
基于语音特征融合的帕金森疾病诊断
2023-09-20 06:37牟新刚陶佳昕
数字制造科学 2023年3期
牟新刚,陶佳昕,陈 龙
( 武汉理工大学 机电工程学院,湖北 武汉 430070)
帕金森病(PD, parkinson′s disease)是一种神经退行性疾病,分为运动特征和非运动特征,包括震颤、强直、运动迟缓、认知障碍、睡眠障碍和抑郁等[1],该病主要影响中枢神经系统,导致帕金森患者的功能障碍[2],据统计全世界大约有4%的帕金森患者年龄在50岁以下,呈年轻化的趋势。因此,探讨帕金森的早期诊断对控制患者的疾病和延长其寿命具有重要意义。
研究发现,90%的患者在其早期症状中有声带损伤。构音障碍作为非运动症状之一,是指产生语言的肌肉的运动减少,构音障碍会影响患者的呼吸、发声、共鸣和发音,呼吸问题会干扰患者的声音响度,发声期间的声带振动会在语音中产生周期性模式,因此研究人员研究了语音特征来诊断帕金森病。
Sakar等[3]使用流行的机器学习技术研究了帕金森数据集,采用多种录音的声学特征的平均值以及标准偏差。Chethan等[4]从MDVR-KCL(mobile device voice recording at king′s college London)[5]语音数据集中提取了13个声学特征(其包括基频微扰、振幅微扰、音调和谐波噪声比),并使用KNN(k-nearest neighbor)分类器来预测PD,其精度达到85%。Berus等[6]使用这些特征以及一些附加的声学特征对来自UCI(university of california Irvine)机器学习数据库的帕金森数据集采用人工神经网络进行预测,得到了86.47%的准确性。Jeancolas等[7]提出使用梅尔频率倒谱系数结合高斯混合模型来检测PD,获得的分辨率为79.5%。由于大多数研究都基于UCI数据库提供的已经处理好的声学特征信息,针对实际应用过程中的原始语音信号,受到外部因素如环境、口音的影响,往往分类效果表现不佳。
近年来,由卷积神经网路和递归神经网络相结合的卷积递归神经网络(CRNN, convolutional recurrent neural network)[8]在语音识别领域很受欢迎,并在相关领域达到了最新水平。但是,CRNN上的大多数工作仅利用简单的光谱信息。因此,笔者提出基于语谱图和声学特征的语音识别模型,旨在从语音中获取更丰富的信息,通过傅里叶变换转换成语谱图,结合手工提取的声学特征,更好地捕捉语音的动态病理特征,利用卷积神经网络和循环神经网络结构,进行PD检测,为了评估所提方法的性能,使用来自PC-GITA数据集的帕金森病语音记录,与UCI数据库中提取好的特征信息数据不同,该数据集提供完整的原始语音信号,结果表明,得到了84.1%的分类准确率。
1 语音特征融合算法
1.1 模型提出
模型总体结构如图1所示。所提出的模型融合了手工提取的声学特征和语谱图深度特征。语谱图深度特征由门限循环单元GRU(gated recurrent unit)进行编码。最后将得到的特征进行拼接,输入到全连接层进行帕金森疾病诊断。
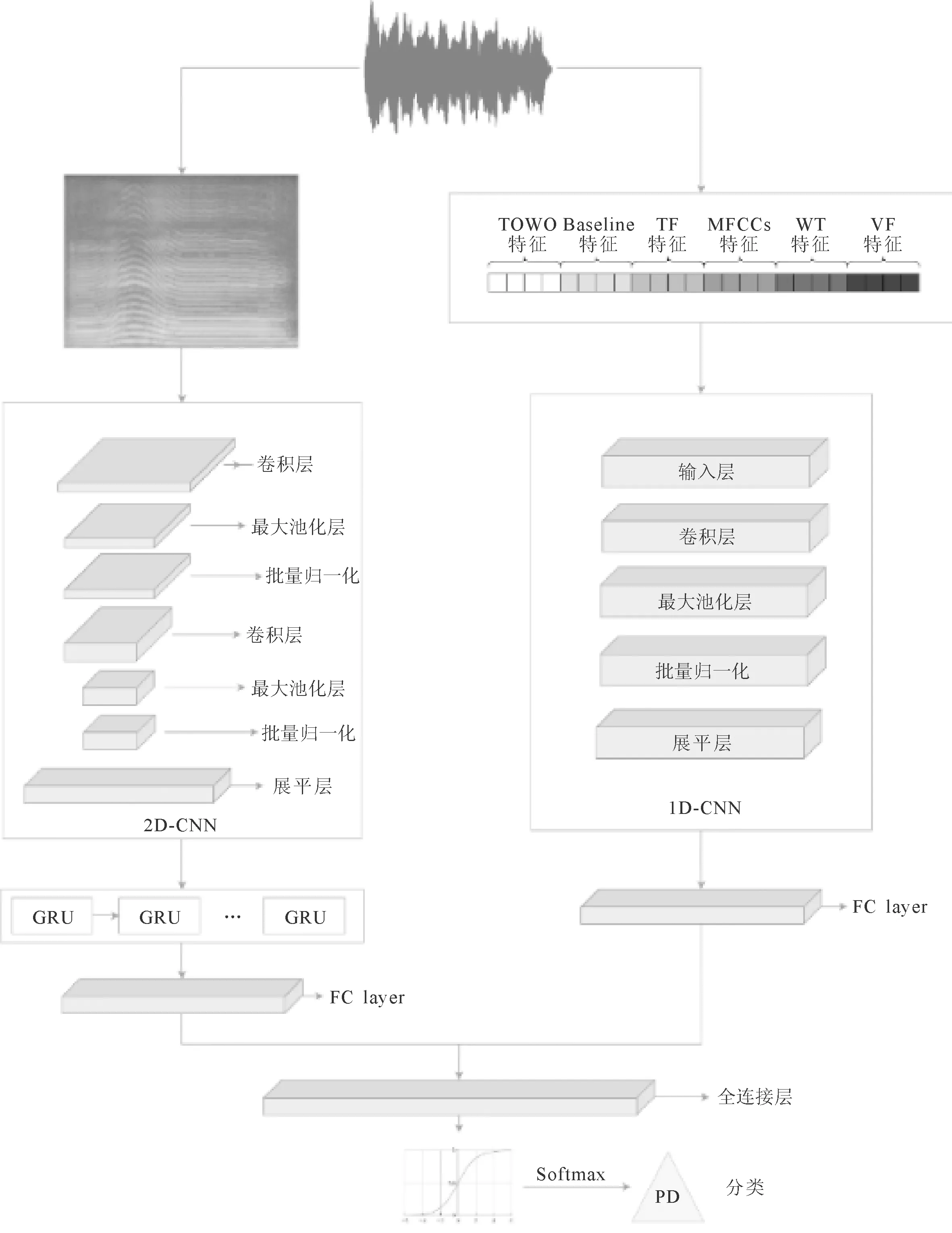
图1 算法模型图
笔者提出了一种新的声学特征融合模型,该模型采用双通道来实现语音特征的联合学习,其中语谱图特征是由原始语音信号分帧加窗后经过短时傅里叶变换得到,对于语谱图,在经过卷积神经网络提取特征后,输入RNN(recurrent neural network)中进行递归编码。 对于手工提取的声学特征,输入到一维卷积神经网络进行训练,最后将处理过后的语谱图特征与声学特征拼接后使用全连接层进行预测。
使用门限循环单元GRU[9]进行递归,用于捕捉语音信号的时间序列特征,相比于长短时记忆网络(long short term memory,LSTM),GRU结构更为简单,能在更少计算的基础上获得不亚于LSTM的结果。
通过卷积模块进行深度特征提取,利用卷积层中卷积核进行特征提取和映射,在池化层中进行下采样,对特征图进行稀疏处理,减少运算量,使用归一化层使数据尽量接近标准分布,上述各层堆叠构成最小单元进行双层堆叠,最后介入展平层将多维输入转换成一维,再连接dropout层,训练时使部分神经元失活,有效避免过拟合的发生。最后通过GRU获取语音信号的时序特征,对特征作进一步提取,提取后的特征作为全连接层的输入,经过Softmax计算类别概率,完成帕金森语音识别。
所提出的帕金森语谱图和声学特征框架用于特征提取,在这两种特征提取方法之前,为了将数据输入分类器,首先要进行信号预处理,也就是通过语音信号得到所需的语谱图和手工声学特征。
1.2 语谱图特征提取
将语音信号转换成语谱图,语谱图是随时间变化的信号频谱的可视化表示,由于语音信号是一维时域信号,虽然目前针对帕金森语音障碍的特征提取方式有很多但无法确定提取的特征是否能够真正用于帕金森诊断,故而引入语谱图的方式,将语音一维信号转化成二维的时频图来进行深度特征提取,即同时在时域和频域中进行特征提取已充分描述它们的性质。为此,需要对原始的语音信号分帧操作并使用汉宁窗进行加窗,逐帧进行短时傅里叶变换(STFT, short-time fourier transform),STFT通过在短重叠窗口上计算离散傅里叶变换来表示时频域中的信号。函数中FFT(fast fourier transform)窗口大小为2 048个样本点,对应16 000 Hz采样率下2.5 s的持续时间。帕金森患者的语音信号时域波形和频谱图如图2所示。

图2 帕金森患者的语音信号时域波形和频域图
从语音信号得到的语谱图大小被缩放到240×240,采用的模型有两层Conv2D,其中第一层的卷积核大小为55,激活函数为ReLU,卷积层后面有一个内核大小为33的最大池化层,第二层的卷积核大小为33,激活函数为ReLU,卷积层后面同样有一个内核大小为33的最大池化层。另外,在每一层中引入批量归一化层,进行归一化处理,提高网络的泛化能力,最后从这些获得的三维矩阵通过展平层转换为一维向量矩阵,用于接下来的特征拼接。
1.3 声学特征提取
帕金森已被证明即使在早期也会影响言语,因此,言语特征已成功地用于评估帕金森并监测其在医疗后的演变。 基于Jitter和Shimmer的特征、基频参数、谐波参数、循环周期密度熵(recurrence period density entropy, RPDE)、去趋势波动分析(detrended fluctuation analysis, DFA)和窗口周期熵(pitch period entropy, PPE)是PD研究中常用的语音特征。梅尔频率倒谱系数(mel-scale frequency cepstral coefficients, MFCC)能模仿人耳的特性,在自动语音识别、生物医学语音识别和帕金森诊断等不同任务中被称为稳健的特征提取器,能检测到帕金森语音的失真部分。小波变换(wavelet transform, WT)是检测长时元音全周期区域尺度波动的重要工具。可调Q因子小波变换(tunable Q-factor wavelet transform, TQWT)是另一种特征提取方法[10],应用上述信号处理技术,依靠Praat声学分析软件提取,每个特征的详细信息和特征个数如表1所示。
由基频特征、时频特征、梅尔频率倒谱系数、小波变换特征、声带特征和可调Q因子小波变换特征组成的手工特征集,先归一化以将数据集中的每个特征向量的值改变为公共尺度,而不扭曲值范围的差异。然后,引入一维CNN(convolutional neural network)模型训练。所提出的模型中有两个模块,其中每一块都有卷积层,最大池化层和防止过拟合的dropout层。输入被传递到这两个模块之后,第二个模块的输出全连接层即可进行后续特征拼接。进行训练和测试以验证模型,训练阶段将数据分为两组,训练集和测试集,其中20%的总数据被分割以用于测试模型,其余80%的数据用于训练网络模型,以提高分类精度。
2 语谱图声学特征融合实验
2.1 数据集
PC-GITA数据库[11]用于评估所提出的模型。该语料库包括50名帕金森患者和50名健康受试者的录音,在这项研究中考虑了两个录音任务,参与者被要求在一次呼吸中发出尽可能长的元音/a/。所有参与者都签署了事先获得哥伦比亚麦德林诺埃尔诊所伦理委员会批准的知情同意书。语音信号是使用舒尔SM63L麦克风和专业声卡在隔音室中记录的。音频以44.1 kHz的频率录制,分辨率为16位。每组参与者包含25名男性和25名女性演讲者。语料库在年龄上也是平衡的(独立样本的t检验,p=0.77)。所有患者均由神经科医生诊断。数据集详细数据如表2所示,UPDRS为帕金森综合评分。
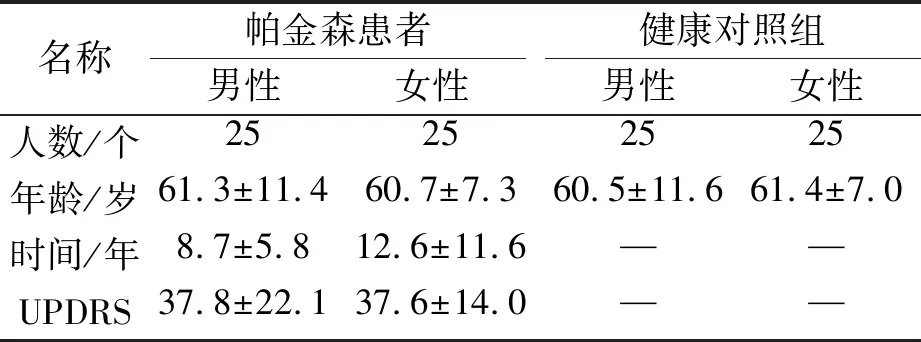
表2 数据集详细数据
2.2 实验设置
为了验证所提方法的有效性,将提出的算法与以下4种方法比较:
(1)单一语谱图(single-spectrum),将输入的语音信号转换为语谱图后,输入卷积神经网络,最后使用全连接层进行帕金森诊断。
(2)单一语谱图配合循环神经网络(spectrum with GRU),将语谱图输入卷积神经网络后,再输入到GRU门限循环单元进行编码,最后使用全连接层进行帕金森诊断。
(3)单一声学特征(single-acoustic),从语音信号提取出多维手工特征后,输入一维卷积神经网络,最后使用全连接层进行帕金森诊断。
(4)单一声学特征配合循环神经网络(acoustic with GRU),将手工特征输入到一维卷积神经网络,再输入到GRU门限循环单元进行编码,最后使用全连接层进行帕金森诊断。
2.3 实验结果
对上述4种方法进行测试,表3为引入门控循环网络GRU实验的对比结果。
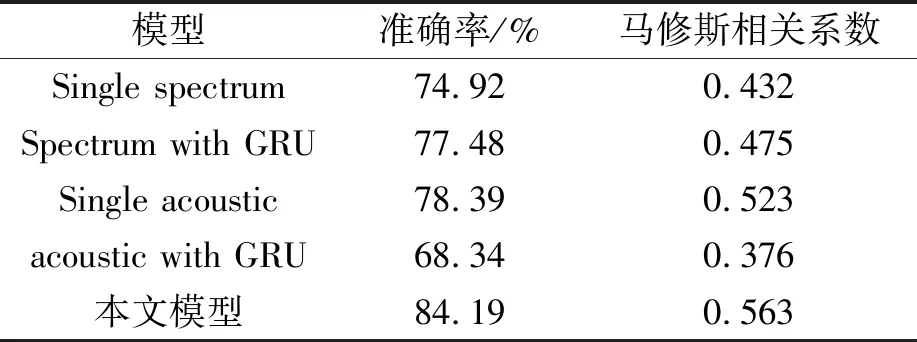
表3 引入GRU前后的对比实验结果
相较于普通CNN模型,单一语谱图特征在引入GRU后的模型识别率在数据库上有了2.56%的提升,证明GRU能够有效地提取语谱图特征中的动态病态信息,提升帕金森疾病的识别性能。单一声学特征在引入GRU模型后识别率反而降低了10.05%,因为声学特征直接不存在时序关系或先后顺序,无需引入GRU循环神经网络学习时间或者序列依赖性的特征。
为了验证不同特征融合的最佳结果,将引入GRU前后的单一声学和语谱图特征两两融合,对比实验结果如表4所示。
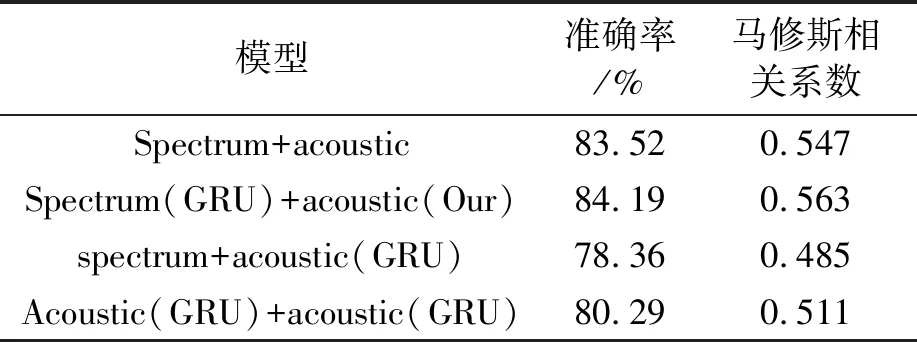
表4 融合方式对比实验结果
实验结果表明,单语谱图与声学特征融合的分类准确率为83.52%,引入GRU模型后的语谱图再与声学特征融合的分类结果可达84.19%,而引入GRU模型后的声学特征与语谱图特征拼接后准确率有所下降,这是由于声学特征不存在时序关系或先后顺序,因此所提出的由CNN和GRU提取语谱图特征融合CNN提取的声学特征的模型更能捕捉语音信号的深层信息,所得的分类准确率和马修斯相关系数都是最高的。
另外,为了进一步说明所提出的模型在帕金森疾病诊断时的分类精度,实验比较了3种之前常用于帕金森语音检测的机器学习模型[12]。得到的分类结果如表5所示。
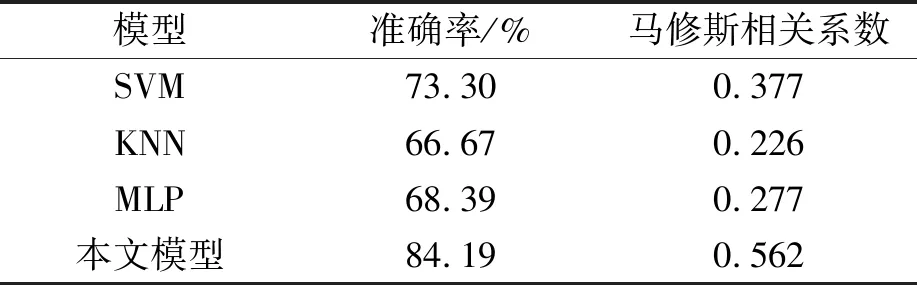
表5 机器学习分类实验结果
表5中展现了不同机器学习方法的对比,包含了SVM(support vector machine),KNN以及MLP(multilayer percetron),虽然处理时间降低,但分类效果不如所提出的门控卷积循环网络好。
3 讨论
在语音PD检测任务中,基于机器学习方法的性能主要受语音特征和机器学习模型架构的影响。目前在UCI帕金森公开语音数据集中,采用机器学习的方法能获得90%以上的分类准确率。但当使用原始语音信号进行分类时,结果降低了一定的准确率。笔者基于门控卷积神经网络,融合语谱图与声学特征,在持续元音输入下获得了更高的分类精度,结果表明,帕金森检测系统得益于这两种方法的结合(基于动态语音特征的GRU模型和CNN模型)。在实际检测环境下输入信号为原始语音信号,而UCI数据集所提供的为提取好的特征值,本文提出的模型在实际诊断环节展现更好的鲁棒性。由于更复杂的网络架构(如具有更多层的深度混合模型或深度强化学习模型)尚未在本研究中进行实验,因此可以看到进一步改进模型架构的空间。
4 结论
笔者研究了使用卷积循环神经网络结构下的帕金森疾病检测任务,提出了双通道卷积门控循环网络以充分利用声学特征以及来自语音频谱的深度信息,分析了50名PD患者和50名健康对照者的录音,参与者以恒定的音调进行元音/a/的持续发声。从录音中提取语音特征。结果表明,融合声学特征和CRNN学习的语谱图特征能为帕金森疾病识别提供更丰富的病例信息,对于持续元音,最高准确率可达到84.19%。
猜你喜欢
中国药学药品知识仓库(2022年6期)2022-04-11
老年医学研究(2021年5期)2022-01-19
家庭影院技术(2020年6期)2020-07-27
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
家庭影院技术(2018年10期)2018-11-02
自动化学报(2017年11期)2017-04-04
中国卫生标准管理(2015年25期)2016-01-14
噪声与振动控制(2015年4期)2015-01-01
