
基于多标签学习的探索性仿真实验因素筛选方法*
2023-12-06 03:15张雪超
指挥控制与仿真 2023年6期
安 靖,张雪超,张 雷,刘 伟
(1. 国防大学 研究生院,北京 100091; 2. 国防大学 联合勤务学院,北京 100858;3. 国防大学 联合作战学院,北京 100091; 4. 中国人民解放军61660部队,北京 100081)
作为一种认识、研究战争的重要手段,探索性仿真实验通过在可控条件下模仿军事行动,观察规律,获得认知。运行过程中,要充分考虑作战体系的整体性、体系内部的动态交互性,以及体系间的对抗性,将面临实验因素数量多,因素水平范围大,实验因素之间、实验因素和仿真结果之间多对多交互,仿真想定样本空间复杂程度高,空间维度爆炸等问题[1-3]。因此,需要研究实验因素的筛选问题,确保探索性仿真样本空间既规模可接受又具有典型代表性。对于这一问题,文献[4-6]采用改进的序贯分支(SB)算法对实验因素进行筛选,文献[7]提出Morris法,完成不确定因素的分析筛选,文献[8]基于回归分析和方差分析提出逐步回归方法,文献[9]根据输出相对于输入的梯度选择重要特征,但这些方法通常不能用于非线性问题分析。文献[10]提出的方法实现了非线性问题的特征选择,但由于不限制单样本的搜索空间,导致计算成本较高,文献[11]通过特征提取压缩空间,但由于空间转换,无法保留现实意义,可解释性差。
本文提出了一种基于定性定量相结合的多标签学习方法,该方法的核心是在设计与实施仿真预实验的基础上,构建深度神经网络,通过多标签学习过程[12-13]中的特征选择,完成实验因素的筛选。关键技术包括:一是训练数据集的生成与预处理,聚焦实验目的,基于定性分析设计并实施仿真预实验,对预实验输出结果进行采集和标准化等预处理,生成学习过程所需的训练数据集,解决军事数据缺失问题。二是神经网络的构建和训练,输入控制层和稀疏正则化搭建深度神经网络,将特征选择(Feature Selection)过程与多标签(Multi-label)模型训练过程结合,同时关注预测和特征选择两个目标,得到拟合效果较好又保留军事意义关键特征的回归预测模型。三是特征的输出和分析,对筛选特征进行定性分析,结合军事经验,基于全局敏感性分析补充完善实验因素。
1 相关定义和形式化描述
本节给出方法相关的定义,并形式化描述如下:
定义1 仿真想定是在军事想定的基础上,面向仿真系统,根据仿真实验的目的、边界条件、实验模式、仿真系统需求等,对初始战场态势、交战各方作战力量、武器装备、作战行动、交战规则、仿真规则等进行的设定。
定义2 仿真想定数据是仿真想定的数据化表现,是对仿真想定进行抽象转化形成的数据集合,支撑仿真系统的初始化和运行。
定义3 特征选择(Feature Selection)是通过一个特定的评价标准(Evaluation Criterion),对原始特征集M各个特征的相关度进行衡量,完成从M中寻找最优特征集N(N⊆M)的过程,是大数据特征工程的重要方法之一。其目的是删除原始特征集合中的冗余(Redundant)特征和不相关(Irrelevant)特征,保留有用特征。
定义4 实验因素筛选本质是一个特征选择问题,是根据特征相关度(评价标准),采用一定的搜索策略(特征选择方法),从高维特征实验因素向量集合(原始特征集M)选择最能代表向量空间的实验因素子集(最优特征子集N),也称属性选择或变量子集选择。
定义5 多标签特征选择(Multi-Label Feature Selection,MLFS)
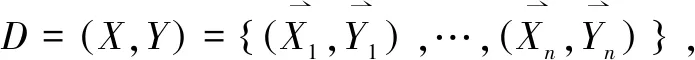
基于上述假设,本文定义多标签特征选择是关注多标签回归预测和特征选择两个目标,训练映射函数f:X→Y的过程。即将多标签学习(Multi-Label Learning,MLL)过程与特征选择相结合,在学习过程中完成特征选择。
2 基于定性分析的仿真预实验设计
数据是机器学习的核心支撑,考虑到作战数据不易获取,本方法在采用机器学习进行特征选择前,基于定性分析,设计并实施仿真预实验,通过仿真系统推演,为学习训练生成所需的训练数据集。
首先,基于军事想定,采用专家研讨、影响图分析等定性工具方法,初步筛选出相对重要的实验因素。实验因素的选择依据主要包括:一是作战行动典型性,采用专家研讨的方法,逐层分解,筛选确定影响或代表各作战主体、重要行动、作战规则的典型因素;二是实验因素可控性,尽量选取可控因素;三是因素水平定量化,尽量选择能够定量化的实验因素。
随后,确定各实验因素的因素水平,完成实验设计。实验因素的确定需重点考虑:一是兼顾现在和未来,作战问题研究具有一定的前瞻性,实验因素在取值时不仅要考虑现阶段情况,还要考虑未来发展情况下的取值。二是关注敏感临界值、极端情况值,仿真预实验的目的在于对定性分析的实验因素进行筛选,因此因素水平将重点考虑对某作战行动效果和仿真实验结果的影响较大的临界值、极端值。三是仿真实验可行性,确定实验因素水平数量时,应在满足实验需求的基础上,充分考虑仿真系统的支持度、计算能力等实验条件的现状。
最后,基于实验设计,运行仿真系统,并采集想定仿真结果。对采集到的仿真结果数据进行特征归一化(Normalization)或标准化(Standardization)等特征缩放预处理。归一化是将所有特征值映射到[0,1]或[-1,1]之间,实现原始数据的等比例缩放;标准化是将所有数据变换至均值为0,标准差为1的分布。
3 基于多标签学习特征选择的实验因素筛选
3.1 基本思路
按照训练数据集的情况,特征选择方法可以分为有监督(Supervised Feature Selection)、半监督(Semi-supervised Feature Selection)和无监督(Unsupervised Feature Selection)[14]。按照与机器学习算法的关系,又可以分为过滤式模型(Filter)、包裹式模型(Wrapper)和嵌入式模型(Embedded)[14-16]。
根据研究目标和数据集的特点,本方法采用有监督的嵌入式模型进行特征选择,特征选择和多标签学习训练在同一个优化过程中完成。基本思路是:引入输入控制层构建深度神经网络,通过多标签学习训练,得到拟合度较高的回归预测模型。根据文献[17-19]的实验验证、结果分析,在对网络结构进行一定稀疏化处理的基础上,模型权值参数代表了特征对于模型的贡献度和重要性,越是重要,就会越大,反之,与输出无关,对应的系数则接近于0。因此,根据训练得到的权值参数,从大到小对相应的特征进行排序,就能够自动完成特征选择。
3.2 引入输入控制层的深度神经网络构建
多层神经网络拥有较强的复杂非线性函数处理能力,能够提高模型的拟合度,因此,本文根据训练集的数据结构,将数据集映射到特征空间,搭建如图1所示的DNN。
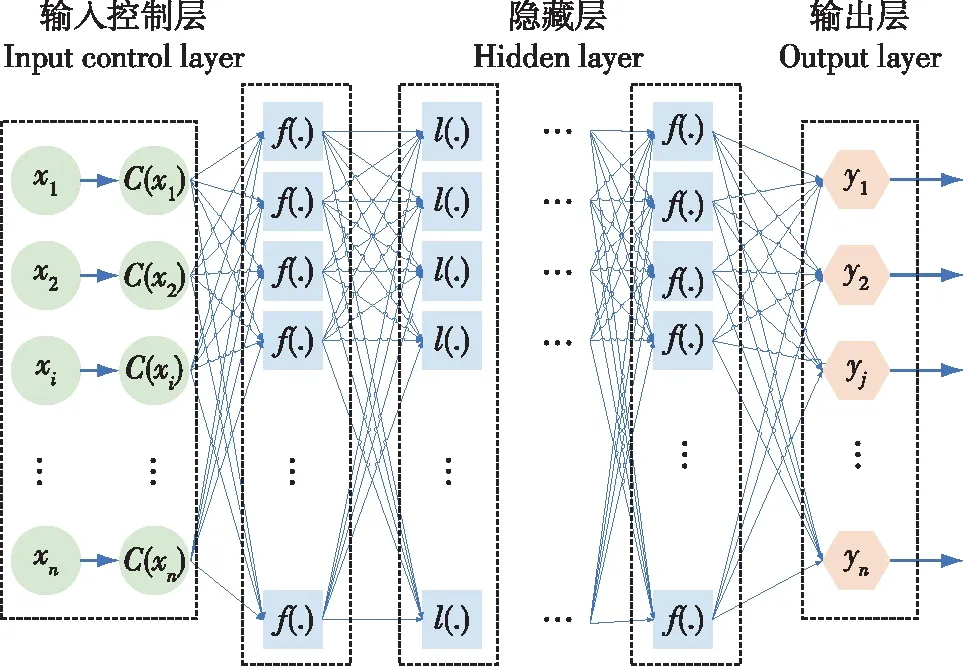
图1 引入输入控制层的深度神经网络结构Fig.1 Deep neural network structure with input control layer
为保证权重的有效输出和选择,该网络f:X→Y主要由以下三部分组成。
1)control_input输入控制层
(1)
2)多个ANN网络隐层
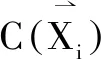
3)输出层
网络的输出可表示为
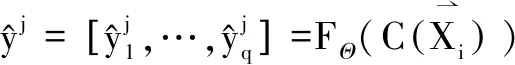
(2)
其中,F(·)是含有超参数Θ={W,b}的多个隐层函数的叠加。
3.3 引入稀疏正则化的多标签学习训练算法
融合单个标签的特定特征空间和所有标签的共享特征空间,对上述网络进行训练。考虑本文数据来源,即训练集特征标签实际值的可用性,采用人在环的干预,确定单个标签的特定特征空间。对于共享特征空间的确定,基于经典的两阶段训练过程[20],将第一阶段的预测值作为附加特征扩展到原始特征空间,强化特定特征和单个标签之间的相关性。
训练过程如下:
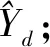
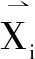
4)训练模型fq,数据从输入层通过隐层沿一个方向将计算出的输出传递到下一层,直到输出层;在输出层将这些计算用于反向传播算法,根据误差最小化的原理,采用SDG随机梯度下降优化器来推导每个特征权重参数,确定下降方向,并更新每个权重参数[21]。优化算法如下:

算法1:模型参数优化算法输入:训练数据集D′j;回归模型fq;特征数t输出:特征权重ωj1,…ωjt 1. initial X′TR02.g0(X′TR0)=fq(X′TR0;Yj)(3)3. fori←1 to t do4. comput ωjt=-[δl(Yj,gt-1(X′TRt-1))δgt-1(X′TRt-1)](4)5. giX′TRt()=func(fq(X′TRt;ωjt))=gt-1(X′TRt-1)+fq(X′TR;ωjt) (5)6. end for
其中,fq是回归函数,作为机器学习的基学习器,公式(3)g0(X′TR0)表示采用基学习器在输入空间X′TR0中对目标Yj进行学习的预测值。公式(4)求出当前模型的权重梯度值,并将梯度值作为残差估计,其中l是添加L1范式正则化(Regularization)的均方误差损失函数。添加L1范式正则化的损失函数l计算公式如下:
l=l0+λ∑ω|ω|
(6)
其中,l0为原始平方误差损失函数,ω为权重,λ为正则化参数,对权重的取值增加了限制。正则化的目的是使模型稀疏化,将无关特征的系数估计(Coefficient Estimate)朝0的方向进行约束、调整或缩小。
5)将残差估计作为目标,根据式(5)利用梯度值对模型进行更新,并作为下一轮迭代的目标。
3.4 基于折交叉验证的模型评价
常用的回归预测指标包括平均绝对误差(Mean Absolute Error,MAE)、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)、均方误差(Mean Square Error,MSE)、均方根误差(Relative Root Mean-Squared Error,RRMSE)等,降低这些误差将意味着模型的预测结果更精确[22]。以均方根误差(RRMSE)为例,计算公式如下:
(7)
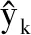
3.5 基于训练模型的特征输出
根据模型综合评价,选择拟合效果较好的回归预测模型。该模型输入控制层的特征权重代表了特征参与模型的程度,按照对应权重大小进行排序并输出。
同时,为了更好地保留实验因素的军事价值,可进一步结合军事经验,基于定性分析和判断,对实验因素进行适当的补充。
4 实例:某作战样式“立体投送”行动仿真实验因素筛选
以某作战样式“立体投送”行动为背景,对本文所提方法进行可行性、有效性验证。
4.1 仿真预实验设计
该行动中,红方的作战目的是尽快利用火力压制蓝方,并综合利用平面、空中、超越等多种投送方式将兵力投送至蓝方陆地,同时,绿方以低、中、高三种强度进行干预。整个过程中追求战损尽可能小,投送成功率尽可能高,同时上陆兵力能够在一定时间内完成固守任务。
上述行动构想涉及多类装备平台、多支作战力量以及多种行动指令,实验因素较多,仿真实验易陷入维度爆炸问题,需要对实验因素进行重要程度排序,忽略部分次要因素。基于对军事问题的理解和经验进行定性分析,初步筛选49个实验因素,设计1个基准想定,29个焦点实验想定,实施仿真预实验。预实验的参数设置如表1所示。

表1 仿真实验参数表Tab.1 Simulation experiment parameters
采集到的仿真预实验结果包含620条样本数据,来自620次仿真实验,每条样本由输入输出两部分组成,一是预实验的实验因素([24,21,4])和过程数据([24,21,4])形成的X的24*6矩阵,二是结果分值数据Y。对其进行整理,形成多标签学习的训练集。如下:
n=620
(8)
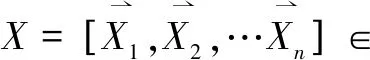
(9)
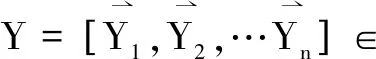
(10)
4.2 网络构建、训练和评估
基于Pythorch深度学习环境搭建8层全连接神经网络。包括:输入控制层1层,relu激活层和liner全连接层各3层,输出层1层。以仿真预实验的数据样本为训练数据集,采用SDG优化器、MSELoss损失函数(L1正则化),按照学习率lr=0.01、Epochs=500、Batchsize=8的参数训练该网络。训练过程的收敛曲线、MAE曲线、MAPE曲线、RRMSE曲线如图2所示。
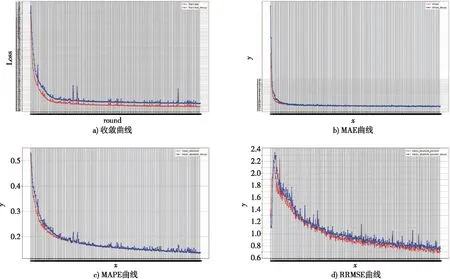
图2 模型训练收敛曲线及模型评价曲线Fig.2 Model training convergence curve and model evaluation curve
4.3 实验因素的筛选确定
在神经网络的训练学习过程中,模型控制层的特征权重参数经过了sigmoid激活函数进行转换,采取特征热图进行输出。图3所示为Epoch=499的特征热图,将该图对应于样本集X的24*6矩阵,对特征权重由大到小进行排序。

图3 特征集热图Fig.3 Feature heat map
选择排名靠前的12个特征,包括绿方两型战斗机数量、某型登陆舰数量、某型战斗机数量、某型护卫舰数量、某型武装直升机数量、各集群出发时间、空中输送编队飞行速度等。
为确保对重点关注的投送实验因素考虑得更加全面充分,我们结合军事经验,补充了运输直升机高度、固定翼运输机高度和登陆舰速度三型投送平台的3个实验因素。
最终从原始的49个实验因素中选定关键实验因素15个。
4.4 实验结果评估与分析
从模型预测性能、特征集有效性两方面进行实验评估,并对实验结果进行定性分析。
1)预测性能评估
以RRMSE值为指标评估预测性能。对本文算法、SST(Stacked Single Target,单目标堆叠)、SVRCC(SVR-correlation Chains,支持向量回归链)共3种算法,分别计算RRMSE值,对比结果如表2所示。可以看出,由于该算法添加了人工的特定特征分组,在预测性能上有一定的优势,但差异不明显,三种算法均能够得到较好的预测性能。

表2 RRMSE值对比Tab.2 Comparison of RRMSE values
2)特征集有效性评估
以筛选的实验因素为变量,更改变量取值为0,加载模型重新计算预测值,并与模型标签结果进行比较,计算RRMSE为0.713,远大于实验的0.32。随后利用统计检验的Wilcoxon signed rank test[23]在显著水平α=0.05上进行检验。提出假设新计算的预测值与均值等价,无显著差异。结果如表3所示。从表中得到p<0.05,假设不成立,前后计算均值不等,说明标签特征的有效性。

表3 Wilcoxon signed rank test检验结果Tab.3 Wilcoxon signed rank test results
3)结果定性分析
对实验结果进行定性分析,可以发现,实验因素的筛选与客观实际情况较为吻合。
首先,选择的实验因素有如下特点:一是作战行动中夺权的关键节点,如某型护卫舰、某型战斗机的数量,作为对抗蓝方反舰导弹及对地战机等武器的主要平台,如果护卫舰、战斗机数量不足的话,将很难迅速压制蓝方对海、对空力量。二是作战行动中敌重点目标,如某型登陆舰数量,作为主要的投送平台,该舰受敌火力威胁严重,生存率极低。三是灵敏度较高的因素,如绿方介入强度,高、中、低三种强度输入对结果的输出影响大。当绿方高强度即直接提供空海力量介入时,红方损失大幅度提高,若绿方仅提供低强度电子干扰,对红方造成的损伤有限,与基准想定相比,并无太大区别。
同时,我们主观上认为较为关键的一些因素,如水雷数量,某型导弹、火箭炮数量,甚至投送比例等,并没有被选定为关键因素。通过分析,也有一定启示,例如,通过对某型导弹数量的实验分析发现,由于某型护卫舰对其拦截成功率极高,削弱了其在仿真结果中的重要程度;某型火箭炮,我们认为其对红方登陆部队和水面舰艇威胁极大,但由于其开火特点,位置暴露较快,一轮开火后,很快就会被红方升空的作战平台锁定,因此在红方掌握了制空权的条件下,其数量对行动影响较为有限。
5 结束语
结合定性分析和定量计算,本文提出了基于多标签学习特征选择的实验因素筛选方法,并以某作战样式“立体投送”行动的仿真实验因素筛选为实例进行实验验证。实验结果表明:该方法能够聚焦探索性仿真实验目的,利用深度神经网络逐层进行学习,并在多标签学习过程中完成实验因素的选择。经筛选的实验因素在一定程度上客观,且与作战行动现实情况吻合。
猜你喜欢
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
数学小灵通·3-4年级(2017年9期)2017-10-13
电子制作(2017年23期)2017-02-02
公民与法治(2016年10期)2016-05-17
西北工业大学学报(2015年4期)2016-01-19
计算机工程(2015年8期)2015-07-03
振动工程学报(2014年4期)2014-03-01
