
基于邻域容差互信息和鲸鱼优化算法的非平衡数据特征选择
2023-07-03 14:12黄金旭徐久成
计算机应用 2023年6期
孙 林,黄金旭,徐久成
(1.河南师范大学 计算机与信息工程学院,河南 新乡 453007;2.智慧商务与物联网技术河南省工程实验室(河南师范大学),河南 新乡 453007)
0 引言
近年来,数据维度爆炸及其类分布的非平衡性给机器学习、数据挖掘等领域带来了巨大的挑战。在非平衡数据中,正类表示样本较少的类,负类表示样本较多的类;特征选择可以通过选择与少数类更相关的特征,是提高非平衡数据泛化能力和预测性能的一种非常有效的方法[1]。特征选择作为机器学习、数据挖掘等领域数据预处理的关键技术之一,不仅能够删除冗余、不相关的特征,还能够保证原始数据分类能力不变[2]。现有的特征选择方法大致分为3 类:过滤、包装和嵌入[3]。过滤法先筛选特征集,再使用学习算法训练,过程与学习算法无关,可以快速剔除噪声特征,计算效率较高、通用性强、复杂性低、所选的特征子集冗余度小,适用于大规模数据集。包装法依赖于所选择的学习算法,使用分类器性能评价特征重要程度,特征子集的分类性能较好,但是不适合处理高维数据,通用性弱,计算复杂度很高。康雁等[4]设计了一种混合花授粉和灰狼优化的包装式特征选择算法,但是仅能处理100 维以下的低维数据集。嵌入法是将特征选择过程与分类器训练过程结合,在使用特定学习算法训练的同时选择特征,但过度依赖具体的学习算法会出现过拟合现象,缺乏通用性。Aram 等[5]提出了基于支持向量机(Support Vector Machine,SVM)的线性成本敏感最大边距的嵌入特征选择方法,但是无法确保找到全局最优特征。上述3 种方法均存在各自的优势与不足。为了有效处理高维数据集、提升计算效率和避免出现过拟合情况,本文使用过滤法策略设计特征选择算法。
邻域粗糙集既能处理离散型数据又能处理数值型和符号型数据[6],当前关于不完备决策系统的研究较少。Sun等[7]针对不完备邻域决策系统设计了基于悲观邻域熵的启发式特征选择算法。目前,大多数基于邻域粗糙集的特征选择算法是利用邻域构建了依赖度、信息熵和知识粒度等评估函数,均满足单调性;但是,当原始数据分类能力较差时,利用这些满足单调性的评估函数建立的特征选择算法存在一定的缺陷:这些评估函数取值较低,因此无法得到更好的约简结果。为了解决这个问题,Wang 等[8]构建了基于邻域互信息的相互区分指数,表征特征的区分能力,并设计了一种非单调特征选择算法;姚晟等[9]利用邻域粗糙互信息熵的非单调性,从属性全集中更合理地选择了具有更高决策公共邻域粗糙信息量的特征子集,并限定了约简集的极小性;Sun等[10]基于邻域可信度和覆盖度提出了决策邻域互信息度量,设计了非单调特征选择算法,更好地反映了高维数据的特征决策能力。另外,姚晟等[9]指出:对于原始分类性能较差的数据集,单调性约简算法不能获得较优的约简结果;但是当非单调性约简集的分类度量值不低于原始数据集的度量值时,最终约简集具有更优的分类性能和更高的约简率。由此可见,基于邻域粗糙集的互信息是衡量特征集相关性大小的一种重要方法,具有非单调性变化的特点,是一种有效处理非单调约简的评估函数。但是,以上方法只适用于完备型决策系统,不适用于处理不完备数据。在上述非单调约简算法的启发下,在不完备邻域决策系统中,本文基于邻域容差可信度和邻域容差覆盖度定义了邻域容差互信息,并证明了邻域容差互信息度量也是非单调的。因此,针对不完备数据,该度量方法不仅能有效度量特征之间的相关性,而且能增强不完备数据的特征决策能力。
在实际应用中,存在许多分布不均匀的非平衡数据。传统的特征选择算法在处理非平衡数据集时,分类器为了最大化整个数据集的分类精度,往往会将少数类误分为多数类,从而忽视了少数类的影响[11]。林耀进等[12]提出了基于最大决策边界的高维类非平衡数据在线流特征选择算法;Chen等[13]针对非平衡数据设计了基于边界区域的邻域粗糙集特征选择算法;但是,这些方法未充分考虑特征之间相关性。本文利用邻域互信息能够有效评估特征之间相关性的优势,结合基于最大决策边界的非平衡数据重要度与邻域容差互信息,定义了非平衡数据的邻域容差互信息,提出了基于邻域容差互信息的非平衡数据特征选择(Feature Selection for Imbalanced Data based on Neighborhood tolerance mutual information,FSIDN)算法。
群智能优化算法具有操作简单、全局寻优能力强等优势,通常用来解决特征选择问题。例如:张亚钏等[14]设计了一种混合人工化学反应和狼群优化的包装式特征选择算法;但是随着样本数和特征数的增加,该算法的计算量显著增加,甚至根本不适用。贾鹤鸣等[15]使用改进的斑点鬣狗优化算法设计了包装式特征选择方法;但是该方法仅能处理低维UCI数据集且计算效率偏低。鲸鱼优化算法(Whale Optimization Algorithm,WOA)[16]通过模拟鲸鱼的收缩包围、螺旋式更新位置和随机捕猎的觅食机制寻优,具有参数设置简单、收敛快和寻优精度高等特点。Agrawal 等[17]提出了基于量子计算WOA 的包装式特征选择算法,增强了搜索的多样化和收敛性。Tawhid等[18]基于二元WOA设计了包装式特征选择算法;但该算法须预先建立平衡分类性能的参数,计算耗时长。因此,这类包装式方法需要大量计算,非常费时,结果可能是局部最优解,存在过适应风险,较侧重于评价方法的使用和改进[19]。
尽管群智能优化算法在特征选择上具有优势,但是一些优化模型存在机制复杂、参数偏多等缺陷,导致求解精度与计算效率并不理想[20]。特征选择算法中参数的设置会影响选择结果,对于不同的数据集,参数设置往往是不同的,因此,找到最佳参数值对算法至关重要。Chen 等[13]使用粒子群优化(Particle Swarm Optimization,PSO)优化非平衡数据特征选择算法中的3个参数。姚晟等[21]利用PSO算法,搜索非平衡数据属性约简中每个数据集的最优2个参数值;但该算法仍使用固定的邻域半径,存在局限性且实验耗时长。鉴于WOA显著的寻优性能,本文首先定义新的非线性收敛因子和基于适应度值的惯性权重,提出自适应权重WOA(Adaptive Weight WOA,AWWOA);然后,利用改进WOA 优化基于邻域容差互信息的非平衡数据的特征选择算法中的参数。本文的主要工作为:1)为了克服评估函数单调性存在的局限性,在不完备邻域决策系统中定义了邻域容差互信息,并证明了它的非单调性;2)针对现有的非平衡数据特征选择算法未考虑不确定分类子集的影响的问题,引入最大决策边界的非平衡数据重要度度量,并将它与邻域容差互信息结合,提出了基于邻域容差互信息的非平衡数据特征选择算法;3)为解决传统WOA易陷入局部最优的问题,定义了新的非线性收敛因子和基于适应度值的惯性权重,设计了自适应权重的WOA;4)为了能够自适应地获取算法中参数的最佳值,利用改进的WOA,获取不同数据集上的最优参数。
1 鲸鱼优化算法
鲸鱼优化算法(WOA)[16]包括包围猎物、气泡网攻击和随机搜索3 种行为。
1)包围猎物。预设初始适应度值最大的鲸鱼所在位置为最优位置,鲸鱼群体会向最优位置靠拢,位置更新为:
其中:M为鲸鱼个体与最优位置间的距离;Q=2k×r1-k和E=2r2为系数变量;r1和r2为[0,1]的随机数;k=2 -为收敛控制因子,从2衰减到0;Maxiter为最大迭代次数;j为迭代次数;S′(j)为预设最优位置;S(j)为鲸鱼个体位置。
2)气泡网攻击。通过减小k值实现,-k<Q<k,由于k是递减的,所以Q也是递减的,因此鲸鱼个体逐渐靠近最优位置。利用螺旋线公式更新鲸鱼的个体位置,表达式为:
其中:M′表示当前鲸鱼个体到猎物之间的距离(当前最优位置);h为螺旋线常数;l为(-1,1)的随机数。鲸鱼捕捉猎物时螺旋游向猎物和收缩包围圈同步进行,则气泡网攻击的表达式为:
其中p为[0,1]的随机数。
3)随机搜索。当 |Q|>1 时,强制鲸鱼群体根据随机选择的个体更新位置,表达式为:
其中Srand(j)表示当前群体中随机一个鲸鱼的位置。
2 非平衡数据特征选择
2.1 非平衡数据的特征重要度
其中δ为不完备邻域关系下邻域半径且0 ≤δ≤1。
2.2 邻域容差互信息
在邻域决策系统中可信度和覆盖度能很好地评估系统的决策能力,具有较高的可信度和覆盖度的条件特征比决策更重要[10]。受此启发,为了有效处理不完备数据,运用邻域互信息作为处理非单调约简有效的评估函数的特性,本文在不完备邻域决策系统中定义了基于容差关系的可信度和覆盖度,并将它引入互信息中,提出了邻域容差互信息,使它有效度量特征之间的相关性。
证明 从定义11 和定义12 显然可以推导。
定理2给定INDS=AT=C∪D,对于任意条件特征子集B⊆C,H(D|B)不满足单调性。
证明 由B1⊆B2⊆C,根据定义13 可得:
证明 由定义12~14、定理2 和定理4 显然可得。
2.3 特征选择算法
接下来设计FSIDN 算法,如算法1 所示。
算法1 FSIDN 算法。
假设|U|=n,|C|=m,步骤1)~4)复杂度为O(n(n+1)m2),根据文献[9]中的计算方法,步骤5)~6)的计算复杂度为O(mnlogn),步骤7)~8)是对特征子集评估,如果邻域容差互信息低于特征全集的值,则步骤9)~10)需要搜索剩余特征集,直至满足终止条件,这4 步的计算复杂度较低,步骤11)和步骤13)为剔除冗余特征的计算过程。综上所述,算法1 总的计算复杂度约为O(mn2)。
2.4 基于WOA的参数优化选择
WOA 中的Q受收敛控制因子影响,收敛控制因子呈线性从2 衰减到0,导致算法易陷入局部最优,于是提出非线性的收敛控制因子。
定义20 非线性的收敛控制因子表示为:
其中:θ为控制常数,一般取为2;j为迭代次数,Maxiter为最大迭代次数。可知,在WOA 前期,式(33)保证k′递减速度较慢,使寻优空间更大,避免WOA 陷入局部最优;在WOA 后期,式(33)确保k′递减速度较快,使跳出局部最优。
适应度值反映了鲸鱼个体当前所在位置的优劣程度,对于适应度值较大的个体Gi,在Gi的局部区域内可能存在更优的点,为了找到这个点,应该减小惯性权重ω以增强局部寻优能力;相反地,对于适应度值较小的个体,应增大惯性权重ω以跳出局部最优[20]。受此启发,为了平衡WOA 的全局寻优能力和局部寻优能力,根据适应度值对惯性权重的取值进行了非线性动态调整。
定义21 基于适应度值的自适应惯性权重表示为:
其中:fiti为鲸鱼个体当前的适应度值,fitavg为所有鲸鱼个体当前适应度值平均值,fitmin为所有鲸鱼个体当前适应度值的最小值,ωmin为惯性权重最小值,ωmax为惯性权重最大值。
定义22 依据自适应惯性权重ω,改进的WOA 的收缩包围和螺旋捕食行为分别表示为:
其中:S′(j)为预设最佳位置;M′表示鲸鱼个体与最佳位置之间的距离;h为螺旋线常数;l为(-1,1)的随机数。
定义23 适应度函数表示为:
其中:ς和τ分别表示特征依赖度和特征子集长度的参数,参照文献[13,20],设置ς=0.9 和τ=0.1;|R| 为所选特征子集数;|C|为所有条件特征数。
算法1中涉及δ、α和β这3个参数,针对不同数据集,它们的取值往往是不同的,会影响特征选择的结果。因此,针对不同的数据集选取最佳参数值对算法1 至关重要。本节利用改进WOA设计这3个参数的优化选择算法,如算法2所示。
算法2 基于自适应惯性权重的WOA 参数优化选择算法。
假设鲸鱼群体大小为n,维度为m,初始化鲸鱼种群的计算复杂度为O(nm),计算依赖度的计算复杂度为O(nmlogn),计算惯性权重的计算复杂度为O(n),步骤5)~11)的计算复杂度为O(nm),步骤12)~15)的计算复杂度为常数项,因此算法2 总的最坏计算复杂度为O(nmlogn)。
3 实验及结果分析
3.1 改进WOA的性能分析
为了验证本文提出的自适应权重WOA(AWWOA)的寻优能力,选择文献[22]中8 个基准函数,基准函数具体信息如表1 所示。

表1 8个基准函数的信息Tab.1 Information of eight benchmark functions
将AWWOA 分别与海洋捕食者算法(Marine Predators Algorithm,MPA)[23]、PSO 算法[24]、WOA[16]、WOA[16]结合本文提出的基于适应度值的自适应惯性权重(WOA with adaptive Weight based on fitness values,WWOA)、WOA[16]结合本文提出基于非线性的收敛控制因子(WOA based on nonlinear Convergence control factor,CWOA)和基于自适应鲸鱼优化算法(Adaptive WOA,A-WOA)[25]这6 个优化算法进行比较,其中MPA、PSO 算法和WOA 均为固定惯性权重。表1 中单峰函数f1~f4主要用来测试算法的寻优精度和收敛能力,多峰函数f5~f8主要用来检测算法的全局寻优能力和避免局部收敛的能力。为了保证实验的公平性,上述7 种优化算法参数保持一致,即种群规模N=30,空间维度dim设置为30 和50,最大迭代次数Maxiter=300,每种算法分别独立运行30 次,其他参数均与文献[22]中保持一致。表2 展示了7 种优化算法在8 个基准函数的30 维和50 维上的最优值、最差值和平均值。

表2 7种优化算法在2种维度8个基准函数上的实验结果Tab.2 Experimental results of seven optimization algorithms on eight benchmark functions on two dimensions
本文实验硬件环境设置为Intel Core i7-3770 CPU 3.40 GHz 和8 GB 内存,软件环境配置为Windows 10 下的Matlab R2016a,本文所有实验结果中的粗体均表示结果最佳值。
由表2 可以看出,当维度dim=30 时,对于函数f1~f3和f5~f7,AWWOA 的寻优结果均是最优的,并且大幅优于其他6 种算法。值得一提的是,对于函数f7,AWWOA、A-WOA 和CWOA 的寻优结果均达到了最优值0;对于函数f4,PSO 算法取得的最差值为7 种算法中最优,但是AWWOA 取得的最差值与PSO 算法相差无几,并且AWWOA 取得的最优值和平均值均大幅优于其他对比算法;对于函数f8,PSO 算法取得的最优值为7 种算法中最优,AWWOA 取得的最差值和平均值均大幅优于其他对比算法,说明在函数f4和f8上,在迭代过程中,PSO 算法粒子更新的速度和位置较好,同时具有自适应寻优机制的AWWOA 表现出的寻优能力与PSO 算法接近,并且与WOA 和MPA 相比性能更好。另外,通过WOA、WWOA、CWOA 和AWWOA 的实验结果可以看出,在函数f2、f3和f5~f7上,WWOA 和CWOA 取得的结果明显优于WOA,在函数f1、f4和f8上,WWOA 和CWOA 取得的结果与WOA 相差无几,但是WOA、WWOA 和CWOA 取得的结果都比AWWOA差。总体地,当dim=30 时,AWWOA 表现出了较强的全局寻优能力和局部寻优能力。当dim=50 时,对于函数f1、f2、f5和f8,AWWOA 的寻优结果均是最优的,并且大幅优于其他6 种算法;对于函数f3,PSO 算法取得的最优值为7 种算法中最优,AWWOA 取得的最优值与PSO 算法相差无几,说明在函数f3上,在迭代过程中,PSO 算法粒子更新的速度和位置相对较好,使它获得的最优值较好,同时AWWOA 具有自适应的寻优机制,使它获得的最差值和平均值大幅优于WOA、PSO算法和MPA;对于函数f4,MPA 取得的最差值和平均值为7种算法中最优,AWWOA 取得的最差值和平均值与MPA 相差无几,并且AWWOA 取得的最优值为7 种算法中最优;对于函数f6,MPA 取得的最差值和平均值为7 种算法中最优,但是AWWOA 取得的最优值达到了理论最优值0;对于函数f7,MPA 取得的最优值和平均值为7 种算法中最优,但是AWWOA 取得的最优值和平均值,明显优于WOA 和PSO 算法,并且AWWOA 取得的最差值优于其他6 种算法,说明MPA 算法中的涡流和鱼类聚集效应,使它很好地避开了局部最优点,而AWWOA 中的自适应收缩包围和螺旋捕食机制的寻优能力与MPA 相差无几,并且明显优于WOA 和PSO 算法。总体地,当dim=50 时,AWWOA 也表现出了较强的全局寻优能力和局部寻优能力。综上所述,由30 维和50 维的测试结果可以看出,本文设计的非线性的收敛控制因子是有效的,同时WOA 系列算法的包围猎物、气泡网攻击和随机搜索的寻优机制明显优于MPA 和PSO 算法,并且AWWOA 的性能优于WOA、WWOA、CWOA 和A-WOA。AWWOA 具有较强的局部寻优能力和较高的寻优精度,能够较好地避免陷入局部最优。但是,AWWOA 在这两种维度上的8 个基准函数的实验结果并不是全优,究其原因是:由于AWWOA 一方面通过非线性的收敛控制因子调整WOA 的寻优空间,提升了WOA 跳出局部最优的能力;另一方面通过自适应惯性权重和螺旋线常数收缩包围和螺旋捕食行为,拉近了鲸鱼个体与适应度最优个体间的距离;尽管这些策略有效提升了AWWOA 在处理单峰与多峰函数时的寻优精度和收敛能力,但也会在一定程度上减弱自身的全局搜索能力。
3.2 FSIDN算法性能分析
为说明FSIDN 算法的分类性能,从UCI Machine Learning Repository(https://archive.ics.uci.edu/ml)和KEEL Data-Ming Software Too(http://www.keel.es/software/KEEL_template.zip)中选择了13 个非平衡数据集进行仿真实验,具体信息如表3 所示,其中,参照文献[13]和文献[26],%P 和%N 分别代表少数类样本和多数类样本占总样本的比例,每个类的样本数表示原始数据集中不同决策类中的样本数。在WEKA 软件中选择了4 种分类器J48、Naive Bayes、Random Forest 和SVM 验证FSIDN 算法的分类性能。FSIDN 算法涉及的3 个参数δ、α和β为AWWOA 寻优到每个数据集的这3 个参数的最优值。

表3 13个二分类非平衡数据集信息Tab.3 Information of thirteen binary imbalanced datasets
3.2.1 FSIDN在二分类数据集上的实验结果
为验证FSIDN在选择特征数量方面的优越性,在9个二分类数据集(Ionosphere、Heart、Pima、Vehicle3、Wdbc、Wpbc、Zoo、Arrhythmia 和Segment)上,将FSIDN 与F2HARNRS(Fast Forward Heterogeneous Attribute Reduction based on Neighborhood Rough Sets)[27]、WAR(Weighted Attribute Reduction algorithm)[28]、CfsSubsetEval(Correlation based feature selection Subset Evaluation)[29]、RSFSAID(Rough-Set-based Feature Selection Algorithm for Imbalanced Data)[13]这4 种特征选择算法进行对比。为了衡量对比算法的分类性能,针对二分类数据集采用选择最优特征子集、曲线下面积(Area Under Curve,AUC)[13]和分类精度[26]作为性能评价指标。表4给出5种算法选择的特征子集和特征数。参照文献[13],该二分类数据集上的所有实验均通过5折交叉验证实现。
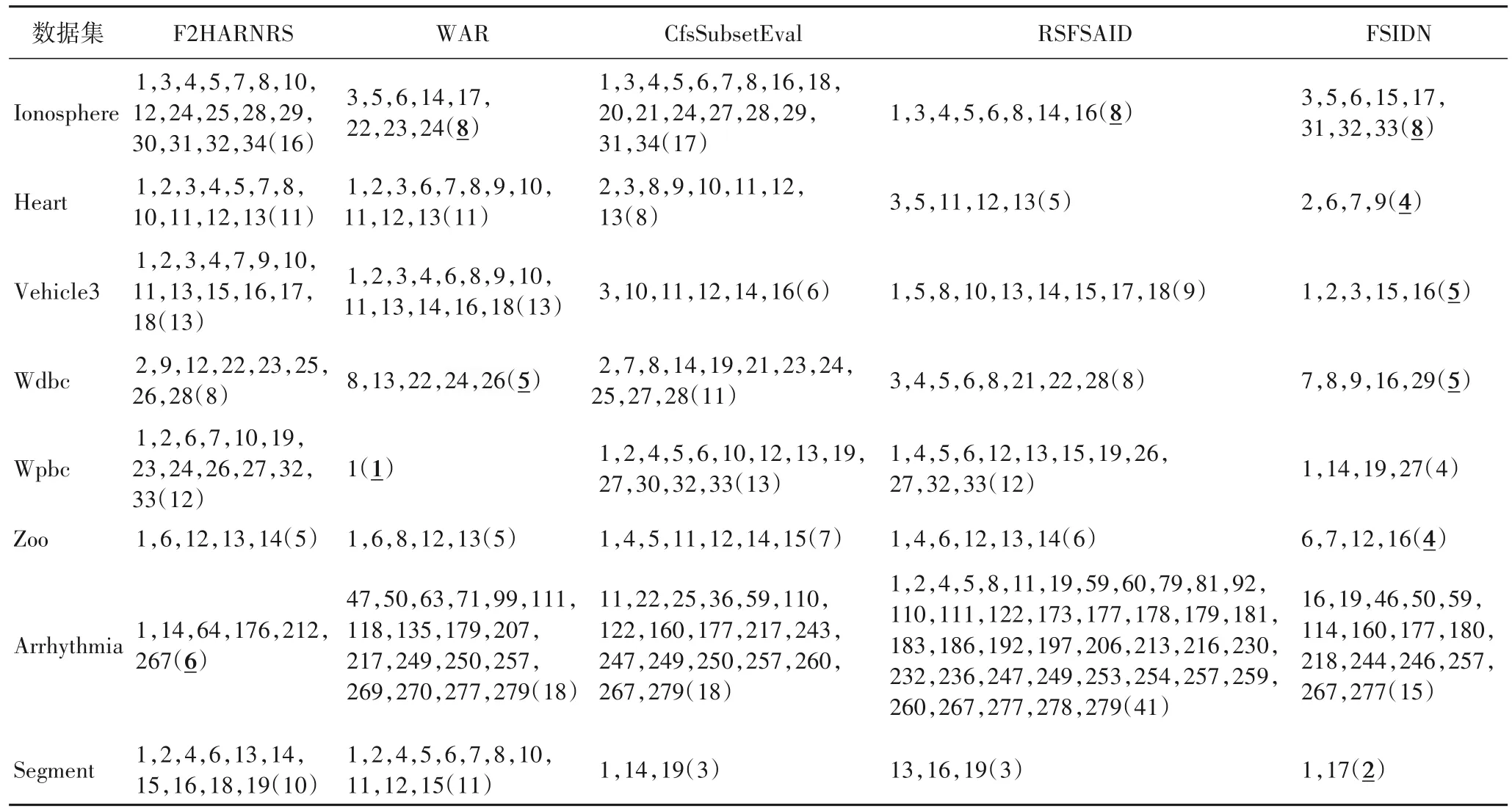
表4 五种算法在8个二分类数据集上选择的最优特征子集和特征数Tab.4 Optimal feature subsets and the number of features selected by five algorithms on eight binary datasets
由 表4 可以看 出,FSIDN 在Heart、Vehicle3、Zoo 和Segment 这4 个数据集上选出的特征数比其他4 种对比算法都少;对于Ionosphere 数据集,FSIDN 与RSFSAID、WAR 这3种算法所选特征数相同,均少于CfsSubsetEval 和F2HARNRS;对于Wdbc 数据集,FSIDN 与WAR 所选特征数相同,均少于RSFSAID、CfsSubsetEval 和F2HARNRS;对于Wpbc 数据集,虽然FSIDN 所选特征数比WAR 多2 个,但比RSFSAID、CfsSubsetEval 和F2HARNRS 这3 种算法少很多;对于Arrhythmia 数据集,FSIDN 所选特征数比F2HARNRS 多,但是少于WAR、CfsSubsetEval 和RSFSAID。综上所述,FSIDN 能够选择出最优/次优的特征子集。
为了验证FSIDN在ROC(Receiver Operating Characteristic)指标上的分类性能,选取Arrhythmia、Heart 和Vehicle3 这3 个数据集,与F2HARNRS[27]、WAR[28]、CfsSubsetEval[29]、RSFSAID[13]、SYMON(feature selection class data using SYMmetrical uncertainty harmONy search for high dimensional imbalanced)[30]和Original(针对原始数据处理的特征选择算法)这6 种算法进行对比,实验结果如图1 所示。由图1 可以看出,黑线(FSIDN 的结果)下的面积均大于其他6 种对比算法,因此,FSIDN优于其他算法。

图1 4种分类器下7种算法在3个二分类数据集上的ROCFig.1 ROC of seven algorithms on three binary datasets under four classifiers
为了验证FSIDN在AUC指标上选择的特征子集的有效性,分别与F2HARNRS、WAR、CfsSubsetEval、RSFSAID和SYMON、FRSA(Feature Reduction for imbalanced data classification using Similarity-based feature clustering with Adaptive weighted K-nearest neighbors)[26]、FSAWFN[25]这7种特征选择算法进行对比。为了方便验证和比较,根据文献[13]的实验设计方法,在J48、Random Forest、Naive Bayes和SVM这4种分类器上进行实验,如表5所示。

表5 4种分类器下8种算法在9个二分类数据集上的AUC值Tab.5 AUC values of eight algorithms on nine binary datasets under four classifiers
由表5 可以看出,在J48 分类器上,FSIDN 在Ionosphere、Heart、Pima、Wdbc、Wpbc 和Arrhythmia 这6 个数据集上取得的AUC 为8 种算法中最优;对于Vehicle3、Zoo 和Segment 这3个数据集,FRSA 最优,FSIDN 次优。在Random Forest 分类器上,FSIDN 在Ionosphere、Heart、Pima、Wdbc 和Wpbc 这5 个数据集上取得的AUC 为8 种算法中最优;对于Vehicle3 数据集,FSIDN 取得的AUC 值虽然比FRSA 低7.70%,但是比其他6 种算法高3.39%~25.54%;对于Zoo 数据集,虽然WAR、RSFSAID 和FRSA 取得的AUC 值比FSIDN 略优,但是FSIDN比另外4 种算法高了1.34%~33.90%;对于Arrhythmia 数据集,WAR 取得的AUC 为最优,但是FSIDN 比其他5 种对比算法 高0.96%~10.18%;对于Segment 数据集,RSFSAID、SYMON 和FASA 取得的AUC 为最优,但是仅 比FSIDN 高0.02%。在Naive Bayes 分类器 上,FSIDN 在Ionosphere、Heart、Pima、Vehicle3、Wdbc 和Arrhythmia 这6 个数据集上取得的AUC 为最优;对于Wpbc 和Segment 数据集,FSIDN 的AUC 值仅比最优值分别低1.34%和0.04%;对于Zoo 数据集,FSIDN 取得的AUC 值虽然比FRSA 低15.05%,但是比其他6 种算法高2.41%~31.16%。在SVM 分类器上,FSIDN 在Heart、Pima、Vehicle3、Wdbc、Wpbc、Arrhythmia 和Segment 这7个数据集上的AUC 为8 种算法中最优;对于Ionosphere 数据集,FRSA 取得的AUC 值为最优,但是FSIDN 仅比最优值低2.82%;对于Zoo 数据集,FSIDN 取得的AUC 值虽然比FRSA低33.93%,但是FSIDN 优于其他6 种对比算法,而且比这6种算法均高26.20%。整体而言,FSIDN 在4 种分类器上取得的AUC 值优于其他7 种对比算法,平均值分别高2.64%~14.18%、1.20%~8.06%、2.27%~7.48% 和5.90%~30.33%。综上分析可知,FSIDN 在大部分情况下均优于其他7 种比较算法,但是在Vehicle3、Zoo 和Segment 这3 个数据集上,FSIDN 略次于FRSA。究其原因是:FRSA 提前处理了非平衡数据,降低了数据对应的非平衡率,有利于达到较优的分类效果,但也降低了错分类的比例。
为了验证FSIDN 在不同分类器下的分类精度,选取Arrhythmia、Bands、Vehicle3、Wdbc、Wpbc 和Zoo 这6 个数据集,将FSIDN 与以下4 种特征选择算法NNRS[31]、ARMDNRS(Attribute Reduction of Mixed Data based on Neighborhood Rough Set)[32]、RSFSAID[13]和ARIHISUD(Attribute Reduction of Incomplete Hybrid Information System based on Unbalanced Data)[21]在Naive Bayes 和SVM 分类器下得到的分类精度进行比较,结果如表6 所示。由表6 可知,FSIDN 在Naive Bayes和SVM 分类器上的分类精度在大多数情况下为5 种算法中最优,分别比其他5 种对比算法平均分类精度高2.19%~10.71%和0.58%~8.98%。在Naive Bayes 分类器上,在5 个数据集上,FSIDN 得到的分类精度均为最大;但是在Zoo 数据集上,FSIDN 仅比最优的ARIHISUD 小了1.80%。在SVM分类器上,除了Wpbc 和Pima 数据集外,在其他4 个数据集上FSIDN 的分类精度均为最大,其中Pima 数据集上仅比最大值小0.88%,在Wpbc 数据集上仅比最优值小1.52%,但比另外3 种算法大1.13%~5.41%。究其略差的可能原因是:在这两个数据集上,FSIDN 滤除了个别相对重要的特征,因此FSIDN 能够得到较优的分类精度,具有良好的分类性能。
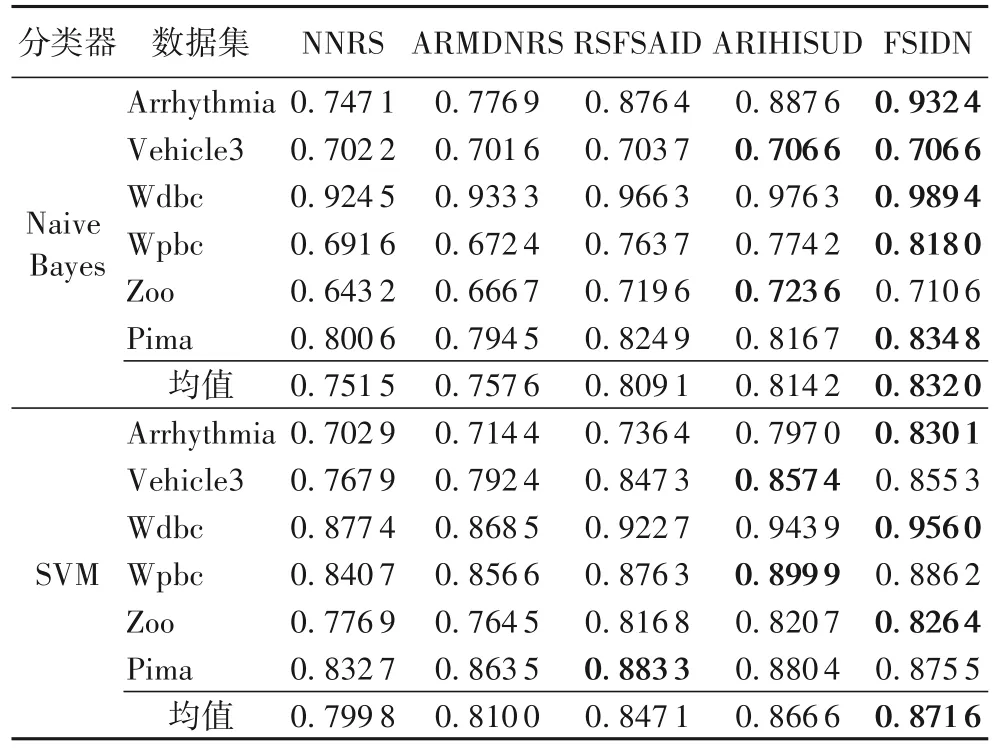
表6 Naive Bayes和SVM分类器下5种算法在6个二分类数据集上的分类精度Tab.6 Classification accuracy of five algorithms on six binary datasets under Navie Bayes and SVM classifiers
最后,为了验证FSIDN 的时效性,以CPU 运行时间为评价指标,参照文献[21],选取6 个数据集Arrhythmia、Bands、Vehicle3、Wdbc、Wpbc 和Zoo,选 择4 种对 比算法NNRS[31]、ARMDNRS[32]、RSFSAID[13]和ARIHISUD[21],如图2 所示。

图2 5种算法在6个数据集上的运行时间比较Fig.2 Comparison of running time of five algorithms on six datasets
从图2 可以看出,FSIDN 所需的时间整体上比另外4 种算法少。其中,在Pima、Vehicle3、Wdbc、Wpbc 和Arrhythmia这5 个数据集上,FSIDN 的运行时间明显比其他4 种算法少;在Zoo 数据集上,FSIDN 比RSFSAID 和ARIHISUD 耗时多,但是比NNRS 和ARMDNRS 耗时少。整体而言,FSIDN 算法具有更优秀的运行时效性。
3.2.2 FSIDN在高维基因数据集上的实验结果
为了验证FSIDN 在高维基因数据集上的分类性能,选择基因数大于500 的DLBCL、Lung、SRBCT 和Breast 这4 个数据集。为了初步降低算法的时空复杂度,采用Fisher Score 算法[10]对这4 个数据集降维,在WEKA 中验证Fisher Score 算法在不同维度下的分类精度。4 个数据集的分类精度随所选基因数的变化趋势如图3 所示。由图3 可知,每个基因数据集选择合适的维度分别为:DLBCL 数据集为200 维,SRBCT和Lung 数据集为50 维,Breast 数据集为100 维。参照文献[26],在高维数据集上的实验使用10 折交叉验证。
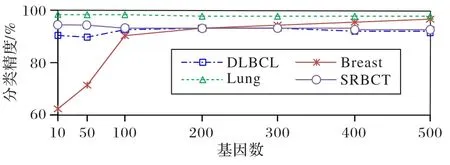
图3 4个高维基因数据集上的分类精度与所选基因数Fig.3 Classification accuracy and the number of selected genes on four high-dimensional gene datasets
针对这4 个高维基因数据集,采用几何均值准则(Geometric mean criterion,G-mean)[26]作为分类性能的评价指标,将FSIDN 与以下6 种特征选择算法:OSFS(Online Streaming Feature Selection)[33]、SAOLA(Scalable and Accurate OnLine Approach for feature selection)[34]、OFS_A3M(Online streaming Feature Selection using Adapted neighborhood rough set in terms of 3 Maximal evaluation criteria)[35]、OFS-Density(Online streaming Feature Selection method based on adaptive Density neighborhood relation)[36]、α-investing(streamwise feature selection using α-investing)[37]和FRSA[26],在KNN(K-Nearest Neighbors)、CART(Classification And Regression Tree)和SVM 分类器下的G-mean 值进行比较,结果如图4 所示。根据文献[26,37]中的实验参数和结果,OSFS 和SAOLA的显著性水平参数设置为0.01。α-investing 算法的参数设置与文献[34]一致。

图4 3种分类器下7种算法在4个高维数据集上的G-meanFig.4 G-mean of seven algorithms on four high-dimensional datasets under three classifiers
由图4 可以看出,在KNN 分类器下,FSIDN 在DLBCL、Lung 和SRBCT 数据集上的G-mean 值最大,FSIDN 在Breast数据集上的G-mean 值,虽然低于OSFS 和OSFS_A3M,但是高于SAOLA、OFS-Density、α-investing 和FRSA 这4 种算法。在CART 分类器下,FSIDN 在DLBCL、Lung 和Breast 数据集上的G-mean 值在7 种算法中明显是最大的,FSIDN 在SRBCT 数据集上的G-mean 值,低于OSFS 和FRSA,但是高于SAOLA、OSFS_A3M、OFS-Density 和α-investing。在SVM 分类器下,FSIDN 在Lung、SRBCT 和Breast 数据集上的G-mean 值在7 种算法中最大,虽然FSIDN 在DLBCL 数据集上的G-mean 值低于 SAOLA,但是高于 OSFS、OSFS_A3M、OFS-Density、α-investing 和FRSA 这5 种算法。综上所述,FSIDN 在这4 个非平衡高维基因数据集上拥有较强的分类能力。
3.2.3 FSIDN在多分类数据集上的实验结果
对于多分类数据集,两个多数类或少数类之间可能是非平衡的,多分类数据的特征重要度与二分类数据也是不同的,所以需要重新定义适应于多分类数据的特征重要度度量。
针对表7 中的多分类数据集,采用平均F 测度(Mean F-Measure,MFM)[13]作为分类性能的评价指标。为了验证FSIDN 在多分类数据集上的性能,分别与Original(原始)、RSFSAID-M[13]和SYMON[30]这3 种算法 在J48、Random Forest、Naive Bayes 和SVM 这4 种分类器上进行对比实验,实验结果如表8 所示。除了FSIDN,其余实验结果和参数设计均来自文献[13]。依据文献[13],采用MFM 评价指标,通过5 折交叉验证衡量多分类数据集上对比算法的分类性能。
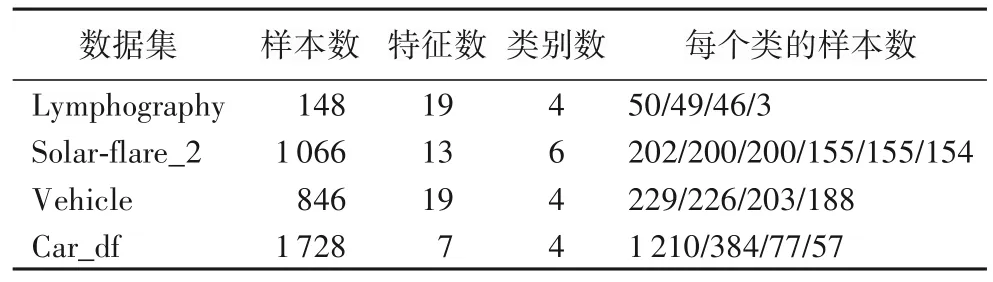
表7 4个多分类非平衡数据集的信息Tab.7 Information of four multi-class imbalanced datasets
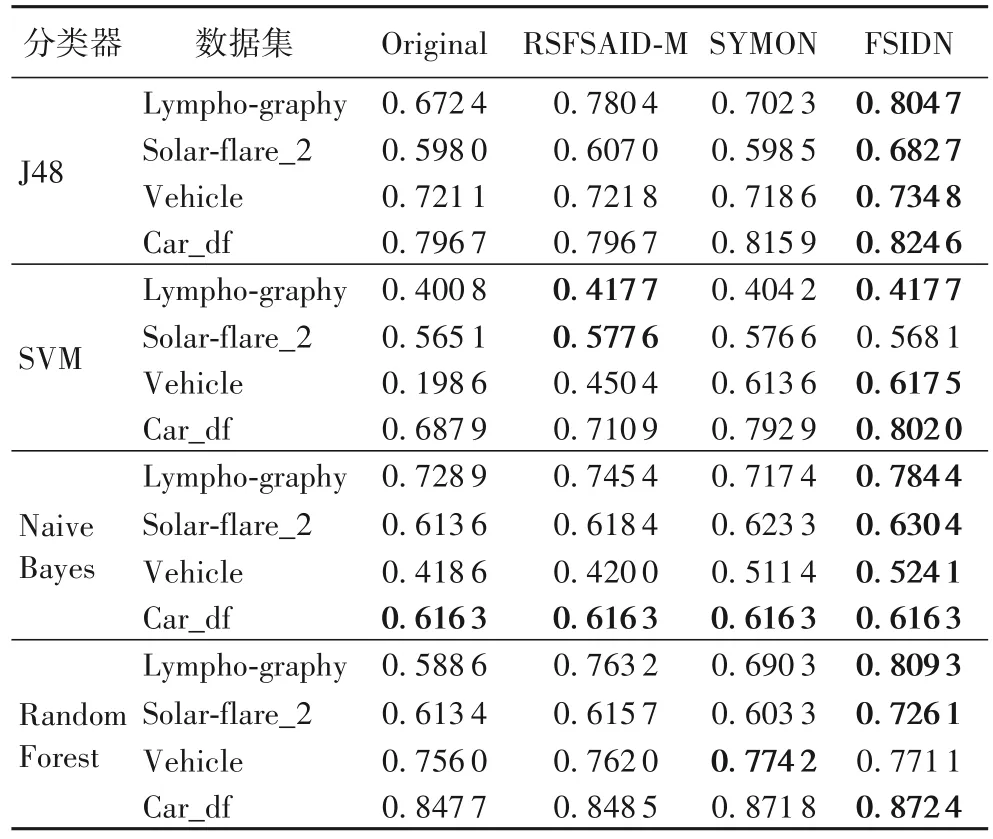
表8 4种分类器下不同算法在4个多分类数据集上的MFMTab.8 MFM of four algorithms on four multi-class datasets under four classifiers
由表8 可以看出,在Lymphography、Solar-flare_2、Vehicle和Car_df 这4 个数据集上,FSIDN 在J48 和Naive Bayes 分类器上明显优于其他3 种对比算法;在SVM 分类器上,除了Solar-flare_2 数据集,FSIDN 明显优于其他3 种对比算法,并且在Solar-flare_2 数据集上,FSIDN 仅比最优值低1.65%;在Random Forest 分类器上,除了Vehicle 数据集以外,FSIDN 优于其他3 种对比算法,并且在Vehicle 数据集上,FSIDN 仅比最优值低0.40%。究其原因是:在这两个数据集上,FSIDN可能存在样本误分类的情况。综上所述,FSIDN 在多分类数据集上同样也具有较好的分类性能。
4 结语
本文提出了基于邻域容差互信息和改进WOA 的非平衡数据特征选择方法。首先,考虑非平衡数据中类的不均匀分布和上下边界域的模糊性,针对二分类和多分类数据集,提出了两种非平衡数据的特征重要度度量;然后,为了充分反映不完备混合型邻域决策系统中特征的决策能力和特征之间的相关性,定义了邻域容差互信息;最后,将非平衡数据特征重要度度量与邻域容差互信息结合,提出了基于邻域容差互信息的非平衡数据特征选择算法,利用WOA 确定该算法的最优参数,针对WOA 存在易陷入局部最优的问题,引入非线性收敛因子和自适应惯性权重改进WOA。在13 个非平衡数据集上的实验结果表明,本文所提特征选择算法是有效的。但是,在非平衡数据集中,少数类中的信息往往是最重要的,如果少数类中存在噪声数据,可能会影响特征选择的结果,在未来的研究中,我们将进一步研究非平衡数据特征选择方法,降低噪声数据的影响。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
数学物理学报(2017年5期)2017-11-23
电子制作(2017年23期)2017-02-02
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
电测与仪表(2015年9期)2015-04-09
弹箭与制导学报(2015年1期)2015-03-11
振动工程学报(2014年4期)2014-03-01
计算机工程(2014年6期)2014-02-28
