
GRU-Transformer 洪水预报模型构建与应用
2023-11-27 06:05李文忠刘成帅胡彩虹解添宁
中国农村水利水电 2023年11期
李文忠,刘成帅,邬 强,胡彩虹,解添宁,田 露
(郑州大学 黄河实验室,河南 郑州 450001)
0 引言
洪涝灾害对人民生命财产安全、社会经济发展等存在着巨大威胁,洪水预报作为重要的防洪减灾非工程措施,其核心在于预报模型构建[1,2]。近年来,机器学习数据驱动技术成为研究热点,其高效的数据并行处理能力可应用于洪水预报领域,并挖掘降雨-径流过程中复杂的非线性关系[3,4]。例如,刘恒等[5]基于神经网络及遗传算法建立了洪水分类预报模型,模型的整体效果优于分类前;李大洋等[6]构建基于变分贝叶斯理论最新算法—随机变分推断SVI(Stochastic Variational Inference,SVI)与LSTM(Long Short-Term Memory,LSTM)耦合的VBLSTM,应用于黄河河源区的径流过程研究,与传统具有物理机制的水文模型相比预报精度更高;XU等[7]提出利用粒子群优化算法(Particle Swarm Optimization,PSO)对LSTM 超参数进行优化,用于汾河静乐流域和洛河卢氏流域的洪水预报任务,提高了LSTM 模型进行洪水预报的精度;崔震等[8]构建了基于概念性水文模型的GR4J(modèle du Génie Ruralà4 paramètres Journalier)与LSTM 的混合模型预报陆水水库的入库流量,结果显示GR4J-LSTM 洪水预报性能优于单个模型。与传统的物理机制水文模型和浅层机器学习模型[9-11]相比,在洪水预报方面,机器学习模型表现出更优越的性能。因此,研究不同机器学习模型在水文预报领域的应用是非常必要的。
2017年提出的Transformer 模型[12]支持并行计算,训练更快,且可以同时建模长期和短期依赖关系,并在处理时间数据序列方面显示出比较好的效果[13,14]。然而,为更好的实现不同任务下的时间序列预测,相关领域学者对其进行了多方面的改进。例如,利用MCST-Transformer[15](Multi-channel Spatiotemporal Transformer)对交通流量的预测、XGB-Transformer(Gradient Boosting Decision Tree transformer)模型[16]被用于电力负荷的预测、Transformer 模型在时间序列预测任务中局部信息不敏感问题的解决[17]和基于Transformer 的双编码器模型对长江月径流量的预测[18]。上述研究结果表明,Transformer 在各个领域的时间序列数据中具有较好的预测能力,也证明了它在水文预报领域同样具有巨大的潜力。但由于Transformer 的编码器和解码器均基于自注意力机制,计算空间复杂度大,对局部信息特征的感知较弱,导致模型易受异常点影响,这是需要进一步考虑优化的问题。
为了使Transformer 模型更好的应用于洪水预报领域,本研究在Transformer 输入部分耦合了预测效果更好的门控循环单元(GRU)层[19],并改进了Transformer模型的结构,构建了GRUTransformer 耦合模型。为探究GRU-Transformer 模型在洪水预报领域中的适用性,以故县水库控制流域为例进行检验,并与ANN和WOA-GRU模型进行对比。
1 GRU-Transformer原理介绍
1.1 GRU
门控制循环单元(Gated Recurrent Unit,GRU)模型与LSTM模型结构相似,同样能够解决传统RNN 存在的梯度消失问题,与LSTM 模型相比,其计算过程更简单、训练参数更少,具有良好的时间序列预测性能。GRU 由更新门和重置门两个门结构构成,其中,更新门的大小代表前一时刻信息的保留程度,以确保前一时刻的信息能够传送到当前时刻;重置门则控制当前时刻与过去的信息间是否结合,即决定多少过去的信息被遗忘,重置门值越小代表被遗忘的信息越多。构建多输入单输出任务的WOA-GRU 模型用于洪水预报,以NSE 为目标函数,采用鲸鱼优化算法(WOA)对GRU模型进行参数率定[20]。
1.2 Transformer
Transformer 模型为基于注意力机制的编码器-解码器架构,原Transformer 模型在进行翻译任务时,需要使用位置编码对数据点序列位置信息进行捕捉,否则会影响翻译结果,并利用Decoder 对编码后的信息进行解码和生成。而洪水时间序列数据是典型的多变量时间序列数据,通过多变量输入对单个流量值进行滚动预测,此任务中位置编码作用性低,且不需要Decoder 结构进行并行计算。因此,为更好的满足洪水预报任务,对原Transformer 模型进行改进,去掉位置编码及解码器部分,且调整模型内部结构,增加卷积层和全局平均池化结构,使用全连接层进行结果输出。
模型采用原Transformer 中的多头缩放点注意力(Multi-Head scaled dot-product Attention,多头注意力)机制;注意力机制可描述为将查询(query,Q)和一组键值对(key-value,K-V)映射到输出,其中输出为value(V)的加权求和,权重取决于由query 和value 的相似性,将h个缩放点注意力的输出进行特征融合做最终输出,每一个注意力的输出称作一个头。图1 为多头缩放点积注意力结构。
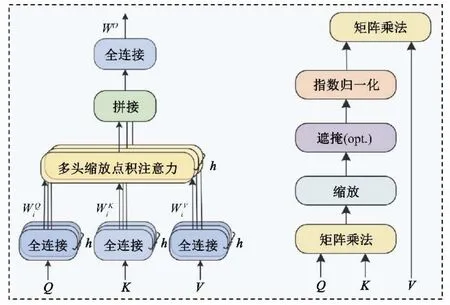
图1 多头缩放点积注意力结构Fig.1 Multiple head scaling point product attention structure
(1)缩放点注意力。
(2)多头缩放点注意力。
其中,WiQ∈Rdmodel×dk,WiK∈Rdmodel×dk,WiV∈Rdmodel×dk,WO∈Rhdv×dmodel,h表示注意力头的数量,设置dk=dmodel/h,d为向量的维度,T表示矩阵的转置。
1.3 GRU-Transformer
在改进的Transformer 模型输入部分耦合GRU 层对时间序列数据进行特征提取,将时间序列数据重构;GRU 层充分利用了当前的数据特征,并使用其门结构来决定是否记住或忘记以前的特征,构建如图2所示的GRU-Transformer 模型。GRUTransformer 模型由具有一层隐藏层的GRU 层、多个编码层和输出层构成,编码层包括多头注意力层、残差和归一化、卷积层,卷积层为两层一维卷积,提取数据深层特征且卷积层通过权值共享和稀疏连接来保证单层卷积中训练参数少,提高前向传播时的效率,并使用Dropout 层防止模型过拟合;输出层采用全局平均池化层对向量化的数据全局平均池化,将多维的输入一维化,之后经全连接层输出,最后与GRU 层进行向量拼接并经全连接层做最终输出。
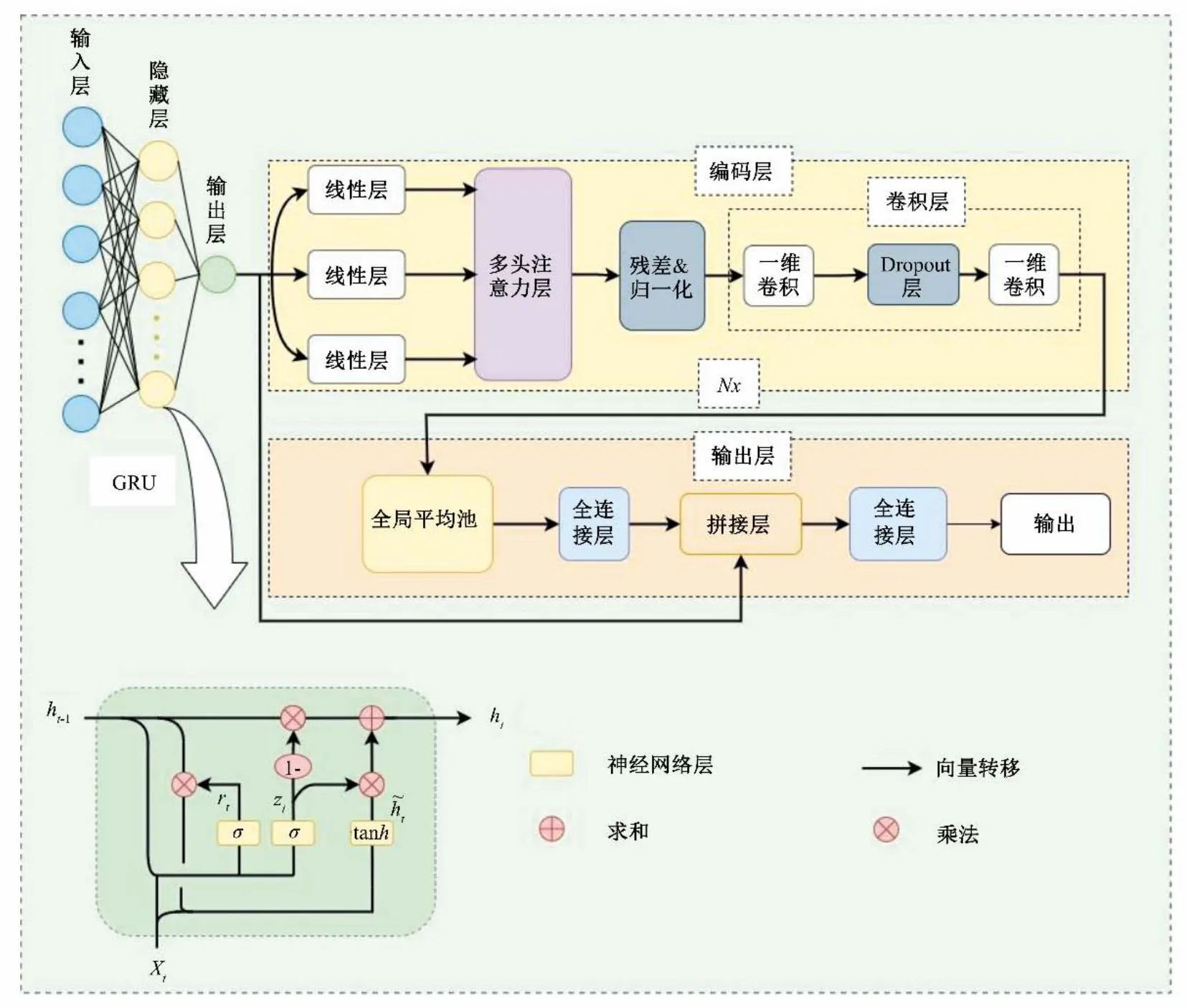
图2 GRU-Transformer结构图Fig.2 Structure of GRU-Transformer
1.4 ANN
人工神经网络的功能类似于人脑和神经系统,是人工智能的一种形式,它可以用数据集进行训练,进行预测模型,并在没有参数的情况下学习内在关系[21]。本文选用在水文预报中应用最广泛的BP 神经网络模型作为对照模型[22-25],图3为具有一个隐藏层的ANN架构图(典型的3层BP神经网络)。
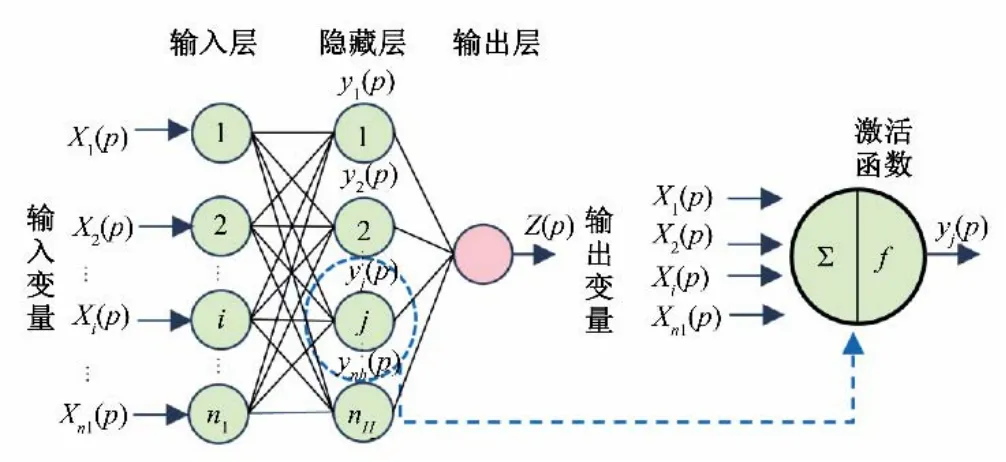
图3 具有一个隐藏层的ANN架构(典型的3层BP神经网络)Fig.3 ANN architecture with one hidden layer(typical three-layer feed forward artificial neural networks)
2 GRU-Transformer洪水预报模型构建
2.1 数据处理
模型所用数据包括降雨和流量数据,两者间数值尺度、单位差异大,为了消除量纲对模型运算的干扰使模型加快收敛[26]对数据进行max-min 归一化处理至(0,1)。将24个站点原始洪水数据资料处理为如表1 中的形式,设置不同预见期T,利用t-T时刻的降雨径流数据预报t时刻出口断面流量Q,P1~P24分别对应24个站点实测降雨量。
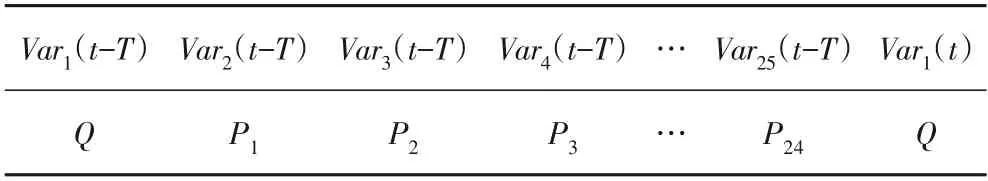
表1 处理后的数据形式Tab.1 Processed data form
2.2 模型基本参数设置
在模型训练之前,需通过实验设定模型超参数[27],初步发现GRU-Transformer 模型中注意力头的维度、头的数量、全连接层维度和编码块数量4个参数对训练效果影响较大。以NSE为目标函数,采用网格搜索法[28]对超参数进行寻优,寻优范围设置为:注意力头维度范围[4,512]、注意力头数量范围[1,256]、全连接层维度范围[4,512]、编码块数量范围[1,10]。本文同时选用ANN、WOA-GRU 模型作为对比实验,各模型参数设置如表2所示。

表2 模型参数设置Tab.2 Model parameter setting
2.3 模型预测过程
洪水预报过程采用滑动窗口的模式实现不同预见期下径流量滚动预报,沿时间轴滑动,到达数据集的时间结束,数据形状为窗口。输入变量为前期的降雨和流量特征,通过GRUTransformer 洪水预报模型模拟降雨和径流间的非线性关系,最终输出预报的洪水过程。图4 为GRU-Transformer 洪水预报模型详细示意图,描述了模型预测过程。式(4)和(5)为模型输入和输出数据的格式,从输入到输出具体过程如下:
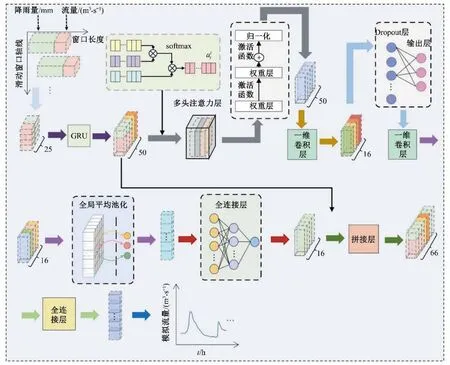
图4 GRU-Transformer洪水预报模型详细示意图Fig.4 Detailed schematic diagram of GRU Transformer flood forecasting model
(1)数据输入:输入洪水数据可以表示为U=[Q,P],其中径流数据矩阵为Q=[Q(t-T-i),Q(t-T-i+1),…,Q(t-T)]T,降雨数据矩阵为P=[P1,P2,…,P24],Pj=[pj(t-T-i),pj(t-T-i+1),…,pj(t-T)]T,(j=1,2,…,24)(T为预见期,i为时间步长,设定值为1。),输入形状为[(None,1,25)]。
(2)GRU 层:嵌入了其他更多维度的数据特征O,经隐藏层得到向量UG=[QG,PG,OG];输出形状为[(None,1,50)]。
(3)多头注意力层:多头注意力层将输入数据映射到多个不同的子空间;输出形状为[(None,1,50)]。
(4)残差&归一化:将原输入与上一步输出相加,防止梯度爆炸,输出形状为[(None,1,50)]。
(5)卷积层及Dropout 层:使用两层一维卷积层代替全连接层卷积计算,进行非线性映射,加入Dropout 防止过拟合;输出形状为[(None,1,50)]。
(6)全局平均池化及全连接层:通过全局平均池化进行数据降维,并对整个网络在结构上做正则化防止过拟合,经全连接层输出;输出形状为[(None,1,16)]。
(7)Concatenate 特征融合及全连接层:将GRU 层输出与上一步的输出进行向量拼接,经全连接层输出最终结果;输出形状为[(None,1)]。
2.4 评价指标
对模型预测结果的评价选取NSE、RMSE、MAE、R2、MAPE作为评价指标,其数学表达式如下:
式中:Q和Qi分别表示观测流量和模拟流量;和i表示观测和模拟流量平均值,i表示第i个时刻,n表示时段数;NSE取值范围为-∞(未拟合)到1(完全拟合);RMSE取值范围为0(完全拟合)到+∞(未拟合),MAE是绝对误差的平均值,描述了观测数据和模拟结果之间的差异,R2的取值范围为0(未拟合)到1(完全拟合),MAPE的取值范围为0(完全拟合)到+∞(未拟合)[29]。
3 GRU-Transformer 洪水预报模型实例检验及比较研究
3.1 研究区及数据选取
选取故县水库控制流域作为研究案例,横跨陕西省和河南省,地理位置介于E109°7′~E111°4′,N33°7′~E34°4′,流域面积4 759 km2,如图5所示。流域为暖温带山地季风气候,年降雨量600~900 mm,降雨量年际变化大,洪水频发。多年平均径流量为12.81 亿m3,最大和最小年径流量分别为31.5 亿m3、5.2 亿m3,实测洪峰流量最大值为4 130 m3/s(1954年8月)。本文选取故县水库上游24 个雨量及水文站点1990-2016年间共49 场洪水进行洪水过程模拟预报,时间间隔为1 h,其中1990-2011年的39场洪水为训练集,2011-2016年的10场洪水为验证集。
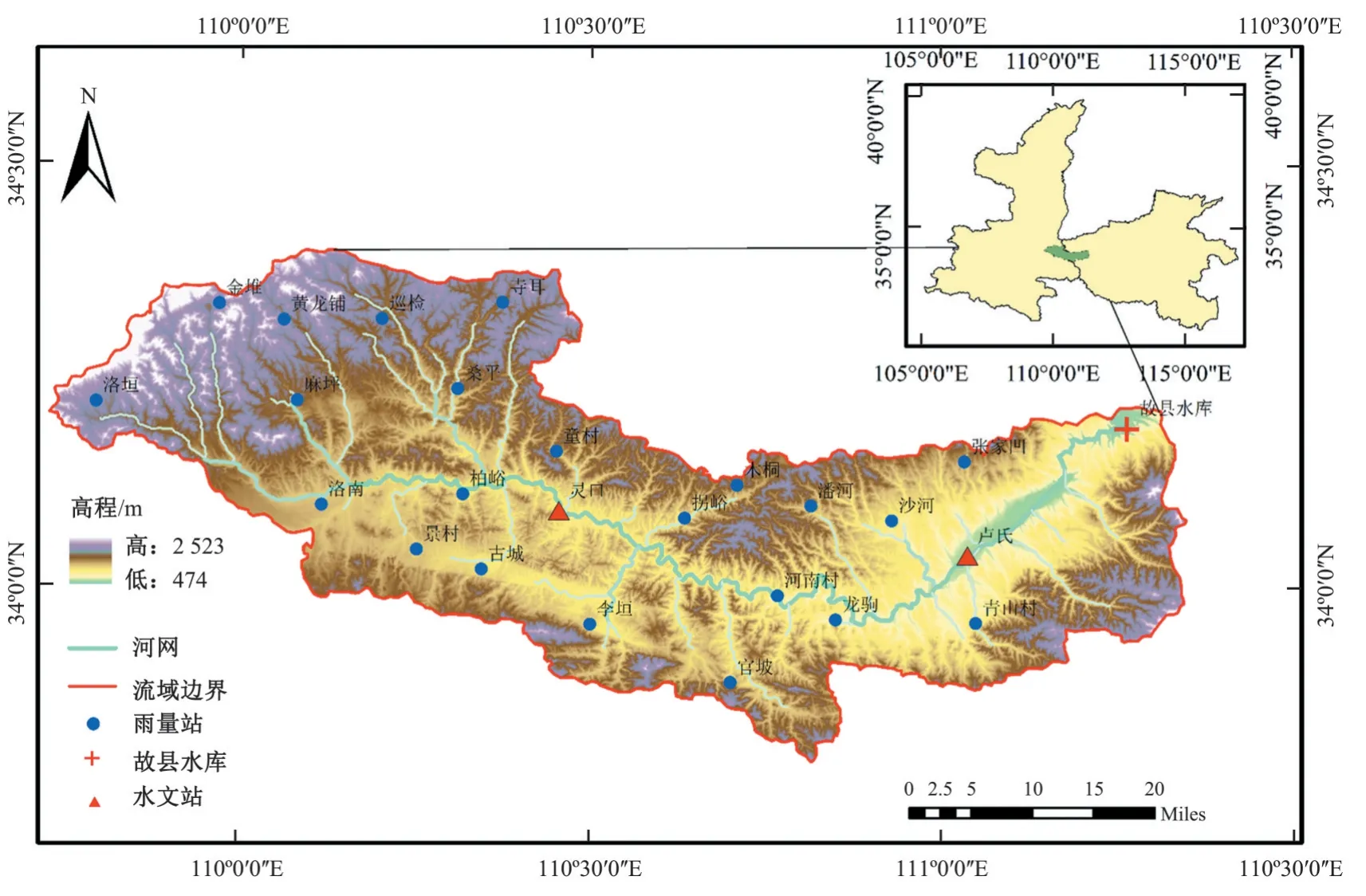
图5 研究区位置图Fig.5 Location map of study area
3.2 整体预报效果评价
图6为GRU-Transformer、WOA-GRU、ANN模型等3种模型在预见期1~6 h 下的降雨-径流过程线图,可以看出,预报流量过程线和实测流量过程线基本吻合。表3 为在预见期T为1~6 h 下对3 种模型预报效果评价指标统计,通过对比结果可见,在T=1 h 时GRU-Transformer 模型预报性能最佳,此时率定期和验证期的NSE、RMSE、MAE、R2、MAPE分别为0.96、33.27 m3/s、21.73 m3/s、0.96、13.91% 和0.95、12.07 m3/s、6.36 m3/s、0.93、10.05%,预测结果已十分接近实际;在T=6 h 时,GRU-Transformer 模型预报精度有所下降,此时率定期和验证期NSE、RMSE、MAE、R2、MAPE分别为0.87、83.75 m3/s、30.15 m3/s、0.88、24.85%和0.86、35.91 m3/s、20.7 m3/s、0.84、20.11%;在相同预见期下,相对于WOA-GRU、ANN 模型,GRU-Transformer 模型的各项预报精度评价指标更优,预报效果最好,说明GRU-Transformer 模型在处理降雨和径流关系上具有更好的非线性模拟能力。
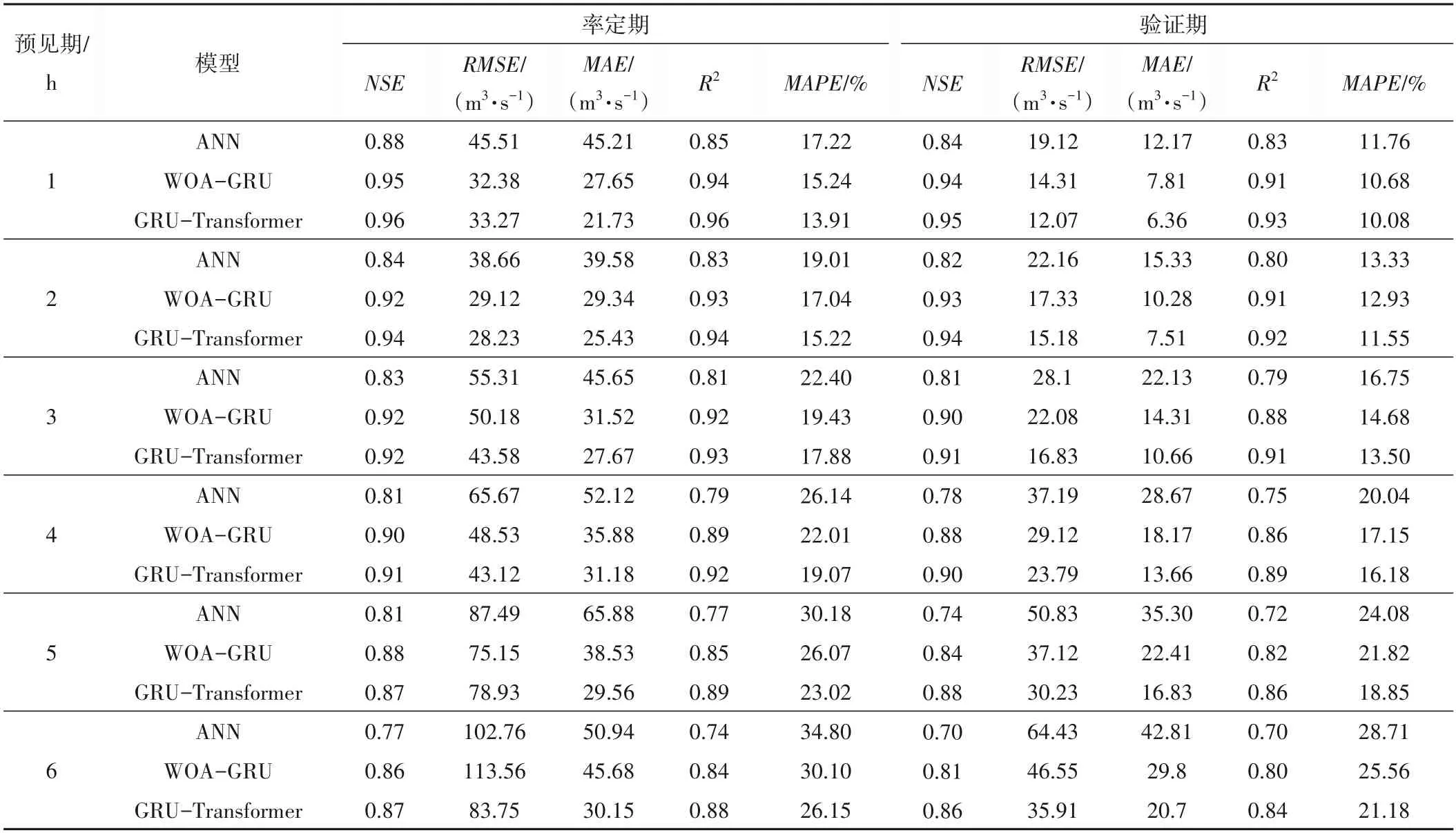
表3 模型预报效果评价指标统计表Tab.3 Statistics of model prediction effect evaluation indicators
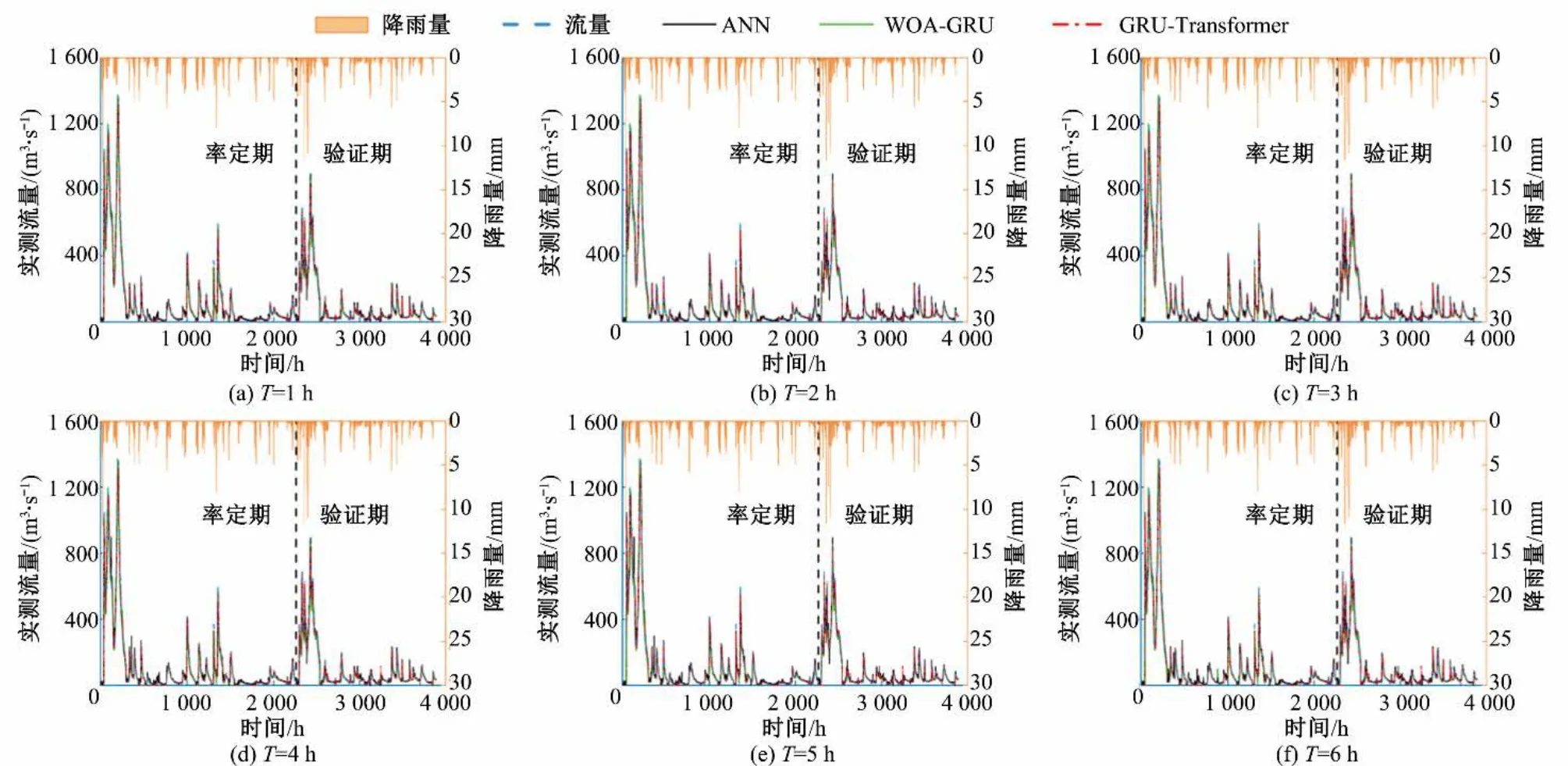
图6 预见期1~6 h下3种模型率定期和验证期洪水过程预报结果对比Fig.6 Comparison of flood process prediction results of three models at regular and verification periods during the forecast period of 1~6 h
图7 为3 种模型分别在预见期T=1 h、T=3 h、T=6 h 下率定期、验证期的实测和预报流量散点图。可见GRU-Transformer耦合模型和单个模型WOA-GRU、ANN 模型相比,其散点图更接近1∶1线,在模型验证期、T=1 h、3 h和6 h时,GRU-Transformer 模型R2值分别为0.93、0.91 和0.84,WOA-GRU 模型的R2值为0.91、0.88 和0.80,ANN 模型的R2值为0.83、0.79 和0.70,GRUTransformer 模型的R2值在相同预见期下优于其他模型,表明该模型可以更好地反映模拟流量和实测流量之间的关系。以上结果显示,GRU-Transformer 模型径流预报结果优于ANN 和WOA-GRU模型。但结合表3来看,3种模型的预报精度会随着预见期的增加出现下降,这是因为预见期增长导致训练集中输入与输出的时间间隔增大,数据的关联性下降,从而导致机器学习模型预报精度下降。
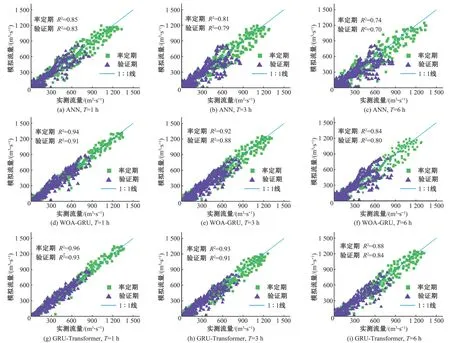
图7 不同预见期下3种模型在率定期和验证期实测、模拟流量散点图Fig.7 Scatter chart of measured and simulated flows of the three models in the periodic and validation periods
3.3 场次洪水预报效果
为了更深一步了解模型对洪水过程的预报效果,进一步分析了验证期中2 场典型洪水事件在T=1,3,6 h 下的降雨径流过程线对比情况,2 场典型洪水事件分别为20150908 场次洪水(洪水1)和20160711场次洪水(洪水2)。从图8可以看出,ANN在较小流量洪水过程模拟中及洪峰前多产生波动,WOA-GRU模型在模拟洪水过程开始阶段表现出较小误差的波动,可能是由于WOA-GRU 模型中记忆单元的存在,较多保存了前一场洪水的数据特征导致的;而GRU-Transformer 模型预报流量最接近实测流量,能够较好的预报洪峰,且在洪水退水阶段表现出良好的预报效果。可见GRU-Transformer 模型整体预报效果最为稳定,具有较好的洪水预报性能。同时,随着预见期的增加模型的预报效果随预见期的增加降低,模型出现低估洪峰的现象,并表现出滞后性,且随预见期滞后现象更明显,这是因为随预见期增长,输入数据和待预报的流量数据之间相关性降低,准确学习挖掘洪水数据特征较为困难导致的。
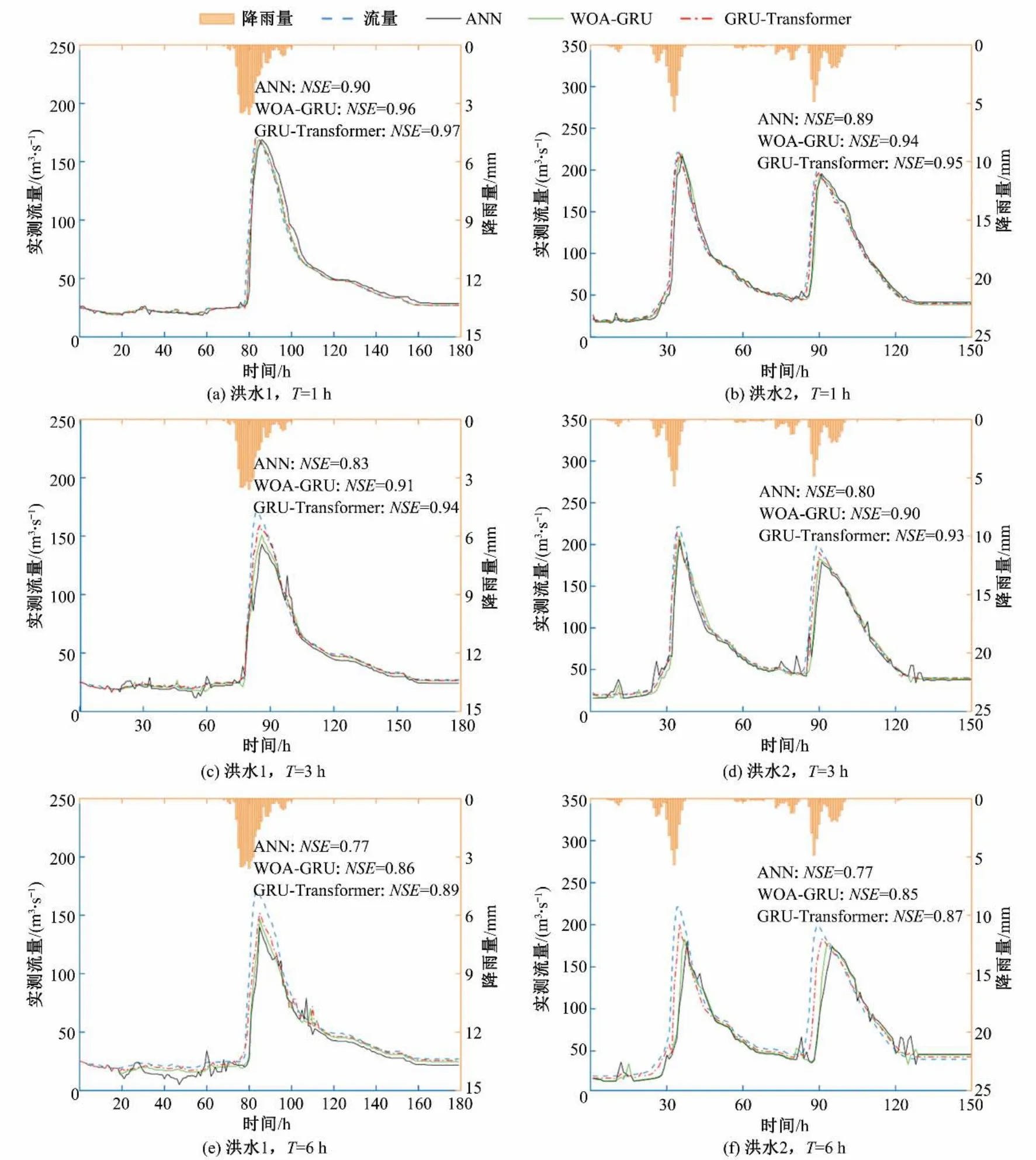
图8 实测流量及ANN、WOA-GRU和GRU-Transformer模型预测结果对比(洪水事件1、2)Fig.8 Comparison of measured discharge and prediction results of ANN,WOA-GRU and GRU-Transformer models(flood events 1 and 2)
3.4 GRU-Transformer模型鲁棒性评估
如图9所示,在相同预见期下,GRU-Transformer 比WOAGRU 和ANN 模型的NSE、RMSE、MAE更优,说明GRU-Transformer 对降雨径流模拟性能最好。3 种模型的预报效果均与预见期密切相关,并且随预见期增大而变差。但GRU-Transformer 模拟表现出随着预见期增加预报精度呈现缓慢下降趋势,而不是急速下降,这说明GRU-Transformer 模型鲁棒性最好。GRU-Transformer 模型的构建是机器学习在洪水预报领域新的尝试,可以有效的进行洪水预报和模拟,但需要在更多的流域进行验证以及进一步研究其在水文预报的应用。未来,进一步调整模型结构降低模型训练耗时,结合更多的方法以提高预报精度和稳定性。
4 结论
提出了构建GRU-Transformer 模型应用于故县水库控制流域洪水过程预报,建立预见期1~6 h 下预报模型,并与WOAGRU、ANN模型进行模拟效果的对比,得到以下结论。
(1)GRU-Transformer 模型在洪水预报种具有较好的适用性,在预见期1~6 h 洪水预报中,GRU-Transformer 预报精度较高,校准期和验证期的NSE均大于0.85,且预报精度在相同预见期下优于WOA-GRU 和ANN模型,但预报精度会随着预见期增大而出现一定程度的下降。
(2)GRU-Transformer 模型较稳定地更好预测洪峰,且在较小流量洪水过程预报时及洪水退水阶段模拟效果表现出优异效果,但随预见期增加出现低估洪峰现象。
(3)与GRU-Transformer 模型比WOA-GRU 和ANN 模型具有更好的鲁棒性,随洪水预见期增大,其预报精度呈缓慢下降,降低的最慢。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
娃娃乐园·综合智能(2019年6期)2019-07-10
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
天津诗人(2017年2期)2017-11-29
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
幼儿画刊(2016年8期)2016-02-28
水利水电科技进展(2014年1期)2014-10-17
