
基于目标检测和迁移时间序列的教室人员检测
2023-08-04 07:57丛帅杨磊华征豪杨晓晖
河北大学学报(自然科学版) 2023年4期
丛帅,杨磊,华征豪,杨晓晖
(1.河北大学 工商学院,河北 保定 071000;2.河北大学 教务处,河北 保定 071002;3.河北大学 网络空间安全与计算机学院,河北 保定 071000)
近年来,随着国家对教育进行智能重构的不断重视[1],人工智能在教育中拥有着巨大的研究空间和发展潜力,其中,教室的使用和分配问题影响着教育场地资源规划和建设等诸多方面.利用现有资源得到一个精准量化参考的方法,能够在节约人力物力的情况下合理布局,高效地进行教育建设.教室的使用和分配通常需要对教室内的人员进行目标检测,相比开放场合下的应用场景,教室内人员的目标检测有环境变化小、人员位置固定时间长的优势,但是也存在着人-人、人-物遮挡,不同教室的光照量差异和由于各种物品存在而导致的教室背景复杂多变,干扰较多的问题.同时,由于不同教室和不同学校之间视频捕获设备存在的图像压缩损耗、噪点等问题,数据来源差异性较大,因此很难单独采用基于运动的目标检测方法对教室人员进行识别和统计.为了更好地进行教室人员目标检测,本文在YOLO算法的基础上进行了改进.
一般将目标检测过程分为2个阶段:目标分类和目标位置坐标确定.在深度学习流行并拥有硬件支撑之前,常用的目标检测方法有如文献[2]使用的方向梯度直方图算法(histogram of oriented gradient,HOG)、文献[3]使用的可变形组件模型(deformable part model,DPM)、文献[4]使用的Haar算法等,其中HOG利用图像的梯度数据反映目标边缘,并通过梯度大小提取图像的特征,此算法中的不同尺度参数、梯度方向等均会对目标检测结果产生较大影响,抗干扰能力欠佳.DPM算法通过使用不同分辨率的滤波器进行特征提取,相比单一HOG效率有所提高,但其参数设计极为复杂且应对抖动、倾斜等稳定性较差.Haar提出了积分图的概念,并将图像经过积分计算得到的结构划分为不同种类的基本形态进行识别,但由于其对明暗的敏感性,对于非正面人脸的识别效果较差.
随着深度学习算法的不断发展,基于深度学习的行人检测算法取得了极大的进展.该类算法主要可以分为有先验框的两阶段方法和没有先验框的单阶段方法.两阶段方法中经典的算法有:文献[5]提出的Mask-RCNN算法和文献[6]使用的Faster R-CNN算法等.单阶段方法中最流行的则是由文献[7]所提出的YOLO算法,其中,单阶段算法由于其效率高、准确率高、便于训练的特点而处于主流地位.为了克服单阶段方法中不同尺度和不同难度样本偏差的问题,文献[8]在YOLO算法思想的基础上提出了使用特征金字塔(feature pyramid network,FPN)的多尺度特征提取的改良方案.虽然经过多尺度图像特征融合后该算法明显提升了目标识别的准确率,但是其在处理带有时间序列的数据时忽略了流式数据的时间连续性.于是,本文结合现有的图像处理算法,利用对教室视频捕捉设备能够获取到的流式数据进行时间序列的迁移,改进连续识别的算法规则,针对以监控设备为主的边缘端提出了基于目标检测的高性能教室人员目标检测算法.
1 所提算法
本文提出的算法由生成对抗网络(super resolution GAN,SRGAN)、YOLO、NMS和TSM组成,算法的框架图如图1所示.
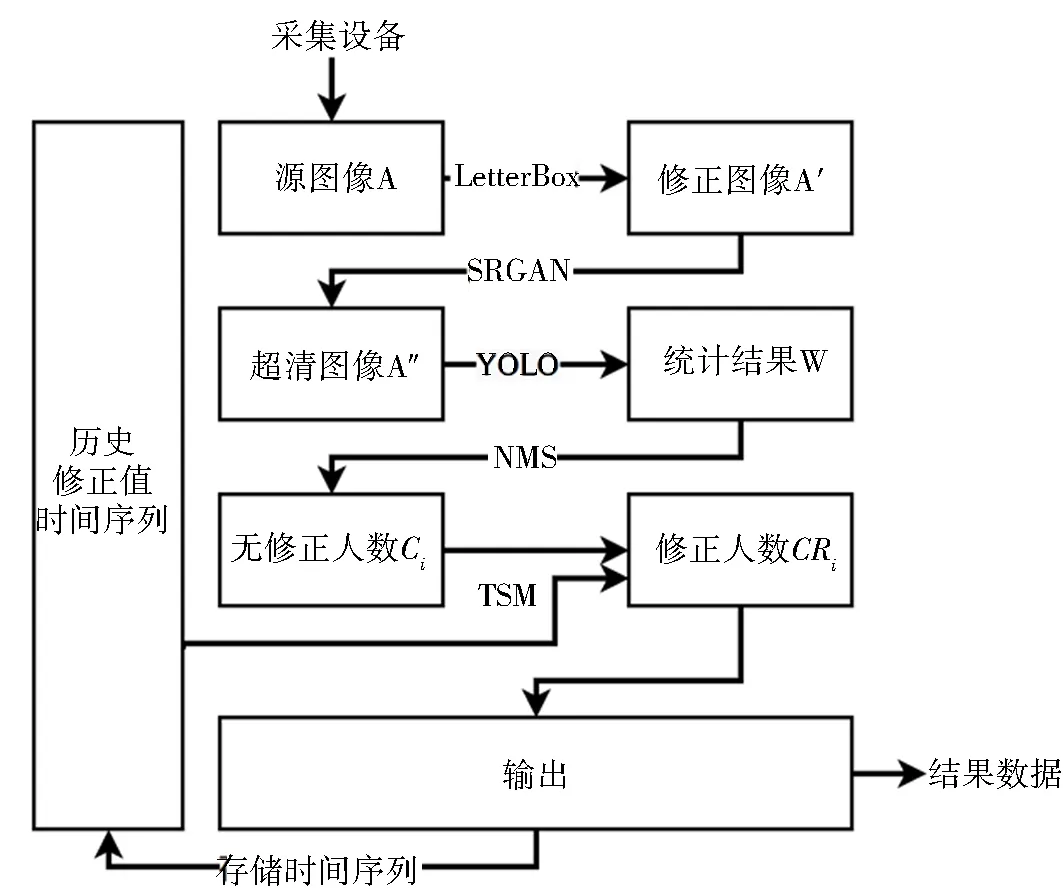
图1 基于目标检测和TSM的教室人员检测框架Fig.1 Diagram of classroom personnel detection algorithm based on object detection and TSM
设在i时刻输入具有不同长宽的图像A,经过目标检测后得到人员位置数据.由图1可知算法的流程如下:
首先,对输入图像A进行LetterBox放缩至模型使用的传入图像尺寸,获得相应的放缩图像A′.当图像在放缩时长宽比不满足要求时将空出部分进行纯色填充以便于识别适配.
其次,使用SRGAN进行图像清晰化处理得到高清图像A″用于进行后续处理.
再次,利用改进后的YOLO模型进行多尺度特征提取和分类回归,得到3种尺度下的检测结果,合并为W.
然后,通过NMS方法对数据进行清洗,得到当前源人数Ci.
最终,通过TSM方法,使用之前的时间序列参考值得到修正人数CRi,并将其存储于内存中,供下一帧使用.
下面对所提算法的各个部分进行详细介绍.
1.1 SRGAN算法
由于在进行教室人员目标识别时,所采集的图像往往会受到光照和灯光等因素的印象,尤其是晚上采集的视频分辨率有所下降,因此本文采用文献[9]提出的SRGAN算法对视频数据进行超分辨重建.SRGAN通过GAN来从低分辨率的图像(low resolution,LR)生成高分辨率的图像(high resolution,HR),其总体效果如图2所示.

a.模糊图片;b.高清图片;c.SRGAN结果图2 SRGAN超分辨率效果Fig.2 Visualization of SRGAN
GAN由生成器(generator,G)和判别器(discriminator,D)2个部分组成.本文将训练GAN网络,从而获得一个最优的生成器用以生成高清图像.由于神经网络可抽象为通过输入得到输出的结构,可以将问题转化为得到一个最优的生成函数得以最好地使超分辨率结果接近真实情况,同时训练过程中需要得到一个最优的判别函数以最好地鉴别出生成的图片质量.
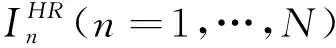
(1)
在D部分,本文定义了鉴别器神经网络DθD用以完成最大最小博弈过程,如式(2).

(2)
其中,ptrain为图片数据的分布.神经网络DθD为文献[10]中给出的VGG网络,其卷积核大小为3×3,使用全连接网络和LeakyReLU激活函数得到样本的真实概率.
1.2 改进的YOLO算法
基于卷积神经网络的YOLO算法核心原理是将目标检测的问题转化为回归和分类的问题.不同于滑动窗口和区域划分类型的算法和模型,YOLO算法使用整张图进行训练和预测,因此能够通过更大的视野更好地区分整体和局部,从而避免因为背景(如墙、桌椅等)带来的影响,具有非常高的泛化性能.同时,其单阶段特征提取和识别的结构相比RCNN等两阶段算法省去了第一阶段生成预选框的操作,在效率上有大幅度地提升.模型的核心过程为:模型首先将图像切分为S×S(不足使用纯色填充)的正方形图像,为每个小正方形预测B个预测框、置信度和C种分类可能性数值,最终得到S×S×(B*5+C)个张量数据[7].
YOLOv5是YOLO系列算法经过多次改进和迭代后的结果,本文在此基础上添加了注意力块,在目标识别上能够较好地确定目标.本文改进后的YOLO模型结构如图3所示.
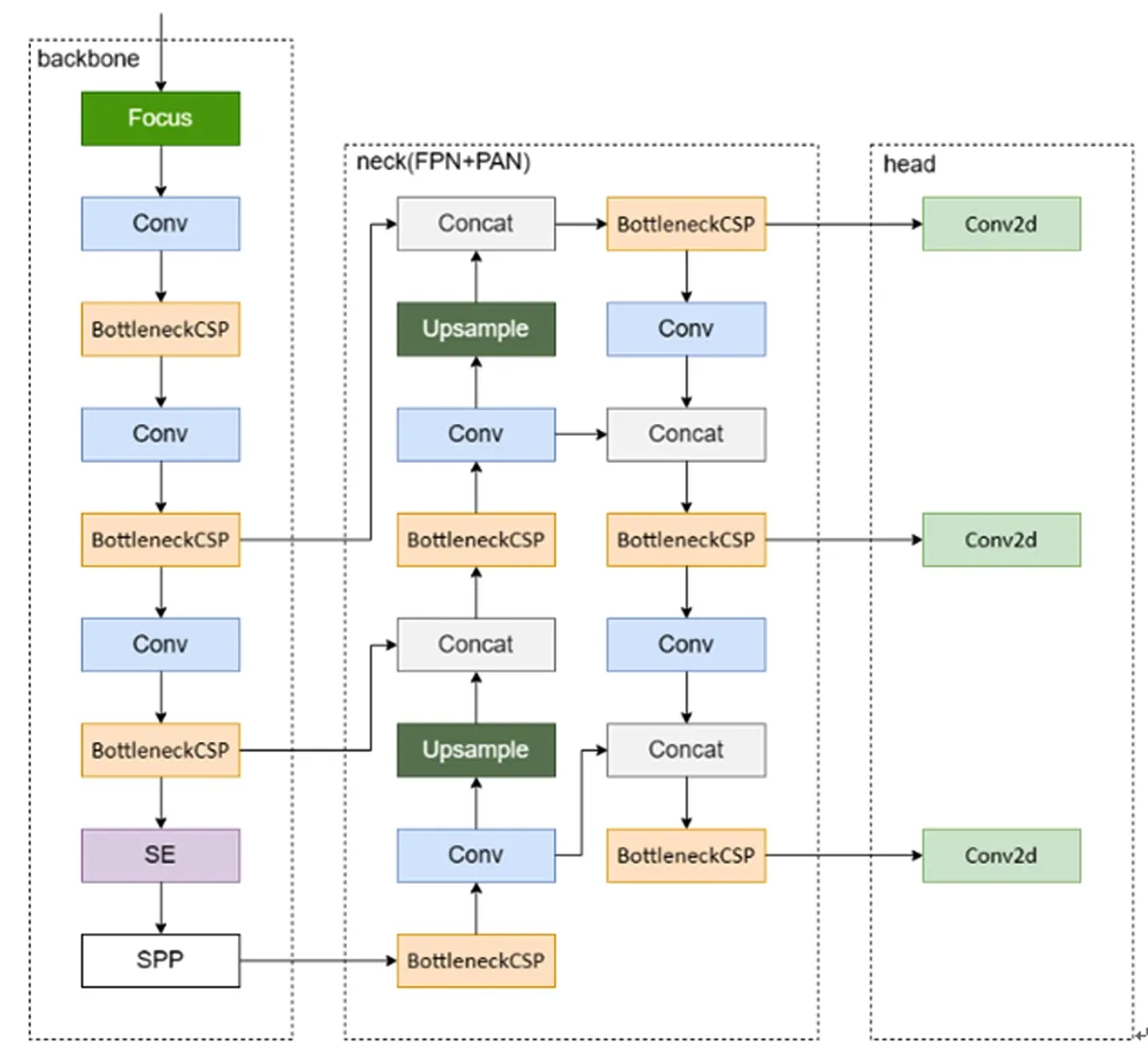
图3 改进YOLO网络模型Fig.3 Model of improved YOLO
本文算法的骨干网络采用的是Focus+BottleneckCSP卷积层,降低卷积维数,有效减少了重复的梯度学习,提升了YOLO网络的学习能力和学习效果.同时为了兼顾复杂背景下识别的准确率和效率问题,本文选用的注意力机制为挤压和激发网络[11](squeeze and excitation network,SE),其结构如图4所示.
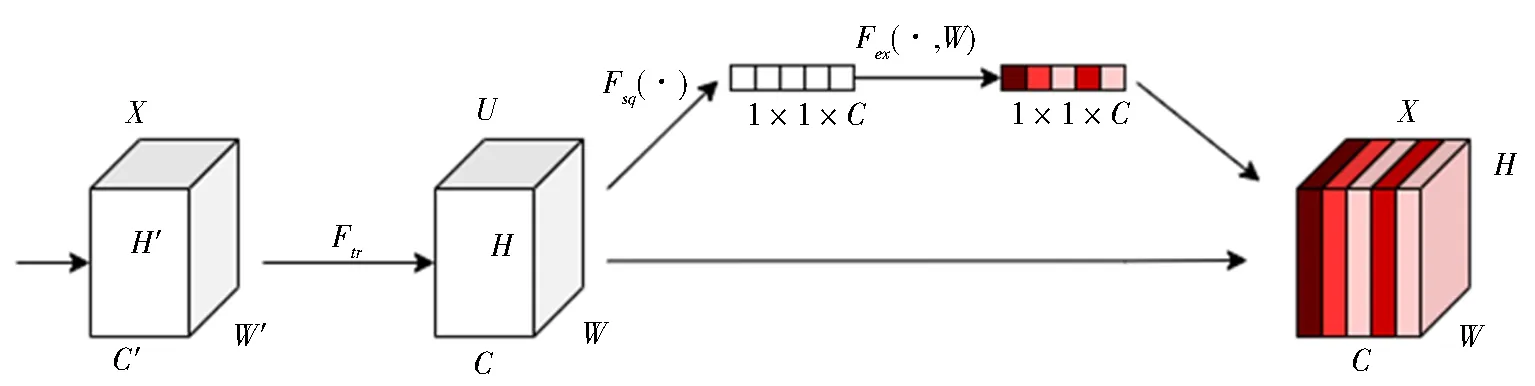
图4 SE网络结构Fig.4 Architecture of SE
由图4可知,SE网络将输入通过1次平均池化后进行全连接,然后经过ReLU函数进行激活后再次使用Sigmoid函数进行激活.
改进的YOLO算法多层次特征提取层部分使用特征金字塔网络[8](feature pyramid network,FPN),生成特征金字塔,从而获得高级语义特征图,便于小目标检测的同时保证大目标的检测准度;同时使用路径聚合网络[12](path aggregation network,PAN)进行定位信息的补偿避免特征和定位的模糊.该算法预测层(head)使用3个检测器,利用基于网格的锚点在不同尺度的特征图上进行目标检测过程,最终获取结果.YOLO模型中的激活函数使用带有负值的线性激活函数以保留部分特征,其公式为
(3)
本文设置模型传入图像的大小为640×640,步长S为8.利用YOLO算法,能够快速获得目标检测的结果.在模型的训练过程中,本文标记有候选框的位置为正例,没有候选框的位置为负例.由此定义预测中正例被预测为正例为TP,正例被预测为负例为FN,负例被预测为负例为TN,负例被预测为正例为FP.由此可以得到2个指标:精确度(Precision,P)和召回率(Recall,R),其计算公式如式(4)和式(5).
(4)
(5)
1.3 TSM算法
对教室人员的计数由于其识别类型单一、基于时间而变化的特点和人员变动行为相对于捕获设备缓慢的特点,当因人员进出而出现运动目标时算法的检测人数会围绕真实值上下波动,然而在人员运动开始前和结束后均能得出准确值.由此可见,能够通过一定区间内的时间序列进行合并迁移从而得出精确的目标检测值.
本文基于迁移时间序列概念提出一种TSM算法,通过计算一定时间区间内的统计平均值忽略不必要的上下文信息,做到不消耗额外时间,并且能够有效进一步改善遮挡、运动情况下带来的统计精度不高的情况.TSM算法其计算公式最终的递推公式如式(6),赋值公式为在计算出RCi后的公式(7).
(6)
Ci=RCi,
(7)
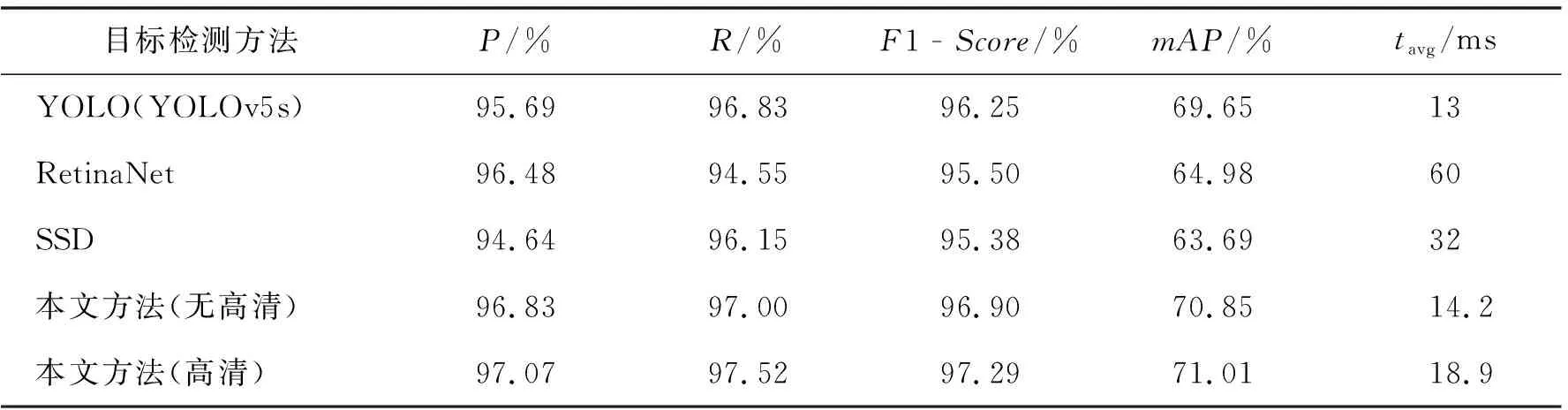
其中,RCi为i时刻经过TSM方法计算得出的修正值,Ck(k 采用改进的YOLO算法对采集到的视频流进行逐帧识别检测,由于模型可接受的图像尺寸常常与实际输入图像不同,且传统放缩将会造成图像畸变,本文采用如文献[13]提出的LetterBox放缩.计算总体缩放比例r和长宽各自缩放比例的公式如下: (8) 非极大抑制[14](non maximum suppression,NMS)是常用的过滤无效值的方法,其使用基于交并比(intersection over union,IoU)阈值进行判断并去除低于阈值的候选项,IoU公式如式(9),其值为A、B交集的空间大小与A、B并集的空间大小之比. (9) 本实验在操作系统为Windows11的工作站上运行,其核心配置为Intel Core i7-10700 * 1, Nvidia RTX 2080Ti * 1以及32G的DDR4运行内存.深度学习框架为Python3.7.8和Pytorch1.7.训练周期设置为70,批量训练大小为32,超分辨率部分的输出图像大小设置为640×640,目标检测部分设置检测输入大小设置为640×640,测试过程中置信度阈值设置为60%,IoU阈值设置为10%. 实验所用的数据来自公开数据集Brainwash.实验数据来自Brainwash数据集,拍摄内容为标注完成的咖啡馆中出现的人群.该数据集包含3个部分,训练集共10 769张图像81 975个人头;验证集为500张图像3 318个人头;测试集共500张图像5 007个人头. 为了有效地评估该算法在不同质量数据源中识别的性能,客观评价指标采用5种不同的方法,如交并比(intersection over union,IoU)、精确度(Precision,P)、召回率(Recall,R)、平均准确率(mean Average Precision,mAP)、F1指标,并通过可视化对比展示结果的差异性.这5种指标中,精确度、召回率、平均准确率和F1指标越高且交并比越低表明头部目标识别的效果越好,识别结果的数量和位置越准确,识别模型越稳定. 本文同时对训练时的上述参数进行计算以比较不同模型间的收敛速度和识别性能偏差.其中,mAP的计算公式如式(10),F1指标计算公式如式(11). (10) (11) 其中,Pinter为P-R构成的曲线通过计算每个R值对应的P值.mAP用于计算在不同IoU置信度区间下模型的准确率特性,F1指标由调和级数导出,用于计算模型的稳定程度.两者越大说明算法的性能越好. 首先对超分辨率部分进行采样前后清晰度比较测试,图5a-b为经典的人像识别数据集BrainWash中选取的人群密集和稀疏时的典型图像.所得超清图像见图5c-d,吊灯、人物部分能够发现本文的算法能够更清晰地表现图像,更符合人眼特性,进一步提升目标检测输入质量.具体细节举例见图5e-h. 图5 Brainwash原始图像和超清处理比较Fig.5 Comparison of super resolution method and Brainwash original image 然后对超清前后图像传入本文的YOLO模型进行比较.图6a-b为原始密集和稀疏人群图像识别结果,图6c-d为超清后密集和稀疏人群图像识别结果. 图6 Brainwash原始图像和超清识别结果比较Fig.6 Comparison of detection results of super resolution method and Brainwash original image 从实验结果中可以发现,融合结果中人员头部位置均定位准确,而在目标置信度上超清处理后的图像普遍高于原始图像. 通过训练文献[7]提出的YOLO算法、文献[15]提出的RetinaNet算法、文献[16]提出的SSD算法,并和本文方法进行比较,原始图像和识别结果依次对应图7a-e,图片选用Brainwash数据集中不同于图6中的另一图片. 图7 Brainwash图像和各算法识别的识别效果Fig.7 Detection effects of each method and Brainwash original image 在实验结果中可以发现,各种算法经过相同数据集训练后识别效果类似,能够发现本文的算法在平均置信度上结果更佳,并且在定位框位置上更精准,克服了置信度偏差较大导致的潜在漏检或错检,对于处于移动状态的人员目标检测也能够取得较高准确率. 同样,表1给出了各种目标检测算法的客观评价指标.由表1可知,本算法具有良好的客观评价标准.这也说明本算法不仅能够发掘源图像中潜在的目标细节信息,很好地避免环境光、复杂背景等的干扰,并且对于不同复杂程度和人员的图像识别具有鲁棒性. 表1 图7中各个算法效果基于Brainwash数据集的客观评价指标 最后在连续的视频数据流应用场景中,为了比较TSM算法对于误差的有效修正,以及相比于文献[17]提出的Deep-sort算法的优越性,本文通过录制教室人员从5人减少到1人时的视频数据,并通过使用不同方法进行修正和不进行修正的结果分析和比较.由表2中实验结果统计数据可见,由于TSM算法不额外增加时间复杂度的特性,相比于基于图像本身内容的Deep-sort算法能够更有效率且准确率相近.因此TSM算法能够在更短时间内得到较为准确的值,在教室环境下是一种比较好的高效修正算法. 表2 修正算法的客观评价指标 综合上述实验可见,本文所述教室人员目标检测方法各部分在实验中都具有最好的综合客观评价标准,所以综合看来本文所提出的目标检测规则是一种较好且值得推广的应用于教室人员识别检测中的方法. 提出了一种基于目标检测和迁移时间序列的教室环境下人员检测方法.该方法有效地利用了超分辨率技术对于图像细节的补充以及单阶段方法对于特征提取和分类回归的高效性.同时,通过加入注意力机制网络增加了原目标检测模型的准确度,又基于教室简单环境和人员行为的特点提出TSM方法,进而弥补了由于人员移动和模糊、重叠导致的识别不准确问题,使得检测能力进一步增强,优于文中单独使用的目标检测和效率相对较低的Deep-sort算法.综合上述实验表明,该方法具有更好的精准性和高效性,在教室环境下进行人员目标检测更优于目前比较流行的目标检测算法.1.4 NMS算法
2 实验方法
2.1 实验环境
2.2 实验数据
2.3 评价指标和对比内容
3 实验结果与分析




4 结语
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
快乐语文(2021年35期)2022-01-18
少先队活动(2020年11期)2020-12-28
作文小学中年级(2020年6期)2020-07-24
甘肃教育(2020年21期)2020-04-13
科学大众(中学)(2018年10期)2018-12-27
自然资源遥感(2014年3期)2014-02-27
意林(2011年10期)2011-05-14
中学英语之友·上(2008年2期)2008-04-01
中学英语之友·上(2008年2期)2008-04-01
