
面向计算机科学领域的专业实体识别
2023-12-12 04:26张仰森李尚美胡昌秀成琪昊
重庆理工大学学报(自然科学) 2023年11期
陈 祥,张仰森,2,李尚美,胡昌秀,成琪昊
(1.北京信息科技大学 智能信息处理研究所, 北京 100101;2.国家经济安全预警工程北京实验室, 北京 100044)
0 引言
命名实体识别是自然语言处理领域中的一项基础任务,也是开展智能问答、关系抽取、机器翻译等研究任务的基础环节。对于实体本身而言,区别于传统命名实体,领域专业实体是具有领域表征作用的某一领域特有的命名实体。随着建设网络强国战略的提出,计算机科学领域相关技术在人们日常生活中发挥着越来越重要的作用。研究领域的发展与科研活动的开展息息相关,面向计算机科学领域,精准识别领域的专业实体,对科研活动的展开具有技术层面的辅助作用,如为科研项目、学术论文的评审专家推荐提供技术支持。
实现计算机科学领域的科技项目或学术论文的评审专家推荐,关键因素在于尽可能满足专家自身的研究领域与文档涉及的研究领域相匹配的条件。而研究领域信息通常以专业实体的形式表现出来,计算机科学领域的专业实体通常包含在科研专家的学术论文中,同时学术论文的摘要是一篇论文的精华,其高度概括了论文的主要内容。专业实体包含多种类别,其中一类是专家研究领域实体,因此从学术论文的摘要中提取专业实体,是获取专家研究领域信息的关键,以此表征专家的学术研究领域,为后续的评审专家推荐奠定基础。为此,实现对计算机科学领域专业实体的识别具有非常重要的现实意义。
1 相关工作
目前,有关命名实体识别任务的研究大致可以分为2类:一类是针对人名、地名、机构名、时间表达式等传统的命名实体进行识别[1-4];另一类是针对某一特定领域的专业实体进行识别,目前研究较多的特定领域主要包括生物医学[5-7]、军事领域[8-9]等。针对命名实体识别的实现方法可分为基于规则和词典的方法、基于统计机器学习的方法以及基于深度学习的方法。近年来,基于深度学习的方法取得的成果较为显著。冯艳红等[10]提出一种基于BLSTM的神经网络结构的命名实体识别方法,结合基于上下文的词向量和基于字的词向量,有效地利用了文本中命名实体的上下文信息以及组成实体的前缀、后缀和领域信息;李博等[5]提出了一种完全基于注意力机制的Transformer-CRF命名实体识别模型,解决了输入和输出序列对模型识别效果的限制问题;唐国强等[6]采用双向门控循环网络、多头注意力机制和条件随机场相容和的方式,进行实体识别,有效地利用了未标注数据并实现了对文本自身特征进行深入地捕捉;单义栋等[8]以字词向量同时作为模型的输入,利用注意力机制获取特征向量,同时采用维特比算法解码,标注命名实体标签;车金立等[9]基于Bi-GRU-CRF命名实体识别模型,引入军事词语中的词位信息,提出了一种融合词位字向量的命名实体识别方法。王月等[11]使用BERT预训练语言模型,同时引入注意力机制改进BiLSTM-CRF模型,完成命名实体识别任务。语言模型保存了较完整的语义信息,从而提高了模型特征抽取能力。李健龙等[12]基于无监督学习的方式训练军事领域语料进行词语向量表示,采用融入注意力机制的双向LSTM递归神经网络模型完成军事领域命名实体识别任务;曹春萍等[13]面向医学领域,提出了一种卷积神经网络-双向长短期记忆网络-条件随机场相结合的实体识别模型,利用多种尺度卷积核的CNN对识别效果进行改善。
近年来,随着RoBERTa预训练模型的提出,越来越多的学者开始着手于此模型的研究与应用,并以此模型为基础进行命名实体识别任务的研究。张云秋[14]提出了一种基于RoBERTa-wwm动态融合的实体识别模型,提升了对电子病历实体的识别效果。Yin等[15]提出一种基于RoBERTa-wwm的细粒度中文命名实体识别模型,并在公开的CLUENER2020数据集中取得较好的效果。Cui等[16]将RoBERTa模型与卷积注意力机制相融合,以此融合模型开展中文命名实体识别的研究,通过实验验证了该模型的有效性。
综上所述,关于命名实体识别任务的研究正如火如荼地进行着,也取得了显著的成果。然而,目前关于计算机科学领域专业实体的识别任务研究较少,考虑以实现评审专家推荐为最终目的开展此方面研究,通过构建的专业实体识别模型获取专家研究领域的相关信息,对专家进行表征。利用RoBERTa-wwm-BiLSTM-CRF模型对计算机科学领域的学术论文中的专业实体进行识别,通过RoBERTa-wwm预训练模型获取输入文本的字符语义向量,并将其输送下游BiLSTM-CRF模型中实现对专业实体的识别,提升获取计算机科学领域专业实体的有效性和准确性。
2 专业实体识别
面向计算机科学领域专业实体识别的研究方案分为以下2个步骤:专家论文摘要数据的获取与预处理以及专业实体识别模型的构建。
2.1 专家论文摘要数据的获取与预处理
2.1.1摘要数据获取
由于专业实体识别方法是面向中文文本领域的,且中国知网(CNKI)平台中收录了大量学术专家的科研论文,论文内容中涉及的专家研究领域信息较为广泛,同时其行文用词具有很高的权威性和可信度,因此利用网络爬虫工具,爬取中国知网平台的专家论文摘要数据作为实验数据集。在爬取专家的论文摘要数据之前,通过人工的方式从全国各大高校官网中手动地获取一些专家基本信息数据。同时结合实验室已有专家基本信息数据,对两部分专家基本信息数据进行先融合再去除重复、无效数据的处理,最终得到专家基本信息数据表,表中主要包括专家姓名、专家所在高校单位名称等字段。
中国知网平台的高级检索功能给使用者提供了一种能准确查找某位专家论文数据的方法。基于已有的专家基本信息数据表,结合中国知网平台高级检索页面所具备的根据作者名和作者单位进行联合查找的功能,利用网络爬虫技术,对表中的每位专家在知网平台中收录的论文摘要进行爬取,如图1所示。同时,为了尽量避免由于同一所高校中存在专家重名现象而导致获取到的论文摘要与计算机科学领域无关的情况,在爬取论文信息时,以论文所属的分类号为依据对不属于计算机科学领域的摘要文本进行过滤。参考《中国图书馆分类法》中的中国图书分类号信息,爬取论文分类号属于TP18(人工智能理论)、TP24(机器人技术)、TP3(计算技术、计算机技术)的论文摘要文本,过滤其他不包含上述分类号的摘要文本,以此保证摘要数据的可用性。
由于专家撰写论文所标注的单位信息不一定同高校名称完全一致,例如:清华大学丁**副教授在论文中标注的单位信息有“清华大学软件学院”“清华大学北京信息科学与技术国家研究中心”等,并不是“清华大学”,因此在高级检索页面中设置模糊匹配的方式对作者单位进行筛选,以保证爬取的专家论文摘要数据充足而全面。
Selenium WebDriver是开源API集合,可以用于自动测试Web应用程序,并可以在大多数Web浏览器上运行,在爬虫中也有很好的应用。 selenium工具具有简单方便、易于实现、隐匿性强的优点[17]。基于上述说明,设计了基于selenium工具的网络爬虫框架,如图2所示。

图2 基于selenium工具的爬虫框架
2.1.2摘要数据预处理
基于中国知网平台的文献知网节页面内容简洁性的特点,通过上述爬虫框架爬取的数据中不包含广告、不相关信息等噪声数据。经观察,在爬取的论文摘要数据中不同摘要的文本长度不尽相同,甚至存在2条摘要的文本字数相差几百的情况。这就可能导致后续对文本向量化处理时需要过多地“补0”,从而影响整体的实验效果。因此,在进行预处理时,以摘要文本的“。”或者“.”为分隔符,对摘要进行切分,以句子作为后续数据标注和文本向量化的基本单位。
2.2 专业实体识别模型的构建
2.2.1RoBERTa-wwm-ext-large预训练模型
基于迁移学习的思想,预训练模型最开始是在图像领域提出的,且获得了良好的效果,近年被广泛应用到自然语言处理各项任务中。目前,BERT模型是使用较为广泛的一种预训练语言模型,其于2018年10月由Google AI研究院提出[14]。BERT预训练模型一经问世,就因其在不同NLP任务中都取得了较为突出的成果而备受广大NLP学者的关注。基础的BERT模型基于默认的12层Transformer Encoder对输入进行编码,同时创造性地使用MLM(masked language modeling)和NSP(next sentence prediction)2种方式对模型进行训练,使得BERT模型具有理解长序列上下文关系的能力和强大的表征能力。
近年来,对于基础BERT模型的改进研究也层出不穷,实验所使用的RoBERTa-wwm-ext-large预训练模型是由哈工大讯飞联合实验室发布的改进模型。相比于基础BERT的模型,RoBERTa模型的改进之处在于具有更多的模型参数、更大的Batch Size、更充足的训练数据,同时在模型训练过程中去除NSP任务。RaBERTa模型采用动态掩码的方式代替静态掩码,通过复制原始语料,每一份语料随机选择15%的Token,对其按照[mask]、replace、keep分别为80%、10%、10%的占比方式进行mask处理,增强模型的表征能力。
RoBERTa预训练模型结构如图3所示。RoBERTa的输入为每一个Token对应的表征,而每一个Token表征由Token Embeddings、Segment Embeddings、Position Embeddings 3部分组成,如图4所示。在将Token表征送入RoBERTa模型之前,在输入序列之前添加[CLS]标签,为RoBERTa最后一个Transformer层的输出所用,同时使用[SEP]标签对输入的句子进行分割。输入的Token表征经Transformer Encoder层和动态掩码MLM层后得到相应的输出。C为[CLS]标签对应最后一个Transformer的输出,Ti(i=1,…,N)则代表其他Token对应最后一个Transformer的输出。在命名实体识别(named entity recognition,NER)任务中,只把部分内容作为下游神经网络的输入。

图4 Token表征构成图
wwm(whole word masking)表示对语料的词进行mask处理,而BERT模型的mask处理则是针对字而言的,RoBERTa-wwm在一定程度上提高了模型的学习能力。
实验使用的RoBERTa-wwm-ext-large是支持中文的RoBERTa-like BERT模型,采用全词遮罩wwm技术,直接采用最大长度512进行训练,预训练数据集包括中文维基百科、百科、新闻、问答等,该模型集成了RoBERTa模型和BERT-wwm模型的优点,具有较好的可用性。
2.2.2BiLSTM-CRF模型
随着近些年深度学习技术不断发展与成熟,越来越来多深度学习模型被应用于实际的NLP任务中。循环神经网络(recurrent neural network,RNN)就是一种典型的深度学习模型,其可以处理时间序列信息,通过“记忆”将序列前后信息关联起来。但是在RNN模型训练的过程中容易产生梯度消失和梯度爆炸的问题,从而导致RNN无法很好地学习到时序数据的长期依赖关系。而长短时记忆网络(long short-term memory,LSTM)引入“门”机制,通过控制特征的流通和损失解决RNN模型存在的问题。单个LSTM单元如图5所示。

图5 LSTM单元结构图
LSTM通过“忘记门”ft、“更新门”it、“输出门”ot实现对信息的选择记忆,过滤噪声信息,减轻记忆负担。LSTM内部的前向传播公式如下:
(1)
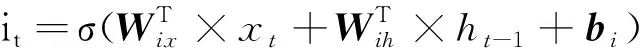
(2)

(3)

(4)
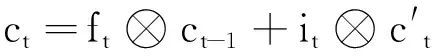
(5)
ht=ot⊗tanh(ct)
(6)

(7)

LSTM往往关注的是上文所传递的信息,从而忽略了当前输入的下文信息,这在一些NLP任务中存在着一定的局限性,如NER任务。为了充分考虑上下文信息对模型输出结果的影响,相关学者设计了将一个输入序列同时连接前向LSTM层和后向LSTM层的BiLSTM深度学习模型。BiLSTM模型将2层网络的隐含层连接起来,共同传递至输出层进行结果预测。
BiLSTM模型只选择标签分数最高的一类标签作为输出,没有考虑到标签与标签之间的内联系和依赖关系,很可能输出不符合常理的无效标签序列,因此单独的BiLSTM模型在NER任务中往往不能取得很好的效果,通常需结合CRF算法共同使用。CRF是一种序列标注算法,在最终输出预测标签之前自动学习并添加标签的约束条件,考虑标签与标签之间的关联性,提高模型输出标签序列的有效性。
CRF接受如X=(x1,x2,…,xn)的输入序列,得到如Y=(y1,y2,…,yn)的输出序列,在NER任务中得到输出结果为模型预测标签序列。输出序列得分的计算公式如下:
(8)
式中:S表示得分;Ayi,yi+1表示从yi到yi+1的转移概率矩阵;Pi,yi表示softmax函数在第i个位置输出yi的概率。在输入序列为X的条件下,预测序列Y的softmax归一化概率计算公式如下:
(9)
式中:P(Y|X)表示在X条件下输出Y的概率;Y′表 示所有标签集合;y′表示真实标签。型损失值loss通过如下公式进行计算:
(10)
最后,计算得到最优标签序列:
y*=arg max(S(X,y′))
(11)
2.2.3模型整体框架
采用RoBERTa-wwm-BiLSTM-CRF联合模型对计算机科学领域的专业实体识别任务进行分析研究,优化BERT预训练模型的语义表征能力,模型框架如图6所示。
将专家论文摘要文本以字为单位进行切分并添加索引,随后将切分后的索引格式文本序列输入RoBERTa-wwm层,获取RoBERTa-wwm层输出的每个位置表示。之后,将各层文本表示信息输入BiLSTM模型,对序列特征信息进行初步获取。最后,利用CRF层处理得到最后的预测序列表示。综上步骤,完成对计算机科学领域专业实体的识别任务。
3 模型验证及实验结果分析
3.1 实验数据集
以爬虫获取的论文摘要数据作为实验数据,采用《计算机科学技术百科全书》中的学科名词及经人工校对后的论文关键词作为标注词,对摘要数据中的计算机领域专业名词进行人工标注。由于目前暂未出现计算机科学领域专业实体的公开数据集,因此以自行标注的数据完成模型的训练与测评。实体采用“BIO”标注方式,“B”表示实体词的开始位置,“I”表示实体词的中部位置,“O”表示非实体词部分。通过对论文摘要中出现的专业名词进行分析,人为地将专业名词实体分为3类,分别是科研方向实体(表述计算机科学领域专家研究方向的专业名词实体,如人工智能)、概念名称实体(表述计算机科学领域某种概念的专业名词实体,如鲁棒性)、技术名称实体(表明进行学术研究所用技术的专业名词实体,如BERT)。由此,所使用的数据集对应的标签集合为:{O、B-sde、I-sde、B-coe、B-tce、I-tce}。其中,sde代表科研方向实体,coe代表概念名称实体,tce代表技术名称实体。
实验数据集*为6 512篇计算机科学领域专家学术论文摘要,并将数据集划分为训练集与测试集。其中,训练集中共5 000篇论文摘要文本,共25 635条句子;测试集中共1 512篇论文摘要文本,共6 278条句子。实体种类与具体数量如表1所示。

表1 数据实体种类与数量
3.2 评测标准
采用实体识别精确率(Precision)、实体识别召回率(Recall)、实体识别F1值(F1-Score)3个指标来进行专业实体识别模型的评价,具体计算公式如表2所示。

表2 评价指标
其中,P为模型识别专业实体的精确率,R为模型识别专业实体的召回率,TP表示正确识别实体的数量,FP表示错误识别实体的数量,FN表示未能被识别实体的数量。
3.3 实验及结果分析
为了验证模型的有效性,设置了不同命名实体识别模型在同一数据集有关识别效果的对比实验。实验所用环境及模型相关参数分别如表3、表4所示。

表3 实验环境

表4 模型主要参数
在训练过程中,设置预训练模型微调学习率的大小为5×10-5,在下游模型中设置学习速率的大小为1×10-3。
实验选取了BiLSTM-CRF模型、BERT-BiLSTM-CRF模型、BERT-wwm-BiLSTM-CRF模型作为对照模型,同所提优化模型进行比较。其中,BiLSTM-CRF模型属于经典的NER模型,后续的拓展模型大多在其基础上进行改进与优化,此模型没有使用预训练模型,采用静态词向量的方式进行训练。BERT-BiLSTM-CRF模型在BiLSTM-CRF模型引入预训练模型获得包含语义信息的字符向量,再同下游模型连接完成命名实体识别的任务。在一些研究中,该模型取得了不错的效果。BERT-wwm-BiLSTM-CRF模型在BERT模型字符级掩码的基础上提出词语级掩码的概念,并通过词语掩码的方式训练模型,实现了对模型的进一步优化。文本模型在BERT模型的基础上,使用RoBERTa预训练模型获取字符向量,此预训练模型凭借动态掩码的训练方式以及更丰富的训练参数和语料,同时结合了wwm机制的优点,进一步提高了模型的泛化能力。通过对比实验,得到了基于实验数据集各模型对专业实体的识别效果,实验结果如表5所示。
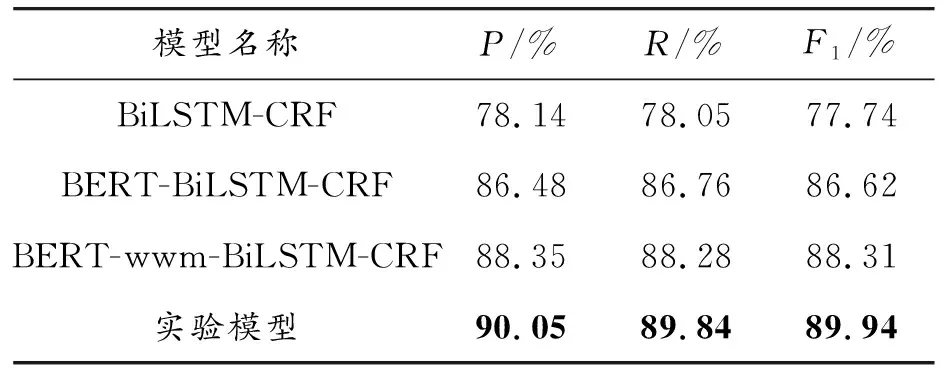
表5 各模型在实验数据集上的专业实体识别情况
实验结果表明,在自主标注的数据集上,加入BERT预训练模型后对专业实体的识别效果相较于传统的BiLSTM-CRF模型而言具有较为明显的提升,F1值提高了8.88%。在BERT模型中融入wwm机制后,其识别的精确率、召回率、F1值均有所提升,说明模型获取文本语义信息的能力有所增强,体现了wwm机制的有效性。从具体数值看,相较于BERT-BiLSTM-CRF模型,BERT-wwm-BiLSTM-CRF模型识别的准确率提升1.87%、召回率提升1.52%、F1值提升1.69%,引入wwm机制有助于下游任务的效果提升。
为了验证动态掩码机制在提高模型识别效果方面的有效性,实验中用此模型(RoBERTa-wwm-BiLSTM-CRF)与BERT-wwm-BiLSTM-CRF模型进行对比实验。从表5可以看出,文本模型在识别精确率、召回率、F1值3项指标上均有所提升,具体分别提升了1.70%、1.56%、1.63%,说明了RoBERTa 动态掩码机制的有效性。实验模型在BERT模型的基础上,将动态掩码与词语级掩码机制相结合,在一定程度上使得预训练模型的输出结果具有更丰富的语义表示,提高了模型的泛化能力,可更好地为下游任务服务,有助于提高识别专业实体的效果。
4 结论
面向计算机科学领域,针对专业实体识别任务构建了一种RoBERTa-wwm-BiLSTM-CRF的联合模型,对模型的有效性在自主标注的数据集上进行了实验验证。同时,在实验中设置3个对照模型与实验模型相对比,得到如下结论:
1) BERT预训练模型的引入使得在NER任务的上游获得了字符级的语义表示,将其送入 BiLSTM-CRF模型后在一定程度上提高了对专业实体识别的效果。
2) wwm机制的引入提高了预训练模型的泛化能力,相较于字符级掩码策略,wwm机制在NER任务上具有更好的实际效果和使用价值。
3) RoBERTa的动态掩码策略提高了模型适应掩码策略的能力和模型学习能力,将RoBERTa的动态掩码策略与wwm方式结合,能获取更丰富的语义表示,在连接下游的BiLSTM-CRF基础模型后,总体上提升了对专业实体的识别准确性,在对比实验中取得了最好的效果。
此外,实验数据集存在不同实体类别数量的不均衡问题。例如技术名称实体数量较其他2类偏少,也在一定程度上导致了对该类实体识别效果劣于其他2类实体的结果。未来的工作中需要针对上述问题提出进一步的改进策略,处理数据不均衡的问题,提升对计算机科学领域专业实体的识别效果。
猜你喜欢
中国外汇(2019年18期)2019-11-25
建材发展导向(2019年10期)2019-08-24
通信学报(2019年5期)2019-06-11
通信技术(2018年3期)2018-03-21
哲学评论(2017年1期)2017-07-31
电子制作(2017年2期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
重庆第二师范学院学报(2017年1期)2017-03-09
浙江大学学报(工学版)(2015年4期)2015-03-01
