
基于Transformer的车辆年款细粒度识别研究
2023-06-21 20:10徐天适文莉张华俊
现代信息科技 2023年1期
关键词:视频监控
徐天适 文莉 张华俊


摘 要:视频监控场景下车辆年款信息抽取对城市数智化治理有着重要意义。为实现细粒度车辆年款的精准识别,首先,构建了覆盖多元采集条件及常见车辆年款的百万级场景数据集;其次,提出了基于Transformer的车辆年款细粒度特征高效提取器;最后,结合任务特点设计了层次标签多任务联合学习方法,获得兼容全局与局部的高鲁棒性特征。实验结果表明,提出的方法在场景数据集上的Top-1准确率达到95.79%,相较基于CNN的单任务方法有大幅提升。
关键词:视频监控;车辆年款识别;细粒度分类;vision transformer
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2023)01-0075-05
Research on Fine-Grained Recognition of Vehicle Model Year Based on Transformer
XU Tianshi, WEN Li, ZHANG Huajun
(GRGBanking Equipment Co., Ltd., Guangzhou 510663, China)
Abstract: Vehicle model year information extraction in video surveillance scenes is of great significance for urban digital intelligent governance. In order to achieve accurate identification of fine-grained vehicle model year, firstly, a mega scene dataset covering multiple collection conditions and common vehicle model year is constructed; secondly, an efficient fine-grained feature extractor of vehicle model year based on Transformer is proposed; finally, a hierarchical label multi task joint learning method is designed based on task characteristics to obtain high robustness features compatible with global and local features. The experimental results show that the Top-1 accuracy of the proposed method on the scene dataset reaches 95.79%, which is significantly improved compared with the single task method based on CNNs.
Keywords: video surveillance; vehicle model year recognition; fine-grained classification; vision transformer
0 引 言
車辆年款细粒度识别解析出了品牌、车系、年款等车辆关键信息,是城市数智化治理中交通调度、违法追溯、治安管理、智慧停车等重要业务的智能决策基础。城市中常见车辆有3 000款以上,并以每年近50款的速度不断新增。然而,同一车系的相近年款仅在车灯、雾灯、前脸格栅等部件细节存在差异,区分度低;同一年款的不同车辆受成像设备、角度、光照、遮挡以及车身颜色、改装等因素影响,差异明显,均对车辆年款的大规模细粒度分类技术提出了更高要求。
传统车辆年款识别算法基于手工设计特征(SIFT、LBP、HOG等),将单个或者多个特征编码后得到特征向量,输入分类器(SVM、Adaboost、随机森林等)得到分类结果[1],这类方法的特征描述能力有限,性能依赖于手工设计特征的可靠性及参数选择的合理性[2],泛化能力差[3],只能处理粗粒度小规模的车辆年款分类问题。
2012年以来,基于深度神经网络方法的迅速发展,提出了AlexNet、ResNet[4]、Mobilenet[5]、RepVgg[6]等网络新结构,推动图像分类任务不断取得突破。ImageNet数据集上Top-1的准确率也从62.5%上升到了82.7%[7]。WANG等[8]以AlexNet、GoogleNet及ResNet三种经典深度卷积神经网络架构作为基础网络,将CNN方法引入到年款分类任务中。Yang[9]等在此基础上结合车辆区域定位及局部关键差异的问题,提出基于区域建议网络的细粒度识别方法,并成功应用于细粒度年款识别。
近两年Vision Transformer取得了巨大进展,DeiT[10]、ViT[11]等方法使得Transformer在CV领域大放异彩。针对ViT的方法在尺度统一和样本分辨率等方面的难题,LIU[12]等人提出了Swin Transformer的方法,构建了层次化Transformer结构,作为通用视觉骨干网络,提升了图像分类、目标检测和语义分割等任务的效果。
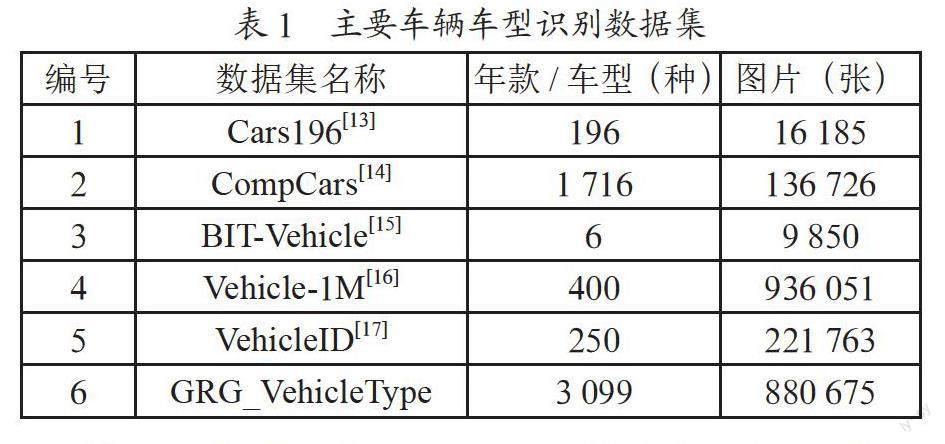
细粒度年款识别的另一个关键任务是场景数据集的构建。为有效地训练和评估大规模细粒度条件下的算法的性能,研究人员构建了多个包含大量车辆图像的公开数据集,如斯坦福Cars-196[13]、CompCars[14]、BIT-Vehicles[15]、Vehicle1M[16]、VehicleID[17]数据集等,但由于采集地点、采集条件、采集时长等条件限制导致数据集场景欠缺丰富性,车辆年款类型少,对现实场景拟合不佳。
针对上述应用场景中的现实难题,本文从数据集构建、细粒度车辆年款识别方法及对比实验三个方面开展工作。
首先,构建了业内领先的车辆细粒度年款识别场景数据集,样本覆盖了城市中的主要车辆年款,通过自建视频监控采集系统,采集了不同角度、光照、遮挡条件下的车辆样本。
其次,提出了一种基于Transformer结构的车辆年款细粒度分类算法,Swin-Based Multi-Task Fine-Grained Vehicle Types Identification(SwinMTFI)。
最后,在公开及私有数据集上对主干网络以及组件进行对比实验,验证基于Transformer的细粒度年款分类算法效果。
实验结果表明,本文提出的SwinMTFI方法无论是在Vehicle1M还是GRG_VehicleType数据集上表现均取得了明显提升。其中基于Swin-L骨干网络,在GRG_VehicleType数据集上Top1准确率达到99.25%,相较于ResNet50的CNN方法取得5.16%的提升。引入多任务机制后,基于Swin-T骨干网络的Top1准确率提升了0.62%,在進一步提升模型性能的同时,复用骨干网络参数,减少算力占用。SwinMTFI方法无论是在识别精度还是对大角度、低区分度车辆年款均取得了较好的识别结果。
1 车辆年款细粒度识别算法
1.1 GRG_VehicleType数据集
当前城市中常见的车辆年款有3 000余种,由于采集地点、采集条件、采集时长的限制,导致数据集场景欠缺丰富性,车辆年款类别少,对现实场景拟合不佳。如表1所示,开源数据集中CompCars[14]中包含1 716种年款,平均每个年款图片数不到80张,场景多样性难以保证。数据集Vehicle-1M[16]包含近百万样本,但年款数仅400种,很难覆盖城市中常见车辆年款。
针对上述问题,本文构建了车辆细粒度分类场景数据集GRG_VehicleType,包含前向年款类别3 099种,后向年款类别2 259种,共计880 675张,平均每个朝向的年款包含样本数大于180张。如图1所示,数据集中样本均为从全图中切割出来的车辆区域,样本统一存储在Image文件夹中。为了更充分记录车辆年款信息,GRG_VehicleType数据集构建了以品牌标签、车系标签、年款标签共同组成的字典表,并形成了如图2所示的三级标签体系,为后续在多标签多任务学习及车辆重识别领域的拓展预留空间。
GRG_VehicleType数据集整体制作流程如图3所示,数据集包含三种数据源:(1)开源数据集;(2)网络爬虫;(3)园区场景监控采集的私有数据。为保证数据集构建过程中对现实场景的鲁棒性,首先利用专业汽车网站建立基准年款库,并形成参考图;其次,将部分开源数据集进行抽取组合,并加入私有数据形成新数据集,以参考图为基准人工核验类别;最后,为了增加样本均衡性,减少低质量样本对训练过程的影响,剔除样本量20张以下的样本类别,对含200张样本以上的高频类别进行随机采样,使得这些类别最终样本数在200张以内。
1.2 基于Swin Transformer的特征提取器
Swin Transformer[12]是一种层次化表达的Vision Transformer(ViT)方法,在车辆年款细粒度识别任务中有着独特优势。车辆年款种类繁多且不断新增,细粒度识别难度很高;区分相似年款主要依靠车辆部件上的细节特征,反之通过车辆整体外形特征即可。例如,同一车系年份相近的两款车可能只在雾灯、前格栅镀铬、是否有天窗等细节特征上有一定区分度,需要特征提取网络具有聚合不同位置细粒度特征能力;同年款车辆在样本采集角度、车身颜色、车窗特征等全局特征上存在较大差异,需要特征提取网络在高水平的全局特征提取能力。此外,部分显著的外观特征不能用于区分车辆年款,例如车身颜色、车窗特征等,反而会对识别带来明显的干扰。
如图4所示的基于Swin Transformer的特征提取器可以很好地克服上述困难:借助多头注意力机制带来强大特征表达能力,克服基于卷积方法的局限性约束,汇集来自图像任意位置的有效信息;使用移动窗口构建ViT的输入序列,在窗口内计算多头自注意力(W-MSA),大幅降低了序列的长度,提升网络效率;引入移窗操作(Shifted)实现了移位窗口多头自注意力(SW-MSA),使得相邻窗口间可以进行信息交互,形成层次化的特征表达,提升了全局特征表达能力。
首先将输入H×W×3的RGB图像通过拆分模块(Patch Partition),拆分为非重叠等尺寸的图像块,形成输入序列。线性嵌入层将维度为(H/4×W/4)×48的张量投影到任意维度C,得到维度为(H/4×W/4)×C的线性嵌入。输入张量到Swin Transformer Blocks,如图5所示。Swin Transformer模块由一个两层的带有多层感知机(MLP)的非重叠局部窗口多头自注意力模块(W-MSA)和移位窗口多头自注意力模块(SW-MSA)的组合组成。在每个MSA模块和每个MLP之前均使用归一化层(LN),并在每个MSA和MLP之后使用残差连接。
这里将线性嵌入层与Swin Transformer模块的组合称第一个处理阶段(Stage1)。随着网络的加深,图像块序列逐渐通过块合并模块(Patch Merging)减少。块合并模块拼接了相邻图像块,使得序列长度变为缩短至1/4,维度则扩大成2C。使用Swin Transformer模块进行特征转换,其分辨率保持不变。这样的合并模块(Patch Merging)和Swin Transformer模块的组合重复三次,称为骨干网络的处理阶段二(Stage2)到阶段四(Stage4)。
上述基准网络结构称为Swin-B(Base),为了应对不同场景对精度及速度的要求,根据不同模型的尺寸及计算复杂度,衍生出了其他系列结构,包括Swin-T(Tiny)、Swin-S(Small)、Swin-L(Large),計算复杂度与模型尺寸分别是Swin-B的0.25、0.5及2.0倍。
本节结合细粒度车辆年款识别任务特点,设计基于Swin Transformer特征提取器,使得网络能够实现兼顾全局特征与局部特征抽取,在解决大尺度变化车辆目标特征抽取问题的同时,降低了ViT网络的计算量,从而实现高精度的细粒度车辆年款识别。
1.3 层次标签联合学习的车辆年款细粒度分类
细粒度年款识别任务需结合车辆的全局特征与局部部件特征以提高细粒度识别的准确率,引入了车辆的品牌、车系信息结合车辆年款标签,构建3类任务的多任务学习的网络,可以有效地将车辆品牌、车系、年款之间的语义级别关联,得到从局部到全局的监督变量。通过多任务的联合学习,在保持较高识别效率同时,实现最终联合识别准确率相比各自单任务学习时的提升。
本文所提出的多任务细粒度车型识别网络利用Swin Transformer作为特征提取器,提取高鲁棒性分类特征;提出结合了车辆品牌、车系、年款细粒度分类的多任务损失函数:
Losstask=λ1Lossyear+λ2Lossseries+λ3Lossbrand
其中,Lossyear为年款损失,Lossseries为车系损失,Lossbrand为品牌损失,均为交叉熵损失函数,其中λ1=0.6,λ2=0.2,λ3=0.2。通过权重设置,将车辆年款分类任务作为主任务,而品牌、车系分类作为两个独立的辅助任务,为细粒度年款识别任务提供更多信息,从而达到正则化的效果。三个任务之间相互促进,共同为其共享的特征部分提供梯度信息。
2 实验分析
本文实验基于Vehicle1M与本文提出的GRG_VehicleType数据集进行训练与测试。其中,数据集70%作为训练数据,剩余全部作为验证数据。
2.1 配置说明
数据方面,图片尺寸统一为224×224;数据增广默认开启随机水平翻转、随机擦除[18]。预处理采用ImageNet数据集[19]的均值和标准差进行归一化。
模型训练方面,训练环境为单台8张A100显卡GPU服务器,根据任务差异分别训练10至15个Epoch,BatchSize统一设置为32。CNN方法的基准学习率设置为0.01,采用Step的方式(gamma=0.1)调整学习率,如图6(a)所示,采用SGD进行优化;提出的SwinMTFI方法,基准学习率设置为0.000 05,采用CosineAnnealing方法结合Warmup策略调整学习率曲线,如图6(b)所示,采用AdamW进行优化。所有模型均采用ImageNet预训练权值。
2.2 整体性能对比
首先对骨干网络进行基准测试,如表2所示,基于SwinTransformer方法与ResNet50[4]、CSPDarkNet[20]等典型CNN方法相比,计算复杂度、参数量更高,对比Mobilenetv2[5]等轻量化网络差距更是明显。Swin-T的方法与ResNet50在参数量、计算量、训练时长、推理速度等方面,均处于相近的水平,可以在进一步的实验中可以作为重点对比指标。
图7对比了Mobilenetv2、ResNet50、Swin-B、Swin-T四种代表性骨干网络训练过程,图7(a)中基于CNN的方法在第4个Epoch就基本达到收敛状态,本文提出的SwinMTFI算法在第14个Epoch时训练损失值的震荡幅度较大,且整体继续呈现出缓慢下降的趋势,可见Swin-Based方法收敛难度更高,需要更长的训练周期。从性能看,SwinMTFI在Top1准确率方面优势明显,如图7(b)所示,Swin-Based方法对比CNN-Based方法最高实现了5.76%的提升。
2.3 单任务性能分析
分别在Vehicle1M、GRG_VehicleType数据集上进行单标签任务实验,结果如表3、表4所示。Vehicle1M数据集包含近百万样本及400个类别,是公开数据集中数据量大且类别较多的车辆识别数据集。与Vehicle1M相比,GRG_VehicleType数据集复杂程度更高,任务难度更大,以ResNet50为例,在Vehicle1M数据集准确率为96.43%,在GRG_VehicleType数据集上仅能达到90.63%。SwinMTFI方法中基于Swin Transformer的特征提取器带来了明显性能提升,例如,Swin-L在Vehicle1M数据集上Top1准确率达到99.25%,接近了Top5准确率,基本达到任务极限;基于Swin-T与ResNet50相比在GRG_VehicleType数据集上提升了4.13%,在细粒度识别任务上的具有明显优势。
2.4 多任务性能分析
在GRG_VehicleType数据集上进行了多标签对比实验。实验结果证明,提出的层次标签联合学习的车辆年款细粒度分类方法对于无论是CNN方法还是ViT的方法均取得了明显性能提升,且保持推理阶段的计算量及计算速度不变。如表5所示,ResNet50骨干网络多任务学习取得Top1准确率91.67%,单任务为90.63%,提升1.04%;Swin-T单任务精度为94.76%,多任务精度为95.38%,提升了0.62%。实验中,基于Swin-B的SwinMTFI方法比基于Swin-L方法在多任务学习后精度略高0.01%,多任务的Swin-T与单任务的Swin-B方法精度相近,在保持精度的同时大幅降低的所需的计算量。实验结果进一步证明了引入的Swin Transformer骨干网络及层次标签联合学习方法对细粒度车辆年款识别任务的适用性。
3 结 论
针对视频监控场景的车辆年款细粒度识别难题,本文首先构建了一个样本覆盖了城市中不同角度、光照、遮挡等采集条件下的常见车辆年款的百万级车辆细粒度年款识别场景數据集GRG_VehicleType。其次,提出了SwinMTFI算法,将Transformer的多头自注意力机制与细粒度分类任务结合,获得兼容全局与局部的高鲁棒性特征;最后,设计了层次标签联合学习的车辆年款细粒度分类方法,结合车辆的全局特征与局部部件特征进一步提高细粒度识别的准确率,从而满足了现实应用的要求。在未来的研究中,我们会在场景数据集和模型推理加速等方面进行进一步的探索,以期达到更好的效果。
参考文献:
[1] XIANG L D,WANG X Y. Vehicle classification algorithm based on DCNN features and ensemble learning [J/OL].[2022-08-18].http://en.cnki.com.cn/Article_en/CJFDTotal-SJSJ202006020.htm.
[2] CSURKA G,DANCE C R,FAN L X,et al. Visual categorization with bags of keypoints [C]//Workshop on statistical learning in computer vision, ECCV. 2004, 1(1-22): 1-2.[2022-08-18].https://www.researchgate.net/publication/228602850_Visual_categorization_with_bags_of_keypoints.
[3] LIU X C,LIU W,MA HD,et al. Large-scale vehicle re-identification in urban surveillance videos [C]//2016 IEEE international conference on multimedia and expo (ICME).Seattle:IEEE,2016:1-6.
[4] HE K M,ZHANG X Y,REN SQ,et al. Deep residual learning for image recognition [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vegas:IEEE,2016:770-778.
[5] SANDLER M,HOWARD A,ZHU M L,et al. Mobilenetv2: Inverted residuals and linear bottlenecks [C]//2018 IEEE/CVFConference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:4510-4520.
[6] DING X H,ZHANG X Y,MA N N,et al. RepVGG: Making VGG-style ConvNetsGreat Again [C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Nashville:IEEE,2021:13733-13742.
[7] HE T,ZHANG Z,ZHANG H,et al. Bag of Tricks for Image Classification with Convolutional Neural Networks [C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Long Beach:IEEE,2019:558-567.
[8] WANG H Y,TANG J,SHEN Z H,et al. Multitask Fine-Grained Vehicle Identification Based on Deep Convolutional Neural Networks [J].Journal of Graphics,2018,39(3):485-492.
[9] YANG J,CAO H Y,WANG R G,et al. Fine-grained car recognition method based on region proposal networks [J].Journal of Image and Graphics,2018,23(6):837-845.
[10] TOUVRON H,CORD M,DOUZE M,et al. Training data-efficient image transformers & distillation through attention [EB/OL].[2022-08-19].https://www.xueshufan.com/publication/3170874841.
[11] DOSOVITSKIY A,BEYER L,KOLESNIKOV A,et al. An image is worth 16x16 words: Transformers for image recognition at scale [EB/OL].[2022-08-06].https://www.xueshufan.com/publication/3119786062.
[12] LIU Z,LIN Y T,CAO Y,et al. Swin transformer: Hierarchical vision transformer using shifted windows [C]//2021 IEEE/CVF International Conference on Computer Vision(ICCV).Montreal:IEEE,2021:10012-10022.
[13] KRAUSE J,STARK M,DENG J,et al. 3d object representations for fine-grained categorization [C]//2013 IEEE international conference on computer vision workshops.Sydney:IEEE,2013:554-561.
[14] YANG L J,LUO P,LOY C C,et al. A large-scale car dataset for fine-grained categorization and verification [C]//2015 IEEE conference on computer vision and pattern recognition(CVPR).Boston:IEEE,2015:3973-3981.
[15] DONG Z,WU Y W,PEI M T,et al. Vehicle type classification using a semisupervised convolutional neural network [J].IEEE transactions on intelligent transportation systems,2015,16(4):2247-2256.
[16] GUO H Y,ZHAO C Y,LIU Z W,et al. Learning coarse-to-fine structured feature embedding for vehicle re-identification [EB/OL].[2022-08-08].https://dl.acm.org/doi/abs/10.5555/3504035.3504874.
[17] LIU H Y,TIAN Y H,WANG Y W,et al. Deep relative distance learning: Tell the difference between similar vehicles [C]//2016 IEEE conference on computer vision and pattern recognition(CVPR).Las Vegas:IEEE,2016:2167-2175.
[18] ZHONG Z,ZHENG L,KANG G L,et al. Random erasing data augmentation [J/OL].arXiv:1708.04896 [cs.CV].[2022-08-02].https://arxiv.org/abs/1708.04896.
[19] DENG J,DONG W,SOCHER R,et al. Imagenet: A large-scale hierarchical image database [C]//2009 IEEE conference on computer vision and pattern recognition.Miami:IEEE,2009:248-255.
[20] BOCHKOVSKIY A,WANG C Y,LIAO H Y M. Yolov4: Optimal Speed and Accuracy of Object Detection [J/OL].arXiv:2004.10934 [cs.CV][2022-08-08].https://arxiv.org/abs/2004.10934.
作者簡介:徐天适(1990—),男,汉族,江西瑞昌人,技术经理,硕士研究生,研究方向:计算机视觉、人工智能系统。
收稿日期:2022-08-31
基金项目:广州市科技计划项目(202206030001)
猜你喜欢
软件导刊(2016年12期)2017-01-21
现代电子技术(2016年24期)2017-01-19
中国新通信(2016年21期)2017-01-06
电脑知识与技术(2016年28期)2016-12-21
电子技术与软件工程(2016年20期)2016-12-21
电脑知识与技术(2016年26期)2016-11-24
电脑知识与技术(2016年24期)2016-11-14
数字技术与应用(2016年9期)2016-11-09
