
针对小目标的YOLOv5安全帽检测算法
2023-06-21 09:28李达刘辉
现代信息科技 2023年9期
李达 刘辉



摘 要:针对当前YOLOv5难以检测小目标、目标识别效果差等问题,提出了一种基于YOLOv5的改进模型。针对开源数据集小目标样本数量不足的问题,重新构建安全帽数据集,扩充小目标数量。引入轻量化的通道注意力ECA模块,提高模型对安全帽的识别能力。将边界框损失函数替换为SIoU加速模型收敛。最后改进Neck部分的特征融合方式,并增加一个小目标检测层。改进算法在自建安全帽数据集上mAP@0.5、mAP@0.5:0.95相较于YOLOv5s分别提高2.6%、1.7%。
关键词:安全帽佩戴检测;YOLOv5;ECA注意力;边界框损失函数;小目标检测
中图分类号:TP391.4;TP18 文献标识码:A 文章编号:2096-4706(2023)09-0009-05
Abstract: Aiming at the problems of small target detection difficulty and poor target recognition effect of YOLOv5 at present, an improved model based on YOLOv5 is proposed. In view of the problem of shortage of small target samples in open source data set, the safety helmet data set is rebuilt to expand the number of small targets. A lightweight ECA module is introduced to improve the identification ability of the model to the helmet. The bounding box loss function is replaced by SIoU to accelerate the convergence of the model. Finally, the feature fusion mode of Neck part is improved, and a small target detection layer is added. Compared with YOLOv5s, the improved algorithm on the self-built safety helmet data set mAP@0.5 and mAP@0.5:0.95 respectively increases 2.6% and 1.7%.
Keywords: safety helmet wearing detection; YOLOv5; ECA attention; bounding box loss function; small object detection
0 引 言
随着我国基础设施的快速发展,在建筑工地工作的工人数也逐渐上升。在安全生產规范中,明确指出在施工场地必须佩戴安全帽。佩戴安全帽可以在工程作业中有效保护施工人员头部,保障工人的生命安全。但在众多施工场地中,安全帽的佩戴很容易被施工人忽略,从而引发人身伤害的事故。我国大多数施工场所中采用人工进行安全帽的佩戴检测,这种原始的检测方法不仅耗时耗力,而且容易产生误差。为了解决现有施工场地存在的这一安全问题,对施工场地进行智能化的管理,对施工人员进行安全帽佩戴状态的精确检测是很有必要的,具有重大的研究意义。
近年来,基于深度学习的目标检测技术飞速发展,目标检测算法也越来越广泛的应用于各个方面。小目标检测一直以来是目标检测技术中的重难点,针对安全帽的目标检测通常应用于施工现场采集到的远距离照片,目标密集易出现阻挡,且像素点小,属于小目标的范畴。对于小目标安全帽的目标检测算法分以YOLO[1](You Only Look Once)系列为代表的单阶段算法和以R-CNN[2](Region-based Convolutional Neural Network)系列为代表的两阶段算法。吴冬梅等[3]在Faster R-CNN的基础上,改进特征融合的方式,显著地降低了对安全帽的误检和漏检率,但检测速度上相比于单阶段算法仍有一定差距。YOLO和SSD[4](Single Shot multibox Detector)是典型的单阶段目标检测算法。李明山等[5]将特征融合的分支网络添加进SSD算法中,通过可变参数调节先验框大小,提升了安全帽检测的速率和实时性;为了进一步提高检测的准确性,徐传运等[6]基于YOLOv4算法进行改进,提出一种数据增广的算法,增强了检测模型对小目标物体的检测能力。王玲敏等[7]人将坐标注意力加入YOLOv5算法中,并将特征金字塔替换为加权双向特征金字塔,增强了模型对密集物体的检测效果。但是在实际场景中对小目标安全帽检测仍存在不足。
因此,为了提高安全帽检测的性能,本文针对YOLOv5s模型进行改进研究,主要的改进方式如下。
首先,针对开源数据集的局限性,对开源数据集进行筛选过滤,去除开源数据集中简单重复的样本,并通过网络爬取技术扩充数据集,丰富小目标数量,使模型能够学习更多的特征,提升对小目标的检测能力。
其次,在主干网络引入高效通道注意力ECA(Efficient Channel Attention)模块[8],使模型更加关注安全帽的特征信息,增强模型对小目标的检测性能。
然后将边界框损失函数由CIoU Loss替换为SIoU Loss,提升模型的收敛速度和推理的准确性。
最后针对小目标样本,改进Neck部分的特征融合方式,加强特征金字塔的特征提取能力[9],同时增加一个160×160尺度的小目标检测层。以提高算法在复杂密集的场景中对小目标的检测精度。
1 YOLOv5s模型
YOLOv5算法模型主要包括4类不同深度和宽度的网络结构,而综合目前的需求,选用深度最小,参数量最小的YOLOv5s模型进行安全帽佩戴检测研究,主要网络结构由四部分组成,依次为输入端Input、主干Backbone,颈部Neck和输出端Head,YOLOv5s结构图如图1所示[10]。
1.1 输入端
输入端负责对输入网络的图片进行预处理,YOLOv5s的输入端采用自适应锚框计算、Mosaic数据增强方法以及图像缩放等策略。
1.2 主干网络Backbone
主干网络主要负责对经过预处理的图片进行特征提取,主要包含卷积模块(Conv)、瓶颈层(C3)、以及空间金字塔池化(SPPF)三个模块。
1.3 颈部Neck
颈部是特征融合网络,由FPN(特征金字塔)和PAN(路径聚合网络)结构构成,负责将主干网络提取到的特征进行多尺度特征融合,实现对特征的充分利用,从而提高网络的检测性能。
1.4 输出端
输出端包含三个检测层,检测尺寸分别为80×80、40×40、20×20,三个检测层负责对图片进行类别预测并生成边界框。检测层采用非极大值抑制(NMS)消除冗余的预测框,输出置信度得分最高的预测类别,并返回边框坐标。
2 YOLOv5s算法改进
2.1 主干网络引入通道注意力ECA
注意力机制能够通过权重聚焦位置,产生更具有分辨性的特征,使网络获取更多的上下文信息。为了加强特征信息的利用率,本文引入一种高效通道注意力ECA模块。ECA是Wang等在2020年对经典的Squeeze and Excitation(SE)模块进行改进、提出来的一种高效轻量通道注意力机制模块。ECA注意力模块如图2所示。
图中,H、W、C分别表示输入特征图的高、宽和通道数,GAP(Global Average Pooling)为全局平均池化层,σ为Sigmoid激活函数,k为自适应卷积核大小,k的大小通过一个函数来自适应变化并与通道数C有关,本文中k设置为5。
ECA注意力机制的实现过程如下:
1)输入的特征图经过全局平均池化之后,特征图大小由[H,W,C]变成[1,1,C]。再对特征图进行卷积核大小为k的一维卷积操作,并经过Sigmoid激活函数得到特征图每个通道的权重。
2)将归一化权重与原输入特征图逐通道相乘,输出加权后的特征图。
本文对YOLOv5s特征提取阶段的结构进行改进,将ECA注意力模型嵌入到SPPF模块之前,对经过主干网络进行特征提取之后的特征图进行进一步的加强,在降低参数量的同时大大提升网络对特征的利用效果。引入ECA注意力模块的主干结构网络图如图3所示。
2.2 损失函数改进
本文采用SIoU Loss作为边界框损失函数,替代YOLOv5使用的CIoU Loss。其公式为:
其中Δ表示距离损失,Ω表示形状损失,Λ表示角度损失,σ为真实框和预测框中心点的距离,cw,ch为真实框和预测框最小外接矩形的宽和高,, 为真实框中心坐标,, 为预测框中心坐标,ω,h,ωgt,hgt分别为预测框和真实框的宽和高,θ控制对形状损失的关注程度本文中参数范围定为[2,6]。SIoU(Scylla Intersection over Union)在CIoU的基础上重新定义了惩罚度量,考虑了期望回归之间的向量夹角,提升了模型收敛速度的同时,提升了模型对于安全帽检测的精度。
2.3 改进特征融合方式并增加小目标检测头
原始的YOLOv5模型在Neck模块对SPPF模块输出的20×20大小的特征图进行两次上采样,并通过四次Concat操作,输出特征图大小为80×80、40×40和20×20的三个尺寸,分别用于检测小目标,中等目标,大目标,但是在实际情况中施工人员遍布整个施工现场,在工人离的距离比较远时就会成为极小目标,此时80×80的检测头对于极小目标的检测很容易出现漏检误检。针对这个问题,本文提出一种新的特征融合方式,并增加一个极小目标检测层,改进的Neck部分与Head部分如图4所示。
原始YOLOv5算法在第二次Concat操作后经过一个C3模块输出特征图大小为80×80的小目标检测层用以检测小目标,本文在两次上采样与Concat操作后,再进行一次上采样得到160×160的特征图,将上采样后的特征图与骨干网络第二层的输出进行Concat,再经过一个不改变特征图大小的C3模块,最终输出特征图大小为160×160的极小目标检测层,改良后的小目标检测层Concat拼接也由原来的主干网络第四层变为第三次上采样前的特征图输出,融合路径的改进加强了Neck的特征融合能力,提升了模型对于小目标与极小目标的检测性能。
3 实验结果与分析
3.1 数據收集与预处理
针对安全帽数据集,网上比较常用的开源数据集有SafetyHelmetWearing-Dataset,共有7 581张图片[11],该数据集中包含大量的简单重复样本不符合实际工地场景,手动剔除数据集中的简单重复样本并通过网络爬虫与自主拍摄,共收集图片12 159张,自主收集的图片使用LabelImg标注工具标注为VOC格式,针对佩戴安全帽与未佩戴安全帽设置两个分类:helmet(佩戴安全帽),head(未佩戴安全帽)。通过脚本将数据集转换为YOLO格式并按训练集:验证集=8:2的比例进行随机划分,得到训练集数据9 669张,验证集数据2 490张。
3.2 实验环境及参数设置
本次实验在AutoDL服务器上运行,操作系统为Ubuntu 18.04,CPU为12核 Intel(R) Xeon(R) Platinum 8255C,内存43 GB,GPU为一块RTX 2080 Ti,显存为11 GB,框架选用Pytorch。具体环境配置如表1所示。
使用SGD优化器进行训练,图片输入大小为640×640,batch-size设置为16,数据加载器数量设置为8,训练轮数为250轮,其他超参数均为默认值,所有对比实验均采用相同参数。
3.3 衡量指标
采用精确率P(Precision)、召回率R(Recall)以及平均精确率(mAP)作为衡量模型性能的指标。
实验中对真实情况和预测情况的分类如表2所示。其中TP表示被模型预测为正类的正样本,FP被模型预测为正类的负样本,FN被模型预测为负类的正样本,TN被模型预测为负类的负样本。
精确率(P)是分类正确的数量占总分类数量的比值,召回率(R)是分类正确的数量占总样本的数量,平均精确度(Average precision, AP)是对精确率—召回率曲线(PR曲线)上的Precision值求均值,平均精确率mAP是对所有类别计算出的AP值求平均值,mAP@0.5表示IoU=0.5时mAP的值,mAP@0.5越大表示模型的检测效果越好,mAP@0.5:0.95指IoU的值从0.5按照0.05的步长增长到0.95时所有mAP的平均值。mAP@0.5:0.95的值越大,表示模型预测框和真实框越契合,检测效果越好。以上指标的计算公式为:
其中式中S表示检测类别数,本文中为2,APi代表第i个类别的精确率。
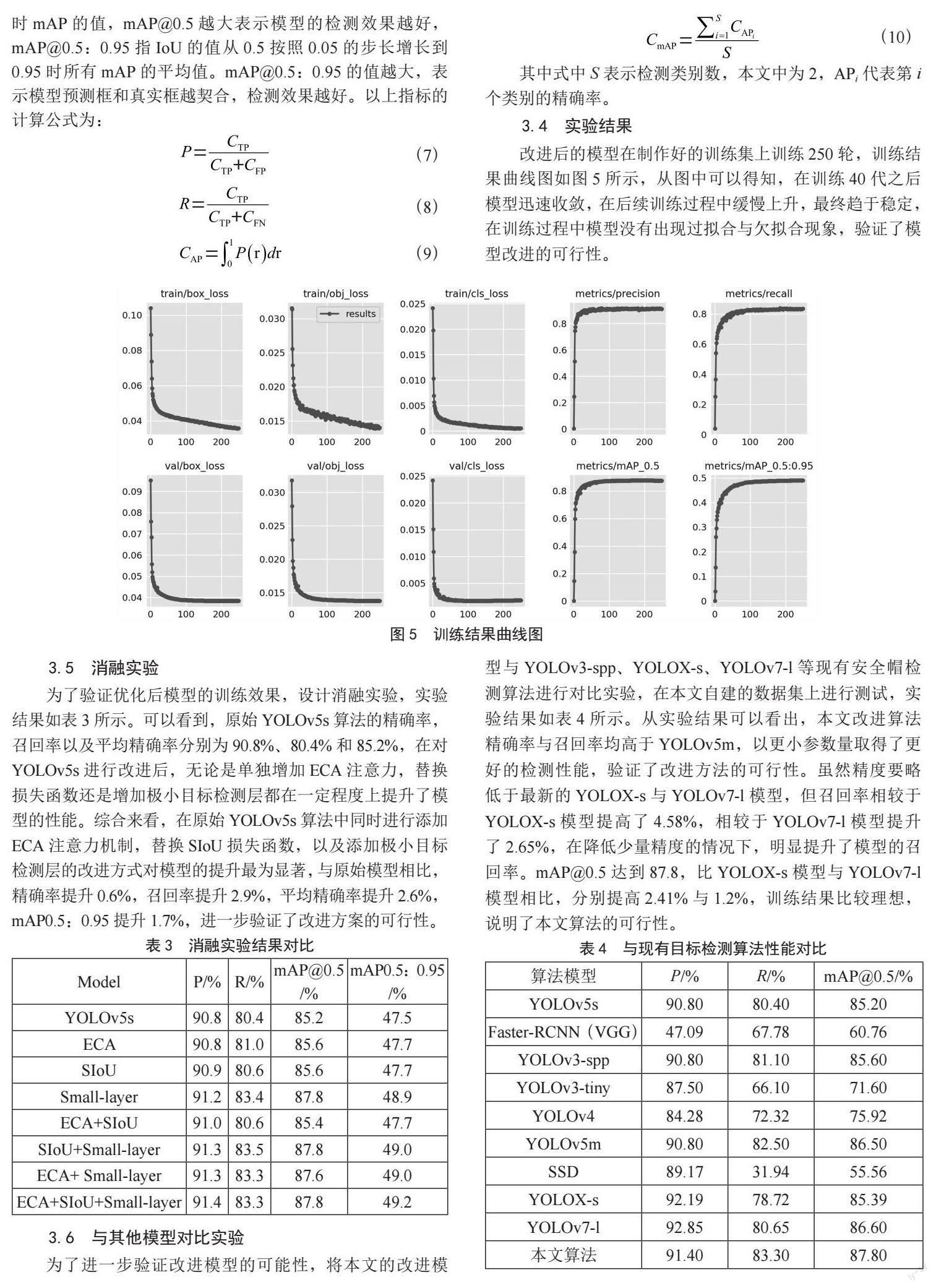
3.4 实验结果
改进后的模型在制作好的训练集上训练250轮,训练结果曲线图如图5所示,从图中可以得知,在训练40代之后模型迅速收敛,在后续训练过程中缓慢上升,最终趋于稳定,在训练过程中模型没有出现过拟合与欠拟合现象,验证了模型改进的可行性。
3.5 消融实验
为了验证优化后模型的训练效果,设计消融实验,实验结果如表3所示。可以看到,原始YOLOv5s算法的精确率,召回率以及平均精确率分别为90.8%、80.4%和85.2%,在对YOLOv5s进行改进后,无论是单独增加ECA注意力,替换损失函数还是增加极小目标检测层都在一定程度上提升了模型的性能。综合来看,在原始YOLOv5s算法中同时进行添加ECA注意力机制,替换SIoU损失函数,以及添加极小目标检测层的改进方式对模型的提升最为显著,与原始模型相比,精确率提升0.6%,召回率提升2.9%,平均精确率提升2.6%,mAP0.5:0.95提升1.7%,进一步验证了改进方案的可行性。
3.6 与其他模型对比实验
为了进一步验证改进模型的可能性,将本文的改进模型与YOLOv3-spp、YOLOX-s、YOLOv7-l等现有安全帽检测算法进行对比实验,在本文自建的数据集上进行测试,实验结果如表4所示。从实验结果可以看出,本文改进算法精确率与召回率均高于YOLOv5m,以更小参数量取得了更好的检测性能,验证了改进方法的可行性。虽然精度要略低于最新的YOLOX-s与YOLOv7-l模型,但召回率相较于YOLOX-s模型提高了4.58%,相较于YOLOv7-l模型提升了2.65%,在降低少量精度的情况下,明显提升了模型的召回率。mAP@0.5达到87.8,比YOLOX-s模型与YOLOv7-l模型相比,分别提高2.41%与1.2%,训练结果比较理想,说明了本文算法的可行性。
3.7 检测结果对比
为了验证改进模型的实际检测效果,设计改进模型与原始YOLOv5s的检测对比实验,实验结果如图6和图7所示。
可以看到,在图6(a)中最左侧的未佩戴安全帽的工人并没有被模型检测出来,出现了漏检,本文的改进模型成功将其检测出来,并分类正确。在图7(a)中,手抬钢板的六名工人只有四名工人被成功检测出来,另外两名没被检测出来的工人因为出现遮挡,并且安全帽颜色与钢板颜色相近而被模型漏检,本文的改进模型将六名工人全部成功检测且置信度高于原始模型,原始YOLOv5s右侧远处的小目标全部漏检,本文的改进算法成功检测出两人。以上结果表明本文的改进模型对于密集场景与小目标检测场景下泛化能力更強。
4 结 论
针对现有安全帽检测算法在密集场景与小目标场景下检测效果不佳的情况,本文在YOLOv5s算法的基础上进行改进,引入高效注意力模块ECA,优化边界框损失函数,改进特征融合方式并增加小目标检测层,与原始算法相比减少了漏检情况,提高了分类置信度得分,并得到更高的平均精确率。与原始算法相比,本文改进算法更适用于实际施工现场中密集目标与小目标的检测,提升了安全帽监管的可靠性。但是,本文仍然存在一些缺陷,参数量与计算量与原算法相比均有增加,增大了显存与内存开销。在后续实验的重点是对模型进行压缩枝剪,获得更轻量化的结构减少模型对算力的需求。
参考文献:
[1] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once: Unified,Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vegas:IEEE,2016:779-788.
[2] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:580-587.
[3] 吴冬梅,王慧,李佳.基于改进Faster RCNN的安全帽检测及身份识别 [J].信息技术与信息化,2020(1):17-20.
[4] LIU W,ANGUELOV D,ERHAN D,et al. SSD: Single Shot MultiBox Detector [J/OL].arXiv:1512.02325 [cs.CV].(2015-12-08).https://arxiv.org/abs/1512.02325.
[5] 李明山,韩清鹏,张天宇,等.改进SSD的安全帽检测方法 [J].计算机工程与应用,2021,57(8):192-197.
[6] 徐传运,袁含香,李刚,等.使用场景增强的安全帽佩戴检测方法研究 [J].计算机工程与应用,2022,58(19):326-332.
[7] 王玲敏,段军,辛立伟.引入注意力机制的YOLOv5安全帽佩戴检测方法 [J].计算机工程与应用,2022,58(9):303-312.
[8] WANG Q L,WU B G,ZHU P F,et al. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks [J/OL].arXiv:1910.03151 [cs.CV].(2019-10-08).https://arxiv.org/abs/1910.03151v1.
[9] 杨真真,郑艺欣,邵静,等.基于改进路径聚合和池化YOLOv4的目标检测 [J].南京邮电大学学报:自然科学版,2022,42(5):1-7.
[10] 伏德粟,高林,劉威,等.基于改进YOLOv5算法的电力工人作业安全关键装备检测 [J].湖北民族大学学报:自然科学版,2022,40(3):320-327.
[11] 许锁鹏,卢健,许心怡,等.基于YOLOv5的安全帽佩戴检测系统设计 [J].黑龙江科学,2022,13(22):49-51.
作者简介:李达(1998—),男,汉族,湖南邵阳人,硕士研究生在读,研究方向:图像处理、计算机视觉;通讯作者:刘辉(1964—),女,汉族,湖南常德人,副教授,硕士,研究方向:图像处理、目标检测、计算机视觉。
