
基于BERT的双特征融合注意力的方面情感分析模型
2024-01-11 13:15夏鸿斌
计算机与生活 2024年1期
李 锦,夏鸿斌,2+,刘 渊,2
1.江南大学 人工智能与计算机学院,江苏 无锡 214122
2.江苏省媒体设计与软件技术重点实验室,江苏 无锡 214122
基于方面的情感分析(aspect-based sentiment analysis,ABSA)旨在对文本如用户评论进行细粒度的情感分析[1],是对文本中一个或多个方面的情感极性进行分类,在学术界受到广泛关注的同时也在工业界得到了广泛的实施。它通过亚马逊等网站上的在线评论提供的实时反馈,获取客户对特定产品或服务的意见。如图1 所示,在句子“This book is a hardcover version,but the price is a bit high.”中“version(封面)”的情感是积极的,而“price(价格)”的情感是消极的。由于这两个方面词表达了相反的情感,仅仅分配一个句子级别的情感极性是不合适的。于是,Jo 等人[2]和Pontiki 等人[3]提出了基于方面的情感分析(ABSA),旨在识别针对特定方面的细粒度情感极性。细粒度的方面情感分析根据方面目标实体数量的不同可以分为单目标方面情感分析任务和多目标方面情感分析任务。ABSA 任务通常只有一个目标实体,而为了处理多个目标实体在预先给定的方面集合中对多个不同的方面产生不同的情感倾向的问题。Saeidi等人[4]又引入了基于目标方面的情感分析(target aspect-based sentiment analysis,TABSA)任务,旨在识别句子中一个指定实体(target,aspect term)的一个指定方面类别(aspect category)的情感。本文中提到的方面词、方面类别以及方面集合等概念较易混淆,特举例说明。例如“这块牛排的味道非常好吃,但价格有点贵。果汁既便宜又好喝”在给定的关于餐厅的目标方面集合{味道,服务,价格,位置,服务,装修等}中,方面词“牛排”“果汁”分别提到了它们在“价格”和“味道”两个方面类别中的情感倾向。为了全面地对句子进行细粒度的情感分析,本文分别针对一个实体的多个方面类别(ABSA 任务)以及多个实体的多个方面类别(TABSA 任务)进行研究。

图1 上下文词对情感极性预测的不同影响Fig.1 Different influences of context words on sentiment polarity prediction
最初,研究者对ABSA任务使用神经网络模型的研究主要集中在使用深度神经网络。近年来,随着强大的自注意力机制[5-7]的出现,以自注意力机制为内核的Transformer[8]和BERT(bidirectional encoder representations from transformers)[9]因其强大的特征抽取能力被Sun 等人[10]相继应用于ABSA,使模型的效果得到显著增强。Zeng 等人[11]提出了一种不同于上述模型的局部上下文关注模型(local context focus,LCF),LCF 模型使用句子序列中单词距离作为语义相关距离(semantic-relative distance,SRD)来得到局部上下文表示。该模型注意到一个方面的情感极性与接近自身的上下文词更相关,且远离方面词的上下文词可能会对特定方面极性的预测精确度产生消极影响。吴仁彪等人[12]参考图像处理领域的胶囊网络,将胶囊网络运用于情感分析任务上,有效降低了模型在特征迭代中信息丢失的问题。赵志影等人[13]提出了GCAN(GCN-aware attention network),引入了基于句法分析树的图卷积神经网络,以挖掘句子的句法特征和结构信息,从而更好地将全局信息整合到特定方面的向量表示中。Wu 等人[14]用Context-Aware Self-Attention Networks 作为模型的特征抽取层,提出了面向方面情感分析的CG-BERT(contextguided BERT for targeted aspect-based sentiment analysis)模型,获得了比基础的BERT 模型更好的结果,上下文感知的自注意力网络的引入,使得深度学习模型能够更好地抽取输入序列的全局语义特征,在多个数据集上都取得了前沿性的成果。
尽管现有的模型在方面词情感分析任务上有着不俗的表现,但仍存在三个方面的不足。其一,在很多研究工作中,方面词的重要性未能得到充分的重视。Jiang 等人[15]在Twitter 数据集上评估了一个情感分类器的效果,结果发现40%的分类错误都缘于没有考虑方面词的指示作用。这说明,如何充分使用方面词提供的位置特征和语义特征将是影响模型效果的重要因素。其二,现有的模型在提取文本特征的过程中未能充分发挥局部特征和全局特征的优势,方面词的情感极性更多的相关于与之在绝对位置和逻辑位置相近的词语,距离较远的词语往往会成为情感分类的干扰项。有些模型虽然发现了局部特征或全局特征的重要性,却未能将两者的特征进行很好的结合进而消除干扰项的不良影响。同时,在局部特征和全局特征进行融合的过程中使用拼接或相加的方式容易造成特征损失和特征覆盖的问题。其三,现阶段大部分模型使用Softmax 激活函数来计算每个位置的注意力分数,由于Softmax 函数的值域为[0,1],这导致每个特征都会对注意力的计算产生积极的影响,从而产生一定的噪声干扰。
针对上述不足,本文受Zeng 等人[11]提出的局部注意力和Yang 等人[16]提出的情境感知网络的启发,提出了基于BERT 的双特征融合注意力模型(dual features local-global attention with BERT,DFLGA-BERT),借助BERT 来获取高质量的语义编码,为突出方面词的重要性,本文根据上下文动态掩码(context dynamic mask,CDM)设计了局部特征抽取模块聚焦与方面词在语义上更相关的特征,在此基础上计算局部特征的注意力分数。同时,为了弥补局部特征容易忽略远距离特征的缺陷和挖掘多维度的全局特征,本文模型使用情景感知网络设计了全局特征抽取模块模型。在获取深度全局语义信息的同时尽可能地降低干扰项对情感分类的影响。同时受Tay 等人[17]的启发,本文将“准”注意力融入到全局注意力的计算中,将注意力分数的值域由原来的[0,1]变换到[-1,1]。通过训练线性层参数让模型学习在不同的上下文语境中分配合适的注意力,(正向、零、负向)分别对应(增加注意力、忽略、降低注意力),从而降低文本噪声对于模型的影响。在特征融合阶段,模型采用多个条件层规范化(conditional layer normalization,CLN)[18]的组合结构,在强调平衡局部特征和全局特征的同时,避免了融合阶段的特征损失,强化了模型的拟合能力。实验证明,DFLGA-BERT 在SentiHood 和SemEval 2014 Task 4数据集上都取得了优异的成绩。同时,在消融实验中进行了子模块的有效性验证,也充分证明了模型主要组成部分的设计合理性。
1 本文模型
对于方面情感分类,为模型准备的输入序列通常由上下文序列和方面词序列组成,方面词序列通常为单个方面词或多个词组成的方面词组,这使得模型能够学习到与方面相关的信息。假设s={wi|i∈[1,n]}是一个包含方面的上下文序列,st={wi|i∈[1,m]}是一个方面序列,其中st是s的子序列,且m≥1。如图1,整个句子为上下文序列s,而“version”和“price”是两个不同的方面序列st。本文模型的目的是预测st在s中所表现的情感极性。模型总体架构如图2 所示,宏观上可以分为三层:输入层、特征抽取层以及输出层。特征抽取层又可以分为局部特征抽取模块和全局特征抽取模块,分别用以获取方面词局部特征以及全局上下文语境动态加权特征。模型的介绍将围绕输入层、局部特征抽取模块、全局特征抽取模块以及输出层这四个部分展开。
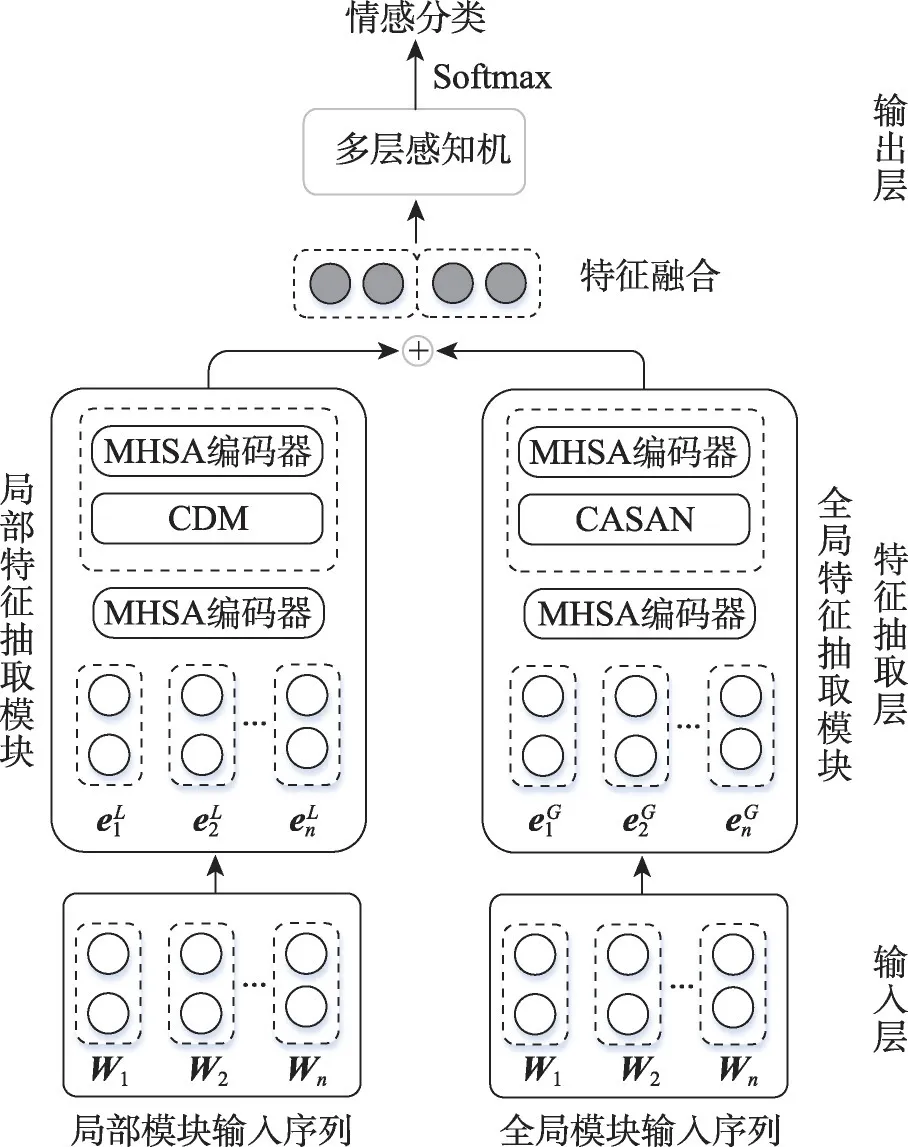
图2 DFLGA-BERT模型整体架构Fig.2 Overall architecture of DFLGA-BERT model
1.1 输入层
输入层是DFLGA-BERT 模型的第一层,其目的是将上下文序列转化为向量化表示然后输入到模型中。在DFLGA-BERT模型中,为了充分发挥BERT在模型训练中的作用,本文将输入序列处理成“[CLS]”+上下文序列+“[SEP]”+方面词序列+“[SEP]”的形式。其中,“[CLS]”和“[SEP]”是BERT 使用的两种标记符号,“[CLS]”是特殊分类向量标记符,聚集了分类相关的信息,“[SEP]”是分隔符,在输入多个序列时用于分隔不同序列。将原输入序列处理成BERT 在处理文本分类任务时所要求的输入格式,从而最大程度地发挥BERT 的效果。
1.2 特征抽取层
1.2.1 局部特征抽取器
(1)词嵌入层
将句子输入到词嵌入层进行特征表示,词嵌入层可以将分好的词变为稠密的向量。在DFLGABERT 中,由于BERT 具有强大的表示能力,为了加快学习进程和获得更强性能,使用经过预训练的BERT词向量作为词嵌入层。假设L∈Rde×|v|是BERT 向量,de是嵌入向量的维度,|V|是词库的大小,每个上下文词Wi对应一个向量。
(2)MHSA 编码器
经过词嵌入层的表示后,输入序列的隐层向量已经包含了所提及的语义特征,为了提取其中有助于判别方面情感的特征,使用多头注意力(multihead self-attention,MHSA)来对特征进行提取。多头注意力与单头注意力的不同之处在于进行了多次计算而不仅仅算一次,这样可以允许模型在不同的表示子空间里学习到相关的信息。MHSA 的主要思想是通过多个注意力函数来对每个单词计算注意力数值,将这多个注意力数值拼接在一起后进行激活函数运算,其结果即为输入序列的语义表示。令词嵌入层的输出为El,单头注意力的计算方式为:
式中,Wq、Wk、Wv均为权重矩阵,。这三个矩阵中的权重属于模型的可训练参数。dq、dk、dv是矩阵维度,三者的值都是dh/h。其中,dh是隐藏层维数,h是多头注意力机制中的头数。根据每个注意力头的H计算结果,可得到整个MHSA 的输出Out(El):
式中,⊕表示向量的拼接操作;WMHSA是一个向量矩阵,;Tanh 是激活函数。通过以上步骤,多头注意力将基础的词嵌入向量编码为包含丰富信息的语义向量表示。
(3)语义相关距离SRD
语义相关距离(SRD)就是指同一句子中两个词互相之间的语义影响度,一般来说,两个单词之间的语义相关距离越近,则两个单词之间的语义相关程度越高。SRD 一般分序列距离和依存距离两种,序列距离就是两个词在句子中位置的绝对距离。依存距离是指两个词在句法依存树中对应节点之间的最短距离。如果方面词由多个词语组成,则SRD 被计算为方面词每个组件单词和输入单词之间的平均距离。SRD(序列距离)的计算过程如下:设输入的原上下文序列为W={w1,w2,…,wi,wi+1,…,wi+m-1,wi+m,…,wn},其中{wi,wi+1,…,wi+m-1}为方面词序列,对上下文序列中的任意单词wj(1 ≤j≤n),SRD 的计算方法为:
经过实验测试,本文模型中使用序列距离的效果更好,因此选用序列距离作为词语的语义相关距离。
(4)上下文动态掩码CDM
通过计算句子中各词与方面词之间的语义相关距离,然后根据与方面词的SRD 大小可以掩蔽掉一些对方面词的情感倾向无关的部分上下文词。给定全局上下文向量H以及语义相关距离的阈值a。具体流程为:对于输入的上下文序列,本文首先计算上下文词与方面词的语义相关距离,再根据阈值a将上下文中与方面词的语义相关距离超过a的词用全零矩阵进行覆盖,进而计算上下文的掩码向量M。
式中,O和E分别表示全零向量和全一向量;O,E∈,其中dh为上下文隐层向量的维度,◦表示哈达玛积(即两个相同维度的矩阵相同位置两两相乘),通过式(10)将与方面词的语义相关距离超过a的词用全零矩阵进行覆盖即得到局部特征嵌入层的输出Outlocal。最后通过注意力机制提取之后输出局部上下文对方面词的注意结果如式(11)。
1.2.2 全局特征抽取器
其中词嵌入部分、MHSA 编码器部分和局部特征抽取器相同,就不再赘述。
(1)上下文感知注意力编码
与传统的注意力编码不同,本文模型采用Yang等人[16]提出的上下文语境融合网络,其核心思想是在保持自注意力模型并行计算和特征抽取的基础上充分利用语料的内在信息去挖掘句子中词语之间的联系。传统注意力编码的计算[16]和深度全局语境融合网络编码[16]的区别见图3和图4所示。
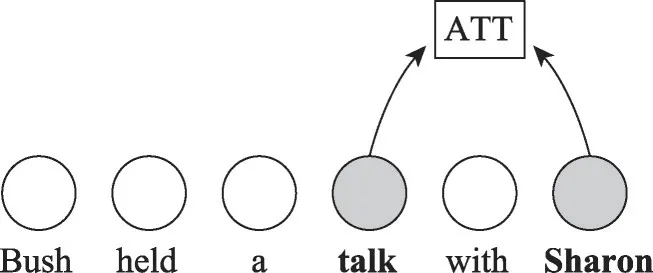
图3 传统注意力计算Fig.3 Conventional attention calculating
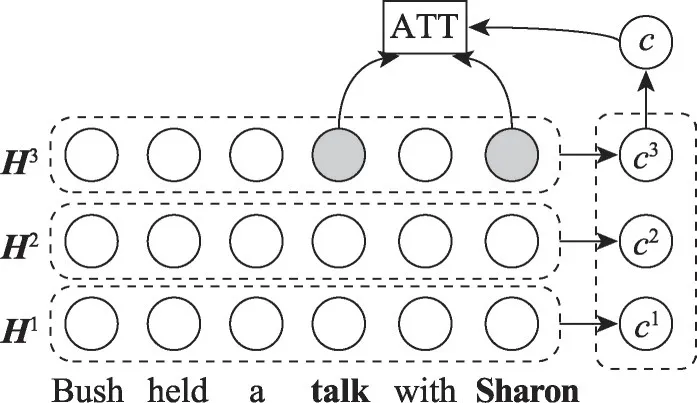
图4 深度全局上下文注意力计算Fig.4 Deep-global context attention calculating
在传统的注意力编码中主要是建模了词与词之间的关联,得到整个输入序列对某一个词的权重序列。全局上下文注意是指用一个在层与层之间共享的向量c来建模序列的全局语义,帮助模型理解整句的整体语义。深度是指模型内部具有多层的隐藏层,在深度学习模型中通常会使用多层的隐藏层来建模多个方面的信息,例如每个词在不同方面的句法信息和语法信息,Yang 等人[16]的研究表明,底层的隐藏层通常会蕴含句法相关的信息,较高层的隐藏层用来捕获上下文相关的方面信息。在深度全局上下文注意力的计算当中结合了全局上下文和深度上下文,充分利用全局上下文和深度上下文的优势,跨层融合全局上下文,将词与词之间的词汇信息、句法信息、语义信息一起融入到特征向量中。
(2)深度全局上下文注意
深度全局上下文注意分数计算是基于上下文感知的注意力编码,为了缓解自注意力模型上下文信息的缺乏,模型将上下文的信息嵌入到编码层的查询矩阵Q和键值矩阵K中,在避免了显著增加计算量的同时保持了原有的并行计算,具体的方式见式(12)所示:
(3)“准”注意力分数计算
在常规的注意力计算中,由于使用了Softmax 函数注意力分数在[0,1]之间,也就是说,它只允许每个位置的隐层向量进行凸加权组合,对注意力分数的贡献只能是相加的,这会导致即使是跟目标方面词不相关的词也会得到正的注意力分数,从而对最终方面词的情感分类造成一定程度的干扰。因此本文模型将Tay 等人[17]在2019 年提出的“准”注意力[17]注入其中,同时允许加性注意和减性注意来克服这一限制。为了导出“准”注意力矩阵,本文首先定义了“准”上下文查询矩阵CQ和“准”上下文键值矩阵CK,如式(14)所示:
式中,α是一个比例因子;fφ(⋅)是相似度度量函数,用来捕捉和之间的相似度,本文使用点积函数来参数化fφ。根据每个注意力头的H(Eg)计算结果,可得到整个MHSA的输出Out(Eg):
式中,⊕表示向量的拼接操作;WMHSA是一个向量矩阵,;Tanh 是激活函数。将全局上下文的权重系数的值表示为双向的,得到式(18):
式中,{β,γ}是控制权重的标量。用来控制“准”注意力权重系数,进而调整全局特征在总体特征中权重占比。由式(13)可知{,}的值域为[0,1]。当β=1,γ=1 时,(β⋅+γ⋅)的值域为[0,2],则的值域为[-1,1]。此时,局部特征和全局特征对模型总体的贡献为1∶1,由此来平衡局部特征和全局特征。通过注意力机制进行提取之后得到全局上下文对方面词的注意力分数的结果,全局特征抽取模块的输出可表示为式(19):
1.3 特征融合
在局部特征和全局特征进行融合时,普通的融合方式如线性层、拼接、和、积等,很容易损失和覆盖特征信息,最终导致模型的性能下降。
为了解决这个问题,本文基于CLN 设计了新的特征融合结构,张龙辉等人[18]曾在对序列进行层规范化(layer normalization,LN)的同时将额外的条件c1和c2融入到LN的过程中,来增强特征,提出了CLN。LN和CLN的计算过程如下:
式(20)为LN 的计算公式,其中E[x]为求x的均值,Var[x]为求x的方差,ε为保持分母不为零的极小常量,φ和η分别为缩放变量和平移变量。式(21)为CLN 的计算公式,其中Wφ、Wη为可训练参数,c1和c2为待融合条件。对比式(20),CLN 将条件c1和c2通过线性变换映射到两个不同的空间,作为缩放变量φ和平移变量η加入到y的规范化过程中。
CLN 中变量的不同输入顺序,同样会导致不同的融合结果,能够体现变量间的方向性特征。本文利用多个CLN 的组合结构来强化阶段间的特征传输过程,丰富语义特征的表达,保留原有特征的信息以及方向性特征,进而达到特征融合的目的。为了最大程度地保留特征抽取模块抽取的特征信息,本文首先将全局特征作为辅助信息融入到局部特征中,过程如下:
然后将局部特征作为辅助信息融入到全局特征中,过程如下:
最后取式(22)和式(23)的均值得到双特征融合向量Ofusion,如式(24)所示:
1.4 输出层
得到特征抽取层输出的双特征融合向量Ofusion后,将其输入到线性分类层去做关于方面词的情感分类,使用Softmax 层预测情感极性。计算过程如式(25)和式(26)所示:
式中,MLP(multilayer perceptron)表示多层感知机,p与情绪标签的维数相同,而分别是学习权重和偏置。
2 实验和结果
在本章中,为了验证模型的有效性,首先介绍了用于评估的数据集和用于比较的基线方法。然后,针对细粒度情感分析任务ABSA 以及它的子任务TABSA 分别进行了实验,并从不同的角度报告了实验结果。
2.1 实验环境及数据集
本文实验环境如下:CPU 为Intel Core i7 8700K,GPU为GeForce GTX 1080Ti,内存大小为DDR4 16 GB,开发环境为win10 64位操作系统,Pytorch1.5.0。
为了更加全面地对本文模型进行评估,本文采用两个公开的英文数据集对ABSA任务和TABSA任务进行了实验评估。对于TABSA 任务,本文使用了由雅虎问答构建的Sentihood 数据集5,它由5 215 个句子组成,其中3 862个句子包含一个目标方面,1 353个句子包含多个目标方面。对于ABSA任务,本文使用的数据集是SemEval 2014 Task 4,这些数据集中包含多个方面项及其对应的情绪极性(积极、中立或消极)。表1显示了每个类别中的训练和测试实例的数量。此外,本文在参数选择过程中随机划分出20%的训练集作为开发集。本次实验所有复现的模型以及本文模型都使用了同样的数据集处理方式。
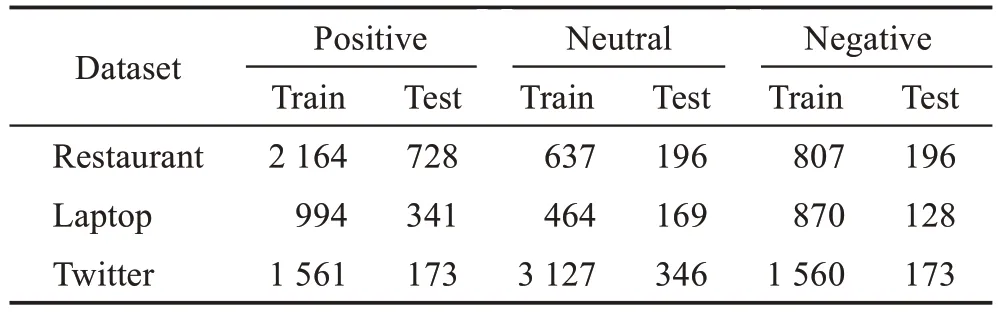
表1 SemEval数据集的统计信息Table 1 Statistics of SemEval datasets
与学者Pontiki等人[3]的研究一样,本文为每个数据集定义了两个子任务:(1)方面词的检测;(2)基于方面的情感分析。对于方面词的检测,如果它是TABSA任务,则检测在目标实体为t的输入句子中是否提到了预先给定的方面集合中的方面类别a(如果为None,则意味着没有提到),如果是ABSA 任务则直接检测输入句子中是否提到了预先给定的方面集合中的方面类别a。对于方面的情感分析,本文给出了模型存在的方面(即忽略掉在句子中没有提到的方面),让模型预测方面的情感极性(Sentihood 数据集是积极或消极,SemEval 2014 Task 4 数据集是积极、中立、消极或冲突)。
2.2 实验参数设置
在本文的实验中,对于方面词的检测(输入的句子中是否存在给定的方面,如不存在则为None),本文采用分类任务常用的准确度Acc、F1 以及AUC 值作为评价指标,对于基于方面的情感分析任务本文使用召回率F1和AUC值作为评价指标。本文使用预先训练好的BERT进行微调,特征向量的层数为12,维度为768。在本文的模型训练中,使用Adam作为优化器,初始学习率为2E-5,batch_size 为4,dropout 概率为0.1,epoch 为20,在两个数据集中单次的训练时间为19 h。
2.3 实验1:TABSA任务
基于目标方面的情感分析TABSA旨在识别句子中针对一个指定实体(target,aspect term)的一个指定方面(aspect category)的情感。例如:“这块牛排的味道非常好吃,但价格有点贵。果汁既便宜又好喝”在给定的关于餐厅的目标方面集合{味道,服务,价格,位置,服务,装修等}中表现出了对“牛排味道”“果汁味道”“果汁价格”这个方面的积极情感,对“牛排价格”这个方面的消极情感,模型需要正确识别出目标实体在目标方面的情感极性。相较于关于方面的情感分析ABSA 任务,TABSA 中可能出现的实体更多,预测的是实体-方面类别词对的情感极性。
为了综合评价本文模型,将它们与一系列基线和最先进的模型进行比较,如下所示:
(1)LR:一种具有多分类语法和位置标签的逻辑回归分类器。
(2)LSTM-Final[20]:Ruder等人使用分层双向长短期记忆网络(long short-term memory networks,LSTM)对评论中句子的相互依存关系进行建模。
(3)LSTM-Loc[21]:Tang 等人将目标位置相关联的状态融入特征的双向长短期记忆网络模型。
(4)LSTM+TA+SA[22]:Ma 等人在长短期记忆网络中引入了目标层注意和句子层注意的分层注意机制。情感相关概念的常识知识被纳入用于情感分类的深度神经网络的端到端训练中。
(5)SenticLSTM[22]:Ma 等人将SenticNet[23]的外部信息引入到模型之中,是LSTM+TA+SA 模型的升级版本。
(6)Dmu-Entnet[24]:Liu 等人受机器阅读记忆增强模型的最新进展的启发,提出了一种新的双向Entnet[25]体系结构,利用外部“内存链”和延迟的内存更新机制来跟踪实体。
(7)BERT-single[9]:Devlin 等人设计为通过联合限制所有层的左右上下文来预先训练来自未标记文本的深层双向表征。仅使用BERT 对自然语言表征进行编码后进行目标方面情感分析。
(8)BERT-pair-QA-M[10]:Sun 等人利用BERT 做神经表征编码的基础上,通过从方面词构造一个助句,将方面情感分析任务转换为问答。
(9)BERT-pair-NLI-B[10]:通过从方面词构造一个助句,将方面情感分析任务转换为自然语言推理。
(10)LCF-BERT[11]:Zeng等人使用语义-关系距离(SRD)的局部上下文-关注设计来丢弃无关的情感词。
(11)LCFS-BERT[26]:Phan 等人结合词性嵌入、基于依赖关系的嵌入和上下文嵌入来提高方面抽取器的性能。提出了句法相对距离来淡化不相关词的负面影响,提高了方面情感分类器的准确性。
(12)Dual-MRC[27]:Mao等人基于三元组的抽取任务,构造了两个机器阅读理解(machine reading comprehension,MRC)问题,并通过联合训练两个参数共享的BERT-MRC模型来解决端到端框架的所有子任务。
(13)DualGCN[28]:Li等人提出双重图卷积网络模型,分别捕获句法知识和语义相关性。
(14)CG-BERT[14]:Wu 等人基于上下文动态分配自注意力权重提出上下文引导的BERT 模型CGBERT,可以针对不同的上下文背景自适应地调节上下文语境对方面词的影响。
(15)QACG-BERT[14]:Wu 等人对CG-BERT 模型进行改进,提出“准”注意力的CG-BRRT 模型,使得模型在学习的过程中支持值为负数的注意力分数。
(16)DFLGA-BERT:本文模型,基于双特征融合注意力分别设计了局部与全局的特征抽取模块,充分捕捉方面词和上下文的语义关联。并将一种改进的“准”注意力添加到DFLGA-BERT 中,使模型学习在注意力的融合中使用减性注意力以削弱文本噪声产生的负面影响。
表2 展示了模型在Sentihood 数据集5 上的实验结果。如表2 所示,在普通的基线模型中,基于特征工程的逻辑回归分类器首先开始尝试方面级情感分析任务。时间最早,但在情感分类上的效果却出人意料得好,超过了许多不含BERT 加持的基线模型。但在传统的机器学习方法中由于手动制作特征的复杂性,在不考虑人工成本的条件下依旧是一个不错的选择。在长短期记忆网络问世之后,Ruder 等人[20]和Ma等人[22]先后利用分层双向LSTM 以及将目标层注意和句子层的注意引入到LSTM中,模型整体在方面类别抽取子任务上的性能得到了提升。由于LSTM的结构比较简单,且未考虑方面词的有关信息,分类的效果依旧不是很理想。BERT-pair-QA-M 和BERTpair-NLI-B模型利用BERT模型在自然语言推理和问答任务上的优势,巧妙地通过构造助句的方法,将情感分析任务转换为问答任务和自然语言推理任务,在方面情感分析任务上的Acc 指标提升了0.07~0.11。LCFS-BERT、CG-BERT、QACG-BERT 也都设计了合适的网络结构和子模块来引导整个模型满足方面词情感分析任务的要求,充分发挥了BERT 强大的优势,取得了令人瞩目的成绩。DFLGA-BERT 则是凭借整合局部特征和深度全局上下文特征的优势,在情感分类的Acc和AUC上,都获得了比上述基线更理想的结果。证明了整体模型在解决方面词情感分析任务上的优秀能力。
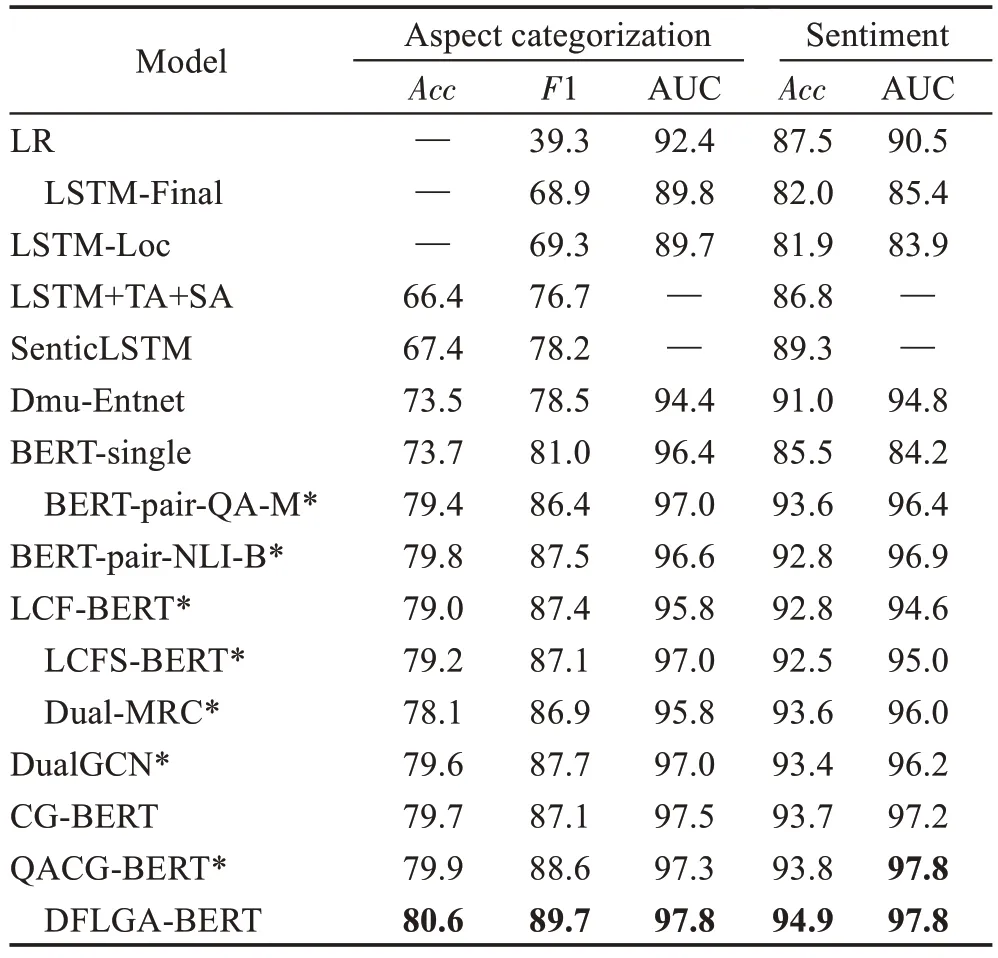
表2 实验结果对比(TABSA任务)Table 2 Comparison of experimental results(TABSA task) 单位:%
2.4 实验2:ABSA任务
基于方面的情感分析任务ABSA 目的是给定文本以及文本中可能出现的方面,预测文本是否提到该方面词,并预测该方面词在文本中的情感极性。
在ABSA 任务中,将本文的DFLGA-BERT 模型与在SemEval-2014 数据集上表现优秀的几个模型进行比较。在方面检测任务中本文采用分类常用的Precision、Recall、F1 值作为衡量指标,在方面情感分析方面,本文采用Acc 作为评价指标,结果展示了模型在二分类(积极,消极)、三分类(积极,中性,消极)、四分类(积极,中性、消极、冲突)上的表现。实验结果如表3所示。
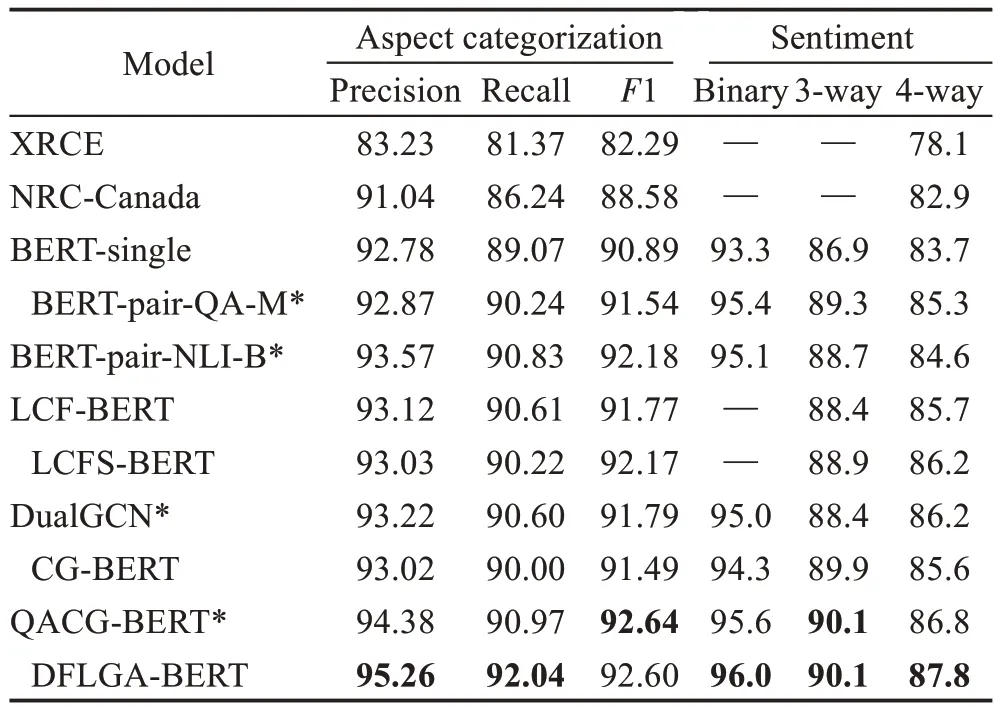
表3 实验结果对比(ABSA任务)Table 3 Comparison of experimental results(ABSA task) 单位:%
为了综合评价本文模型,将它们与一系列基线和最先进的模型进行比较,如下所示:
(1)XRCE[29]:Brun 等人介绍了为SemEval-2014任务4开发的专门用于基于方面的情感分析的系统。该系统基于一个健壮的解析器,该解析器为不同的分类器提供信息,为不同的分类器提供专用于方面类别和方面类别极性分类的语言特征。
(2)NRC-Canada[30]:Kiritchenko等人基于SemEval-2014 任务4 设计的关于方面检测以及方面情感分析的分类器。
其他对比模型同实验1中模型,此处不予赘述。
表3 展示了各个模型在SemEval-2014 数据集上的表现。如表3 所示,XRCE 和NRC-Canada 模型是Brun 等人[29]和Kiritchenko 等人[30]基于SemEval-2014任务4 设计的关于方面类别检测以及方面情感分析的分类器,虽然没有用复杂的深度学习网络,但依靠手工编码特征依旧取得了不错的成绩,为之后的学者提供了可参考的实验结果。Sun 等人[10]在利用BERT 做神经表征编码的基础上,通过从方面词构造一个助句,将方面情感分析任务转换为问答和自然语言推理,充分利用BERT 模型在分析句子对任务上天然的优势。在二分类的情感分类任务上达到了95.4%的准确率,该模型的性能已近乎达到其潜在最优效果的极限。LCFS-BERT则基于依赖关系提出了句法相对距离来淡化不相关词的负面影响,在三分类和四分类的任务上提升了1 个百分点。本文模型在方面词检测的精确度和召回率上都表现出了比基线模型更优的实验结果,Macro-F1 分数比Wu 等人[14]的QACG-BERT 模型略低4E-4,在情感分类任务上也相对占优,证明了整体模型在解决方面词情感分析任务上的优秀能力。
2.5 实验结果分析
综合两个实验来看,本文提出的基于双特征融合注意力的方面情感分析模型,针对局部特征抽取和全局特征抽取分别设计了局部特征和全局特征的抽取模块,能够显著提升BERT 在方面词检测和方面情感分析任务上的表现,在TABSA 任务和ABSA 任务上都有比较好的效果。其一,本文将模型的输入处理成BERT 在处理文本分类任务时所要求的输入格式,最大程度地利用BERT 在语义抽取方面的优势。其二,ABSA 任务和TABSA 任务中由于有来自方面词(aspect)和目标项(target)的额外信息,分类场景比普通的SA(sentiment analysis)任务更加复杂,直接微调传统的BERT 预训练模型并不能实现模型性能的增长。本文根据不同的上下文场景,设计局部特征抽取模块减少注意力的感知范围,屏蔽距离较远的词对方面词产生的干扰,强化方面词的范围感知能力。同时设计全局特征抽取模块,去弥补局部特征抽取时忽略的距离较远但也和方面词比较相关的词。以内部的隐藏状态作为上下文的特征向量,在不增加外语义信息的条件下深度抽取全局语义信息。其三,本文在特征融合阶段采用多个条件层规范化的组合结构,丰富了语义特征的表达,避免了特征融合阶段的特征损失。在方面词的检测和情感分类上都取得了相比于之前的基线模型更好的结果。
2.6 实验参数分析
为了检验DFLGA-BERT模型学习到的全局参数的有效性,本文用训练好的DFLGA-BERT 模型将测试集中的一个句子进行了自注意力和准注意力的可视化展示,如图5所示。在这个句子中本文正确地预测了“book version”的情感极性为正,high 相对于方面词version 也是一个积极情感的词,因此在自注意力的计算中high的自注意力分数和hardcover都很高。但是就全句上下文语境而言,high与price更相关,并且表示负面的情感极性,因此可以看到在“准”注意力分数上high的分数接近负1.0,这也会在本文最终的关注度中将对应的注意分数减去,最终得到version更多相关于hardcover 并且情感极性为正。由于准注意力的存在,很明显看到在特征融合之后部分词的注意力分数为负,Tay等人[17]在论文“Compositional De-Attention Networks”第四章对自然语言处理任务的分析中得出结论,“准”注意力的使用能有效帮助模型学习在不同的上下文语境中分配合适的注意力(正向、零、负向),这些分别对应(增加注意力、忽略、降低注意力),因此方面词会降低对“high”的关注度。这也证明了DFLGA-BERT模型能有效地排除大部分的噪声干扰,能够忽略输入中一部分不相关的信息,有效提升后期情感分类任务的准确度。
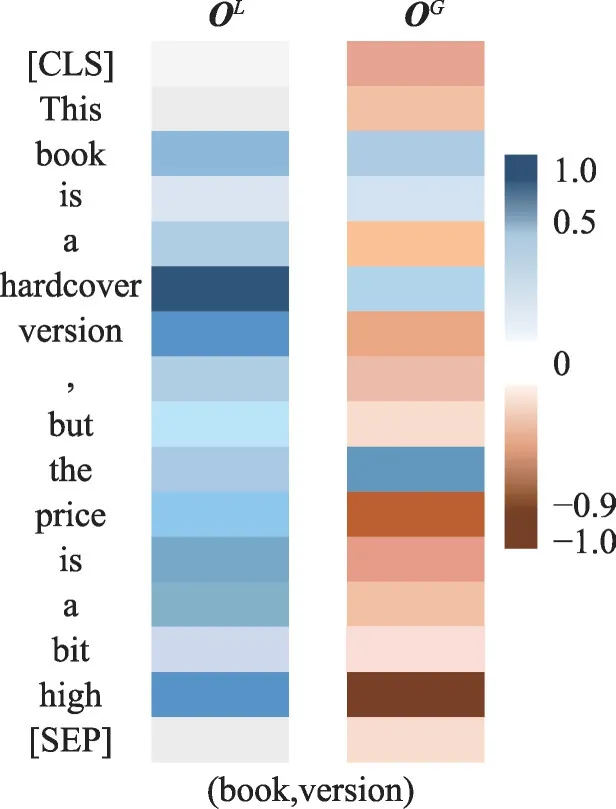
图5 测试集中对(book,version)词对的注意力权重示例Fig.5 Example of attention weights extracted from test set of pair(book,version)
2.7 自注意力和“准”注意力对比实验
从图6 可知,在传统的自注意力(attention)中,方面词“book version”将注意力主要集中于上下文的“a hardcover”以及“a bit high”中,由于自注意力分数的计算受到softmax 函数的限制,注意力分数的数值会分布在[0,1]区间内。通俗地理解为方面词会按照注意力分数的大小分配自身的自注意力,而所有上下文词的自注意力分数都大于0,这表示它们或多或少都会“被关注”,因此才会造成一定的噪声问题。例如图中的例子,从自注意力的角度而言,“a hardcover”和“a bit high”的关注度都很高,那么“a bit high”也很有可能在最后进行情感分类的时候被误认为是“book version”的观点项,从而导致模型预测结果不准确。而从“准”注意力(de-attention)的角度而言,“准”注意力中学习了全局上下文的整体语义,它“学”到“a bit high”也饱含情感,但与“book version”在语境上不符,因此降低对它的关注度,最终会将注意力集中于“a hardcover”,将它作为情感分类的观点项,这正是本文模型所追求的。
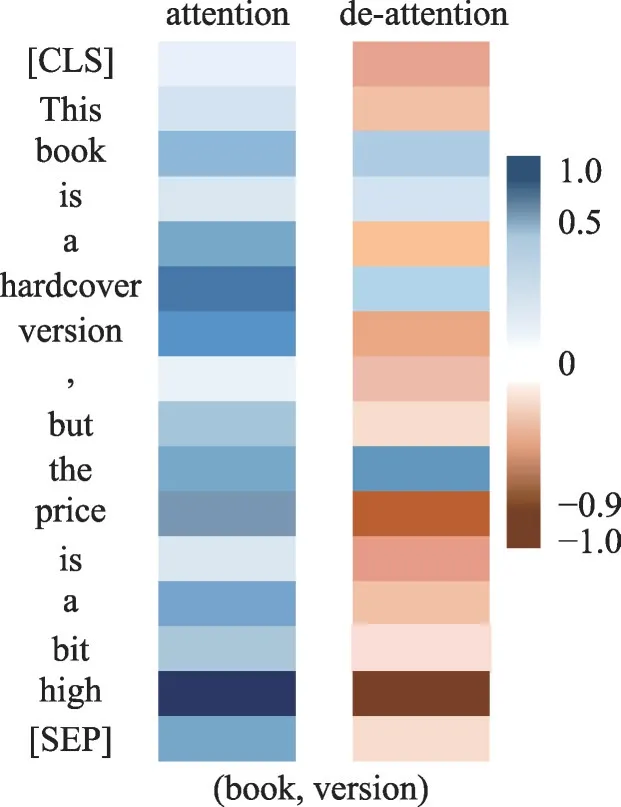
图6 自注意力与“准”注意力可视化效果对比(book,version)Fig.6 Comparison of visualization between attention and de-attention(book,version)
2.8 SRD参数的选择
为了探究不同的语义相关距离对DFLGA 模型的影响,以及寻求DFLGA 模型在各个数据集上的最佳SRD 阈值参数,本文在两个数据集上进行了关于SRD 阈值a和序列距离以及依存距离的实验,以评估在不同情况下的最佳语义相关距离和阈值a。相应模型和数据集的SRD 范围为0 到8,如果SRD 阈值a为0,则局部上下文等于方面词本身。结果如图7 和图8 所示,序列距离为Seq,依存距离为Deq。在本次的比较实验中,除SRD 阈值外,所有的参数和超参数均一致。由于实验结果波动,本文在每个数据集上进行了多次实验,以得到的平均结果进行比较。由图7 和图8 可知,无论是在Sentihood 数据集还是SemEval-2014 数据集中,使用序列距离的效果都优于使用依存距离。当阈值为3 附近的时候取得本次实验的最佳结果。
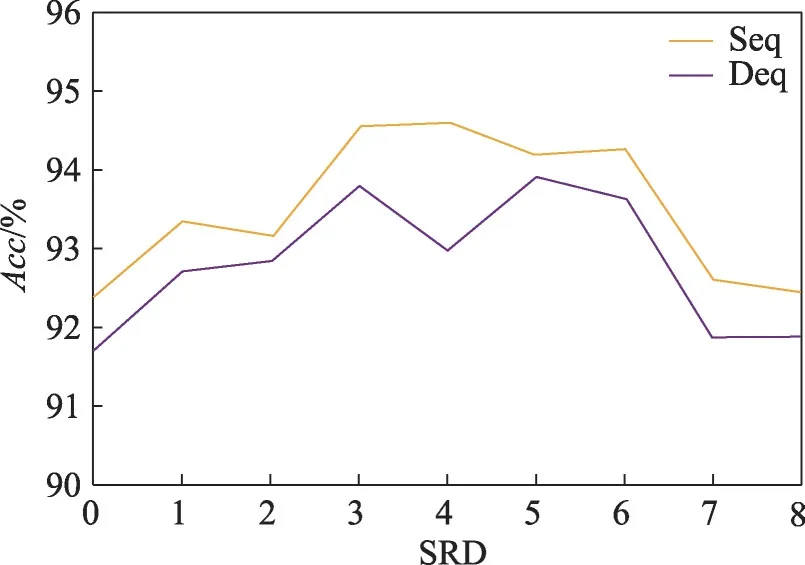
图7 不同a下DFLGA的精度(Sentihood)Fig.7 Accuracy of DFLGA under different a(Sentihood)
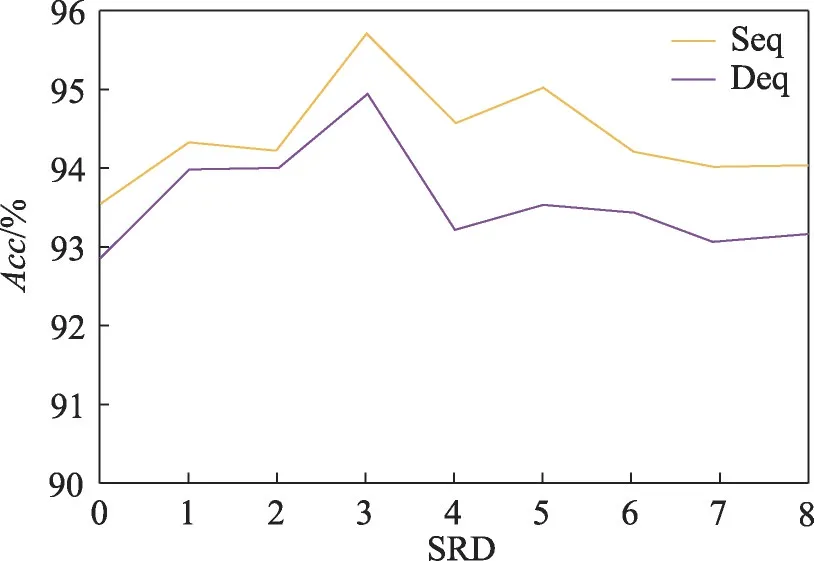
图8 不同a下DFLGA的精度(SemEval-2014)Fig.8 Accuracy of DFLGA under different a(SemEval-2014)
2.9 消融实验
为了分析DFLGA-BERT 模型每个组件的重要性,本文设计了DFLGA-BERT 关于TABSA 任务和ABSA任务的消融实验,实验结果列于表4和表5。
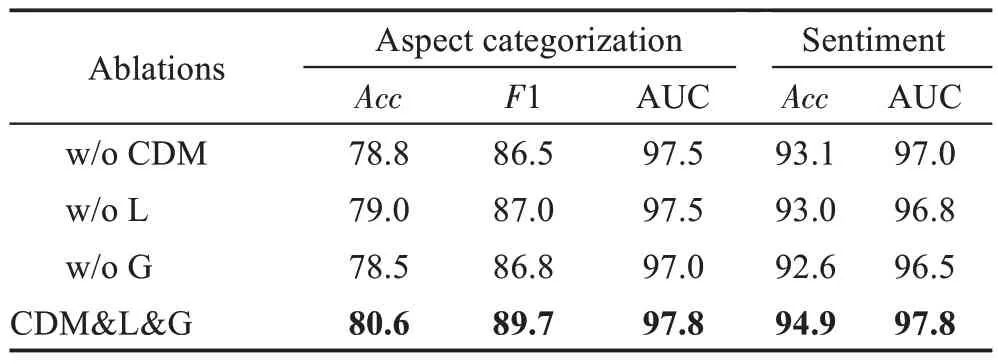
表4 DFLGA-BERT消融实验(TABSA任务)Table 4 DFLGA-BERT ablation experiment(TABSA task) 单位:%
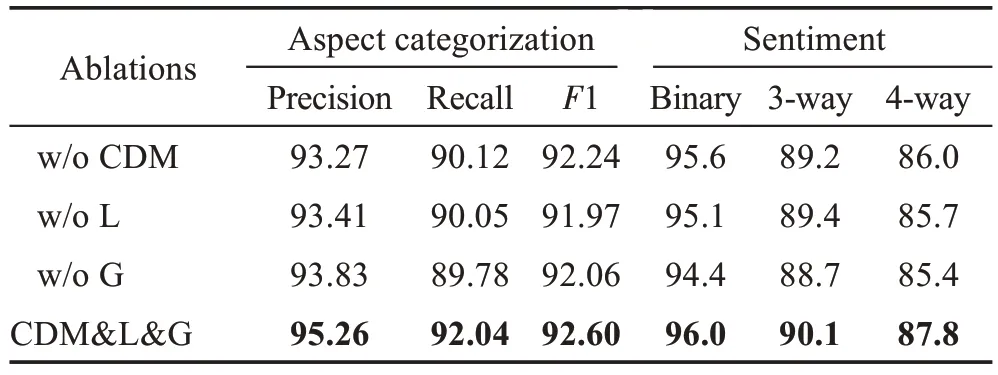
表5 DFLGA-BERT消融实验(ABSA任务)Table 5 DFLGA-BERT ablation experiment(ABSA task) 单位:%
由表4 和表5 可以清楚地看到,缺少了任意一个模块,DFLGA 的效果都会出现明显的下降。全局特征抽取模块对模型整体的效果影响最大,这表明了全局语义特征对自然语言理解任务的重要性,相对于普通句中方面词和情感指示词都相距较近,比较容易判断。最难判断的句子往往是情感指示词出现在模型意想不到的地方,甚至是局部特征抽取会直接忽略的地方,此时就只能依靠全局语义特征来进行判断。在模型整体中,局部语义特征和全局语义特征相辅相成,全局语义特征能够估计全面的语义但不够突出,局部特征能充分捕捉邻近的语义特征但容易忽略较远的词语,两个特征抽取模块都对DFLGA 模型非常关键。通过上述消融实验,可以验证DFLGA各个子模块在本任务中的有效性。
3 结束语
本文针对当前方面词情感分析任务研究中存在的不足,设计了DFLGA 模型。该模型首次将局部注意力模型LCF 与全局特征抽取的深度上下文感知网络相结合,能够高效地抽取指定方面词的情感特征。全局和局部特征抽取器的设计使模型能够兼顾全面的同时聚焦局部特征,同时注入“准”注意力来削弱文本中噪声对分类的影响。为了加快模型的训练获得更好的结果,本文使用了BERT 的预训练模型,在TABSA 任务的Sentihood 数据集5、ABSA 任务的SemEval 2014 中,进行了实验验证,取得了比之前的模型更好的结果。此外,本文还设计了消融实验以验证模型各组件的有效性。尽管DFLGA 模型在多个数据集上都有不错的表现,但仍然存在一定的提升空间。在未来,将考虑使用额外的领域内语料资源来增强BERT 在该领域的语义表示能力,从而帮助模型获得更优秀的情感判断能力。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
小雪花·成长指南(2022年1期)2022-04-09
开放教育研究(2020年2期)2020-03-31
金桥(2018年4期)2018-09-26
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
中国卫生(2014年5期)2014-11-10
