
高速列车零部件知识图谱的智能问答知识子图匹配研究
2024-01-08 04:16曾文驱马自力王淑营
铁路计算机应用 2023年12期
曾文驱,马自力,王淑营
(1.西南交通大学 机械工程学院,成都 610031;2.广州地铁设计研究院股份有限公司,广州 130062;3.西南交通大学 计算机与人工智能学院,成都 611756)
知识图谱的智能问答中最关键的一步是识别用户的问句意图,并根据意图进行知识图谱中知识的定位。但高速列车零部件知识存在海量、复杂及多层级性的特点,高速列车零部件知识图谱智能问答系统(简称:问答系统)如果不经由知识的筛选,直接由意图识别模型进行知识定位,会增加检索的复杂度,影响知识图谱智能问答的效果,所以,应先通过知识子图匹配模型进行知识的筛选。知识子图就是知识图谱中与问句相关的部分知识所构成的子图谱。高速列车零部件知识依据情景可被划分为不同知识域,因此,可设定知识子图匹配的目标是将用户问句定位到所属知识域,并将该知识域所包含的知识作为用户问句相关的知识子图,剔除其他知识域的无关知识。依据该思路,可采用分类模型进行用户问句所属知识域的划分,而分类模型的改进则需要依靠情景感知,并基于用户当前所处环境下的情景信息。
国内外研究人员针对如何利用情景感知改进分类模型,从而实现知识子图匹配,展开了众多研究。情景感知研究的核心课题是情景模型的构建。Sheng等人[1]提出了一种面向情景感知的Web 服务的建模语言ContextUML;GuermaH 等人[2]探索了一种以本体为核心的情景感知服务模式,聚焦于情景元模型的构建与推理过程;SOCAM[3]是一种基于情境感知技术的系统架构,可有效帮助场景的捕获、识别、理解及使用功能;周维琴等人[4]改进了感知机制,依据AutoCAD 的特点研究了一种实用性更好的感知模型。目前,应用较为广泛的文本分类模型有Text-CNN 模型[5]、Bilstm-CRF 模型[6]、BERT(Bidirectional Encoder Representation from Transformers)模型[7],三者中效果最好的是BERT 模型,所以选用该模型作为本文的分类模型,但分类模型如果不结合领域情景信息,其效果在知识子图匹配这样的领域任务中会大打折扣。
因此,本文将情景感知与分类模型相结合,构建高速列车零部件知识图谱智能问答知识子图匹配模型(简称:知识子图匹配模型),将问句的情景因素转化成向量,输入到BERT 模型内,从而完成知识子图匹配。
1 高速列车零部件知识图谱
高速列车零部件知识图谱构建流程包括本体构建、知识抽取、知识融合及知识存储等。即先构建高速列车零部件知识本体,再整理数据集,从这些数据集中抽取知识,并将其按知识本体组装成知识三元组后,存进Neo4j 图形数据库,从而得到高速列车零部件知识图谱。本文抽取的数据集包含14282条数据,其中,7728 条高速列车零部件运行维护(简称:运维)数据、3991 条高速列车零部件设计需求数据、2563 条高速列车零部件设计参数数据。最终构成知识图谱共包含节点19781 个、关系15003 条、知识三元组 18835 个。高速列车零部件知识图谱的知识本体结构如图1 所示。
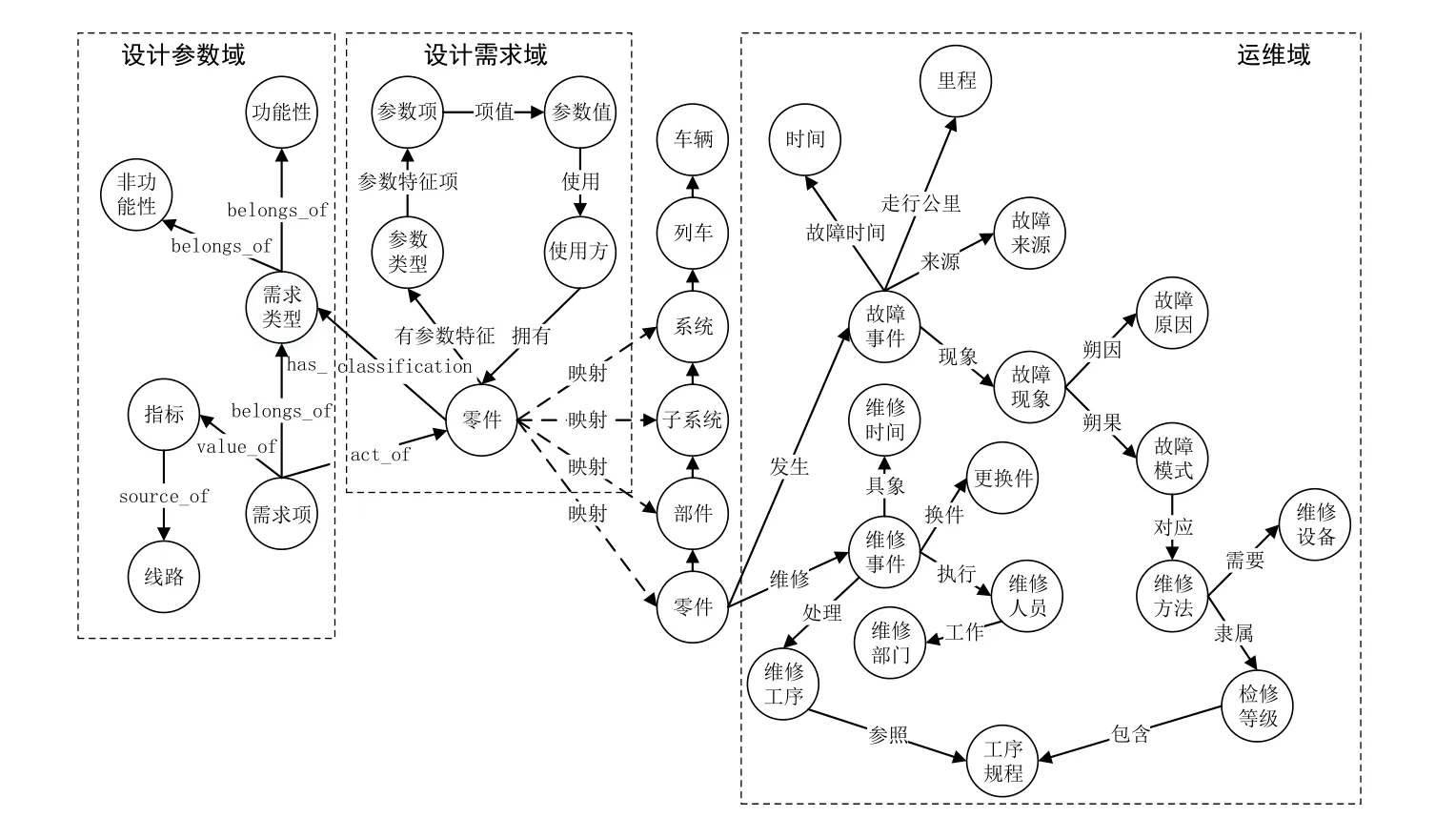
图1 高速列车零部件知识图谱知识本体结构
由图1 可看出,本文构建的高速列车零部件知识图谱主要包含高速列车零部件的运维域、设计需求域和设计参数域等3 个知识域。由该知识图谱的结构可看出,高速列车零部件的知识存在海量性、多层级及复杂性的特点,每个域内的知识依然存在阶段性特征。因此,本文以高速列车零部件知识图谱的不同知识域为依据,对用户问句进行分类,将其定位到正确知识域,剔除域外的无用知识,实现从知识图谱中匹配到符合问句语义的知识子图。
2 知识子图匹配模型
本文利用知识子图匹配模型进行高速列车零部件知识图谱的知识筛选。该模型包含情景特征提取模块和分类模块2 部分,模型架构如图2 所示。情景特征提取模块基于情景模型,分类模块基于BERT模型。BERT 模型包含用户问句向量提取、向量融合及模型训练等3 个步骤,其中,向量提取步骤包括了词向量的提取和情景向量的提取。完成向量提取后,将2 者融合后的问句向量输入到BERT 模型内,进行问句所属知识域的划分。

图2 知识子图匹配模型架构
2.1 情景特征的提取模块
2.1.1 高速列车零部件知识情景模型构建
高速列车零部件知识情景模型(简称:情景模型)的构建以零部件的相关任务为线索,通过对高速列车零部件情景的抽象化处理,构建多维层次的情境模型,可表达为
其中,PDC为情景模型,CiEj表示第i个零部件的第j个情境要素。
为适应情景感知需要,本文将情景因素提炼为任务、零部件、领域、人员4 项,情景模型架构如图3 所示。
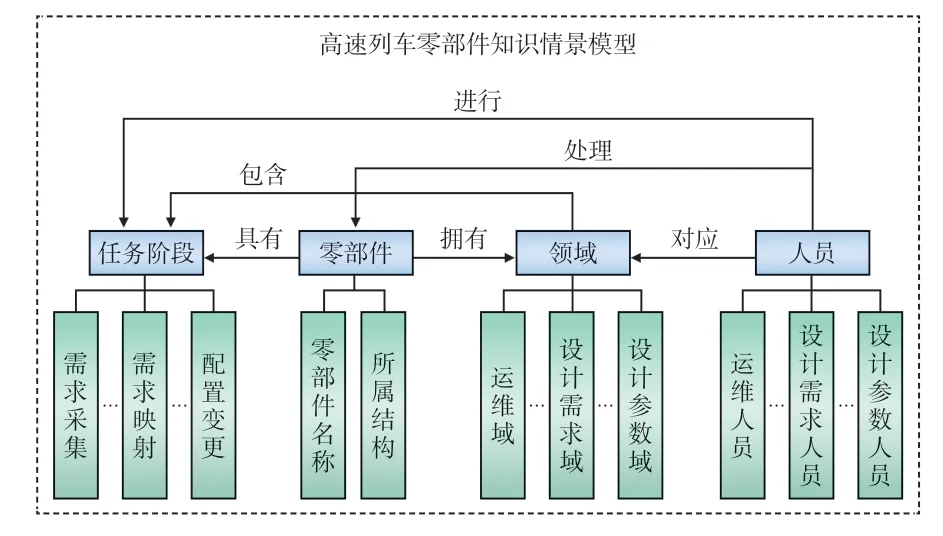
图3 高速列车零部件知识情景模型架构
其中,任务是指用户在运维研发活动中所处的活动阶段,以需求域人员为例,其任务阶段包含需求采集、需求映射等;零部件指当前人员所处理的具体零部件,包含零部件名称及所属结构;领域和人员指当前的任务域,在本文中被细分为3 类,即设计需求、设计参数及运维。
2.1.2 情景因素提取
建立情景模型后,需提取用户问句中的情景因素,并将其转化为相应的情景向量。
(1)任务
任务情景因素属于用户问句中不可见的成分,即无法直接从用户问句中提取。因此,本文参考该用户在问答系统中的历史任务。例如,若该用户在问答系统中的上一个任务为需求采集任务,则当前任务很可能为需求采集的下一阶段任务,即需求映射任务;如果无历史任务,则选取符合用户身份的第1 阶段任务,以设计需求人员为例,其第1 阶段需求采集任务即为该用户的当前任务。
(2)零部件
零部件情景因素指用户当前任务所处理的具体零部件,包括零部件名称及其所属结构。本文采用词典匹配的方式进行此类情景因素的提取,因此,需要建立高速列车零部件实体及其所属结构词典。本文采用从知识图谱中导出所有零部件实体的方式建立实体词典,根据相关规范文档,手动建立每个实体的所属结构,从而建立结构词典。高速列车零部件实体名称及其所属结构词典(部分)如表1 所示。

表1 高速列车零部件实体及其所属结构词典(部分)示意
(3)人员及领域
人员和领域情景因素都属于用户问句中的不可见成分,但人员情景因素在用户登录问答系统时便会被记录,所以人员情景因素可根据问答系统记录的用户身份进行提取。而领域与用户身份具有密切联系,假设一位用户是零部件的运维人员,则其进行的任务极大概率属于运维领域,所以可认定为运维领域任务。
2.1.3 情景因素向量转化
(1)任务
本文采用分词模型中已进行预训练的词向量对情景因素进行向量转化,该方式能抓取到更多的语义特征,且可与BERT 模型的句向量嵌入相契合,任务情景向量公式为
(2)零部件
由于零部件名称向量和所属结构向量维度相同,且其代表了零部件的结构信息,所以将两向量进行加权平均后便得到了零部件情景向量,公式为
式中,Vectorp为零部件名称向量;VectorS为零部件所属结构向量。
(3)人员及领域
人员及领域情景因素均被分为运维、设计需求及设计参数3 类。较小的类别数及与问句间较小的语义联系使得可用词袋模型对该情景因素进行转化。将原始向量设为[a,b,c],其中,a为运维的向量位、b为设计需求的向量位、c为设计参数的向量位,根据人员及领域情景因素的值,将相应向量位置设为1,其余位置设为0。
2.2 分类模块
2.2.1 文本向量的提取
文本向量提取的形式化描述为:给定一句文本S,得出S的文本向量序列Vectors={V1,V2,V3,···,VN},在本文中,向量的提取包含情景向量和句向量2 部分,因此,N的大小由情景向量的长度和问句长度共同决定。此小节主要阐述问句的句向量提取方式。
BERT 模型采取字符级嵌入的方式对用户问句文本的句向量进行提取,将用户问句的每个字符的字向量加权平均就得到了句向量。以运维域问句“转向架有哪些故障”为例,其句向量的提取方式如图4 所示。

图4 句向量提取
2.2.2 向量的融合
得到用户问句的情景向量和句向量后,需要将两者融合,形成用户问句的总特征向量。因为句向量和情景向量是相互独立的,故本文采用向量拼接的方式实现句向量与情景向量的融合。以高速列车转向架需求设计问句“联轴节的使用寿命需求有哪些具体指标?”为例,假设其句向量为[0,0,1],其情景向量为[X1,X2,0,1,0,0,1,0],则其总特征向量为[0,0,1,X1,X2,0,1,0,0,1,0]。其中,X1、X2 分别代表用户问句的任务情景向量和产品情景向量。
2.2.3 BERT 模型数据集及预测
(1)数据集
BERT 模型的训练需要有相应的数据集作支撑。需要构建相应知识域类别所对应的训练问句。数据集构建方式为人工编写对应知识域类别下的问句,共编写4897 条问句,其中,非领域类别1021 条、运维域类别1472 条、设计参数域类别1310 条、设计需求域类别1094 条,部分训练数据的形式如表2 所示。

表2 训练数据(部分)
将训练数据集进行向量转化后,输入到BERT模型内进行训练,完成模型的构建。
(2)模型预测
BERT 模型训练完成后,可利用其进行问句所属知识域的预测。BERT 模型依据问句的特征向量,计算并得出每个知识域类别在此特征向量下的权重,权重最高的知识域类别即为该用户问句所对应的知识域类别。以高速列车运维域问句“转向架有哪些故障”为例,BERT 模型依据其特征向量,计算出各个知识域类别的权重分别为:非领域问句0.03、运维域问句0.88、设计需求域问句0.06、设计参数域问句0.03,因此,将该问句划分为运维域问句。问答系统可依据其知识域类别将“转向架”相关的运维域知识提交到下一板块进行后续处理,从而剔除与运维域无关的知识(如设计参数域及设计需求域的知识),避免在进行具体知识定位时知识数量过大的情况。
3 实验设置及结果分析
3.1 评价指标和对比模型选择
知识子图匹配问题的本质是文本多分类问题。常见评价指标为准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1 值(F1-score)。本文采取的评价指标是在上述指标的基础上形成的宏准确率、宏召回率和宏F1 值。宏指标是取所有类别的统一评价指标的算数平均值。
为验证模型的有效性,本文测试了单BERT 模型,以及其他研究者提出的Kg-BERT 和K-BERT 模型对高速列车零部件知识问句的知识域分类效果。
3.2 实验设计与结果评估
本文的实验步骤为:(1)使用本文的向量转化策略将数据集中的文本向量化;(2)将数据集的85%作为模型训练的训练集,15%作为测试集;(3)使用本文模型及单BERT 模型、Kg-BERT 模型、K-BERT 模型等 4 种多分类模型基于数据集进行训练;(4)将测试数据输入到训练好的模型内进行分类效果比对。
本文模型与其他模型的分类效果比对如表3 所示。由表3 可知,本文模型的评价指标优于其余模型,在执行高速列车零部件知识图谱智能问答知识子图匹配的任务上具有先进性。
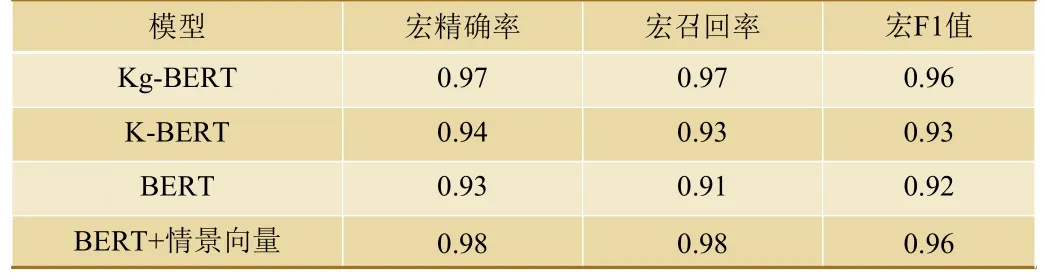
表3 4 种模型实验结果对比
4 结束语
本文提出了一种高速列车零部件知识图谱智能问答的知识子图匹配模型。该模型通过情景模型进行情景特征提取及向量转换;再将词向量和情景向量相融合输入到BERT 模型中,进行用户问句的所属知识域分类,分类结果即为知识子图的匹配结果。经试验证明,本文模型能够满足高速列车零部件知识图谱智能问答知识子图匹配的需求,且模型分类性能要优于未融合情景向量的其他通用分类模型,具有参考价值。
猜你喜欢
疯狂英语·初中天地(2022年2期)2022-07-07
少先队活动(2020年12期)2021-01-14
劳动保护(2019年3期)2019-05-16
同济大学学报(自然科学版)(2019年2期)2019-04-02
中成药(2017年3期)2017-05-17
小天使·一年级语数英综合(2017年3期)2017-04-25
电子科技大学学报(2016年2期)2016-08-31
领导科学论坛(2016年9期)2016-06-05
小天使·一年级语数英综合(2015年8期)2015-07-06
华东师范大学学报(自然科学版)(2014年1期)2014-04-16
