
基于Scrapy的新浪微博数据爬虫研究
2023-06-22 17:02邓晓璐姚松
现代信息科技 2023年3期
邓晓璐 姚松


摘 要:为了快速获取到新浪微博中的数据,在学习和分析当前爬虫技术的原理、核心模块和运行过程的基础上,文章将探索实现一个基于Scrapy框架的网络爬虫工具,以完成数据捕获等目标。该工具可根据一个或多个微博关键词搜索相关微博信息,并将搜索结果写入本地文件。实验结果显示:该爬虫拥有较好的加速比,可以快速地获取数据,并且这些数据具有一定的实时性和准确性。
关键词:Scrapy;新浪微博;数据抓取
中图分类号:TP391.3 文献标识码:A 文章编号:2096-4706(2023)03-0044-04
Research on MicroBlog Data Crawler Based on Scrapy
DENG Xiaolu, YAO Song
(Guangdong Polytechnic of Science and Technology, Zhuhai 519090, China)
Abstract: In order to quickly obtain the data in MicroBlog, based on learning and analyzing the principle, core modules and operation process of current crawler technology, this paper will explore and implement cyber crawler tool based on the Scrapy framework to achieve data capture and other goals. This tool can search relevant MicroBlog information according to one or more MicroBlog keywords, and write the search results into local files. The experimental results show that the crawler has a better speedup ratio and can quickly obtain data, and the data have a certain degree of real-time and accuracy.
Keywords: Scrapy; MicroBlog; data capture
0 引 言
近年來,新兴数据平台的地位与日俱增,越来越多的人更加乐意通过网络来关注当前社会的热点话题。微博作为新兴数据平台之一,自其投入开放以来,逐渐被越来越多的人所使用,同时,微博话题也正以指数的趋势不断增长,这些话题涉及众多维度。在信息爆炸的时代,微博主题的不同指标成为研究人员的重要研究数据,比如近几年火爆的推荐系统等。因此,如何高质量且个性化的获取微博数据对研究者和运营者具有非常重要的意义。
然而,新浪微博并未提供相应的数据接口供研究人员使用,目前国内有一些网站提供公开数据,但这些数据量非常有限,并且类似于推荐系统这类研究,对数据的实时性具有很高的要求。众所周知,微博热点话题随着时间的推移、人们关注程度而不断更新的,如以往的话题热点可能成为现在的非热点,从而使其推荐价值降低;同样的,一条非热点话题也可能变为现在的热点话题。微博话题的这些特征也给微博话题推荐算法带来了越来越多的挑战,因此,如何提高抓取微博数据的实时性也有重要的研究价值。
本文所提供的爬虫工具可以模拟客户端操作,如用户登录、查看微博话题、查看评论等,通过设置某些条件,获取某个时间段内一个或多个微博关键词搜索结果,并将结果写入本地文件且永久保存。所谓微博关键词搜索即:搜索正文中包含指定关键词的微博;本系统还可以指定搜索的时间范围,能更好地匹配研究者的研究需求;此外,本系统还可以通过设置参数筛选各种要搜索的微博类型,如原创微博、热门微博、关注人微博、媒体微博等。使用本爬虫一方面可以节省研究人员的时间,让他们专注于数据分析上,同时也更加能够匹配研究人员的需求。
1 网络爬虫现状
网络爬虫是自动提取网页数据的程序,近几年关于网络爬虫的研究不计其数,谢蓉蓉[1]等人通过分析网络爬虫操作的基本流程,按照流程提取了大数据的关键特征,然后根据特征提取结果提出了基于网络爬虫的数据捕获策略;李俊华[2]等人利用Python网络爬虫的相关知识对豆瓣电影评论进行了一次抓取,并使用可视化库生成单词云并对其进行分析。王锋[3]等人针对当前影响爬虫程序效率的许多关键因素,在研究爬虫程序内部运行机制的基础上,优化了爬虫程序的架构并改进了相关算法。SU[4]等人首先分析了爬虫的功能结构,然后提出了一个三层爬虫模型。针对海量专题组织数据的空间信息和属性信息缺失的问题,杨宇[5]等人提出了一种基于爬虫框架的专题组织数据空间信息采集方法,以专题组织信息网站为信息源,以深度优先策略爬虫为信息获取方式。曾建荣[6]等人提出了一种面向多数据源的网络爬虫数据采集技术,解决了现有爬虫技术不便于采集多源数据的问题。在研究新浪微博、人民日报、百度百科全书、百度贴吧、微信公众号、东方财富吧六大媒体平台上的数据采集爬虫的基础上,采用Servlet后台调度技术,整合面向多数据源的网络爬虫,解决了不同媒体平台的数据采集问题。张宁蒙[7]等人提出了一种结合LDA的卷积神经网络主题爬虫,将主题判断模块视为一个文本分类问题,并使用深度神经网络来提高主题爬虫的性能。在卷积层之后,对LDA提取的主题特征进行拼接,以弥补传统卷积神经网络中主题信息的不足。汪岿等人[8]提出融合LDA的卷积神经网络主题爬虫,将主题判断模块视为文本分类问题,利用深度神经网络提升主题爬虫的性能。李俊华[2]龙香妤[9]张胜敏[10]等人面对获取有用信息的需求,在通用网络爬虫技术的基础上,利用Python软件对爬虫数据采集器进行了深度优化。然而新浪微博一方面具有反爬虫机制,一方面又具有较复杂的登录机制,因此,普通爬虫很难直接拿过来直接获取微博数据,针对这种问题,本文开发出一款专门适用于新浪微博的爬虫工具。
2 模拟用户登录
由于登录是新浪微博访问数据的必要步骤,所以本爬虫工具首先需要解决的问题就是如何登录微博。通过分析微博平台代码可知,登录微博时客户端需要向服务器端发送请求,服务器端会在收到请求后生成并返回密钥给客户端,客户端收到密钥后结合着用户的ID和密码一并发给服务器端,微博服务器端验证通过后则进入当前用户的登录状态。登录具体方式描述如下:
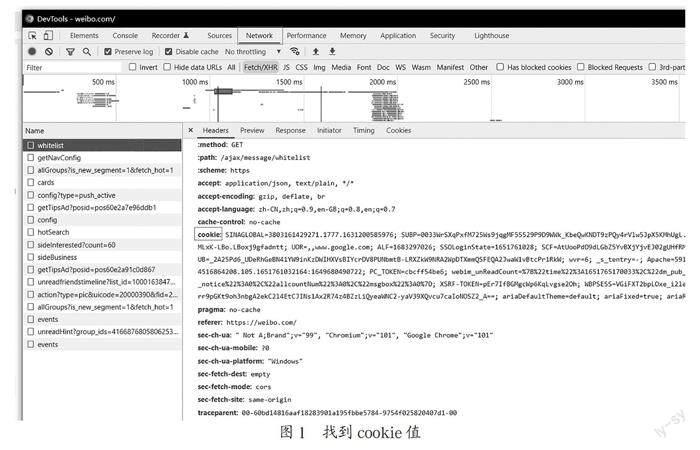
首先使用者需要设置cookie值。DEFAULT_REQUEST_HEADERS中的cookie是需要填的值,其获取方式为:用Chrome打开https://weibo.com/。使用者模拟用户登录成功之后,按F12打开开发者工具,在开发者工具的Network->whitelist->Request Headers,找到"Cookie:"后的值,这就是要找的cookie值,将其复制即可,如图1所示。
3 设置爬虫参数
使用者应按照自身需求设置搜索关键词,本爬虫支持搜索包含一个或多个关键词、分别搜索包括多个关键词、搜索某个微博话题等。使用者在设置关键词时,可以直接通过代码设置,也可以通过文本文档设置后,將其传到代码中。具体示例如下:
首先,用户需要修改setting.py文件夹中的KEYWORD_LIST参数,接着使用者根据不同需求进行以下设置:
如用户需要搜索微博正文包含一个指定关键词,如“听_猫在裙角”:
KEYWORD_LIST = ['听_猫在裙角'];
如用户需要搜索微博正文包含多个关键词,如想要分别获得“听_猫在裙角”和“璐璐”的搜索结果:
KEYWORD_LIST = ['听_猫在裙角', '璐璐'];
如用户需要搜索微博正文同时包含多个关键词的微博,如同时包含“听_猫在裙角”和“璐璐”微博的搜索结果:
KEYWORD_LIST = ['听_猫在裙角 璐璐'];
如用户需要搜索指定微博话题,即包含#的内容,如“#听_猫在裙角#”:
EYWORD_LIST = ['#听_猫在裙角#'];
本爬虫支持设置是否进一步搜索的阈值,一般情况下,如果在某个搜索条件下,搜索结果通常会有很多,则搜索结果应该有50页微博,多于50页不显示。当总页数等于50时,程序认为搜索结果可能没有显示完全,所以会继续细分。比如,若当前是按天搜索的,程序会把当前的1个搜索分成24个搜索,每个搜索的条件粒度是小时,这样就能获取在天粒度下无法完全获取的微博。同理,如果小时粒度下总页数仍然是50,系统则会继续细分,以此类推。然而,有一些关键词,搜索结果即便很多,也只显示40多页。所以此时如果阈值是50,程序会认为只有这么多微博,不再继续细分,导致很多微博没有获取。因此为了获取更多微博,阈值应该是小于50的数字。但是如果设置的特别小,如设置为1,这样即便结果真的只有几页,程序也会细分,这些没有必要的细分会使程序速度降低。因此,将程序的阈值设置为40~46之间。如使用者将搜索阈值设置为46,只需要设置代码FURTHER_THRESHOLD = 46即可。
设置好搜索阈值后,使用者需要设置结果保存类型,第一个代表去重,第二个代表写入csv文件,第三个代表下载图片,第四个代表下载视频。后面的数字代表执行的顺序,数字越小优先级越高。若使用者只要写入部分类型,可以把不需要的类型用“#”注释掉,以节省资源。本系统还可以筛选要搜索的微博类型,0代表搜索全部微博,1代表搜索全部原创微博,2代表热门微博,3代表关注人微博,4代表认证用户微博,5代表媒体微博,6代表观点微博。如使用者需要搜索全部原创微博,只需设置代码WEIBO_TYPE = 1即可。
在爬虫系统爬取数据的过程中,使用者需要设置等待时间,所谓等待时间,即访问完一个页面再访问下一个时需要等待的时间,默认为10秒。系统支持筛选结果微博中必须包含的内容,0代表不筛选,获取全部微博,1代表搜索包含图片的微博,2代表包含视频的微博,3代表包含音乐的微博,4代表包含短链接的微博。如,当使用者想需要爬虫等待时间为15秒,且在搜索中包含图片的微博,只需设置代码DOWNLOAD_DELAY = 15;CONTAIN_TYPE = 1即可。
设置好搜索关键词后,使用者可以设置搜索微博发布的时间范围,即微博发布的起始日期和结束日期。本系统筛选微博的发布地区时,可以精确到省或直辖市,值不应包含“省”或“市”等字,如想筛选北京市的微博请用“北京”而不是“北京市”,想要筛选安徽省的微博请用“安徽”而不是“安徽省”,可以写多个地区,注意本系统只支持省或直辖市的名字,不支持省下面的市名及直辖市下面的区县名,不筛选则用“全部”。如,当使用者筛选微博发布日期为2020-06-01到2020-06-02之间且发布地区为“山东”的微博时,只需设置代码START_DATE = '2022-05-01;END_DATE = '2022-05-02';REGION =['山东']即可。
其中,各个变量表示的含义如表1所示。
4 实验与分析
4.1 并行效率分析
对本文爬虫的并行效率进行分析,分别在不同CPU核数的计算机上抓取了以“校企合作”为关键词的微博,其中运行设备的具体配置与型号如表2所示。
如图2和表3所示,随着CPU核数的增加,该爬虫的加速比呈线性增长趋势。
由图2可得出结论:该爬虫在CPU核数为2时并无显著的加速效果,但随着CPU核数的增加,加速比也呈现线性增加的趋势,这表明该爬虫在抓取大量数据时具有很好的加速效果。
4.2 校企合作数据分析
在该实验中,本文针对关键词“校企合作”,获取了在2012年1月至2022年1月这个时间段内的共2 904 270条微博,部分结果如圖3所示,并且将获取微博所发布的时间记录下并作图分析。
如图4所示,是“校企合作”相关微博的发布数量在2012年到2022年不同年份变化曲线,可以看出:有关于“校企合作”的话题数量在总体上呈现出指数增长的趋势,由此可以看出,此爬虫工具具有非常重要的应用价值,使用者完全可以根据其研究方向及需要进行数据的实时爬取,从而进行必要的研究分析。
5 结 论
本文以为社交网络研究者们提供优质的研究数据为目标,设计了一款方便快捷的新浪微博数据获取工具。经实验验证,该工具具有使用方便、支持关键字匹配、支持并行的特点,使用者只需提供微博账号、设置好抓取的微博关键字,即可利用本工具进行数据抓取,并将抓取的数据永久性保留至本地文件内。很好地解决了目前国内社交软件研究者们研究数据匮乏的问题,具有很大的使用价值。
参考文献:
[1] 谢蓉蓉,徐慧,郑帅位,等.基于网络爬虫的网页大数据抓取方法仿真 [J].计算机仿真,2021,38(6):439-443.
[2] 李俊华.基于Python的网络爬虫研究 [J].现代信息科技,2019,3(20):26-27+30.
[3] 王锋,王伟,张璟,等.基于Linux的网络爬虫系统 [J].计算机工程,2010,36(1):280-282.
[4] SU F,LIN Z W,MA Y. Modeling and Analysis of Internet Worm Propagation [J].The Journal of China Universities of Posts and Telecommunications,2010,17(4):63-68.
[5] 杨宇,孙亚琴,闫志刚.网络爬虫的专题机构数据空间信息采集方法 [J].测绘科学,2019,44(7):122-127+140.
[6] 曾健荣,张仰森,郑佳,等.面向多数据源的网络爬虫实现技术及应用 [J].计算机科学,2019,46(5):304-309.
[7] 张宁蒙.基于Python的网络爬虫技术探析 [J].移动信息,2020(2):84-85.
[8] 汪岿,费晨杰,刘柏嵩.融合LDA的卷积神经网络主题爬虫研究 [J].计算机工程与应用,2019,55(11):123-128+178.
[9] 龙香妤.基于网络爬虫技术的数据抓取程序的设计 [J].技术与市场,2021,28(10):41-43.
[10] 张胜敏,王爱菊.基于Python的分布式多主题网络爬虫的研究与设计 [J].开封大学学报,2021,35(1):93-96.
作者简介:邓晓璐(1994.01—),女,汉族,江苏徐州人,助教,硕士研究生,研究方向:推荐系统;姚松(1997.11—),男,汉族,广东珠海人,助理研究员,硕士研究生,研究方向:数据挖掘。
收稿日期:2022-09-14
基金项目:广东省教育厅科研项目-青年创新人才类项目(2020KQNCX157)
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
好日子(2018年5期)2018-05-30
电子测试(2018年1期)2018-04-18
小资CHIC!ELEGANCE(2017年8期)2017-07-03
电子制作(2017年9期)2017-04-17
中国新闻周刊(2016年33期)2016-10-27
故事林(2016年20期)2016-10-18
小学生作文选刊·低年级版(2015年12期)2015-12-16
传奇故事(破茧成蝶)(2015年6期)2015-02-28
