
基于双向稀疏的多视图子空间学习算法
2023-07-07 06:56饶雨泰
计算机应用与软件 2023年6期
杨 凡 饶雨泰
(湖北广播电视大学软件工程学院 湖北 武汉 430074)
0 引 言
随着多视点数据采集技术的不断完善,多视点学习已成为一个研究热点,如何处理多样化和复杂的数据是多视图学习中一个具有挑战性的问题[1-2]。
不同类型的视觉描述可以代表不同的特征,这种对同一对象通过不同方法或不同层次获得的数据称为多视图数据现实世界数据具有高维、复杂和冗余的特点[3]。因此,对多视图数据的内在结构进行分析是非常困难的。由于在许多情况下数据的标签难以获取,为了解决这一问题,提出一系列无监督多视图学习方法。主要分为两类:(1) 基于图的多视图学习:这类方法的目的是利用所有视图学习一个融合图,然后在融合图上使用特殊聚类等有效算法得到结果[4-5];(2) 基于共享子空间的多视图学习,即基于所有视图共享一个共同表示的假设,这类方法旨在学习所有视图的统一特征表示[6-7]。为了进一步提升传统的无监督学习方法的性能,研究如何处理异常值成为了无监督学习的难点之一。为了减少数据中异常值的影响,提高多视图方法的鲁棒性。主要包括两种方法:(1) 基于稀疏范数的鲁棒多视图学习。例如,Pu等[8]采用L1范数代替L2范数,提高了模型的鲁棒性。(2) 基于低秩稀疏分解的鲁棒多视图学习。例如,洪敏等[9]提出一种鲁棒的学习方案来去除错误和噪声,并学习可靠的低阶表示。传统的多视图方法很难选择一个合适的统一表示维数,许多方法使得统一表示的维数与簇的个数相同。但是,如果多视图数据是高维的,且簇数较少,那么采用上述方案可能会丢失太多的信息。如果选择大维数的特征提取,可能无法完全去除冗余特征。因此,如何选择合适的特征维数也是多视图学习的难点之一。
为了有效解决传统的多视图子空间学习方法不能同时找到有效的子空间维数和处理孤立点问题,提出一种基于双向稀疏性的多视点子空间学习方法。通过多个数据集验证了本文方法的有效性。
1 基于双向稀疏的多视图子空间学习
1.1 建立模型
假设现在有V个视图。令χ={X(1),X(2),…,X(V)}表示所有视图的数据。X(v)∈Rdv×n代表第v个视图的数据矩阵,在传统的矩阵分解中,可以找到两组矩阵因子U(v)∈Rdv×rv和L(v)∈Rrv×n来近似每个视图,U(v)∈Rdv×r代表第v个视图的投影矩阵,dv表示第v个视图的维数,n表示数据大小,r代表特征提取的维数,V代表视图数。
R(v)≈U(v)L(v)
(1)
可以将L(v)视为X(v)的一个潜在低维表示。由于不同视图之间存在相关性,该方法不适用于多视图问题。为了解决这个问题,假设多视图数据的不同特征来自相同的潜在空间,即低维表示。当将不同的数据映射到一个共享的、低维的和潜在的空间时,便可以得到一个紧凑的数据分布,揭示不同视图之间的统计关系和基本结构。因此,对于所有视图,存在:
X(v)≈U(v)L
(2)
式中:L∈Rr×n。然后,可以使用共享的低维表示来解决多视图问题。其中一个常见的重构过程可以表述为一个Frobenius范数优化问题,其定义如下:
(3)
尽管上述方法可以得到良好的多视图数据的低维表示,但它仅考虑多视图数据具有共享空间,而忽略了共享子空间本身的固有结构。另外即使已经将多视图数据降到低维,低维表示也可能存在冗余特征或相关特征。因此,固有表示应该是用于特征提取的行稀疏矩阵。此外,实际数据并非都是理想的,可能存在一些异常值。因此,固有表示应为样本的列稀疏矩阵。但是固有的低维表示不是一个具有稀疏行和稀疏列的矩阵。因为如果是这样,则低维表示也会优化异常值。考虑到以上几点,将低维表示分为两部分:第一部分是用于优化特征的行稀疏矩阵,第二部分是用于优化样本的列稀疏矩阵。目标函数可以表述为:
(4)
式中:P、Q∈Rr×n代表公共表示矩阵,P是行稀疏矩阵,Q是列稀疏矩阵。由于P是一个行稀疏矩阵,然后通过应用正则化,可以将其表示为:
(5)
考虑到这是一个NP难题,很难解决,决定把它放宽为:
(6)
式中:p∈(0,1)表示稀疏性。那么本文方法的目标函数可以表示为:
(7)
由于P和Q在公式中具有相似的状态,因此设λ=β1=β2。考虑到不同的视图应该在问题中扮演不同的角色,使用参数来平衡不同视图的有效性。在数学上,目标函数是:
(8)
式中:γ是一个平滑因子,并将其设置为1。最后,在目标函数上添加U(v)的Frobenius范数,以避免出现病态问题并减少变量的自由度。所以本文方法的最终目标函数是:
(9)
1.2 优化算法
从式(9)可以看到需要求解四组变量。U(v)是所有视图X(v)的投影矩阵。P和Q是所有视图的统一表示。α是包含平衡不同视图重要性的权重系数。但由于公式中所有变量都是耦合的,直接求解式(9)比较困难。因此,提供了一种有效的变量交替更新算法,即固定了三组变量,只对剩下的一组变量进行了交替优化。
(1) 固定P、Q和α,优化U(v)。当P、Q和α固定时,需要优化一组投影矩阵U(v)。显然,目标函数中的第二项和第三项与U(v)不相关。然后,优化子问题变为:
(10)
上述规划问题是凸的,并且可导,因此可以通过其导数得到封闭形式的解,即:
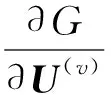
(11)
将导数设置为零,可以得到:
(12)
(13)

(14)
式中:D∈Rr×r是一个对角矩阵,第i个对角元素为:
(15)
因此,可以通过迭代地解决以下问题来解决式(13)。
(16)
新问题是凸的,可以得到它的封闭形式的解。
(17)
(18)
与P相似,式(18)可以通过迭代解决以下问题来解决。
(19)
其中S与D相似,S∈Rn×n,且:
(20)
式(19)是一个西尔维斯特方程,难以用封闭形式求解。因此,采用梯度下降法对其进行求解。假设已经完成了第k次迭代。那么第(k+1)次迭代是:
(21)
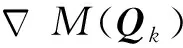
(22)
式中:tk是迭代步长,并通过精确线性搜索方法进行固定。即:
(23)
(24)

(25)
可以对α(v)取导数并将其设置为零。
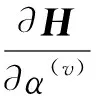
(26)
然后可以得到α(v)如下:
(27)
由于h(v)≥0且c<0,因此α(v)的导出结果满足其非负性条件。算法1中列出了本文方法的过程。
算法1本文算法
输入:数据矩阵X(v)∈Rdv×n,参数λ1,p,λ2,c。
输出:稀疏矩阵P,Q∈Rr×n。

循环:
2.利用式(12)更新投影矩阵U(v);
3.利用式(17)更新行稀疏公共矩阵P;
4.利用式(21)更新列稀疏公共矩阵Q;
5.利用式(27)更新权值系数α(v);
6.直到收敛, 算法结束。
2 算法分析
2.1 收敛性分析
引理1假设a、b是非零向量,那么对于任何p∈(0,2],有:
(28)

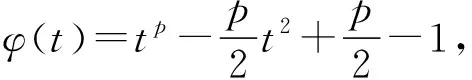
φ′(t)=ptp-1-pt=pt(tp-2-1)
(29)
分析式(29)。对于任何p∈(0,2],如果t∈(0,1],φ′(t)≥0且如果t>1,φ′(t)<0。所以t=1是最大值点。可以发现,当t=1时,φ(t)=0。即当t>0时,φ(t)≤0始终成立。

(30)
等价于以下不等式:
(31)
引理2通过引理1,可以证明由式(16)获得的最优解也是使式(13)不增加的解。

F(P*)+λtr((P*)TDP*)≤F(P)+λtr((P)TDP)
(32)
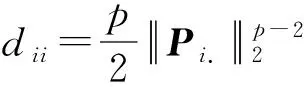
(33)
通过引理1,可以得到:
(34)
将式(34)代入式(33),结果得到:
(35)
等价于:

(36)
定理1通过采用算法1中的优化程序,式(9)中SLBS的目标函数值不会增加。
证明:设
(37)

(38)

(39)
然后,由于更新的α(v)分别是式(25)中问题的最优解,因此以下不等式成立。
(40)
结合以上结论,可以得到结果。
2.2 计算复杂度
由于SLBS是以一种替代的方式解决的,因此可以对每个子步骤的计算复杂度求和,以计算它们的总计算复杂度。每个子步骤的计算复杂度如下:
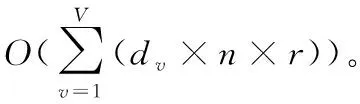

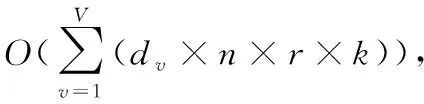

2.3 参数确定
参数是模型的重要部分,参数的确定与模型的性能密切相关。有许多参数需要在式(9)中确定。但是可以将它们分为两部分。其中一部分是优化变量,例如P、Q、α和U(v),它们需要在每次迭代中进行优化。另一部分是需要在SLBS迭代之前确定的超参数,例如λ1、λ2、p和c。
由于每个超参数都有其独特的影响,因此可以根据先前的研究凭经验确定一些超参数。对于所提出的模型,将列出每个超参数如何确定。对于p,它是为了保证P和Q的稀疏性而设计的。最佳稀疏近似为p=0,但这是一个NP难题,难以解决。大多数论文将p设为1,因为它是最佳凸逼近。这里设置p=1/2而不是p=1,以获得更精确的稀疏近似p=0。至于c,它是用来衡量视图的重要性的。不同的c可以改变视图的权重。
对于参数λ1和λ2,由于它们被用来平衡损失函数、稀疏表示和正则化因子的重要性,因此对于最终性能非常重要。由于没有关于这些参数的先验信息,因此在[10-5,10]中进行了试凑验证。
3 实验与结果分析
3.1 数据集描述
选择6个具有不同特征的标准数据集来评估本文方法的有效性。在许多实际应用中,通常使用6个多视图数据集。
(1) MSRC_v1数据集由240幅图像组成,分为8类。根据文献[10],选取了由人脸、树木、飞机、建筑、自行车、奶牛、汽车组成的7个类别,每个类别有30幅图像。为了区分所有场景,提取了256个局部二值模式(LBP)、48个颜色矩(CMT)、1 302个中心点、100个方向梯度直方图(HOG)、512个GIST和200个SIFT特征。
(2) Handwritten numerals(HW)数据集由0~9个10位数类的2 000个数据点组成,每个类有200个数据点。6个特征可用于聚类:47个Zernike矩(ZER)、240个像素在2×3窗口中的平均值(PIX)、64个Karhunen-love系数(KAR)、216个轮廓相关性(FAC)、76个字符形状的傅里叶系数(FOU)和6个形态学(MOR)特征。
(3) Caltech_7数据集包含8 677幅图片,属于101个类别。根据文献[11],选择了最常用的7类,即人脸、多拉比尔、史努比、温莎椅、摩托车、加菲猫和停车标志。对数据进行采样并选取了441幅图片作为Caltech_7,并提取了相同的视觉特征:LBP、HOG、GIST、CMT、CENTRIST和SIFT。
(4) Scene15由4 485幅图像组成,这些图像属于15个类别:高速公路、城市内部、高层建筑、街道、郊区住宅、森林、海岸、山脉、野外、卧室、厨房、客厅、办公室、工业和商店,提取了6个视觉特征:SIFT、SURF、PHOG、LBP、GIST和小波纹理(WT)。
(5) MvYale包含了15位志愿者的165幅图片,每个人都有15幅图片。该数据集是一个灰度数据集,主要包括光照、面部表情和姿势的变化。为了有效地分析数据,提取了5种视觉特征:SIFT、HOG、LBP、WT和GIST。
(6) KSA包括4个受试者,他们执行5个动作。在这里,每个动作都被视为一个类。从每个动作中选择2 000个视频帧,形成10 000个示例的子集。这里使用了4个姿势特征,即文献[12]中提取的fJJ_d、fJL_d、fLL_a和fPP_a。
在6个数据集中,本文方法的4个需要提前确定的超参数如表1所示。

表1 各个数据集的超参数选择
3.2 实验对比
由于本文关注的是无监督学习,因此将SLBS与一些可预期的方法进行了比较,并使用K-means聚类方法来评估本文方法的有效性。比较方法如下。
(1) 最佳单视图(BSV):在每个单一视图上使用SLBS,并在低维表示上使用K-means来获得聚类结果。
(2) 组结构稀疏矩阵分解(GSSMF):在文献[13]中提出的一种通过结构稀疏来学习将潜在空间分解成维度的方法。
(3) 多视图光谱嵌入(MSE):在文献[14]中提出的一种多视图图学习方法。
(4) 多视图非负矩阵分解(MVNMF):在文献[15]中提出的一种基于NMF的多视图聚类方法。
(5) 自动加权多图学习(AMGL):在文献[16]中提出的另一种多视图图学习方法。
(6) 大规模多视图子空间聚类(LMVSC):在文献[17]中提出了一种具有线性时间的新颖的多视图子空间学习方法。
对于实验结果,采用两种不同的度量来评估所提出的SLBS聚类方法的性能,即聚类准确度(ACC)和标准化互信息(NMI)。
所有实验都是在配置为64位Intel Core i7-6700CPU@3.4 GHz/16 GB RAM计算机上的MATLAB2016A上进行的。
3.3 SLBS与其他算法之间的比较
表2和表3分别给出了不同特征提取维度下所有比较方法的NMI和ACC结果。就聚类结果而言,有以下观察结果:

表2 不同方法对6个不同子空间维数数据集的ACC

表3 不同方法对6个不同子空间维数数据集的NMI
与度量标准ACC的其他特征提取方法相比,SLBS在大多数情况下在大多数数据集上表现最佳。特别是在Scene15数据集上,SLBS比其他方法的最佳ACC高出近0.1,在大多数数据集中超过其他方法的平均ACC 0.05以上。对于另一个度量指标NMI,可以得到类似的结论。实验结果表明了本文方法的有效性。
至于最佳单视图方法(BSV)与以前的多视图方法的比较,后者并不总是表现得更好。这可能是由于以前的方法分别表征每个视图数据的结构并通过简单的加法运算将它们组合在一起所引起的。但是与加权多视图方法相比,最佳单视图方法有时也会有更好的性能。这可能是由于统一子空间的双向稀疏性所导致的。
基于图的多视图特征选择方法在所选特征维数与数据类别数目相同的情况下表现得非常好。还将本文方法与基于图的方法进行了比较,发现本文方法在大多数情况下都优于它们的最佳结果。这有效地证明了本文算法的有效性。
通过对基于矩阵分解方法的ACC和NMI的分析,可以得出ACC和NMI随着维数的增加先增大后减小。由于随着维数的增加,学习的子空间首先更接近于本征维数,并且当子空间的维数大于本征维数时,就会出现冗余特征。但是本文方法在大多数数据集中也能很好地处理高维数据。这表明了双向稀疏性在SLBS中的有效性。
3.4 收敛效果
在图1中绘制了MSRC_v1、Caltech_7和HW数据集的迭代收敛曲线,以验证算法SLBS的收敛性。通过对迭代收敛曲线的分析,本文算法在迭代过程中是非递增的,并逐渐收敛到一个确定的值。此外,本文算法在约10次迭代中收敛良好,因此收敛速度快是本文方法的优势。

图1 具有不同迭代次数的SLBS的目标值
3.5 计算时间和参数影响
为了考察本文方法在计算时间上的效率,在表5中比较了具有不同数据和特征尺度的6个数据集的运行时间。由于所有方法都需要使用K-means算法进行聚类,并且关注的焦点是学习子空间的过程,因此没有报告聚类算法的计算时间。
在表4中,比较了SLBS和其他方法对于数据大小n的时间复杂度。从表5中,可以发现本文方法在6个数据集上花费的时间最少。讨论了该实验结果的根本原因。(1) 基于图的方法的计算时间受数据数量n的影响最大,因为它需要分解n维数据矩阵,并且计算复杂度为O(n3)。对于相同的情况,本文方法仅具有线性复杂度。因此,随着数据大小的增加,本文方法要比基于图的方法快得多。(2) 尽管MVNMF、GSSMF和LMVSC的计算复杂度与本文方法相同,但是本文方法仍然比它们快。通过分析,发现本文方法具有更快的收敛速度。例如,在MSRC_v1上,本文方法需要进行35次迭代,而MVNMF和GSSMF需要进行50次以上迭代。

表4 关于所有方法的数据大小n的计算复杂度
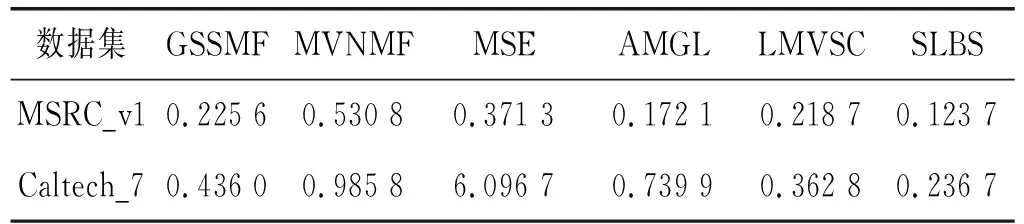
表5 6个数据集的平均运行时间比较 单位:s
对于超参数确定问题,在MSRC_v1和Caltech_7这两个数据集上设计了实验。由于仍然需要确定3个参数,因此在一个数据集上执行了3个实验,它们的差为c的值。这里从{-1,-2,-3}改变参数c。当参数c固定时,从{0.1,0.2,0.3,0.4,0.5}改变λ1,从{2,4,6,8,10}改变λ2。将所研究的子空间维数设为10,选取ACC作为评价指标。结果如图2所示。显示不同的参数会导致不同的结果,这表明了参数选择的重要性。可以发现,当参数c等于-1时,两组结果都很好。可能是由于较大的c表示更关注不同视图的多样性。此外,两个数据集的最优解具有不同的λ1和λ2,因为这两个数据集具有不同的数据特征。

图2 不同参数c对λ1和λ2的敏感性分析
3.6 可视化和鲁棒性分析
在图3中给出行稀疏矩阵P和列稀疏矩阵Q的可视化。可以看到P的行和具有几个小值,而Q的列和具有几个大值。这是合理的,因为第一次降维后的大部分特征都是有用的,并且数据集中没有太多的异常值。实验结果表明了本文算法的有效性。

图3 两个数据集中的行稀疏矩阵P和列稀疏矩阵Q的可视化
为了分析模型的鲁棒性,在两个数据集上将SLBS与两种称为RMSC和RRMA的鲁棒多视图子空间学习方法进行了比较。设计了3种错误数据比率,分别为0、10%和20%。即在原始的数据集中随机替换10%以及20%的相同风景图片,该图片不包含数据集中任何一个类别,从而保证错误数据集的公平性,以保证实验的可对比性。如果错误数据集被聚类为其中某一类别,则认定该聚类错误。进一步利用3种方法进行聚类分析,结果如图4所示,随着错误数据数量的增加,3种方法的性能趋于降低,但是与RMSC和RRMA相比,SLBS始终表现最佳。这充分表明了本文算法的鲁棒性。

图4 在两个数据集中具有不同错误示例比率的鲁棒性分析
4 结 语
传统的多视图子空间学习方法很难找到一个有效的子空间维数并同时处理异常值,故提出一种基于双向稀疏的多视图子空间学习方法。通过多个数据及验证得出如下结论:
(1) 本文方法更加有效地解决子空间维数问题,从而高效处理高维数据,这表明了双向稀疏性在SLBS中的有效性。
(2) 相对于传统方法,本文方法对异常值具有较强的鲁棒性。
(3) 相对于其他传统方法,本文方法具备较好的收敛性,且收敛速度较快,整体计算效率较高,精度也具备优势。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2020年3期)2020-07-27
电子测试(2017年15期)2017-12-18
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
雷达学报(2017年6期)2017-03-26
数学物理学报(2016年5期)2016-08-24
数学物理学报(2016年6期)2016-04-16
