
基于深度强化学习的机械臂运动控制研究
2023-09-20 11:54王文龙张帆
农业装备与车辆工程 2023年9期
王文龙,张帆
(200335 上海市 上海工程技术大学 机械与汽车工程学院)
0 引言
随着人工智能和机器人技术的发展,机械臂被广泛应用于工业生产的各个领域,其智能化要求也随之提高。人工智能和机械臂技术相结合,研究具有自主决策能力的控制方法成为一个重要分支,也是国内外研究的重点和前沿。
机械臂经典控制方法如自适应滑模控制、示教控制、前馈补偿控制等,提高了机械臂运动的鲁棒性,具有响应速度快、稳定性好和精确度较高等特点。肖任等[1]提出了一种基于时间固定扰动观测器的滑模控制方法,在消除不确定扰动的基础上,有效地抑制了系统抖振;Wang 等[2]提出了基于连续轨迹点控制的位置控制方法,提高了机械臂的控制精度。这些控制方法虽有一定成效,仍存在编程难度大、泛化性能弱、适应环境能力较差、智能化程度低等问题。
强化学习(RL)是人工智能的一个重要分支,在深度学习的快速发展下,深度学习和强化学习结合,使强化学习在机器人控制领域有了进一步发展,使其具有强大的感知和决策能力,深度强化学习算法也应用在机械臂的控制领域。尤其是在深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法[3]被David Silver 等提出后,可以让深度强化学习算法的经典算法深度Q 学习网络(Deep Q-learning Network,DQN)拓展到连续动作空间,这使得深度强化学习和机器人技术的结合更加紧密。Peng 等[4]将采用后视经验重放的方法改进DDPG 算法应用到机械臂,对冲压自动生产线中的运动物体进行抓取,提高了智能体的样本的利用,将平均成功率从31%提升到82%;赵寅甫等[5]采用DDPG 算法先2D 后3D 模型的方法,通过数据驱动的训练过程,控制机械臂到达目标位置,缩短了接近52%的训练时长;刘勇等[6]将传统的PID控制方法与DDPG 算法相结合,利用PID 控制快速接近目标位置,采用DDPG 算法使机械臂学习追踪目标物体投影,并避开障碍物体投影,最终实现在三维空间实现追踪和避障。
本文使用Gym 官方提供的机械臂深度强化学习训练环境,重置其奖励函数,并在DDPG 算法中比较其对机械臂训练过程的影响,比较不同的深度强化学习算法在机械臂自主学习中的性能。实现虚拟环境中达到较高的奖励值,并使末端执行器快速、准确地到达目标位置,并保持姿态不变。
1 机器人模型与环境
带接触的多关节动力学(Multi-Joint dynamics with Contact,MuJoCo)是一个物理引擎模拟器,主要用于机器人、生物力学、图形与动画、机器学习等领域,能够快速准确模拟铰链结构和环境的交互,它包括广义坐标系中的多关节动力学、整体约束、干关节摩擦、关节和肌腱极限、无摩擦和摩擦接触、可能具有的滑动、扭转和滚动摩擦[7]。本文机械臂模型及其使用的MuJoCo 运行界面如图1 所示。
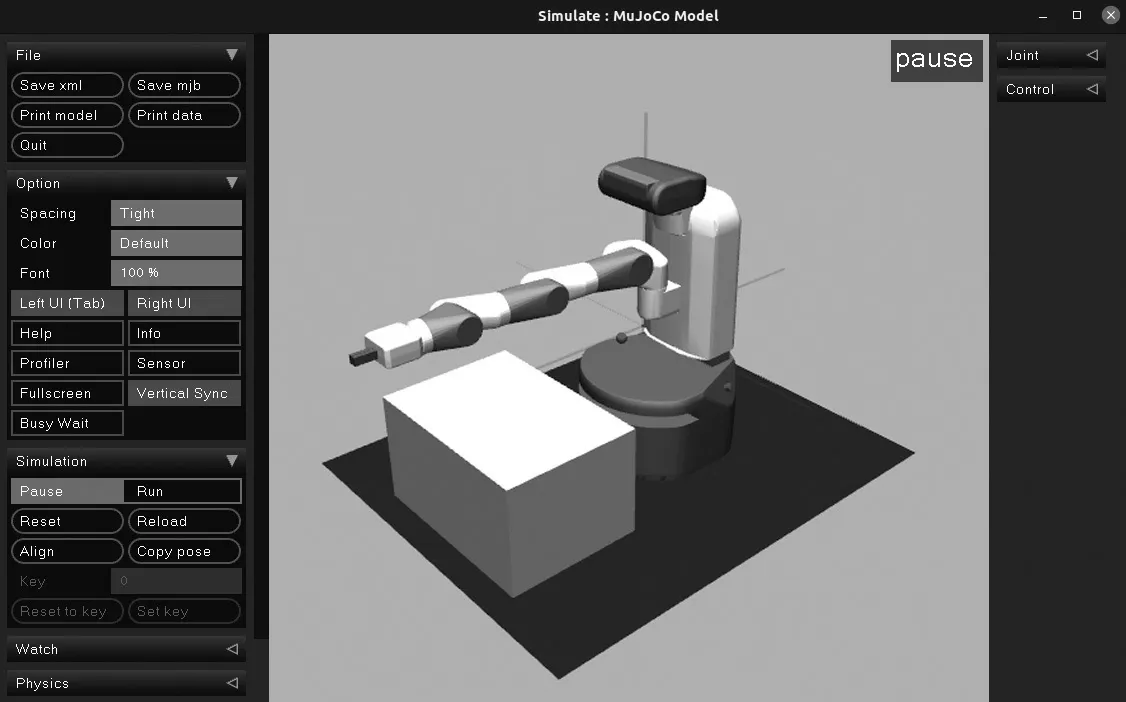
图1 Simulate 中的机械臂Fig.1 Manipulator in simulate
Gym 是由OpenAI 公司提供的一个可调节参数训练和比较RL 算法的环境平台,其中含有很多强化学习环境,包括Atari 游戏、Classic control、MuJoCo、Robotics 等,现在主要支持Python 语言。本文结合Pytorch 框架,进行深度强化学习的训练。采用的是环境ID 为“FetchReach-v1”的机械臂。在此环境中,主要输出为当前状态St、下一时刻的状态St+1以及输入动作策略的奖励值R。状态包含3 个部分:智能体的观察状态、智能体经过动作所到达的位置坐标以及目标位置。状态作为Actor 网络的输入,应为向量形式,在此环境中以字典形式储存,故需要对此进行预处理,转化为一维向量。此机械臂的状态为1×16 的向量。
2 深度强化学习算法
深度强化学习是利用深度学习的感知功能以及强化学习的决策功能的算法,强化学习是在智能体和环境之间交互时,在不被告知采取哪种行动的情况下,智能体通过执行某些动作,基于环境反馈的奖励或者惩罚不断地调整其策略、改善其行为、得到最优策略的算法。它包含智能体、环境、奖励、动作、观察5 个元素,其交互过程如图2 所示。
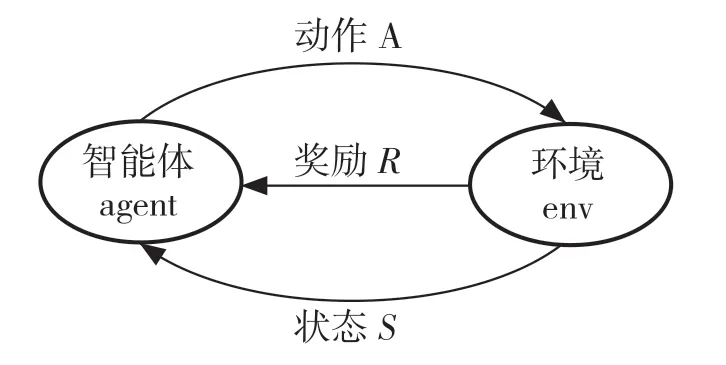
图2 智能体与环境交互Fig.2 Interaction between an agent and the environment
智能体观察环境t时刻的状态S,采取动作A并在环境中执行,得到下一时刻的状态即St+1,并且奖励函数对执行的动作A 进行评价,得到奖励R,反馈给智能体。
2.1 马尔可夫决策过程
马尔可夫决策过程(Markov Decision Process,MDP)是深度强化学习的理论基础,它的4 元素为(S,A(s),R(s,a),P(s,a,s')[8]。其中,S为所有状态的集合,A(s)为状态s下的所有动作的集合,R(s,a)为智能体的奖励值,表示在状态s下执行动作a后所得到的奖励值或者惩罚值。P(s,a,s')为状态转移概率,在状态s执行动作a后转移到状态的概率值。
在MDP 中有一个较重要的参数为折扣因子γ∈(0,1),它控制在训练中一个回合的收益值对下一个动作奖励值的依赖程度,收益为
执行策略为π时,其状态分布则为pπ,学习目标为执行最优策略时使期望累计奖励值达到最大值,累计期望值为
最佳策略可表示为
在寻找最优策略过程中,Bellman 方程给出了最优状态的值
式中:pa,i→j——在状态i产生的动作a以状态j结束的概率。
除了状态值外,在强化学习中还定义了动作值Qs,a,在Q-learning 中
对于状态值和动作值的可尔科夫决策过程,进行Bellman 迭代更新
2.2 深度确定性策略梯度算法(DDPG)
DDPG 算法是基于Actor-Critic(演员-评论家)网络的异策略算法,相比于Actor-Critic 算法,它的策略是确定的,直接根据状态确定所采取的动作,并且不需要像PG 算法那样为计算的每个步骤集成到整个动作空间中。这样可以将链规则应用于Q值,通过最大化Q值改进策略。Actor 和Critic 网络都是3 层神经网络,其控制策略如图3 所示。
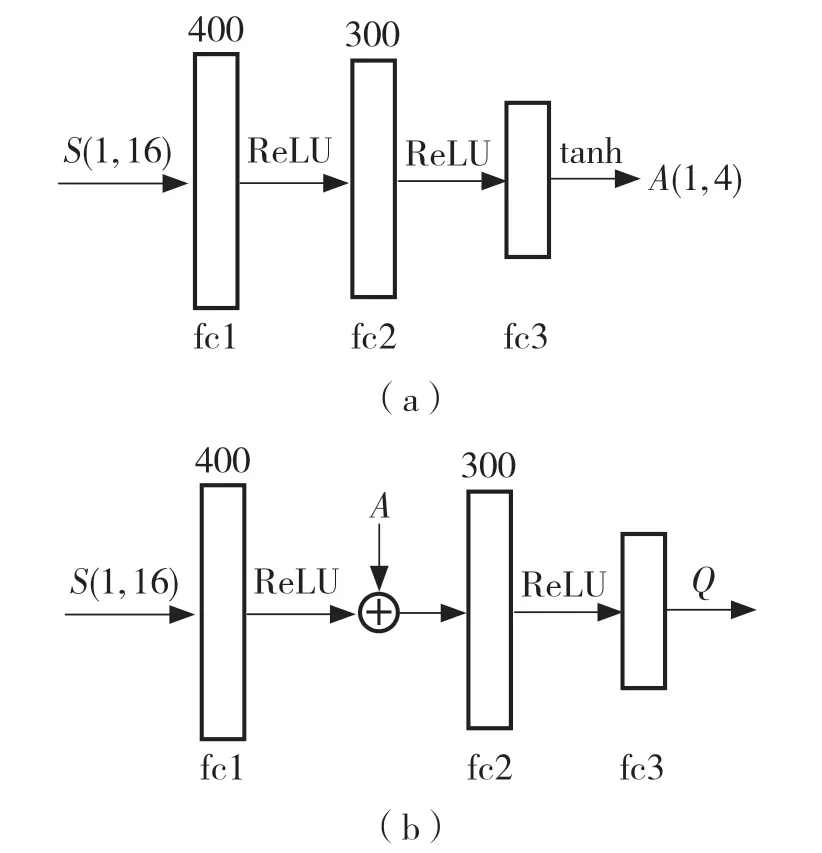
图3 DDPG 算法的网络结构Fig.3 Network structure of DDPG algorithm
其中,Actor 网络是根据每个给定的状态返回N个值,每个动作一个值,这种映射关系是确定的。Critic 的作用是估计Q值,即在某个状态下智能体采取的动作经过环境交互所获得的折扣奖励。因为动作在网络中是以数字向量的形式呈现,所以Critic 网络有2 个输入,即状态和动作,动作是在第2 层网络中输入,它的输出是反映Q值的单个数字。Actor 网络最后一层网络使用tanh 激活函数主要利用其值域为[-1,1]的特性,保证所得到的动作也是在这个区间内。
DDPG 算法使用了当地(local)和目标(target)2 套神经网络,在此算法中由于使用的是确定性策略,为了增加机械臂对环境的探索能力,在Actor网络的返回值中增加噪声再传递给环境来实现,此噪声被称为OU 过程,在离散时间情况下可以写为
式中:θ,μ,σ——超参数。
该式(8)表示OU 过程的下一个值由先前的噪声值加上一个正常噪声产生。最终输入到环境中的动作为
式中:∊——超参数,主要作用是动作a对噪声N的贪婪程度。
DDPG 算法的目标网络参数更新方式采用软更新方式,也可称为指数平均移动,使用超参数学习率,将上一时刻的网络参数和新的本地网络参数做加权平均,然后赋给目标网络
当地的Actor 网络采用采样的策略梯度方法进行优化
式中:si——当前时刻智能体观测到的状态。
当地的Critic 网络使用均方差损失函数定义损失,并进行优化更新。在这个过程中使用目标网络对下一个策略的估计,其预估价值为
式中:ri——当前策略所得到的奖励值;在本实验中γ=0.99;Q'——目标Critic 网络对下一个策略的估值。在此基础上,其网络损失函数表示为
3 分布式策略梯度算法
分布式策略梯度算法(D4PG)是由Gabriel Barth-Maron 等在2018 年提出的方法[9],主要是在DDPG 算法的基础上进行改进,将经验收集的Actor 和策略学习learner 分开,使用多个actor 分布式采样,并储存在同一个经验池中,经过优先级重放采样方式进行采样[10],更新后将权重同步到各个actor 上,实现了更好的离线学习。
D4PG算法的Critic网络使用分布式价值函数,为了引入分布式更新,其随机变量的返回值为
式中,s=s0,a=a0,a=π(s)。则分布更新的Q为
分布贝尔算子就可以定义为
式中:Jπ——分布贝尔算子,关于随机变量的概率定律是相等的,此算子虽然跟规范的Bellman 算子相近,但是它所用的函数类型不同。
分布变量采用从状态到动作对映射到分布的函数,并返回相同形式的函数。为了在此算法中使用这个函数,将其参数化,并定义其损失函数为
式中:d——分布之间的度量,在D4PG 算法中主要使用交叉熵损失来度量。
为了完成这种分布式梯度策略,Actor 网络的优化方式使对行动价值分布的期望来完成。
在D4PG 中改进的部分还包括在估计TD 误差时使用N步返回,减少了更新时的方差。
机械臂在D4PG 算法的训练步骤如下:
(1)超参数输入:包括学习率、经验池大小、批量大小、经验池初始大小、轨迹长度等;
(2)环境激活:定义网络、智能体、经验池,随机初始化网络的权重(θ,ω),初始化目标权重(θ',ω'),定义Actor 和Critic 网络参数优化器;
(3)进行400 000 次循环训练;
(4)为更好地探索环境,初始化随机过程噪声;
(5)初始化环境,获得观察状态s;
(6)对观察状态进行预处理;
(7)经过100 次随机动作热身后,将经过处理的状态输入Actor 网络返回π(s);
(8)对π(s)增加随机噪声得到动作,并返回环境,得到奖励值及下一个状态值s',并将(s,a,r,s')储存在经验池中;
(9)当循环次数大于经验池初始大小值时对经验池进行优先级重放的方式采样;
(10)构建目标分布:
(11)计算Actor 和Critic 网络进行更新参数:
(12)更新网络参数:
(13)采用软更新方式对目标网络更新:
(14)每1 000 次对训练模型进行测试,并保存最好模型。
4 仿真实验与结果
4.1 重置奖励函数
在Gym 环境中设置的奖励值为稀疏奖励,其奖励函数为
式中:δ——机械臂到达目标位置的精度,在此环境中设定为δ=0.05。
在训练初期,使用此奖励函数训练速度慢,效果不显著,主要原因是探索环境中不同的动作策略可能出现相同的奖励值,导致机械臂学习速度较慢。考虑到稀疏奖励训练困难,使用线性奖励函数
设置此奖励函数的原因为:在环境训练中,包含有正负奖励值的奖惩方式对机械臂训练稳定有较好的帮助,先利用DDPG 算法进行训练并与奖励函数r=-d(全负奖励)进行比较,其训练结果经过0.6因子的平滑后如图4,图5 所示。在训练过程中的测试奖励如图6 所示。
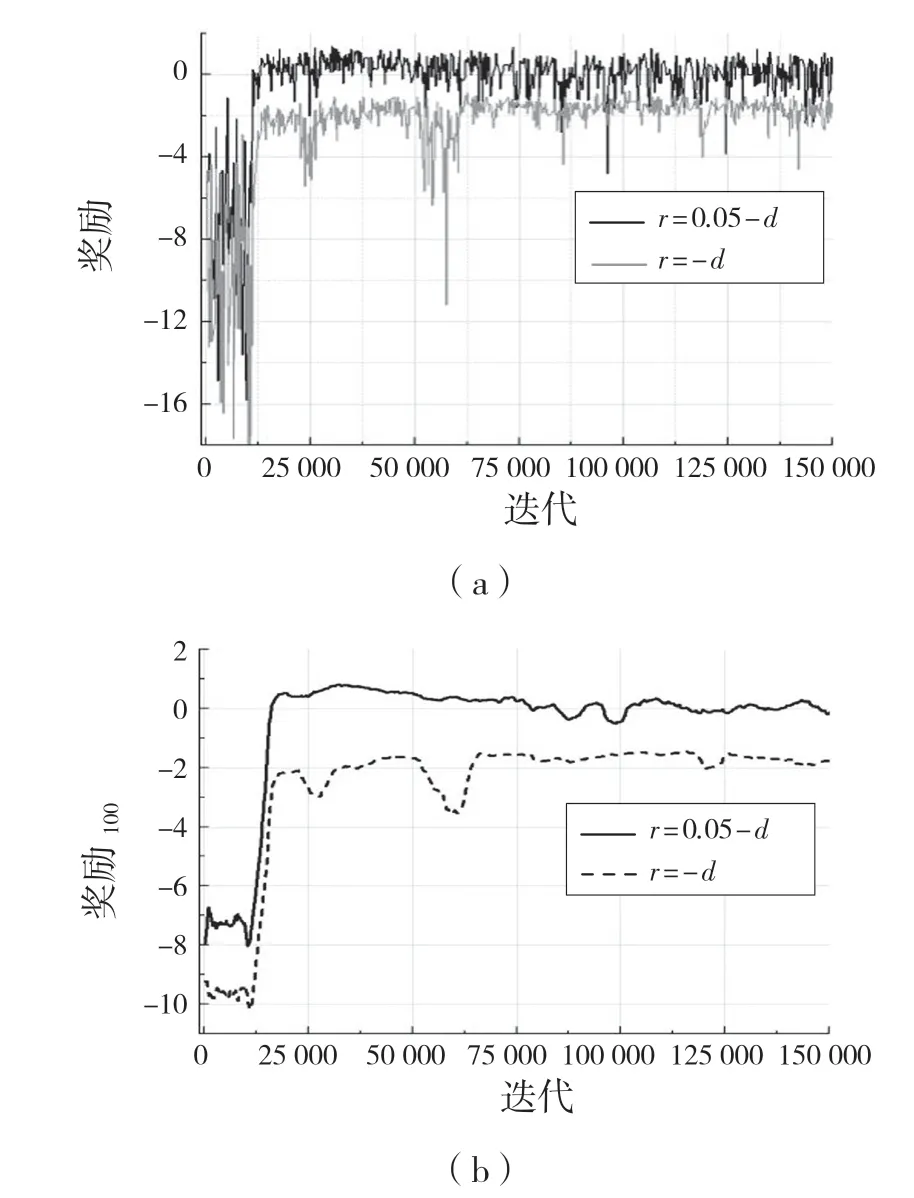
图4 DDPG 算法下训练期间的奖励Fig.4 Rewards during training under DDPG algorithm
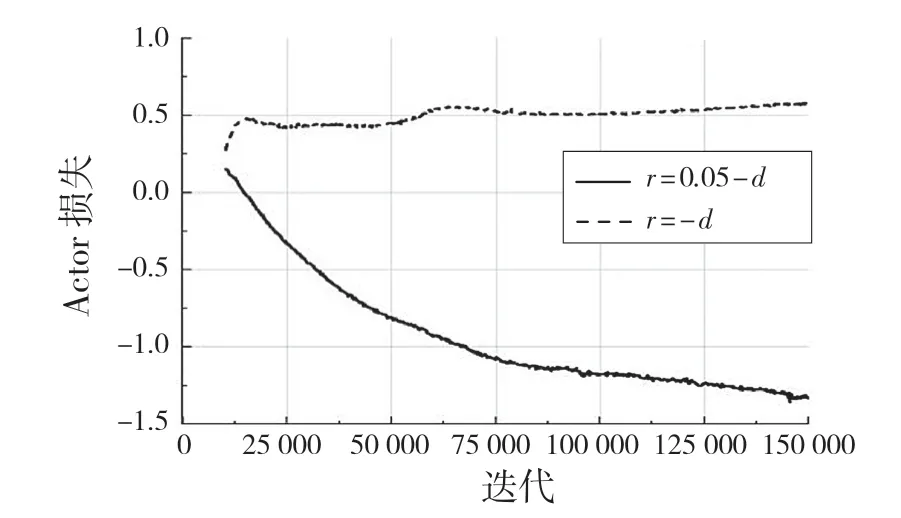
图5 DDPG 算法下Actor 网络损失Fig.5 Actor network loss under DDPG algorithm
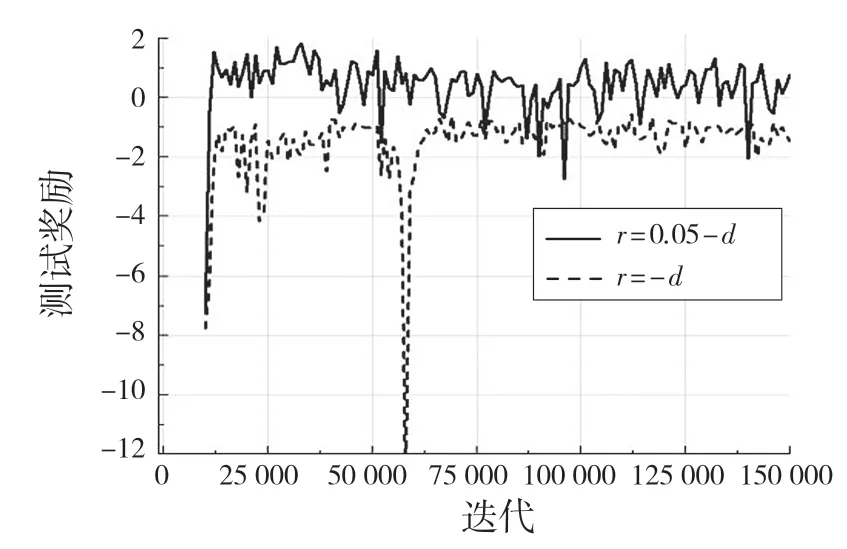
图6 不同奖励函数的测试结果Fig.6 Test results of different reward functions
在对DDPG 算法的2 种奖励机制训练得到的最好模型进行100 次可视化实验,均能在精度范围内到达指定位置,但是奖励函数为r=-d的模型在到达指定位置后出现幅度较大的抖动现象,而r=δ-d的奖励机制所训练的最好的模型在100 次实验中未出现抖动现象。
通过实验可以看出,带有正负样本的奖励机制对机械臂训练稳定性有显著的作用,其每个策略的奖励值在达到较好的奖励值后不会出现大幅度的下降,Actor 网络和Critic 网络的损失函数收敛较为稳定,不会出现激增现象。
4.2 D4PG 训练参数设定
在D4PG 训练过程中有很多关键超参数,对训练结果至关重要,如果参数不合理,可能造成训练不稳定,达不到预期要求。本实验的超参数设定如表1 所示。
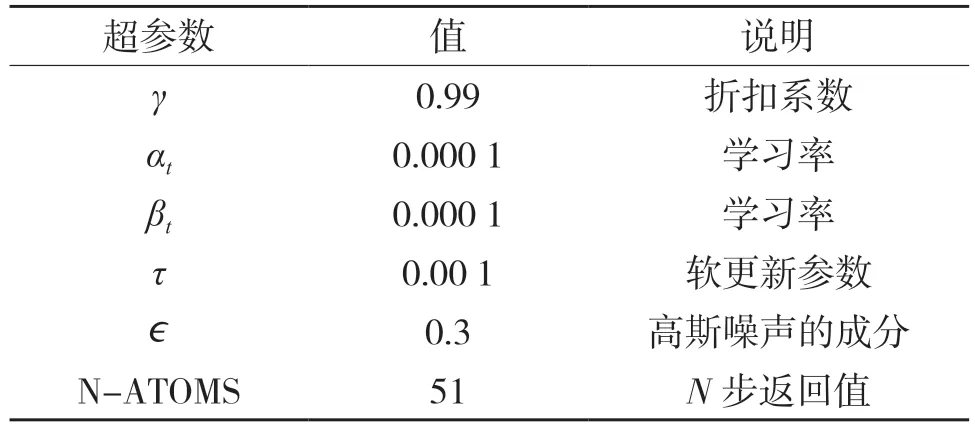
表1 D4PG 算法的超参数设定Tab.1 Hyperparameter setting of D4PG algorithm
4.3 D4PG 训练结果及分析
结合上述较佳奖励机制,设置随机目标位置,利用D4PG 算法对机械臂进行训练,每次100 个回合,每回合50 步,进行400 k 次训练,并相应地用DDPG 算法训练,结果如图7、图8 所示。
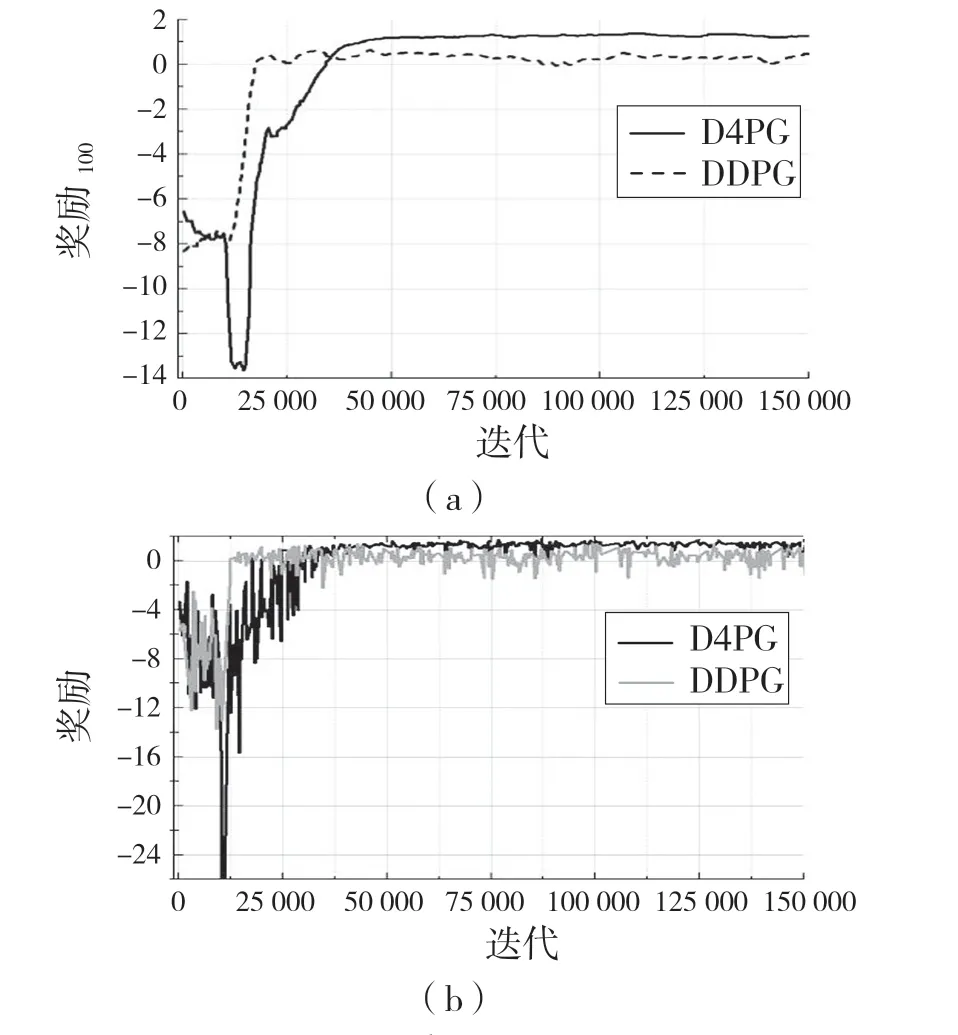
图7 机械臂训练期间奖励Fig.7 Rewards during manipulator training
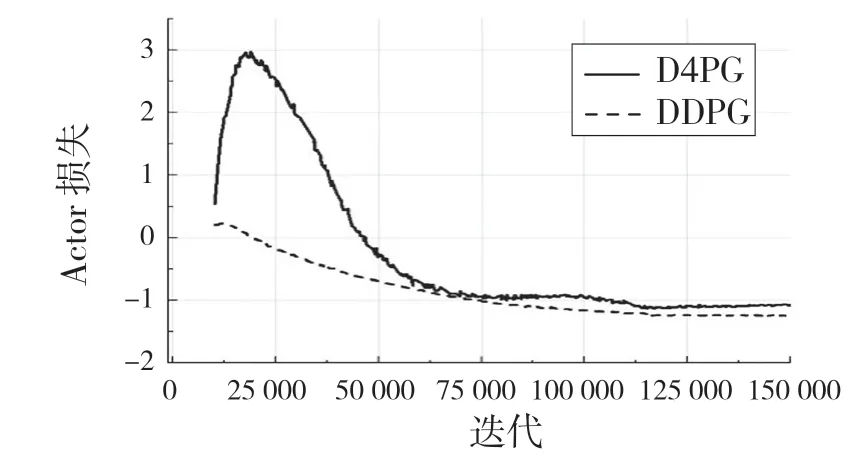
图8 机械臂训练期间损失Fig.8 Loss of manipulator during training
图7 为机械臂在训练期间的奖励变化曲线,其中图7(a)为每100 个回合平均奖励值,图7(b)为每帧的奖励值。从图7 可以看出,D4PG 算法在训练中能收敛到更好的奖励值,接近环境的最高奖励值;DDPG 算法在前期奖励值大于D4PG,这主要原因是D4PG 是先采样一定数量的动作后再进行智能体的学习过程。
从图8 的Actor 和Critic 网络的2 种算法的损失对比,D4PG算法的性能更优,训练过程更加稳定,收敛度好。在训练过程中每1 000 次对训练模型进行测试,测试结果如图9 所示。
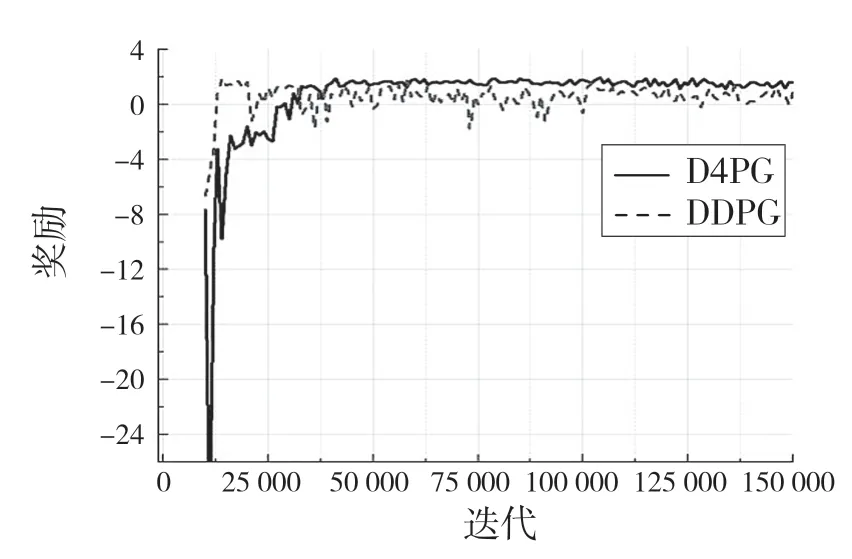
图9 机械臂测试期间奖励Fig.9 Rewards during manipulator testing
在测试中可以看出D4PG 训练的模型在测试中比DDPG 算法表现更好,能更快接近环境的最大奖励值,并保持较稳定的收敛状态,而DDPG 收敛到最大奖励值的速度慢。在经过400 k 帧的训练中,D4PG 算法最大达到了1.978 的奖励,已经非常接近环境的最大奖励值了。
5 结论
控制策略对机械臂生产效率有很大影响,好的控制策略能起到事半功倍的效果。本文利用DDPG算法,研究奖励函数对机械臂训练的作用。利用较好的奖励机制,使用D4PG 算法进行机械臂末端执行器到达目标位置进行仿真训练,相比于DDPG 算法,D4PG 训练过程更加稳定,在最短时间内收敛,在相同次数的测试中能达到更大的奖励。模型可视化实验中也能以100%的成功率到达目标位置。利用深度强化学习控制策略使机械臂的控制更加智能化,效率更高。
在D4PG 算法的模型测试中也遇到了一些问题,最好的测试模型在可视化实验中会出现到达目标位置后发生抖动现象,但是在测试中奖励值次一点的模型可视化实验中未出现抖动现象,需要进一步研究和改进。
猜你喜欢
当代工人(2020年8期)2020-05-25
小学生作文(低年级适用)(2019年5期)2019-07-26
小学生作文(低年级适用)(2018年3期)2018-04-17
读友·少年文学(清雅版)(2018年12期)2018-04-04
小溪流(画刊)(2017年12期)2018-01-10
山东青年(2016年3期)2016-02-28
儿童故事画报·发现号趣味百科(2015年12期)2016-01-25
少儿科学周刊·少年版(2015年4期)2015-07-07
