
融合多窗口局部信息的方面级情感分析模型
2023-07-03 14:11郑智雄刘建华孙水华林鸿辉
计算机应用 2023年6期
郑智雄,刘建华*,孙水华,徐 戈,林鸿辉
(1.福建工程学院 计算机科学与数学学院,福州 350118;2.福建省大数据挖掘与应用技术重点实验室(福建工程学院),福州 350118;3.闽江学院 计算机与控制工程学院,福州 350108)
0 引言
方面级情感分析(Aspect-Based Sentiment Analysis,ABSA)可以精确分析每条在线评论所包含的不同方面的情感极性,是一种细粒度的情感分析任务[1-2]。方面级情感分析已成为自然语言处理(Natural Language Processing,NLP)领域的一个研究热点,它的任务目标是预测同一句子里每个方面独立的情感极性。例如评论“Great food but the service was dreadful!”,其中包含了对两个方面词“food”和“service”情感极性的评价,分别是积极评价和消极评价。相较于句子级和文档级的情感分析技术,显然方面级情感分析可以挖掘更细粒度的情感信息。
近年来,深度神经网络被广泛应用于NLP 任务[3-4]。大量研究表明深度神经网络学习和提取文本特征效果显著。长短期记忆(Long Short-Term Memory,LSTM)网络是循环神经网络(Recurrent Neural Network,RNN)的一种变体,常被用于编码序列文本生成特征表示。文献[5]中把所有词向量与方面词向量拼接,然后输入LSTM 提取特征,考虑了方面词和上下文之间的交互作用。文献[6]中引入了一种自注意力机制,与传统的注意力机制[5,7-8]相比,它能捕获文本上下文特征的内在联系;但是将自注意力机制应用于方面级情感分析任务时,自注意力机制会错误地把方面词联系到与它无关的上下文词语。文献[9]中提出了一种局部上下文焦点机制,动态地加大与方面词语义距离较近词语的权重,减小其他词的权重,使模型更关注方面词周围的语义信息。
最近有许多研究者将句法依赖树与图神经网络结合应用于模型中,使之可以精确学习和提取与方面词相关的上下文语义信息和情感特征。文献[10]中利用依赖树关系直接从方面词的句法上下文传播情感特征,并且利用LSTM 改进建模不同层之间的关系。文献[11]中采用图卷积网络(Graph Convolutional Network,GCN)建模依赖树语法信息和语句上下文的依赖关系。文献[12]中提出把位置嵌入加入图注意力网络(Graph ATtention network,GAT),使它能同时捕获图节点的结构和位置信息。文献[13]中提出了一种关系GAT(Relational GAT,RGAT),在学习含有语法关系的上下文特征时加入依赖树的关系类型,形成语法信息更丰富的上下文特征。句法依赖树为每个句子提供了对应了语法结构信息,GCN 和GAT 以这些信息为指导,使每个词重点学习在依赖树上与它相邻的词语特征。
但是,上述研究都过多依赖句法依赖树所提供的结构信息建模,而句法依赖树相较于常规注意力机制提供的是较稀疏的依赖关系,让语义信息在间接传播时不可避免地丢失了一些与语义距离不远的重要信息,称之为局部信息;同时,由于语法分析工具在生成依赖树结构信息时存在一定的误差,一些语义距离较远且无直接关系的词语有时也会被错误地连接。如图1 所示,例如文本“The food is great but the service and the environment are dreadful”,其中“food”“service”和“environment”是文本的3 个方面词(下划线表示),“great”和“dreadful”之间的关系是一种噪声。

图1 句法依赖树Fig.1 Syntactic dependency tree
针对上述问题,提出了一种融合多窗口局部信息的方面级情感分析模型MWGAT(combining Multi-Window local information and GAT)。该模型首先以多个不同大小的窗口学习上下文特征的局部信息,把每个通道学习得到的特征向量输入独立的自注意力机制,重新分配权重分布;同时采用GAT 结合句法依赖树的方法学习语法感知的上下文特征;然后将含有局部信息和语法感知的两种上下文特征融合,形成语法信息和局部信息相互补充的特征表示;最后将经过融合的特征输入分类器,得到模型对情感极性的预测值。MWGAT 模型可以有效解决丢失局部信息的问题,同时由于增加了局部信息的权重,语法分析工具导致的依赖关系误差会被减弱。
本文主要工作如下。
1)设计了融合多窗口局部信息的MWGAT 模型,在GAT的基础上加入多窗口学习的局部信息特征,加强了特征表示能力。
2)提出了局部相对距离(Local-Relative Distance,LRD)评价一个词语局部信息的有效范围,LRD 阈值决定了局部特征学习范围。
3)通过实验分析窗口的大小和学习局部特征的窗口数量,选择最优参数设置。
4)在3 个公开数据集上与其他先进的模型实验对比,验证本文模型的性能。
1 图注意力网络
GAT 主要根据句法依赖树的依赖关系学习上下文特征表示。依赖树结构信息可以表示成一个含有n个节点的图G,其中每个节点都表示句子的一个词语。G的边表示两个词之间的依赖关系。第i个节点的所有邻居节点表示为Ni。GAT 通过融入依赖关系的多头注意力机制,使每个节点从各自的邻居节点学习特征,迭代更新每个节点的特征表示,计算公式如式(1)(2)所示:
2 MWGAT模型构建
针对网络评论作方面级别情感分析,MWGAT 模型在学习语法感知特征的同时,额外学习多种不同窗口大小的局部信息特征。语法感知的特征可以较为精确地表达不同方面词的情感特征,局部特征可以弥补语法感知特征丢失的一些潜在的局部信息,将这两种特征融合以提高模型整体的情感特征捕获能力,模型结构如图2 所示。
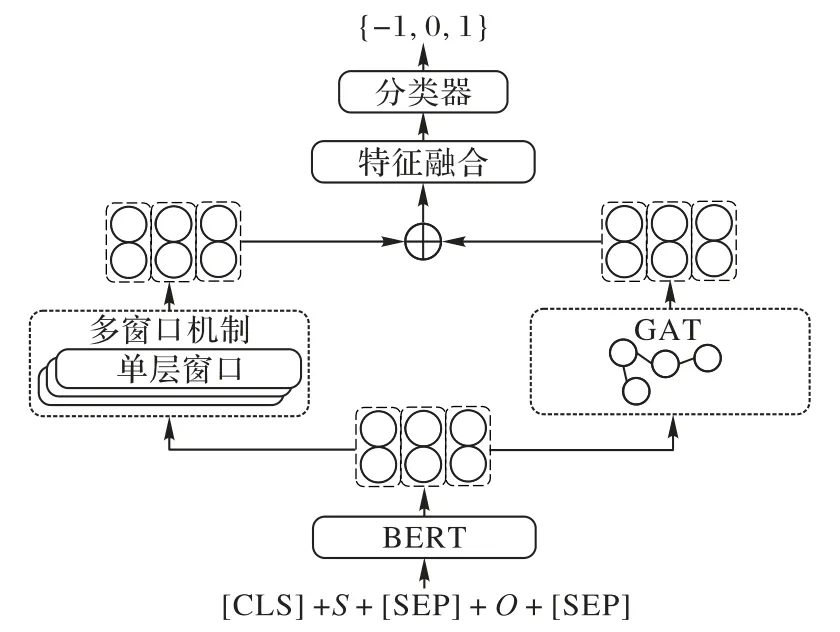
图2 MWGAT模型的结构Fig.2 Structure of MWGAT model
2.1 任务定义
MWGAT 模型的每个训练样本由1 个句子、方面词和句法依赖树这3 个部分组成,将这3 个部分定义成一个三元组:S,O,T,其中S={w1,w2,…,wn}表示一个含有n个词组成的句子;一个单词的列表O={a1,a2,…,ak}表示句子S中包含k个方面词,其中每个方面词ai={wi,wi+1,…,wi+m-1}可以是1 个或至多m个词组成;T=(V,A)表示句子句法依赖树的无向图,V表示依赖树的n个节点,A∈Rn×n是用1 和0 表示两个节点之间有无依赖关系的邻接矩阵。模型的目标是预测句子S关于每个方面词的情感极性y∈{-1,0,1},-1、0 和1 分别表示消极、中性和积极。
2.2 词嵌入层
词嵌入是将文字符号转换为可计算数值的基础,大量研究已经证明了BERT(Bidirectional Encode Representation from Transformers)预训练语言模型在编码词嵌入方面的有效性,因此MWGAT 模型使用BERT 编码器生成词向量。根据文献[5]中,样本句子重构成适配BERT 模型的格式“[CLS]+S+[SEP]+O+[SEP]”,输入BERT 获得初始的词向量{x1,x2,…,xn},记 为X∈Rn×d,其中d表示词嵌入维度,“[CLS]”和“[SEP]”为BERT 编码器的特殊标记符号。
2.3 多窗口局部特征学习机制
学习多窗口局部特征是MWGAT 的重要部分,目的是使每个词语都能学习不同窗口大小的局部信息特征,深度挖掘潜在的局部信息,生成具有更强表达能力的特征表示。本文提出了多窗口局部特征学习机制高效捕获局部信息,每个窗口的特征学习框架如图3 所示。在自注意力机制的计算过程中引入可以限定特征学习范围的遮罩矩阵,实现每个特征只与规定范围内的特征相互学习。

图3 局部特征学习框架Fig.3 Framework of local feature learning
2.3.1 局部相对距离
LRD 是决定上下文词语或特征是否属于目标词局部特征的判断依据,计算公式如式(3)所示:
其中:i表示上下文词语的位置下标;Pt表示目标词的位置下标,目标词可以是句子里任意一个词;表示第i个上下文词与目标词之间的局部相对距离。
2.3.2 局部特征学习
学习局部特征利用了遮罩自注意力机制,使用遮罩屏蔽非局部范围内的其他特征,不参与自注意力机制的学习。首先把长度为n的句子通过词嵌入层生成的词向量表示为X={x1,x2,…,xn},通过3 个不同的线性层将X映射到查询矩阵Q、键矩阵K和值矩阵V,如式(4)所示:
其中:WQ、WK和WV均是可训练的权重矩阵;bQ、bK和bV是可训练的偏置参数。
然后根据式(5)所示的计算公式,计算每个特征的局部特征联系,再重新分配注意力权重:
其中:dK表示矩阵K的维度,遮罩矩阵M∈Rn×n为每个词都指定不同的局部范围,使每个词向量特征重点学习在自己局部范围内的特征向量,构建方法如式(6)~(8)所示。在使用Softmax 函数计算权重分布之前,将M与计算得来的权重系数矩阵相加,使在局部范围之外的注意力系数为负无穷大。接着输入Softmax 函数把非局部范围内的权重置零,借此达到只学习指定范围内特征的目的。
其中:vi表示第i个单词是否被遮罩,β表示单词在窗口内的最大局部相对距离,ei表示第i个词的局部范围遮罩向量,n表示句子的长度。如图4 所示,当β=1 时vi-1~vi+1为第i个词的局部特征,赋值为-∞。

图4 遮罩向量示例Fig.4 Example of masked vector
2.3.3 多窗口局部特征学习
其中:||和[;]表示拼接操作;Wl∈ R[d×(L+1)]×d是可训练的权重矩阵为多窗口局部特征学习的最终输出。
2.4 特征融合层
然后,将两个池化后的特征向量融合成一个向量。为了学习既包含语法感知特征又包含局部信息特征的复合特征表示,融合策略引入细粒度特征融合机制,控制融合比例。文献[14-15]中的门控机制可以很好地实现这个功能,具体的融合计算如式(13)所示:
其中γ是控制融合比例的参数,由式(14)计算:
其中:Wg和bg分别是权重矩阵和偏移向量,σ表示激活函数。
2.5 分类器
MWGAT 模型的分类器采用单层全连接神经网络,它的输入为融合后的特征hf,输出为每个情感类别c的概率,具体的计算公式如式(15)所示:
其中:Wf和bf是可训练的模型参数,C是所有情感类别的集合。
2.6 模型训练
本文模型通过减小真实值和预测值的L2 正则化交叉熵函数值进行训练,具体的计算公式如式(16)所示:
其中:I是一个指示函数,N是训练样本的总数,λ是正则化超参数,θ表示模型中所有参数的集合。
3 实验与结果分析
3.1 数据集与评价指标
为验证MWGAT 模型的有效性,本文选用3 个公开数据集将MWGAT 模型和其他模型进行实验对比。3 个数据集分别来自SemEval2014(https://alt.qcri.org/semeval2014/task4/)的餐饮评论数据集Restaurant、笔记本评论数据集Laptop 和Twitter 数据集(http://goo.gl/5Enpu7)。这些数据集的每个样本都标注了1 个或多个方面的情感标签,情感标签有3 个分类:积极(Positive)、消极(Negative)和中性(Neutral)。数据集样本数的相关统计信息如表1 所示。

表1 实验数据统计信息Tab.1 Experimental data statistical information
本文实验考虑了模型评估的两个评价指标:准确率(Accuracy,Acc)和Macro-F1(MF1)分数。Acc 表示样本正确分类的百分比,即正确分类的正样本数和负样本数之和占总样本数的比例,如式(17)所示。MF1 分数是一个多分类任务的评价指标,表示模型在不同类别的平均表现情况,如式(18)所示:
其中:TP(True Positive)表示的是正确分类的正样本数;TN(True Negative)表示的是正确分类的负样本数;FP(False Positive)表示错误分类的正样本数;FN(False Negative)表示错误分类的负样本数;N表示的是样本总数;| |C表示情感类别的总数;Pi表示每个情感类别对应的精确率,表示每个情感类别中预测正确的正样本数占预测正样本总数的比例;Ri表示每个情感类别对应的召回率,表示每个情感类别中预测正确的正样本数占实际正样本数的比例。
3.2 参数设置与实验环境
所有实验的模型超参数设置如表2 所示,MWGAT 模型的词向量使用BERT 编码器生成,维度为768。BERT 的dropout 设置为0.1,多窗口局部特征学习层(Multi-Window local Feature Leaning Layer,MWFLL)的dropout 设置为0.1,正则化参数 设置为10-5。在训练过程中采用Adamax[16]优化器优化模型参数,学习率设置为2×10-5。对于GAT 组件,每层采用4 个注意力头。本文实验使用依赖树生成工具[17]为每个样本生成对应的语法依赖树信息。实验环境如表3 所示,主要基于PyTorch 深度学习框架实现模型的训练和预测。

表2 超参数设置Tab.2 Hyperparameter setting

表3 实验环境Tab.3 Environment of experiments
3.3 对比实验
3.3.1 对比模型
本文选择的对比模型包括传统注意力机制模型和基于语法的模型。
1)传统注意力机制模型。
ATAE-LSTM(ATtention-based LSTM with Aspect Embedding)[5]:将方面词特征向量与所有上下文特征向量逐个拼接,再使用LSTM 提取上下文信息。
IAN(Interactive Attention Networks)[7]:通过LSTM 网络和注意力机制交互上下文和方面词的特征表示。
MGAN(Multi-Grained Attention Network)[18]:利用双向长短期记忆(Bi-directional LSTM,BiLSTM)捕捉上下文信息,利用多粒度注意力机制捕捉方面词和上下文之间的关系。
AEN(Attention Encoder Network)[19]:采用注意力编码器网络表示特征,以语义交互的方法建模目标和上下文。
AEN-BERT(Attention Encoder Networks -BERT)[19]:在AEN 的基础上将词嵌入编码器替换为BERT 编码器。
CapsNet(Capsule Network)[20]:利用胶囊网络[21]建模方面词和上下文之间复杂的关系。
2)基于语法的模型。
PhraseRNN(Phrase RNN)[22]:对AdaRNN(Adaptive Recursive Neural Network)[23]添加了两个短语组合函数,然后使用依赖树和组合树作为模型的输入。
LSTM+SynAtt(LSTM+Syntax Attention)[24]:将语义距离纳入注意机制的计算,建模目标词与上下文之间的联系。
TD-GAT(Target Dependent GAT)[10]:应用GAT 模型捕获语法结构,并且利用LSTM 改进建模不同层之间的关系。
CDT(Convolution over Dependency Tree)[25]:把依赖树与GCN 模型结合,应用到方面词表示学习。
R-GAT+BERT(Relational GAT+BERT)[26]:提出一种语法依赖树的调整方法,把树根设置为方面词,优化依赖关系以方面词为中心,然后输入GAT 学习特征。
T-GCN(Type-aware GCN)[27]:在结合语法依赖树结构信息的图注意力网络的基础上,计算注意力时考虑依赖关系的类型,增强上下文语义表达能力。
3.3.2 对比实验结果分析
对比实验的结果如表4 所示。从表4 中可以看出,首先,MWGAT 模型在3 个数据集上的两种评价指标均超越了其他基准模型,验证了多窗口局部信息和图注意力网络融合的有效性。其次,在模型里加入语法信息可以显著提高模型的性能,上述的6 个基于语法的模型,除了PhraseRNN 均比传统注意力机制模型的性能好。PhraseRNN 因为主要使用了RNN 结构导致模型建模上下文语义信息的能力较弱,而语法信息需要建立在准确的上下文语义之上,所以模型性能提升较少。最后,在使用语法信息的模型之中,通过GAT 和GCN 编码语法信息的模型性能最优,这是因为语法信息的主要结构是依赖树,图结构可以比较准确地表达依赖树所蕴含的信息。R-GAT+BERT 和T-GCN 分 别是采用GAT 和GCN 结合语法信息的模型,相较于其他对比模型,表现出良好的性能。MWGAT 模型相较于对比模型中性能最优的T-GCN 模型,在3 个数据集上的准确率分别提高了1.27%、1.54%和0.38%,MF1 分数分别提高了2.48%、2.37%和0.32%;这是因为MWGAT 模型在图神经网络结合语法信息的基础上,融合了多窗口局部信息,这种方式可以为语法信息补充一些潜在的语义信息,进而提高模型性能。其中Twitter 数据集由于是网络社交文本,包含了大量无效的特殊符号,语法也较为混乱,所以有效的潜在局部信息较少,导致性能提升较小。另外,根据表1 数据集样本数统计分析得出样本数分布不够均衡,所以本实验结果的MF1 分数相较于准确率提升得更多,进一步验证了该模型的有效性。本文实验结果表明,融合了多窗口局部信息的图注意力网络可以更好地应用于方面级别情感分析任务。

表4 不同模型的实验结果 单位:%Tab.4 Experimental results of different models unit:%
3.4 参数选择分析实验
3.4.1 窗口大小对模型的影响
多窗口局部特征学习层依靠融合不同窗口大小的局部信息学习特征。为选择合适的窗口参数,设置MWGAT 只以单窗口学习局部特征,对比不同窗口大小对模型性能的影响。共选择{3,5,7,9,11}这5种不同大小的窗口在Restaurant 和Laptop 数据集上实验,实验结果如表5 所示。其中当窗口尺寸为5 时模型的性能最优,两个数据集分别达到了87.12%和81.25%的预测准确率;其次,窗口尺寸为3 时达到了次优的性能,准确率分别是86.51%和80.70%;而当窗口尺寸设置为7 及以上时,模型性能逐步下降。通过实验数据(表5)可以分析得到,窗口尺寸设置为5 时可以提取得到的潜在信息较多;窗口尺寸设置为3 时则较少,这是因为一些方面词已经包含了3 个单词,还有许多短语组合都超过了3 个单词,导致提取的内容不够,从而在部分情况下无法获得有效的局部信息;窗口尺寸设置为7 时模型的预测准确率比设置为3 时更低,这是因为尺寸设置过大时,较大的局部范围包含了过多不同的局部信息,导致模型提取的局部语义信息不统一,较为混乱,从实验数据的窗口尺寸9 和11 也可以证明这一点。因此,将窗口尺寸设置为5 是最优选择,其次是3。
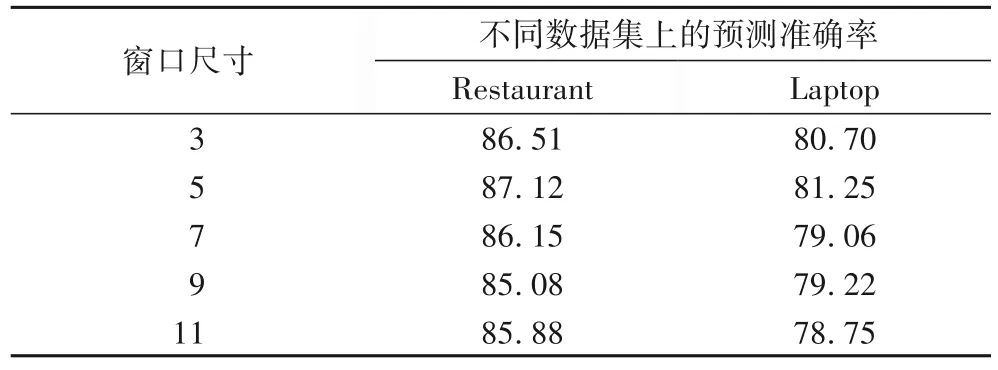
表5 不同窗口尺寸的性能对比 单位:%Tab.5 Performance comparison results for different window sizes unit:%
3.4.2 窗口数对模型的影响
多窗口局部特征学习机制的窗口数量也是一个重要的参数。如表6 所示,本节共设计了窗口数从1~5 的实验,每个窗口的尺寸大小取值为3.4.1 节最优结果依次组合。结果显示当窗口数为2 时实验结果最优,在两个数据集上都达到了最高准确率87.21%和81.56%。而在5 个窗口的情况下准确率降至最低,分别是84.71%和77.81%。实验结果说明融合多个不同窗口大小的局部信息可以有效提升模型的预测准确率。但是当融合过多窗口反而会导致模型准确率下降,因为提取尺寸差距较大的局部信息可能会产生截然不同的语义信息,而局部信息是一种细粒度的特征信息,将它们融合必然会导致局部信息的混乱。
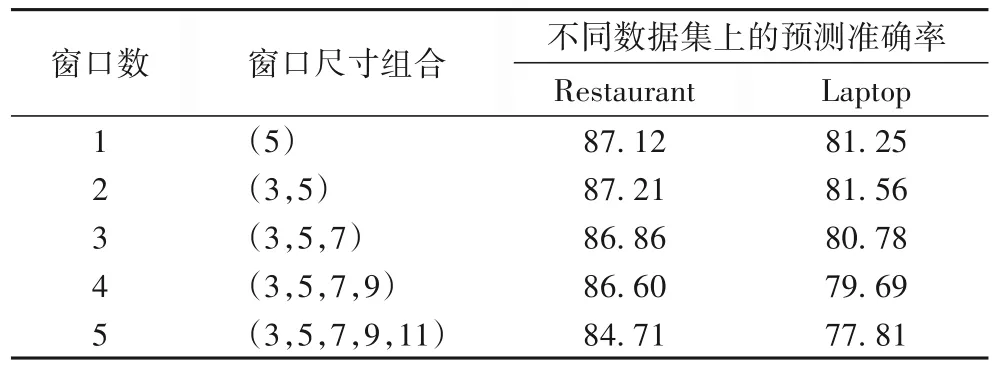
表6 不同窗口数的实验结果 单位:%Tab.6 Experimental results for different numbers of windows unit:%
3.5 消融实验
为了进一步检查MWGAT 模型每个组件对模型性能的影响,本文设计了消融实验,在Restaurant 和Laptop 数据集上观察实验结果。实验结果如表7 所示,当去掉MWFLL 时准确率和MF1 值分别下降了0.89、1.40 个百分点和2.35、1.71个百分点;这是因为缺少MWFLL,单独以GAT 模块学习特征时导致局部信息提取能力不足,所以模型性能下降。当去掉GAT 时准确率和MF1 值分别下降了1.6、2.65 个百分点和3.15、3.72 个百分点;这是因为没有GAT 模块会使模型提取的局部信息无法高效组织成可靠的语义信息。该实验结果说明了局部信息和依赖树信息都能有效提升模型性能,将这两种信息融合达到最优效果。
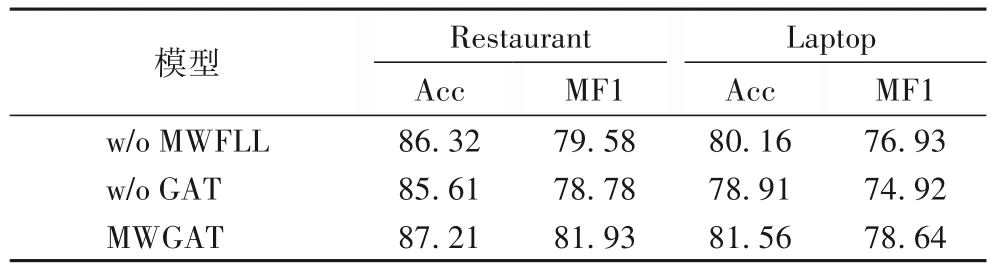
表7 消融实验结果 单位:%Tab.7 Results of ablation study unit:%
4 结语
本文提出了一种融合多窗口局部信息特征和语法感知特征的方面级情感分析网络模型MWGAT。该模型首先使用GAT 和多窗口局部特征学习机制学习不同的特征,然后通过特征融合层融合成一个特征,最后通过分类器预测情感极性。通过实验验证了局部信息拥有一些重要的特征信息,挖掘这些信息有助于提升模型的性能。虽然MWGAT 已取得不错的效果,但所挖掘的局部信息还包含了一些无关的信息,未来还将进一步研究如何更加精确地提取有效局部信息。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化·七年级数学人教版(2022年11期)2022-02-22
数学物理学报(2021年2期)2021-06-09
时代英语·高一(2019年1期)2019-03-13
新高考(英语进阶)(2017年10期)2017-12-23
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
发明与创新(2016年38期)2016-08-22
艺术生活-福州大学厦门工艺美术学院学报(2016年3期)2016-07-31
