
风电机组异常数据检测、清洗与解释方法研究*
2023-12-09 08:51张佳楠薛安荣
计算机与数字工程 2023年9期
张佳楠 薛安荣
(江苏大学计算机科学与通信工程学院 镇江 212013)
1 引言
风能作为可再生的清洁能源是“十四五”碳中和能源战略的重要组成部分,风电场规模及数量不断扩大。但风能自身的不确定性致使风电并网后,电网系统易出现大规模的功率波动,影响安全运行。为使风能成为可靠的能源来源,通过风电机组运行数据建立高效、精准的风电监测和预测模型十分重要。但受环境、调控等因素影响,采集的风电机组运行数据中会存在大量不符合风电机组正常输出特性的异常数据。这些“脏数据”的会影响进一步的预测建模分析,甚至对电网系统的安全运行产生不利影响,因此对风电机组运行数据中的异常数据进行准确的检测与清洗是提高预测建模分析精度的必要前提。通过风电场的数据采集与监视(SCADA)系统收集风电机组运行数据是常见手段。当前许多研究人员基于SCADA 系统数据构建的风电机组异常数据检测方法主要可分为两类:
1)基于数理统计的方法:这类方法主要通过数据的分布特征结合先验的理论知识使用数理统计的方法进行异常数据检测。如ZHENG L 等[1]利用局部离群因子算法构建风速-功率曲线模型中曲线附近的相对密度实现异常检测;董兴辉等[2]使用统计方法构建输出功率模型量化分析功率以实现异常检测功能。该类方法在建模时忽略了SCADA 系统数据的时序性,很难准确地识别风电机组运行状态变化趋势导致的异常。
2)基于人工智能的方法:这类方法从数据自身的特性与结构出发,能有效发掘原始数据间的相关性。自编码器(AE)[3]、去噪自编码器(DAE)[4]等无监督学习的方法模型可以在训练时脱离对数据标签的需求,更贴近实际应用领域,但难以识别风电机组运行状态变化趋势导致的异常。长短时记忆(LSTM)[5]神经网络作为循环神经网络的一个变体,通过门的结构将时序数据间的长依赖性以及非线性特性引入模型训练。基于以上,柳青秀等[6]提出了一种基于LSTM-AE的风电机组数据异常检测方法,结合LSTM 有效处理多维数据时序性的特点与AE 能有效提取数据的本质特征的优势,学习并重建输入序列并通过重建误差进行异常检测。但在实际应用过程中原始数据的部分机组可能会出现异常数据占整体比重过大的情况,导致基于单机组的运行数据建模时在检测阶段对正常数据与异常数据不能明显分化。同一时间段内的邻近风电机组的工况是相近的,可在训练过程中联合近邻机组的数据训练。因此,本文提出一种能在模型训练过程中优化参数调整各个机组数据影响比重的隐藏状态共享模块,并结合LSTM-AE 网络结构设计了能有效进行多机组模型联合训练的集成共享框架,用于异常检测。
风电机组运行数据的各个性能参数在不同的工况下变化幅度差异较大,不同的工况下对异常的判定标准是不同的,传统的通过固定阈值对重构误差进行异常清洗的方式具有局限性,容易出现错判与漏判现象。陈俊生等[7]在基于滑动窗口的堆栈降噪自编码(SDAE)模型上通过核密度估计方法分析机组正常数据监测指标的概率密度分布,比较参数对监测指标超限的贡献度确定异常阈值,但该方法中窗口区间长度对判定结果精度影响较大。柳青秀等[6]通过支持向量回归(SVR)自适应的确定异常指标与设备工况间的非线性关系,提出了自适应阈值的清洗方法。但该方法对中核函数的选择会结果影响较大且选择合适的核函数较为困难。自动编码器能自适应确定重构误差的多元高斯分布中的概率密度与重构值的非线性期望函数,本文通过重构值的期望误差概率密度与实际误差的概率密度间的差值得到异常清洗过程中的自适应阈值。在不同工况下性能参数对整体异常的贡献度不同,根据异常数据可进一步确定与异常高度相关的性能参数,对清洗结果做出异常原因解释,可帮助风电机组定位故障原因。本文通过对比重构误差中不同性能参数与概率密度差值的互信息量,确定异常关键性能参数。
2 异常数据检测
2.1 LSTM-AE模型
LSTM-AE 模型[6,8]结合了LSTM 有效处理多维数据时序性的特点与AE能有效提取数据的本质特征的优势,其结构如图1。
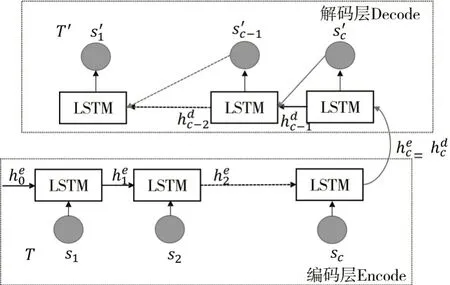
图1 LSTM-AE模型结构图
LSTM-AE 模型由编码器(Encode,E)与解码器(Decode,D)组成,两者呈对称关系,处理多维时序序列时,在编码层中由基本LSTM 神经单元对输入的数据进行编码和隐藏状态信息的传递,基本LSTM神经元结构如图2。

图2 基本LSTM神经单元结构图
LSTM神经单元可以进行长时间记忆的关键是单元状态(Ct)的传递,分别通过别输入门(i)、遗忘门(f)和输出门(o)来实现移除和添加信息到单元状态(Ct)。
其中W为LSTM 神经单元各个门结构权重系数矩阵,bi,bf,bo,bs分别代表各节点的偏置项,具体公式如下:
在编码阶段中,编码器接收维度为(l,M)的矩阵作为输入,其中l为单次训练输入的多维时间序列T=(s1,s2…sn)中的向量个数。M即对应的是序列中的向量维度。LSTM单元接受当前时刻的输入向量st以及上一单元的输出的状态信息,编码后得到当前时刻的输出状态信息,依次传递到第l个LSTM 单元,完成输入编码。将最后一个编码单元的输出的作为第一个解码单元的初始输入,通过非线性层重构输入sc对应的输出,并计算得到该LSTM 单元的隐藏状态。将输出以及隐藏状态作为下一个LSTM 单元的输入,以此类推,得到重构输入的序列T'=(s1'…s'n-1,s'
n),完成解码。LSTM-AE模型中损失函数loss选用均方差(Mean Square Error,MES)如下:
2.2 集成共享框架
针对实际应用过程中原始数据的部分机组可能会出现异常数据占整体比重过大的情况,导致该机组在LSTM-AE模型的检测阶段对正常数据与异常数据的重构误差不能明显分化的问题,本文提出一种能在模型训练过程中最优化参数调整各个机组数据影响比重的隐藏状态共享模块,并结合LSTM-AE 网络结构设计了能有效进行多机组模型联合训练的集成共享框架。基于LSTM-AE集成共享框架结构图如图3。

图3 基于LSTM-AE集成共享框架结构图
2.2.1 数据预处理
同一时间段,邻近风电机组的工况是相似的,因此在同构模型中的隐藏状态信息也是相似的。对SCADA 系统数据按照机组进行分组,并对分组后的数据按照时间戳进行数据对齐,保证在后续联合训练时输入数据在时序上的一致性。
2.2.2 构建集成共享框架
框架包括滑动窗口扩增层、编码层、隐藏状态共享层和解码层;滑动窗口扩增层在输入的每个机组的原始序列T=(S1,S2…Sn)上使用跨度2d,以d为间隔的窗口进行滑动[9],并计算每个窗口区间内向量集合中每向量参数的统计特征与衍生特征作为新的扩增向量得到新的短时相关性扩增时序序列T'=(H1,H2…Hk),统计特征与衍生特征[10]包括均值(MEA)、最大值(MAX)、最小值(MIN)、标准差(STD)、峰间距(P2P)以及三个四分位数,得到的扩增时序序列的特征空间比原始序列大得多,有助于在模型训练过程中自动编码器识别出最具代表性的特征。
编码层与解码层由多个相同结构的LSTM-AE模型的E与D构成,记作ES=(E1,E2…En) 与DS=(D1,D2…Dn)。将机组i经过滑动窗口扩增后的扩增序列输入编码层E中对应的编码器Ei中,编码层中编码器对输入序列进行学习得到隐藏状态,解码层D中的解码器Di接受隐藏状态后对输入序列进行重构得到
隐藏状态共享模块位于在ES与DS中间,分别为ES中的每个E设计一个线性权重矩阵,共享隐藏状态通过叠加每个隐藏状态与对应线性权重矩阵的积组成,具体公式如下:
2.2.3 训练及检测
集成共享框架中参数众多,故在最小化损失函数的过程中,容易出现过拟合现象。本文中集成共享框架损失函数由多个LSTM-AE模型的损失函数叠加,并引入作为惩罚项构成,具体公式如下:
其中lossi表示机组i的基本LSTM-AE模型的损失函数,‖·‖2为L2正则化函数[11],loss表示集成共享框架损失函数,为惩罚项,λ是控制在损失函数中惩罚效果的重要权重。本文中通过在损失函数中添加惩罚项,可有效减小编码器对原始序列的过拟合影响,可以使得解码器更加健壮,在检测阶段,可以使得正常数据与异常数据的重构误差明显分化。
将完成训练后集成共享框架中ES=(E1,E2…En)与DS=(D1,D2…Dn)中的Ei与Di的拆分并按照LSTM-AE 模型的架构,组成机组i的LSTM-AE模型进行异常数据检测。使用机组i经过滑动窗口扩增后的扩增序列作为机组i的LSTM-AE 模型输入,模型输出得到重构序列,计算输入序列与重构序列的误差得到误差向量序列,具体公式如下:
其中 |· |为绝对值函数,ℎj及ℎ'j分别是扩增向量与重构向量中第j个参数。误差向量序列Ei作为机组i的异常指标。
3 清洗与解释
3.1 自适应阈值清洗
针对固定阈值清洗方法没有考虑异常指标与设备工况间的非线性关系具有局限性,容易出现错判与漏判现象。本文通过结合集成共享框架得到的异常指标误差向量序列Ei与重构序列Ri' 之间的非线性关系,采用自适应阈值的方式对SCADA系统数据进行清洗。直接建立两个多维向量间的映射函数难度较大,本文通过建立误差向量序列Ei的多元高斯分布模型Ei~N(μ,∑),使用最大似然法给出模型参数μ和∑的估计量,并计算重构误差的概率密度函数PEi',具体公式如下:
其中g为误差向量维度,得到重构误差概率密度序列PEi=(PE1i,'PE2i'…PEki'),利用AE 网络[12]拟合重构误差概率密度序列PEi与重构序列的映射函数,即期望误差概率密度估计器:
其中WP为拟合AE 网络的权重系数矩阵,bP为其偏移量,f为期望误差概率密度估计函数。
本文通过对比重构值的期望误差概率密度与实际误差的概率密度进行异常的差值进行异常数据清洗,具体公式如下:
其中f(·)为期望误差概率密度估计器,η为设定的误差偏移量。通过设置η,自适应调整误差阈值,若ξ为正,则表示该误差向量所对应的输入向量为异常数据。
3.2 异常原因解释
为确定异常数据中不同性能指标对异常的贡献度,本文通过对比重构误差=(e1,e2…) 中不同性能参数ej与概率密度差值ςi的互信息量Ij(ej;ςi),确定异常关键性能参数,具体公式如下:
其中ej表示在重构误差E'i中的第j个参数,P为分布函数,Ij(ej;ςi)表示该参数在概率密度差值ςi中的互信息量。Ij(ej;ςi)值越大,表明在重构误差中的第j个参数与异常的相关度越高,由此确定异常关键性能参数。
4 实验
4.1 实验设置
4.1.1 实验数据
本文使用的数据集为某风电场群共12 台风电机组全年SCADA 系统数据(来自国家电投)。数据集分为两个部分:风电机组工况数据、风电机组规范参数。其中风电机组的工况数据的采集周期为2017 年11 月-2018 年10 月,采集时间间隔为10min,监测的性能参数为风速、功率以及风轮转速;数据集时序数据共计497837条。
4.1.2 实验参数
本次训练是无监督学习的方式,使用完整数据集作为训练集与验证集。本文使用的网络模型参数设置如下:LSTM 网络步长为20,LSTM 神经单元隐藏状态大小为64,优化器使用Adam,学习效率选用0.01,目标误差选用0.1,AE 网络层数为2,其余参数为默认值。在集成共享框架中,将滑动窗口的步长设置为24,λ设置为0.005。
4.2 结果与分析
4.2.1 异常检测指标精度比较
异常数据得检测是清洗与解释的基石,其输出的异常指标精度直接影响了清洗结果的准确性。为了验证集成共享框架的有效性,本文分别搭建了Bi-RNN[13],SDAE[14]以及LSTM[15]模型作为对照试验,对比检测阶段正常数据与异常数据的重构误差的分化性能,本文通过对比两类数据的重构误差的均方根误差(RMSE)评估模型的异常指标精度,RMSE差值越大,模型精度越好。公式如下:
其中为重构误差。风电机组群的性能指标均值作为最终结果数据如表1。

表1 不同模型的RMSE对比
据表2 可知,LSTM 及LSTM-AE 模型在正常数据与异常数据的分化上性能明显优于Bi-RNN 与SDAE,这体现出LSTM网络对数据时序性较强的学习能力。集成共享框架对比LSTM-AE 模型RMSE差值明显提高,验证了集成共享框架对提升异常检测精度的有效性。
4.2.2 不同阈值清洗结果准确性比较
异常数据清洗算法常见的模型评价指标矩阵如表2。
自适应阈值的性能评估从以下指标中体现:
F值为综合评Precision和Recall的性能指标,越大越好。分别计算固定阈值与自适应阈值下模型清洗的性能评估指标,将风电机组群的性能指标均值作为最终结果如表3。

表3 不同阈值的F 值对比
据表3可知,采用自适应阈值得到的F值明显高于传统的固定阈值的清洗方法,故本文提出的自适应阈值的清洗方法可有效提高对异常数据判定的准确率。
4.2.3 异常关键性能参数识别比较
为验证基于互信息的异常原因解释方法的有效性,根据互信息计算异常数据中不同关键性能参数的占比,结果如图4。

图4 异常关键性能参数比重图
据图4 可知,风速是风电机组的异常关键性能参数。风电机组作为成熟可靠的大型设备,风速作为外在环境变量是导致风电机组工况异常的主要原因,符合预期。风轮转速受调控策略影响,在调控时会出现功率和风轮转速的联合异常,与图4 的计算结果基本相符,且与风电故障诊断研究[16]相符,验证了方法的有效性。
5 结语
本文针对实际应用过程中原始数据的部分机组可能会出现异常数据占整体比重过大的情况及传统固定阈值清洗准确率较低的问题,提出一种基于LSTM-AE集成共享框架的风电机组异常数据检测、清洗与解释方法。通过在训练过程中使用其他机组的数据帮助机组进行模型训练,提高了正常数据与异常数据的重构误差的分化性能,提升了异常检测精度。通过AE网络重构误差的在多元高斯分布中的概率密度与重构值的非线性期望函数设置自适应阈值进行异常数据清洗方法,能根据运行工况自适应调整阈值。通过对比重构误差中不同性能参数与概率密度差值的互信息量,给出了异常关键性能参数,可有效帮助风电机组定位故障原因。下一步将针对数据插补的方式修正异常数据展开深入研究。
猜你喜欢
摄影世界(2022年1期)2022-01-21
数学学习与研究(2020年15期)2020-11-28
知识经济·中国直销(2018年12期)2018-12-29
能源(2018年6期)2018-08-01
能源(2018年6期)2018-08-01
能源(2018年8期)2018-01-15
商周刊(2017年6期)2017-08-22
山东大学法律评论(2016年0期)2016-08-16
风能(2016年12期)2016-02-25
数学年刊A辑(中文版)(2015年1期)2015-10-30
