
一种联合空间约束与差异特征聚合的变化检测网络
2023-10-13 12:17韦春桃周永绪
测绘学报 2023年9期
韦春桃,龚 成,周永绪
重庆交通大学智慧城市学院,重庆 400074
变化检测是通过识别变化像素及未变化像素来判断同一区域在不同时相影像中的差异,在异常监测[1]、城市发展监测[2]及土地利用[3]等领域中被广泛应用。复杂场景下地物类型混杂交错,自然、人文、生态要素相互作用造成了土地覆被/利用的时空分异,并有很强的尺度依赖性[4],这种分异导致具有相同属性的地物要素在多时序影像中存在着光照、位置及噪声等差异,这对模型的稳健性及抗干扰能力提出了更高要求。
传统遥感领域变化检测方法大多利用遥感影像的低层次特征[5]进行变化类别判断,包括基于代数的方法[6]、基于图像变换的方法[7]、基于图像分类的方法[8]及基于机器学习的方法等[9]。这类利用光谱或数据本身的物理特性进行统计分析得出变化类别的方法通常需要使用阈值来区分变化区域和非变化区域,定义一个适当的决策函数来判别目标区域变化至关重要,因此,很难适用于复杂的检测场景。深度学习是摄影测量和遥感图像处理的新趋势[10]。经试验发现,基于深度学习的变化检测算法与传统方法相比有更好的检测性能,可自动地学习变化特征,能够克服传统方法中稳健性差、特征提取能力差等缺陷[11]。
遥感影像变化检测需要利用堆叠的卷积模块对单个像素进行密集预测,卷积神经网络能够同时提取出包含空间位置的低层特征及包含抽象语义的深层特征,满足复杂场景的检测需要[12]。因此,一系列端到端的网络模型被提出以实现图像像元级预测任务[13-18]。IFN[19]通过深监督和注意力机制提高了输出变化图像中信息的完整性。STANet[20]利用自注意力机制构建双时影像空间距离依赖,并提出批权重对原有对比损失的类权重进行修正。类似地,DSAMNet[21]中使用了度量模块,通过深度度量学习来生成变化图。文献[22]提出多尺度变化特征逐级融合模块来控制信息传播以减少特征融合时的差异性。文献[23]提出使用变化图像选择器识别“查询”变化图像,并通过构建先验图生成器辅助实现多尺度变化检测。CDFormer通过引入多头自注意机制(MHSA)提取联合加权空间-光谱-时间特征以提高监督效率[24]。MFATNet提出空间语义标记器引导Transformer结构学习关键区域之间的关系[25]。MAEANet[26]将判别边缘信息和先验边缘信息结合到模型中,以优化网络对于建筑物变化检测成果的质量。
然而,常用方法在编码解码的训练过程中,浅层特征由于映射不足,缺少对变化像素进行判别的决策性信息;另一方面,深层特征的空间信息在下采样的过程中不断丢失,导致像素在解码过程发生位置跃迁、生成伪变化等问题。训练后期针对多尺度特征进行融合,虽然能够简单有效地使较低层次特征被赋予更多的判别线索[27],但在深层特征进行传递的过程中,其所包含的显著视觉语义信息由于通道数的减少逐渐淡化,不利于上下文信息的充分利用[28]。
基于此,本文提出一种联合空间约束与差异特征聚合的变化检测网络,利用孪生网络结合特征金字塔结构[29],提取不同时相影像的差异信息,作为全局判别特征,兼顾复杂场景中对多尺度目标的检测所需。在特征金字塔自顶而下的结构中,本文提出一种差异特征聚合模块,根据不同尺度特征的语义优势,强化深层特征中的判别信息,编码浅层特征中的全局依赖关系以进行空间信息约束。最后,利用门控融合机制捕获多尺度特征的通道域关系以对原始特征进行矫正,并将其上采样到原始图像大小进行变化图像生成。
1 联合空间约束与差异特征聚合的变化检测网络
为关注变化检测后期异构特征融合的问题,本文设计了一种差异特征聚合网络,包括特征提取、差异特征聚合模块及门控融合模块3个部分(图1)。结构如图1(a)所示,其中ConvBlock表示堆叠的3×3卷积模块(图1(b)),Up表示双线性上采样,C表示通道级联操作,Feat1、Feat2、Feat3及Feat4分别表示不同尺度的特征图,CBAM和CSAM分别代表两种不同的注意力机制,Gate表示门控融合单元。

图1 网络结构Fig.1 Network structure
1.1 整体结构
本文提出的网络模型是一种基于特征金字塔的后期特征融合网络,主要利用孪生结构提取双时影像的差异特征,这是由两个分支网络构成的一种耦合架构[30]。在特征金字塔自下而上的提取路径中,为了优化模型性能,减少模型复杂度,本文在编码器部分采用ResNet-34残差网络对差异特征进行提取,它主要包括4个卷积模块,每个卷积模块分别包含了卷积核大小为3×3的4个卷积层。计算相同层级输出的绝对值作为差异图像Fabs=|T1i-T2i|,i=1,2,3,4。
为了强化浅层特征中的空间信息及深层特征中的判别信息,本文提出了一种多尺度的差异特征聚合模块,利用CBAM[31]捕捉深层特征(Feat1、Feat2)中的通道及空间信息,强化模型的学习能力;利用本文提出的CSAM对浅层特征(Feat3、Feat4)进行全局空间信息约束,强化边缘细节及精确位置信息,并抑制光照差异、季节交替等无关变化带来的干扰。最后,将融合特征输入门控融合单元,进行特征内的通道自适应选择,构建多尺度特征之间的互补趋势,以生成高精度变化图像。
本文采用二元交叉熵损失作为整个模型的损失函数,使得模型可以快速收敛

yilnpi]
(1)
式中,yi是真实标签;pi表示预测为变化类别的概率;N表示样本的数量。
1.2 差异特征聚合模块
传统检测模型将深、浅特征直接拼接或求和以丰富特征信息,但此方法忽视了不同层级特征之间的差异性。本文提出差异特征聚合模块,在该模块中,利用两种不同注意力机制捕捉深、浅特征中的显著语义信息,为不同尺度特征有效融合提供基础。
1.2.1 坐标自注意力机制
在遥感变化检测任务中,离散的检测对象易在尺度空间中产生随机性变化,通常使用注意力机制强化“感兴趣”特征的学习。常用注意力对全局空间信息进行压缩以编码通道特征,难以保存位置信息;通过在通道域进行全局池化引入位置信息,这种方式只能捕获局部空间特征,而无法对全局特征关系进行约束。CA[18]通过嵌入位置信息到通道注意力中捕捉长距离依赖关系,但在复杂场景中,因其体量较小,常表现出性能不足。在此动机的驱动下,本文引入Self-Attention[32]的思想,设计了一种坐标自注意力机制,主要包括生成坐标注意力及构建全局空间约束两个步骤,通过分解通道特征为两个并行的1维特征高效地整合变化特征中的空间坐标信息到注意力特征中,然后利用Transformer结构对坐标特征进行编码,以挖掘变化像素间更深层次的全局空间依赖关系,进一步约束特征信息在尺度空间中的表达,以赋予微小型检测对象更多关注,实现细粒度变化影像重建,其结构如图2所示。

图2 坐标自注意力机制Fig.2 Coordinate self-attention module
首先,使用尺寸为(H,1)和(1,W)的池化核分别沿水平坐标及垂直坐标方向对输入特征的精确位置信息进行编码,从两个不同维度生成具备方向感知的注意力特征Zh、Zw;其次,将两种变换进行通道维度的级联,使用1×1卷积进行融合,将跨通道关系嵌入特征信息中;然后,将特征图分解为两个单独的张量fh、fw;最后,通过卷积变换及激活函数生成两个权重,将两个权重相乘实现加权操作,以提取要素坐标信息
f=δ(Conv([Zh,Zw]))
(2)
Z=σ(Fh(fh))×σ(Fw(fw))
(3)
式中,δ是非线性激活函数;Conv是1×1卷积函数;σ是Sigmoid激活函数;Fh、Fw代表两个方向上的1×1卷积操作。
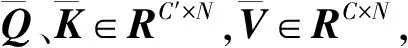
(4)
(5)
(6)
1.2.2 卷积注意力模块
为了强化深层特征中重要的判别信息,本文引入了经典的CBAM模块捕捉深层特征中的重要判别信息,抑制非变化信息带来的干扰,CBAM包括两个子模块,特征信息依次通过通道注意力模块以及空间注意力模块以获得强化,如图3所示。

图3 卷积注意力机制Fig.3 Convolutional attention mechanism
1.3 门控融合机制
由特征金字塔输出多尺度特征需要经过连续上采样及通道降维操作以融合生成变化图像,直接融合多尺度特征会受到尺度差异及语义区别的影响,导致判别信息丢失或是变化目标偏移等情况出现,不利于影像重建及模型判别。本文提出了一种适用于多尺度特征的门控融合模块,使用前馈传播的方式整合多尺度信息,通过构建融合后多尺度特征之间的通道内联关系,并将此作为残差特征对原始特征进行矫正,以抑制无关变化信息的表达及深、浅层特征中的语义鸿沟和定位差异带来的影响,如图4所示。首先,对于不同注意力机制增强后的特征图像使用1×1卷积、双线性插值将通道、尺寸及大小统一到与Feat4一致,对统一后的多尺度特征进行求和,利用通道注意力模块对融合后特征进行组内通道域的自适应选择,并将其还原至4倍通道数大小以便于与原始特征相乘形成多尺度通道注意力特征。然后,将所捕获到的特征添加到原始特征中。最后,利用卷积模块消除降维过程中的混叠效应,并输出模型所预测的变化图像

图4 门控融合机制Fig.4 Gated fusion module
Xconcat=[X1,X2,X3,X4]
(7)
Xsum=X1+X2+X3+X4
(8)
Gate(X1,X2,X3,X4)=Cov[Xconcat(1+
CAM(Xsum)×4)]
(9)
2 试 验
2.1 试验设计
为了验证所提出方法在不同场景下进行变化检测任务中的有效性,本文在两个公开的大尺度开源数据集上进行了试验,分别是CDD[33]季节变化数据集及LEVIR-CD[20]建筑物变化检测数据集,并与其他先进方法进行比较,对于所提出的模块结构进行消融试验以验证其贡献性。
2.1.1 试验环境
本文利用大尺度遥感影像变换检测数据集CDD和LEVIR-CD作为训练、验证样本对所提出模型进行评估,其试验参数设置学习率为2×10-3,设置训练迭代次数为100,使用二元交叉熵作为损失函数并使用Adam优化器进行优化。为了丰富样本数据多样性,本文对训练样本进行了随机翻转、旋转、平移及图像归一化等图像增强处理。试验基于Windows系统的PyTorch深度学习框架,硬件环境为Nvidia GeForce GTX1080ti显卡。
2.1.2 试验数据
文献[33]通过对CDD数据集中7对大小为4725×2200像素的季节变化图像进行裁剪和旋转处理原始图像数据,生成了10 000张训练数据、3000张验证数据和3000张测试数据,其中图像数据大小为256×256像素,空间分辨率为3~100 cm,部分数据如图5所示。

图5 CDD数据集示例图像Fig.5 Example image of CDD dataset
LEVIR-CD[20]数据集收集了2002—2018年间美国得克萨斯州20个不同区域的遥感影像。具有637张大小为1024×1024像素的影像对,空间分辨率为50 cm。本文将每一个样本裁剪为16张大小为256×256像素的图像块进行训练,部分数据如图6所示。

图6 LEVIR-CD数据集示例图像Fig.6 Example image of LEVIR-CD dataset
2.1.3 评价指标
为了验证本文提出方法的有效性,试验采用了5种不同的指标,即总体准确率(overall accuracy,OA)、精确率(Precision)、召回率(Recall)、F1值(F1score)及IoU(intersection over union)。具体地,精确率反映了模型检测误报情况,召回率反映了模型的漏报情况,F1值反映了精确率和召回率的整体水平,IoU表示模型输出预测图片与实际变化图片之间的重叠率,其中精确率、召回率及F1值最能反映模型的检测性能,如式(10)—式(14)所示,TP表示预测正确的正样本数,FP表示预测错误的正样本数,TN表示预测正确的负样本数,FN表示预测错误的负样本数
(10)
(11)
(12)
(13)
(14)
2.2 遥感图像变化检测试验
为验证本文方法的有效性,对本文方法与其他先进变化检测方法进行了对比,FC-EF[15]、FC-Siam-conc[15]及FC-Siam-diff[15]是3种U形的全卷积神经网络,其中后两种是基于孪生神经网络的拓展。IFN[19]是一种基于U形结构的网络模型,利用多层深度监督机制对影像特征进行判别。CDNet[34]将两个不同时相图像拼接为一张输入图像,然后输入全卷积网络以实现变化特征提取。STANet[20]通过构建不同时相影像的时空依赖性,抑制遥感影像光照变化以及配准误差带来的误检问题。
2.2.1 在CDD数据集中的试验对比
表1展示了本文方法与上述先进方法在CDD数据上的各项评估指标情况,其中本文方法在各项指标中均取得了最佳的表现,相比于IFN在Recall和F1值中分别提高了2.18%、1.14%,这说明本文方法能够更加准确地识别变化类别,对于实际应用任务有着重大意义。

表1 在CDD数据集中的评价指标对比
图7展示了不同方法在CDD测试集不同尺度场景下的可视化结果,在(1)中,该场景受季节变化干扰较大, 本文方法比其他方法保留了更多林地变化区域的边缘细节。在(2)中,CDNet、IFN、FC-Siam-conc丢失了入户小路的部分信息,FC-Siam-conc、STANet对道路上的车辆进行了错误检测,而本文方法能够准确提取所有车辆,并还原其之间的空间关系。在(4)中,墙体和建筑物本身的连通关系复杂,CDNet对于主体和边缘信息丢失严重,IFN对墙体进行伪变化的生成,FC-Siam-conc及STANet无法对墙体及建筑物主体之间的空间关系进行准确判断,而本文方法在该复杂场景中表现出了显著的优越性,主要是依靠所提出的CSAM模块对细粒度空间信息进行强化,能够对复杂地物场景边缘及内部变化进行精确定位。

图7 在CDD测试集中不同方法的可视化结果Fig.7 Visualization results of different methods in the CDD test set
2.2.2 在LEVIR-CD数据中试验对比
表2展示了本文方法与其他方法在LEVIR-CD数据中性能表现,在所有使用的评估指标中,除了召回率略低于STANet,其余指标均优于其他先进方法,STANet将多层特征上采样至输入图像1/4大小并进行融合作为输入特征提取出双时影像的时空关系,一定程度上提高了模型的召回率,但同时加大了模型负担并造成了一定的精度损失。

表2 在LEVIR-CD数据集中的评价指标对比
图8展示了不同方法在LEVIR-CD测试集中不同尺度场景下可视化结果,可以看出本文方法较其他方法在复杂场景的检测中更具优势。在(1)中,IFN在建筑物内部出现断裂,STANet缺失了对于小目标墙体的检测,而本文方法检测结果更加完整。在(3)中,其余方法均出现了“假阳性”的现象,将无关变化误识别为建筑物变化,而本文方法利用CSAM模块对低层变化语义信息进行空间约束,有效保留了较小目标的高精度稳健特征,并利用门控机制整合深度语义特征,消除无关变化带来的影响。

图8 在LEVIR-CD测试集中不同方法的可视化结果Fig.8 Visualization results of different methods in the LEVIR-CD test set
2.2.3 模块间的消融试验
本小结针对所提出的CSAM模块及门控融合模块进行了消融试验,所有的比较均使用相同的超参数设置。本文所使用的基线网络为去除差异特征聚合模块中的CSAM及门控融合模块,将特征直接融合并进行通道降维的网络。在差异特征聚合模块中,本文分别使用了所提出的CSAM及传统的CA模块进行对比,以验证所提出CSAM机制的先进性,结果如表3所示。

表3 在CDD数据集中的消融试验评价指标对比
由表3中可知,所提出CSAM模块对于模型性能的提升明显,精度提高了2.66%,召回率提高了5.9%,F1提高了4.34%。所提出的门控单元对于模型在各评价指标中的表现也均有提高。特别地,笔者对于常用的CA模块与本文所提出的CSAM模块进行比较,召回率提高了1.23%,F1值提高了0.69%,这说明了构建空间特征约束对于变化检测任务的有效性。
图9可视化了模块间消融试验的结果。在(2)中,Base+CSAM显示了CSAM模块能够较为准确地判断出变化区域的空间位置,但丢失了细节信息,而本文方法使用了门控融合单元补充了边缘信息,对特征影像中的错误预测进行纠正。(3)中,Baseline方法未能正确识别被雪覆盖后的未变化区域,其余两种方法均对于变化区域内部连通性进行了错误的判断,而本文方法能够较为准确地判断变化区域之间的空间关系,这可归结于CSAM模块通过建立要素的全局依赖提高内部一致性,帮助特征判别以及图像重建,减少预测结果中的误判现象。

图9 在CDD测试集中进行消融试验可视化结果Fig.9 Visualizing results of ablation experiments on CDD test set
3 总 结
本文提出了一种面向复杂场景变化检测的空间约束与差异特征聚合网络,使用权重共享的孪生双分支结构对变化影像进行差异特征提取,采用特征金字塔结构生成多尺度的差异特征,利用所提出的特征聚合模块对不同尺度特征进行语义强化,构建低层特征空间约束以细化目标边界,并通过门控融合单元进行语义筛选,形成多尺度特征信息的互补趋势。本文方法对不同尺度变化具有较高稳健性,能够精确判断变化区域的空间关系,在复杂场景的变化检测任务中具有较高的检测精度,在实际生产具有一定的应用价值。通过观察LEVIR-CD数据集中的测试结果发现,在检测目标尺度较小的任务中,本文所提出的模型仍会出现少量漏检的情况,可能是因为低分辨率的小目标可视化信息少,难以提取到具有鉴别力的特征,同时,所采用的特征金字塔结构在不断下采样的路径中,过小目标的判别语义信息容易丢失,导致模型检测失效,未来将进一步探究其原因并进行模型优化。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2021年9期)2021-11-02
河北地质(2021年1期)2021-07-21
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
中国生物医学工程学报(2019年5期)2019-07-16
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中南林业科技大学学报(2017年12期)2017-12-19
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
