
多波束声呐海底底质半监督学习分类方法
2023-09-14 01:02倪海燕王文博任群言鹿力成马力
声学技术 2023年4期
倪海燕,王文博,任群言,鹿力成,马力
(1.中国科学院声学研究所,北京 100190;2.中国科学院水声环境特性重点实验室,北京 100190;3.中国科学院大学,北京 100049)
0 引 言
海底底质分类及特性表征是海洋测绘、海洋地质和海洋工程领域的重要研究内容,为各种海洋应用提供必要的海洋环境信息[1-2]。单波束、多波束测深声呐等走航式声呐设备,可以快速提供大范围的海底地形、地貌及含沉积层信息的海底回波数据,具有快速、高效、节省成本的优势。
多波束测深声呐的反向散射强度是海底底质分类中常用的物理量。目前利用多波束反向散射数据进行海底底质分类的分类方法较多,但最佳分类器选择问题仍未有定论[2-3]。根据数据分析过程中是否应用海底底质标签信息,可将各方法划分为监督学习[1,3-8]及无监督学习方法[9-11]。监督式机器学习的思路是通过大量数据训练和底质类型标签建立其预测性分类模型,包括决策树[12]、随机森林[8,13-14]、随机决策树[6]、支持向量机[1,4,15]以及神经网络[16]等。
由于监督学习方法需要对数据及标签信息进行学习训练,因此监督式分类算法的性能受限于可用的代表性训练样本的数量及质量[17]。实际中,海底的真实底质信息通过采样获得,通常为点状采样,难以获得大面积的底质类型信息,存在底质标签信息采集不足的问题,且耗费大量人力财力。该问题限制了监督分类方法的效率与应用。无监督分类方法无法直接给出不同沉积层的确切类型预测,需结合具体的海底底质采样信息,才可将聚类结果与沉积物类型结合起来。
针对上述问题,有学者开始研究单纯利用辅助任务从大量无标签数据中挖掘监督信息、学习到对下游任务有价值表征的自监督学习[18-21],以及利用无标签数据与有标签数据的半监督学习方法[22-27]。将两大类传统的机器学习算法结合起来,即使在有标签样本较少情况下,也可获得较好的分类性能和预测结果。目前半监督分类方法在图像、心电步态数据分类及声学领域均取得了一些成效。颜延[28]利用可以进行无监督预训练的深度自编码器及深度信息网络,以人体心电信号及步态信息的传感数据为研究对象,从有效特征提取及小样本学习等角度进行了无监督学习等方面的研究。在声学领域,Xe‐naki等[29]利用变分自动编码器对合成孔径声呐平台运动未有标签数据中进行无监督表示学习,在包含少量有标签数据情况下进一步提高了平台运动估计的准确性。Bianco等[30-31]提出了混响环境下基于带有变分自动编码器的深度生成建模的半监督定位方法,在标签受限的情况下该方法性能优于传统方法和卷积神经网络方法。
本文利用多波束声呐的反向散射数据,研究了海底底质分类的半监督学习(Semi-supervised learn‐ing,SSL)算法。利用黄海海域两次实验获得的多波束反向散射角度响应曲线,采用基于自动编码器(Auto Encoder,AE)预训练以及伪标签(Pseudo Label‐ling,PL)自训练的半监督学习分类算法(分别称为SSL-AE 及SSL-PL),进行少量有标签样本下的海底底质分类研究。分类准确度与仅利用有标签样本的支持向量机(Support Vector Machine,SVM)、随机森林(Random Forest,RF)、反向传播神经网络(Back Propagation Neural Network,BPNN)等方法进行对比。数据处理结果表明,本主文所提方法在可利用底质标签信息尽可能少的情况下实现较准确的底质分类。
1 自动编码器预训练的半监督学习分类方法
实现半监督学习算法的其中一种思想是数据的无监督预训练。半监督学习算法基于迁移学习的思想,首先利用自动编码器和受限玻尔兹曼机(Restricted Boltzmann Machines,RBM)等无监督式的神经网络结构进行数据的无监督预训练[32-33]。然后在实际任务中重用网络的底层结构,通过有标签的小量数据进行网络微调。最后利用少量有标签的数据样本和大量无标签的数据样本,以期望达到较好的分类效果。
1.1 自动编码器
AE 网络能够在无标签情况下对输入数据表征学习[33-34],其结构框架如图1 所示。全连接(Full Connection,FC)的结构与多层感知机(Multilayer Perceptron,MLP)结构类似,不同的是,AE的输入层神经元个数与输出层个数相同,这与其原理与功能有关。自动编码器的编码器从输入数据中强制学习重要的数据功能,实现数据的内部表示;解码器则负责利用学习到的表征与规则重建输入,利用成本函数计算重建损失并对模型实施惩罚[33,35]。自动编码器在试图复现原始输入的非线性学习过程中,逐渐捕捉到类似于主成分分析(Prin‐ciple Component Analysis,PCA)方法中最能有效代表原信息的主成分,最终实现无监督数据的有效表达与学习。
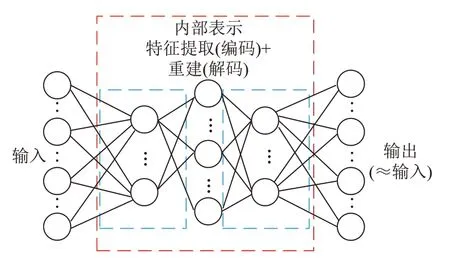
图1 自动编码器结构图Fig.1 Structure of Auto-Encoder
将上述自动编码器神经网络结构以逐层的方式堆叠,即为栈式自编码结构(Stacked Auto Encoder,SAE)。在多层的栈式自编码网络中,数据由输入层输入,在网络结构中每一层的输入即为前一层的激活函数的输出。每次仅训练其中一层的参数,其余已经训练层的参数固定不变。
1.2 自动编码器预训练的半监督学习分类方法
基于自动编码器的半监督分类算法首先通过大量无监督的数据训练神经网络,让神经网络学习并提取特征,这一过程称为无监督的预训练;再结合少量标签通过监督训练的方式微调网络参数与模型;最后将训练好的网络模型应用到相似实际任务中新的数据集上。其算法步骤如图2所示,具体步骤如下:
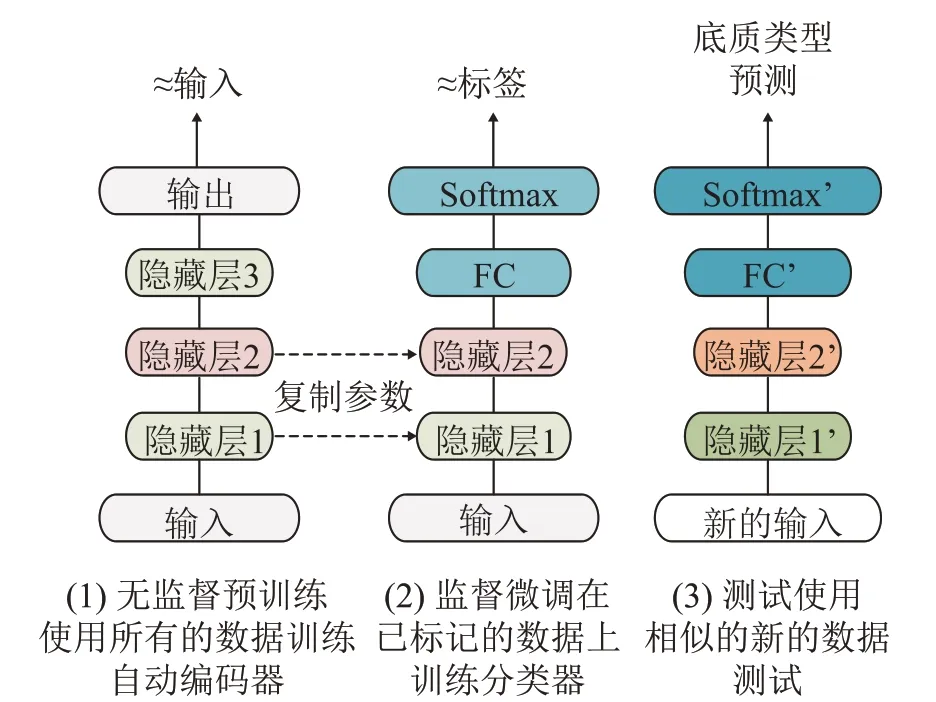
图2 自动编码器预训练的半监督分类方法的算法步骤Fig.2 Procedure of the semi-supervised classification based on auto encoder pre-training
(1) 给定数据集1 的全部无标签数据,利用自动编码器逐层训练,非监督地学习特征,得到预训练模型。
(2) 选择数据集1的部分少量有标签数据样本,通过标准多层神经网络监督训练方法(梯度下降)微调整个网络系统参数,为实际任务创建一个新的神经网络。此时为了实现分类功能,需要在预训练好的最顶层的编码器上方加一个分类器(这里选择softmax分类层)。
(3) 将训练好的网络模型应用到实际任务中新的数据集上进行测试。
2 伪标签自训练的半监督学习分类方法
实现半监督学习算法的另外一种思想是数据的伪标签自训练。半监督学习的核心思想是通过借助无标签的数据来提升有监督过程中的模型性能。对于无标签数据的利用,除了第1节所提无监督预训练的方式,还可以尝试利用已标注数据所训练的模型在未标注的数据上进行预测,预测的结果通常被称为伪标签。利用伪标签进行自训练的半监督学习分类方法的步骤如图3 所示。算法的具体步骤如下:
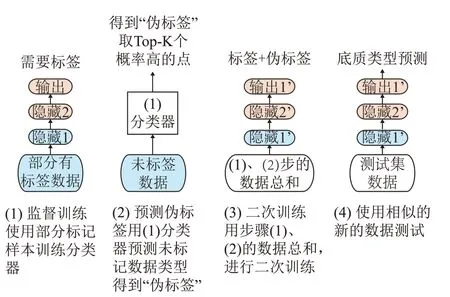
图3 伪标签自训练的半监督分类方法(SSL-PL)的算法步骤Fig.3 Procedure of the semi-supervised classification based on pseudo label self-training (SSL-PL)
(1) 使用有标签数据训练有监督模型M;
(2) 使用有监督模型M对无标签数据进行预测,得出预测概率P;
(3) 通过预测概率P筛选高置信度样本,确定伪标签;
(4) 使用有标签数据以及伪标签数据训练新模型M’;
(5) 利用新模型M’对测试集数据进行预测。
3 多波束声呐数据采集实验
3.1 实验介绍
2018年8月及2019年8月,分别在黄海海域进行了沉积层底质特性综合测量的海上实验。两次实验均使用同款多波束测深仪走航声呐设备。多波束测深仪被固定安装在船体左侧。两次走航测量实验的海域位置及航线轨迹如图4(a)~4(b)所示。在图4(a)中,2019年的实验航线为“三角”形状,从E1开始,先后经过E2、E3,最后回到E1,行航线全长约300 km。2018 年的实验航线由A点出发,行驶至B点,与2019年实验中E1E2段航线接近平行,总长约为120 km。
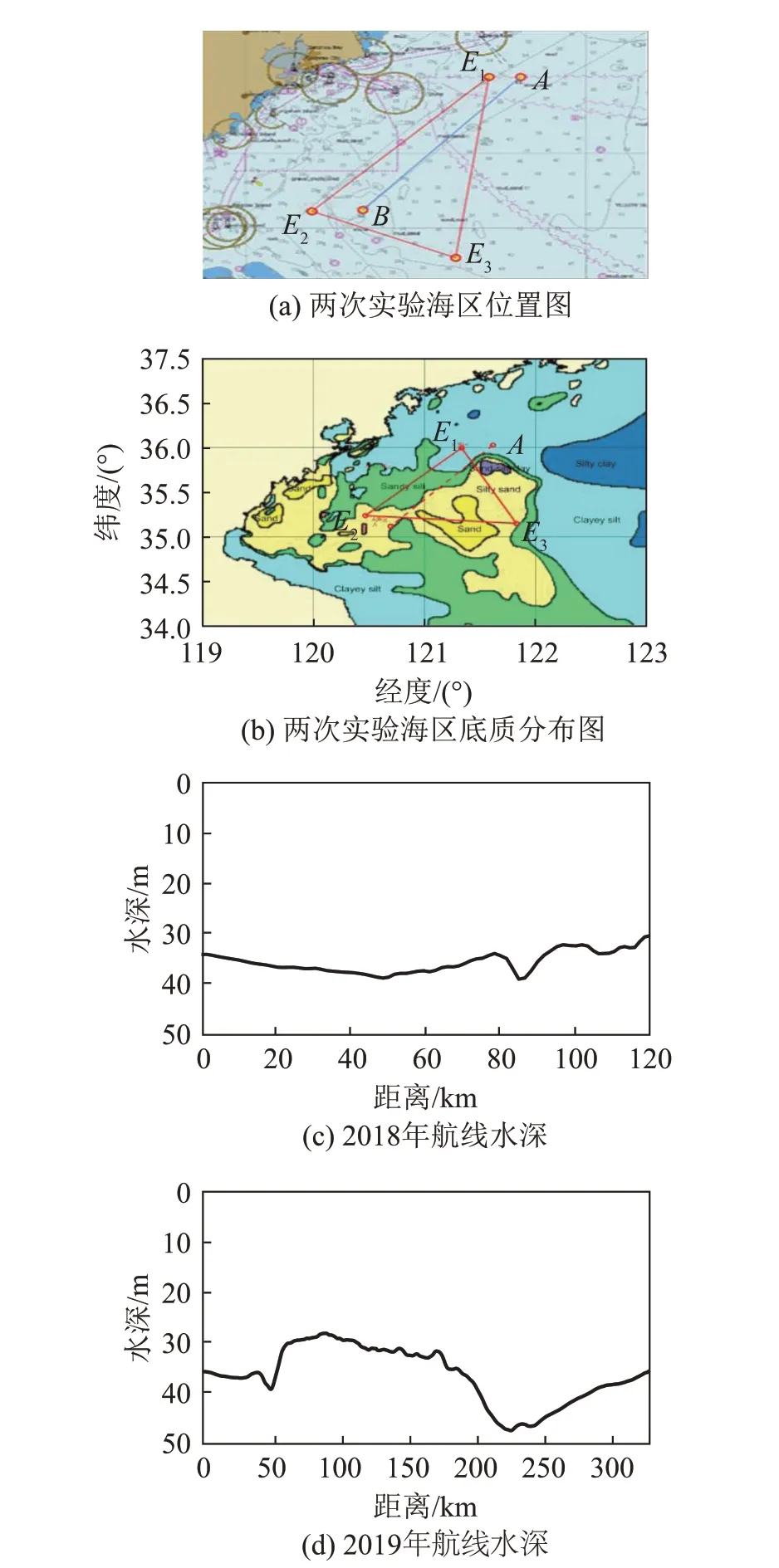
图4 两次多波束声呐数据采集实验概况Fig.4 Overviews of twice multi-beam sonar data acquisition experiments
由于海况等原因,两次实验没有实时采得海底底质样本。但根据图4(b)所示的沉积物历史采样分布结果,可以观察到,2018年AB航线主要经过了黏土质粉砂(clayey silt)、砂质粉砂(sandy silt)及粉砂质砂(silty sand)三类海底底质类型,2019年航线主要经过了黏土质粉砂、砂质粉砂、粉砂质砂以及砂(sand)四种底质类型。
该实验海域水深约30~50 m。图4(c)~4(d)分别给出了两次实验航线上的海水深度。2018年实验航线上,海深略有起伏,前80 km存在坡度较缓的海底斜坡,后40 km内海深有约4~5 m的起伏。2019年实验航线上,海底地形不平坦,存在较大的海深起伏,50 km 处海水深度起伏约4~5 m,180 km 后存在坡度较大的海底斜坡。
多波束测深声呐设备为NORBIT 公司生产的WBMS Bathy 200系统,使用QINSY采集软件采集水深及反向散射数据。两次实验中,多波束声呐发射中心频率为200 kHz的调频信号,声呐系统其他参数,如频率带宽、脉冲宽度、系统开角、波束角个数,以及可设置的系统增益G0、时变增益(Time Varied Gain,TVG)补偿有关的参数等如表1 所示。系统会自动采集每一帧(Ping)里各个波束角下的海底反向散射回波数据。
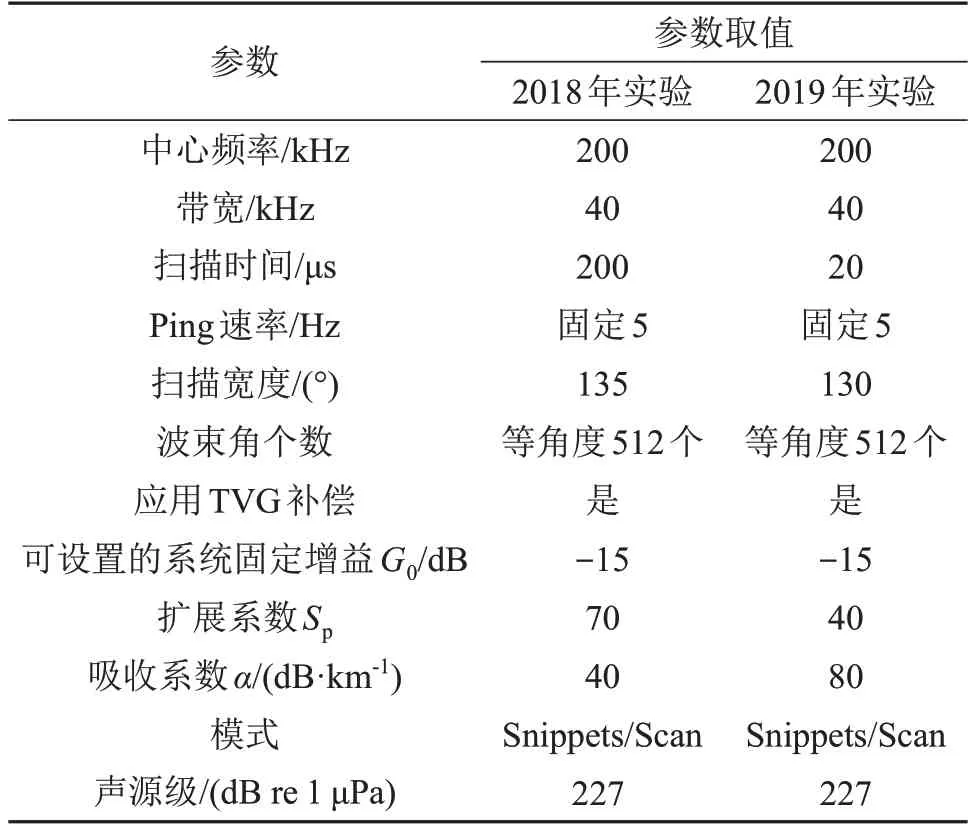
表1 NORBIT WBMS BATHY 200 声呐设备的设置参数Table 1 Parameter setting of NORBIT WBMS BATHY 200 used in two experiments
3.2 数据预处理
FMGeocoder Toolbox (FMGT)[36]是一款专门读取、处理分析及可视化多波束声呐反向散射数据的软件。针对声波传输过程中海洋环境和声呐系统参数等因素带来的影响,FMGT可以应用适用于特定声呐的所有辐射校正算法,对多波束声呐采集的反向散射数据进行处理[36]。处理后的多波束声呐反向散射数据可对应创建海底反向散射图像,也可以形成随入射角度变化的角度响应曲线(Angle Response Curves,ARC),以分析不同沉积物类型。
对于系统校准良好的声呐系统,FMGT还可利用绝对数值的ARC 曲线进行角度与距离分析,通过建模并拟合的方式反演获取沉积层特性参数。对于Norbit WBMS Bathy 200 等未校准声呐,FMGT可以将原始记录的声压数据转换为dB 形式的反向散射强度值,但即使经软件处理,未校准声呐所采集记录的反向散射强度数值范围仍无法达到校准声呐的标准范围[36],因此仍是相对意义上的反向散射强度,而非绝对数值。即便如此,相对意义的回波强度数据也记录了不同海底底质类型间的差异,因此仍然可以采用分析ARC 曲线间的相对差异的经验方法进行海底底质分类研究[37-40]。
经FMGT进行数据处理后,可从软件中直接导出包括每一Ping每个波束角下经度、纬度、海水深度、真正波束入射角、原始记录的反向散射强度值、改正处理后的反向散射强度值,以及Ping时间和声呐工作频率在内的数据文件,进而根据数据文件生成ARC曲线。
2018 年及2019 年实验数据中均存在不同程度的部分波束角数据缺失情况,为方便对比分析及验证,选取统一波束入射角度的反向散射强度数据。首先舍弃波束角缺失严重的部分数据,然后取波束入射角范围为3° 40°,并对每个角度的反向散射数据进行数据平均。为避免瞬时接收反向散射强度的随机起伏对海底底质分类结果的影响,对每50 Ping 数据(重叠30 Ping,距离跨度约20~43 m)进行平均处理。由于2018年AB航线及2019年E1E2航线的实验轨迹基本平行,且底质类型分布基本相同,均贯穿了黏土质粉砂、砂质粉砂及粉砂质砂三类海底底质类型,因此以两条航线数据为本文研究对象,进行海底底质分类研究。数据预处理后,2018年AB航线及2019年E1E2航线上可用多波束反向散射样本数分别为4 567和2 667个。
图5给出了两条航线上三类底质类型下的多波束平均ARC 曲线,误差棒为数据标准差,每7°显示一次。如图所示,不同底质类型下,海底反向散射强度随入射角变化呈现不同的变化规律,体现在强度、斜率及形状上[41],因此可以通过ARC 曲线间相对差异以区分不同海底类型。两次实验中部分声呐系统参数设置不同,导致FMGT处理后的多波束相对反向散射强度值具有不同的区间范围。两次实验航线上,三种海底底质类型的相对变化趋势较为一致,存在略微差异。当被分析的海底区域不均匀或位于不同底质类型的边界区域时,ARC 曲线会较为相似[41],会导致一定的分类结果误判。
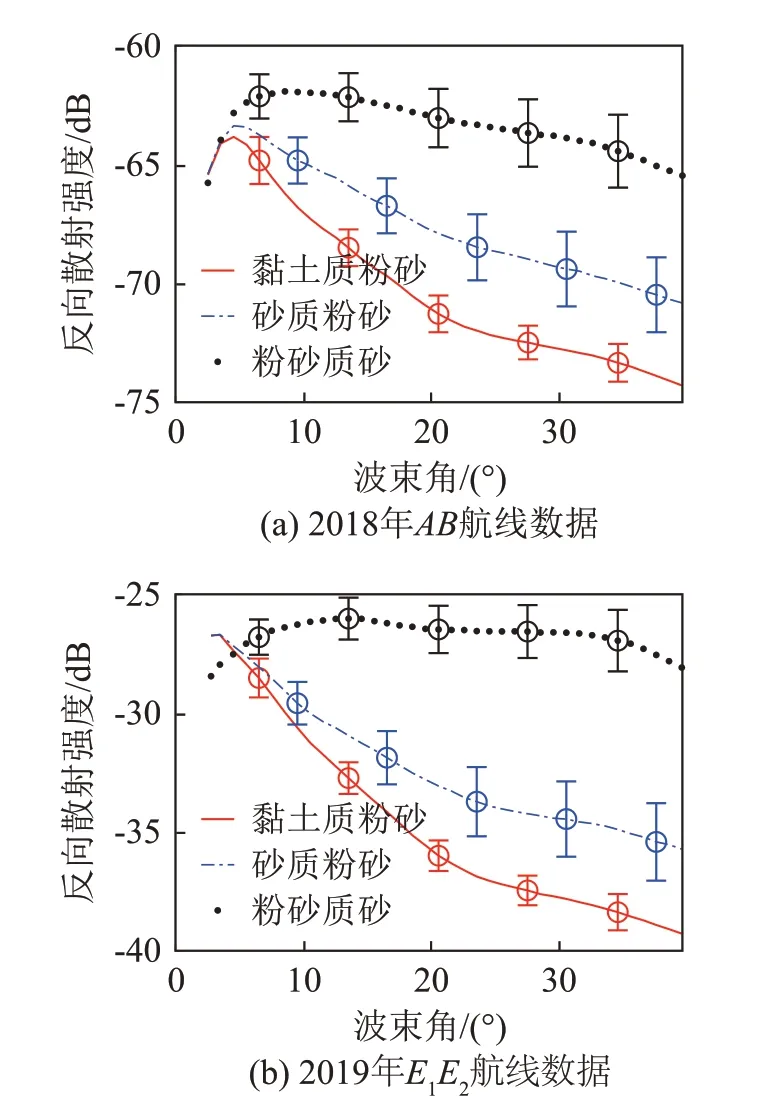
图5 两次实验中多波束反向散射强度随波束角度的变化曲线Fig.5 Variation curves of the multiple beam backscattering intensity with the beam angle in the two experiments
4 结果分析
为验证本文提出的方法在海底底质分类中的有效性,本节利用两次实验获得的多波束反向散射ARC曲线,比较了两种半监督学习分类算法(SSLAE,SSL-PL)与BPNN反向传播神经网络、支持向量机SVM、随机森林RF等监督学习算法的分类性能。对2018年AB航线及2019年E1E2航线数据进行交叉引用,分别将两次航线数据样本用作训练数据集,另一实验航线数据样本作为测试数据集。对ARC 曲线各角度的强度数据进行标准差标准化处理(减去均值再除以数据标准差)[42]。为测试各种分类算法在有标签样本数量较少时的分类效果,样本数在30~300 范围内分别取不同数量的有标签样本用于各分类器训练。其中三类海底底质的数据样本量均等,每类底质中有标签样本的数量为1~100。为避免随机选择的有标签样本对训练结果产生的影响,训练过程重复100次,并取平均值进行分析。
4.1 性能指标
混淆矩阵是估计分类器性能的常用办法[33,43]。二维混淆矩阵的一维索引是各样本的真实类别,另一维索引是各分类器预测的样本类别。通过统计每个真实类别的数据样本被预测为各类别的个数,可计算得到多个性能指标以评价分类结果,主要包括预测精度、召回率以及F1分数等[33,43]。
以BPNN方法中,用2018年AB航线全部数据样本训练,并用2019 年E1E2航线数据样本测试的结果为例,生成混淆矩阵,并解释说明各评价指标。如图6所示,主对角线中的样本数分别表示各类底质正确预测的观测样本数,称为真正类样本(True Positive,TP)。图6中第1行、第4列中的数值为83.8%,表示在全部预测为黏土质粉砂的样本中,实际确为黏土质粉砂的样本比例,其计算方式为1 146/(1 146+222)×100%≈83.8%。此指标,从分类器的预测结果出发,表示预测为正的样本中预测准确的比例,称为精度(Precision),体现分类器的查准率。以此为例,可类推第4列中三类底质的精度指标。与之对应的,图6 中第4 行第1 列的数值为99%,表示在全部实际类别为黏土质粉砂的样本中,分类器预测为黏土质粉砂的样本比例,其计算方式为1 146/(1 146+11)×100%≈99.0%。此指标,从实际数据样本出发,表示正样本中预测准确的概率,称为召回率(Recall),体现分类器的查全率。以此为例,可类推第4行中三类底质的召回率。
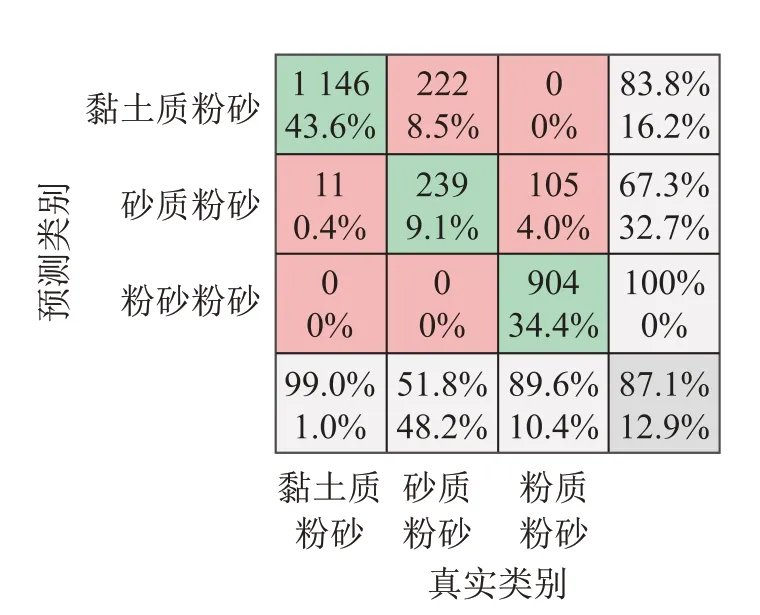
图6 海底底质三分类问题的混淆矩阵Fig.6 Confusion matrix chart for tri-classification problem of seafloor sediment
以Cij表示图6混淆矩阵中第i行、第j列,即真实类别为第j类、预测类别为第i类的数据样本,图7给出了混淆矩阵中各类别数据的TP类样本及对应误判样本的ARC 曲线。图7 中红色、蓝色及黑色ARC曲线分别为黏土质粉砂(C11)、砂质粉砂(C22)及粉砂质砂(C33)三类底质的TP 类样本,玫红色ARC曲线为“1”“2”类底质(即黏土质粉砂和砂质粉砂)间的误判样本(C12),绿色ARC曲线为“2”“3”类底质(即砂质粉砂和粉砂质砂)间的误判样本(C23)。可以看出,误判样本均位于两类底质ARC 曲线的中间区域,分别与两类底质的TP类ARC曲线存在一定的重合或相似。相似的ARC 曲线,会导致一定的分类误判,这与海底区域不均匀或处于不同底质类型的边界区域有关。
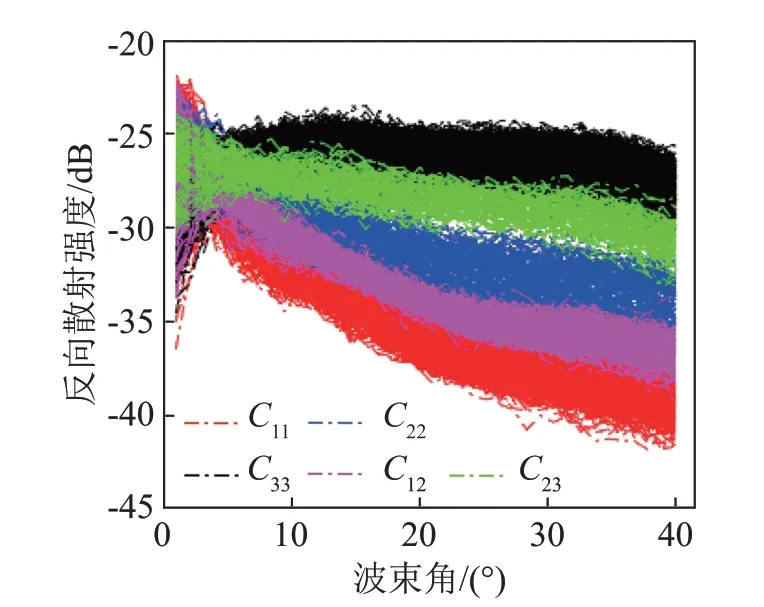
图7 混淆矩阵中各类别数据的TP类样本及对应误判样本的角度响应曲线Fig.7 ARC of the TP class samples and the corresponding misjudgment samples of each category data in the confusion matrix
由于精度和召回率的数值结果常存在一定差异,将精度和召回率组合计算的谐波平均值F1 分数SF1,可以综合衡量分类器的查准率与查全率。由于谐波平均给精度和召回率较低的值更高的权重,因此只有当精度和召回都很高的时候,分类器才能得到较高的F1分数[33,43]。对类别数据不平衡且所有类别同样重要的多分类问题,宏观F1 分数SF1-macr可按式(1)计算[44],式中N为类别数。本文将采用F1分数对各分类算法进行性能分析。
4.2 半监督学习分类算法性能分析
图8 和图9 分别给出了以2018 年航线数据、2019 年航线数据作为训练数据集时,SSL-PL 及SSL-AE两种半监督学习分类方法随有标签样本数量变化的F1分数。在图8与图9所示两种训练数据集下,随着参与数据训练有标签样本数量增加,利用伪标签的SSL-PL 方法性能均逐渐提升,而利用自动编码器无监督预训练的SSL-AE方法性能均相对稳定一致。
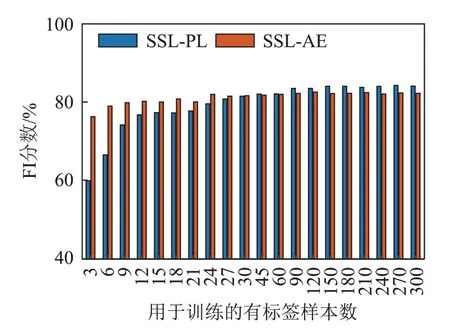
图8 以2018年数据集作为训练数据集时两种半监督学习分类算法的F1分数对比Fig.8 Comparison of the F1 scores for SSL-PL and SSL-AE algorithms when the 2018 experimental data is used as training data set
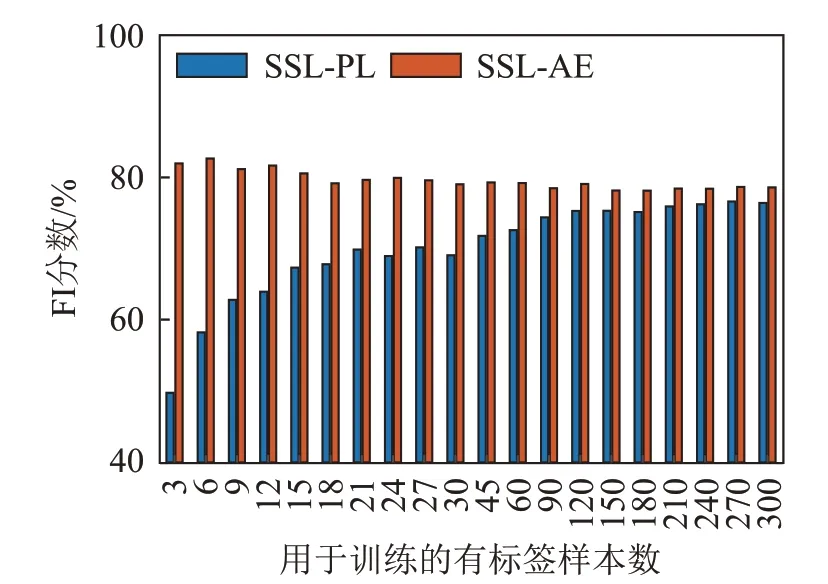
图9 以2019年数据集作为训练数据集时两种半监督学习分类算法的F1分数对比Fig.9 Comparison of the F1 scores for SSL-PL and SSL-AE algorithms when the 2019 experimental data is used as training data set
在SSL-AE方法中,第一步即利用全部可用的无标签数据,利用自动编码器逐层学习数据特征,得到预训练模型,在第二步中有标签样本仅用来将预训练模型中各数据特征与实际分类类别联系起来。因此,在标签正确的情况下,用于数据训练的有标签样本数量对SSL-AE方法性能影响较小。
对于SSL-PL 方法,用于数据训练的有标签样本数量不同,对SSL-PL 方法性能影响较大。这与产生伪标签的准确度有关。当有标签训练数据较少时,由少量有标签数据训练可能导致过拟合,因此预测得到的伪标签未必正确,即使筛选出概率较高的数据样本,其结果仍未必可靠。将此类伪标签数据加入网络二次训练,网络预测性能仍较差。此时SSL-PL方法性能比SSL-AE方法性能差。当有标签训练数据多时,网络训练后预测出来的伪标签可信度更高,将类别估计准确的数据点继续用于训练,将提升网络预测性能。SSL-PL 方法性能是否优于SSL-AE方法,与采用航段的训练数据情况有关。
4.3 不同分类算法性能对比分析
图10 给出了以2018 年航线数据中不同数量的有标签样本用于数据训练时,各分类算法的F1 分数。图11 为以2019 年航线数据作为训练数据的对应结果。整体观察图10 与图11,以不同航次实验数据作为训练数据集时,各算法的分类性能存在部分较一致的现象。首先,当用于训练的有标签样本数量较少(如样本数小于120)时,各分类算法的分类结果差异明显。当有标签样本数量极少时,自动编码器预训练的SSL-AE方法分类效果最好,其次是支持向量机SVM。当总训练有标签样本数小于18个(即每类底质的训练样本数量小于6个)时,随机森林RF方法不能正确地进行分类。其次,当有标签样本数量增加时,各分类算法的分类结果趋于稳定,差异减小。随着有标签样本数量增加,BPNN和RF方法性能逐渐提升。
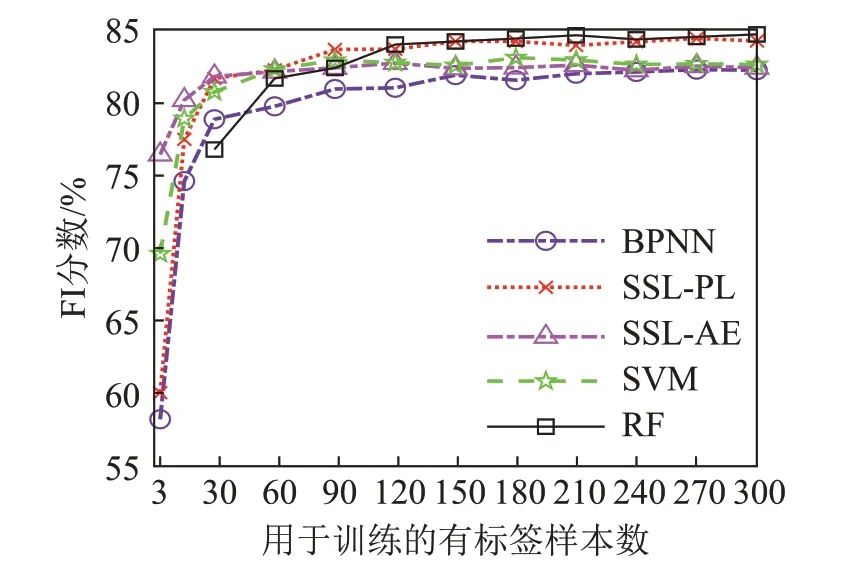
图10 以2018年数据集作为训练数据集时各分类算法的F1分数对比Fig.10 Comparison of the F1 scores for different classification algorithms when the 2018 experimental data is used as training data set
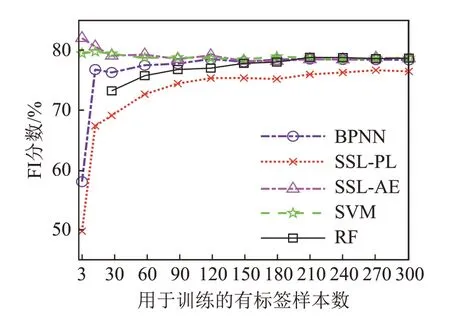
图11 以2019年数据集作为训练数据集时各分类算法的F1分数对比Fig.11 Comparison of the F1 scores for different classification algorithms when the 2019 experimental data is used as training data set
图10和图11中,伪标签自训练的SSL-PL方法和RF方法性能趋势存在差异。以2018年实验航线数据做训练集,且有标签样本数量较多时,SSLPL 方法与RF 方法分类效果略高于其他方法。以2019 年实验航线数据做训练集时,SSL-PL 方法分类性能低于其他方法,RF 方法分类性能逐渐逼近其他方法。以上结果表明,部分分类器预测性能受不同训练数据、测试数据影响,预测性能并不完全稳定。另一方面,两次实验航线数据存在一定差异,如图5的ARC曲线所示。此外,底质标签的准确性,也会影响各分类算法的预测性能。
5 结 论
本文针对监督分类算法依赖海底底质标签而底质标签采集数量可能不足的问题,提出了海底底质半监督学习分类算法。采用自动编码器预训练以及伪标签自训练的两种半监督学习分类方法,将有标签训练样本与无标签训练样本结合使用。利用黄海海域两次实验获得的多波束反向散射角度响应曲线,对提出的SSL-AE 和SSL-PL 方法进行了分类准确度研究。实验结果表明,相比仅利用有标签数据的监督分类算法,提出的半监督学习分类算法可以在利用较少的海底底质标签样本情况下实现更准确的分类。自动编码器预训练的半监督学习分类SSL-AE方法在有标签样本数量极少时的准确率仍高于75%。
除底质标签数量不足的问题外,当底质标签不准确、质量不高时,如何保证或提高分类模型预测准确度,也是未来值得继续研究的问题。
猜你喜欢
水生生物学报(2022年6期)2022-07-08
海洋通报(2022年2期)2022-06-30
海洋通报(2021年1期)2021-07-23
通信技术(2019年3期)2019-05-31
成都信息工程大学学报(2018年3期)2018-08-29
电子测试(2018年6期)2018-05-09
海洋渔业(2017年5期)2017-11-07
声学与电子工程(2017年1期)2017-06-22
电子设计工程(2017年20期)2017-02-10
电子器件(2015年5期)2015-12-29
