
基于多目标混合蚁狮优化的算法选择方法
2023-07-20 11:21李庚松郑奇斌杨长虹
计算机研究与发展 2023年7期
李庚松 刘 艺 郑奇斌 李 翔 刘 坤 秦 伟 王 强 杨长虹
1 (国防科技创新研究院 北京 100071)
2 (军事科学院 北京 100091)
3 (天津(滨海)人工智能创新中心 天津 300457)
在大数据时代背景下,利用数据进行分析和决策成为了不同领域的重要工作,各种人工智能算法为此提供了不可忽视的助力.然而,“没有免费午餐”定理表明,不存在一个在所有问题上具备优越性能的“最优”算法[1].如何从大量可行方法中为给定任务选择满足需求的合适算法成为了工程中的关键问题,即算法选择问题[2].算法选择问题可以通过人工选择方法和机器学习方法解决.人工选择方法包括实验试错法和专家知识法.前者通过大量的实验获得算法性能,分析结果并选择算法;后者则按照领域专家的指导进行算法选择.然而,实验试错法成本较高,专家知识法基于专家的经验知识,存在人为偏差且获取较为困难.机器学习方法提取问题的抽象特征,设计模型实现自动化的算法选择,包括基于元学习的方法和基于协同过滤的方法[3-4].其中,基于元学习的方法研究基础较为深厚,具有灵活性高、适用范围广、计算成本低等优点,成为了算法选择的主要方法[5-7].
基于元学习的算法选择利用问题的元特征(抽象特征)和历史学习经验训练元算法,构建问题元特征到合适算法的映射.元特征和元算法是其中的关键内容,而现有研究在元特征和元算法的选择和使用上存在一些缺点:在元特征方面,多数研究选择固定的元特征[8-10],可扩展性较弱,且难以充分利用元特征的互补性;在元算法方面,研究或采用单个元算法,泛化性能不足,或采用同构集成元算法[11-14],没有利用不同元算法的优势,导致多样性不足.
集成学习的相关研究表明,利用准确且多样的基学习器进行集成可以获得更精确、更稳定的学习性能[15-16].选择性集成方法根据基学习器的准确性和多样性从多个基学习器中选取部分进行集成,可以减少集成算法的存储空间和预测时间并提升其泛化性能,是集成学习的热点方向之一[17-19].演化算法有着鲁棒性强、适用性高、可以全局搜索等特性,在选择性集成研究中得到了广泛应用[20-22].
蚁狮优化(ant lion optimizer,ALO)[23]算法是近年来出现的演化算法,它模拟蚁狮捕食蚂蚁的行为机制对最优解进行搜索,具有寻优性能强、参数设置少、易于实现等优点.研究人员将ALO 扩展应用于多目标优化问题,在污水处理、工程设计等领域取得了良好的应用效果[24-26].
为了提升基于元学习的算法选择性能,提出基于多目标混合蚁狮优化的选择性集成算法选择方法(selective ensemble algorithm selection method based on multi-objective hybrid ant lion optimizer,SAMO),该方法包括一种算法选择模型和一种多目标混合蚁狮优化算法.算法选择模型以集成元算法的准确性和多样性作为优化目标,同时选择元特征和构建选择性集成元算法.多目标混合蚁狮优化算法对模型进行优化,通过离散型编码选择元特征子集,使用连续型编码构建集成元算法,在此基础上应用增强游走策略和偏好精英选择机制提升寻优性能.
本文的主要贡献包括3 个方面:
1)提出一种算法选择模型,同时从元特征和元算法2 个方面提升基于元学习的算法选择性能.模型通过元特征选择寻找互补性较强的元特征子集,通过选择性集成构建异构集成元算法.
2)提出一种多目标混合蚁狮优化算法,求解算法选择模型.通过混合编码机制使个体同时进行元特征选择和选择性集成;采用增强游走策略,在个体搜索过程中引入随机性,增加算法的种群多样性;应用偏好精英选择机制,以不同的优化目标为偏好选择精英个体,增强算法的寻优能力.
3)使用260 个数据集、150 种元特征和9 种候选算法构建分类算法选择问题,在此基础上将所提方法与8 种典型方法在4 种性能指标上进行对比分析,结果证明了所提方法的有效性和优越性.
1 相关概念和工作
1.1 基于元学习的算法选择
1.1.1 基于元学习的算法选择框架
基于元学习的算法选择框架[27-28]如图1 所示.框架首先提取历史数据集的元特征,并通过性能测度评估确定历史数据集的最优算法,在过程中采用不同的性能测度方法可能获得不同的最优算法;然后以元特征为属性,以最优算法为标签组成元实例构建元数据集,并在元数据集上训练元算法;最后,提取新数据集的元特征输入已训练的元算法,元算法即对其最优算法进行预测输出.
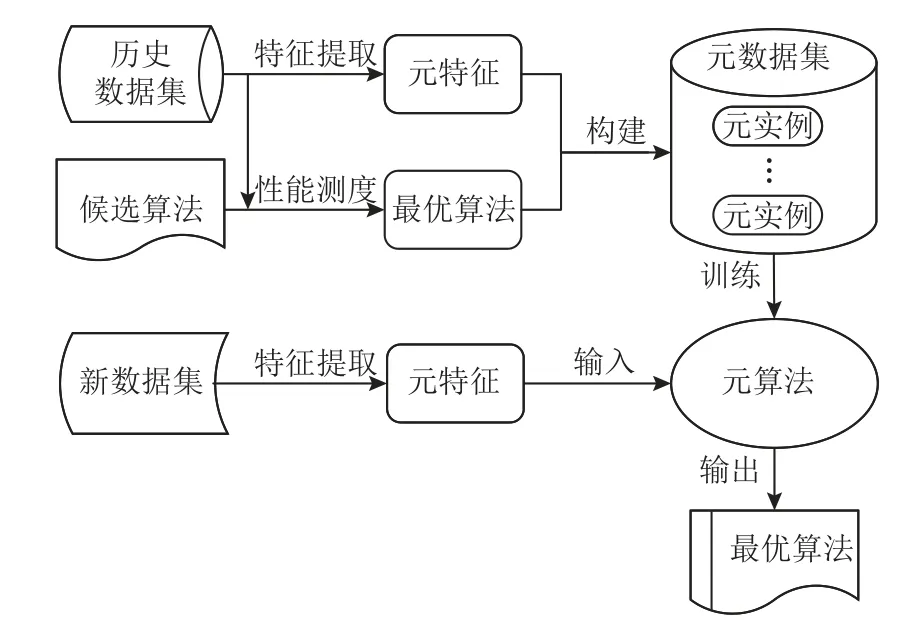
Fig.1 Framework of algorithm selection based on metalearning图1 基于元学习的算法选择框架
1.1.2 元特征相关内容
根据反映数据集特性的不同,元特征分为4 类:
1)基于统计和信息论的元特征采用统计学和信息论的方法提取数据集的抽象特征[27].该类型元特征应用广泛且易于提取,然而其难以较好地刻画数据集特性.
2)基于决策树的元特征在数据集上训练决策树,使用决策树的结构信息作为元特征[28].其能够发掘数据集的整体特性,但提取成本高昂.
3)基于基准的元特征将基准算法在数据集上的性能指标值作为元特征[29],其提取方法较为简单,然而对基准算法的依赖度较高.
4)基于问题复杂度的元特征从类重叠、类不平衡、数据稀疏度等方面对数据集的几何复杂度进行量化评估[30].该类型元特征反映了求解问题的困难程度,应用效果较好,但是计算复杂度较大.
1.1.3 元算法相关内容
按照训练过程的技术特点,将元算法分为4 类:
1)基于规则的元算法生成候选算法的选择规则,通过将元特征与规则进行匹配,为新数据集选择合适算法,该方法具备较强的可解释性,但泛化性能较差.针对负荷预测问题,文献[8]提取18 种数据集元特征,训练分类回归树(classification and regression tree,CART)选择最优算法.
2)基于距离的元算法通过元特征测度距离,评估数据集之间的相似度,使用相似数据集的最优算法作为新数据集的合适算法.k最近邻(knearest neighbors,kNN)是研究中常见的元算法,其实现简单且运行较快,但关键参数k的最优值设置较为困难.文献[9]使用32 种分类数据集元特征,基于kNN 构建元特征到最优算法的映射.
3)基于回归的元算法预测各候选算法的性能指标值并进行比较,从而完成算法选择决策,使用较为广泛的元算法为支持向量回归(support vector regression,SVR).该类方法可以灵活地增减候选算法,但训练成本较高.文献[10]选用12 种元特征,应用SVR 学习元特征与候选分类算法性能的映射关系.
4)基于集成的元算法通过一定策略组合多个性能较弱的元算法,得到具有较强性能的集成元算法,常见的元算法包括随机森林(random forest,RF)、极端梯度提升(extreme gradient boosting,XGB)等,这些方法的泛化性能较好,但训练速度较慢且参数设置较为复杂.文献[11]提取22 种元特征,采用RF 学习元特征到最优分类算法的映射.文献[12]使用22 种元特征,采用随机森林回归(random forest regression,RFR)预测候选分类算法的性能.文献[13]提取98 种图像元特征,分别训练RF 和XGB 并预测最优图像分割算法.文献[14]选择39 种分类数据集元特征,应用轻量梯度提升机(light gradient boosting machine,LGBM)进行算法选择.
在上述研究中,元特征和元算法的选用仍存在一些问题:在元特征方面,研究通常根据需求选取固定的元特征,耦合度较高,可扩展性较弱;不同元特征从不同方面描述和提取数据集的抽象特征,具备一定的互补性,然而现有的方法难以有效利用.在元算法方面,现有研究或使用泛化性能较弱的单个元算法,或采用同构基学习器的集成元算法,未能充分利用不同元算法的优势和多样性.
1.2 多目标优化问题
多目标优化是指同时优化多个目标且目标间相互矛盾的问题,该问题通常是NP 难的,无法获取唯一最优解,而是一组次优解[31].不失一般性地以最小化问题为例,给出多目标优化问题的定义.
定义1.多目标优化问题.给定一个具有n维决策变量,m(m≥2)个目标的优化问题,其数学模型的定义如式(1)所示:
其中x=(x1,x2,…,xn),x为决策向量,Ω为决策空间;F:Ω→Λ,F为目标函数向量,Λ为由m个优化目标构成的目标空间.
定义2.帕累托支配.给定2 个解x和y,当满足如式(2)所示约束条件时,则称x支配y,表示为x≺y.
定义3.帕累托最优解.给定解x∈Ω,当且仅当不存在另一个解支配它,即∄y∈Ω:y≺x时,x为帕累托最优解.
定义4.帕累托解集(Pareto set,PS).决策空间Ω中所有帕累托最优解的集合称为帕累托解集,如式(3)所示:
定义5.帕累托前沿(Pareto front,PF).PS对应的目标向量集合称为帕累托前沿,如式(4)所示:
多目标优化旨在获取靠近真实PF的解集S,从2 个方面评估解集S的质量:收敛性,即解集S与真实PF的接近程度;分布性,即解集S在目标空间中的散布程度.
1.3 ALO
ALO 通过蚂蚁的随机游走模拟蚁狮使用陷阱诱捕蚂蚁的过程,实现个体解的搜索更新.蚂蚁各维度的随机游走方法如式(5)所示:
其中t为当前迭代次数,T为最大迭代次数,X(t)表示随机游走位置,cusum表示随机游走步长的累加和,用于生成随机游走步长,rand表示位于[0,1]之间均匀分布的随机数.
在随机游走过程中,蚂蚁逐渐滑入陷阱,其游走边界随之缩小,如式(6)所示:
其中c和d表示个体各维度值的上界和下界,ct和dt分别表示第t次迭代中蚂蚁各维度值搜索范围的上界和下界,缩小程度I的计算如式(7)所示:
其中倍率因子w的值取决于当前迭代次数t.t≤0.1T时,w= 0;t> 0.1T时,w= 2;t> 0.5T时,w= 3;t>0.75T时,w= 4;t> 0.9T时,w= 5;t> 0.95T时,w= 6.可见随着t的增加,10w和I值呈递增趋势,而ct和dt呈递减趋势.
ALO 将适应度最优的蚁狮选为精英蚁狮,每只蚂蚁通过轮盘赌方法选择1 个蚁狮,围绕精英蚁狮和轮盘赌蚁狮进行随机游走,并根据式(8)更新位置:
其中At为第t次迭代蚂蚁的位置向量,e和r分别表示精英蚁狮和轮盘赌蚁狮,为第t次迭代蚂蚁围绕e进行随机游走得到的向量,为第t次迭代蚂蚁围绕r进行随机游走所得向量.
2 SAMO
为了充分利用元特征的互补性和元算法的多样性来提升算法选择性能,SAMO 设计算法选择模型,并提出多目标混合蚁狮优化算法对模型进行求解,从而构建准确性和多样性较强的集成元算法.
使用SAMO 进行算法选择的流程如图2 所示.将元数据集输入SAMO 后,SAMO 利用所提优化算法对模型进行优化,输出集成元算法集合,然后从其中选择一个集成元算法用于预测新数据集的最优算法.
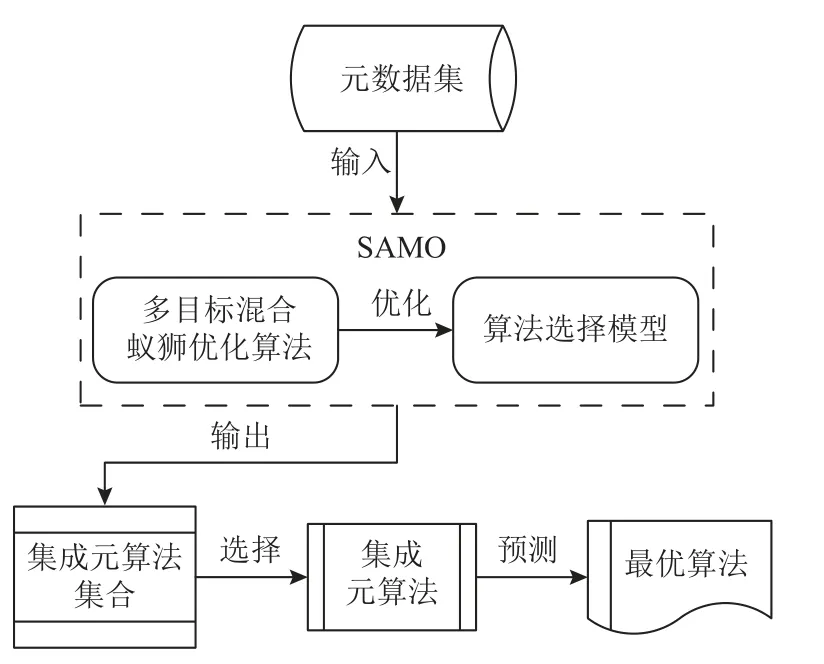
Fig.2 Algorithm selection process of SAMO图2 SAMO 算法选择流程
2.1 算法选择模型
2.1.1 模型优化目标
模型使用分类错误率(error rate,ER),评估集成元算法的准确性.
设有m个测试元实例X={x1,x2,…,xm},各个元实例对应的最优算法标签为Y={y1,y2,…,ym},且有yk∈A,1 ≤k≤m,其中A={a1,a2,…,al}为包含l个候选算法标签的集合,ER的计算公式为
其中E表示集成元算法,和yi分别表示第i个测试元实例的预测最优算法标签和真实最优算法标签.通过加权投票法,利用集成权重W={w1,w2,…,wv}组合v个基分类器B={b1,b2,…,bv}构建集成元算法E,E对测试元实例xk∈X进行预测,如式(10)所示:
其中E(xk)表示预测最优算法结果;a为A中的一个候选算法标签;bi表示B中的第i个基分类器,bi(xk)表示对xk的预测结果;I()为示性函数,当其中的表达式逻辑为真时,I()=1,否则I()=0;wi为第i个基分类器的集成权重;函数表示取使其内部表达式最大的算法标签a.ER值越小,表示集成元算法的性能越好.
采用不同的多样性指标(diversity indicator,DI),度量集成元算法的多样性,包括Q 统计量(Q statistic,QS)、K 统计量(K statistic,KS)、相关系数(correlation coefficient,CC)、一致度量(agreement measure,AM)和双错测度(double fault,DF).
基分类器bi和bj对X的预测结果列联表如表1所示.

Table 1 Contingency Table of Prediction Results表1 预测结果列联表
表1 中,c表示bi和bj均预测正确的元实例数;p表示bi预测正确而bj预测错误的元实例数;q表示bi预测错误而bj预测正确的元实例数;d表示bi和bj均预测错误的元实例数.根据表1,bi和bj的QS,KS,CC,AM,DF指标计算公式为
式(11)~(15)所述的指标值越小代表基分类器多样性越强,除AM和DF指标的值域为[0,1]外,其余指标的值域均为[-1,1];此外,这5 个指标均为成对指标,即满足DIbi,bj=DIbj,bi.集成元算法E的DI值为所有成对基分类器DI值的平均值,如式(16)所示:
综上,算法选择模型的目标函数向量为
2.1.2 模型设计
模型从元特征和元算法2 个方面提升算法选择性能.在元特征方面,选择互补性较强的元特征子集,从而有效利用元特征;在元算法方面,通过选择性集成方法,对异构基分类器进行集成,构建具有较强泛化性能和多样性的集成元算法.为了利用不同基分类器的优势和多样性,采用kNN、支持向量机(support vector machine,SVM)和CART 作为基分类器,且本文设置每种基分类器的个数相等.
在对元数据集进行元特征选择的基础上,算法选择模型构建集成元算法的过程如图3 所示.首先使用自助法对训练集进行若干次抽样生成多个训练子集;然后运用基分类器在训练子集上进行训练形成基分类器集合;最后通过选择性集成方法,从集合中选择准确性和多样性较强的基分类器并基于加权投票法策略进行组合,得到集成元算法.
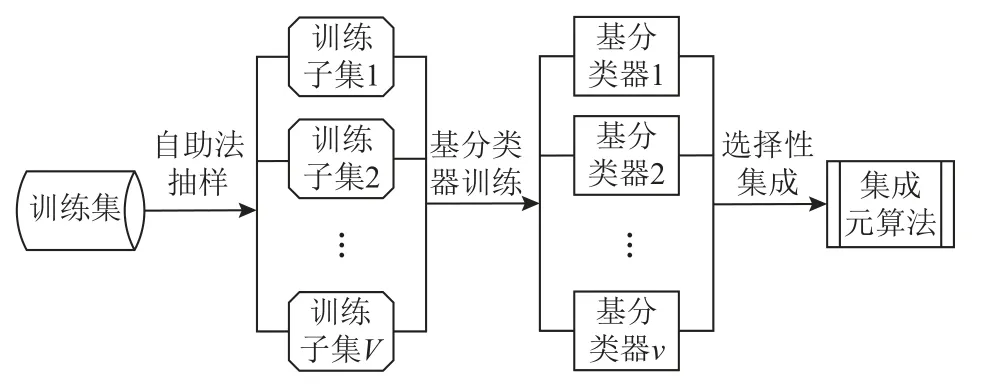
Fig.3 Construction process of ensemble meta-learner图3 集成元算法构建过程
2.2 多目标混合蚁狮优化算法
2.2.1 混合编码机制
多目标混合蚁狮优化算法针对元特征选择的离散特性(元特征选择与否),使用离散型编码选择元特征子集;采用连续型编码构建集成元算法,该连续型编码包括1 个用于控制基分类器选择概率的选择阈值编码,以及若干个基分类器权重编码,用于选择基分类器的训练子集并生成集成权重.
个体的混合编码方式如图4 所示.设元数据集含有M个元特征,则个体的离散型编码数为M;设基分类器个数为V,则自助法抽样生成的训练子集个数为V,个体依次为kNN,SVM,CART 使用V个编码选择训练子集和生成集成权重,因此基分类器权重编码数为3V,个体的连续型编码数为3V+1.
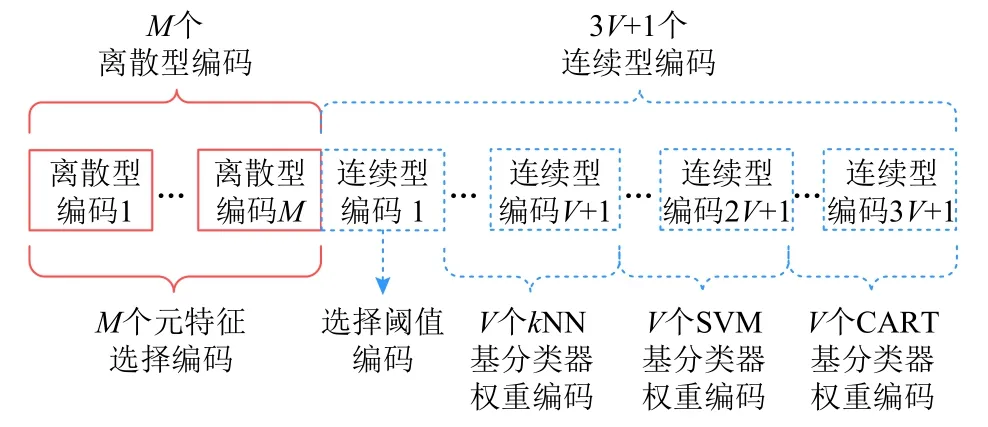
Fig.4 Coding pattern of individuals图4 个体编码方式
根据混合编码机制,对个体各维度的编码值进行初始化,如式(18)所示:
其中Ai为个体第i维的编码值,个体前M维编码为离散型的元特征选择编码,其值为1 表示第i维编码对应的元特征被选中,值为0 表示未被选中.个体第M+1 维编码为选择阈值编码,其后的3V个编码为基分类器权重编码,前V个基分类器权重编码为kNN 选择训练子集,如式(19)所示:
其中AM+1为选择阈值编码值,J(Ai)= 1 表示第i维编码对应的训练子集被选中,J(Ai)= 0 表示未被选中,以此类推可得SVM 和CART 的训练子集.3 种基分类器分别在选择的训练子集上独立训练,得到基分类器集合B={b1,b2,…,bv},通过基分类器权重编码值生成这3 种基分类器集合对应的集成权重W={w1,w2,…,wv},如式(20)所示:
其中wi为第i个基分类器的集成权重,Ai为第i个基分类器对应的基分类器权重编码值,Aj为第j个基分类器对应的基分类器权重编码值.通过式(20)的归一化方法,使得集成权重和为1,即=1.
2.2.2 增强游走策略
在混合编码机制的基础上,采用增强游走策略对个体进行搜索更新.
在迭代过程中,个体的离散型编码使用离散随机游走方法,如式(21)所示:
Fig.5 Change trend of m(t)图5 m(t)变化趋势
随机游走后,蚂蚁离散型编码值更新为
对于个体的连续型编码,在其游走更新过程中引入随机性.ALO 中每只蚂蚁的搜索边界ct和dt变化趋势相同,种群多样性不足.为了增强所提算法的种群多样性,对式(6)进行改进,如式(24)所示:
Fig.6 Change trend of search boundary图6 搜索边界变化趋势
通过上述设计,增强游走策略对个体不同类型的编码进行搜索更新,保留了蚂蚁搜索边界变化的递减趋势,同时在该过程中引入了随机性,增加了算法的种群多样性.
2.2.3 偏好精英选择机制
算法将帕累托解作为蚁狮保存至外部存档S,为了提升算法的寻优能力,分别以不同优化目标为偏好,从存档S中选择在该目标上最优的精英蚁狮.为了增强解的分布性,通过小生境技术计算蚁狮解的稀疏度从而量化其分布性,然后利用稀疏度通过轮盘赌选择蚁狮,蚁狮解xS的稀疏度为
其中s(xS,φ)表示给定半径 φ的小生境范围内解xS的稀疏度,yS表示存档S中的另一个解,半径 φ计算为
其中m(m≥2)为优化目标个数,ei和ej分别表示第i个和第j个优化目标对应的精英蚁狮,‖‖计算二者目标函数值向量的欧氏距离,c为常数;‖F(xS)-F(yS)‖计算解xS和解yS目标函数值向量的欧氏距离,其值小于半径 φ时表示yS是xS的相邻解.给定解在存档中的相邻解越多,则该解的稀疏度越低,分布性越差.以2 个优化目标为例,稀疏度计算示意如图7 所示.
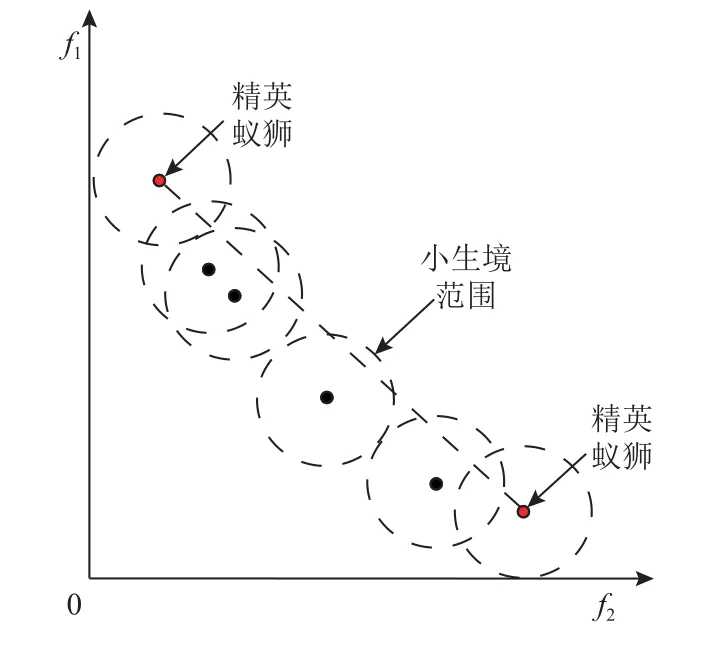
Fig.7 Schematic diagram of sparsity calculation图7 稀疏度计算示意图
在迭代过程中,对于每个优化目标,每只初始化蚂蚁根据蚁狮的稀疏度通过轮盘赌选择1 个蚁狮,围绕该优化目标的精英蚁狮和轮盘赌蚁狮进行随机游走,产生新的个体解.由此可得个体数是初始化种群的新蚂蚁种群的m倍,将新蚂蚁种群加入外部存档,筛选保留存档中的帕累托解作为新一代蚁狮.
通过偏好精英选择机制,分别围绕不同优化目标上的最优个体进行迭代更新,增强算法的寻优性能;采用轮盘赌方法以较大概率选择分布性较好的个体,并围绕该个体进行搜索,使解的分布性更强.
2.3 SAMO 方法整体描述
SAMO 流程如图8 所示.方法首先输入元数据集;然后根据混合编码机制初始化蚂蚁种群;计算蚂蚁的适应度,通过帕累托支配关系从中选出帕累托解作为蚁狮保存至外部存档;按照偏好精英选择机制,从蚁狮中选出准确性和多样性优化目标上的精英个体,分别称为准确性精英蚁狮和多样性精英蚁狮,并计算蚁狮的稀疏度;在迭代过程中,每只初始化蚂蚁根据蚁狮稀疏度进行2 次轮盘赌选择蚁狮,围绕准确性精英蚁狮和第1 次轮盘赌蚁狮,以及围绕多样性精英蚁狮和第2 次轮盘赌蚁狮,基于增强游走策略进行随机游走,生成2 只新的蚂蚁;计算新蚂蚁种群的适应度并将其加入存档,更新存档和精英蚁狮;最后,达到最大迭代时,输出蚁狮构建的集成元算法集合.在该过程中,个体的适应度为集成元算法的准确性和多样性指标值.

Fig.8 Process of SAMO图8 SAMO 流程
SAMO 方法的伪代码如算法1 所示.
算法1.SAMO 方法.
现对SAMO 的时间复杂度进行分析,设元特征数为M,基分类器个数为V,可得个体维度数D=M+3V+1;设种群规模为N,最大迭代次数为T,则蚂蚁随机游走进行迭代的时间复杂度为O(2N×D×T),计算解的支配关系和稀疏度的时间复杂度为O(N2×T).综上所述,SAMO 的时间复杂度为O(N×T×(N+2D)).
3 实验与结果分析
3.1 实验设置
3.1.1 数据集
由于分类算法应用的广泛性,通过分类算法选择问题进行测试实验.实验使用来自于UCI[32],KEEL[33],StatLib[34],OpenML[35]的260 个分类数据集,这些数据集的数据来源领域各异,实例数从13~149 332 不等,属性数从1~1 558 不等,类数从2~188 不等,具有一定的差异性,构成多样化的数据集,从而能够有效评估方法的性能.实验数据集信息如表2 所示.

表2(续)

Table 2 Information of Experimental Datasets表2 实验数据集信息
3.1.2 元特征
通过元特征提取工具MFE[36]提取常用的150 种分类数据集元特征,包括77 种基于统计和信息论的元特征、24 种基于决策树的元特征、14 种基于基准的元特征和35 种基于问题复杂度的元特征.元特征信息如表3 所示.

Table 3 Information of Meta-Features表3 元特征信息
3.1.3 候选算法
使用8 种sklearn[37]机器学习平台的分类算法,包括kNN、RF、SVM、逻辑回归(logistic regression,LR)、朴素贝叶斯(naive Bayes,NB)、线性判别分析(linear discriminant analysis,LDA)、ID3 决策树和多层感知机(multi-layer perceptron,MLP),以及基于Keras[38]构建的卷积神经网络(convolutional neural network,CNN)作为候选算法.基于sklearn 实现的算法均采用其默认参数设置,对于CNN,使用1 个含有32 个卷积核的1 维卷积层、1 个全连接层以及1 个最大池化层构成其隐藏层,并设置其卷积层和全连接层使用ReLU(rectified linear unit)激活函数,输出层使用softmax 激活函数.
3.1.4 候选算法性能测度
使用准确率(Acc)、查准率(Pre)、查全率(Rec)、F1 得分(F1)和ARR(adjusted ratio of ratios)[39]指标测度并比较候选算法的性能.ARR指标综合考虑算法的运行时间和准确率,其计算如式(27)(28)所示:
其中ai和aj表示候选算法,l为候选算法数,Acc和Rt表示算法在数据集上的准确率和运行时间;α为可变参数,表示准确率和运行时间的相对重要程度.实验中ARR的 α值取研究中常用的0.1,0.01,0.001,并各自记为ARR1,ARR2,ARR3指标,以获得较为全面的算法性能测度结果.
通过5 次10 折交叉验证获取候选算法在各数据集上的性能指标值,对指标值进行比较从而确定数据集的最优算法,将最优算法作为标签与元特征结合,构建相应性能指标的元数据集.采用DAcc,DPre,DRec,DF1表示通过准确率、查准率、查全率和F1得分指标构建的元数据集;使用DARR1,DARR2,DARR3分别表示通过ARR1,ARR2,ARR3指标生成的元数据集.此外,当应用基于回归的元算法时,为各候选算法构建单独的元数据集,其中的元实例标签为性能指标值,训练元算法预测各候选算法的性能指标值,比较预测值从而选出最优算法.
3.1.5 对比方法
采用kNN,SVM,CART,SVR,RF,RFR,XGB,LGBM 作为元算法与SAMO 进行对比实验.研究表明kNN 的距离度量采用欧氏距离,邻居数k值位于元数据集实例数的10%~15%之间时,其表现更好[9,40].经过对比择优,本文设置k=30,距离度量采用以距离倒数为权重的加权欧氏距离.除kNN 外,其他基分类器和元算法均采用sklearn 中的默认参数设置.
通过5 折交叉验证,即将元数据集随机划为5 份,选择其中4 份作为训练集,1 份为测试集,计算各方法的性能指标值.
3.2 元数据集分析
对构建的7 个元数据集进行分析,候选算法在各元数据集中的胜出次数如表4 所示.
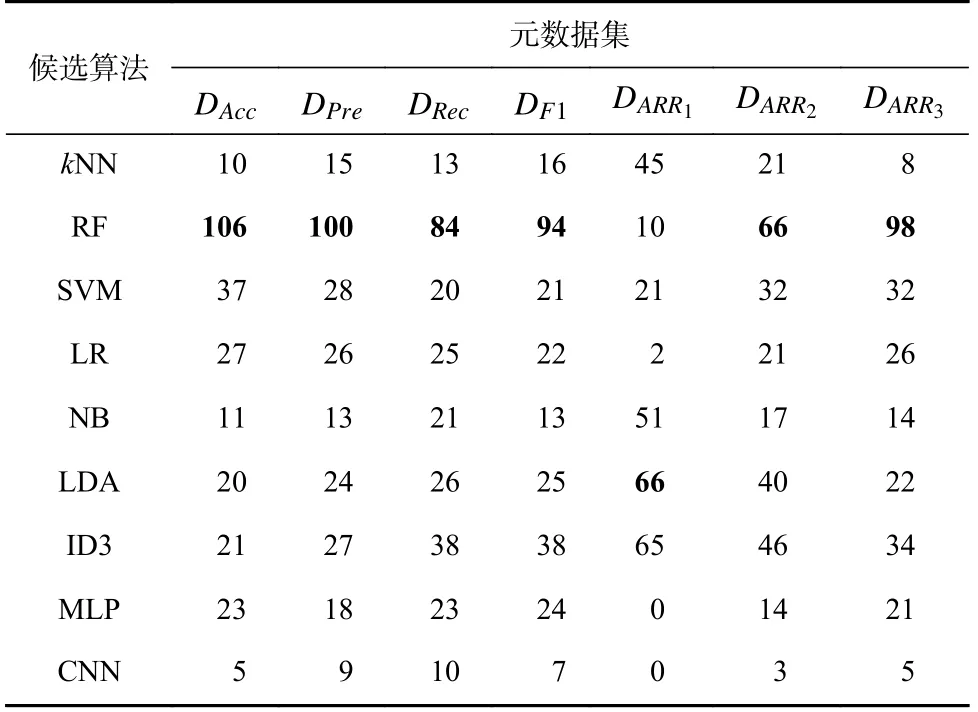
Table 4 Win Times of the Candidate Algorithms表4 候选算法胜出次数
从表4 可以看出,在本文的测试环境中,RF 具有较为优越的分类性能,但是其在DARR1元数据集中的胜出次数较少,表明运行时间是其短板.与RF 相对的是kNN 和NB,得益于算法较快的运行速度,kNN和NB 在ARR指标上具备一定优势,但其分类性能较差,因此,随着α值的减小,运行时间的重要性降低,kNN 和NB 在ARR指标元数据集中的胜出次数减少.相较于kNN 和NB,LR 的分类性能略优但时间开销更高,在7 个指标上的表现较为平庸.SVM 的分类性能较优且具有合适的时间开销,在7 个指标上均取得了较好结果.LDA 和ID3 展现了较好的分类性能,另一方面,LDA 和ID3 在ARR指标的元数据集中也取得了较多次数的胜出,说明其在运行时间和准确率上较为均衡.MLP 的分类性能具有一定优势,但其在各数据集上的运行时间较长,因此MLP 在ARR指标的元数据集中取得的胜出次数较少.CNN 的分类性能较弱且运行开销较高,在7 个指标上的结果较差.
3.3 参数敏感性分析
为了确定合适的参数设置,本节设置种群规模N=50 和最大迭代次数T=300,对方法的关键参数,即基分类器个数V和多样性指标DI进行敏感性分析.
为了便于说明,以DAcc元数据集为例,DI∈{QS,KS,CC,AM,DF},V∈{10, 15, 20, 25, 30},对方法独立运行20 次的平均帕累托解数量和准确性精英蚁狮的ER平均值进行对比,结果分别如图9 和图10 所示.
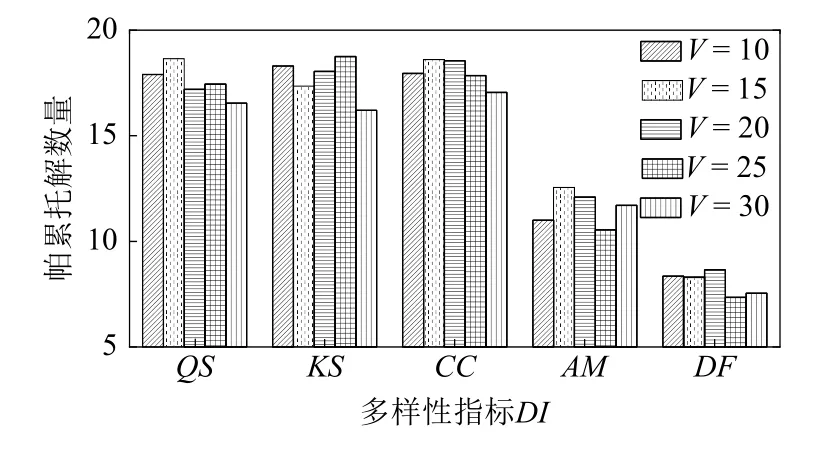
Fig.9 Pareto solution numbers of different diversity indicators图9 不同多样性指标时的帕累托解数量
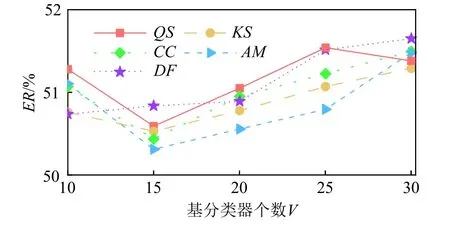
Fig.10 Error rates of different base classifier numbers图10 不同基分类器个数时的错误率
观察图9 中的帕累托解数量,其在5 种多样性指标上均呈现相同的变化趋势,即随着基分类器个数V的增加,帕累托解数量整体呈现出先增加后减少的趋势,当V=15 时,SAMO 在5 种DI上的帕累托解数量相对较多.另一方面,当使用QS,KS,CC指标时,SAMO 产生的帕累托解数量较为接近,优于AM和DF指标上的结果.
分析图10 结果可以发现,随着基分类器个数V的增加,SAMO 的ER性能在5 种多样性指标上均呈现出先降低后提升的趋势,当基分类器个数V=15 时,5 种指标上的ER值取得最优结果.此外,当基分类器个数V相同时,5 种指标上的ER性能较为接近,其中AM指标上的整体表现优于其他指标.
进一步分析图9 和图10,随着V的增加,基分类器的多样性得到提升,集成的效果变好;而当V>15 时,基分类器多样性的提升有限,却引入了部分准确性较差的基分类器,同时方法个体的搜索空间扩大,搜索效率降低,导致了方法性能的下降.
综合上述结果,为了获取具有较好算法选择性能的集成元算法,设置基分类器个数V=15 较为合适,多样性指标DI宜使用AM指标.
3.4 优化算法效果验证
对本文所提多目标混合蚁狮优化算法、多目标蚁狮优化(multi-objective ALO,MALO)[41]、第2 代非支配排序遗传算法(non-dominated sorting genetic algorithm 2,NSGA2)[42]、速度约束多目标粒子群优化(speed-constrained multi-objective particle swarm optimization,SMPSO)[43]以及第2 代强度帕累托进化算法(strength Pareto evolutionary algorithm 2,SPEA2)[44]的优化性能进行比较,其中NSGA2,SMPSO,SPEA2基于框架jMetalPy[45]实现.各对比算法均采用连续型编码,设置阈值为0.5 对个体的元特征选择编码进行离散化.具体而言,设Ai为个体的第i维元特征选择编码,当Ai≥0.5 时表示第i个元特征被选择,Ai<0.5 时表示未被选择;在个体的选择性集成编码部分设置与本文算法相同的编码和解码方式.
设置基分类器个数V=15,多样性指标DI为AM,算法种群规模N=50,最大迭代次数T=300,取算法独立运行20 次的平均结果.对算法准确性最优个体的ER值、多样性最优个体的DI值和帕累托解数量进行比较,结果如表5~7 所示.
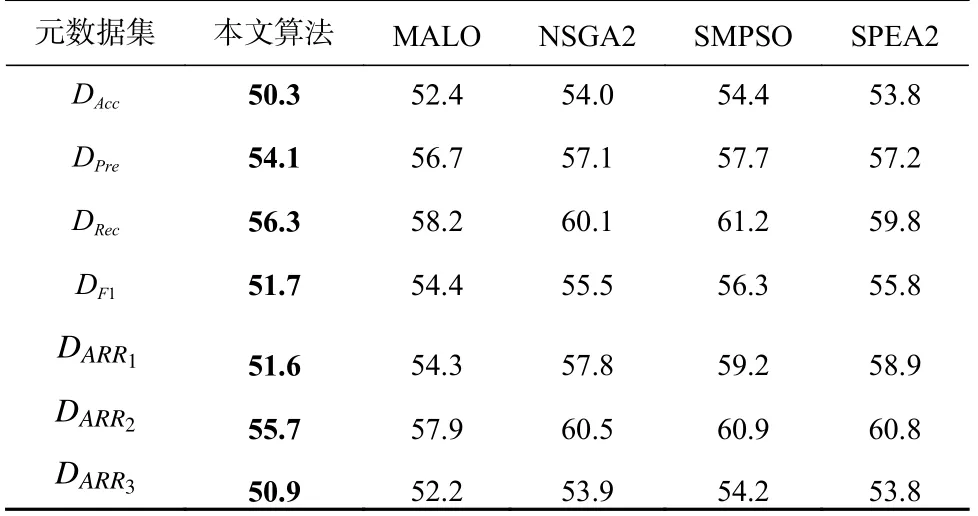
Table 5 Error Rate Results of the Algorithms表5 各算法错误率结果%
从表5 和表6 可以看出,本文算法的准确性最优个体和多样性最优个体分别可以取得最低的ER值和DI值,说明其寻优性能优于其他对比算法.对比MALO,NSGA2,SMPSO,SPEA2 的结果,不难发现MALO 的性能优于另外3 种算法.
表7 中,本文算法可以产生较多的帕累托解数量,而其他算法的帕累托解数量较之有明显的差距,进一步验证了本文算法具有较强的寻优性能.
使用非支配比率(non-dominance ratio,NR)[46]、超体积(hyper volume,HV)[47]和空间指标(spacing,SP)[48],对各算法的解集质量进行评估.NR将不同算法产生的多个解集合并为1 个解集并从中筛选出帕累托解构成解集Sm,然后计算某一个解集中的解在Sm中所占的比例,比值越大说明该解集的质量较之其他解集的质量越优.HV计算解集与目标空间中的最差点所构成空间的面积,ER和DI最差的指标值均为1,因此最差点为(1,1),HV值越大表示解集质量越好.SP计算解集中相距最近的2 个解距离的标准差,其值越小代表解的分布性越好.各算法在NR,HV,SP上的比较结果如表8~10 所示.
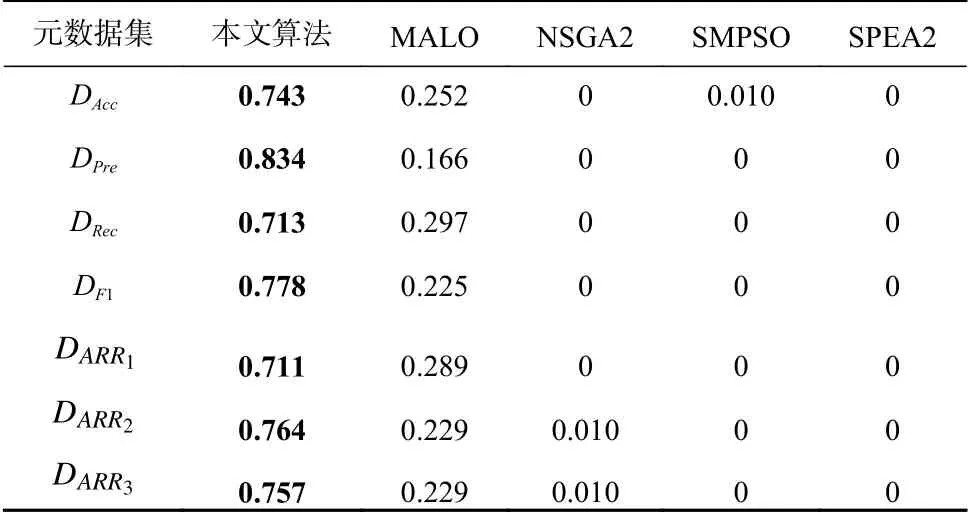
Table 8 NR Results of the Algorithms表8 各算法NR 结果
对比表8 中的NR结果,相较于其他算法,本文算法有明显的优势,展现了更强的收敛性.MALO可以搜索到本文算法所未能发现的帕累托解,具备一定的寻优性能.NSGA2,SMPSO,SPEA2 在NR上的表现较差.
分析表9,所提算法在各元数据集上取得了最大的HV值,表明算法产生的解在目标空间中距离最差点较远,解集的质量高于其他算法.MALO 在个别元数据集上可以取得与本文算法相近的HV值,其性能优于NSGA2,SMPSO,SPEA2.
表10 的结果显示5 种算法在不同元数据集上具有较优的SP值,其中本文算法和MALO 分别在部分元数据集上都取得了最优结果,NSGA2,SMPSO,SPEA2 的结果较为接近.结合帕累托解数量结果,本文算法产生较多的帕累托解,同时可以保持较好的分布性.
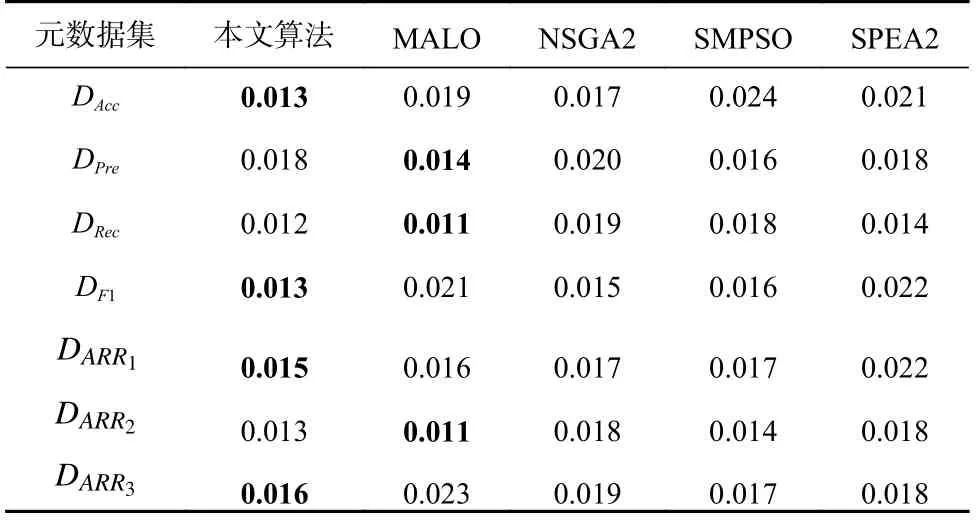
Table 10 SP Results of the Algorithms表10 各算法SP 结果
综合上述分析,在对算法选择模型进行优化时,相较于其他4 种算法,本文算法可以在2 个优化目标上搜索到更优解,并且可以发现数量更多且质量更高的帕累托解,在收敛性和分布性上有较大的优势,说明本文算法在寻优性能上具备优越性.
3.5 SAMO 实验结果
采用与3.4 节相同的方法参数设置,取SAMO 运行20 次所得的准确性精英蚁狮的性能均值进行对比,各方法的ER比较结果如表11 所示.
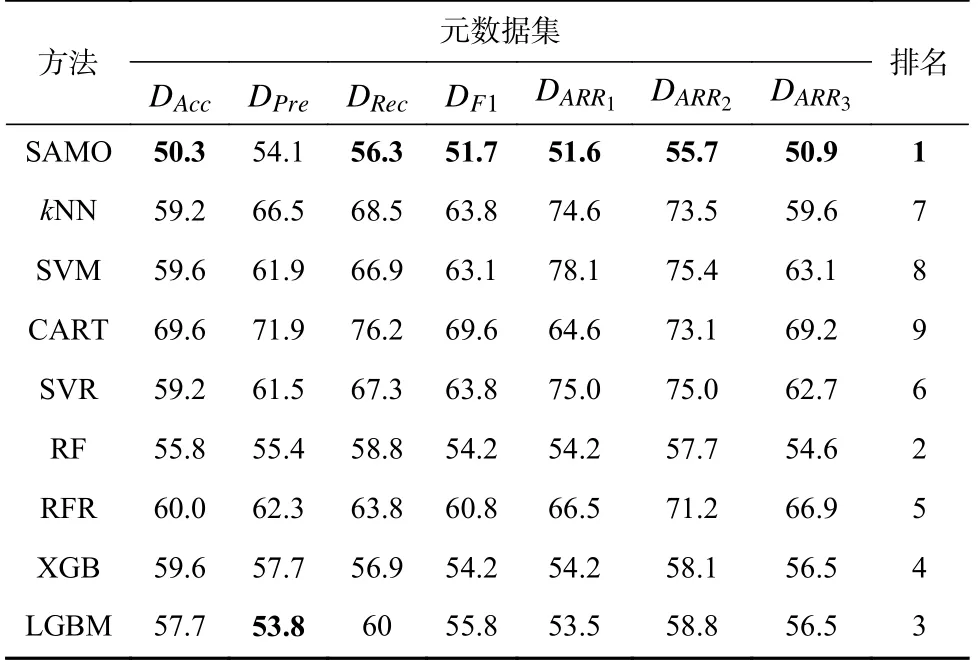
Table 11 ER Results of the Methods表11 各方法ER 结果%
对表11 进行分析,可以看出SAMO 在各元数据集上有更优越的性能,其在除DPre外的其他元数据集上均取得了最好结果.kNN,SVM,CART 的性能较弱,SAMO 的性能明显优于这3 种元算法.SVR 预测各候选算法的性能指标值,比较预测值并选择最优算法,计算开销较高,且其在ER指标上不具备性能优势.在集成方法中,除SAMO 外,RF 具有较好的性能,在各元数据集上均有较好的表现;RFR 结合集成和回归方法,预测算法的性能指标值,其性能优于SVR 但明显劣于其他集成方法;XGB 在DRec元数据集上的性能强于RF,但是方法的整体性能不如RF;LGBM的整体表现并不突出,但其在DPre元数据集上取得了最优结果.将SAMO 与平均性能排名第2 的RF 进行比较,SAMO 有着2.9%的平均性能领先,证明了SAMO 在ER指标上的优越性.
进一步使用查准率、查全率和F1 得分指标比较方法性能,结果如表12~14 所示.
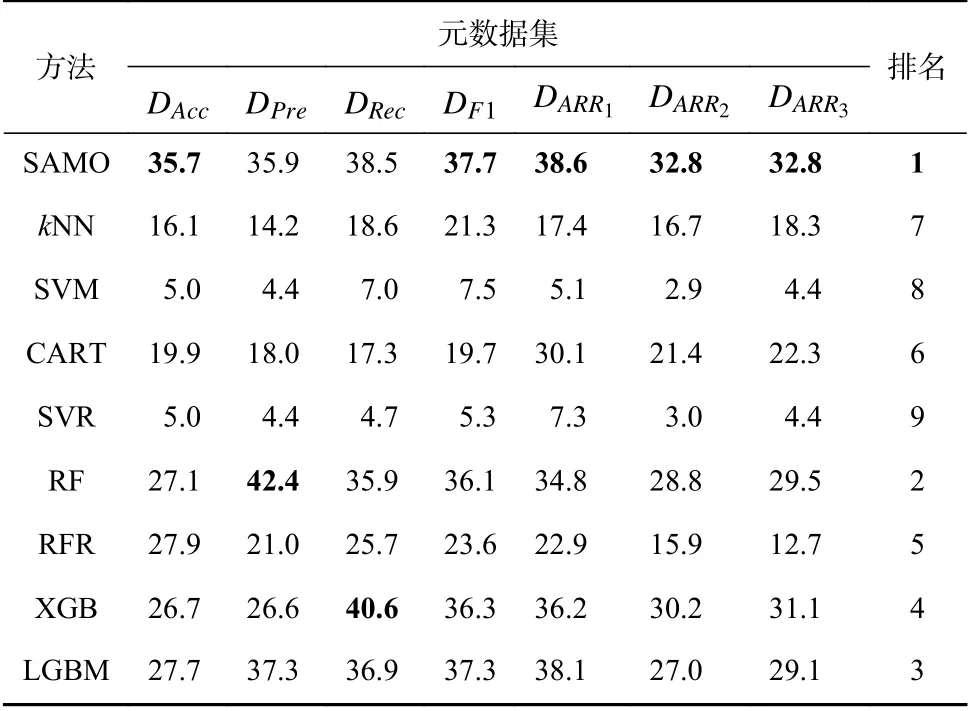
Table 12 Precision Results of the Methods表12 各方法查准率结果%
分析表12 查准率结果,SAMO 在5 个元数据集上均获得了最好性能.kNN 和CART 在查准率指标上的表现明显优于SVM 和SVR.在除SAMO 外的集成方法中,RFR 的性能不如其他方法.RF,XGB,LGBM 的性能较优,其中RF 在DPre元数据集上表现突出,XGB 在DRec元数据集上具有优越性能.SAMO相较于kNN,SVM,CART,SVR 有较大程度的性能优势,其与RF 相比平均性能提升了2.5%,表明SAMO在查准率指标上具有优越性.
表13 中,SAMO 在ARR指标的元数据集上取得了较好的查全率结果.CART 的查全率性能优于kNN和SVM,SVR 的性能表现稍劣于SVM.RFR 的性能优于CART,在DAcc上具有优异表现,但是在其他元数据集上的表现一般.RF,XGB,LGBM 的查全率性能较好,其中XGB 在DRec,DF1,DARR2元数据集上以及LGBM 在DPre元数据集上表现优异.SAMO 的性能相较于RF 平均领先了2.5%,相较于XGB 平均领先了0.5%,说明SAMO 在查全率指标上具备一定的有效性.
从表14 可以看出,SAMO 在各元数据集上的F1得分性能较好,在部分元数据集上取得了最好的结果.在kNN,SVM,CART 中,CART 的性能优于kNN和SVM.SVR 与SVM 的性能较为接近,与其他方法的差距较大.RFR 的性能稍劣于CART,表现较为一般.RF,XGB,LGBM 具有较好的F1 得分性能,其中XGB 和LGBM 分别在不同元数据集上表现突出.SAMO的F1 得分优于kNN,SVM,CART,另一方面,其相较于RF 性能平均提升了2.4%,与XGB 相比则性能平均提升了0.8%,验证了SAMO 在F1 得分指标上的有效性.
将SAMO 与RF,RFR,XGB,LGBM 这4 种集成方法进行对比,SAMO 使用3 种基分类器进行选择性集成,而其他方法仅使用CART 基学习器进行集成,SAMO 生成的集成元算法具有更强的多样性.另一方面,在实验测试中,SAMO 构建的集成元算法在DAcc,DPre,DRec,DF1,DARR1,DARR2,DARR3上平均集成的基分类器数量分别为7.7,6.5,6.7,7.2,5.5,7.1,7.8,而其他方法固定使用100 个基学习器进行集成,由此可见SAMO 通过选择性集成有效减少了基学习器的数量,从而降低集成元算法的存储和运行开销.
综上所述,SAMO 选择具有互补性的元特征子集,并使用不同类型的基分类器进行选择性集成,生成具有较好算法选择性能和多样性的集成元算法.其在测试指标上的性能均明显优于kNN,SVM,CART,SVR 方法,而与RF,XGB 等采用同构基学习器的集成方法相比,也具有相对优越的性能表现,证明了SAMO 的有效性和优越性.
4 结 论
为了提升基于元学习的算法选择性能,提出基于多目标混合蚁狮优化的算法选择方法SAMO.设计算法选择模型,引入元特征选择和选择性集成,同时寻找互补性较强的元特征子集和对多种元算法进行选择性集成;提出多目标混合蚁狮优化算法求解模型,使用混合编码机制选择元特征并构建集成元算法,采用增强游走策略和偏好精英选择机制提高寻优性能.构建分类算法选择问题进行实验测试,将SAMO 与8 种典型的元算法进行对比,结果显示SAMO具有优异的算法选择性能,明显优于kNN,SVM,CART,SVR 元算法,较之RF,RFR,XGB,LGBM 这4 种集成元算法也有一定优势,并且具备更强的多样性,综合体现了SAMO 的有效性和优越性.
未来的工作包括3 个方面:
1)由于算法选择相关因素较多,问题较为复杂,因此目前本文所提方法SAMO 的效果有限,后续将深入研究数据集、元特征和元算法的内在关系,对SAMO 进行改进,显著提升算法选择性能.
2)本文方法的时间复杂度较高,未来将通过并行计算、迁移学习等手段降低方法的训练开销.
3)将SAMO 拓展应用于实际工程,构建算法选择系统.
作者贡献声明:李庚松提出方法设计,负责实验方案的实现和论文内容的撰写;刘艺提出研究问题,梳理论文结构;郑奇斌整理论文内容,负责实验数据集的收集和处理;李翔参与方法的实验结果分析;刘坤提出方法思路的改进建议;秦伟提出论文修改和优化建议;王强负责实验方案的实现指导;杨长虹给出完善论文整体框架的建议.
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
数学年刊A辑(中文版)(2020年2期)2020-07-25
电子制作(2019年22期)2020-01-14
数学物理学报(2019年6期)2020-01-13
疯狂英语·新读写(2018年3期)2018-11-29
电子测试(2018年1期)2018-04-18
数学物理学报(2017年5期)2017-11-23
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
