
一种资源友好的零延时Turbo交织器设计
2023-07-17 05:51梁晨
舰船电子对抗 2023年3期
梁 晨
(中国电子科技集团公司第二十研究所,陕西 西安 710068)
0 引 言
Turbo码综合了级联码、卷积码、迭代译码及最大后验概率的思想,考虑了C.E.Shannon信息速率达到信道容量可实现无差错传输假设的3个基本条件,获得了接近Shannon极限的优异性能,因而被广泛应用于各类无线通信协议中[1]。Turbo码的编码器结构如图1所示,主要包括交织器、分量编码器、删余矩阵和复用器。其中交织器的作用是改变输入码源的排列顺序;分量编码器的作用是对输入码源序列和交织后的码源序列进行编码;删余矩阵的作用是根据规则对编码后的校验序列进行选择性删除,以控制码率;复用器的作用是按要求对码源和校验序列重组输出[2]。
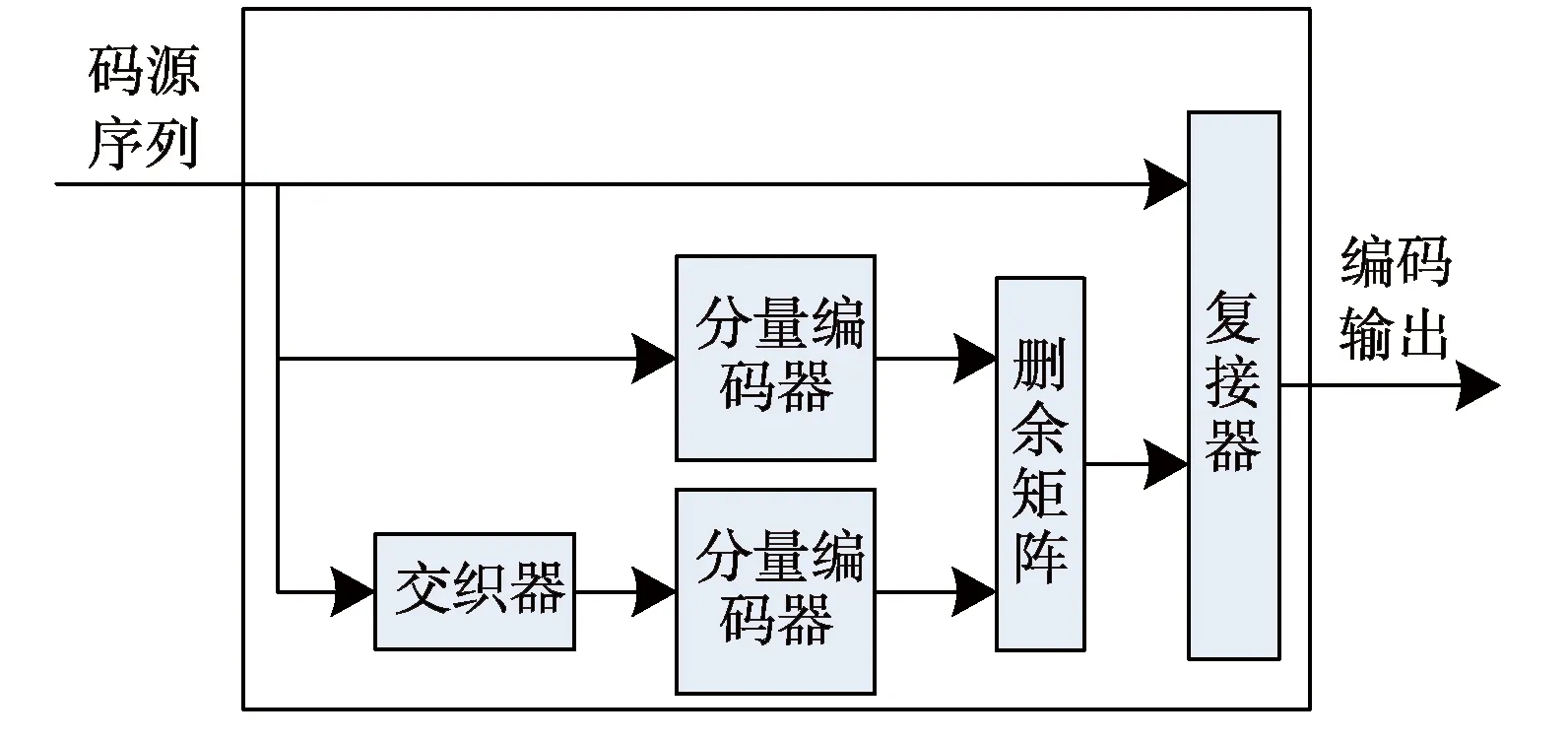
图1 Turbo码编码器结构图
在Turbo编码器中,交织器是十分重要的组成部分,Turbo码的交织器使得码重分布合理,降低了数据序列的相关性,增大了输出码字的最小汉明距离,满足了香农信道编码定理中的随机性编码条件[3]。LTE 中定义了一种二次置换多项式(QPP)交织器。对于交织器的实现,哈尔滨工程大学的赵旦峰、雷李云和罗清华提出,如果将交织算法直接用硬件实现,则会增加Turbo编译码器硬件实现复杂度,同时会增加编译码延时,所以采用将预先计算好的交织地址序列存入现场可编程门阵列(FPGA)的只读存储器中,保证了交织器的电路简单和交织运算的零延迟[4]。这种方法的弊端是对于不同的码块长度需要存储不同的交织地址表,当码块长度类型较多时会占用较多的存储器资源。复旦大学专用集成电路与系统国家重点实验室黄跃斌、陈赟和曾晓洋采用递推公式的方案来进行QPP交织器设计[5],但未对递推计算进行进一步的优化改进。
本文在QPP交织器递推公式的基础上进行设计优化,设计了一种零延时、资源友好的QPP交织器。QPP递推公式涉及到取余运算,如果在FPGA中调用除法器实现,时序上就不能保证交织器的零延时,则图1中2路分量编码器就不能同步工作,影响了编码效率。本文通过比较器实现取余,简化了取余运算,节约了乘法器资源。递推算法的每一步都需要完成加法运算和比较运算,如果在FPGA的一拍时钟完成2种运算,势必会带来时序紧张,使得编码器不能在较高的时钟频率下工作,影响了编码效率。本文通过对递推公式进行改进,分别对交织地址的奇偶序列进行并行递推,利用乒乓的方式输出交织地址,将之前一拍时钟完成的运算分为2个时钟完成,简化了每一拍时钟的逻辑运算电路,使得交织器可以在较高的时钟频率下工作。在时序上,递推运算实现了交织器的零延时。
1 QPP交织器的递推公式
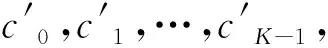
(1)
输出序号i和输入序号ε(i)的关系满足如下二次形式:
ε(i)=(f1·i+f2·i2)modK
(2)
参数f1和f2与码块长度K有关,需要进行巧妙设计来确保QPP交织器避免冲突。在长期演进(LTE)中,总共设计了188种码块长度[6]。
交织地址可以通过递推运算来实现,递推公式如下[6]:
ε(i+1)=[ε(i)+δ(i)]modK
(3)
δ(i+1)=[δ(i)+b]modK
(4)
容易得到初始值ε(0)=0,δ(0)=(f1+f2)modK。b是一个常量,b=(2f2)modK。该递推公式只涉及加法、取余运算,可以相对容易在逻辑硬件上实现。但取余运算在硬件实现中需要用到除法器,时序上不能保证交织器的零延时,影响编码效率。
在公式(3)中:
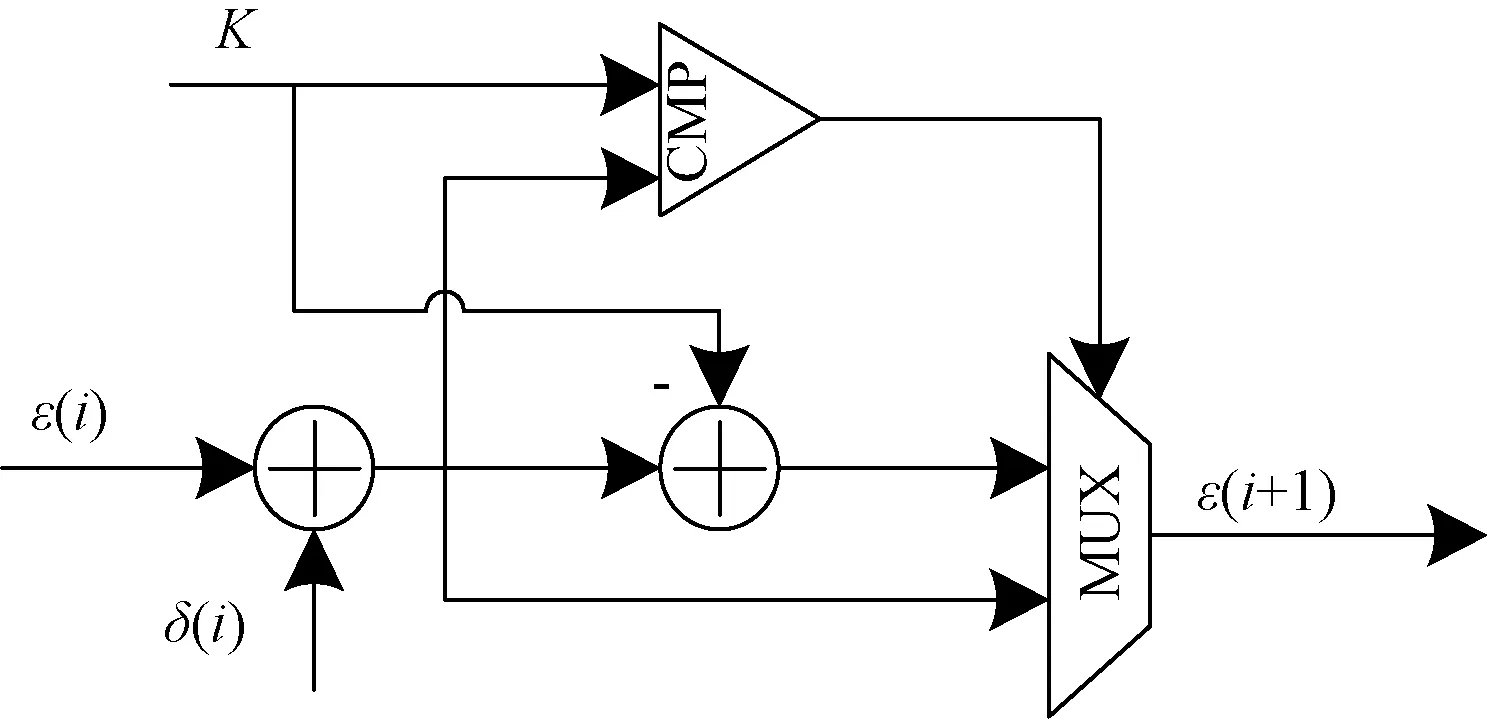
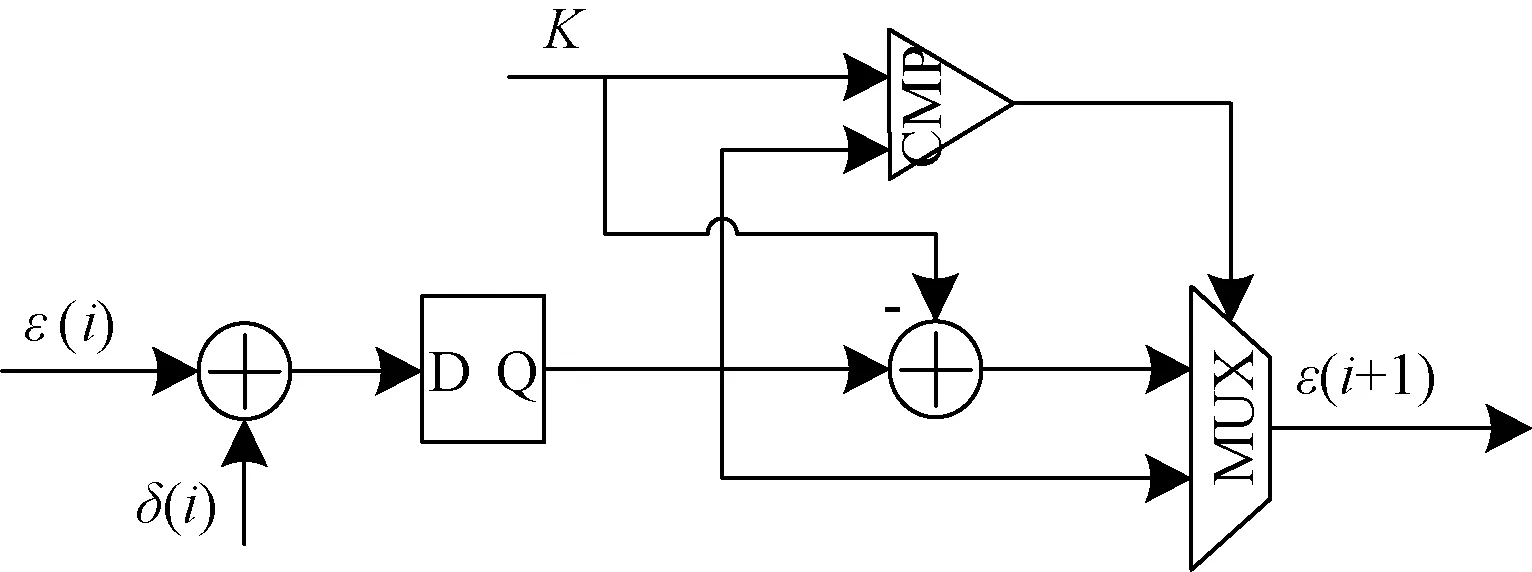
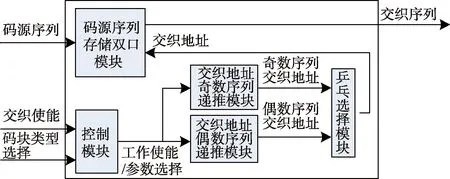
∵ε(i) ∴ε(i)+δ(i)<2K 因此递推运算中取余运算可以用比较、选择等简单运算来实现: (5) 同理可得: (6) 如公式(5)所示,在上一个时钟周期计算出来的ε(i)和δ(i)首先进行加法运算。ε(i)和δ(i)相加得到的结果一方面与K进行比较,另一方面再减去K。比较的结果控制二选一选择器,当ε(i)和δ(i)之和小于K时,选择ε(i)+δ(i)作为ε(i+1);反之选择ε(i)+δ(i)-K作为ε(i+1)的结果,逻辑电路实现示意图如图2所示。这个过程如果在同一个时钟周期来完成,组合逻辑较为复杂,时序较为紧张,使得交织器不能在较高时钟频率下工作。如果分为2个时钟节拍来完成,第1个时钟完成ε(i)+δ(i)计算,第2个时钟周期完成ε(i)+δ(i)求和值与K的比较,同时并行完成ε(i)+δ(i)求和值减去K,根据比较结果控制二选一选择器给ε(i+1)赋值。逻辑电路实现示意如图3所示,这样时序较为宽松,交织器可以在较高的时钟频率下工作。 图2 1个时钟完成递推计算逻辑电路示意图 图3 2个时钟完成递推计算逻辑电路示意图 将公式(3)、(4)进行改进,得出: ε(i+k)=[ε(i)+δ(i)]modK (7) δ(i+k)=[δ(i)+b]modK (8) 式中:k是一个大于0、小于K的任意整数,可以推算出初始值ε(0)=0,δ(0)=(f1·k+f2·k2)modK;b是一个常量,b=(2k2f2)modK。 为了实现不提高时钟的条件下零延迟交织器设计,本文将交织地址序列分为奇偶2个序列进行并行递推,并利用乒乓的方式输出交织地址。 将k=2代入公式(7)、(8)得到: ε(i+2)=[ε(i)+δ(i)]modK (9) δ(i+2)=[δ(i)+b]modK (10) 初始值为ε(0)=0,δ(0)=(2f1+4f2)modK,ε(1)=(f1+f2)modK,δ(1)=(2f1+8f2)modK。b是一个常量,b=(8f2)modK。 递推运算中取余仍可以用比较、选择简单运算来实现: (11) 同理可得: (12) 基于改进后的递推公式,QPP交织器设计架构如图4所示,主要包括码源序列存储双口模块、控制模块、交织地址奇数序列递推模块、交织地址偶数序列递推模块和乒乓选择模块组成。其中原始码序列存储双口模块一端用来写入编码前的码源序列,另一端按照交织地址读出码源数据完成交织功能。控制模块输入交织码块的类型和交织使能信号,根据输入的交织码块类型得出不同码块大小对应的f1、f2、K值以及递推公式中ε(0)、δ(0)、ε(1)、δ(1)和b的值;根据输入的交织使能脉冲信号开始交织器的工作,交织器工作时间等于K个时钟周期。交织地址奇数序列递推模块,利用初值ε(1)和δ(1),2个时钟递推出一个奇数序列的交织地址。交织地址偶数序列递推模块,利用初值ε(0)和δ(0),2个时钟递推出1个偶数序列的交织地址。乒乓选择模块根据交织工作计数器的奇偶交替,分别选择输出奇偶序列的交织地址。该交织器的输出延时等于RAM IP核的读延迟,同顺序码源序列读延迟一致,实现了交织模块的零延迟。 图4 QPP交织器设计架构图 依照设计方案在FPGA上完成编程实现,该交织器支持全部码块大小类型进行交织运算。功能仿真验证时按照一种码块大小为例(K=264,f1=7,f2=66),逻辑运算结果如图5所示。其中pi_odd和pi_even分别为交织地址的奇偶序列,经乒乓选择器选择后合路的交织地址为信号addr2,可以看出addr2和顺序序列地址addr1同步对齐,输出顺序序列c和交织序列c_i也同步对齐,交织器工作的零延时保证了编码效率。交织地址和Matlab计算的交织地址波形如图6所示,经数值对比结果一一对应。交织器实现后资源使用情况如图7所示,可以看出该交织器使用资源极少,实现了资源友好的设计目标。 图5 QPP交织器逻辑软件仿真时序图 图6 逻辑软件和MATLAB仿真结果对比图 图7 交织器实现后资源使用情况图 本文提出了一种零延时、资源友好的Turbo交织器优化设计方案。该方案简化了递推公式中的复杂运算,通过奇偶序列进行并行递推和乒乓输出的方式,将递推运算中的逻辑运算由1个时钟完成改为2个时钟完成,使得交织器时序宽松,可在较高的时钟频率下工作。经仿真验证,交织结果准确无误;经工程验证,该设计方案可在240 MHz时钟工作频率的Xilinx FPGA中稳定工作。2 改进后的QPP交织器递推公式
3 零延时QPP交织器模块设计
4 QPP交织器功能验证



5 结束语
猜你喜欢
美食(2022年2期)2022-04-19
自动化仪表(2020年10期)2020-11-13
女报(2019年3期)2019-09-10
成都信息工程大学学报(2018年3期)2018-08-29
成都信息工程大学学报(2018年6期)2018-03-21
电子设计工程(2017年20期)2017-02-10
华人时刊(2016年17期)2016-04-05
电子器件(2015年5期)2015-12-29
船舶力学(2015年6期)2015-12-12
电测与仪表(2014年13期)2014-04-04
