
基于多头自注意力机制的茶叶采摘点语义分割算法
2023-09-23 03:48郑子秋宁井铭
农业机械学报 2023年9期
宋 彦 杨 帅 郑子秋 宁井铭
(1.安徽农业大学工学院,合肥 230036; 2.安徽省智能农机装备工程实验室,合肥 230036;3.茶树生物学与资源利用国家重点实验室,合肥 230036)
0 引言
目前我国名优茶采摘仍以人工为主,在春茶加工季节,需要大量的人力资源,成本高。而现有的采摘机械[1-3],嫩芽和老叶不加区分的“一刀切”,原料质量得不到保证[4]。但随着机器视觉技术的兴起,为解决茶叶选择性采摘问题提供了一种新的途径,茶芽的识别和可采摘区域定位则是实现选择性自动化采摘的前提。
早期的研究多基于图像的阈值分割方法进行茶芽的识别,如文献[5-7]中采用单一色彩阈值或联合色彩阈值的方法从图像中识别茶芽目标。然而,茶园环境具有非结构特性,包括不受控制的光照、茶叶嫩芽和老叶之间的高度相似性等,在这些条件下,阈值分割法可能面临鲁棒性不足的问题。
近年来,卷积神经网络得益于较为优秀的特征提取能力,对复杂背景的目标定位表现出较好的鲁棒性,受光照、背景影响较小。王琨等[8]、吕军等[9]选取茶叶的部分颜色和形状特征作为特征集,输入卷积神经网络模型,通过训练最终使得模型能够识别茶叶嫩芽。孙肖肖等[10]使用改进的YOLO v3识别茶叶,经测试平均准确率达到了84.2%,召回率达到了82%。吕军等[11]使用结合图像预处理的改进YOLO v5模型,解决由于茶园的光照变化茶芽难以准确检测的问题。由前述可知,基于卷积神经网络的目标检测技术为茶芽的识别提供了可行的技术途径。
一旦图像中的茶芽目标被定位,准确采摘的下一步就是分割可采摘点或可采摘区域。然而,由于采摘点区域不尽相同,形态大多不规则,而茶叶选择性采摘又需要准确的像素坐标,此时再使用目标检测不再合适。语义分割是机器视觉中的典型任务,可用于像素级的对象检测,能够准确定位茶叶采摘点的区域。该方法已被应用于需精准定位目标像素坐标的相关农业领域,如作物采摘。LI等[12]使用DeepLabv3+模型[13]分割龙眼果串的主果枝,分割结果的像素准确率达到了94.52%。ZHU等[14]为自动准确地识别甜椒采摘区域,使用自建的全分辨率残差网络分割彩椒图像,在测试集的像素准确率达到了97.94%。YU等[15]使用Mask R-CNN模型分割草莓图像中的可采摘区域,100幅测试图像的检测结果显示,平均检测准确率为95.78%,召回率为95.41%,分割的平均区域重合度为89.85%。由于语义分割结果能精准获取采摘区域,极少包含无关信息,在采摘点定位领域,可以给予后续处理器有效的目标信息,简化下一步需要数据过滤工作。但上述研究的试验环境,部分目标与背景相似程度较小,如草莓果实与背景的颜色特征差异明显;部分研究工作在室内环境或实验室环境开展,可能难以直接应用于复杂的茶园环境。
本文针对茶芽采摘点分割时面临的目标尺度小、背景复杂等问题,提出RMHSA-NeXt语义分割模型,其特点在于使用残差多头自注意力模块和结合条形池化的ASPP[13]模块,能够提高对关键特征的关注程度,并降低对背景与目标的干扰,达到准确分割采摘点的目的,以期为自然环境下茶叶机械选择性采摘提供可靠识别依据。
1 材料和方法
1.1 茶叶采摘点数据来源与数据集构建
茶叶图像数据采集于六安市金寨县青山镇抱儿村,采集时间为2022年4月上旬到10月下旬。图像采集设备为STEREOLABS公司生产的ZED双目相机,为了使图像数据更加贴合采茶机械的工作状况,采用视频录制的模式,视频分辨率为1 920像素×1 080像素。所有数据采集完成后通过STEREOLABS公司提供的视频转换软件,将视频数据逐帧转换为图像数据,筛选后,得到原始数据集图像数量为3 192幅。
为了开展茶叶采摘点语义分割模型研究,首先采用目标检测模型对原始数据集做茶芽目标检测,经过对目标检测结果的筛选,最终采摘点数据集图像数量为26 793幅,本文使用Labelme软件标注出茶叶可采摘区域,按照9∶1的比例将数据划分为训练集和测试集。
分析采摘点数据集后,发现本文的分割目标的特点在于:茶叶采摘点目标较小(普遍尺度约100像素)、光照强度变化范围大、采摘点的背景多为茶叶,纹理和色彩差距不明显、采摘点形状普遍为长条形等,图1 为茶叶目标检测与分割的场景分析图。

图1 茶叶目标检测与分割的场景分析
1.2 RMHSA-NeXt语义分割模型
通用的语义分割模型由编码器和解码器构成,编码器进行特征提取,解码器利用反卷积或者上采样运算将编码器输出的低分辨率特征映射到高分辨率像素空间,得到密集的像素预测分类[16]。为解决茶叶采摘点较小、光照变化范围大、采摘点与老叶较为相似等问题,本文使用编码-解码架构设计提出了一种新的语义分割模型——RMHSA-NeXt,其网络结构如图2所示。为了准确分割茶芽采摘点,该模型提出了以下方法:①在模型的编码阶段,采用ConvNeXt作为特征提取单元,其可以有效地筛除无用特征,增强有效特征的表达,减少茶园环境中的光照变化和茶芽采摘点与背景相似度较大的影响。②提出残差多头自注意力模块(Residual multi-head self-attention,RMHSA),其根据茶芽特征相关性为各特征分配权重,将模型注意力集中于茶叶采摘点目标,减少不相关的老叶背景的干扰,进一步强化模型的特征提取能力。③设计结合条形池化的ASPP结构,由于茶芽采摘点多为长条形,故将常用的正方形池化改变为条形池化,便于抑制背景干扰,且由于其内部的多尺度融合机制,有望解决茶芽采摘点小、目标特征信息不足的问题。
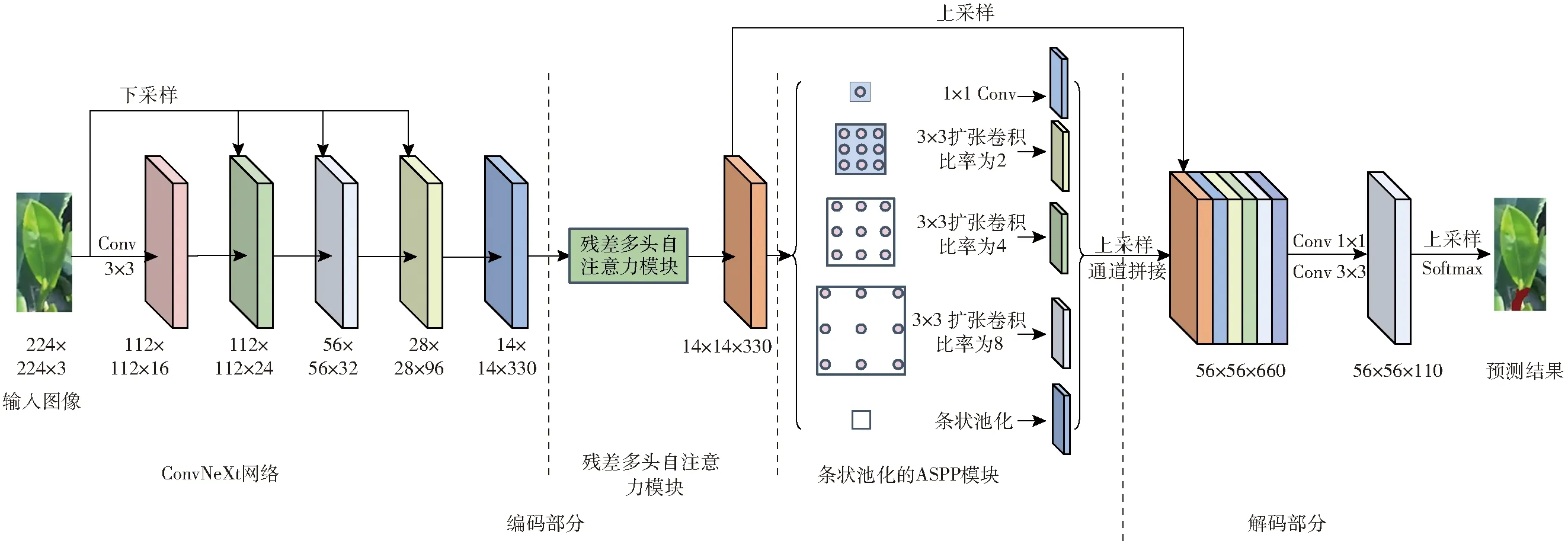
图2 RMHSA-NeXt语义分割模型
1.2.1特征提取网络
近年来,Swin Transformer[17]越来越多地被应用于计算机视觉领域,并且展现了优异的性能。ConvNeXt吸收Swin Transformer的优点,通过结合Swin Transformer的层结构、倒置瓶颈和深度可分离卷积(Depthwise Convolution)等技巧,进一步提高了模型的特征提取能力,因此,本文的语义分割模型使用ConvNeXt作为初始特征的提取单元。
图3是ConvNeXt网络结构图,其借鉴了ResNet的设计思想,在ResNet传统结构上,增加了下采样方法,该网络主要由ConvNeXt block组成。图4是ConvNeXt block的结构图,首先将初始特征与提取后的特征相融合;其次在特征提取过程中使用深度可分离卷积,只在每个通道上进行空间信息的交互,减少了参数,同时激活函数使用GeLU,相较于ReLU更加平滑和连续,也有更高的收敛几率;而后使用层归一化(Layer normalization),将这一中间层的神经元参数进行归一化,对神经网络中隐藏层的输入进行归一化,从而使得网络更容易训练[18];最后使用Drop path随机地将深度学习中的多分支结构删除,即让某些神经元失效,添加正则化能力,防止模型过拟合。

图3 ConvNeXt网络结构图

图4 ConvNeXt block 网络结构图
1.2.2残差多头自注意力模块
注意力机制主要根据上下文内容或像素间的相关性快速提取数据或者图像中的重要特征。多头自注意力模块[19](Multi-head self-attention,MHSA)是多个自注意力模块[20]平行堆叠而来,其可以根据采摘点目标相关性为各特征动态地分配权重,将网络注意力集中于茶叶采摘点目标,减少茶园中不相关背景的干扰,提高网络特征提取性能。
本文基于残差结构和多头自注意力机制,构建了如图5所示的 RMHSA 结构,其中多头自注意力模块代替了原本残差结构中的卷积模块,同时使用两次的跳连接,让未被处理过的原始特征与被多头自注意力模块处理过的特征充分融合。在图5中多头自注意力机制部分是由多个自注意力机制平行计算,最后拼接而来,自注意力机制作用在于减少了对外部信息的依赖,更有利于捕捉茶芽采摘点数据或特征的内部相关性,图6展示了自注意力机制的结构。

图5 残差多头自注意力模块结构示意图

图6 自注意力机制结构示意图
模块的输出Z为基于查询向量WQ、键向量WK、值向量WV的加权和,计算式为
Z=Softmax(WKWQ)WV+X
(1)
式中X——输入特征
自注意力模块的输入通过线性变换得到WQ、WK、WV。其中WQ的目的是计算当前位置与其他位置之间的相似度;WK用于计算当前位置和与其他位置之间的相似度,在运算过程中,WK通常会与WQ进行矩阵乘法,得到每个位置向量的权值。而WV与WQ、WK计算出的权值矩阵进行矩阵乘法,得到特征的加权平均结果。
1.2.3结合条形池化的ASPP
多尺度结构可以通过不同尺度的特征提取,帮助网络获得不同感受野下的图像信息,以增强模型对小目标的感知能力。因此,多尺度信息捕获能力对于解决茶叶采摘点图像有效信息过少具有重要意义,本文选择了ASPP结构作为模型中的多尺度结构。ASPP通常由1个1×1卷积、3个不同采样率的3×3扩张卷积和1个空间池化组成。在这种结构中,通过设置不同的采样率可以得到不同比例的特征图。
由于初始ASPP中的空间池化的采样窗口为正方形,而本文中的茶叶采摘区域大部分为长条形,此时正方形窗口不可避免地会包含其他不相关区域的干扰信息。因此,本文采用了条形池化结构,由于长条形采样窗口采样时会减少不相关信息的获取,从而降低无关信息的干扰[21]。改进后的ASPP结构如图7所示,而条形池化计算过程如图8所示。

图7 改进后的ASPP结构示意图
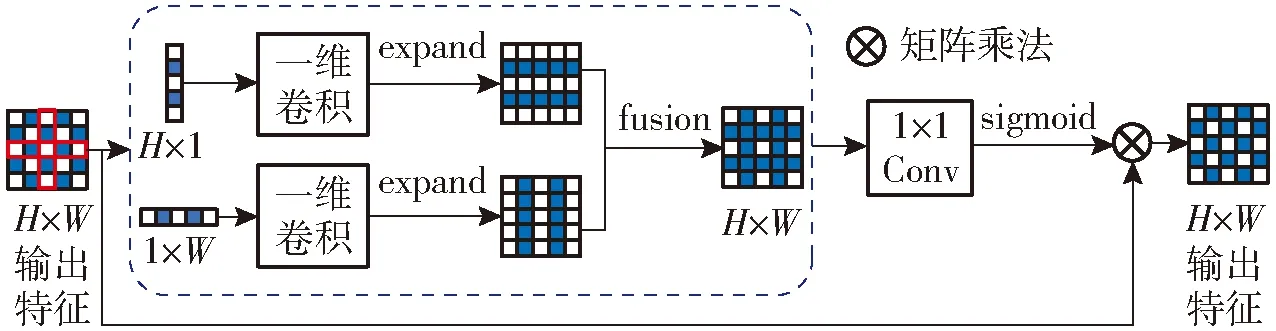
图8 条形池化示意图
在条形池化时,首先将输入特征图进行水平和竖直条形池化后变为H×1和1×W两个特征图,随后经过卷积核为3的一维卷积对2个特征图分别沿着左右和上下进行扩容,扩容后两个特征图尺寸相同,扩容后的两特征图对应相同位置求和得到H×W的特征图,之后通过1×1的卷积与sigmoid处理后与原输入图对应像素相乘得到了条状池化输出结果,在本文中H和W均为5。
1.2.4解码部分
在编解码结构中,编码器的作用是提取特征,而解码器的作用是将经过编码器处理后的特征进行采样和映射,最终实现逐像素分类。在本文模型中,首先会将从改进ASPP中获得的多尺度特征和从残差多头自注意力机制中获得的特征进行通道拼接,在此过程中,部分多尺度结构会被上采样以保证特征图大小一致;而后会经过一次1×1卷积和3×3处理,降低特征图的维度,筛选特征;最后使用上采样将图像恢复到与输入图像一样的大小,再使用Softmax函数进行结果预测,确定每一个特征图的类别。
2 实验结果与分析
2.1 实验平台
计算机配置CPU型号为Intel Core i7-9700 CPU,GPU型号为NVIDIA GTX2080Ti,内存为32 GB,1 TB固态硬盘。计算机操作系统为Ubuntu 20.04,配置PyTorch深度学习框架用于所有模型的训练和测试,模型评价等程序均在Python语言环境下编写。
2.2 模型评价指标
本文语义分割模型采用准确率、检测速度、参数量等指标进行性能评价。准确率是根据网络模型预测图像与人工标注图像之间的像素误差计算得到,设语义类别总数为k+1(k个目标类与1个背景类),Pii表示属于第i类且被预测为第i类的像素数,Pij表示属于第i类却被预测为第j类的像素数,在本文中k+1为2,即采摘区域和非采摘区域。
像素准确率(Pixel accuracy,PA)为正确预测像素数量与图像像素总量的比值,计算公式为
(2)
平均区域重合度(Mean intersection over union,MIoU)为每类预测像素数量与真实像素数量交集与并集比值,然后取所有类别的平均值。平均区域重合度反映了预测结果与图像真实结果的重合程度,是语义分割模型常采用的准确率度量标准,计算公式为
(3)
检测速度(每秒检测帧数,FPS)用来表明每秒能检测的数据帧数,其数值越高表明训练好的模型检测速度越快。
2.3 结果分析
2.3.1消融实验
为测试本文所提出的语义分割算法的有效性,设计消融实验分析各功能模块对模型性能的影响。构建基础模型,由ConvNeXt网络和解码部分组成。在基础模型上逐步加入残差多头自注意力机制、改进的ASPP等结构构成基础模型+RMHSA、基础模型+ASPP、基础模型+改进ASPP以及基础模型+RMHSA+改进ASPP模型等。通过像素准确率、平均区域重合度、参数量和检测速度对模型性能进行分析,表1为测试集在上述5种模型的运行结果。

表1 不同模型的分割结果
由表1可知,改进ASPP通过聚合不同尺度的信息增强了模型的判别能力,模型的PA与MIoU相较于基础模型也增加15.46%和16.54%,且由于采摘点目标形状均为长条形,使用条形池化减少了不相关信息的获取,提高了分割指标;对比基础模型和增加RMHSA模型的结果发现,增加RMHSA模型的PA与MIoU提升到57.14%、51.42%,表明增加RMHSA模型后,由于高效注意力机制的引入,模型更加倾向于寻找更有显著性的特征,实现强化目标、弱化背景的目的;对比基础模型+RMHSA+改进ASPP与基础模型的结果发现,相较于基础模型,本文模型的PA和 MIoU增加35.74%和37.90%,相较于基础模型+改进ASPP与基础模型+RMHSA,本文模型在准确率上有了较大的提升,且在高效注意力机制以及针对性多尺度结构的同时作用下,模型最大程度地保留了有效特征,保证了其向后传播,减少无用信息的干扰,促使网络更加关注目标物体不同部位的细节特征,也提升了目标区域的定位精度,有效组合不同尺度下的特征信息,提高分割精度。
在实时性方面,随着功能模块的加入,分割模型包含的参数不断增加,检测速度逐渐降低。其中,基础模型的参数数量最小,检测速度最快,RMHSA模块的加入使基础模型参数量增加25.35%,检测速度降低12.99%;改进ASPP模块的增加使参数量增加34.9%,检测速度降低22.80%。基于上述数据定性分析,可以得知改进ASPP模块对模型的运行效率和计算开销影响最大,RHMSA模块次之。
图9为表1中5种类别模型识别结果图,针对于分割目标的3个难点:目标较小、光照强度变化范围大、背景复杂,本文选取7幅图像展示。由图9可知,基础模型由于缺少多尺度结构以及有效的注意力机制,7幅图像均出现了较大面积的错检和漏检。基础模型+RMHSA虽然增加了高效的注意力机制,相较于基础模型有较大的进步,如图9中的第1行和第5行,但由于网络结构中的多次下采样,模型损失较多的有效特征,所以造成结果仍有较多的漏检和错检。而基础模型+ASPP和基础模型+改进ASPP结果中,由于增加了多尺度结构,减少了下采样的特征丢失,但是由于缺少高效的注意力机制的引导,仍然效果不佳,如图9中的第2、3、6、7行。而本文所提出的模型结合残差多头自注意力机制以及改进的ASPP的优点,其识别结果相较于标注图像没有明显差距,没有大面积的漏检和错检,证明使用这两种结构组合,可有效加强模型的茶芽采摘点的分割能力。

图9 不同模型的语义分割结果
2.3.2不同语义分割模型性能对比
为验证本文所提出的模型具体性能情况,选择HRNet V2[22]、EfficientUNet++[23]、DeeplabV3+[24]、BiSeNet V2[25]等模型与本文模型进行对比测试,通过像素准确率、区域重合度、检测速度和参数数量等指标对模型性能做出评价。表2为不同语义分割模型性能参数对比。
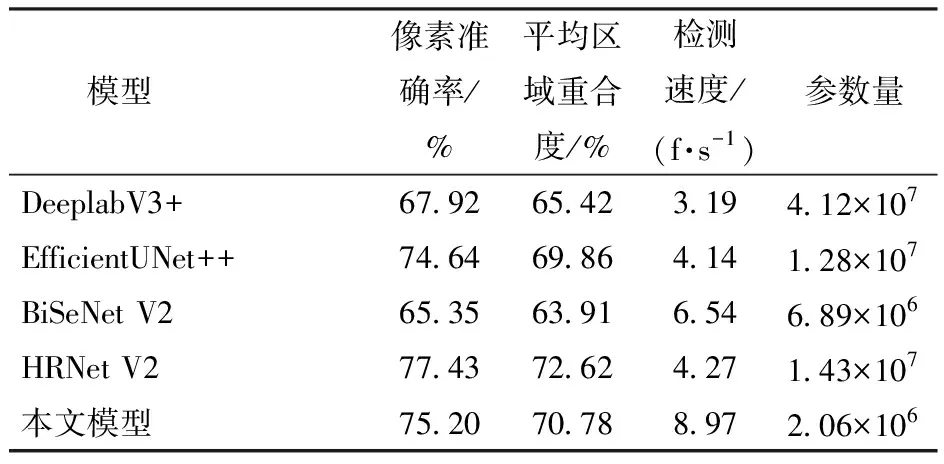
表2 不同网络模型性能对比
由表2可以看出,在像素准确率方面,本文模型的平均像素准确率与平均区域重合度分别为75.20%、70.78%,比DeeplabV3+分别高7.28、5.36个百分点;比EfficientUNet++分别高0.54、0.92个百分点;比BiSeNet V2分别高9.85、6.87个百分点,主要原因是本文模型引入的残差多头自注意力机制和条形池化的ASPP模块能够强化模型各阶段判别特征的能力,聚合不同尺度池化区域获取有效的全局上下文信息,增加模型对茶芽采摘点对象的分割精度;尽管DeeplabV3+也采用空洞卷积金字塔模块聚合多尺度特征以提高分割准确性,但由于数据集的特殊性,目标形态均为长条形,造成DeeplabV3+存在像素预测不一致性,因此在分割精度方面略低于本文模型。在实时性方面,本文采用ConvNeXt作为前置基础网络降低模型计算量,检测速度达到8.97 f/s,为DeeplabV3+、EfficientUNet++、BiSeNet V2、HRNet V2模型的2.81、2.17、1.37、2.10倍。在参数量方面,本文模型为2.06×106,低于其他网络模型。
在所有对比模型中,BiSeNet V2的特点是双路同时计算,模型的设计过程中缺乏多个尺度的图像特征交换,所以BiSeNet V2并不能很好地解决本文问题;HRNet V2以及通过多次高分辨率特征浅层网络与快速下采样深度网络融合,对于小目标的识别有很好的效果,但是由于自身设计的原因,参数量约为本文模型的7倍,虽在识别精度上超过了本文模型,但是在识别速度上确实有所差距;而EfficientUNet++使用EfficientNet[26]作为每层的特征提取网络,同时使用U-Net[27]的结构来构建网络,U-Net结构的特点是同时存在多层特征提取网络,各层之间通过下采样和上采样相互联通,从各项指标来看,虽然EfficientUNet++的精度指标与RMHSA-NeXt相近,但是由于EfficientNet的参数量较高,造成整体的检测速度不佳。综合评价上述精度和速度指标后,可得MHSA-NeXt模型可以实现精度与速度的均衡,具有良好的分割性能。
针对茶叶采摘点存在的目标较小、光照强度变化范围大和背景复杂问题,选出了7幅图像,图10为5种模型对测试集的分割结果。

图10 不同网络模型语义分割结果对比
从图10中可知,DeeplabV3+虽然在背景较为简单的场景如第2、7行分割效果与标注结果覆盖区域相似,但是在较为复杂的场景如第1、3、4、5行中,均有较大的误差,尤其在第3行出现了较大面积的错检,基于结果,本文认为DeeplabV3+分割效果不佳的原因在于缺少高效的注意力机制和针对于茶叶采摘点特性的针对性设计。BiSeNet V2识别效果不佳,虽然在第6行没有出现大面积漏检,但是在第1、3行等都有较为明显的误差,说明BiSeNet V2的双路并行计算的方式并不能很好地解决目标小、背景复杂、光照强度变化范围大的问题。HRNet V2的识别效果与本文模型识别效果也如表2所示,检测结果与标注差别较小,但其在PA和MIoU指标上略高于RMHSA-NeXt,表明多次的高低层级特征融合能有效利用小目标的图像信息,但是由于层次堆叠过多模型的整体数据量较高,检测速度较慢。从本文模型的识别结果来看,图10中除了在第3行中出现部分漏检,在其他目标中识别结果与标注图像基本相差较小,其根据目标的实际特点,设计了残差多头自注意力模块和结合条形池化的ASPP模块,以较小的参数量,获得了较好分割性能。
3 结论
(1)本文模型在实际茶园场景下,检测结果的像素准确率达到75.20%,MIoU为70.78%,运行速度达到8.97 f/s,解决了该场景下茶叶采摘点目标较小、背景复杂、光照强度变化范围大等困难,较好地完成了茶叶采摘点语义分割的任务。
(2)选择HRNet V2、EfficientUNet++、DeeplabV3+、BiSeNet V2模型与本文模型进行对比测试,通过比较像素准确率、区域重合度、检测速度、参数数量等指标,可以发现多次不同阶段的高低层特征融合可以有效提取小目标的显著特征,但是检测速度就会下降,而本文中提出的两种特殊结构,以相对较少的参数量达到了较高的准确率,平衡了模型的检测速度与准确率。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
青岛农业大学学报(自然科学版)(2022年3期)2022-10-10
小雪花·成长指南(2022年1期)2022-04-09
软件导刊(2022年3期)2022-03-25
新一代信息技术(2021年22期)2021-12-29
茶业通报(2021年3期)2021-12-07
计算机技术与发展(2019年1期)2019-01-21
传媒评论(2017年3期)2017-06-13
诗潮(2017年2期)2017-03-16
第二课堂(课外活动版)(2016年2期)2016-10-21
