
基于AM和DPCNN模型的新闻文本分类研究
2023-07-03 08:19路昌炜于龙昆闵江洪
计算机仿真 2023年5期
路昌炜,于龙昆,吕 程,闵江洪
(南昌大学信息工程学院,江西 南昌 330031)
1 引言
随着我国互联网技术的不断发展,人工智能在如今多项领域取得了快速发展和广泛应用,并且越来越深入到居民日常生活中,如人脸识别、智能家居、地图导航、无人驾驶等。如今人们越来越习惯使用手机或计算机在互联网上获取全世界的各类新闻信息,尤其在中文社交媒体上会产生大量的文本数据信息,为了使民众能够快速且准确地获得期望的文本内容,如何实现对文本进行准确高效的分类成为了自然语言处理中的一大目标。
文本分类的方法可分为根据规则[1]以及基于机器学习和基于深度学习进行分类。根据规则分类即先定义规则再人为将文本数据进行分类,但这种方法较为古老,需要对此类文本信息所属的领域有着深入的了解,不仅成本较大还容易受主观因素影响,而且随着科技发展数据规模越发庞大,所以靠人为来分类的方法逐渐减少。于是人工智能领域的机器学习分类方法逐渐崭露头角,近年来,深度学习方法更是如雨后春笋的被发明出来,各类神经网络能够通过不断学习迭代来挖掘文本深层特征。
本文基于ERNIE(Enhanced Representation Through Knowledge Tntegration)模型和DPCNN (Deep Pyramid Convolutional Neural Networks for Text Categorization)相结合成ERNIE-DPCNN模型,并基于清华大学自然语言处理实验室提供的THUCNews构建数据集,通过对比实验证明了本文所提出的方法和模型的有效性。
2 相关研究
2.1 词向量表示
词向量表示即以向量的形式表示每个词。Word2Vec[2]一度是词向量表示的重要方法,通过目标词的上下文关系来得到该词的词向量表示,主要方法为CBOW[3](Continuous Bag Of Words)和Skip-gram[4],COBW可以通过上下文的词来预测目标词得到词向量,Skip-gram则是通过目标词来预测周围词得到词向量。GloVe[5]( Global Vectors for Word Representation)利用全局矩阵分解和局部上下文窗口方法,可以把局部信息和全局信息结合起来。虽然Word2Vec和Glove这两种方法都能有效的将每个词的词向量表示出来,但显然它们对每个词的词向量表示是固定的,无法表示一个词的其它意思,更别说中文词汇里有相当数量的多义词,比如这两种表示方法下“苹果”公司和水果中的“苹果”的词向量表示是相同的,但显然是不准确的。于是ELMo[6](Embedding from language model)采用了双向模型来预测目标词,在正向模型中,先用目标词前面的词来预测目标词,再在反向模型中利用目标词后面的词来预测目标词,顺利解决了多义词表示的问题。2018年, 谷歌公司提出了BERT(Bidirectional Encoder Representations from Transformers)模型[7],该模型大幅提升了许多自然语言处理任务的实验效果,几乎刷新了当时各项任务指标,但是BERT模型同样存在缺陷,即难以学到词或短语的完整语义,缺乏对句子的全局建模。之后,清华大学和百度基于BERT模型分别提出了两种ERNIE模型。清华大学提出的ERNIE[8]则是将知识图谱引入到BERT模型中增强语义表示,主要由文本编码器(T-Encoder)和知识编码器(K-Encoder)两部分构成,其结构如图1。

图1 清华ERNIE结构
本文使用的为百度提出的ERNIE[9]模型,该模型改进了新的遮盖机制(mask),BERT在预训练中采用随机掩盖掉单个的字,而ERNIE采用掩盖某个词或短语以增强模型对语义的识别作用。例如:南昌是江西的省会,ERNIE不像BERT模型一样对该句中的某个字进行掩盖,而是掩盖南昌和江西这个词,让模型学会了南昌与江西的关系如图2。

图2 ERNIE与BERT的mask机制对比
2.2 深度学习分类模型
几个经典的机器学习分类方法主要有逻辑回归、朴素贝叶斯[10]、随机森林[11]、支持向量机[12,13]等。基于深度学习如卷积神经网络(Convolutional Neural Networks,CNN)等的分类方法开始出现。Kim提出了基于改进卷积神经网络以更适应于对文本数据进行分类的TextCNN[14],然而卷积神经网络对于长文本的特征提取有着明显缺陷。之后,由于RNN本身适合处理长文本数据,Lai提出了一种基于文本分类任务上的RNN模型[15],以最后一个隐状态作为句子向量,因此能够更好的表达上下文信息。Hochreiter等人基于RNN提出了LSTM[16],解决了长文本序列中容易出现的梯度消失问题。Kyunghyun等人启发于LSTM提出GRU[17](Gated Recurrent Unit)模型,同样解决了梯度消失问题,并且在数据集不大时该模型能起到比LSTM更好的效果。本文所使用的DPCNN是RieJohnson等提出的一种基于CNN结构的神经网络[18],相比于CNN,DPCNN能快速有效的提取文本中的远程关系特征。
3 基于ERNIE-DPCNN模型的分类方法
近年来,在预训练模型基础上进行训练并对垂直任务进行微调的神经网络训练方式在许多自然语言处理项目上取得较好的效果。比如高等人提出的基于注意力机制和DPCNN模型[19],能有效提高情感分析分类的评估指标,李利用BERT-DPCNN模型更高效的提高了垃圾弹幕的识别能力[20]。本文所使用到的ERNIE是一种预训练语言表示的新方法,其本质与BERT相同,将数据集在大语料环境下预训练得到的模型上根据具体任务进行微调从而将目标输入表示为一个固定大小的特征向量进行分类。本文使用 ERNIE 模型与DPCNN两种模型相结合的方式来进行文本分类方法研究。
3.1 ERNIE模型
ERNIE的结构与BERT相同都是基于双向自注意力机制的编码器部分(Encoder),主要包含多头注意力和前馈神经网络,其结构如图3。
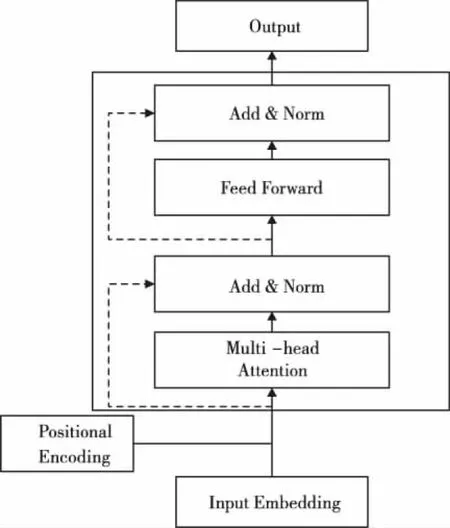
图3 Transformer编码器结构
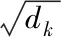
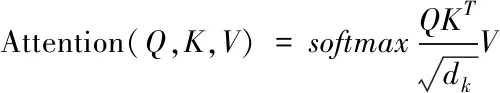
(1)
把多次运算得到的Attention矩阵横向拼接起来,接着乘以权重矩阵压缩成一个矩阵,单头注意力Headi的计算公式如式(2)所示:

(2)
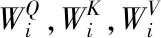
多头注意力机制的计算公式如式(3)所示
Multi-head Attention(Q,K,V)=
Concat(Head1,Head2…Headn)W0
(3)
其中,Concat函数将多个头的计算结果进行拼接,W0是拼接时使用的权重矩阵。
Feed Forward层其实就是一个简单的全连接神经网络,由两层全连接层及ReLU激活函数组成,计算公式如式(4)所示
FFN(x)=max(0,xW1+b1)W2+b2
(4)
在Add &Norm 层中,Add为残差连接,Norm为层正则化,设输入为x,其输出公式如式(5)~(6)所示
LayerNorm(x+Multi-head Attention(x))
(5)
LayerNorm(x+FeedForward(x))
(6)
3.2 DPCNN层
由于有些文本过长的原因,神经网络可能会出现结构复杂、梯度消失、梯度爆炸等问题,DPCNN网络可以在不增加太多计算成本的情况下增加网络深度获得更好的性能,弥补了CNN不能通过卷积获得文本长距离的依赖关系,DPCNN主要由文本区域嵌入层(Redion embedding)和数个卷积块组成,每个卷积块包含两个卷积核为3的卷积函数,结构如图4。

图4 DPCNN结构图
DPCNN使用的是输出与输入的卷积长度相等的等长卷积,然后为两端补零,等长卷积后,再固定feature map的数量进行池化。在每个卷积块后结束之后,对特征合集做一个池化, 其中短连接的作用与残差连接类似避免网络深度变深而性能下降。设置pool_size=3, stride=2,使每个卷积核的维度减半,形成一个金字塔结构,因此DPCNN对全局特征的提取能力得到了大幅增强如图5。

图5 每次池化后每层的计算时间减半
4 实验设计与结果分析:
4.1 实验数据
本实验使用了两组公开的中文新闻类数据集。
1)THUCNews数据集(简称cnews):抽取了清华大学自然语言处理实验室推出的THUCNews数据集中的20万条新闻数据作为本次实验的数据集,等量的划分为finance(财经)、stocks(股票)、education(教育)、science(科学)等十个类别,并按照8:1:1分为训练集16万条,测试集2万条和验证集2万条见表1。
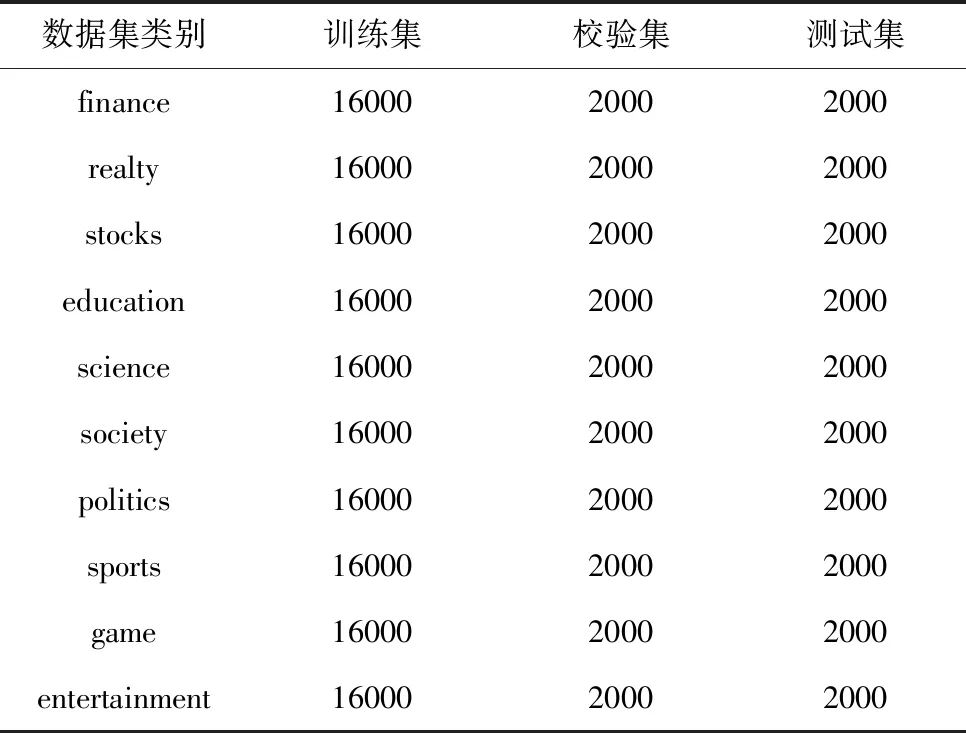
表1 THUCNews数据集设置
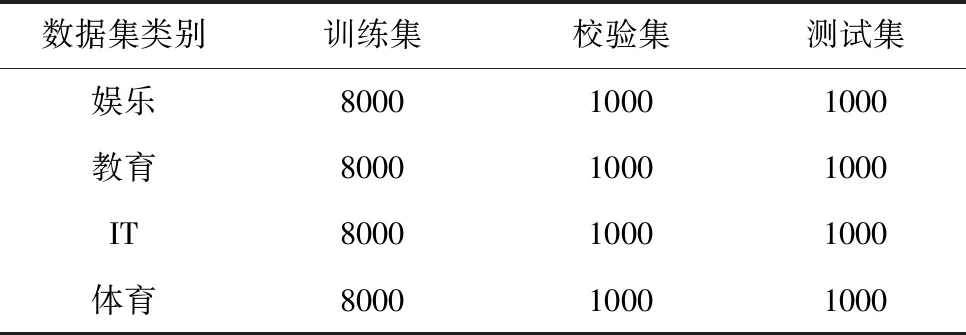
表2 搜狐新闻数据集设置
2)news_sohusite_xml数据集(简称nsx):来自搜狐新闻数据(SogouCS)[21],由搜狐新闻2012年6月到7月期间国内、国际、体育、社会、娱乐等18个频道的新闻数据。本文从中选取了其中娱乐、教育、IT、体育、四类合计4万条数据并按照8:1:1分为训练集32000条,测试集4000条和验证集4000条见图2。
4.2 实验环境
本实验环境见表3。

表3 实验环境
4.3 实验参数
本实验参数见表4。

表4 实验参数
4.4 评价指标
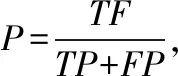
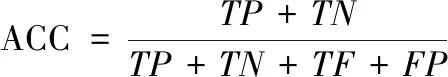
(7)
(8)
(9)
(10)
4.5 对比实验
为了验证本文提出的 ERNIE-DPCNN 模型在文本分类上的效果,本文基于cnews、nsx两组数据集共各进行了八组对比实验。
实验(1):该实验使用谷歌提出的BERT作为下游任务模型,再连接全连接层将输出向量输入Softmax 分类器得到分类结果;
实验(2):该实验使用百度提出的ERNIE作为下游任务模型,再连接全连接层将输出向量输入Softmax分类器得到分类结果见表5。
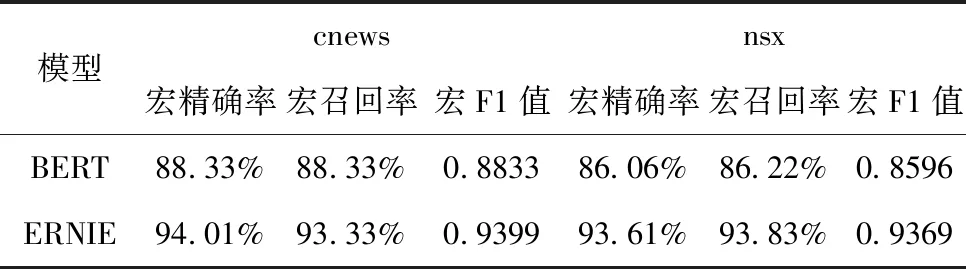
表5 BERT与ERNIE的结果对比
由表5可知,将实验(1)与实验(2)进行对比,发现ERNIE通过改进了掩盖机制比BERT具有更好的性能。
实验(3):BERT-CNN:该实验使用BERT进行词向量表示,再连接CNN提取特征并进行分类,CNN卷积核的大小为(2,3,4),每个尺寸的卷积核个数为256;
实验(4):BERT-LSTM:该实验使用BERT进行词向量表示,再连接LSTM提取特征并进行分类,本文设定双向LSTM每层包含256个神经元;
实验(5):BERT-DPCNN:该实验使用BERT进行词向量表示,再连接DPCNN提取特征并进行分类,本文设定DPCNN卷积核的大小为3,个数为250;
实验(6)~(8)则分别将实验(3)~(5)的BERT模型替换为 ERNIE模型,其余参数均相同。各模型的宏精确率、宏召回率、宏F1值以及各模型的训练时长结果见表6、7。
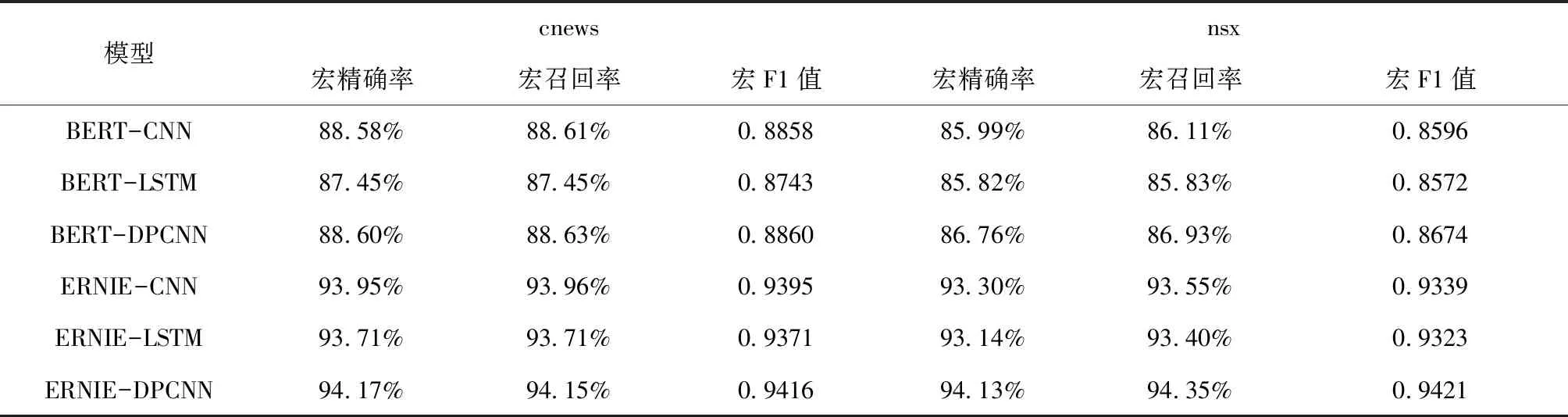
表6 各模型评估指标结果
将实验(3)~(5)和实验(6)~(8)进行对比,证明在连接相同的神经网络进行分类时,ERNIE仍具有比BERT更好的性能,将实验(3)~(5)和实验(6)~(8)分为两组进行对比时,证明DPCNN在对词向量进行特征提取和分类时比其它神经网络具有更好的分类效果,足够达到模型普适性的性能提升。表7统计了各模型所用时长,可以看出采用ERNIE的模型相较于BERT模型略有进步,体现了ERNIE在改进掩盖机制后的效率有所提升。将所有实验的准确率进行对比如图6。
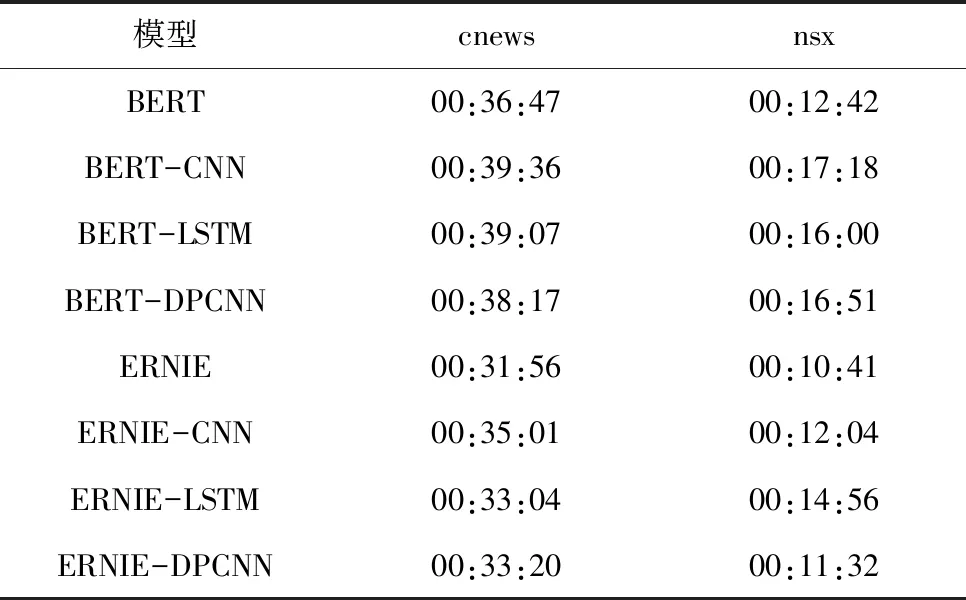
表7 各模型所用时长
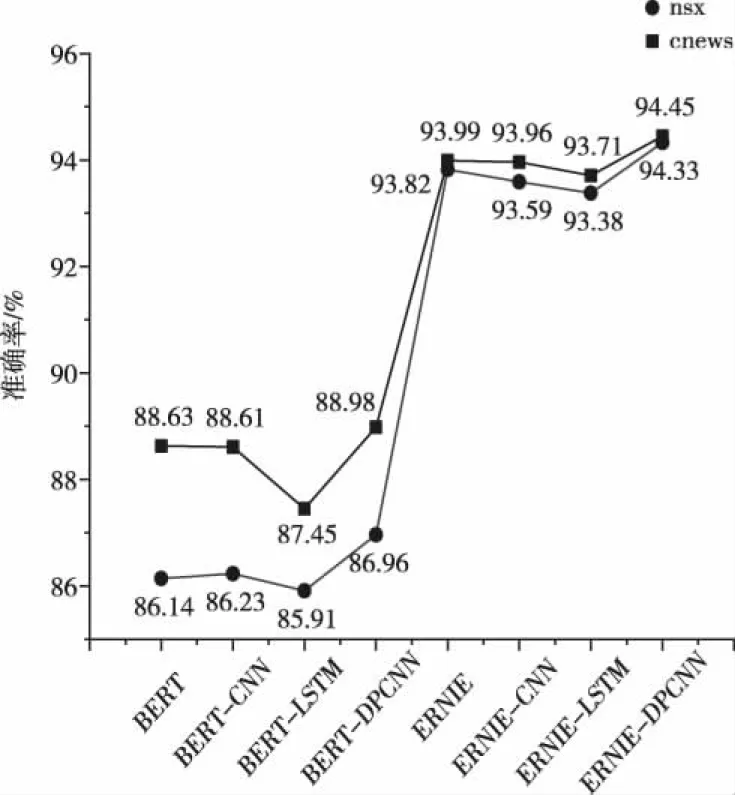
图6 各模型准确率对比
对比所有实验的准确率,ERNIE代替BERT后效果提升十分明显,DPCNN也具有一定的提升效果。综合上述结果,选取本文提出的ERNIE-DPCNN模型在cnews数据集中的各类别详细预测结果的准确率表示见图7。
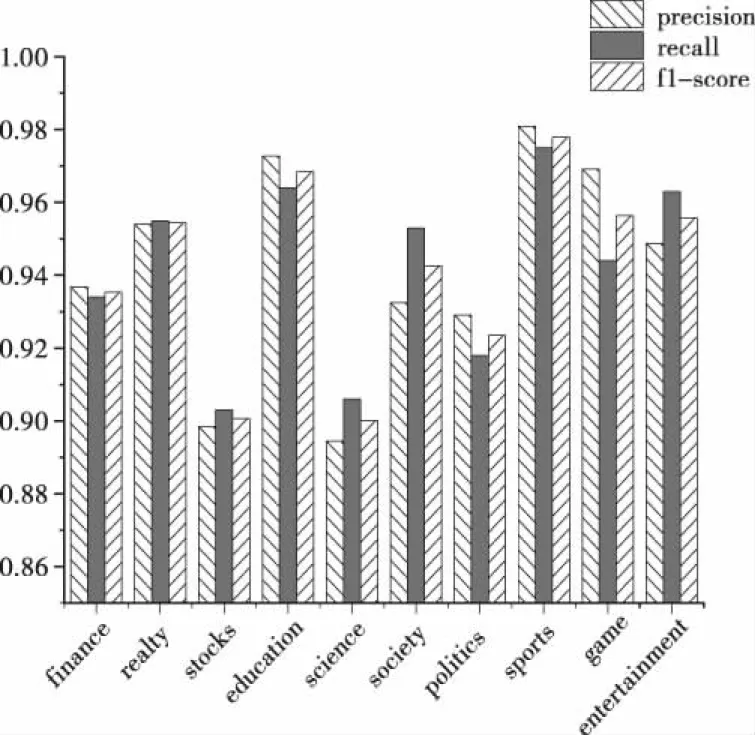
图7 ERNIE-DPCNN各类别准确率
由上图可知体育分类有着最高的评估指标,作者认为因为体育新闻中的词语如“篮球”、“足球”等词语具有十分鲜明的特色,结合本文所使用的ERNIE能够学习到更好的语义表达,故此分类的准确度最高。总的来说,ERNIE-DPCNN模型在处理中文文本数据时具有更好的性能,在宏精确率、宏召回率和宏F1值和准确率几个重要指标中均有着不同程度的提升。证明了本文提出的ERNIE-DPCNN结合模型的有效性。
5 总结
本文针对文本分类问题,在两个新闻类数据集上进行对比实验证明本文提出的 ERNIE-DPCNN 模型的检测效果。结果表明本文方法的检测效果均优于其它分类模型。本文创新点主要在于结合了ERNIE和DPCNN模型,实验证明该模型适用于中文文本分类,使用ERNIE模型代替BERT在预训练好的基础上进行微调使得中文文本数据集的准确度有着较大提升。
然而,本文提出的模型也存在一些问题,其一,由于新闻标题的精简性,该数据集中绝大部分数据为中短文本数据,很难有效体现出该模型对长文本数据的识别能力,故未来需要在数据集中添加足够的长文本数据以完善数据集。其二,由于模型结构的复杂度,尤其是对多达二十万条数据的数据集训练时每次训练的时间较长,如何在保证实验指标不下降的基础上缩短实验时间成本也是本文未来需要解决的问题。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
高中生学习·高三版(2016年9期)2016-05-14
重型机械(2016年1期)2016-03-01
新高考·高二数学(2015年11期)2015-12-23
大连工业大学学报(2015年4期)2015-12-11
