
基于两次字典裁剪的高光谱稀疏解混方法
2023-10-18 13:32张子龙阎庚未
科技创新与应用 2023年29期
张子龙,沈 珣,阎庚未
(1.中国航空工业空气动力研究院,哈尔滨 150001;2.低速高雷诺数航空科技重点实验室,哈尔滨 150001;3.南京航空航天大学,南京 210016)
高光谱图像包含大量的混合像素,这极大地阻碍了对高光谱图像信息的进一步探索[1]。高光谱解混是解决这一问题的一种非常有效且常规的方法。而高光谱解混过程一般包括端成员提取和丰度反演2 个步骤[2]。由于高光谱图像包含的端元很少,一个像素通常不包含整个图像的所有端元,该像素的许多丰度值为零,因此可以在光谱库下得到的丰度系数是稀疏的,这是丰度的稀疏性特征。因此可将稀疏模型用于解混中,目前依赖于光谱库的稀疏解混成为最流行的研究课题之一,稀疏解混的目的是在一个大型的光谱库中找到最优的光谱子集,它可以最好地建模高光谱图像中的混合像素。现有的稀疏解混方法有很多,比如,通过变量分裂和增广拉格朗日[3]进行稀疏解混,不需要提取端元来估计丰度。在基于变量分裂和增广拉格朗日算法的稀疏解混(Sparse Unmixing Based On Variable Splitting And Augmented Lagrangian,SUnSAL)算法的基础上添加了空间约束,将全变异(Total Variation,TV)空间正则化项应用于SUnSAL,形成SUnSAL-TV 算法[4-5]。但SUnSAL-TV 对丰度系数缺乏有效的约束。由于光谱库通常具有较高的相互相干性,得到稀疏解仍然是一项具有挑战性的任务。光谱先验信息方法(sparse unmixing using spectral a priori information,SUnSPI)利用高光谱图像中的光谱先验信息来缓解这一问题[6]。近期,通常会对丰度矩阵施加低秩约束,因此提出了JSpBLRU[7]算法,它的原理在于使用了一种新的两次加权策略,两次加权策略可以提高丰度矩阵的稀疏性。
稀疏解混的前提是有一个过完备的光谱库,而最稀疏解的唯一性受到谱库的高相互相干性的严重限制。解决这个问题的一个有效方法是通过字典裁剪,所谓的字典裁剪是通过某些标准删除光谱库中没有目标信息的波段,尽可能准确地保留有用的光谱子集。常用的方法是用来处理传感器阵列处理的多信号分类[8],但是它假设真实的端元特征与字典的光谱特征之间没有不匹配,因此在实践中无法得到良好的解混结果。在此基础上提出了一种鲁棒多信号分类算法(Robust Multiple Signal Classification,RMUSIC)[9]。它提出了一个RMUSIC 公式,其目标是识别接近真实端元特征的光谱特征样本。光谱信息散度(Spectral Information Divergence,SID)、光谱角制图(Spectral Angle Mapping,SAM)2 种光谱匹配方法可用于字典裁剪中,SAM 根据目标光谱与测试光谱之间包含的夹角值来判断2 个光谱波段的相似性[10]。SID 是一种基于信息论的测量2 个光谱之间差值的光谱分类方法[11]。
然而,现如今大部分字典裁剪都只使用一种方法,这将会降低解混的准确性,并可能带来一些错误。因此,我们提出了将SID 和SAM 相减作为两次字典裁剪方法(SS),采用SS 作为字典裁剪的依据,通过两次字典裁剪来尽可能准确地保留有用的光谱子集来表示整个图像。
1 方法
1.1 常见字典裁剪方法
1.1.1 SID
光谱信息散度(SID)是一种基于信息论的方法,是一种用来比较2 个光谱之间的差值的光谱分类方法。设E=[e1,e2,…,eN]、F=[f1,f2,…,fN]分别为目标光谱和测试光谱。这2 个光谱的概率向量为a=[a1,a2,…,aN],b=[b1,b2,…,bN]。其中
可得E关于F的相对熵为
信息熵的数值越大则表示2 条光谱越不相似。
1.1.2 SAM
光谱角匹配法(SAM)根据目标光谱与测试光谱之间的夹角值来判断2 个光谱的相似性。如果2 个光谱之间的角度较小,则它们之间的匹配程度较高。2 个光谱E,F之间的光谱夹角定义为
式中:θ(E,F)是SAM 光谱匹配模型。
1.1.3 RMUSIC
在MUSIC 模型中,它主要研究无噪声的情况。MUSIC 模型定义如下
其中U∈m×s为包含高光谱图像Y的左s个奇异向量的矩阵表示的是U的正交互补投影结果。然后我们确定对于i=1,…,s,有={k1,…,ks},对所有的都有γMUSI(Uk)i<γMUSI(Uj)。上述操作过程为MUSIC,MUSIC被用来丢弃那些有较大残差的光谱,然后剩下的光谱形成一个更小的子集。
MUSIC 用来丢弃残差大的光谱,剩下的光谱形成一个更小的字典。然而,基于MUSIC 的字典裁剪方法对频谱特征不匹配的问题非常敏感。因此,提出了一种鲁棒多信号分类算法(RMUSIC)公式如下
1.2 本文提出的SS 模型
SAM 只能比较光谱角值的大小,很难区分光谱之间局部特征的差异。因此,SID 可以弥补SAM 的缺点。SID 通过比较信息熵的数值来判断曲线的相似性。信息熵的值越大,2 条光谱曲线就越不相似。根据SID 和SAM 2 种方法的特点,将2 种方法相结合,更准确地识别光谱的相似性,字典裁剪的结果也更加准确。SID 和SAM 的混合方法如下
通过SAM 与SID 作差的方法来进一步筛选掉光谱特征不相匹配的部分,得到更加精准的光谱库子集,能够有效地提高解混精度。
2 实验结果
2.1 评价指标
本文使用的关于实验的评价指标如下所示。
利用均方根误差(root-mean-square error,RMSE)对丰度图En和测试的丰度图进行比较,并将两者之间计算的误差定义为
采用信号重构误差(Signal-to-reconstruction error,SRE)对原始图像X与混合图像X^进行比较,是测量解混精度的指标,定义为
光谱角距离(Spectral angle distance,SAD)用于比较端元签名cn和估计的端元成员签名,它是评估差异的指标,定义为
2.2 模拟数据实验
所有实验都是使用MATLABR 2016 版本进行测试。这2 个实验旨在利用所提出的SS 模型,将SS 模型与SAM、SID、RMUSIC 模型相比较。实验的目的是通过模拟数据实验和真实数据实验来验证SS 模型的优越性,得到基于两次字典裁剪方法能够有效地提高解混精度的结论。
在本次模拟数据实验中,我们所使用的模拟数据数据集是高光谱研究中经常采用的美国地质调查局(USGS)光谱库的第一部分的子集,A∈R224×62,它有224个波段,64 个光谱签名,波长范围为0.4~2.5 μm。
在本实验中,我们的目的是证明在使用模拟数据的情况下,提出的SS 字典裁剪方法在基于联合稀疏块和低秩解混(Sparse Unmixing Based On Joint-Sparse-Blocks And Low-Rank Unmixing,JSpBLRU)中优于其他方法。具体来说,我们使用SAM、SID、RMUSIC、SS 作为字典裁剪方法。我们将这4 种字典裁剪方法用于JSpBLRU 中。此处,我们将列出4 种字典裁剪方法用于JSpBLRU 的结果。
在JSpBLRU 中使用4 种字典裁剪方法得到的RMSE、SRE 和SAD 值在表1 中列出了。使用不同字典裁剪方法的JSpBLRU 的估计丰度如图1(b)—(e)所示。使用不同字典裁剪方法的JSpBLRU 的端元#5 的估计丰度图如图2(b)—(e)所示。
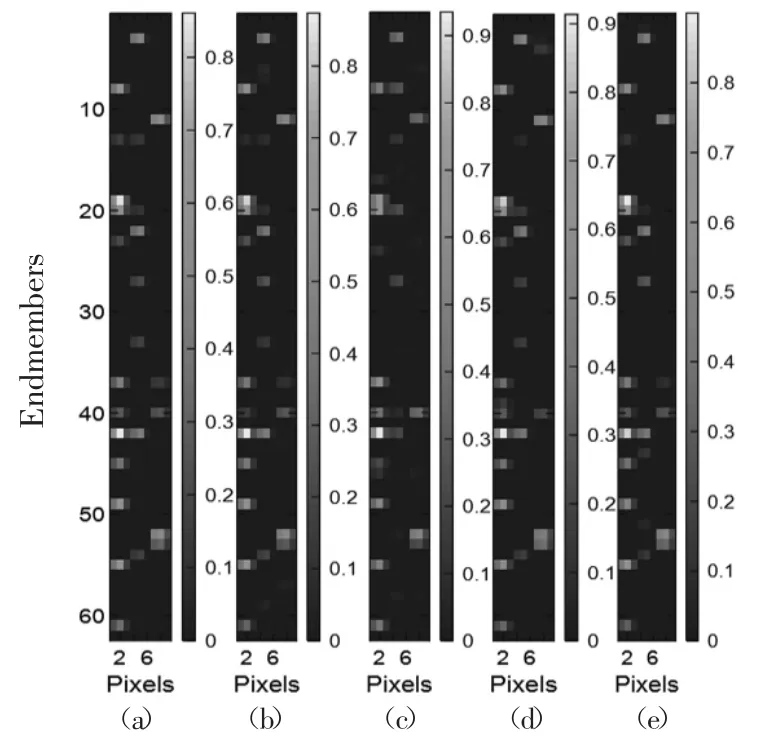
图1 高斯噪声为30dB,JSpBLRU 使用字典裁减的估计丰度矩阵
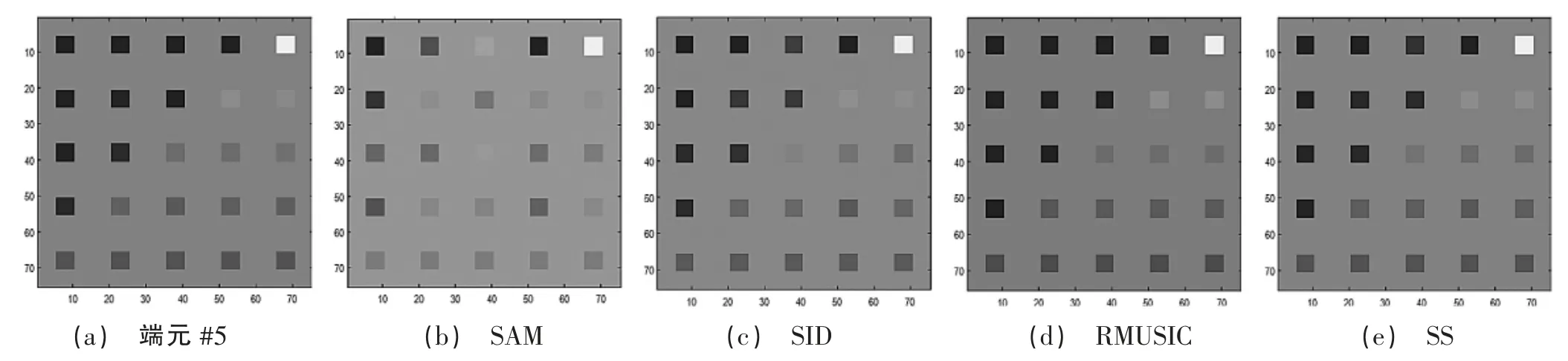
图2 JSpBLRU 使用字典裁减方法对端元#5 的估计丰度图
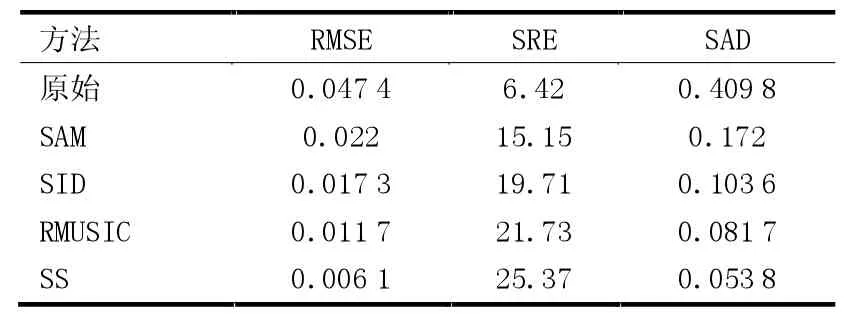
表1 使用模拟数据集的JSpBLRU 通过4 种字典裁剪方法的RMSE、SRE、SAD 值
因为RMSE 是均方根误差,而均方根的值越小表示解混效果越好。SRE 是信号重构误差,它表示解混的精度,SRE 值越大表示解混精度越高。SAD 值越小表示解混效果越好。由表1 可以清楚地看出,综合3 项指标,SS 方法在JSpBLRU 中得到的效果最好。
由图1 可以看出,我们看到SS 方法消除了许多假设为零的低丰度值,降低了解中的自由度,并如预期的那样给出了比较精确的丰度矩阵。
通过不同的字典裁剪方法,端元#5 的估计丰度图如图2 所示。
综合上述的实验过程,从JSpBLRU 的4 种字典裁剪方法的表现可以定量得出使用两次字典裁剪方法比只使用一种字典裁剪方法的效果要好。这验证了所提出的SS 模型的优越性。
2.3 真实数据实验
在这个测试中,我们证明了在著名的空气可见/红外成像光谱仪(AVIRIS)铜数据集上,所提出的SS 字典裁剪方法在高光谱稀疏解混方法JSpBLRU 中的性能优于其他方法。此处列出4 种字典裁剪方法用于JSpBLRU 得到的结果。图3 显示了JSPBLRU 通过4 种字典对Alunite 矿物进行裁剪获得的估计丰度图。从图中可以看到,由上述方法产生的所有估计的丰度图看起来都很相似。然而,与其他字典裁剪方法相比,SS 方法得到的估计丰度图与原丰度图差异最小。

图3 4 种字典裁剪方法估计的Cuprite 子场景的分数丰度图
图3(b)—(e)展示了4 种字典裁剪方法对Alunite的绘图结果,与实际调查结果[12]相比较,可以观察到看出SS 方法得到的估计丰度图比其他几种方法都要好,这与模拟数据实验的结果一致。
3 结论
本文提出了新的基于两次字典裁剪的高光谱稀疏解混方法SS,它融合了SID与SAM方法,通过SAM与SID作差的方法能够更加充分地去除无用的目标信息波段,得到了更精确的光谱库子集,减少了影响解混精度的因素,从而能够有效地得到更准确的解混结果。从实验结果可以看出,与现有的SAM、SID、RMUSIC方法相比,该方法有效地减少了丰度估计的误差,提高了波段选择的精度。该方法对提高高光谱稀疏解混的精度具有非常重要的意义。
猜你喜欢
家教世界(2023年25期)2023-10-09
北京航空航天大学学报(2022年8期)2022-08-31
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
阜阳师范大学学报(自然科学版)(2020年3期)2020-08-13
南京大学学报(数学半年刊)(2020年1期)2020-03-19
小学阅读指南·低年级版(2019年11期)2019-07-01
创新作文(小学版)(2016年19期)2016-08-22
读者(2016年14期)2016-06-29
中国光学(2015年5期)2015-12-09
都市丽人(2015年4期)2015-03-20
