
基于分数阶微分和最优光谱指数的大豆叶面积指数估算
2023-09-23 06:38向友珍安嘉琪唐子竣李汪洋史鸿棹
农业机械学报 2023年9期
向友珍 王 辛 安嘉琪 唐子竣 李汪洋 史鸿棹
(1.西北农林科技大学旱区农业水土工程教育部重点实验室,陕西杨凌 712100;2.西北农林科技大学水利与建筑工程学院,陕西杨凌 712100)
0 引言
大豆是世界农产品贸易中最重要的油脂产品之一,我国的大豆消费市场广阔,但大豆的自给率却不到15%,其产量与品质直接影响着我国粮食安全水平[1]。大豆开花期生长状况对于大豆后续生殖生长与最终产量形成有着重要影响[2]。单位耕地面积上作物叶片总面积与耕地面积之比[3]即为叶面积指数(Leaf area index,LAI),是一种描述植物冠层结构与生长状况的关键植物生理参数[4-5]。科学高效地获取大豆开花期LAI对开花期大豆的生长状态评估与产量预测具有重要意义[6-7]。
采用传统方法对LAI进行直接测定费时、费力、成本较高且具有破坏性与不可恢复性。高光谱遥感农作物生长监测技术因其光谱分辨率高、连续波段多[8]的特点,可对田间作物LAI进行实时、高效测定[9-10]。现有研究大多利用原始冠层高光谱反射率数据进行LAI反演模型构建,但直接采用原始高光谱反射率数据构建的LAI反演模型预测效果并不理想[11]。有学者引入整数阶微分变换方法对原始高光谱反射率数据进行处理,在一定程度上消除了光谱数据的背景噪声,提高了建模精度[12];但也有研究表明1阶、2阶乃至更高阶的整数阶微分变换方法忽略了光谱信息的连续性与渐变性[13],在消除背景噪声的同时也会造成光谱特征的丢失[14]。在土壤含盐量的反演研究中,已有学者发现相较于整数阶微分变换,分数阶微分变换处理得到的光谱反射率与盐分指标具有更强的相关性[15]。作为整数阶微分的数学拓展,分数阶微分变换可以突出光谱信息的细微变化,增强部分较弱的光谱特征,提高光谱反射率信噪比[16]。
光谱指数是不同敏感波段的线性或非线性组合[17],与单一波段相比,根据绿色植被特有光谱特征选择的波段构建的高光谱植被指数包含的作物生长信息更为充分[18]。在LAI预测模型构建过程中,适宜的波段组合选择能有效提高模型精度[19],因此构建高光谱植被指数时的波段优选也是重要的研究内容[20]。传统光谱指数多采用2个或多个固定波段进行构建,作物种类与生长环境的变化会改变作物的光谱特征,固定波段限制了光谱指数对于光谱信息的充分提取从而影响预测模型的拟合优度[21]。采用相关矩阵法在全部可用波段内筛选与大豆LAI相关性高的波段进行最优光谱指数构建,可有效解决光谱特征易受作物本身生理信息差异影响的问题,显著促进了光谱信息的利用[22]。高光谱遥感技术对于光谱的划分更为精细,提供了在所有可用光谱波段范围内选择与LAI有强相关性的波段进行最优光谱指数构建的可能。
本文以不同施氮水平与覆膜处理下的开花期大豆LAI为研究对象,对原始高光谱反射率进行0~2阶分数阶微分变换(步长0.5),采用相关矩阵法在350~1 830 nm波段内筛选与大豆LAI相关性最高的波段构建5组、共计25个最优光谱指数。在此基础上采用支持向量机(Support vector machine,SVM)、随机森林(Random forest,RF)、遗传算法优化的BP神经网络(BP neural network optimized by genetic algorithm,GA-BP)构建开花期大豆LAI预测模型,并讨论不同微分阶数与不同机器学习方法的组合对于大豆LAI预测模型精度的影响,以期为更加准确、快速地获取开花期大豆LAI提供理论参考。
1 材料与方法
1.1 试验区概况
两年大豆田间试验在西北农林科技大学旱区农业水土工程教育部重点实验室节水灌溉试验站试验田(壤土)进行。试验站坐标:108°24′E、34°20′N(见图1),海拔524.7 m,属于暖温带季风半湿润气候区,降雨集中分布于7—9月,多年平均降水量约580 mm,多年平均温度约为12.9℃。

图1 试验小区布设示意图
本试验共设置了4个施氮水平:N1:30 kg/hm2、N2:60 kg/hm2、N3:90 kg/hm2、N4:120 kg/hm2,4种覆盖处理:SM:秸秆覆盖、FM:农膜覆盖、SFM:秸秆+农膜覆盖、NM无覆盖处理。秸秆覆盖量为6 000 kg/hm2,FM与SFM处理采用起垄覆盖膜侧播种方式,于试验小区内起底两条宽40 cm、高25 cm的垄,用60 cm宽的地膜覆盖垄面,大豆播种于膜侧5 cm处,行距50 cm。试验以平作不施氮处理(CK)为对照,各处理随机排列,两次重复,试验小区面积为2.5 m×6 m=15 m2,共计33个小区。试验用缓释氮肥(SNF)、钾肥(K2O,30 kg/hm2)、磷肥(P2O5,30 kg/hm2)作为基肥,在播前一次性施入。试验用大豆品种为山宁17号,分别于2021年6月17日与2022年6月9日播种,于2021年9月30日与2022年9月28日进行收获,大豆开花期分别为:2021年7月28日—8月24日与2022年7月23日—8月20日,大豆生育期内未出现明显病虫害。
1.2 数据采集
于两年试验中大豆开花期(2021年8月5日与2022年8月10日)进行LAI的测定与光谱数据的采集,采集日天气晴朗,光照稳定,两年试验共计获得LAI与高光谱反射率样本66组。数据如表1所示。

表1 大豆开花期LAI数据统计
1.2.1大豆冠层高光谱数据采集
分别于2021年8月5日和2022年8月10日10:40—13:00进行试验小区大豆冠层高光谱反射率数据采集,该时段光照充足,测量光谱信息多,误差较小。试验用高光谱测量仪器为美国ASD(Analytical Spectral Devices)公司生产的Field Spec4型可见光/近红外便携式地物高光谱仪[23],仪器波段350~1 830 nm,其中,350~1 000 nm光谱分辨率为3 nm,采样间隔为1.4 nm;1 000~1 830 nm分辨率为10 nm,采样间隔为2 nm,仪器自动将采样数据插值为1 nm间隔输出,视场角25°。
在高光谱数据采集前对光谱仪进行预热、优化处理并在1 min内完成参考板检验和比对,在前一试验小区高光谱反射率数据采集结束后,后一试验小区高光谱反射率数据采集开始前进行参考板校正。于每个试验小区中选取长势均衡的作物冠层,试验人员手持光谱传感器探头,距作物冠层顶部75 cm垂直向下采集数据,每次共采集记录10次高光谱反射率数据,依据“3σ”原则[24]剔除异常值后以余下光谱波段反射率的均值作为各小区最终高光谱反射率数据。
1.2.2大豆LAI数据采集
田间大豆LAI实测使用美国LI-COR LAI-2200C型植物冠层分析仪测定。在高光谱反射率数据影像采集的当天进行大豆LAI数据采集。在33个试验小区内各随机进行6次大豆LAI数据采集,以其均值作为各试验小区的实测值。
1.3 光谱数据处理
本研究采用Savitzky-Golay(SG)平滑法对光谱数据进行降噪处理,采用G-L分数阶微分(Fractional order differentiation,FOD)算法对高光谱反射率数据进行0~2阶(步长0.5)分数阶微分变换。G-L FOD算法可将传统的整数阶微分拓展为任意阶微分,可以更加充分地解释数据的细微变化与整体性信息,本试验中高光谱反射率数据的α阶微分公式为[25]
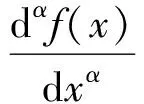
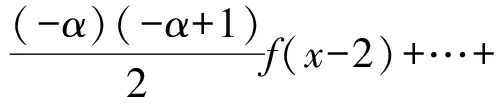

式中x——对应点的值
α——分数阶微分阶
Г——Gamma函数
n——微分上下限之差,阶数为0,则表示未经预处理
光谱数据预处理、植被指数计算均在Matlab 2018中完成,使用Origin 2021进行图形绘制。
1.4 光谱指数选择与构建
选取7种光谱指数(表2):比值植被指数(Ratio index,RI)和三角植被指数(Triangular vegetation index,TVI)与植物的叶绿素含量、LAI具有强相关性,但当植被较茂密时其灵敏度会降低[23];改进红边比值指数(Modified red edge simple ratio,mSR)与改进红边归一指数(Modified normalized difference index,mNDI)可对叶片的镜面发射效应进行优化,对于叶片的变化较为敏感;差值植被指数(Difference index,DI)、归一化植被指数(Normalized difference vegetation index,NDVI)和土壤调节植被指数(Soil-adjusted vegetation index,SAVI)均可反映植物冠层的背景影响并消除部分辐射误差[26]。
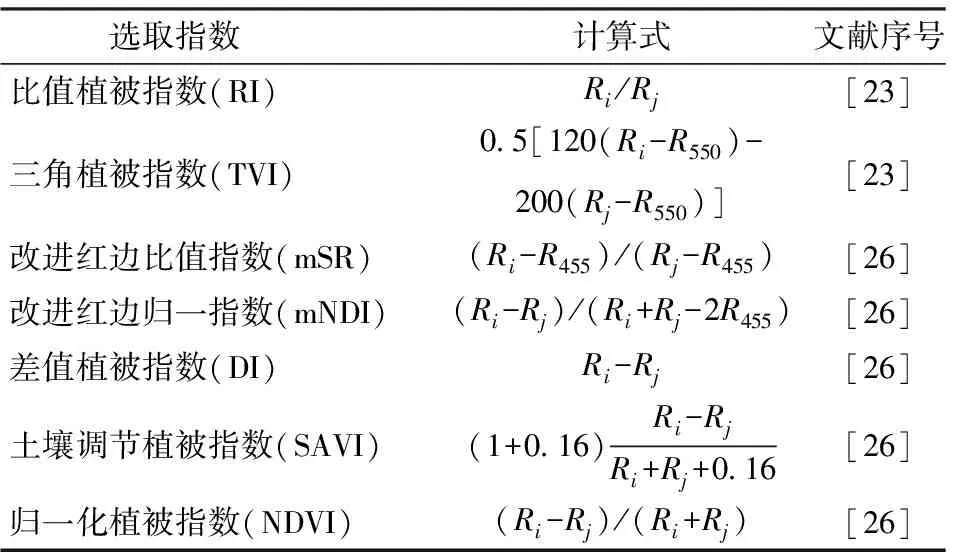
表2 研究选取光谱指数
1.5 模型构建
本研究以构建的不同阶最优光谱指数组合作为输入变量,采用SVM、RF、GA-BP共3种机器学习方法进行建模,对开花期的大豆LAI进行回归预测,训练集与验证集数据比例为2∶1,机器学习模型多次预测拟合结果的平均值作为本试验中的最终模型拟合结果。
1.5.1支持向量机
支持向量机(SVM)是一种以高斯核和多项式核作为基核函数,采用梯度下降算法进行权重系数优化的二分类机器学习算法[27],具有良好的泛化能力和鲁棒性,没有过拟合缺陷,在模式识别、分类以及小样本回归分析中得到了广泛应用[28]。根据最小交叉验证误差的原则,本研究中SVM模型的惩罚系数C与γ分别为20与0.02。
1.5.2随机森林
随机森林(RF)是一种基于Bagging模型思想的积分模型。由于其简单、方便的特点,已广泛应用于各种回归和预测问题中。RF模型对每棵树的结果进行加权平均以达到最终输出,因此该模型的实现需要构建大量的决策树,并通过交换和改变协变量来构建一组决策树以提高预测性能[29-30]。随机森林需要在放回样本得到的N个采样训练-测试集上训练N棵决策树,基于随机森林模型的回归,将多棵决策树的平均预测结果作为最终结果。在决策树模型内进行训练-测试时,需要遍历每个特征和每个方法以有效地确定最优决策树数量,经过多次训练与误差分析,RF模型中的决策树数量确定为100。
1.5.3遗传算法优化的BP神经网络
BP神经网络(Back propagation neural network)是采用逆向传播算法进行训练的一种多层前馈型网络,本质上是基于梯度下降的一种迭代学习算法,存在易陷入局部极小点、收敛速度慢、接近最优解时可能产生振荡等缺陷[31]。
遗传算法(Genetic algorithrn,GA)是以自然选择和遗传理论为基础,将生物进化过程中适者生存原则与群体内部染色体的随机信息交换机制相结合产生的一种全局寻优搜索算法,它不依赖梯度信息,特别适用于高度非线性、不连续等复杂系统的优化问题,广泛应用于机器学习、人工神经网络训练、模式识别等复杂优化问题[32-33]。遗传算法可对BP神经网络的初始权值进行优化,替代梯度下降调节网络权值和阈值的过程,解决BP算法由于梯度下降引起的难题。本研究采用遗传算法对BP神经网络进行优化,遗传算法的初始种群数量为5,遗传代数设为50,交叉概率为0.4%,变异概率为0.05%;种群经优化后BP神经网络输入层节点个数为5,隐含层节点个数为5,输出层节点个数为1,最大迭代次数为1 000,训练目标为1×10-6。
1.6 模型精度验证
(1)模型评价指标
模型拟合结果采用决定系数(R2)、均方根误差(RMSE)、标准均方根误差(NRMSE)与平均相对误差(MRE)进行评价[34-35],R2越接近1,说明模型的预测精度越高;RMSE与MRE越小,说明模型的性能更稳定,预测结果也更为集中,NRMSE小于10%时,模型的预测值与实测值的一致性表现为极好;NRMSE为10%~20%时,模型的预测值与实测值的一致性表现为较好;NRMSE为20%~30%时,模型的预测值与实测值的一致性表现为一般;NRMSE大于30%时,模型的预测值与实测值的一致性表现为较差。
(2)显著性检验
参考自相关性系数检验表,当自由度(即样本量)为66,相关系数大于0.310,达到极显著相关水平(P<0.01);当自由度为44,相关系数大于0.376,达到极显著相关水平(P<0.01);当自由度为22时,相关系数大于0.515,达到极显著相关水平(P<0.01)。
2 结果与分析
2.1 0~2阶微分光谱曲线
本研究采用FOD算法对原始高光谱反射率数据进行0~2阶(步长0.5)分数阶微分变换处理,图2为平均后的各阶高光谱反射率曲线。大豆原始高光谱反射率曲线呈现出典型的绿色植物反射特征,在绿光波段550 nm左右有1个明显的反射峰,这是因为植物对于绿光具有较强的反射作用;由于植物对红光的强吸收性,反射率曲线在红光波段680 nm左右出现了1个吸收谷;在波段 680~760 nm 光谱反射率急增,出现一段反射陡坡,形成了绿色植被特有的光谱特征——红边。由于植被含水率的影响,1 300~1 830 nm光谱反射率快速下降,1 400 nm 左右出现了水汽波段的吸收峰。分数阶微分处理可降低光谱反射率噪声,突出反射率曲线中的细微变化,并保留植物的光谱特征,随着微分阶数增加,各波段对应的光谱反射率渐趋于0,标准差也逐渐减小,红边特征波段在各阶反射率曲线中均具有较高的反射率。

图2 0~2阶微分光谱反射率曲线
2.2 光谱指数构建与最优光谱指数波段组合提取
为更充分地利用高光谱反射率数据所含信息,选取了7个典型光谱指数。首先对0~2阶分数阶微分处理后的高光谱反射率的所有波段进行逐波段光谱指数计算,再通过相关矩阵法与大豆LAI进行相关性分析,以最大相关系数所在的i和j波长进行不同阶光谱指数构建,并在7个光谱指数中选取与大豆LAI相关性最高的5个指数作为最优光谱指数组合。绘制相关性矩阵图,如图3~6所示,从蓝到红表示光谱指数与大豆LAI的相关性由高负相关到高正相关。

图5 0~2阶微分下NDVI、mSR与开花期大豆LAI相关矩阵图

图6 0~2阶微分下mNDI与开花期大豆LAI相关矩阵图
图3~6为经分数阶微分处理,0~2阶分数阶微分高光谱植被指数与大豆LAI的相关矩阵图,各阶光谱指数大豆LAI的相关系数均大于0.310(P≤0.01),达到极显著相关水平,说明本研究选取的7个光谱指数均可用于预测开花期大豆LAI。0~2 阶光谱指数与大豆LAI相关系数的平均值分别0.616、0.657、0.666、0.669、0.658,分数阶微分处理后计算得出的最优光谱指数与大豆LAI的相关性与原始光谱指数相比得到显著提高。1.5阶微分处理下,与大豆LAI相关系数最高的是TVI,相关系数为0.755,波长组合坐标为(687 nm,754 nm),各光谱指数与大豆LAI的相关系数由高到低排列为:
TVI、DI、SAVI、RI、NDVI、mNDI、mSR。在上述7个光谱指数中选取5个相关系数最高的光谱指数TVI、DI、SAVI、RI、NDVI作为最优光谱指数组合,其对应波段组合:(687 nm,754 nm)、(687 nm,754 nm)、(728 nm,738 nm)、(687 nm,744 nm)、(620 nm,653 nm)为最优光谱指数波段组合。其余分数阶微分最优光谱指数组合与最优光谱指数组合对应波段见表3。

表3 不同微分阶数下的最优光谱指数波长组合
2.3 大豆LAI预测模型构建与比较
以提取出的各阶最优光谱指数组合作为自变量,以大豆LAI作为响应变量,分别采用SVM、RF、GA-BP构建大豆开花结荚期LAI估算模型,从R2、RMSE、MRE 3方面综合评定模型精度,不同建模方法对于大豆叶面积的预测结果如表4、图7所示。

图7 模型评价结果
结果表明:不同阶微分变换处理下大豆LAI估算模型R2从大到小依次为1.5阶、2阶、1阶、0.5阶、0阶;RMSE、NRMSE与MRE从小到大均依次为:1.5阶、2阶、1阶、0.5阶、0阶。1.5阶微分光谱指数构建的SVM、RF、GA-BP大豆LAI预测模型的验证集R2分别为:0.776、0.880、0.846,均高于0.515,达到极显著相关水平,具有良好的线性拟合效果;NRMSE介于10%~20%之间,3种模型的预测值与实测值之间的一致性呈较好水平。同阶微分变换处理下,3种建模方法构建的大豆LAI估算模型的建模集与验证集精度从大到小依次为RF、GA-BP、SVM。各阶微分处理下,基于RF构建的大豆LAI预测模型验证集R2较SVM与GA-BP提高0.047~0.133;NRMSE与MRE分别降低0.704~8.042个百分点与0.781~7.35个百分点。综上所述,1.5阶微分处理与RF方法分别为本研究中的最优微分阶数与最优模型构建方法,由此构建的最优大豆LAI估算模型建模集与验证集的R2为0.890与0.880,RMSE分别为0.348 cm2/cm2与0.320 cm2/cm2,NRMSE分别为11.278%与10.354%,MRE分别为9.795%与9.572%。
3 讨论
目前,在利用高光谱反射率数据进行LAI反演模型构建的研究中发现直接运用原始高光谱反射率对于作物LAI进行反演模型构建得到的模型精度往往较差[36]。引入微分变换处理,可以削弱光谱反射率背景噪声,突出高光谱特征信息,增强高光谱反射率与作物LAI间的相关性进而促进反演模型精度的提升[37-38]。本研究对高光谱反射率数据进行0~2阶分数阶微分处理(步长0.5)构建大豆LAI反演模型,随着微分阶数的提高,光谱指数与大豆LAI的相关性与模型精度均呈现出先升后降的趋势,1.5阶微分下最优光谱指数与大豆LAI相关性及其构建的预测模型精度均高于1阶与2阶整数微分。这是因为分数阶微分是高光谱反射率整数阶微分变换的拓展与延伸,可以提取整数阶微分无法表征的渐变性信息[39]。但是随着微分阶数提高,背景噪声被逐渐削弱,高频噪声会被逐渐放大,也减少了反射率数据中的潜在敏感信息,导致了光谱信息信噪比的降低,继而影响模型精度[40]。本研究发现在全波段范围内筛选波段构建的最优光谱指数包含了更多与大豆LAI相关的有效信息,且构建的25个0~2阶最优光谱指数中的23个指数所对应的波段分布在红边或近红外波段。叶绿素对红光波段的强吸收和近红外波段在叶片内部发生的强反射使得红边波段成为绿色植物反射率增长最快速也是最能反映植物生长生理特征的重要指示波段,80%以上的植物理化参数都可以从红边波段所包含的光谱信息中找到映射[41-42]。分数阶微分处理在过滤背景噪声的同时,也保留了红边波段对于植物理化参数的描述能力,因此本研究中各阶微分处理下筛选出的与大豆LAI呈极显著相关关系的波段组合多分布于680~760 nm范围内,与前人研究结果相符[43]。
本研究以选出的各阶最优光谱指数组合作为输入数据,选用SVM、RF、GA-BP共3种机器学习方法进行LAI预测模型的构建。3种方法中,基于RF方法构建的LAI预测模型精度最高,说明RF提取光谱反射率数据中LAI相关信息的能力更强,这是因为RF算法具有较强的抗干扰与抗过拟合能力,对背景噪声与异常值的容忍性也更高,更适合解决一些非线性问题[44],陈晓凯等[45]对冬小麦LAI进行反演时也得到了相同的结果。BP神经网络是一种按误差逆传播算法训练的监督式学习方法,也是当前应用最广泛的非线性多层前馈网络模型之一,但神经网络模型精度也因容易陷入局部极值且收敛速度较慢的缺点[46]受到了限制。遗传算法可对BP人工神经网络的初始权值和阈值进行优化,提高网络的收敛速度与识别精度[47]。本研究中GA-BP模型精度低于RF,可能是因为样本相对较少但模型训练次数较高,导致了模型精度与泛化能力的降低[48]。与RF和GA-BP相比,SVM模型对于LAI的预测效果较差,推测是因为SVM抗干扰性较弱且受到核函数与惩罚因子等参数选择的限制[49]。
当前,利用高光谱数据对作物的LAI、生物量、氮素、叶绿素的模型研究取得了很好的效果,但常用的地面高光谱数据一般只能在地面进行获取,受限制条件较多。本研究结果表明以1.5阶最优光谱指数组合作为输入变量,采用RF构建LAI预测模型可以得出最佳的拟合精度,今后需要通过不同地区、不同尺度和不同品种类型的试验对模型进行检验和改进,实现模型估测精确性和普适性的有效统一,为使用多光谱和无人机高光谱等多源遥感手段预测多生育期大豆LAI与进一步探索高光谱反射率分数阶微分变换提供参考。
4 结论
(1)与原始高光谱反射率数据相比,分数阶微分变换后提取出的各阶最优光谱指数与大豆LAI的相关性得到显著提高,1.5阶处理下各光谱指数与大豆LAI相关系数的平均值较原始光谱指数提高0.053,其中TVI(687 nm,754 nm)表现出最高的相关性,相关系数为0.755。
(2)当建模方法相同,输入变量不同时,大豆LAI预测模型的精度从大到小依次为:1.5阶、2阶、1阶、0.5阶、原始阶位;当输入变量相同,建模方法变化时,大豆LAI预测模型的精度从大到小依次为:RF、GA-BP、SVM。综合比较模型的评价指标可知1.5阶微分与RF方法分别为本研究中的最优微分阶数与最优模型构建方法,由此构建的最优大豆LAI估算模型建模集与验证集的R2分别为0.890与0.880,RMSE分别为0.348 cm2/cm2与0.320 cm2/cm2,NRMSE分别为11.278%与10.354%,MRE分别为9.795%与9.572%。
猜你喜欢
印制电路信息(2022年11期)2022-11-30
海洋通报(2022年4期)2022-10-10
光谱学与光谱分析(2022年4期)2022-04-06
数学物理学报(2021年2期)2021-06-09
数学物理学报(2019年5期)2019-11-29
电子器件(2017年2期)2017-04-25
广东技术师范大学学报(2016年5期)2016-08-22
高师理科学刊(2016年8期)2016-06-15
西藏科技(2015年4期)2015-09-26
哈尔滨师范大学自然科学学报(2015年1期)2015-04-19
