
基于最大距离和最大密度的聚类算法改进
2023-07-11 11:02白洁杨怿
电脑知识与技术 2023年15期
白洁 杨怿

关键词:K-Means 算法;聚类分析;聚类中心;最大距离;最大密度
0 引言
最近科学数据收集技术的进步和复杂多样的数据量的不断增长,在数据分析或挖掘过程中更难操纵它们或提取有用的信息。此外,为数据找到合适的标签既昂贵又耗时,因此大多数数据都没有标签。这就是无监督聚类方法发挥作用的地方。聚类是将具有相似特征的项目分组在一起的行为。这样,每个聚类分组由与其他聚类分组的项目不同的相似项目组成。
目前最流行的数据挖掘方法有分类、聚类、关联规则分析、回归等,聚类算法是数据挖掘的一个重要分支,它丰富了各种不同的问题主题,在现实生活中有着广泛的应用,包含机器视觉、信息检索、图像处理等领域[1]。它是一种无监督的学习方法,其过程是将数据集划分成若干个类,使得同一类中的数据信息相似度尽可能大,不同类中的数据信息差异尽可能大[2]。聚类算法近些年不断发展,现今已经有很多分支,按照算法的性能主要分为基于划分的聚类、基于层次的聚类、基于网格的聚类、基于密度的聚类等。KMeans算法是基于划分的聚类算法这一分支中经典的算法。1967年,MacQueen首次提出了K-Means聚类算法[3]。由于它具有实现形式简单、时间复杂度低的优点,已在数据科学、工业应用等领域中被广泛采用[4-6]。
1 K-Means 算法及改进
1.1 K-Means 算法
K-Means算法是基于划分的聚类算法这一分支中经典的算法。K-Means算法一般采用欧氏距离作为度量对象之间相似性的指标。相似度与记录之间的欧氏距离成反比。记录之间的相似度越大,距离越小。该算法需要事先指定初始聚类个数k 和初始聚类中心,并根据数据对象与聚类中心的相似度不断更新聚类中心的位置。当目标函数收敛时,聚类结束[7]。
目前,K-Means算法的改进方法主要集中在以下几个方向:算法初始k 值的选取、初始聚类中心点的选取、孤立点的检测与去除。
1.2算法改进
K-Means聚类算法是经典且应用广泛的基于划分的聚类方法之一,具有理论可靠、算法简单、收敛速度快、能有效处理大数据集等优点。但是传统的KMeans算法过度依赖于初始条件[8]。即初始聚类数目K值和聚类中心的选择影响最终的聚类结果以及KMeans算法的收敛速度。假设聚类数目K值已经确定,选取不同的初始聚类中心又会导致不同的聚类结果,随机选取的初始聚类中心点将会增加最终聚类结果的随机性和不可靠性。在上文的分析中也总结出,K-Means算法对离群点和孤立点敏感。因此针对聚类中心的选择对K-Means算法作出改进。
在K-Means++中,对于下一个聚类中心点一般选择距离当次迭代的聚类中心最远的数据点或者与其最近的数据点,此方法遵循了两个类簇尽可能远的原则。因此借鉴K-Means++选择聚类中心的思想,以及基于密度分类的DBSCAN算法的思路,提出一种优化聚类中心的K-Means算法。改进以及优化聚类中心的选择与确定,同时基于密度和最大距离来分类的思想也可以避免选择离群点或孤立点为聚类中心,导致聚类结果有偏差的情况。
传统K-Means算法是计算各个类内记录的均值作为新的聚类中心,但往往因为异常值或者离群点导致结果出现局部最优,因此采用最大密度和最大距离的方法来确定聚类中心。基于最大距离和最大密度的中心点初始化方法分为两个步骤,首先计算所有样本的密度,然后选取一部分密度较大的样本作为候选集,然后从候选集中选取彼此相距较远的k个样本作为初始中心。
改进后的算法思路是,计算数据集中所有任意两个数据之间的距离和平均距离,计算出数据的密度和平均密度,设置一个空数据集T,将大于平均密度的所有数据对象添加到数据集T中,选择密度最大的数据对象作为第一个聚类中心,并将这个数据添加到设置的空数据集F中;再根据定义5计算数据集T中距离数据集F最远的数据,把这个数据添加到数据集F中;重复计算,直到数据集F中有K 个数据,就是最终的聚类中心。根据距离公式计算其他数据与k 个聚类中心的距离,根据大小划分到最近的聚类当中。
具体步骤如下:
输入:n条数据的数据集D,聚类个数k
输出:k 个聚类中心和k 个类
Step1:根据欧氏距离公式和定义1计算出任意两条记录之间的距离和平均距离。
Step2:根据定义3和定义4计算出数据集中每条数据的密度和平均密度。
Step3:比较每条数据的密度和平均密度,设置一个空数据集T,将大于平均密度的数据添加到T中。
Step4:在数据集T中选取密度最大的一条数据作为第一个聚类中心,加入新数据集F中。
Step5:从T中选择离数据F最远的数据,作为下一个聚类中心。
Step6:重复step5,直到数据集F中有k条数据,也就是k个聚类中心。
Step7:根据剩余n-k条数据和k个聚类中心之间的距离,依次划分到相应的类当中,得到k个聚类。
2 实验结果对比分析
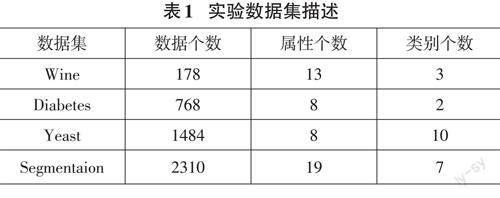
在K-Means++的算法思想基础上,提出一种基于k 值确定和优化聚类中心的K-Means 算法(DD-Kmeans)。其中,优化聚类中心是基于距离和密度来确定聚类中心,和DBSCAN 算法有部分相同思想。因此,这部分实验是将改进的K-Means 算法与KMeans++、DBSCAN算法进行对比分析。实验部分选择UCI上的机器学习常用数据集,包括wine、yeast、Di?abetes、segmentation。
实验从准确率和算法稳定性两方面进行对比。准确率就是改进算法DD-K-means的聚类结果中,每个类别的数量与数据集原始类中数据数量的比值。将DD-K-Means算法与K-Means++算法,DBSCAN算法在wine,segmention,yeast,Diabetes 数据下多次实验,取平均值。实验结果图如图1所示,由图可以分析出,DD-K-Means算法相较于K-Means++和DBSCAN有明显的准确度提升。在wine 数据集上,DD-KMeans算法聚类准确率相较于其他算法提高了7.03%,4.06%;而在Segmentaion 数据集上,DD-KMeans算法相较于其他算法提高了16.54%,13.64%。数据量越大,聚类效果提升更明显。因此,基于密度和最大距离的算法改进,有效优化了聚类结果。如图2 所示,DD-K-Means 算法和K-Means++算法,DB?SCAN算法在Yeast數据集上进行多次实验,明显看出K-Means++算法稳定性在这三种算法中最差,最高达到19%的差值,而DBSCAN算法近11%的波动范围。DD-K-Means将算法准确率的波动维持在6%以内,保证了算法的稳定性。
3 结论
K-Means聚类算法中初始聚类中心一般是随机选取,聚类数目往往人为确定,使得有不同的初始聚类中心和聚类数目的相同数据集聚类结果不一样。为了解决此问题,基于最大距离和最大密度选取聚类中心,计算数据的距离和平均距离,密度和平均密度,根据距离和密度选择合适的聚类中心,避免人为选择聚类中心影响聚类结果,同时也避免孤立点和离散点对聚类结果的影响。实验结果表明,所提出算法聚类结果更稳定,效果更好。与K-Means聚类算法相比,改进算法具有如下优势:初始聚类中心以及其他聚类中心的选取是经过计算得到的。但是,由于改进算法同时进行了距离和密度的计算,导致复杂度增加;聚类数目人为确定的问题也没有改善。因此,在今后的研究工作中,可以考虑优化k值的选择,利用程序确定合适的k值,同智能优化相结合,以得到更加高效的聚类效果。
猜你喜欢
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
西安工程大学学报(2016年6期)2017-01-15
现代防御技术(2016年1期)2016-06-01
