
多流残差网络结合改进SVM模型的面部表情识别
2023-12-12 04:26郝秉华
重庆理工大学学报(自然科学) 2023年11期
郝秉华,吴 华
(内蒙古财经大学 计算机信息管理学院, 呼和浩特 100010)
0 引言
随着科技迅速发展,基于人工智能(artificial intelligence,AI)技术的目标识别算法不断更新,其中,面部表情识别技术作为人机交互的重要组成部分,已被广泛应用到生物识别、临床检测、课堂检测等领域[1]。但面部表情比正常的目标识别更复杂,需要更细粒度的特征学习能力来保证识别精度,导致现存的AI识别算法难以取得预期效果。因此,实现基于AI算法的面部表情稳定识别仍是一个充满挑战的任务。
目前,面部表情识别算法主要分为基于传统的识别方法和基于AI技术的深度学习算法。传统方法包括特征提取及特征分类两方面[2],主流算法有主成分分析(principal component analysis,PCA)、局部二值(local binary pattern,LBP)特征、光流法、几何法等。例如,钱勇生等[3]提出结合LGRP(local gabor rank pattern,LGRP)与多特征融合方法识别面部表情,该方法首先提取输入图像的Gabor多方向与多尺度特征,然后引入Otsu阈值及Hear小波分割法进一步提取表情特征,最后进行分类并输出结果;Bougourzi等[4]提出基于融合变换深浅特征的面部表情识别算法,通过将PCA变换后的深层与手工特征结合,实现对静态图像中6个基本面部表情的识别;胡敏等[5]提出一种基于几何和纹理特征的表情层级分类方法,利用表情特征自身分布规律对其进行识别判定。虽然传统方法可识别基本的面部表情,但大多忽略了对图像的预处理操作,导致识别错误率较高且耗时长[6]。
随着人工智能技术的不断更新,大量学者提出基于深度学习的面部表情识别算法,主要流程包括图像预处理、特征提取及表情结果分类等阶段。Rajan等[7]提出基于最大增强卷积神经网络(convolutional neural network,CNN)和长短记忆网络(long short-term memory,LSTM)的人脸表情识别网络,首先对输入图像进行预处理,消除照明差异、保留细微特征,后使用卷积神经网络提取特征,最后将特征图与LSTM层结合并输出结果。杨鼎康等[8]提出集成网络模型,使用多种网络获得不同语义的特征并将其融合,提高模型学习能力,同时使用对抗网络生成特定表情图像,以平衡数据分布。宋玉琴等[9]提出嵌入注意力机制和多尺度的表情识别算法,通过叠加不同尺寸的卷积提取多尺度特征,利用空间通道注意力机制提高特征表达能力,有效提升识别算法的准确率。虽然上述研究方法大多都能够提取表情特征,但针对表情细微特征的区分能力仍然较差,导致对相似表情特征之间的识别精度不稳定。
针对上述问题,本文中提出一种多流交互残差结合改进SVM模型的面部表情识别算法。首先,为防止输入图像信息缺失导致算法识别率低,提出一种自适应多流信息增强模块(adaptive multi-stream information enhancement module,AM-SIEM)预处理输入图像,并增强面部表情特征,降低网络参数;其次,在特征提取阶段提出残差交互融合模块(residual interactive fusion module,RIFM),进一步从多流信息中提取面部表情特征,突出关键识别信息;最后,使用改进支持向量机方法来分类面部表情,进一步提高算法的准确度及鲁棒性。
1 理论基础
1.1 残差网络
深度学习网络的特征提取能力与精度会随着网络加深而提高,然而当层级达到一定程度时,训练与测试精度会迅速下滑,导致网络性能下降[10]。为此,He等[11]提出一种残差网络ResNets(residual networks),将残差连接应用于深度网络时,可良好地改善训练过程中因梯度消失而导致的网络性能下降问题。如图1所示,将输入直接添加到输出中,使高层专注于残差部分学习,避免低层特征丢失导致模型退化。输出如式(1)所示。
Y=F(X)+X
(1)
式中:X、Y分别为输入、输出;F(·)为网络内部处理结果。

图1 残差网络模型
1.2 支持向量机模型
支持向量机(SVM)是一种用于分类和回归的模型,其主要原理为求解如式(2)所示的凸二次规划问题[12]。
(2)
式中:αi与αj分别为第i和j个样本的拉格朗日因子;C为惩罚参数;x、y为样本与类别的向量值;K(xi,xj)为核函数。由式(2)得到最优解α*,再进一步由式(3)得到位移项b*。
(3)
最终,对于采用高斯核函数的支持向量机分类决策函数如式(4)所示,其中x代表新的观测数据。
(4)
2 本文算法
2.1 整体框架
本文中设计了一种结合深度学习与SVM的面部表情识别算法,结构如图2所示。相比传统算法,本文方法利用深度学习技术进行特征提取,在泛化能力和鲁棒性等方面有着传统方法不具备的优势。相比普通的深度学习算法,本文使用SVM进行表情分类,模型可解释性强,便于调整参数,且SVM具有较少的超参数,模型更加稳定,不容易过拟合。
当图像输入到网络时,首先经过自适应多流信息增强模块,增强面部表情图像的多流空间信息,并提升特征关联程度;然后将处理后的特征图传输到残差交互融合模块,进一步对其进行交互提取,突出面部关键特征;最后使用改进的支持向量机进行分类。下面将详细介绍各模块。

图2 本文网络框架
2.2 自适应多流信息增强模块
为确保信息完整的同时增强输入图像的特征,提出自适应多流信息增强模块(adaptive multi-stream information enhancement module,AM-SIEM),该模块由多流信息收集模块(multi-stream information collection module,M-SICM)和权重注意模块(weighted attention module,WAM)组成,结构如图3所示。

图3 自适应多流信息增强模块
图3(a)为多流信息收集模块,该模块包括3条分支,每条分支主要由批量归一化层(batch normalization,BN)、卷积核(Conv)、激活函数(ReLU)组成。BN层主要用于将输入图像的特征值调整到相近范围,防止因特征值差距过大导致梯度消失,提高信息表征能力[13]。经过归一化处理后,将特征图输入到3条分支,即分别使用1×1、3×3、5×5大小卷积来收集不同尺度的多流空间特征信息。其中,1×1卷积单元主要收集图像的细微特征,5×5卷积单元用于扩大感受野,3×3卷积单元则作为本文网络的主干分支,传输主要信息。最后使用ReLU激活函数输出,确保信息稳定输出。ReLU激活函数公式如下。
(5)
由式(5)可以看出,当输入大于零时,函数可有效维持原有输出,当输入小于零时,输出为零,因此,该函数在一定程度上可抑制无效特征。为防止单一卷积导致收集信息不完整的问题,在激活函数后使用元素相乘的操作将大尺度特征结合到邻级小尺度中,提高信息关联程度的同时进一步扩大小尺度特征的感受野。然后使用Conv-ReLU结构降低维度,缓解学习压力。
受自注意力网络[14]启发,提出的权重注意力模块如图3(b)所示,该模块由L1和L22条分支组成,能够将L1特征权重转移到L2主干分支中。首先,为避免L2分支的主干特征权重较大而抑制其他分支权重,使用平均池化(Average pooling)来对其进行平滑处理,如式(6)所示。
(6)
式中:R为特征值的个数;vn为对应特征值。
使用与主干网络和邻级分支大小相等的卷积单元提高对应分支的特征维度;将ReLU和Sigmoid激活函数结合,不仅可以抑制无用信息,还可以利用Sigmoid激活函数特征转移权重,如式(7)所示。
(7)
图3(b)中的i、j分别代表不同分支下特征权重注意力中的卷积核大小,设置规则如下:
Algorithm1: Convolution kernel size setting rules
Input: Connect=I1,I2,I3;
Output:i,j;
If Connect==I1:
i=1,j=1;
If Connect==I2:
i=1,j=3;
If Connect==I3:
i=3,j=5;
Return:i,j
此外,当模块连接I1时,L1分支输入为单位矩阵。
2.3 残差交互模块
在面部表情图像信息增强的基础上,设计一种残差交互模块来提取面部特征,包括深度提取模块(deep extraction module,DEM)和残差交互机制(interactive residual mechanism),结构如图4所示。

图4 残差交互模块
图4(a)为深度提取模块结构,首先,该模块使用Conv-ReLU结构对输入特征进行初步处理,减少特征通道数量,缓解网络学习压力;其次,由于最大池化(Maxpooling)操作在提取图像深度特征时会损失少量信息[15],因此,分别将3条过滤器大小为2×2、4×4、6×6的最大池化并联来增强图像特征,并将输入特征与最大池化结果使用拼接层(Concat)融合,避免信息丢失;最后,使用卷积单元减小特征图像通道,提取图像的深度特征。该模块最终使用SiLU激活函数输出,相比于ReLU激活函数,SiLU对于负样本权重的影响进行一定程度的减弱,而不是直接赋值为零,因此可以保留更多信息[16],公式为:
(8)
图4(b)为残差交互机制结构,该结构输入为3条附带面部表情的特征流,将3条特征数据流拼接成一个整体,增加特征之间的关联性;通过卷积和激活的操作提取多条特征流之间的交互特征,计算多流特征之间的联系;将交互特征与各个原分支的特征进行相加,重新融合并赋予对应分支特征。该机制能输出对应分支所提取的空间尺度特征,提高后续判断和分类的准确率。考虑到每个分支得到的特征不同,因此在第一层使用Leaky ReLU函数,避免因特征梯度过大导致神经元死亡。第二层使用Sigmoid函数作为最终输出,防止信息丢失。
2.4 改进的支持向量机
为提高网络对多个小样本分类任务的准确度,选择使用支持向量机来保证表情分类的准确性,该方法优于传统的Softmax方法,相比决策树更不容易过拟合。但由于传统支持向量机分类方法大多采用“一对多”的方式,容错率低。考虑到本文对预处理和特征提取阶段的网络设计,将其改进为“三对多取大”的方式提高分类的容错率。改进后的算法流程如图5所示。
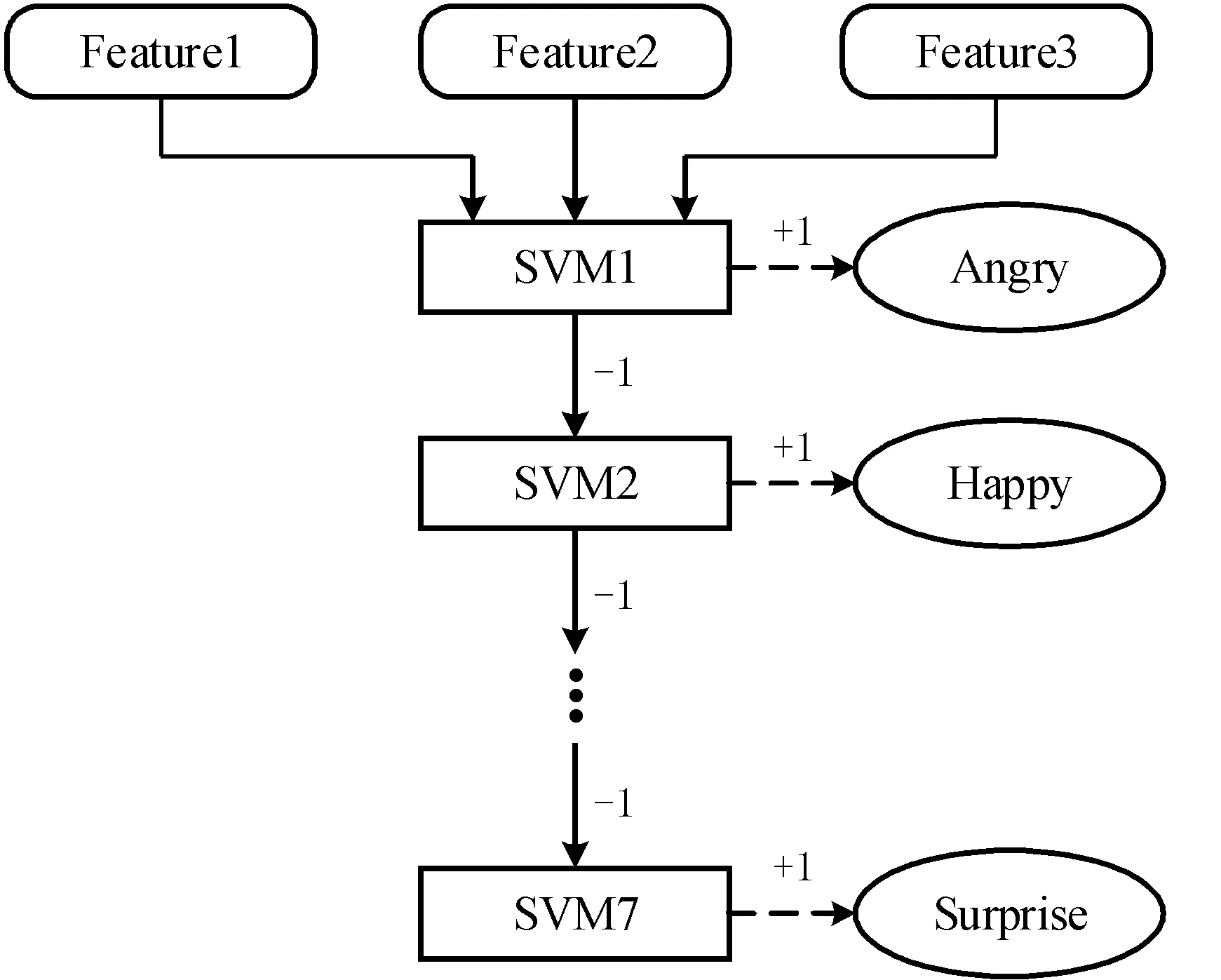
图5 改进后的SVM算法流程
以CK+[17]数据集为例,将面部表情分为7类,并构造7个子分类器,训练对应分类器模型。当3个特征图输入时,算法流程如下。
步骤1:将特征图1、2、3依次传入对应子分类器来判断特征图是否为真,若判断为真,则对应样本数值+1,其余样本数值-1。
步骤2:判断3条分支的特征图是否全部计算完毕,如果计算完毕,则比较7个样本数值大小,输出最大数值对应的样本。否则,继续输入特征图进行计算。
3 实验结果和分析
本实验环境为:GPU为GeForce RTX 3090,CPU为Inter(R) i9-12900H,Unbuntu20.04系统,Pytorch1.10.1框架。训练网络时,批量大小(Batch Size)设置为8,优化器为Adam,动态学习率设置为10-6~10-3。SVM中C值取1,σ2取1。当网络训练到85epoch时,网络达到最优。
3.1 实验数据集
为证明深度SVM模型面部表情识别算法的有效性,选择在CK+、FER2013[18]及JAFFE[19]数据集上进行实验。其中,CK+数据集包括123名参与者在各种环境下的表情变化,表情示例如图6(a)所示;JAFFE数据集由10位参与者在规范控制条件下获得213张表情图像,示例如图6(b)所示;FER2013数据集共有35 887张图像,选取30 000张作为训练集,3 000张作为测试集,示例如图6(c)所示,该数据集包括姿态、旋转、光照等一系列挑战,因此本文及对比算法在此数据集上的识别率总体较低。

图6 数据集图像示例
3.2 消融实验
为验证所提模块的有效性,在JAFFE数据集中进行消融实验,结果如图7所示。
MSIR表示含有自适应多流信息增强模块、残差交互模块及改进后的支持向量机算法的原始网络;MSIR_AM-SIEM表示去掉自适应多流信息增强模块的网络;MSIR_RIM为去掉残差交互模块后的网络;MSIR_SVM表示不使用支持向量机算法(使用softmax损失函数代替)后的网络。可以看出,原始网络在训练76epoch后逐渐平稳,85epoch左右网络识别率达到最高值。由于MSIR_AM-SIEM去掉了自适应多流信息增强模块,仅通过输入图像来提取特征,导致其训练时波动较大,可以证明自适应多流信息增强模块的有效性。MSIR_RIM的准确率最低,此外,使用Softmax的MSIR_SVM准确率也比使用SVM的准确率低,进一步证明了改进后的支持向量机算法可以提高网络的识别能力,增强鲁棒性。

图7 消融实验曲线
3.3 数据集结果对比分析
为了证明本文方法的泛化能力,分别在CK+、FER2013、JAFFE数据集进行测试,对比算法如下:DAM-CNN[20]、VGG19[21]、ResNet50[11]、Xception算法[22]、文献[23-28]的方法,除VGG19、ResNet50、Xception外的实验结果均取自原论文。结果如表1所示。
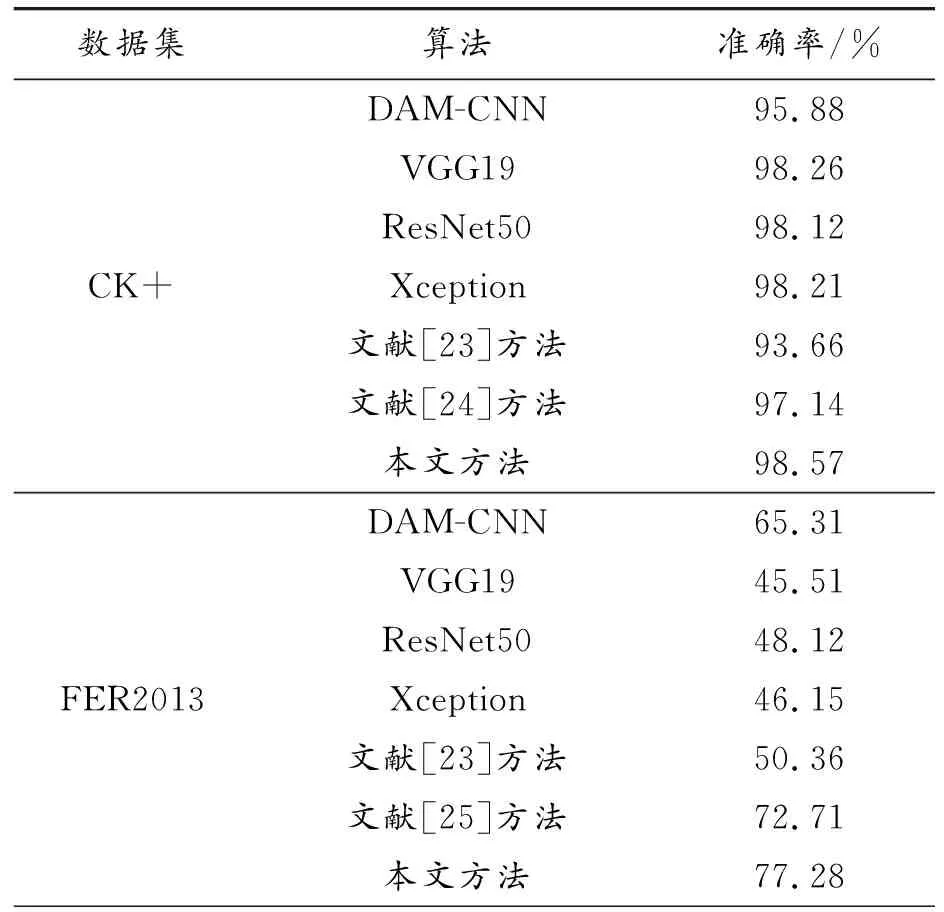
表1 标准数据集下实验结果

续表(表1)
由表1可以看出,在CK+数据集中,所提算法的准确率达到98.57%,比经典的DAM-CNN、结合关键点和金字塔卷积算法高出1.43%~2.69%,且均优于新颖的深度学习算法;在FER2013和JAFFE数据集中,本文算法的准确率分别为77.28%、96.24%,证明了所提出的自适应多流信息增强模块可以增强面部表情信息,提高表情的辨识度。残差交互模块可以更好地融合面部信息,SVM能提高模型对面部表情识别的鲁棒性。
3.4 表情实验分析
为了验证所提算法辨识表情的稳定性,在CK+数据集中挑选了100张识别难度较高的表情图像进行测试,得到的结果如图8所示。
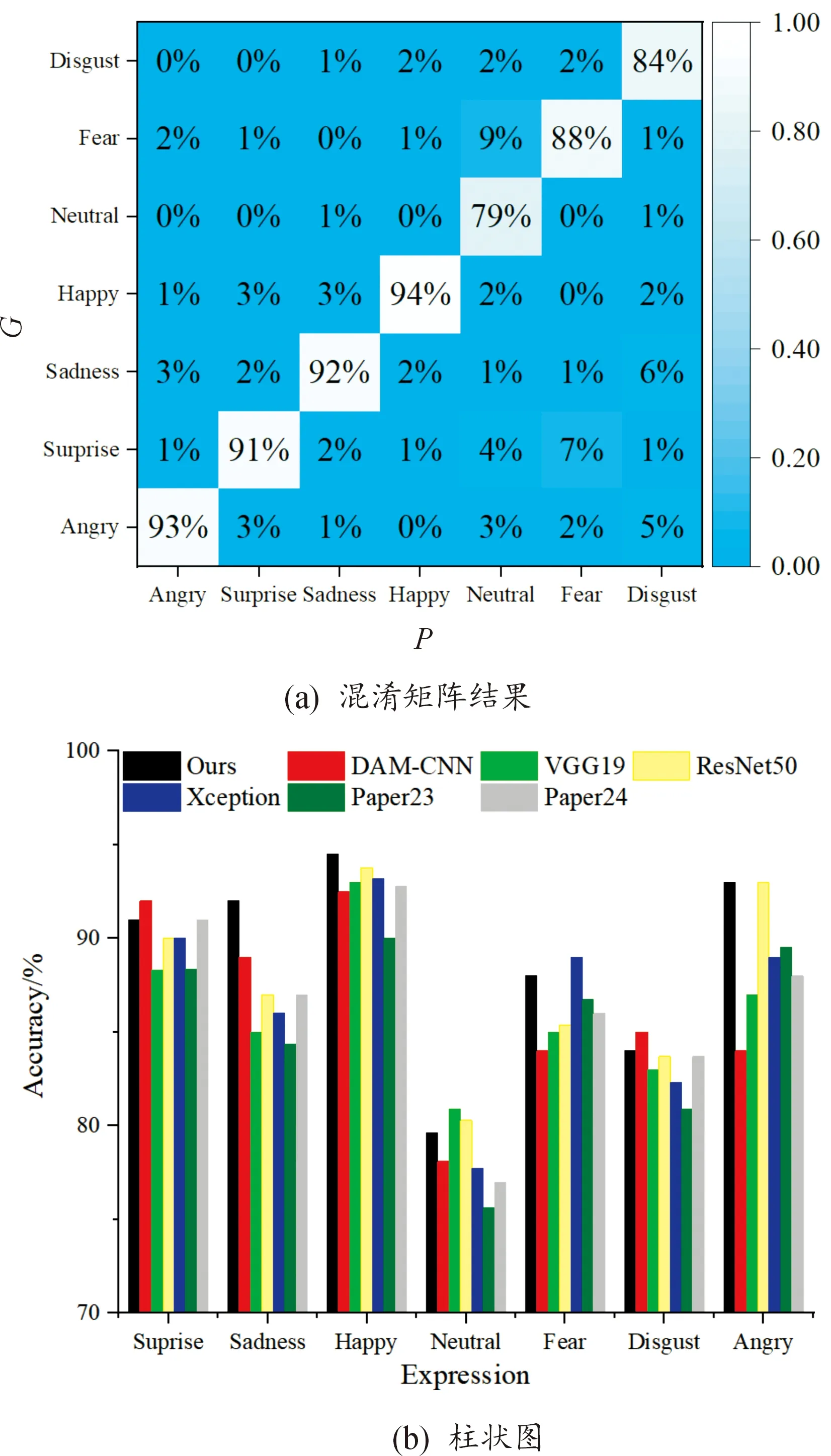
图8 表情测试结果
图8(a)为混淆矩阵结果,其中G为真实值,P为预测结果,可以看出,算法对“高兴”表情的识别准确率最高,达到94%;对“中立”“恐惧”“厌恶”表情的识别准确率较低,分别为79%、88%、84%。为了更直观地展示本文算法在7个表情上的判断能力,得到的柱状图如图8(b)所示,可以看出本文算法对“生气”“惊讶”“悲伤”“高兴”表情的判断能力比较稳定,而对“中立”“厌恶”的判断能力较弱,主要原因可能为:① 由于目前缺少公开的表情数据集,本文挑选的数据存在一定误差,导致不同表情存在相似特征,降低了对相似表情的识别准确率;② 由于该实验是在正常数据集训练得到的权重来对表情进行测试的,因此对相近表情的辨识度较低;③ 每个参与者的面部特征均有差异,存在某参与者的“中立”表情相似于其他参与者的非中立表情,因此导致本文算法判断失误。
3.5 算法轻量化分析
为了评估本文算法对输入表情图像的预测速度,分别将所提网络与VGG19、ResNet50、Xception算法在相同环境下训练出对应预训练模型,然后选取100张面部表情图像进行预测,得到的平均参数量与预测时间如表2所示。
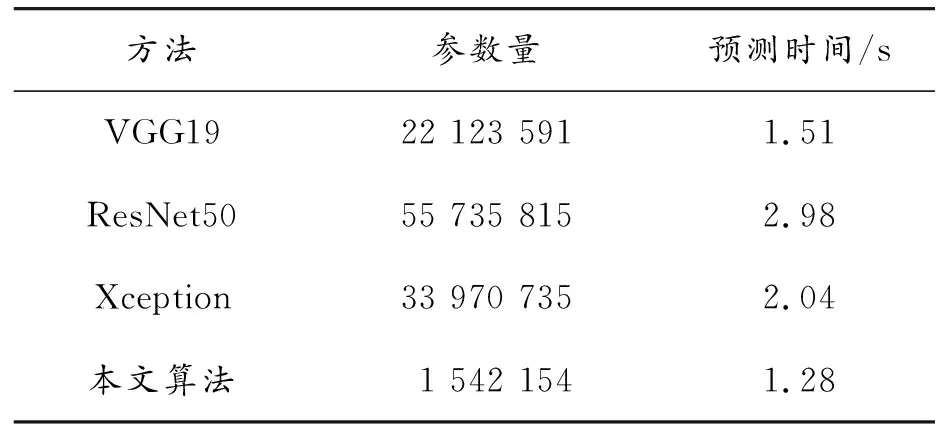
表2 平均参数量与预测时间
从表2可以看出,相较于对比算法,本文算法的参数量仅为1.5 M,这是因为表情识别属于小样本识别任务,对模型规模没有严格要求,因此本文在深度学习模型的通道数和深度方面作了一定的缩小。除此之外,本文算法采用SVM进行分类,相比其他方法使用全连接层,SVM参数要少很多。平均预测时间为1.28 s,优于以上对比算法,计算时间主要消耗在SVM分类方面,因为SVM不适合使用GPU计算,因此消耗了一定的时间,但总体上能够证明所提算法在保证准确率较高的前提下实现了网络模型的轻量化任务。
4 结论
针对现存算法难以稳定识别面部表情的问题,提出一种多流交互残差结合改进SVM模型的面部表情识别算法,提出的自适应多流信息增强模块可以增强面部表情图像的关键特征信息,提升信息间关联程度;残差交互模块可以进一步突出面部表情,提高识别准确率;改进的支持向量机方法使用3条分支特征判别表情类别,提高算法的鲁棒性。大量实验结果证明,该算法在CK+、FER2013、JAFFE数据集中的测评指标均优于现存的经典及新颖算法,网络模型在参数量及预测速度上更具优势,具有更可观的实用价值。然而,由于目前缺少公开的面部表情数据集,导致本文算法在表情实验中,对“中立”“厌恶”表情的判断能力较弱,在后续工作中将进一步提升网络对相似表情的判断能力。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
