
单次定制订单的青年女性群体服装定制号型
2023-08-31 11:47徐希朋徐燕妮季晓芬
丝绸 2023年8期
关键词:聚类分析
徐希朋 徐燕妮 季晓芬


















摘要: 为了满足消费者对于服装合体性的更高需求及企业提高服装定制生产效率的需要,文章提出考虑拟合度损失系数的青年女性服装定制号型的制定方法。使用三维人体扫描收集100名年龄在18~25周岁的青年女性的8项人体数据,包括身高、胸围、腰围、臀围、背长、肩宽、腿长和大腿围,采用主成分分析、相关性分析确定聚类的依据变量,使用拟合度损失系数方法确定聚类数,然后通过K均值聚类分析和线性回归分析得到定制号型表。为证实拟合度损失系数方法的优越性,另选取两种确定聚类数的方法混合F统计量和最终聚类中心距离和,设置对比实验。实验结果表明,考虑拟合度损失系数制定的服装号型相较其他两类方法,在合体性、覆盖率和生产效益等方面的综合考量更优。
关键词: 服装批量定制;服装号型;聚类分析;拟合度损失系数;服装合体性
中图分类号: TS941.17 文献标志码: A
文章编号: 10017003(2023)080082-09
引用页码: 081110 DOI: 10.3969/j.issn.1001-7003.2023.08.010
服装号型在指导服装生产、调控生产成本、帮助消费者挑选服装等方面的作用弥足轻重。然而,现阶段服装号型因易出现与个体体型的不匹配,使得服装难以满足消费者更高的合体性需求[1]。为调和离散性与合體性的矛盾,服装大规模定制成为解决号型与个体体型的离散问题、满足消费者服装合体性需求的重要途径。根据中研普华研究院研究数据显示,中国2022年服装定制产业市场整体规模为2 000亿元[2]。国内服装定制市场需求庞大,因此对制定服装号型的技术方法进行革新,使其进一步满足服装大规模定制的需要。
在已有的研究中,Tryfos[3]提出整数规划方法、McCulloch等[4]使用非线性规划方法制定号型,但开发的号型表过度倾向于预先设定的约束。之后聚类分析[5]、神经网络[6]和决策树[7]等数据挖掘技术被应用于开发服装号型。齐静等[8]应用三维人体扫描描述青年男性体型,通过聚类分析将西部男性体型分为7类。余佳佳等[9]通过优化聚类分析方法进一步细分体型,但仍没有解释人体测量变量之间的关系。张小妞等[10]以身高与腰围为自变量,得到不同体型的数学回归模型,定义了同一体型内的变量关系,为档差设置提供了数学模型基础,但没有通过计算拟合度损失,即服装尺码与身体净量尺寸的离散性对该档差的合理性作进一步评价。
随着消费者对于服装合体性需求的提高,拟合度损失的研究逐渐深入。对于服装合体性,Alexander等[11]、Boorady[12]、许轶超等[13]学者使用主观评价的方法,选定特定人体部位作为评价合体性的因素。主观评价法操作简单、结果清晰,但缺少客观的评价因素,无法量化合体性。Esfandarani等[14]通过计算不同因子数的拟合度损失,量化服装合体性。Vadood等[15]使用拟合度损失确定神经网络的最优学习率。Gupta等[16]通过计算总拟合损失来验证号型表。然而上述研究仅将拟合度损失作为服装号型表的合体性评价指标,在体型分类过程中,没有将其作为体型分类依据,使服装号型更注重覆盖率而非合体性,并不能充分满足消费者对于定制服装的合体性需要。
本文针对企业单次订单内的青年女性客户群体,通过建立拟合度损失系数模型,从服装最终拟合度的角度考虑选择最优聚类数进行K均值聚类分析,并与混合F统计量方法、最终聚类中心距离和两种方法进行对比,以确定服装大规模定制最优号型表。本文为小众品牌及中小型企业的单次订单提供号型定制方法思路,无须搭建消费者三维人体数据库,仅通过收集订单内消费者的八项重要测量部位数据,进而快速制定服装大规模定制号型表。
1 数据采集和预处理
1.1 人体测量变量及数据采集
因服装定制面向中国市场,故不将区域经济发展状况考虑在内,随机选取18~25周岁在校大学生作为实验对象。参考GB/T 22187—2008《建立人体测量数据库的一般要求》,制定大规模服装生产号型的人体测量最小样本量为131人。考虑在服装定制生产模式下,定制订单具有订单批次多、每单数量少、生产需求多变等特点[17],所制定号型仅适用于某一次订单内的小批量客户群体,不同批次订单需要重新制定号型。且订单内客户数量即为样本采集量,并为此订单内个体身体数据完整的客户制定号型。数据不完整的客户递推至下一次订单,待数据补充完整后制定号型,故不须达到大规模生产标准所要求的最小样本量,由此确定样本采集量为100人。
考虑到小众品牌及中小企业难以对客户群体中所有个体单独进行身体数据测量,故需要顾客线上填报身体数据。因此通过对杨蕾等[18]、潘力等[19]、樊萌丽等[20]、余佳佳等[9]所选用的身体测量部位进行筛选,以及参考GB/T 16160—2017《服装用人体测量的尺寸定义与方法》,得到8个易于消费者测量并且在定制层面上能足够代表身体特征的变量:身高、胸围、腰围、臀围、背长、肩宽、腿长、大腿围。在本文中,使用型号为2NX-16的[TC]2三维人体扫描仪对100个个体测量此8个变量,完成数据采集。
1.2 数据预处理
对收集的100份人体数据进行筛选和检验。在删除缺漏值后,使用箱式图检查是否存在奇异值。Q-Q概率图、P-P概率图是常用的正态分布检验方法,因P-P概率图更加直观、易于判断,所以删除奇异值后,本文使用P-P概率图进行正态分布检验,结果如图1所示。
由图1可见,身高数据基本沿一条直线分布,因此,可以判定身高变量符合正态分布。同理,其余7个变量,经去除缺漏值、奇异值后检验均符合正态分布。经过上述数据处理,最终有效样本数量为87。
2 青年女性人体体型特征变量提取
2.1 人体数据主成分分析
使用SPSS对人体数据进行主成分分析,如表1所示。提取初始特征值大于1的2个成分,其累积贡献率为73.806%。
使用Kaiser标准化的正交旋转法旋转因子载荷矩阵,成分1、成分2所包含变量如表2所示。图2显示了旋转空间中的人体数据变量分布,成分1包括胸围、腰围、臀围、肩宽、大腿围;成分2包括身高、腿长、背长。
2.2 人体特征变量提取
通过主成分分析得到每个成分的特征变量后,对变量进行相关性分析。表3为8个人体特征变量间的相关系数矩阵。
计算8个变量的相关指数以确定聚类的依据变量[21]。相关指数的计算公式如下:
式中:R为变量间判定系数;i=1,2,…,m,其中m为所在成分的特征变量个数;rij为同一成分内第i个特征变量与第j个变量的相关系数,i≠j,j=1,2,…,m。
最终变量相关指数计算结果如表4所示。成分1的所有特征变量中,肩宽的相关指数为0.289 4,远低于其他变量的相关指数;成分2的所有特征变量中,背长的相关指数为0.162 5,远低于身高和腿长的相关指数,故选择身高、腿长、胸围、腰围、臀围、大腿围这6个变量作为聚类依据变量进行K均值聚类分析。
3 人体体型特征变量聚类分析
本文采用K均值聚类分析,它是预先随机设置K个质心,通过计算每一个变量到K个聚类中心之间的距离关系,将变量与距离关系最近的质心归为一类的迭代算法。如今常用的确定聚类数K的方式有两种,其一是按照操作者的经验或者参照实际的尺码标准数量来确定;其二是依照某种指标比对不同聚类数的结果[22]。第一种方式方便省时,但不够精确[23]。因此,本文选取第二种方式确定聚类数K。根据现有的确定聚类数方法的相关文献引用次数及其在服装号型制定中的应用情况,最终选取混合F统计量[24]、最终聚类中心距离和[19]两种确定聚类数的方法。此外,本文提出考虑拟合度损失系数的K均值聚类算法,与前两种方法进行对比,最终获取服装大规模定制的最优号型表。
3.1 混合F统计量
使用混合F统计量确定K均值算法的优聚类数,其混合F统计量值越大,聚类内联系越密切,聚类之间的联系越疏远[24]。具体计算公式如下:
式中:c为预先设置的聚类数;ni为第i个聚类的样本个数;vik为第i个聚类的第k个特征变量的聚类中心;vk为第k个特征变量聚类中心的平均值;k为聚类分析所依据的特征变量;n为样本容量;xijk为第i个聚类中第j个样本的第k个特征变量的实际数值;Mixed-F为混合F统计量;p为聚类分析所依据特征变量总数6。
依据方方等[23]的研究,聚类数区间应在2≤c≤intn,因有效样本数为87,故聚类数量应在区间[2,9]。最终得到不同聚类数对应混合F统计量计算结果及变化趋势,如图3所示。结果表明,聚类3混合F统计量最高,因此3个聚类为最优聚类数。
3.2 最终聚类中心距离和
样本到聚类中心的距离表示了聚类内个体的相关性,数值越低,类内相关性越高。对人体数据进行聚类分析,分别计算聚类数3~9中样本个体到聚类中心的距离并求和。图4为不同聚类数的最终聚类中心距离和碎石图。图4中,聚类数2到聚类数4距离和急剧下降,并在聚类数4时出现拐点,聚类数4到聚类数9距离和相对平缓。因此,选定4为最优聚类数。
3.3 拟合度损失系数
考虑拟合度损失系数的号型制定方法,不同于以往确定体型分类后便进行号型归档的号型制定方法。为体现服装最终合体性对于体型分类的影响,需对不同聚类数预先求得拟合度损失,即对聚类数2~9的所有个体数据进行尺码预归档。归档结束后,计算人体数据与赋予尺码的离散性,依据拟合度损失系数确定最优聚类数后,对预归档的号型进行优化,生成最终定制号型表。
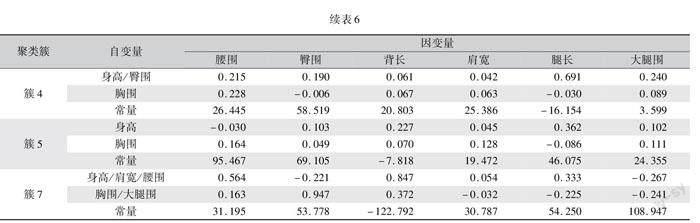
拟合度损失系数通过计算样本值与所赋予尺码的离散程度来表示号型系列的合体性。Esfandarani等[14]咨询领域专家,确定胸围、腰围和臀围是确定服装合体性最重要的尺寸。因此,本文采用这三个特征变量计算拟合度损失系数。确定变量后,需对三个变量的尺寸进行归档赋予尺码。首先,以聚类中心值作为中间体,通过线性回归设置档差,最后根据中间体尺寸、档差对每个个体变量赋予尺码。预先已对聚类数2~9进行计算,得知7为最优聚类数,所以本文以7个聚类数进行演示。因聚类中心值的数据多含有小数,且客户在测量时存在一定误差,所以在保证调整前后数据平均值相近的规则下进行微调,如表5所示。
依据GB/T 1335.2—2008 5.4《中华人民共和国女子服装号型标准》系列,将身高档差设置为5 cm。因18~25岁青年女性体型偏瘦,档差值过大不能准确反映体型,在咨询专家后将胸围档差设置为2 cm。然后进行线性回归的预分析,确定腰围、臀围与身高、胸围的线性关系,以换算档差。计算公式如下:
初步线性回归时,簇4腰围、簇7腰围与臀围三个变量以身高和胸围为自变量初步换算所得档差值为负。故参考表3,选择臀围、胸围作为簇4腰围的自变量;选择肩宽、胸围作为簇7腰围的自变量;选择腰围、大腿围作为簇7臀圍的自变量进行第二次线性回归分析。簇6因为只含有一个样本,故不进行线性回归,最终结果如表6所示。
依据表6偏回归系数,计算服装合体性关键尺寸档差。计算公式如下:
因变量档差数值=B(x1)×自变量x1档差+B(x2)×自变量x2档差(5)
式中:B(x1)为变量x1偏回归系数,B(x2)为变量x2偏回归系数。
档差计算结果如表7所示。
确定档差后,对样本数据中胸围、腰围、臀围进行尺码赋值,簇6样本赋实际值。拟合度损失系数考虑了聚类内、聚类间的联系,通过计算赋予尺码数值与实际值的离散程度,评价服装合体性。
拟合度损失系数Vi优先考虑数值的拟合度损失,其数值越低表示在此拟合度损失所能达到的聚类效果越好。由混合F统计量计算公式可知,倒数加权致使数值较小的F(k)值对最终的混合F统计量计算值影响过大。因人体数据不具有连续性,且為突出所赋予尺码的拟合度损失V的影响及均衡地体现各变量F统计量,对F统计量求均值的倒数记为Fp(k),即Fp(k)值越大聚类内联系越疏远,聚类之间的联系越密切,进而确定最佳聚类数。计算公式如下:
式中:L为预先设置的聚类数;h为关键尺寸变量总数;n为聚类某一簇的样本容量;Xjki表示第j个聚类簇中第k个变量的第i个实际数据;Gjki为Xjki所对应的尺码赋值。
表8为拟合度损失系数的计算结果。聚类数7的Vi值最低,即在优先考虑拟合度损失的情况下,聚类数7聚类效果最好,故选定聚类数7为最优聚类。因簇6只含有一个样本,为提高尺码覆盖效率追求更高的实际生产效益,舍弃簇6中的特殊个体,所以聚类数7对应6种体型。
4 服装号型系列设置与分析
4.1 服装号型系列设置
混合F统计量、最终聚类中心距离和、拟合度损失系数三种方法确定的最优聚类数分别是3、4、7,于是对聚类数3、聚类数4、聚类数7分别设置服装号型。服装号型归档、档差设定方法已在计算拟合度损失系数过程中演示。
本文服装号型系列采用身高、胸围、体型的方式制定,体型分类依照聚类分类确定,体型名称采用罗马数字依次命名。通过减少尺码数量控制实际的生产成本,放弃对某聚类簇中某样本数据所赋予尺码在该聚类簇所有尺码中占比过低的样本数据,以及只有单个样本数据聚类簇6的覆盖,以此对号型进行初步调整,因此最终制定号型表包含6种体型,得到号型覆盖图,如图5—图7所示。矩形框代表尺码覆盖范围,长为身高档差、宽为胸围档差,尺码值为矩形框对角线交点;黑色填充正方形代表样本实际尺寸。
聚类数3、4、7号型系列所对应尺码数分别是33、40、33;体型数分别是3、4、6。聚类数7号型因舍弃只含有一个样本数据的聚类簇,故只有6种体型。聚类数3号型与聚类数7号型尺码无重叠或有极少重叠,聚类数4号型重叠尺码相对较多。对于样本数据的覆盖,三个号型系列尺码分布均与样本数据分布大致相同,但聚类数3号型与聚类数7号型尺码数量少于聚类数4号型,因此聚类数4号型的尺码覆盖效率明显低于其他两个号型。对于未覆盖的样本数,聚类数7号型最少,聚类数4号型少于聚类数3号型。对于号型合体性,图中难以清晰呈现,需要进一步计算分析。
综上所述,聚类数7号型对于样本尺寸的覆盖率优于聚类数3与聚类数4号型,且尺码数量明显少于聚类数4号型。
4.2 分析与讨论
初步所得三个号型系列,因部分尺码只覆盖单独一个样本,故进一步调整优化,将此部分尺码调整为样本实际尺寸最接近的整数,得到最终号型系列后进行对比评价。号型表评价指标如表9所示,在考虑尺码数量的基础上,比较号型覆盖率及拟合度损失。尺码数量作为生产效益的评价指标,号型覆盖率、拟合度损失分别作为此号型服装满足消费者穿着的比例及穿着合体性的评价指标。聚类数7号型表与聚类数3号型表相比,号型数量相同,号型覆盖率提高5.75%,且拟合度损失下降了0.023 5;聚类数7号型表与聚类数4号型表相比,号型数更少,覆盖率提高3.45%,拟合度损失下降了0.019 9。因此,考虑拟合度损失系数所建立的聚类数7号型表最优,以最低的尺码数达到最高的号型覆盖率,可以为消费者提供更好的穿着体验。
表10为最终聚类数7号型系列,图8为调整后聚类数7最终号型分布覆盖图。结果表明,体型Ⅰ覆盖样本数9,覆盖率为10.84%;体型Ⅱ覆盖样本数16,覆盖率为19.28%;体型Ⅲ覆盖样本数23,覆盖率为27.71%;体型Ⅳ覆盖样本数6,覆盖率为7.23%;体型Ⅴ覆盖样本数22,覆盖率为26.51%;体型Ⅵ覆盖样本数7,覆盖率为8.43%。由此可得,此样本群体中,主要体型为体型Ⅱ、体型Ⅲ、体型Ⅴ。对主要体型中,尺码覆盖样本数覆盖率进行分析。体型Ⅱ中,尺码身高155 cm、胸围81 cm覆盖样本最多,覆盖样本数5,在体型Ⅱ中的覆盖率为31.25%;体型Ⅲ中,尺码身高159 cm、胸围79 cm,身高159 cm、胸围81 cm,身高159 cm、胸围83 cm覆盖样本最多,且均为4人,三个尺码在体型Ⅲ中覆盖率为52.17%;体型Ⅴ中,尺码身高165 cm、胸围84 cm,身高165 cm、胸围90 cm,身高170 cm、胸围92 cm覆盖样本最多,且均为4人,三个尺码在体型Ⅴ中覆盖率为54.55%。上述分析有利于服装企业合理安排生产及制定定价策略,即根据各尺码所需生产件数安排裁剪,提高生产效率,从而降低生产成本,进而根据各尺码生产成本及对应的合体度制定销售价格。
5 结 论
本文提出基于拟合度损失系数的聚类分析方法,为18~25周岁青年女性顾客开发了服装定制号型。本文采用主成分分析、相关性分析确定聚类的依据变量,并基于拟合度损失系数模型,确定优先考虑服装合体性情况下的最优聚类数量,再通过线性回归确定变量关系以设置档差。通过设置对比实验,综合三个评价指标,基于拟合度损失系数方法所制定号型表在号型覆盖率、服装合体性、生产成本方面要优于混合F统计量及最终聚类中心距离和,因此相较而言也更适用于开发服装定制号型。所制定的服装号型在覆盖率高达95.40%、拟合度损失仅0.039 9的基础上,保持合理的尺码数量,同时满足消费者合体性及企业实际生产的需要。
本文尚存在不足之处:采取线性回归的方法设置服装号型档差,虽然保证了特征变量尺寸变化的协同,但并不能十分贴合同一聚类中某一变量尺寸的变化关系,未来可细化档差设置。
参考文献:
[1]齐雪良. 批量定制服装号型分类算法研究[D]. 芜湖: 安徽工程大学, 2017.
QI Xueliang. Research on Classification Algorithm of Batch Customization Garment Size[D]. Wuhu: Anhui Engineering University, 2017.
[2]赵琳琳. 千亿市场蓝海服装定制业正在崛起[N]. 中国产经新闻, 2022-01-15(002).
ZHAO Linlin. The blue ocean clothing customization industry is rising in the 100 billion market[N]. China Industrial and Economic News, 2022-01-15(002).
[3]TRYFOS P. An integer programming approach to the apparel sizing problem[J]. Journal of the Operational Research Society, 1986, 37 (10): 1001-1006.
[4]MCCULLOCH C E, PAAL B, ASHDOWN S A. An optimal approach to apparel sizing[J]. Journal of the Operational Research Society, 1998, 49: 492-499.
[5]MOON J Y, NAM Y J. A Study the Elderly Women’s Lower Body Type Classification and Lower Garment Sizing Systems[C]. Seoul: Proceedings of International Ergonomics Association Conference, 2003.
[6]SHE F H, KONG L X, NAHAVANDI S, et al. Intelligent animal fiber classification with artificial neural networks[J]. Textile Research Journal, 2002, 72 (7): 594-600.
[7]HSU C H, WANG M J J. Using decision tree based data mining toestablish a sizing system for the manufacture of garments[J]. The International Journal of Advanced Manufacturing Technology, 2005, 26 (5/6): 669-674.
[8]齐静, 李毅, 张欣. 我国西部地区青年男性体型描述与体型分类研究[J]. 纺织学报, 2010, 31(5): 107-111.
QI Jing, LI Yi, ZHANG Xin. Description and classification of young men’s body type in the west China[J]. Journal of Textile Research, 2010, 31(5): 107-111.
[9]余佳佳, 李健. 中国东部地区青年女性人体体型分类[J]. 纺织学报, 2020, 41(5): 134-139.
YU Jiajia, LI Jian. Classification of young women’s somatotypes in eastern China[J]. Journal of Textile Research, 2020, 41(5): 134-139.
[10]张小妞, 王軍, 张春媛. 东北女青年下身体型分类及数学模型建立[J]. 服装学报, 2020, 5(6): 482-487.
ZHANG Xiaoniu, WANG Jun, ZHANG Chunyuan. Classification of lower somatotype and mathematical models of young women in northeast China[J]. Journal of Clothing Research, 2020, 5(6): 482-487.
[11]ALEXANDER M, JO C L, PRESLEY A B. Clothing fit preferences of young female adult consumers[J]. International Journal of Clothing Science and Technology, 2005, 17(1): 52-64.
[12]BOORADY L M. Functional clothing-principles of fit[J]. Indian Journal of Fibre & Textile Research, 2011, 36(4): 344-347.
[13]许轶超, 丁永生. 服装合体性评价的研究方法与应用进展[J]. 纺织学报, 2007, 28(10): 127-130.
XU Yichao, DING Yongsheng. Research and application of garment fit assessments[J]. Journal of Textile Research, 2007, 28(10): 127-130.
[14]ESFANDARANI M S, SHAHRABI J. Developing a new suit sizing system using data optimization techniques[J]. International Journal of Clothing Science and Technology, 2012, 24(1): 27-35.
[15]VADOOD M, ESFANDARANI M S, JOHARI M S. Developing a new suit sizing system using neural network[J]. Journal of Engineered Fibers and Fabrics, 2015, 10(2): 108-112.
[16]GUPTA D, GANGADHAR B R. A statistical model for developing body size charts for garments[J]. International Journal of Clothing Science and Technology, 2004, 16(5): 458-469.
[17]陈莎, 修毅, 张海波. 服装大规模定制生产企业订单排程优化研究[J]. 北京服装学院学报(自然科学版), 2022, 42(1): 65-73.
CHEN Sha, XIU Yi, ZHANG Haibo. Research on optimization of order scheduling for apparel mass customization manufacturing enterprises[J]. Journal of Beijing Institute of Fashion Technology (Natural Science Edition), 2022, 42(1): 65-73.
[18]杨蕾, 马凯. 北京地区中年女性体型细分研究[J]. 北京服装学院学报(自然科学版), 2021, 41(2): 35-40.
YANG Lei, MA Kai. Body shape classification of middle-aged women in Beijing[J]. Journal of Beijing Institute of Fashion Technology (Natural Science Edition), 2021, 41(2): 35-40.
[19]潘力, 王军, 沙莎, 等. 东北地区青年女子体型分类与服装档差研究[J]. 纺织学报, 2013, 34(11): 131-135.
PAN Li, WANG Jun, SHA Sha, et al. Study on body typing and garment size grading of young women in northeast China[J]. Journal of Textile Research, 2013, 34(11): 131-135.
[20]樊萌丽, 罗戎蕾, 刘芳. 华东地区青年女性体型特征与分类研究[J]. 现代纺织技术, 2019, 27(6): 68-73.
FAN Mengli, LUO Ronglei, LIU Fang. Study on body characteristics and classification of young women in eastern China[J]. Advanced Textile Technology, 2019, 27(6): 68-73.
[21]袁惠芬, 王旭, 齐雪良, 等. 基于神经网络的批量定制服装号型分类研究[J]. 武汉纺织大学学报, 2018, 31 (3): 41-45.
YUAN Huifen, WANG Xu, QI Xueliang, et al. Investigation on mass customization clothing shape classification by artificial neural network[J]. Journal of Wuhan Textile University, 2018, 31(3): 41-45.
[22]汪海仙, 尚笑梅. 人體体型分类方法研究综述[J]. 现代丝绸科学与技术, 2019, 34(3): 37-40.
WANG Haixian, SHANG Xiaomei. A review of research on human body classification methods[J]. Modern Silk Science & Technology, 2019, 34(3): 37-40.
[23]方方, 王子英. K-means聚类分析在人体体型分类中的应用[J]. 东华大学学报(自然科学版), 2014, 40(5): 593-598.
FANG Fang, WANG Ziying. Application of K-means clustering analysis in the body shape classification[J]. Journal of Donghua University (Natural Science), 2014, 40(5): 593-598.
[24]孙才志, 王敬东, 潘俊. 模糊聚类分析最佳聚类数的确定方法研究[J]. 模糊系统与数学, 2001(1): 89-92.
SUN Caizhi, WANG Jingdong, PAN Jun. Research on the method of determining the optimal class number of fuzzy cluster[J]. Fuzzy Systems and Mathematics, 2001(1): 89-92.
Customized sizes for young women’s group clothing with a single customized order
ZHANG Chi, WANG Xiangrong
XU Xipenga, XU Yannib, JI Xiaofenb
(a.School of Fashion Design & Engineering; b.School of International Education, Zhejiang Sci-Tech University, Hangzhou 310018, China)
Abstract: With the improvement of material living standards, consumers have a higher demand for fitting clothing. Due to the characteristics of low cost, high quality, and fast speed, mass customization of clothing has become an important way to meet the needs of consumers for high fitness and good production efficiency of enterprises. As the basis of mass customization of clothing, clothing size is prone to mismatches between size and individual body shape, making it difficult for clothing to meet consumers’ higher fitness needs. Therefore, the technical methods for formulating clothing sizes should be innovated to further meet the needs of mass customization of clothing.
To meet the higher demand of consumers for clothing fit and the need of enterprises to improve the production efficiency of clothing customization, a method for formulating customized sizes for young women’s clothing considering the loss coefficient of fit was proposed. Eight human body data were collected from 100 young women aged between 18 and 25 by using [TC]2 three-dimensional human body scanning. The measurement sites included height, chest circumference, waist circumference, hip circumference, back length, shoulder width, leg length, and thigh circumference. After performing data preprocessing on the collected initial human body data, we deleted the missing and abnormal values, and then performed a normal distribution test. It is verified that the data conform to normal distribution. We also performed principal component analysis on the pre-processed data to determine the number of components, and extracted two components with initial feature values greater than 1. After determining the basis variables for clustering through correlation analysis, the optimal number of clusters was determined by using the loss coefficient of fit method. Then, the sample data were classified through K-means clustering analysis, and the linear regression analysis was used to set the grade to obtain a customized size table. To prove the superiority of the loss coefficient of the fit method, two other methods including the mixed F statistics and the sum of final cluster center distance for determining the number of clusters were selected, and a comparative experiment was conducted. According to this research idea, we established a loss coefficient of fit model and selected the optimal cluster number from the perspective of clothing and individual fitting to determine the optimal size table for clothing mass customization. The research results show that the coverage rate of the clothing size table based on the loss coefficient of the fit method is as high as 95.40%, and the fitting loss is only 0.039 9. It is superior to the mixed F statistics and the sum of the final clustering center distance in terms of size coverage, clothing fitness, and production efficiency.
The method of the loss coefficient of fit provides a new way of thinking for the formulation of clothing size, and improves the size coverage rate based on giving priority to meeting the fitness needs of consumers. The research results can provide customized size development methods for single orders of niche brands and small and medium-sized enterprises. It is unnecessary to build a three-dimensional human body database for consumers, but necessary to quickly develop a clothing mass customization size table by collecting data on the eight important measurement positions of consumers within the order.
Key words: clothing mass customization; clothing size; cluster analysis; loss coefficient of fit; clothing fit
收稿日期: 20221102;
修回日期: 20230702
基金項目: 浙江省教育厅一般项目(21190071-F);浙江理工大学科研基金启动项目(21192116-Y);安徽省纺织工程技术研究中心、安徽省高等学校纺织面料重点实验室联合开放基金项目(2021AETKL03)
作者简介: 徐希朋(1998),男,硕士研究生,研究方向为服装智能制造、服装供应链管理。通信作者:季晓芬,教授,博导,xiaofenji@zstu.edu.cn。
猜你喜欢
软件导刊(2016年11期)2016-12-22
科技创新导报(2016年21期)2016-12-17
对外经贸(2016年8期)2016-12-13
数学学习与研究(2016年19期)2016-11-22
商场现代化(2016年26期)2016-11-21
大经贸(2016年9期)2016-11-16
中国市场(2016年33期)2016-10-18
科技视界(2016年20期)2016-09-29
企业导报(2016年9期)2016-05-26
