
基于图像与雷达信息融合的校园巡逻车识别方案
2023-06-04 13:59卢明宇秦雪薇王正华
黑龙江工业学院学报(综合版) 2023年4期
高 宇,李 进,卢明宇,秦雪薇,王正华
(安徽科技学院 机械工程学院,安徽 凤阳 233100)
当代技术的快速发展,各类行业都开始使用自动化、现代化、智能化种种词汇,从汽车结构优化发展方向转型为自动驾驶智能识别路况中,可以窥见技术在逐渐达成节省劳动力以及工作成本的目的。当代交通行驶逐渐趋向智能化,行驶违禁信息可以通过智能交通管理实现;智能驾驶通过传感器环境感知识别路况,规划识别最优行驶路线,通过智能模块控制转向、行驶速度以保证智能驾驶的稳定性。其中环境感知主要通过传感器感知分辨行驶路径上的障碍物,主要可以分为雷达与视觉检测两个方向。计算机视觉的成熟推动智能驾驶产业发展,用于车辆视觉分为两个方面:目标检测、图像分割,以分割为标准又有实例分割、语义分割。雷达则通过激光雷达测定障碍物位置,毫米波雷达近距离感知。将视觉与雷达融合的多传感器融合技术,在二十世纪八十年代就早已运用于军事并逐渐走向民用。信息融合不同于单一类型传感器的检测方式,而是对于传感器信息的测量、评价与决断,从而提高时效性与准确性。根据校园巡逻车行驶速度在25km/h以下,行驶环境有单行道与双行道,检测环境包含大量行人,视觉与雷达传感器相互配合可以提高校园巡逻车不同环境下的检测精度。
1 结构设计与安装
本文所采用的校园巡逻车数据均为市面常用型号三排六座封闭治安电动巡逻车,由于学校环境下,道路多以单车道为主,道路上受环境以及光照影响很大,特殊时间段人流量大,校内路标各种障碍物较多。校园行驶过程属于行驶速度慢,突发情况多,环境影响较大。需要满足校园情况的检测传感器,同样要考虑巡逻车的轻便性,减少所搭载的设备,减少计算量增加稳定性。
考虑到应用于校园路面环境的情况,相机需要高成像质量、高准确度以及高处理速度。因此相机采用海康威视全彩摄像机固定机位,相比普通相机具有抗干扰能力强、成像稳定快速等优点。此相机为单目相机,单目相机有别于双目多目相机更适用于小型车辆处理简单数据,算法逻辑简单处理速度快,成本低。当然硬件劣势较大、应用场景有限,综合来看适用于校园巡逻车较简单的路况环境。
雷达选用16线激光雷达,三维激光雷达相较二维激光雷达更适用于校园错综的行人与路况环境,同样无人驾驶领域三维雷达也更优于二维雷达。16线三维雷达在户外行驶状况中的雨雪天气、雾霾天气一样可以发挥检测作用,多个单线激光可以准确完整地输出检测结果。三维激光雷达也比二维激光雷达更能体现空间信息,容易获得障碍物距车体的距离。校园巡逻车基本参数如表1所示,校园巡逻车实体图,如图1所示。

图1 校园巡逻车实体图

表1 校园巡逻车基本参数
2 图像信息识别
校园巡逻车行驶环境下所选取的视觉识别为深度学习模型进行语义分割,该方法是计算机视觉研究的一大类,其中也包含图像信息、计算机学习、计算机视觉。图像采集由单目摄像机获得图像信息。
2.1 基于图像信息的语义分割
基于计算机视觉处理图像的方法很多,图像语义分割属于计算机视觉经常使用的一类计算机视觉识别方法,近年来计算机深度学习的发展使语义分割计算更加多样[1]。用于车辆语义分割的卷积神经网络的基本结构、常用的几种优化函数中,围绕构建车辆语义分割的简化全卷积神经网络通常包括完全卷积网络(FCN),SegNet和U-Net[2]。语义分割对比图像检测更倾向于利用预训练模型区分识别区域,适用于校园巡逻车较为简单的环境,在轻便化的巡逻车上也可以保持稳定性以及计算的快速性。
2.2 语义分割训练模型
本文使用预训练的Resnet-18网络初始化权重创建Deeplab v3+网络,为了将32个类别减少为11个类别,将原始数据集中的多个类别组合在一起。例如,将各类别的车辆定义为“Car”标签。Resnet-18编码语言在巡逻车这种轻便的落地环境有更快更小的模型,数据场景较为简单足够胜任识别任务。训练模型流程图,如图2所示。
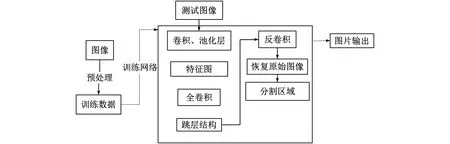
图2 训练模型流程图
之后利用SegNet编码输出复原图片点云的类型,形成将图片分割各部分的解码过程。训练网络结构上来说因为SegNet采取先将计算量记录池化替代反卷积操作,SegNet训练过程要比FCN要简单很多。
以上是两种不同的算法方式,SegNet是将摄像头检测到的视觉信息点生成特征点云图,之后根据卷积计算将稀疏点云聚类构成多点特征图。而FCN则跳过预生成的点云图直接进行反卷积再加上编码器的计算结果,计算量相较上述更大。关于解码方式所体现出的优点在于特征图实现的效果更好,体现在Boundary-F1轮廓匹配分数上以及运行过程中内存受限的情况下SegNet可以使用特征图的压缩形式来提升表现,得到明显分割点云图。
利用matlab软件训练语义分割网络DeeplabV3+,执行训练或使用预训练模型建立数据集。首先选择符合校园场景的数据图片库设置图片尺寸,根据训练模型其中60%的图片用于训练,剩下20%图片用于验证评估,20%的图片用于测试结果即训练集、验证集、测试集[3]。将训练集图片RGB值灰度化根据灰度值分割区域评估分类,通过对CamVid数据集中的类加权平衡提高训练水平。
3 雷达信息识别
本节介绍该车雷达的参数与识别过程,基于16线激光雷达的坐标系建立与点云生成和用于测量车辆前方障碍物的毫米波雷达。雷达信息的识别相较于视觉信息更能体现空间性,可以体现出障碍物的具体位置确定其分布。
3.1 多线激光雷达的安装与参数
对于单一传感器识别路况障碍物的原理在不同方面各有优缺点。雷达与视觉传感器的区别是通过检视前方行人及障碍物的位置进行构图确定位置分布,视觉则是通过检视图像区别及边缘特征去分辨障碍物及定位分布。激光雷达作为单一传感器确定障碍物位置的流程为激光束扫描、数据转换、建立点云图。这种基于相对距离的方法更加准确地获取障碍物的位置,同样由于激光射线的分布关系2.5m内误差较大,越远激光射线越稀疏精确度越低。
雷达的安装位置根据雷达激光器的垂直角度范围是-15°~+15°,安装高度为2.32米,距车顶40cm。具体参数如表2所示。

表2 16线激光雷达重要参数
激光雷达检测物体的精度根据距离误差逐渐增大,误差变化如图3所示。
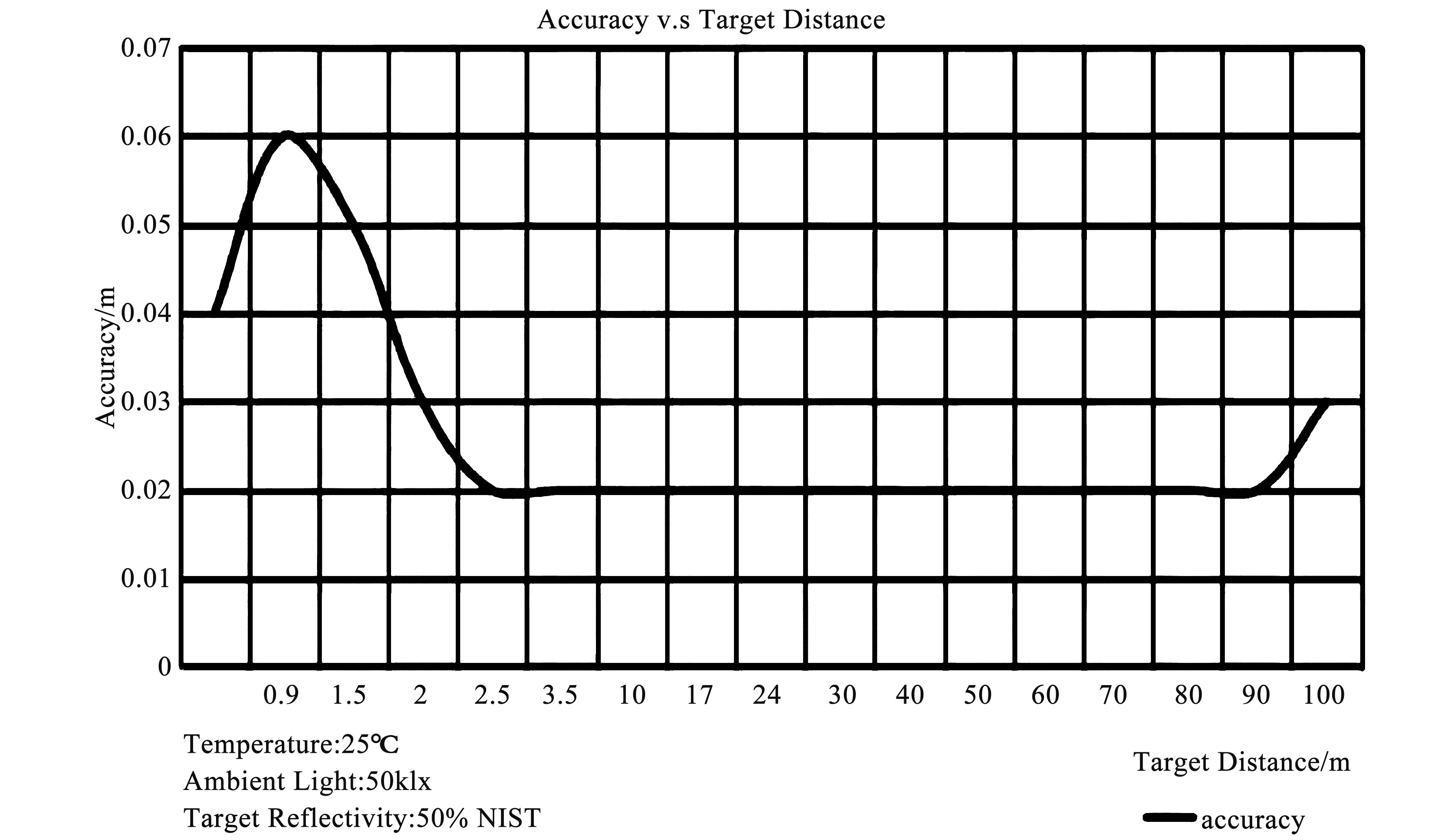
图3 雷达检测误差范围变化图
3.2 激光雷达的识别
雷达点云的呈现原理为坐标映射,为呈现三维点云图效果通过笛卡尔坐标系转化极坐标下的角度距离信息为x、y、z坐标[4],转换公式如式(1)所示。
(1)
式(1)中,d为实测距离,ω为雷达激光角度,α为水平旋转角度,可以得出任意第i根雷达激光线距目标水平距离D为式(2)所示。
D=h×tan(αi+i×2),i∈[0,15]
(2)
h为雷达中心点到地面高度,由式(2)可得16根激光扫描线之间与巡逻车的位置关系,重新以巡逻车前轮中间点建立新的坐标系。以车辆行驶方向为新建Y轴正方向,Y轴正方向水平旋转90°为新建X轴正方向,水平向上为Z轴正方向,建立车体坐标系。θ为激光与y轴正方向的夹角,φ为雷达扫描面与新坐标系XOY平面夹角[5],该坐标系命名为车体坐标系,三维坐标P=(X,Y,Z)将雷达坐标系中的点转换为汽车坐标系数据,如式(3)所示。
(3)
坐标系的转换也是将以雷达为中心转换为以车头尾中心保证行驶识别的准确度。
摄像头信息与激光雷达信息的数据融合的主要特征是结合多个传感器的获取信息,合理分配利用资源根据规则分析、综合用于完成所需的决策和评估任务[6]。雷达与视觉两种类型的传感器优化感知数据融合根据处理方式的不同主要有三个层面:数据采集层面、特征分辨层面和处理决策层面。本章节考虑视觉雷达信息融合用于校园巡逻车行驶的方法,根据校园巡逻车行驶速度在20km/h左右的特性以及路边行人较多的路况需要视觉根据雷达所检测到的目标数据更准确地确定位置。
4 多传感器的融合与标定
这部分描述的多传感器即视觉与雷达相关传感器的坐标系标定融合,根据上一章节所介绍的两种坐标系雷达坐标系与车体坐标系中加入图像视觉信息,提供多种参考数据使其融合处理以达到多传感器的精度优势,使检测的原始数据转化为更有效的目标数据[8]。
4.1 视觉与雷达的坐标标定
通过16线激光雷达中心与车前轮中心相对位置所建立的新坐标系车体坐标系P=(X,Y,Z)以及原始坐标系p=(x,y,z)将雷达的角度距离信息体现在车与障碍物的距离位置上以此为依据将建立雷达与视觉同步计算的标定坐标系,使视觉信息体现在雷达坐标系决策中[7]。首先建立雷达标定坐标系,取任意障碍物p点车体坐标系与雷达坐标系的数据(xp,yp,zp)与汽车车体坐标系数据(Xp,Yp,Zp)得到转化关系式,如式(4)所示。
(4)
式(4)中的(xp,yp,zp)T与(Xp,Yp,Zp)T代表雷达坐标系与车体坐标系数据通过取点可通过超定方程求出旋转矩阵R与平移矩阵T,两个量分别表达角度与雷达中心到前车轮中心的距离。具体参照物数据,如表3所示。
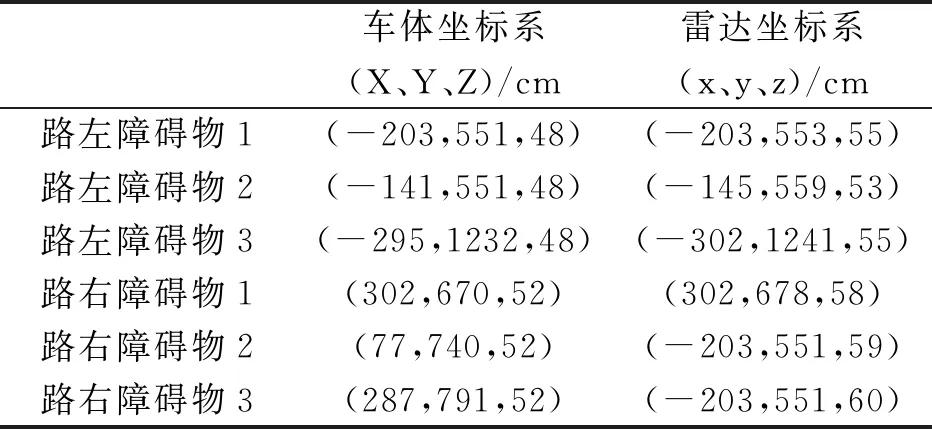
表3 车体坐标系与雷达坐标系中的参照物数据
将上述表3中数据代入式(4)通过使用matlab求解超定方程可以得到旋转矩阵R与平移矩阵T的量,如式(5)所示。
(5)
之后再将雷达坐标系数据代入式(5)计算误差评估标定方程准确度,主要考虑水平面上坐标度量的精度可以得到x,y方向误差,如表4所示。

表4 车体坐标系与雷达坐标系中标定误差分析
可以得出误差水准均小于5cm,雷达工作的过程中,精度满足识别要求。
4.2 视觉与雷达的信息融合
雷达数据所体现的信息为车体坐标系中的P= (X,Y,Z),根据车体坐标系的建立其中三个参数X,Y,Z综合表达了巡逻车前轮中线距障碍物的空间位置,将坐标映射到图像坐标中简化计算减低计算量。当雷达的车体坐标信息与图像信息相对应可以忽略雷达的误差信息只保留大致的位置信息。
其中的难点就是视觉采集的信息在空间上与之对齐,因此去车体坐标系P中的Z值是两种信息高度相对应以确定空间位置的一致其中的步骤如下:
(1)将雷达坐标系中的坐标信息转化车体坐标系中的坐标信息,取其中Y值;
(2)将视觉信息中感兴趣的特征区域范围与Z值查看是否相匹配;
(3)完成雷达与视觉信息的融合。
另外的一个难点是如何做到时间上的对齐,时间对齐的问题是如何将图像信息的帧数时间对齐雷达数据时间。为了解决这种问题使用计时器设定采集一段时间的图像帧数使之与雷达帧数,并保证两者帧率相同,若数据一致可以在误差较小的情况下认为两者数据其时间对齐。
5 结论
根据标点坐标系的建立提出一种融合视觉与雷达多传感器处理校园巡逻车路况信息的方案,并用建立数据库深度学习的方法使图像识别部分更加轻便,激光雷达坐标系的建立也更直观体现车头距障碍物的位置关系。在光照的强弱影响、阴影影响以及路况拥堵场景都有很好的表现。
猜你喜欢
北京测绘(2022年5期)2022-11-22
汽车观察(2021年8期)2021-09-01
动漫界·幼教365(中班)(2020年3期)2020-04-20
铁道通信信号(2020年9期)2020-02-06
中国交通信息化(2019年1期)2019-03-26
电子制作(2018年16期)2018-09-26
中学生数理化·七年级数学人教版(2018年4期)2018-06-28
数学大世界(2018年1期)2018-04-12
中等数学(2017年2期)2017-06-01
中国海洋大学学报(自然科学版)(2014年8期)2014-02-28
