
基于Chipyard的RISC-V处理器设计与实现
2023-11-14 08:05谭飞鸿苏成悦
现代计算机 2023年17期
谭飞鸿,苏成悦
(广东工业大学物理与光电工程学院,广州 510000)
0 引言
在计算机领域,软硬件之间的接口规范就是指令集[1]。RISC-V 是一个自由开放的指令集,具有良好的模块化结构,可用于多种应用场景的芯片定制[2]。国内已涌现大量的基于RISC-V指令集架构的芯片,如平头哥半导体公司研发的应用于物联网的处理器CK902[3]、中国科学院计算机技术所研发的RISC-V 处理器“香山”[4]以及芯来科技研发的广泛应用于嵌入式领域的处理器蜂鸟E203[5]等。Chipyard 是一个基于Chisel开发的处理器生成器框架,它集成芯片从设计到验证的全流程工具链,降低了芯片开发难度,基于Chipyard 框架开发的多款处理器芯片已流片[6]。
本文将在Chipyard 框架下实现基于RISC-V指令集架构的五级流水线处理器设计,并在FPGA 上完成板级验证,Dhrystone测试性能达到1.27 DMIPS/MHz。
1 RISC-V指令集架构及流水线设计
采用增量指令集架构(instruction set architecture,ISA)的计算机体系结构,处理器迭代过程中为保持向后的二进制兼容,ISA 的体量逐渐增大,而RISC-V 采用模块化的方式规避体量问题[7]。RISC-V 基于基本软件栈,提供多个标准扩展,而无需为冗余的指令分摊成本。
1.1 RIISSCC--VV指令集
RISC-V 开发团队于2017 年正式发布第一版规范,规定指令的格式、操作方式、数据类型和内存管理机制等内容[8]。规范凸显RISC-V 的可裁剪性和定制性,实现不同应用场景下的处理器设计需求。RISC-V 指令集由一个基础指令集和多个扩展指令集构成,工作在特定的工作模式下[9]。
最新一版规范规定了五种基础指令集[10],分别是弱内存次序指令集RVWMO、32 为整数指令集RV32I、64 位整数指令集RV64I、128 位整数指令集RV128I 和32 位嵌入式整数指令集RV32E。RVWMO内存一致性模型由内存模型原语、指令依存句法和程序次序组成,并满足加载值公理、原子性公理和进度公理[11]。RV32I、RV64I 和RV128I 都属于整数指令集,区别在于寄存器的位宽大小。RV32E是用于嵌入式设计的指令集,它仅有16个整数寄存器[12]。基础指令集格式一共有六种,以RV32I为例,如图1所示。

图1 RV32I的六种基础指令格式
扩展指令集是RISC-V 灵活性的体现,可与基础指令集组合应对各种应用场景。截至2022年6月,规范共发布40多种扩展指令[10]。
1.2 RIISSCC--VV编译链
编译器将高级编程语言编译成可执行文件,RISC-V 编译链有其独特的函数调用规范(calling convention)[13]。函数调用时规定是否保留寄存器数据,若过程和方法不产生其它调用,将由程序二进制接口(application binary interface,ABI)自由分配寄存器,无需保存和恢复[14]。链接器将目标代码和机器语言模块进行链接,使编译和汇编相互独立进行,节约时间开销。加载器将可执行文件加载到内存中,并跳转至程序执行的开始地址,常用的编译工具有riscv-gnu-toolchain[15]。
1.3 五级流水线设计
流水线技术能使多条指令重叠执行,它将有效提高指令整体执行速度[16]。流水线级数与寄存器的电路延时和硬件面积有关[17]。图2 所示为流水线整体设计图,包括取指(IF)、译码(ID)、执行(EX)、访存(MEM)、写回(WE)。
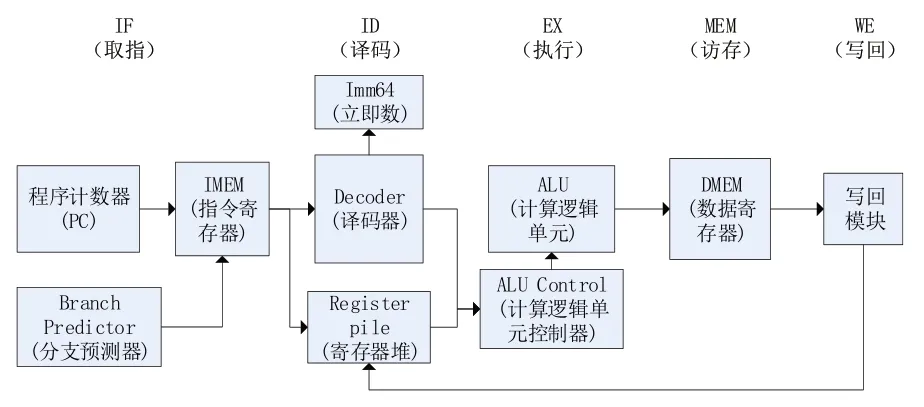
图2 五级流水线总体结构
取指阶段程序计数器(PC)从指令寄存器(IMEM)取出指令,分支预测模块会预测下一条指令;译码阶段将提取指令操作码、功能码、立即数、目的寄存器和源寄存器等信息;执行阶段由ALU 和ALU 控制器执行运算。当指令涉及对内存的读写操作,将进入访存和写回阶段。
2 Chipyard框架
Chipyard 为敏捷的SoC 开发提供统一的框架和工作流程,通过配置和互连多个独立IP 以确保SoC 的完整性[18]。生成的SoC 可以通过FPGA加速和电子设计自动化软件(EDA)进行验证,最后通过可移植的超大规模集成电路(VLSI)设计流程获取GDSⅡ数据库。GDSⅡ是一个二进制文件,用于重构版图信息,以此制作掩模版[19]。
截至2021 年,基于Chipyard 框架开发的已实现流片(Tape Out)的SoC 复杂度呈现出逐年增加的趋势[18],如图3所示。
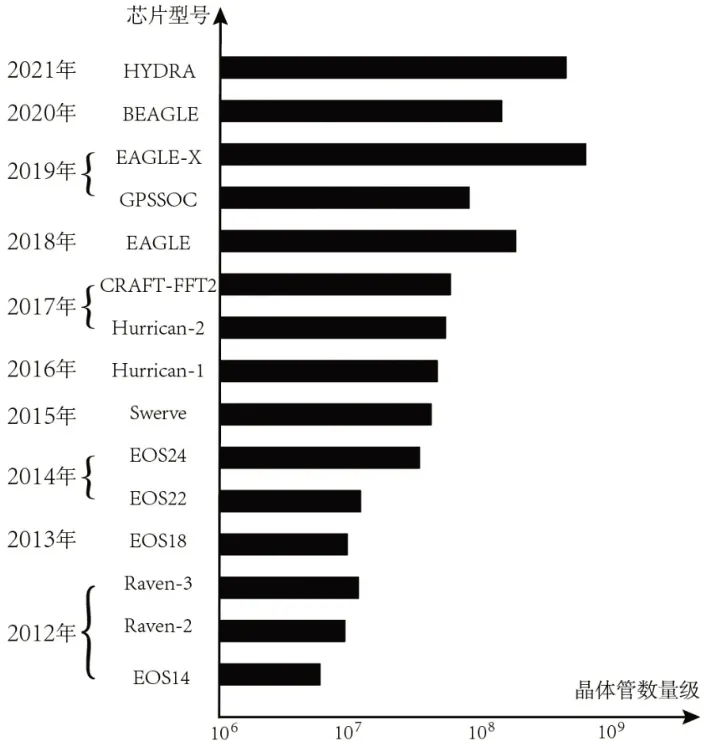
图3 基于Chipyard框架构建的RISC-V SoC测试芯片的复杂度变化趋势
2.1 Chhiisseell敏捷开发
Chisel(constructing hardware in a scala embedded language)采用Scala 作为宿主语言[20],Scala 基于JVM(java virtual machine)开发。传统处理器开发主要基于Verilog 和VHDL 语言,但二者功能复用性差,同等电路设计较Chisel代码更繁琐。Chisel具有面向对象、函数式编程、参数化编程和类型推理的特性[21]。Chisel可进行复杂电路设计,并创建可复用的电路模块,编译成Verilog代码在EDA中进行仿真。
Chisel并不是高层次综合(high-level synthesis,HLS),而是属于寄存器转换级(register transfer level,RTL)语言,而HLS是将行为级描述的高级语言编译成RTL,例如C/C++编写程序,并直接将其转化为Verilog代码[22],这将降低硬件开发的灵活性和颗粒度。处理器开发和迭代过程中涉及大量参数,许多模块可以通过派生、继承和重载来实现,使得基于Chisel开发的优势得以凸显。
2.2 Chippyyaarrdd框架构成
Chipyard 包括可配置、模块化和开源的IP,涵盖SoC 设计阶段全流程。Chipyard 继承于Rocket Chip 框架[23],Rocket Chip 同为伯克利团队基于Chisel 开发的SoC 生成器。Chipyard 在Rocket Chip 基础库上增加大量的IP,比如伯克利乱序机(BOOM)[24]、Hwacha 矢量单元[25]、数字信号处理模块(DSP)、内存系统和外设等。
Chipyard 依赖静态接口用于集成IP 核,硬件生成阶段动态生成编码、内存映射和总线,在内存映射IO(MMIO)外围作为加速器和控制器[26]。在本文的处理器设计中,处理器核由具备Linux 能力的Rocket 核组成,支持RV64GC,拥有浮点单元和虚拟内存。相较其他直接替换内核的SoC 开发框架,Chipyard 的通用内核配置接口提高了开发效率。
2.2.1 Chippyyaarrdd开发流程
Chipyard 框架整合大量工具包,用于SoC 设计周期内的三个主要环节:前端RTL 设计、系统验证和后端芯片物理设计。
由于Chisel 在SoC 设计到实现流程中会缺失原始信息,导致Chipyard 在前端RTL 设计中不能直接生成RTL 文件,所以要通过FIRRTL 作为中间态(IR),再由FIRRTL编译器生成Verilog代码[27]。基于Verilog 或SystemVerilog 的设计框架在仿真、模拟和物理设计之间转换时必须依赖特定的设计脚本,而基于FIRRTL 编译器的转换方法更加灵活,可应用在Chipyard 框架集成的Chisel设计中。
图4展示Chipyard 的开发流程,根据设计需求进行SoC 参数配置,主要包括RISC-V 内核、加速器、Caches、外部设备和自定义模块,通过软件建立RTL 文件工程,并将生成的处理器部署在FPGA 上。Chipyard 拥有开源的RTL 仿真器Verilator,框架中的Makefile 将根据SoC 的结构完成仿真可执行文件和顶层设计文件的生成和软件匹配,并输出测试结果。Chipyard对最终生成的处理器可直接进行FPGA部署,如由亚马逊EC2 公共云推出的FireSim FPGA 加速仿真平台[28],FireSim 可以模拟时序行为、I/O 和外设,配合Chipyard 框架的全系统性可以完成硅前验证和性能评估。Chipyard后端物理设计中支持模块化VLSI 流程,如Hammer VLSI 模块[29],可通过抽象化软件API 生成Tcl 脚本、时钟约束和功率规格对特定供应商的组件进行复用和模块化。
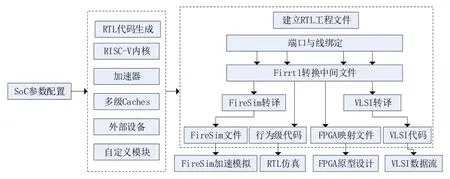
图4 Chipyard通过生成器支持多种转换的设计流程
SoC开发作为计算机科学的重要领域也面临着可重复性危机[30],当一个低级电路需要升级为更高级的电路被应用时,软件栈需要跟踪所有硬件接口并保持版本匹配,这使软件工作负载管理复杂度增加。FireMarshal[31]是基于RISC-V 的全栈硬件开发的软件工作负载管理工具,可实现自动化工作负载生成、开发和评估,通过允许用户以可存储、版本控制、共享无歧义可读形式描述和共享工作负载来使得Chipyard避免重复性危机。如图5所示,全栈式硬件开发组件在系统迭代中会保留大部分原先版本,FireMarshal 使核心应用逻辑和部分组件与新的SoC 设计一致,只改变内核和驱动配置以适应新的系统,这将大大减少SoC设计中的重复性工作。

图5 Chipyard使用FireMarshal进行软件工作负载管理
2.2.2 软核配置
图6 所示为RISC-V SoC 结构设计图,各部分对应代码如下。

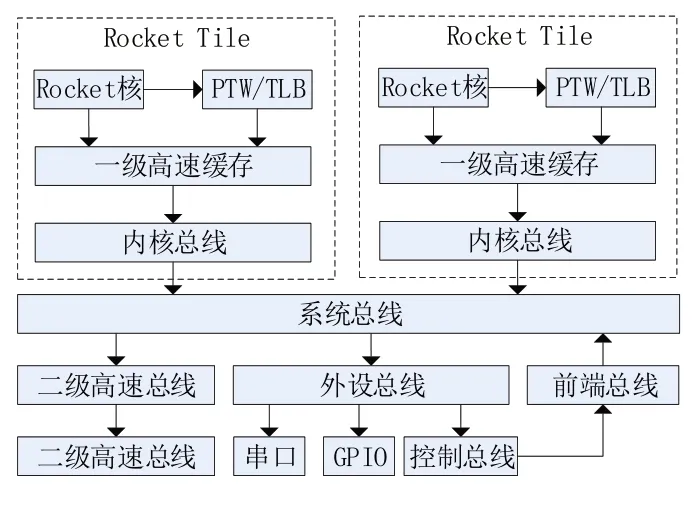
图6 RISC-V SoC结构设计图
Rocket核是顺序执行流水线内核,指令集所需数据可从页表控制器(page table walker,PTW)中获取,PTW 包含虚拟地址和物理地址之间的映射表,虚拟地址在编译时由链接器生成,由页号和页偏移组成,页号用于检索页表得到物理块号,并与页偏移一起载入物理地址寄存器中。内核总线用于一级高速缓存(cache)和系统总线上的设备之间的通信,系统总线(system bus)包括数据总线、地址总线和控制总线。二级高速缓存连接内存总线,内存总线通常是通过AXI 转换器连接DRAM 控制器;外设总线则是连接各个外部设备,包括串口、GPIO 等。CPU 可通过前端总线和外部通信,如内存系统可通过前端总线对DMA设备进行读写。
3 验证测试
Chipyard框架生成的处理器并不以电路图形式呈现,Chisel 进行处理器设计和实现是解耦的,缺少集成环节,故在转换Verilog 代码过程中会损失端口信息,而且在ECO(engineering change order)阶段,Chisel 无法精确控制网表生成,使后端实现需要重新做布局规划(floor plan),而在Firrtl 层面允许设计者自定义转换(transform)[27],所以Chisel 在生成电路图前会先编译成Firrtl文件,进而生成Verilog文件。
图7为Chipyard生成的RISC-V SoC的电路原理图,利用EDA 生成比特流并固化在FPGA 上,部署Linux操作系统,通过网络实现人机交互。存储器管理单元(memory management unit,MMU)是通过快表(translation lookaside buffer,TLB)来实现地址转换[32],Linux 操作系统采用分页式内存管理机制。图8为FPGA板级验证的实物展示。
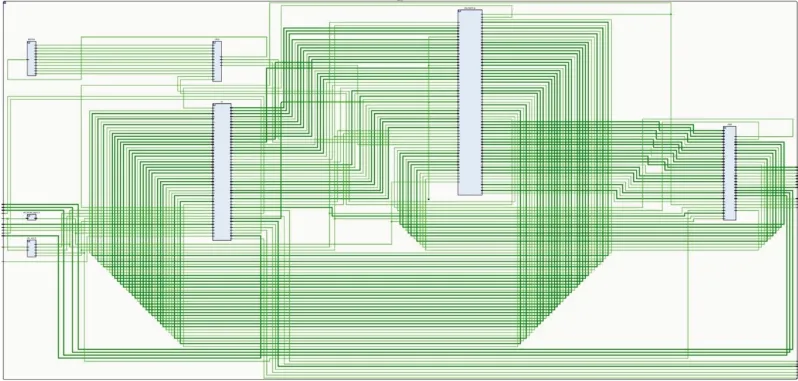
图7 基于Chipyard生成的RISC-V SoC的电路原理图
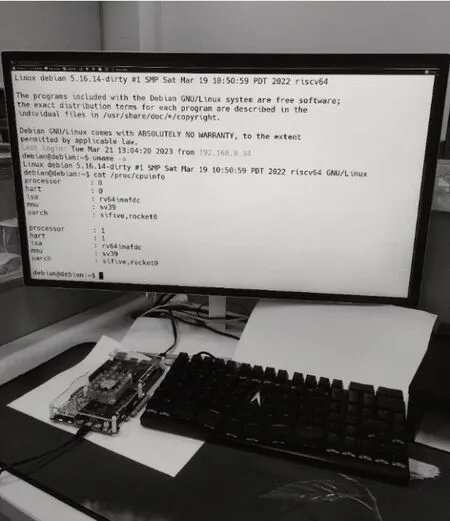
图8 FPGA板级验证实物
Dhrystone 是诞生于1984 年的综合性测试程序,输出结果代表每秒运行Dhrystone的次数,因其简洁、直观,至今依旧被广泛应用于CPU性能测试。图9为RISC-V SoC 的Dhrystone测试结果,结果显示SoC每秒运行2236次Dhrystone程序。

图9 Dhrystones运行结果
4 结语
本文验证了一种高效的RISC-V SoC 开发方法,并在FPGA 上成功运行,Chipyard 支持日益复杂和差异化的定制SoC。从表1 中得出部分处理器对比结果,本文所设计的SoC 的跑分与STM32F407VET6相近,性能优于基于ARM 的第二代树莓派处理器。

表1 各架构典型的处理器Dhrystone跑分比较
猜你喜欢
汉语世界(The World of Chinese)(2023年2期)2023-06-22
电脑报(2021年49期)2021-01-06
计算机应用(2020年5期)2020-06-07
小学科学(学生版)(2020年2期)2020-03-03
单片机与嵌入式系统应用(2017年7期)2017-07-31
电测与仪表(2016年21期)2016-04-11
中国资源综合利用(2016年9期)2016-01-22
中国信息化周报(2014年19期)2014-07-22
自动化博览(2014年6期)2014-02-28
计算机工程(2014年6期)2014-02-28
