
基于手机加速度异常极值处理的步态身份识别
2023-06-21 01:58陈志强苗敏敏胡文军
智能计算机与应用 2023年6期
陈志强, 苗敏敏,2, 胡文军,2
(1 湖州师范学院信息工程学院, 浙江湖州 313000;2 浙江省现代农业资源智慧管理与应用研究重点实验室, 浙江湖州 313000)
0 引 言
近年来,智能设备已成为日常必需品,人们每天都在依赖智能设备来完成日常生活中的各种任务,因此对智能手机的安全问题也越来越重视[1-2]。 移动智能设备最广泛使用的身份识别技术主要分为3大类:第一类是基于PIN、密码[3]的识别方式,这种方式的缺点是密码容易被遗忘和泄露;第二类是基于人脸、指纹以及虹膜等生物特征[4]的识别方式,这种方式要求被监测对象必须近距离获取信息,同时需要高昂的手机成本;第三类方法是基于三维手势、步态等行为习惯特征[5]的识别方式,该方式具有改变困难、模仿困难等优点,其步态识别是唯一一个在远距离非接触情况下,也能正确识别身份的一种行为习惯特征。 如今大多数智能手机都配备了许多内置传感器,例如加速度、陀螺仪等。 这些传感器支持隐式身份识别技术,能从传感器中捕捉到用户的行为特征。 孔菁等人[6]提出采用坐标轴转换算法,让基准坐标系和惯性坐标系重合,提取特征后使用支持向量机算法进行分类识别,识别准确率达到95.5%。 Sun 等人[7]提出一种速度自适应步态周期分割方法和个性化阈值生成方法,与基于固定步行速度和恒定阈值的最新技术相比,用户身份识别准确率提高了21.5%。 Hoang Minh Thang 等人[8]采用时域和频域进行实验,采用支持向量机对提取的特征进行分类识别,得到的准确率分别为79.1%和92.7%。胡春生等人[9]通过对数据进行特征提取和数据权重分析,构建BP 神经网络进行训练和匹配识别实验,准确率可达96.67%。 王彬等人[10]建立了步频分布的特征模型,利用相对熵判别用户身份,识别准确率达到86%。
由于经过滤波后加速度信号中仍然存在小范围的异常极值,为进一步提高识别的准确率,本文提出一种基于四分位数去除异常极值的算法,并采用公用数据集以及自行采集的数据集分别对所提算法进行实验。 实验结果表明,在两个数据集上使用本文提出的算法后,准确率均得到提高。
1 公开数据集身份识别方案的设计
1.1 数据获取
采用福坦莫大学无线数据挖掘实验室所提供的公开步态数据集[11]进行实验。 该数据集利用手机加速度传感器采集了36 个不同受试者的步行、慢跑、静坐、站立、上楼和下楼6 种步态,采样频率为20 HZ。采集过程中手机放在大腿的便携包里,Z轴指向为前进方向。 通过文献[12]发现重力方向上的加速度信号比其他两个方向上的信号更稳定。 因此,本文重点分析重力方向的加速度信号,即Y轴。
为保证实验数据充足,在6 种步态中选取步态为步行,且采样点大于3 000 的时间序列作为实验数据(某个时间序列代表在某一连续时间内采集到的步态加速度数据),共得到57 个步行时间序列。在各时间序列中分别选取连续的2 000 个采样点进行实验,其中前1 200个采样点作为训练数据,后800个采样点作为测试数据。
由于受试者在步行过程中,并未始终处在稳定步行状态,此时采集到的数据不是步行的真实数据。针对这一现象,本文提出一种基于波峰和波谷方差之和的最小值方法来自适应截取数据。 以窗口大小为2 000,步长为400 进行滑窗操作,计算Y轴方向上各窗口内所有波峰值与波谷值的方差,选取波峰方差与波谷方差之和最小的窗口作为实验数据。 某步行时间序列各个窗口波峰方差与波谷方差之和统计如图1 所示。 从图中可以看到,在1 600-3 600范围内的数据方差之和最小,表示该范围内的数据较为平稳,因此将该段数据选为稳定步行数据进行实验。

图1 时间序列选择Fig. 1 Time series selection
1.2 数据预处理
采用Savitzky-Golay 滤波[13]方法对数据进行两次平滑处理,两次平滑窗口分别为7 和5。 考虑到滤波之后仍然会有一些异常极值,因此本文提出一种基于四分位数[14]去除异常极值的算法来提高识别准确率。
四分位数分为下边缘、下四分位数、中位数、上四分位数和上边缘。 其中,下四分位数位置记为Q1,中位数位置记为Q2,上四分位数位置记为Q3。
最小估计值公式:
最大估计值公式:
其中,k表示异常值检测因子,设定为1.5。
当数值大于最大估计值或小于最小估计值时都记为异常值。 异常极值去除算法实现步骤如下:
(1)计算信号的所有极大值点,计算如公式(3):
其中,xi表示当前时刻的采样点,xi-1和xi+1分别是前一时刻和下一时刻的采样点。
(2)使用公式(1)、公式(2)计算所有极大值的最小估计值和最大估计值,若满足公式(4),则被确定为异常极大值。
其中,pi为信号的极大值。
(3)将异常极大值点前一个极大值点到后一个极大值点之间的采样点删除,其余两轴使用与该轴数据相同的起始与结束位置进行删除,以保证删除后的三轴数据在时间上一一对应。
(4)计算去除异常极大值后信号的所有极小值点,使用公式(1)、公式(2)计算所有极小值的最小估计值和最大估计值。 若满足公式(5),则被确定为异常极小值。
其中,vi为信号的极小值。
(5)将异常极小值点前一个极小值点到后一个极小值点之间的采样点删除,其余两轴使用与该轴数据相同的起始与结束位置进行删除,以保证删除后的三轴数据在时间上一一对应。 得到去除异常极值后的信号。
各步行时间序列的异常波峰箱线与波谷箱线如图2 所示。 去除异常波峰与波谷后的对比图如图3所示,图3(a)和图3(b)分别表示处理前和处理后的波形图,可以看出使用所提算法后,异常极值已被有效去除。
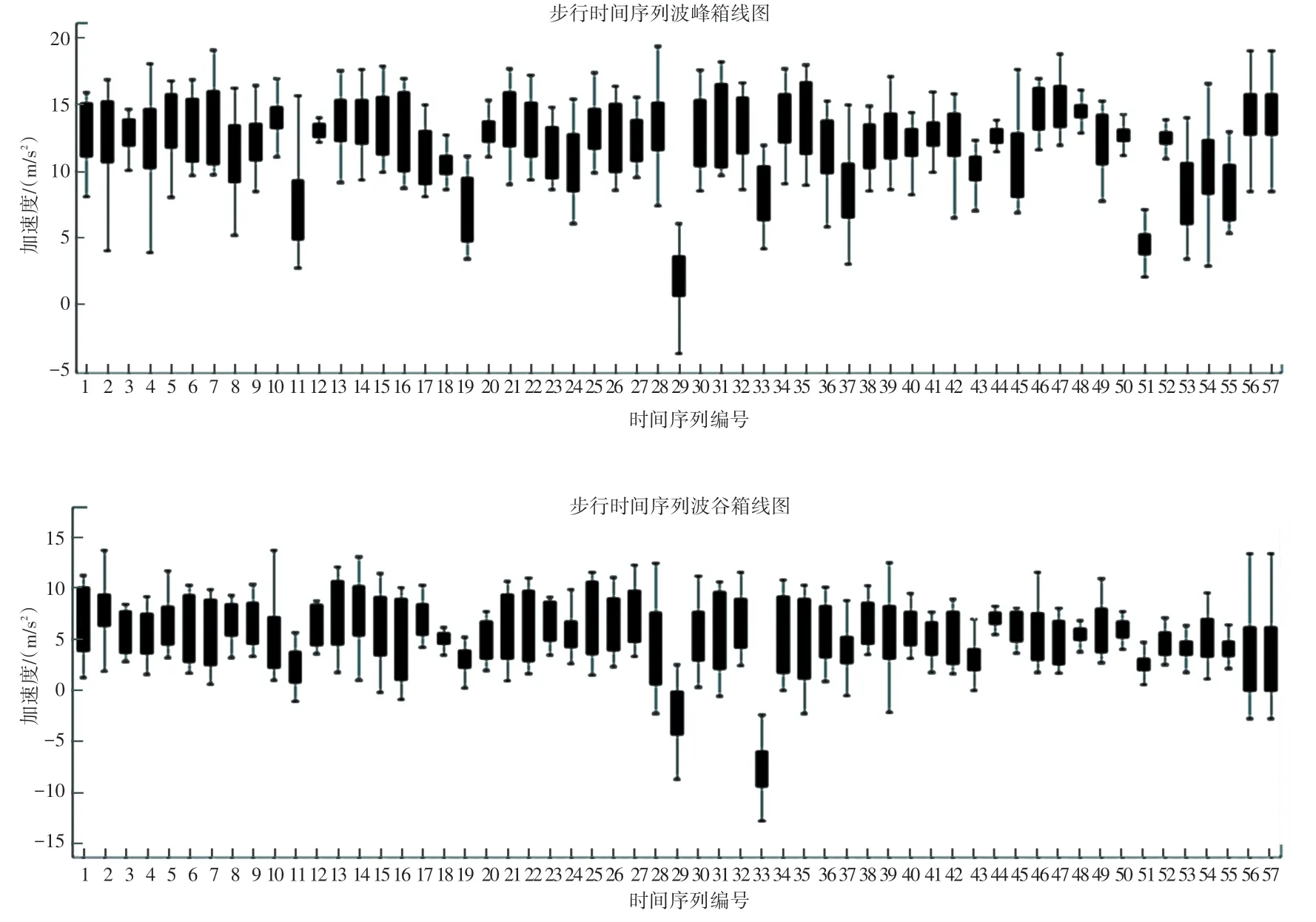
图2 各步行时间序列的异常波峰箱线图与波谷箱线图Fig. 2 Abnormal wave peak and trough boxplots of each walking time series
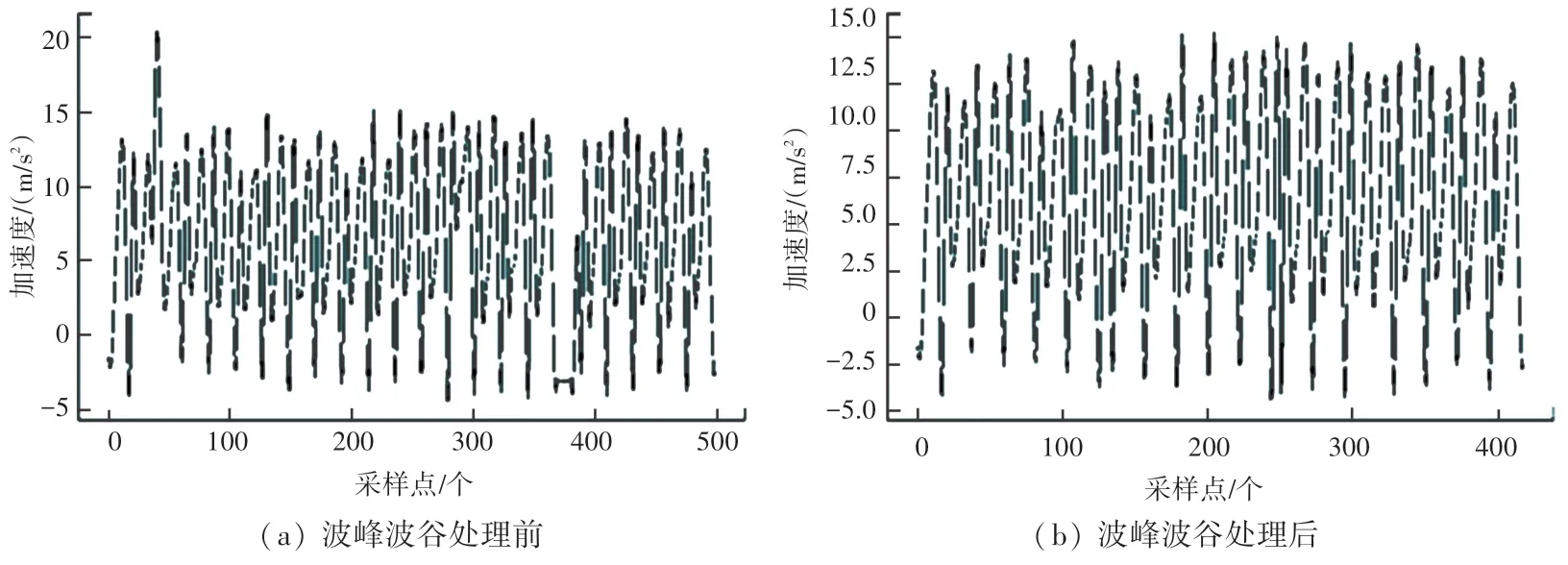
图3 去除异常波峰与波谷前后加速度信号对比Fig. 3 Comparison of acceleration signal before and after removing abnormal wave peak and trough
1.3 模板划分
以每8s 的步行数据作为步行模板。 由于采样频率为20 Hz,因此一个步行模板包含160 个采样点。 统计步行时间序列中Y轴方向上加速度数据的波峰位置信息,以每个波峰位置作为起始点,后160个采样点作为步行模板。
为了得到更多的步行模板,当正向截取结束后,再从最后一个波峰位置开始逆向截取,X轴与Z轴使用与Y轴的波峰位置进行数据截取。 模板截取如图4 所示。

图4 模板截取Fig. 4 Template to intercept
1.4 特征提取
根据文献[15-17],从时域和频域两方面对步态模板进行特征提取。 下面描述这些特征,括号中注明的是每个特征类型生成的特征数量。
(1)时域特征
平均值(3):X轴、Y轴、Z轴的平均值。
标准差(3):X轴、Y轴、Z轴的标准差。
相关系数(3):X轴和Y轴、X轴和Z轴、Y轴和Z轴的相关系数。
三轴加速度合成标量最大值(1):X轴、Y轴、Z轴加速度平方和的平方根的最大值。
M为三轴加速度合成标量最大值,计算公式如式(6):
波峰平均值(3):X轴、Y轴、Z轴所有波峰的平均值。
波谷平均值(3):X轴、Y轴、Z轴所有波谷的平均值。
直方图(10):重力方向上的加速度轴(Y轴)数据中的最大值和最小值,相减的差除以10 的结果作为间隔,算出每个间隔里点的个数所占的百分比。
(2)频域特征
直流分量(3):X轴、Y轴、Z轴经快速傅里叶变换后频率为0 的分量。
1.5 级联森林模型
级联森林是深度森林的一部分[18],每个级联层包括两个随机森林和两个完全随机森林,每个决策器包含100 棵决策树。 完全随机森林中,每棵树随机选择一个特征作为分裂点,然后一直增长,直到每个叶子节点细分到只有一个类别或者不多于10 个样本。 随机森林中,每棵树选取个特征(n为特征维度),再通过gini 系数[19]筛选分裂节点。 级联森林分类原理如图5 所示。

图5 级联森林Fig. 5 Cascade forest
首先,将样本特征提取后的29 维特征分别输入两个随机森林和两个完全随机森林中,每个森林得到一个36 维概率类向量,将4 个36 维类向量与原始特征拼接成一个173 维数据,并作为下一层的输入,以此类推。 最后输出4 个36 维数据,将这4 个36 维数据中的每一维取平均值,得到一个新36 维数据,取36 维数据中结果最大的类别作为最终预测。
2 实验结果与分析
在各时间序列中分别选取连续的2 000 个采样点进行实验,其中前1 200 个采样点作为训练数据,后800 个采样点作为测试数据。 将训练集经过预处理、模板划分共得到14 050 个样本,对样本特征提取后进入模型训练。 测试集经过预处理、模板划分共得到8 651 个样本。
为了验证级联森林分类算法在身份识别中的有效性,分别使用支持向量机和BP 神经网络模型[9]进行对比。 其中,BP 神经网络输入层节点为29,隐藏层节点为30,输出层节点为36,得到一个29-30-36 的BP 神经网络模型。 同时为了验证本文提出的异常峰值去除算法的有效性,设计实验将未经算法处理的样本与经算法处理的样本在各识别分类算法中训练,在各分类算法中得到的准确率见表1。

表1 各分类算法准确率对比Tab. 1 Comparison of the accuracy of several classification algorithms
从表1 中可以看出,使用异常峰值去除算法后,各分类算法的准确率均有提高,平均提高了0.98%。从各分类算法可以看出,级联森林分类算法的准确率明显高于支持向量机和BP 神经网络,分类效果更佳;同时在运行时间方面(训练+测试)也表明了级联森林算法模型训练的高效率以及可扩展性。
3 实验验证
为了验证公开数据集实验方案的有效性,本文自行采集人体真实步行数据进行实验验证。 使用自行开发的手机APP 采集受试者行走时加速度传感器的数据,采样频率为14 Hz,使用一阶低通滤波器去除重力的影响。 在公开数据集中,手机放在大腿的便携包里,加速度传感器的Y轴平行于重力加速度方向,而在自采数据集中,手持手机行走时的加速度传感器的Z轴平行于重力加速度方向,如图6(a)所示。 因此,在验证实验中以Z轴数据为基准进行实验。

图6 实验采集场地和手持手机图Fig. 6 The site for collecting data and picture of handheld phone
所选的受试者均为在校本科生和研究生,身高为155~180 cm,体重45~80 kg,年龄20~25 岁。 本次实验共采集了11 名受试者的步行数据,要求受试者在走廊从规定的起始点步行至结束点,记为第一次步行实验数据name1,再从结束点步行至起始点,记为第二次步行实验数据name2。 如此反复,每名受试者采集5 次,采集到的数据以txt 文本文件记录,以“姓名+编号”命名,实验步行场景如图6(b)所示。 将每名受试者的5 次步行数据样本中,编号为1、2、3 的步行数据作为训练集,编号为4、5 的步行数据样本作为测试集。 由于每次步行数据的采样点在350-450 之间,因此以步长为30 且窗口为250选择有效数据段,将训练集选择后的数据以1.2 节的方法进行预处理,特征提取后使用分类算法训练。测试集数据使用与训练集数据同样的数据选择方式、预处理和特征提取操作,最后输入到模型中进行身份识别。
选择的训练样本数据和测试样本数据得到的结果可能存在偶然性,因此对5 次步行数据样本轮流选取3 次步行数据样本作为训练数据进行实验,剩余2 次步行数据作为测试数据,即=10 组。 使用支持向量机、BP 神经网络和级联森林分类算法在各样本组的准确率见表2。 其中,训练数据样本编号为1、2、3 在级联森林、支持向量机和BP 神经网络模型的混淆矩阵分别如图7(a)、图7(b)和图7(c)所示。

表2 三种分类算法在各样本组的准确率Tab. 2 The accuracy of three classification algorithms in various sample groups%
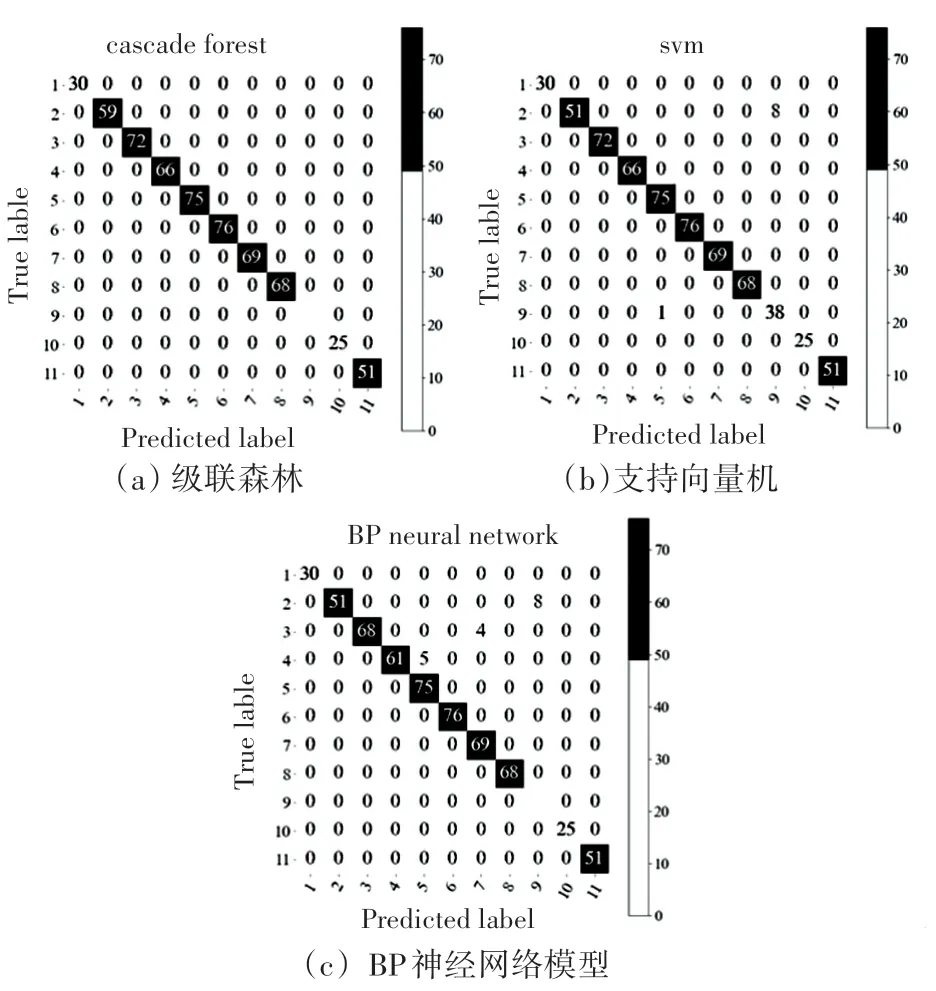
图7 三种分类识别算法的混淆矩阵Fig. 7 Confusion matrix of three classification algorithms
为了进一步验证所提算法的有效性,将经异常极值去除算法处理过的数据与未处理过的数据在级联森林模型中对比,得到的10 组不同训练集和测试集的准确率如图8 所示。
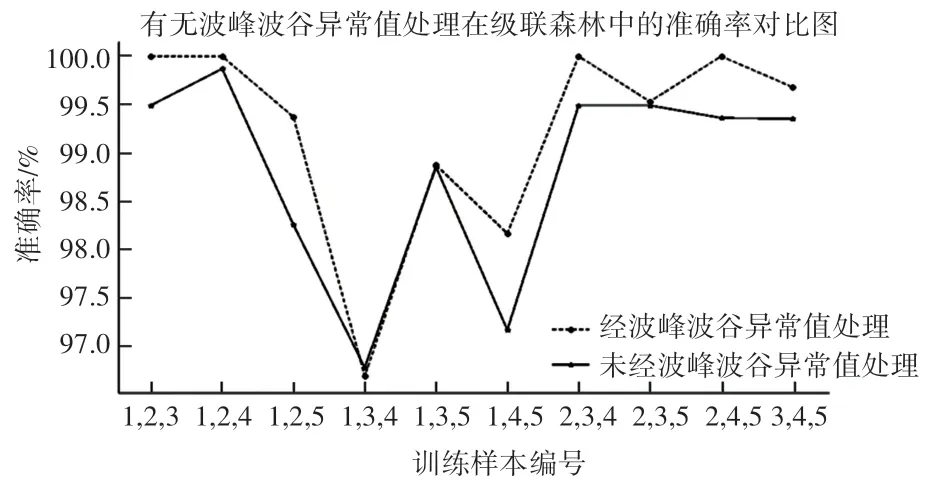
图8 有无波峰波谷异常值处理在级联森林中的准确率Fig. 8 Comparison of accuracy with and without peaks and troughs abnormal value processing in cascaded forest
由图8 中可见,经异常峰值去除算法处理后的平均准确率为99.23%,未经处理的准确率为98.81%,准确率提升了0.42%,再次验证了此方法对于提升识别准确率有较好的效果。
4 结束语
针对现阶段身份识别准确率低的问题,在充分分析加速度信号之后,考虑到信号中会出现小部分异常极值的现象,提出了基于四分位数去除异常极值算法来进一步提高识别准确率。 实验结果表明,在公开数据集和自采数据集上,经过算法处理后的识别准确率均得到进一步提高,并验证了级联森林分类算法在身份识别领域有较好的实际价值。
猜你喜欢
今日农业(2021年4期)2021-06-09
公民与法治(2020年20期)2020-11-27
水利规划与设计(2020年1期)2020-05-25
中学生数理化·八年级物理人教版(2017年3期)2017-11-09
电子制作(2016年15期)2017-01-15
中国医药指南(2016年1期)2016-07-11
系统工程与电子技术(2016年2期)2016-04-16
电测与仪表(2014年1期)2014-04-04
电测与仪表(2014年1期)2014-04-04
