
基于实例分割与毕达哥拉斯模糊决策的目标跟踪
2023-07-03 14:12赵元龙单玉刚赵康迪
计算机应用 2023年6期
赵元龙,单玉刚,袁 杰,赵康迪
(1.新疆大学 电气工程学院,乌鲁木齐 830017;2.湖北文理学院 教育学院,湖北 襄阳 441053)
0 引言
视频目标跟踪是计算机视觉的一个重要研究方向,普遍地运用在智能监控、移动终端、无人驾驶以及军事勘测等领域[1]。在实际场景目标跟踪中,如何解决尺度变化、相似性干扰、遮挡等问题成为研究热点。
近年来,随着深度学习在目标识别、检测等领域的广泛应用,越来越多的研究人员投入到基于深度学习的目标跟踪算法研究中。Danelljan 等[2]将卷积神经网络(Convolutional Neural Network,CNN)与空间正则化判别相关滤波器(Spatially Regularized Discriminative Correlation Filter,SRDCF)结合,提出了DeepSRDCF 算法,利用深度学习网络增强了特征的外观表征能力,但网络参数过多导致跟踪速度不满足实时性要求。为了进一步提高跟踪速度,Bertinetto 等[3]将全卷积网络融入孪生网络结构中提出了SiamFC(Siamese Fully-Convolutional)算法,通过卷积网络计算两条分支中图像的相关性,提高了算法的实时性,但复杂环境下的目标跟踪效果欠佳。Danelljan 等[4]提出的连续卷积算子跟踪器(Continuous Convolution Operator Tracker,C-COT)算法采用多分辨率高维特征图,将不同分辨率的特征图通过隐式插值的方式插入连续空间域,有效地提高了跟踪精度,然而深度特征的使用需要训练大量滤波器,导致算法复杂度较高。Danelljan 等[5]在C-COT 算法的基础上对滤波器降维,提出了高效卷积算子(Efficient Convolution Operators,ECO)算法,该算法利用混合高斯模型表征样本,降低了算法复杂度,跟踪速度虽然有所提升,但复杂场景中鲁棒性略有下降。Nam 等[6]提出的TCNN(CNN in a Tree structure)算法利用多个CNN 构成树结构,通过共享卷积层的所有参数,节省了存储空间,但没有解决部分帧中目标被遮挡致使跟踪失败的问题。Li等[7]将区域建议网络加入SiamFC 框架,提出了SiamRPN(Siamese Region Proposal Network)算法,虽然增强了目标的判别性,但跟踪过程中位置预测和尺度估计存在误差,容易出现漂移现象。Wang 等[8]在SiamFC 算法的基础上进行改进,提出了SiamMask 算法。SiamMask 将掩模特征应用于目标跟踪任务,实现了视觉目标分割(Video Object Segmentation,VOS)与视觉目标跟踪(Video Object Tracking,VOT)的统一,但对于复杂情景中目标遮挡、相似性干扰等问题仍需进一步优化。
上述算法均不能很好地应对尺度变化、相似性干扰、遮挡等问题,为此,本文提出一种基于实例分割与毕达哥拉斯模糊决策的目标跟踪算法。针对大多数正常帧,通过选择基于MaskIoU(Mask Intersection over Union)的匹配方式或基于外观的匹配方式权衡运行速度和精度;对于大范围遮挡或目标消失这样的特殊帧,使用基于卡尔曼滤波的轨迹预测法预测目标位置,有效地提高了成功率;同时采用基于毕达哥拉斯模糊决策[9]的模板更新机制DFPN(Decision Fusion of Pythagoras fuzzy Number)决定是否更新目标模板和更换匹配方式,有效地防止了漂移问题,提高了鲁棒性。实验结果表明,本文算法能够准确地在存在尺度变化、相似性干扰、遮挡等问题的视频序列上进行跟踪。
1 本文跟踪算法
在本文算法中,目标模板用来表示目标信息。如图1 所示,目标模板Tem包含目标的边界框Tbox、分割掩码Tmask,根据边界框Tbox内裁实例图块Tpatch。相应地,预测结果Pre包含了预测目标的边界框Pbox、分割掩码Pmask、根据边界框Pbox内裁实例图块Ppatch。设当前帧ft的目标状态为Ct,则:

图1 目标模板Fig.1 Object template
1.1 跟踪框架
本文跟踪算法属于检测跟踪(tracking-by-detection),使用YOLACT++(improved You Only Look At CoefficienTs)实例分割网络[10]作为检测器,与检测算法相比,实例分割网络能够提供更多的目标信息,例如掩码信息,以便跟踪部分实现多种匹配方式。跟踪框架如图2 所示,在实例分割网络的掩码分支(mask branch)上引入基于MaskIoU 的匹配方式,在边界框分支(box branch)上引入基于外观的匹配方式,同时融合卡尔曼滤波器(Kalman Filter,KF)来缩小候选目标范围和预测特殊情景中的目标位置。基于毕达哥拉斯模糊决策的模板更新机制DFPN 对预测结果进行质量鉴定,并以此决定是否更新目标模板和更换匹配方式。对当前帧的处理分为4 个步骤。

图2 本文算法的跟踪框架Fig.2 Tracking framework of the proposed algorithm
1)采用基于MaskIoU 的匹配方式生成临时的初步结果。首先确定目标的搜索区域reg(见图3),将它输入YOLACT++分割网络,生成大量的候选预测;然后采用基于MaskIoU 的快速匹配,在候选预测中找到初步预测结果。

图3 搜索区域regFig.3 Region of search reg
2)DFPN 判断初步预测结果的正确性和质量,确定目标模板是否更新。DFPN1、DFPN2 都是DFPN,只不过DFPN1、DFPN2 的输入不同,所以在DFPN 后加1 和2 来区分。DFPN1、DFPN2 的决策结果为D0 或者D1,D0 表示预测结果质量高,目标模板将完全被初步结果所取代,并生成最终结果;D1 表示预测结果质量低,初始结果将被丢弃,目标模板保持不变,将进一步采用其他方式预测目标。
3)判断当前帧ft是否需要基于外观的重检测。如果遇到目标漏检、遮挡等特殊情景,则需要使用基于外观的匹配方式重新检测目标。在进行基于外观的重检测时,是将整个帧而不是上述搜索区域送入YOLACT++网络;然后,通过基于外观的匹配方式从所有候选预测中选择一个新的结果,再次执行第2)步以生成新的最终结果。
4)判断ft是否需要轨迹预测法预测目标位置。如果目标消失或被大范围遮挡,则需要使用基于卡尔曼滤波的轨迹预测法预测目标位置;否则,不需要对ft重新检测,将对下一帧ft+1进行处理。
1.2 基于MaskIoU的快速匹配过程
对于大多数正常帧,使用MaskIoU 进行快速匹配,以提升跟踪速度。首先,根据历史帧的目标运动矢量信息(位置、移动速度等)确定目标的搜索区域reg(见图3),将它输入YOLACT++网络,生成大量的候选预测。然后采用基于MaskIoU 的匹配方式,在所有候选预测中找到初步预测结果。传统算法采用边界框交并比(Intersection over Union,IoU)匹配,只能从位置信息上匹配目标,容易造成模板漂移。本文使用MaskIoU,结合了目标的轮廓信息与位置信息,以减少模板漂移现象。
1.2.1 搜索区域
搜索区域的大小在一定程度上影响着分割与跟踪结果的质量[8]。如果对出现在场景中的所有对象都进行特征提取、匹配,将会增加系统的计算成本,因此有必要采用一定的方式预测运动目标可能出现的区域以减少冗余,提高目标跟踪的速度。SiamRPN 和SiamMask 以上一帧目标框为中心,将目标框尺寸放大2 倍作为当前帧目标可能出现的范围[7-8]。如图3 所示,本文搜索区域reg以上一帧目标框Tbox为基础,先利用卡尔曼滤波法预测当前帧目标的中心点,然后根据目标移动的快慢确定搜索区域的尺寸大小。
1.2.2 MaskIoU快速匹配
其中n表示候选预测个数。
在产生预测结果之后,保持Tmask、Pmask区域不变,将Tmask、Pmask以外区域的像素值变为0,记为:
其中函数Ω()可以将像素值变为0。
MT、MP提供了目标在模板帧和当前帧中的位置、外观和分割信息。计算MT、MP的IoU 值Ipos,该值表示模板帧中的目标与当前帧中目标的位置重合度,能够进一步从位置信息确认预测结果的正确性。视频序列的帧率越高,上下帧之间目标位置越接近,Ipos值越大,则预测结果是跟踪目标的可能性越大。将Im、Ipos送入模板更新机制DFPN1 中,DFPN1 将对预测结果进行质量评估,并根据评估结果决定是否更新目标模板以及是否进行外观匹配。
1.3 基于孪生网络的外观匹配过程
外观匹配网络是一个添加了空间金字塔池化(Spatial Pyramid Pooling,SPP)层的孪生网络[11],如图4 所示,它的输入是目标模板中的实例图块Tpatch和候选预测结果每个输入将生成它们各自的嵌入向量。这两个向量之间的欧氏距离较小,说明两个图块是相似的,反之亦然。

图4 加入SPP的孪生网络框架Fig.4 Architecture of Siamese network with SPP
标准CNN 的输入尺寸是固定的,当任意尺寸的图像块输入这些网络,会导致识别精度降低。将SPP 层放在特征提取层和第一个全连接层中间,可以使网络能够接受任意尺寸的图像块作为输入且不影响精度,避免了因缩放分割对象而造成的信息损失[11]。3 层空间金字塔的池化层结构为{(4×4),(2×2),(1×1)},改进后池化层结构为{(3×3),(2×2),(1×1)},如图5 所示。改进后的空间金字塔能够满足本文实验的要求,并且进入全连接层的特征向量由21(4×4+2×2+1×1)个减少到14(3×3+2×2+1×1)个,对应全连接层的神经元数量减少了1/3,在一定程度上提升了跟踪速度。

图5 改进后的SPPFig.5 Improved SPP
其中:Sim()表示计算相似度的孪生网络,n表示候选预测个数。
取预测结果对应的分割掩码Pmask,它充分展示了预测结果的轮廓信息。Pmask与目标模板分割掩码Tmask的IoU 值Spro能够从一定程度上体现目标轮廓的重合度。将Sm、Spro送入到模板更新机制DFPN2 中,与1.2.2 节一样,DFPN2 将根据预测结果质量评估结果决定是否更新目标模板以及是否使用基于卡尔曼滤波的轨迹预测法进行目标位置预测。
1.4 基于卡尔曼滤波的目标位置预测
在目标消失、大范围遮挡这类特殊情景下,无论是基于MaskIoU 的快速匹配还是基于孪生网络的外观匹配都会跟踪失败。针对这类特殊情景,本文提出了一种基于卡尔曼滤波的轨迹预测法预测目标位置。预测过程如式(6)所示:
其中:Δt表示目标速度系数,大小根据目标在相邻两帧之间Tbox的IoU 值确定,该IoU 值若小于设定阈值,表示目标运动速度非常大,需要在预测时提高速度分量的比重,此时将Δt设置为1;相反,表示目标运动缓慢,则将Δt设置为一个较小的数0.01。
1.5 基于毕达哥拉斯模糊决策的模板更新机制
1.5.1 毕达哥拉斯模糊决策
设X为一个论域,则该论域X中的一个毕达哥拉斯模糊集(Pythagorean Fuzzy Set,PFS)可表示为:
其中:对于集合P中的任意x∈X而言,映射μp:X→[0,1]表示它的隶属度;映射vp:X→[0,1]表示它的非隶属度。πp(x)表示它的不确定性,称之为犹豫度:
一个PFS 中的某一元素(μp(x),vp(x))称为毕达哥拉斯模糊数(Pythagorean Fuzzy Number,PFN),也可表示为p=p(μ,v),其中μ为隶属度,v为非隶属度。Peng 等[9]在考虑犹豫度的影响下提出得分函数:
将犹豫度纳入得分函数中,高效地利用了决策信息,在遇到隶属度与非隶属度相等而无法区分PFN 情形时,可以通过比较它们的犹豫度进行区分[9]。
1.5.2 模板更新机制
本文算法中将毕达哥拉斯模糊决策应用于模板更新机制。如图2 所示,基于MaskIoU 的快速匹配和基于孪生网络的外观匹配,产生的预测结果Pre都会由模板更新机制DPFN决定是否更新为模板。式(8)中μ和v为隶属度和非隶属度,在本文中分别表示为对当前预测结果更新为模板的赞成度和怀疑度;犹豫度πp(x)表示对赞成度或怀疑度的偏向。模板更新机制如图6 所示。

图6 模板更新机制DFPNFig.6 Template update mechanism DFPN
如图6(a),DFPN1 的输入有两个:一是MaskIoU 匹配过程中,候选预测与目标模板掩码Tmask的最高IoU 值Im;二是表示模板帧与当前帧目标重合度的值Ipos。令
如图6(b),DFPN2 的输入也是两个值:一是外观匹配过程中,候选预测中与目标模板图块Tpatch外观相似度的最高值Sm;二是表示模板帧与当前帧中目标轮廓重合度的值Spro。令
DPFN 的决策过程如式(11)所示:
2 实验平台与参数设置
本文算法使用Python 语言调用PyTorch 深度学习框架实现,操作系统为Windows 10 专业版,显卡使用NVIDIA GTX1080Ti GPU(11 GB),处理器为lntel Core i7 -11700K CPU @ 4.90 GHz。
实验中,YOLACT++实例分割网络的训练分为3 步进行,首先使用ImageNet 分类数据集对ResNet-101 进行预训练,然后将训练好的ResNet-101 与特征金字塔网络作为主干网络,最后在COCO 数据集上进行网络训练[12]。损失函数主要包含分类损失函数Lcls、边界框回归损失函数Lbox和Mask 损失函数Lmask,权重分别为1、1.5、6.125。使用随机最速下降法(Stochastic Gradient Descent,SGD)训练8×105次迭代,初始学习率为0.001,分别在第3×105、6×105、7×105和第75×104次迭代进行衰减,衰减为当前学习率的10%。
3 实验与结果分析
本文算法实现了目标分割与目标跟踪的统一,使用YOLACT++实例分割网络作为检测器,将掩模特征应用于目标跟踪,同时利用跟踪器进行目标模板更新,以便准确地对后续帧进行目标分割,因此从目标分割与目标跟踪两方面进行实验。
3.1 VOS评估
3.1.1 数据集
在VOS实验中,利用DAVIS(Densely Annotation VIdeo Segmentation)数据集进行评估,包括DAVIS 2016[12]、DAVIS 2017[13]。DAVIS 2016 数据集中有50 个高质量的视频序列,每个视频序列只标注一个目标。DAVIS 2017 数据集在DAVIS 2016 数据集的基础上进行了扩展,由90 个视频序列组成。不同于DAVIS 2016 的单目标分割,DAVIS 2017 数据集的每个视频序列均包含多个需要分割的对象,并且出现了不同于常见视频目标分割的多个挑战,如外观变化、尺度方向变化、目标遮挡、光线变化和运动模糊等。按照DAVIS 2016 中提出的方法进行评估,采用的评估指标包括区域相似度J和轮廓相似度F。区域相似度J为预测目标分割掩膜RM与真实掩膜RG之间的IoU 值,如式(12)所示;而轮廓相似度F权衡了轮廓精度PC和轮廓召回率RC,如式(13)所示。J&F为区域相似度J和轮廓相似度F的平均值,表示每个算法性能的总体度量。
3.1.2 评估结果
本文在480P 分辨率(720×480)的视频下进行测试。表1给出了本文算法和其他对比算法在DAVIS 2016 与DAVIS 2017 数据集上的性能指标实验结果,其中OnAVOS(Online Adaptive VOS)[14]、OSVOS(One-Shot VOS)[15]、OSVOSS(Semantic One-Shot VOS)[16]、MSK(即MaskTrack 算法)[17]使用掩码进行初始化,并使用在线微调的方法;FAVOS(Fast and Accurate online VOS)[18]、RGMP(Reference-Guided Mask Propagation)[19]、OSMN 算法[20]也使用掩码进行初始化,但不使用在线微调的方法;本文算法和SiamMask[8]使用边界框进行初始化,不使用在线微调的方法。从表中可以看出,本文算法在DAVIS 2016 上的J&F指标为83.65%、区域相似度J为84.0%,轮廓相似度F为83.3%,优于所有不使用在线微调的算法,仅略低于使用在线微调的OnAVOS 算法,相较于SiamMask,J和F分别提升了12.3 和15.5 个百分点;在DAVIS 2017 上的J&F指标为69.05%、区域相似度J为69.6%,优于其他对比算法,相较于SiamMask,J和F分别提升了15.3 和10.0 个百分点。
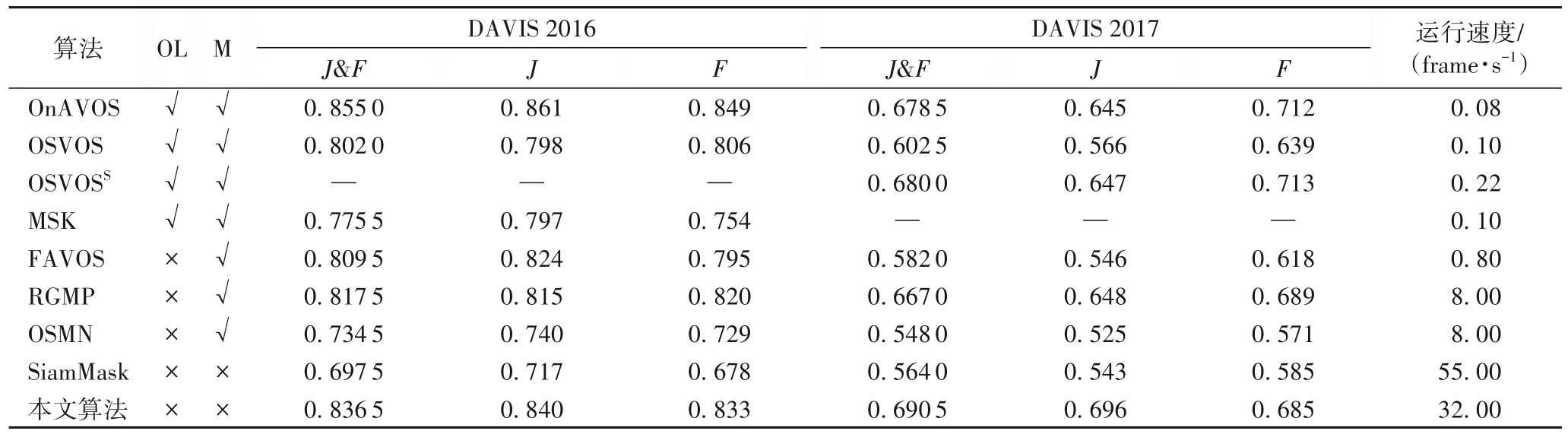
表1 不同算法在DAVIS 2016与DAVIS 2017数据集上的实验结果Tab.1 Experimental results of different algorithms on DAVIS 2016 and DAVIS 2017 datasets
相较于DAVIS 2016 数据集,DAVIS 2017 更具有挑战性,在DAVIS 2016 上性能较好的算法,在DAVIS 2017 数据集上不一定有较好的表现,如OnAVOS 算法,而本文算法在两个数据集上都有较高的性能指标,表明本文算法具有更好的稳健性。
3.2 VOT评估
3.2.1 数据集
对于VOT 实验,在VOT2016[21]、VOT2018[22]数据集上对本文算法进行评估,VOT2016 和VOT2018 均包含60 个具有挑战性的视频序列,这60 个序列中包含了单目标跟踪领域中的难点问题,如光照变化、尺度变化、外观变化、相似背景干扰、运动模糊和遮挡等。将VOT2016 中一些易于跟踪且准确度较高的视频序列进行更换,形成了VOT2018 序列。VOT2018 重新标定了序列的真值,给出了更为精细的标注信息。根据VOT 的评估标准,本文采用以下3 个指标显示跟踪性能:准确率(A)用于评价算法跟踪目标的准确度,值越大准确度越高;鲁棒性(R)表示跟踪算法的稳定性,值越小稳定性越高;预期平均重叠率(Expected Average Overlap rate,EAO)是一种综合考虑跟踪算法准确性和鲁棒性的度量指标,值越大表示跟踪器性能越好。
3.2.2 评估结果
将本文算法与SiamMask[2]、ATOM(Accurate Tracking by Overlap Maximization)[23]、ECO[5]、ASRCF(Adaptive Spatially-Regularized Correlation Filters)[24]、C-COT[4]、TCNN[6]、SiamRPN[7]、DaSiamRPN(Distractor-aware Siamese RPN)[25]、SiamRPN++(SiamRPN with Deep Networks)[26]、LADCF(Learning Adaptive Discriminative Correlation Filters)[27]、SPM(Series-Parallel Matching)[28]、RCO(Continuous Convolution Operators with Resnet Features)[22]、UPDT(Unveiling the Power of Deep Tracking)[29]、MFT(Multi-Hierarchical Independent Correlation Filters for Visual Tracking)[30]和GFS-DCF(Group Feature Selection and DisCriminative Filter)[31]算法进行对比分析,在不同数据集上的对比结果如表2 所示。在VOT2016 数据集上,在A 相差不大的情况下,本文算法的R 达到了最优,EAO 为0.475,高于其他对比算法。在VOT2018 数据集上,A为0.586,仅次于SiamMask 和ATOM[23];R 为0.183,虽然没能排在前列,但优于SiamMask 和ATOM;EAO 为0.421,优于其他对比算法。相较于SiamMask 算法,虽然本文算法的A略低,但R 和EAO 指标均较好,在VOT2016 数据集分别降低和提高了7.2 个和4.2 个百分点,在VOT2018 数据集分别降低和提高了9.3 个和4.1 个百分点。
在VOT 实验中,本文算法的A、R 和EAO 虽然没能同时优于其他对比算法,但各指标均排在前列。VOT2016 和VOT2018 的测试中,EAO 值均高于其他对比算法,表明本文算法有着不错的跟踪性能。同时,本文算法的运行速度为32.00 frame/s,满足实时性要求。
3.2.3 与其他算法的定性对比
为验证本文算法的有效性,选取VOT2018 数据集中具有代表性的视频序列做定性对比实验,测试结果如图7 所示,由上到下bmx、basketball、dinosaur、girl这4个视频序列包含尺度变化、相似目标干扰、相似背景干扰、目标遮挡等挑战场景。

图7 在不同视频序列上的定性对比Fig.7 Qualitative comparison on different video sequences
1)目标尺度变化下的对比。目标在运动过程中,尺度变化是很常见的,当目标的尺度变化过快,会对跟踪效果产生影响。从bmx 序列的跟踪效果可以看出,当目标的尺度发生快速变化时,SiamMask 只预测到了目标的一部分,本文算法有更准确的预测结果。
2)相似目标干扰下的对比。当目标与周围存在的相似干扰物共同进入检测视野时,容易发生混淆导致跟错目标。basketball 序列的第647 帧到664 帧,目标被相似物体部分遮挡,SiamMask 将目标与干扰物共同预测为跟踪对象,而本文算法准确地预测了结果。
3)相似背景干扰下的对比。目标图像与图片背景反差不明显,比如目标图像颜色与背景颜色基本相同,会干扰对目标的辨识,影响跟踪的性能。dinosaur 序列中背景颜色与目标颜色相差较小,从结果来看,本文算法准确地完成了对目标的跟踪。
4)目标遮挡情况下的对比。由于周围环境的复杂性和其他物体的干扰,目标在运动过程中会被部分遮挡或者完全遮挡(目标消失)。在girl 序列中当目标被遮挡时,SiamMask将遮挡物预测为跟踪对象,而本文算法没有丢失目标,完成了对目标的跟踪。
3.3 消融实验
为验证不同模块对目标跟踪性能的影响,本文在VOT2018 和DAVIS 2017 数据集上进行消融实验。首先,移除模板更新机制DFPN,采用单一的MaskIoU 匹配或外观匹配(Appearance),此时目标模板一直更新。然后,同时采用MaskIoU 匹配和外观匹配,并增加基于毕达哥拉斯模糊决策的模板更新机制DFPN 进行目标模板更新和匹配方式选择。从表3 可以看出,仅采用MaskIoU 匹配,跟踪速度是可观的,但是模板漂移问题导致跟踪性能不佳;仅采用外观匹配,跟踪性能有所提升,但复杂的深度网络导致跟踪速度仅19 frame/s。增加模板更新机制DFPN 进行目标模板更新和匹配方式选择(MaskIoU 或外观),EAO 指标达到了0.403,速度满足实时性要求。在此基础上,增加卡尔曼滤波器,跟踪性能有所提升,EAO 达到了0.421。

表3 消融实验对比结果Tab.3 Comparative results of ablation experiments
单一的匹配方式中,目标模板无论正确与否,总是被更新,因此跟踪性能不均衡。从表3的消融实验结果可以观察到,增加DFPN,跟踪性能有所提升。DFPN1用来鉴定MaskIoU 匹配过程中目标模板的质量,DFPN2 用来鉴定外观匹配过程中目标模板的质量,整个DFPN 所起到的作用是将3种匹配方式的优势结合在一起,进而均衡跟踪的速度与精度。
3.4 分割跟踪定性分析
本文算法在DAVIS 和VOT 序列上的分割跟踪定性结果如图8 所示,其中,第1 行为DAVIS 2016 上的单对象分割效果,掩膜轮廓展示了像素级的分割结果;第2~3 行为DAVIS 2017 上的多对象分割效果,图像中多个目标以不同的轮廓突出显示。第4 行图像序列同时存在于VOT2016 和VOT2018 中,第5 行只存在于VOT2016 中,第6 行只存在于VOT2018 中,从这3 行视频序列的分割跟踪结果可以清晰观察到,不论在简单场景,还是复杂场景,本文算法都能产生准确地分割掩码和目标边界框。这6 个视频序列,包含了目标形变、光照变化、尺度方向变化、目标遮挡、相似性干扰等挑战场景。不难看出,即使存在干扰,本文算法仍能够产生准确的分割掩码和匹配到正确的目标,实现持续稳定的跟踪。

图8 本文算法在VOT和DAVIS数据集上的定性分析结果Fig.8 Qualitative analysis results of the proposed algorithm on VOT and DAVIS datasets
4 结语
本文提出了一种基于实例分割与毕达哥拉斯模糊决策的目标跟踪算法,在深度学习实例分割网络YOLACT++的mask 分支上引入MaskIoU 匹配,以提升速度;在box 分支上引入外观匹配,以提升精度;同时融合卡尔曼滤波算法缩小候选目标范围和预测特殊情景中的目标位置。提出的基于毕达哥拉斯模糊决策的模板更新机制决定是否更新目标模板和更换匹配方式,以应对不同场景中的目标跟踪问题。在DAVIS 和VOT 数据集上的实验结果表明,即使在尺度变化、相似性干扰、遮挡等复杂场景下,本文算法仍能够实现准确稳定的跟踪。在后续的研究中,将考虑改进YOLACT++网络结构以提高分割精度和设计新的目标模板更新机制,进一步提高算法的性能。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
阅读(快乐英语高年级)(2022年6期)2022-06-17
家庭影院技术(2021年10期)2021-11-20
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
通信学报(2019年5期)2019-06-11
通信技术(2018年3期)2018-03-21
数学物理学报(2017年5期)2017-11-23
紫禁城(2017年6期)2017-08-07
浙江大学学报(工学版)(2015年4期)2015-03-01
