
基于H2O 平台自动化机器学习的糖尿病视网膜病变预测模型的建立
2023-11-28 03:48王慧霞张玉婷朱曼辉
医学信息 2023年22期
王慧霞,张玉婷,朱曼辉
(苏州大学理想眼科医院斜视与小儿眼科1,病理科2,江苏 苏州 215000)
糖尿病视网膜病变(diabetic retinopathy,DR)是最常见且患病率较高的糖尿病(diabetic mellitus,DM)微血管并发症之一,主要病理改变是视网膜血管闭塞性循环障碍[1]。DR 严重威胁着糖尿病患者的生存质量,同时给社会带来严重经济负担。早期筛查防治DR,对于改善DM 患者远期预后至关重要[2]。近年来,国内外学者基于医院或社区的横断面或病例对照研究,利用广义线性模型算法,建立了一系列预测DM 患者发生DR 的模型及列线图,展现出较好的预判能力和临床运用效果[3,4]。广义线性模型属于机器学习中发展较早的统计学模型,而今机器学习飞速发展,算法不断更新,在监督学习中涌现出如支持向量机、决策树、朴素贝叶斯、人工神经网络等算法[5]。算法的不断更迭进步,伴随而来是对建模者专业知识不断增长的要求,这大大提高了临床医生利用机器学习算法的门槛。自动化机器学习(AutoML)可通过自动化建模和调参程序,大大降低建模人员的工作门槛和负担[6]。本研究采集本院患者一般资料及实验室检查结果,利用H2O 运算平台推出的AutoML 算法建立预测模型,旨在为DM 人群的DR 筛查提供新的思路。
1 资料与方法
1.1 一般资料 选取2019 年1 月-2021 年1 月于苏州大学理想眼科医院就诊患者电子病历数据,采用ICD-10 疾病分类标准进行编码。纳入606 例DM 患者,根据眼底照相分为单纯DM(DM 组)303 例及DM合并DR(DR 组)303 例。纳入标准:所有患者诊断均符合最新国内临床指南[1,2]。排除标准:①其他原因导致的高血糖;②合并2 型DM 急性并发症;③妊娠及哺乳期女性;④合并显著肝肾功能异常、严重的心脑血管疾病或恶性肿瘤等;⑤资料不全者。本研究已获苏州大学附属理想眼科医院伦理委员会批准(批准号SLER2018112),所有患者均签署知情同意书。
1.2 临床及实验室检测
1.2.1 人体数据测量 测量并记录纳入人群的身高、体重、血压(SBP/DBP)、臀围和腰围,并计算体质量指数(BMI)和腰臀比(WHR)。采集患者既往病史、服药史、烟酒史,并通过计算代谢当量商(metabolic equivalent of task,MET)计算体力活动量。
1.2.2 DR 检查方法 视网膜检查使用免散瞳眼底数码照相机(型号:TRC-NW300),由专科技师在摄片暗室进行。患者进入暗室休息5 min,待视觉适应后,由技师应用免散瞳眼底数码照相机进行拍摄以黄斑为中心的视网膜彩色图像,每只眼睛拍摄一张照片。照片由对此项研究盲法的眼科医生进行阅读。
1.2.3 血清学检测 获取所有纳入者空腹静脉血10 ml。将收集的血样统一离心,立刻上机检测或储存于-80 ℃冰箱待检。血清生化分析采用Mindray 迈瑞800 全自动生化分析仪。检测项目包括:①糖代谢和胰岛素功能相关指标:空腹血糖(FPG)、空腹胰岛素(FINS)及糖化血红蛋白(HbA1c),并计算稳态模型胰岛素抵抗指数(HOMA-IR);②肝酶指标:谷丙转氨酶(ALT)、谷草转氨酶(AST)及γ-谷氨酰转肽酶(GGT);③脂质代谢相关指标:三酰甘油(TG)、高密度脂蛋白胆固醇(HDL-C)及低密度脂蛋白胆固醇(LDL-C)。
1.3 评价方法 利用H2O 运算平台推出的AutoML算法建立针对DR 二分类结局的机器学习预测模型,产生相应预测结果,据此绘制受试者工作特征(ROC)曲线并建立混淆矩阵,计算特异度、敏感度、准确度及误分类率,评价模型区分能力。
1.4 统计学方法 本研究建模及绘图软件包括:R(4.0.4 版)、H2O 包(H2O cluster 版本:h2o_3.32.1.7)、tableone 包(0.13.2 版本)及lime 包(0.5.3 版本)。计量资料以(±s)或[M(P25,P75)]表示,组间比较采用Student'st检验或Mann-WhitneyU检验。计数资料采用[n(%)]表示,比较采用χ2检验。为进一步了解变量在模型中的重要性及分布情况,进行可视化分析,包括Shapley Additive exPlanations(SHAP 分析)、Partial dependence(部分依赖)及LIME 可视化。双侧P<0.05 为差异有统计学意义。
2 结果
2.1 两组一般及临床资料比较 DR 组糖尿病病程长于DM 组,吸烟、饮酒、高血压、脂肪肝比例、腰臀比、BMI 及收缩压高于DM 组,差异有统计学意义(P<0.05);DR 组 HDL -C 低 于 DM 组,FPG、FINS、HOMA-IR、HbA1c、ALT 和AST 均高于DM 组,差异有统计学意义(P<0.05),见表1。
表1 两组一般及临床资料比较[±s,M(P25,P75)]

表1 两组一般及临床资料比较[±s,M(P25,P75)]
2.2 模型建立判断DR 发病风险 将上述单因素分析中存在差异的变量纳入AutoML 机器学习工作环境中,利用H2O 平台进行随机分组、特征选择、建模运算及验证。将606 例DM 患者按照8∶2 比例随机分组为Train 集(482 例)及Valid 集(124 例)。最佳模型为通用梯度回归模型(generalized boosted regression model,GBM)。这是一种由多棵决策树组成的迭代决策树算法。该模型(基于Train 数据集的5 折交叉 验 证):Gini 值0.914,R2为0.679,LogLoss 为0.260。模型中各变量的重要性见表2。其中在最佳模型GBM 中,重要性排名前3 的变量(即对模型贡献的排名)分别为空腹血糖、糖尿病病程及空腹胰岛素,其占比均超过10%。
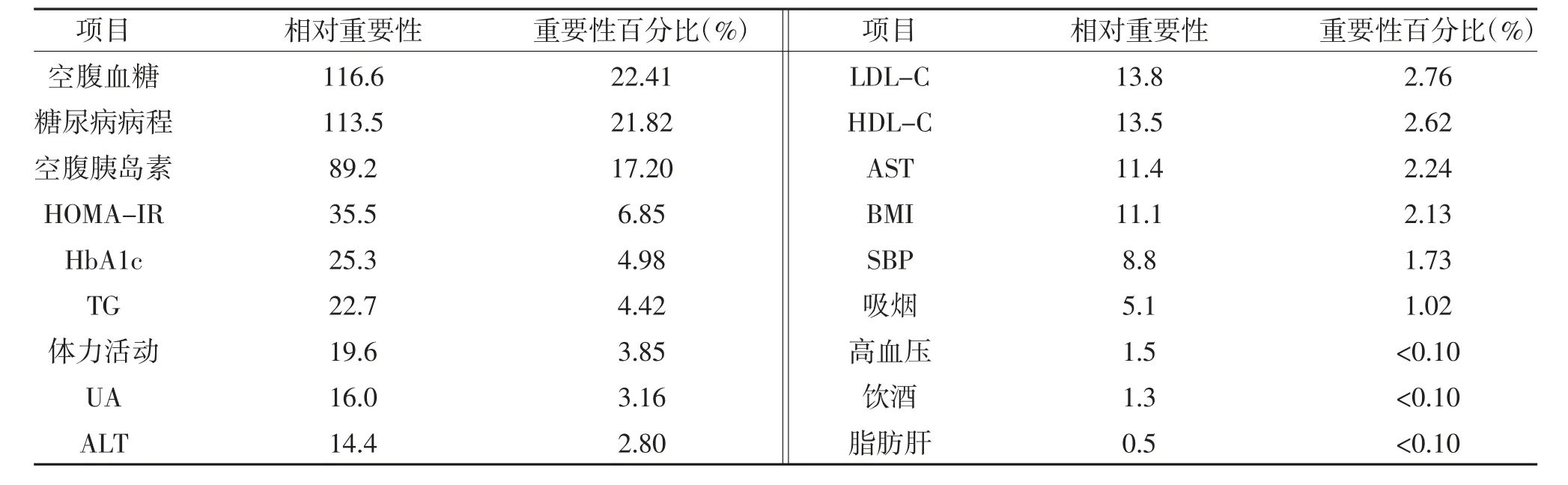
表2 最佳模型中各变量重要性排名
2.3 变量在模型中的作用 在最佳模型GBM 中,各变量的SHAP 特征图绘制在图1 中。重要性排名前3 的变量是空腹血糖、糖尿病病程及空腹胰岛素。三者在结局二分类中的分布,体现其标准化数值与发病呈正相关趋势。图2 为LIME 可视化,显示是随机抽取的8 个样本(DM 组5 例,DR 组3 例),3 个重要变量对预测结果的重要性贡献。图3 显示的3 个变量在模型中的部分依赖图,可以看出三者与结果基本上呈现的是单调的上升趋势。
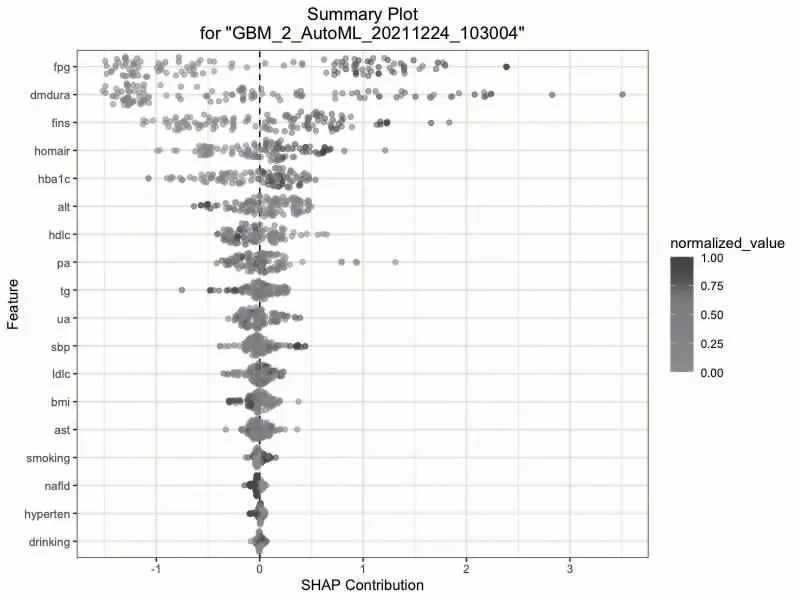
图1 最佳模型中各变量SHAP 特征

图2 随机样本中变量重要性LIME 可视化
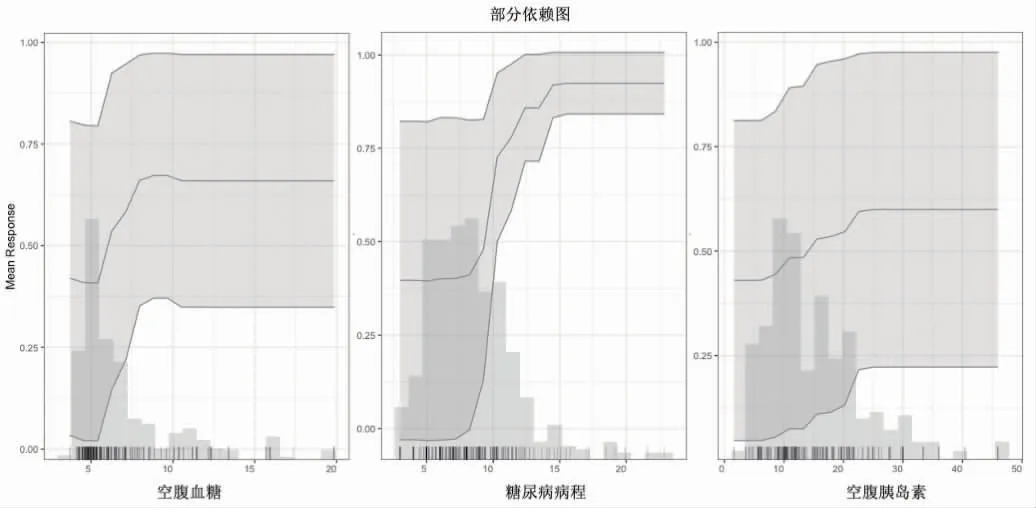
图3 最佳模型中变量部分依赖图
2.4 预测模型的区分能力 采用上述获得的预测模型GBM 绘制预判DR 发病的ROC 曲线并建立混淆矩阵。在Train 数据集中,ROC 曲线下面积为0.942(95%CI:0.921~ 0.963)。利用混淆矩阵得到特异度为0.924,敏感度为0.959,准确度为0.942,误分类率为0.058。在Valid 数据集中,ROC 曲线下面积为0.831(95%CI:0.764~0.897)。利用混淆矩阵得到特异度为0.828,敏感度为0.833,准确度为0.831,误分类率为0.169,见表3。

表3 最佳预测模型GBM 在各个数据集中的区分能力
3 讨论
随着机器学习及深度学习的快速发展,选择合适的模型并根据超参数不断调整优化模型,这一过程变得十分繁琐且耗时。此外,它还对建模者的计算机知识提出了较高要求[5]。近几年,各大科技公司陆续推出自动化学习平台,如谷歌公司推出的Cloud AutoML、H2O 平台的AutoML 等[6]。AutoML 可以自动化完成机器学习的前期工作:包括数据准备、编码、功能选择/提取以及工程化环境。同时,在模型生成过程中,如模型算法选择、优化、迭代以及验证,AutoML 均可在少量代码基础上实现。
H2O AutoML 是H2O 平台提供一种针对自动化工作流程的算法,主要功能涵盖:轻数据准备、环境建立、模型选择及优化[6]。其中亮点包括:通过堆叠一组集成学习模型,自动化迭代模型。当前版本H2O AutoML 可建立并交叉验证以下模型:广义线性模型、随机森林、极随机森林、梯度提升机随机网格、XGBoosts、深神经网随机网格以及相关的集成学习。H2O AutoML 的一大特点就是组合堆叠多个集成学习算法,以获得比从单个成分学习算法更好的预测性能,广泛运用在监督学习中。许多流行的现代机器学习算法实际上都是集成学习。例如,随机森林和梯度提升机都是通过组合弱学习算法(例如决策树)并形成单一、强学习的集成学习法。
近年来,随着人民群众饮食结构改变、人口老龄化等因素的影响,我国糖尿病患病率大幅增加。流行病调查显示[7],我国大陆糖尿病患者中合并视网膜病变约占23%。由于DR 的早期隐蔽性、慢性进展性、不可逆性等特点,目前早期筛查工作仍然面临诸多困难,选择基于临床资料、实验室检查的无创性筛查工具是DR 的防治工作重点[8]。DR 的发生发展是一个较复杂的病理生理过程,具体的机制尚不明确[9]。目前观点认为[10],DM 患者机体能量代谢障碍,特别是胰岛素抵抗和糖脂代谢紊乱可诱发视网膜病变。DR 在病程10 年以上的DM 患者中患病率高达80%,是全球中老年人视力丧失的首要病因[11]。患者随着DM 病程的延长,一系列机体能量代谢功能紊乱逐渐发展并加重,其中如高血糖或血糖波动大、脂类代谢紊乱等都被证实是DR 的独立危险因素。
及时的DR 筛查对于高危病例至关重要,通过全面的眼科检查与干预,来避免永久性的视力丧失。在过去几年中,各个国家通过大型流行病学研究提出了综合各类风险因素的个性化筛查方案,体现了较好的成本-效益比。DCCT 是北美地区一项开展了近40 年的大型队列研究,该研究提示长病程、高HbA1c、高血压等是DR 发生发展的独立危险因素,为基于社区的筛查提供标记工具[12]。有研究[4]报道了一项跨我国多省份的横断面研究,发现DM 发病早、病程久、高血压、高血糖及高HbA1c 是DR 的独立危险因素;该团队构建了列线图模型,为DR 早筛早诊提供帮助。基于人工智能的新技术,包括移动设备检测系统、数字图像算法等,将在未来改变筛查模式,再次改善成本-效益比[13,14]。
本研究收集单纯DM 患者和合并DR 的DM 患者临床资料及实验室结果,利用H2O 平台的AutoML算法进行自动化的变量筛选,发现高血糖、DM 病程、高空腹胰岛素等是该地区DR 发生的重要独立危险因素,这与国内外研究相似[3,4,12]。采用上述因素建立的GBM 预测模型判断DR 发病,显示出较好区分能力以及均衡的敏感度和特异度,优于基于线性模型算法的相关报道[3,15]。本研究中的机器学习模型在训练集和测试集中都展现了良好的特异性,作为一个初筛工具,可以用于社区高危人群的筛选,大大降低眼科卫生机构的工作压力,避免医疗资源的浪费[16-18]。
本研究报道了利用AutoML 算法处理DM 患者数据,为今后的DR 筛查提供参考和思路。该方法优势在于:一方面相比较传统的逻辑回归等统计模型,提高了模型准确率;另外,使用自动化算法,大大降低了医务人员利用人工智能技术的门槛,为今后AutoML 在临床科研领域的应用提供参考[19,20]。本研究样本是基于我院的单中心数据,利用随机分组和交叉验证,具有较高的参考价值。但仍需多中心的外部验证进一步评估该模型在DR 诊断中的作用。
综上所述,本次利用AutoML 算法建立的通用梯度回归DR 患病预测模型可用于DM 人群中DR的筛查。
猜你喜欢
公民与法治(2022年1期)2022-07-26
小学生学习指导(高年级)(2021年4期)2021-04-29
中国生殖健康(2020年7期)2021-01-18
云南医药(2020年5期)2020-10-27
河北理科教学研究(2020年2期)2020-09-11
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
幸福(2019年12期)2019-05-16
小学生学习指导(低年级)(2018年11期)2018-12-03
现代防御技术(2016年1期)2016-06-01
