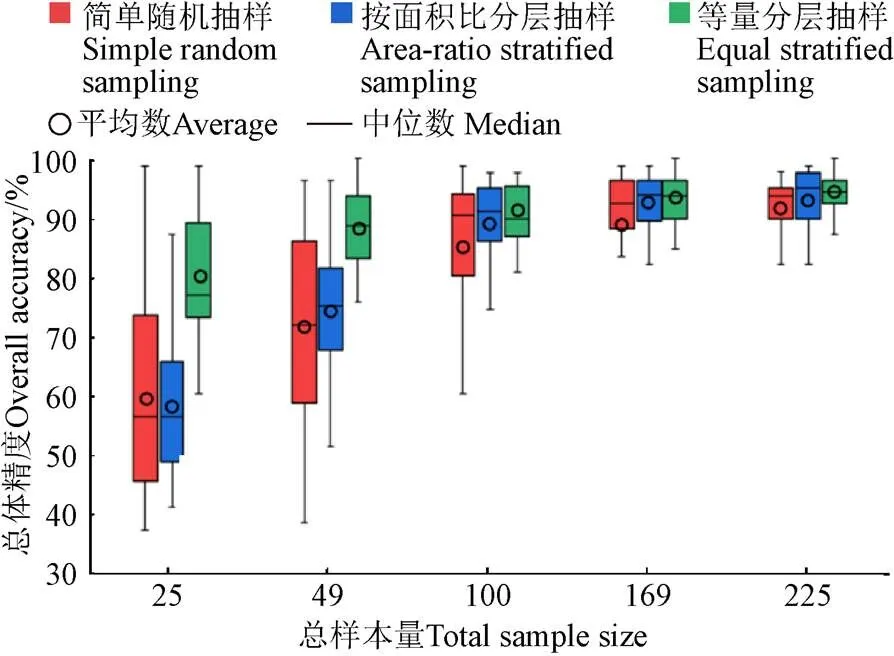
图8 基于随机森林分类器的各抽样策略作物分类精度评价
5 结 论
数据驱动方法重在数据挖掘,通过监督与非监督机器学习等方法自动学习数据的参数特征,进而实现对遥感影像数据的信息提取。为证明在没有可直接使用的当季作物分布数据前提下,遥感影像数据驱动生成的抽样底图能科学指导抽样设计,本研究通过遥感技术、非监督聚类算法与经典抽样方法相结合,在同一个-means聚类最优值对应的聚类结果图上,设计等量分配和按面积比分配2种样本量分配方式,样本点数量为25、49、100、169、225的5个总样本量,结合与139个样本点的理论总样本量和400个样本点的传统方式总样本量对研究区作物分类的分类精度和抽样效率进行了对比分析,结果表明:
1)在数据驱动非监督聚类生成的底图上进行抽样(按面积比分层抽样法、等量分层抽样法)获得的样本点质量和分类精度明显优于没有该底图的抽样策略(简单随机抽样法、系统抽样法)。
2)当总样本量低于理论总样本量时,等量分层抽样法能获取比按面积比分层抽样法更高的分类精度。例如,当理论样本量为139时,总样本量为25、49和100时等量分层抽样法的分类精度均值(75.5%、80.5%和86.0%)均明显高于按面积比分层抽样法的分类精度均值(48.4%、69.0%和83.0%),而当总样本量为169和225时,两种分层方式的分类精度均值都在90.0%左右。
3)当满足总体精度需求时,分层抽样法所需的实际总样本量小于理论样本量,例如,等量分层抽样法的实际样本量为其理论样本量的69.1%时可满足85.0%总体精度需求;当分类精度与人工选取方式分类精度一样时(97.5%),等量分层抽样法的实际样本量为传统方式的93.5%。研究结果印证了分类精度及稳定性随着总样本量的增加而增加这一普遍认识,但当总样本量超过一定值时,精度增长速度变慢。
总之,本研究构建数据驱动的样本点布设方法体系,可以通过“事前优化”科学获取类间均衡、类内多样化的样本点,进而提高分类精度与效率,为农作物遥感地面样本点布设、快速高效分类等提供参考。
[1] STEHMAN S, FOODY G. Key issues in rigorous accuracy assessment of land cover products[J]. Remote Sensing of Environment, 2019, 231: 111199.
[2] OLOFSSON, P, FOODY, G, HEROLD, M, et al. Good practices for estimating area and assessing accuracy of land change[J]. Remote Sensing of Environment, 2014, 148: 42-57.
[3] ZHANG C, DI L P, HAO P, et al. Rapid in-season mapping of corn and soybeans using machine-learned trusted pixels from Cropland Data Layer[J]. International Journal of Applied Earth Observation and Geoinformation, 2021, 102: 102374.
[4] 冯权泷,陈泊安,李国庆,等. 遥感影像样本数据集研究综述[J]. 遥感学报,2022,26(4):589-605. FENG Quanlong, CHEN Boan, LI Guoqing, et al. A review for sample datasets of remotesensing imagery[J]. National Remote Sensing Bulletin, 2022, 26(4): 589-605. (in Chinese with English abstract)
[5] EBRAHIMY H, MIRBAGHERI B, MATKAN A, et al. Per-pixel land cover accuracy prediction: A random forest-based method with limited reference sample data[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2021, 172: 17-27.
[6] GE S, ZHANG J, PAN Y, et al. Transferable deep learning model based on the phenological matching principle for mapping crop extent[J]. International Journal of Applied Earth Observation and Geoinformation, 2021, 102: 102451.
[7] WANG S, AZZARI G, LOBELL D. Crop type mapping without field-level labels: Random forest transfer and unsupervised clustering techniques[J]. Remote Sensing of Environment, 2019, 222: 303-317.
[8] WICKHAM J, STEHMAN S, SORENSON D, et al. Thematic accuracy assessment of the NLCD 2016 land cover for the conterminous United States[J]. Remote Sensing of Environment, 2021, 257: 112357.
[9] 冯权泷,牛博文,朱德海,等. 土地利用/覆被深度学习遥感分类研究综述[J]. 农业机械学报,2022,53(3):1-17. FENG Quanlong, NIU Bowen, ZHU Dehai, et al. Review for deep learning in land use and land cover remote sensing classification[J]. Transactions of the Chinese Society for Agricultural Machinery, 2022, 53(3): 1-17. (in Chinese with English abstract)
[10] 任旭红,潘瑜春,高秉博,等. 类别辅助变量参与下的土壤无偏采样布局优化方法[J]. 农业工程学报,2014,30(21):120-128. REN Xuhong, PAN Yuchun, GAO Bingbo, et al. Optimization method of unbiased soil sampling and layout using categorical auxiliary variables information[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE),2014, 30(21): 120-128. (in Chinese with English abstract)
[11] 厉芳婷,张过,石婷婷,等. 耕地“非农化”遥感解译样本分类体系及应用[J]. 农业工程学报,2022,38(15):297-304. LI Fangting, ZHANG Guo, SHI Tingting, et al. Classification system and application of remote sensing interpretation samples of cultivated land non-agriculturalization[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2022, 38(15): 297-304. (in Chinese with English abstract)
[12] 李若溪,周翔,吕婷婷,等. 植被异质性样区真实性检验的优化采样策略[J]. 农业工程学报,2021,37(8):177-186. LI Ruoxi, ZHOU Xiang, Lyu Tingting, et al. Optimal sampling strategy for authenticity test in heterogeneous vegetated areas[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(8): 177-186. (in Chinese with English abstract)
[13] 谭建光,张锦水,高晨雪,等. 基于结构规模的冬小麦种植面积遥感抽样估算[J]. 农业工程学报,2012,28(23):114-122. TAN Jianguang, ZHANG Jinshui, GAO Chenxue, et al. Winter wheat area estimation based on structure and scale using remote sensing[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2012, 28(23): 114-122. (in Chinese with English abstract)
[14] 吴金胜,刘红利,张锦水. 无人机遥感影像面向对象分类方法估算市域水稻面积[J]. 农业工程学报,2018,34(1):70-77. WU Jinsheng, LIU Hongli, ZHANG Jinshui. Paddy planting acreage estimation in city level based on UAV images and object-oriented classification method[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(1): 70-77. (in Chinese with English abstract)
[15] 王迪,仲格吉,张影,等. 空间自相关性对冬小麦种植面积空间抽样效率的影响[J]. 农业工程学报,2021,37(3):188-197. WANG Di, ZHONG Geji, ZHANG Ying, et al. Effects of spatial autocorrelation on spatial sampling efficiencies of winter wheat planting areas[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(3): 188-197. (in Chinese with English abstract)
[16] WICKHAM J, STEHMAN S, GASS L, et al. Thematic accuracy assessment of the 2011 National Land Cover Database (NLCD)[J]. Remote Sensing of Environment, 2017, 191: 328-341.
[17] YOU N, DONG J, HUANG J, et al. The 10-m crop type maps in Northeast China during 2017–2019[J]. Scientific Data, 2021, 8(1): 1-11.
[18] LIANG S, WU W, SUN J, et al. Climate-mediated dynamics of the northern limit of paddy rice in China[J]. Environmental Research Letters, 2021, 16(6): 64008.
[19] FOODY G, MATHUR A. Toward intelligent training of supervised image classifications: Directing training data acquisition for SVM classification[J]. Remote Sensing of Environment, 2004, 93(1/2): 107-117.
[20] 曹志冬,王劲峰,李连发,等. 地理空间中不同分层抽样方式的分层效率与优化策略[J]. 地理科学进展,2008,27(3):152-160. CAO Zhidong, WANG Jinfeng, LI Lianfa, et al. Strata efficiency and optimization strategy of stratified sampling on spatial population[J]. Progress in Geography, 2008, 27(3): 152-160. (in Chinese with English abstract)
[21] 杨倩倩,靳才溢,李同文,等. 数据驱动的定量遥感研究进展与挑战[J]. 遥感学报,2022,26(2):268-285. YANG Qianqian, JIN Caiyi, LI Tongwen, et al. Research progress and challenges of data-driven quantitative remote sensing[J]. National Remote Sensing Bulletin, 2022, 26(2): 268-285. (in Chinese with English abstract)
[22] 代浩,金铭,陈星,等. 数据驱动的应用自适应技术综述[J]. 计算机研究与发展,2022,59(11):2549-2568. DAI Hao, JIN Ming, Chen Xing, et al. Survey of data-driven application self-adaptive technology[J]. Journal of Computer Research and Development, 2022, 59(11): 2549-2568. (in Chinese with English abstract)
[23] BORYAN C, YANG Z, WILLIS P, et al. Developing crop specific area frame stratifications based on geospatial crop frequency and cultivation data layers[J]. Journal of Integrative Agriculture, 2017, 16(2): 312-323.
[24] CHEN J, CHEN L, CHEN F, et al. Collaborative validation of GlobeLand30: Methodology and practices[J]. Geo-spatial Information Science, 2021, 24(1): 134-144.
[25] 陈逸聪,邵华,李杨. 多源土地覆被产品在长三角地区的一致性分析与精度评价[J]. 农业工程学报,2021,37(6):142-150. CHEN Yicong, SHAO Hua, LI Yang. Consistency analysis and accuracy assessment of multi-source land cover products in the Yangtze River Delta[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(6): 142-150. (in Chinese with English abstract)
[26] Gorelick N, Hancher M, Dixon M, et al. Google Earth Engine: Planetary-scale geospatial analysis for everyone[J]. Remote Sensing of Environment, 2017, 202(12):18-27.
[27] 刘园,蔡泽江,余强毅,等. 从作物轮作角度评价华南典型赤红壤农区耕地质量空间差异[J]. 农业资源与环境学报,2021,38(6):1051-1063. LIU Yuan, CAI Zejiang, YU Qiangyi, et al. Spatial variation evaluation of cultivated land quality from the perspective of crop rotation for a typical lateritic red soil farming area in South China[J]. Journal of Agricultural Resources and Environment, 2021, 38(6): 1051-1063. (in Chinese with English abstract)
[28] ZHAO Y, POTGIETER A, ZHANG M, et al. Predicting wheat yield at the field scale by combining high-resolution Sentinel-2 satellite imagery and crop modelling[J]. Remote Sensing, 2020, 12(6): 1024.
[29] DEVENTER V, WARD A, GOWDA P, et al. Using thematic mapper data to identify contrasting soil plains and tillage practices[J]. Photogrammetric Engineering and Remote Sensing, 1997, 63: 87-93.
[30] MCFEETERS S. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features[J]. International Journal of Remote Sensing, 1996, 17(7): 1425-1432.
[31] 查勇,倪绍祥,杨山. 一种利用TM图像自动提取城镇用地信息的有效方法[J]. 遥感学报,2003,7(1):37-40. ZHA Yong, NI Shaoxiang, YANG Shan. An effective approach to automatically extract urban land-use from TM imagery[J]. National Remote Sensing Bulletin, 2003, 7(1): 37-40. (in Chinese with English abstract)
[32] ANCHANG J, ANANGA E, PU R. An efficient unsupervised index based approach for mapping urban vegetation from IKONOS imagery[J]. International Journal of Applied Earth Observation and Geoinformation, 2016, 50: 211-220.
[33] 王洋,丁志刚,郑树泉,等. 一种用户画像系统的设计与实现[J]. 计算机应用与软件,2018,35(3):8-14. WANG Yang, DING Zhigang, ZHENG Shuquan, et al. Design and implementation of a user portrait system[J]. Computer Applications and Software, 2018, 35(3): 8-14. (in Chinese with English abstract)
[34] 王建仁,马鑫,段刚龙. 改进的k-means聚类k值选择算法[J]. 计算机工程与应用,2019,55(8):27-33. WANG Jianren, MA Xin, DUAN Ganglong. Improved k-means clustering k-value selection algorithm[J]. Computer Engineering and Applications, 2019, 55(8): 27-33. (in Chinese with English abstract)
[35] 姬鹏飞,孟伟娜,杨北方,等. 基于改进BP神经网络的农业机械数据预测研究[J]. 中国农机化学报,2020,41(2):200-205. JI Pengfei, MENG Weina, YANG Beifang, et al. Research on prediction of the number of agricultural machinery data based on an improving method of BP neural network[J]. Journal of Chinese Agricultural Mechanization, 2020, 41(2): 200-205. (in Chinese with English abstract)
[36] COCHRAN W.Sampling Techniques (3rd ed. )[M]. New York: John Wiley & Sons, 1977.
[37] CORTES C, VAPNIK V. Support-Vector Networks. [J]. Machine Learning, 1995, 20(3): 273-297.
[38] MOUNTRAKIS G, Xi B. Assessing reference dataset representativeness through confidence metrics based on information density[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2013, 78: 129-147.
[39] WALDNER F, BELLEMANS N, HOCHMAN Z, et al. Roadside collection of training data for cropland mapping is viable when environmental and management gradients are surveyed[J]. International Journal of Applied Earth Observation and Geoinformation, 2019, 80: 82-93.
[40] NDAO B, LEROUX L, GAETANO R, et al. Landscape heterogeneity analysis using geospatial techniques and a priori knowledge in Sahelian agroforestry systems of Senegal[J]. Ecological Indicators, 2021, 125: 107481.
Data-driven field sample location approach for crop classification using remote sensing
WU Qingying, YU Qiangyi※, DUAN Yulin, WU Wenbin
(,,,100081,)
The field sample points can be directly input into the crop classification models using remote sensing. Therefore, the quantities and quality of sample points can dominate both the classification accuracy and mapping. In this study, a data-driven approach was established for sampling strategies using the features of spectral bands and vegetation indices from image classification. A field sample points approach was carried out to combine a few stratified random sampling, and then followed by the multiple evaluation metrics, according to the dependence of the crop remote sensing classification upon the varied sampling. A data-driven approach based on-means unsupervised clustering was used to generate a graph of clustering with the same optimal, considering 78 classification features extracted from the 6-phase Sentinel-2 images. The comparison experiments consisted of two intra-stratified sample allocation strategies with equal and area-ratio sample allocation, five total sample sizes of 25, 49, 100, 169 and 225, one theoretical total sample size of 139 and one traditional method of total sample size of 400. The accuracy of the mapping was also evaluated by the Support Vector Machine (SVM) classification model. The experimental results showed: 1) Sampling on the data-driven basemap generated by unsupervised clustering (area-ratio, and equal stratified sampling) obtained the better quality sample dataset, which was significantly higher classification accuracy than that without the basemap (simple random, and systematic sampling); 2) In cases where the total sample size was less than the theoretical total sample size, the equal stratified sampling performed better than the area-ratio stratified sampling. For example, when theoretical sample size was 139, mean accuracies of classification with the equal stratified sampling method (75.5%, 80.5% and 86.0%) at total sample sizes of 25, 49 and 100 was significantly higher than that with the area-ratio stratified sampling method (48.4%, 69.0% and 83.0%), while mean accuracies of classification with the two stratified methods at total sample sizes of 169 and 225 were all around 90.0%; 3) The actual total sample size by stratified sampling was smaller than the theoretical sample size, in order to fully meet the overall requirement of accuracy, indicating the great improvement in the sampling efficiency. For example, equal stratified sampling was required about one-seventh of the theoretical sample size to satisfy the overall accuracy requirement of 85.0%. The classification accuracy was equal to that of the manual selection (overall accuracy=97.5%), and the actual sample size of the equal stratified sampling was about one-ninth of the traditional one. Therefore, the classification accuracy and stability increased with the total sample size and then tended to saturate at the end, even if the sample size continued to increase. A well-balanced inter-class and diverse within-class sample set can be expected to obtain for an optical field sample distribution using crop remote sensing classification
agriculture; remote sensing; crop classification; sample point distribution; sampling basemap; cluster analysis
10.11975/j.issn.1002-6819.202210229
S127
A
1002-6819(2023)-06-0214-10
吴清滢,余强毅,段玉林,等. 数据驱动的农作物遥感分类地面样本点布设[J]. 农业工程学报,2023,39(6):214-223.doi:10.11975/j.issn.1002-6819.202210229 http://www.tcsae.org
WU Qingying, YU Qiangyi, DUAN Yulin, et al. Data-driven field sample location approach for crop classification using remote sensing[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2023, 39(6): 214-223. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.202210229 http://www.tcsae.org
2022-10-27
2023-02-14
国家重点研发计划项目(2019YFE0125300);现代农业产业技术体系北京市数字农业创新团队“数字大田应用场景建设”项目(BAIC10-2022-E06)
吴清滢,研究方向为农业遥感。Email:wuqingying@caas.cn
余强毅,副研究员,研究方向为农业遥感。Email:yuqiangyi@caas.cn
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
内蒙古统计(2021年4期)2021-12-06
今日农业(2020年20期)2020-12-15
今日农业(2020年17期)2020-12-15
世界农药(2019年4期)2019-12-30
浙江档案(2019年12期)2019-12-17
测控技术(2018年4期)2018-11-25
上海精神医学(2017年5期)2017-11-29
陕西档案(2016年5期)2016-11-26
上海农业学报(2016年2期)2016-10-27
