
基于改进Deeplabv3+的桥梁裂缝分割算法研究
2024-01-12 12:32姚玉凯郭宝云李彩林孙娜王悦孙晓凯
山东理工大学学报(自然科学版) 2024年2期
姚玉凯,郭宝云,李彩林,孙娜,王悦,孙晓凯
(山东理工大学 建筑工程与空间信息学院,山东 淄博 255049)
桥梁是交通运输体系的重要组成部分,保障桥梁安全稳定运行至关重要。混凝土表面裂缝是桥梁设施常见的病害形式,对桥梁性能有很大的影响,裂缝严重时会威胁到过往车辆与行人的安全。因此,及时发现裂缝并进行维护保养是保障桥梁工程安全运行的重要举措,有利于促进社会安全生产。传统的裂缝检测方法是人工进行目视观测,这种检测方法需要耗费大量人力,效率较低,对于一些高架桥进行人工检测时,需要检测人员高空作业,具有很大的安全隐患,并且检测结果具有主观性,无法统一标准[1]。
近年来,随着科学技术的快速发展,国内外学者将计算机视觉应用于桥梁裂缝检测领域,大大提高了桥梁裂缝检测效率,节约了时间和成本[2-4]。阈值分割算法因其实现简单、计算量小、性能较稳定被广泛应用于桥梁裂缝检测,如Li等[5]为了正确有效地从背景中分割出裂缝,提出了一种基于邻域差分直方图法的路面图像阈值分割算法,但该算法易受噪声干扰,抗干扰性差。 目标检测算法能够快速准确地检测裂缝,廖延娜等[6]针对桥梁裂缝复杂多样以及传统检测方法精度较低的问题,引入基于卷积神经网络的YOLOV3单阶段目标检测算法,该算法可用于实际工作中。但由于桥梁裂缝大多形状不规则、纹理复杂,所以目标检测算法对于小目标的、相邻紧密的物体检测效果不好,检测精度较低。
语义分割算法可以弥补目标检测算法的不足,能够对目标进行分割,准确地描述裂缝的整个区域,提供裂缝检测所需的形状信息。常用的语义分割算法有PSPNet、FCN、U-Net、OCRNet、Deeplabv3+。李良福等[7]提出了一种基于改进PSPNet的桥梁裂缝图像分割算法,能够提高算法检测精度和最大化保留裂缝图像细节信息。韩静园等[8]为了准确地对裂缝进行分割,提高复杂背景下裂缝分割效果,通过分析特征通道之间的关系,在FCN的池化层加入挤压和激励模块,并通过实验证明改进后的FCN模型对裂缝的分割效果良好。胡文魁等[9]为了解决传统图像分割方法存在去噪效果不明显、分割后裂缝连续性较差等问题,提出了一种基于全卷积神经网络的 BCI-AS(bridge crack image-automatic segmentation)桥梁裂缝自动分割模型和一种基于投影技术的最小二乘拟合中心线的裂缝宽度测量算法,在实际工程中有良好的可行性。朱苏雅等[10]为了解决传统的桥梁裂缝检测方法准确性低、容易丢失细节信息、难以获取裂缝宽度信息的问题,提出了Net卷积网络的像素级、小样本的检测方法,通过实验证明了这种方法效果良好。王墨川等[11]为了提高桥梁裂缝的检测效果,提出一种基于高语义特征与注意力机制的桥梁裂缝检测方法,实验结果表明该方法具有较高的检测精度和准确的定位效果。葛小三等[12]提出了一种基于Deeplabv3+的地物分类方法,证明Deeplabv3+对图像纹理及空间几何特征的识别具有很高的有效性和适用性。Fu等[13]基于Deeplabv3+模型对裂缝进行检测,证明Deeplabv3+能够准确分割裂缝细节。
综上所述,Deeplabv3+模型对于裂缝分割具有较好的效果,但是原始的Deeplabv3+模型需要依赖计算机的计算能力,并且分割速度较低。本文改进Deeplabv3+模型对裂缝进行检测,并将本文改进模型与PSPNet、U-Net模型进行对比分析,证明本文改进DeepLabv3+模型的有效性。
1 Deeplabv3+模型简介
Deeplabv3+是Deeplab系列中的最新内容,其分割效果非常好,是当前最流行的语义分割模型之一,其网络结构如图1所示。由图1可以看出Deeplabv3+网络结构包括两大部分,分别是Encoder和Decoder,也就是编码+解码的过程。
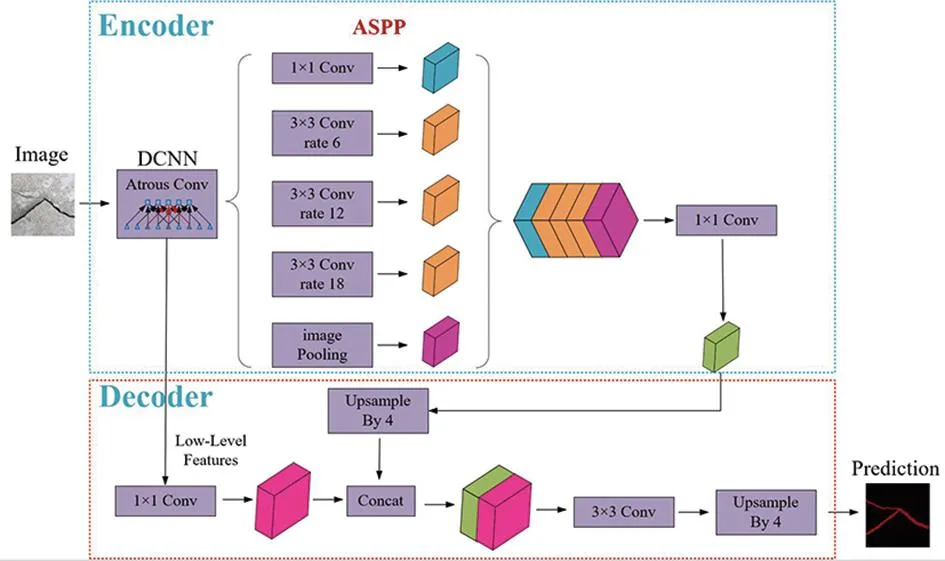
图1 Deeplabv3+网络结构
编码模块的作用是逐步减少特征图分辨率,捕获高级语义信息,该模块由DCNN和ASPP组成。利用DCNN可以获取两个有效特征图,一个是低层有效特征图,一个是深层有效特征图,低层有效特征图通过1×1卷积块直接进入解码模块。ASPP模块接受深层有效特征图并使用不同扩张率(6,12,18)的卷积进行特征提取,提高了网络感受野,能够获取更多的上下文信息,输出高级语义特征图,最后经过一个1×1卷积块后送入解码部分。
解码模块接受来自编码模块的两个特征图,对于高级语义特征图进行一次4倍上采样,在完成上采样后与经过一次1×1卷积的低层特征图进行特征融合,完成特征融合后再经过一次3×3的卷积进行特征提取,最后再次进行4倍上采样得到与原图分辨率大小相同的输出分割结果图。
2 改进的Deeplabv3+模型
改进Deeplabv3+模型的目的是提高模型的网络运行速度和分割精度,扩大感受野以提高模型性能,增强模型对裂缝的细节切分效果,避免分割过程中出现漏检、过检等现象。本文对模型进行以下改进:(1)在ASPP模块后增加RFB多分支卷积块;(2)替换Deeplabv3+模型的骨干网络,使用Mobilenetv2替换Xception作为主干特征提取网络;(3)使用深度分离卷积替换ASPP模块和Decoder部分的3×3普通卷积;(4)在ASPP模块中增加一次对底层特征的融合。改进后的模型网络结构如图2所示,其中红色虚线框内为改进部分。

图2 改进Deeplabv3+网络结构
2.1 引入RFB多分支卷积模块
RFB多分支卷积块是一个可以集成至其他检测算法的模块,具有很高的泛化性,能有效扩大感受野,提升模型鲁棒性。在目标检测过程中,使用强有力的主干网络能够提高网络的特征提取能力,但需要强大的算力支撑,运行速度较慢;使用轻量级的主干网络(如Mobilenetv2)运行速度快,但检测性能较差,而RFB模块能使轻量型模型在速度和精度上达到很好的平衡,将RFB模块与轻量级主干网络Mobilenetv2相结合能提高网络的特征提取能力,使模型更快更准。RFB的网络结构如图3所示。RFB模块包含两个组件:多分支卷积层和dilated(膨胀)卷积层,模块通过不同大小的卷积(1×1,3×3,5×5)和不同的卷积膨胀率(1,3,5)来提高网络感受野。
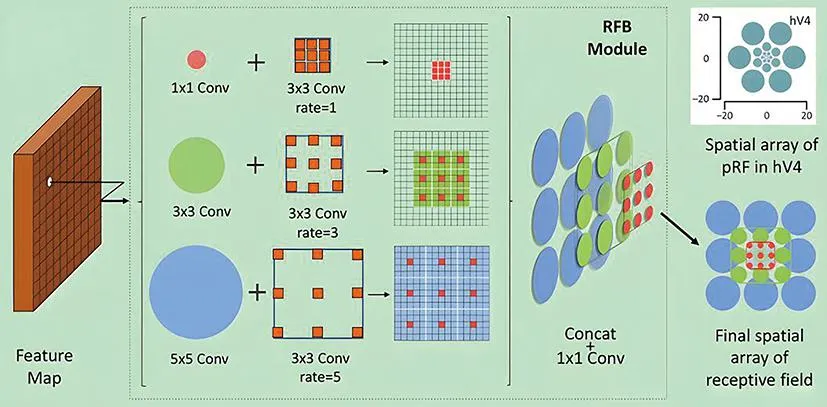
图3 RFB网络结构
2.2 基于Mobilenetv2的主干特征提取网络构建
Deeplabv3+采用的主干网络是Xception,本文使用Mobilenetv2替换Xception作为主干特征提取网络,主要原因有两点:一是由于裂缝分割任务语义信息简单,只包含裂缝和背景两类,故为了加快网络速度选择用Mobilenetv2替代 Xception 作为骨干网络;二是由于Mobilenetv2是Google公司针对手机、笔记本等移动嵌入式设备推出的一种轻量级的深层神经网络,受算力限制较小,具有轻质高效的优点,方便对桥梁裂缝进行移动识别并获得高质量像素级的分割结果图。Mobilenetv2网络结构如图4所示。

(a)主干部分 (b)残差部分图4 Mobilenetv2网络结构
Mobilenetv2使用了Inverted resblock(倒残差模块)和Linear Bottlenecks(线性瓶颈),倒残差模块首先对输入特征矩阵通过1×1卷积进行升维,增加通道的大小,然后通过3×3的深度卷积进行卷积处理,最后通过1×1的卷积进行降维。由于倒残差结构具有低维的特征,为了避免信息丢失,使用一个线性的激活函数替代Relu6激活函数。
2.3 融入深度可分离卷积降低模型参数量
通过实验发现Deeplabv3+模型的ASPP部分和decoder部分的参数量很大,为了减少模型的参数量和计算成本,将所有的普通卷积替换为深度可分离卷积,如图5所示。

(a)普通卷积 (b)深度可分离卷积图5 网络结构对比图
深度可分离卷积的计算步骤主要有两个,一个是逐通道卷积(depthwise convolution),另一个是逐点卷积(pointwise convolution)。逐通道卷积的一个卷积核负责一个通道,一个通道只被一个卷积核卷积,这个过程产生的特征图通道数和输入的通道数完全一样;逐点卷积会将上一步得到的特征图在深度方向上进行加权组合,生成新的特征图。经过计算发现,在计算量相同的情况下,使用深度可分离卷积比使用普通卷积能够提取到的网络特征更深。另外,如果要提取的特征越来越多,使用深度可分离卷积能够节省更多的参数,提高运算速度。
2.4 底层特征融合
通常情况下,桥梁表面裂缝形状多样、纹理复杂,且由于拍摄角度、光照条件以及图片分辨率等因素的影响,会增加模型对裂缝的分割难度,导致模型对裂缝细节切分效果较差,造成裂缝细节信息丢失严重的后果。为了提高模型细节切分效果,将1/2大小的特征图和decoder特征进行融合,有效提高了模型的分割效果。
3 实验及结果分析
3.1 数据集与实验环境
为了验证本文改进的DeepLabv3+模型对裂缝的分割效果,将改进后的Deeplabv3+模型与原模型及当前主流的图像检测模型PSPNet、U-Net进行对比实验。四种模型均使用相同的数据集,本文使用的桥梁裂缝数据集是VOC格式,包含3 876张图片,将数据集中图片按照 6∶2∶2 的比例随机划分为训练集、验证集和测试集。图片包含各种干扰条件下拍摄的裂缝,可有效检测模型的鲁棒性和泛化能力,如图6所示。

图6 桥梁裂缝图片
使用Labelme标注软件对所用的图像进行标注,构建桥梁裂缝数据集,以.json文件存储标注信息,标注流程如图7所示。实验平台软硬件配置信息见表1。
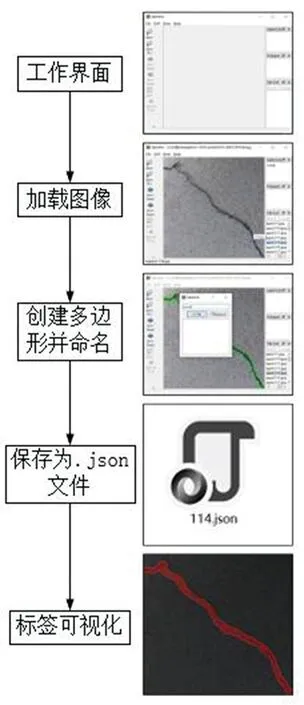
图7 标注流程

表1 实验平台配置信息
3.2 评价指标
本文的分割任务是提取影像中的裂缝信息,像素类别只有背景和裂缝两类,因此使用类别平均像素准确率(mean pixel accuracy,MPA)、平均交并比(mean intersection over union,MIoU)、精准率(Precision)、每秒帧数(frames per second,FPS)对模型性能进行评价。MPA表示的是分别计算每个类被正确分类像素数的比例,然后累加求平均;MIoU表示的是模型对每一类预测的结果和真实值的交集与并集的比值,之后求和再计算平均值;Precision表示的是预测结果中某类别预测正确的概率;FPS表示模型的推理时间,考察实时性,数值越大推理速度越快。各指标计算公式分别见式(1)—式(3)。
(1)
(2)
(3)
式中:i代表真实值;j代表预测值;TP代表真实值与预测值相同,为真阳,即预测为裂缝且真实标签也是裂缝的像素个数;FP表示预测为裂缝但真实标签为背景的像素个数,为假阳;k+1为类别数(本文只有裂缝和背景两类,故k=1)。
3.3 消融实验
为了分析本文提出的改进方法对Deeplabv3+模型的优化效果,利用相同数据集进行消融实验,实验结果见表2。通过实验数据可知,使用Mobilenetv2作为主干特征提取网络和在模型中加入RFB模块时模型的分割精度提高最为明显,使用Mobilenetv2作为主干提取网络时MIoU比原始模型提高2.62%,加入RFB模块后得到的MIoU比原始模型提高2.97%,推理速度也有所提升,说明这两点改进内容对于整体模型优化效果帮助最大。

表2 消融实验结果
3.4 不同算法模型实验对比
将本文改进模型与当前主流检测模型PSPNet、U-Net进行实验对比,实验所得各项指标数据见表3。从表3可以看出,Deeplabv3+和本文改进模型的各项性能均优于PSPNet和U-Net,且本文改进模型的推理速度优于Deeplabv3+,MIoU较原始模型提高了4.07%。实验结果证明,本文提出的改进Deeplabv3+模型能够提高裂缝分割精度和速度。
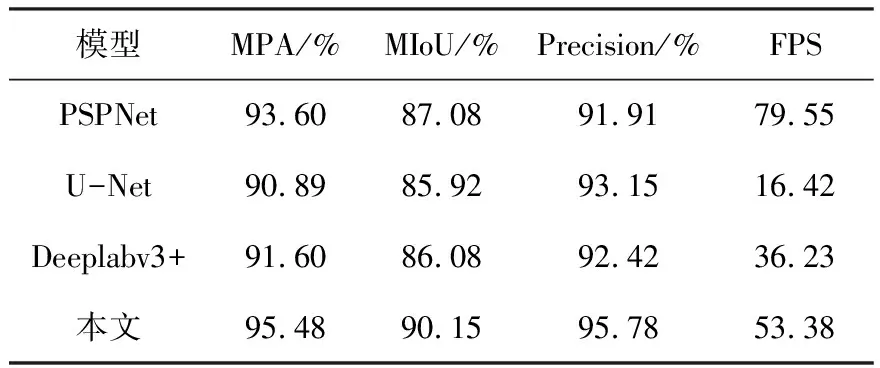
表3 不同模型分割结果
为了更加直观展示本文改进模型的有效性,将其与主流模型PSPNet、U-Net的 MIoU变化曲线进行比较,如图8所示。从图8可以看出,所有模型在前10轮训练中的MIoU值呈现急剧增长趋势,10轮以后逐渐趋于平稳,其中PSPNet模型在大约45轮训练时MIoU又出现了一次较大幅度的增长,而U-Net、Deeplabv3+以及本文模型变化趋势接近,但是可以看出本文改进模型MIoU值要高于Deeplabv3+和U-Net模型的,所以本文改进后的模型性能是有明显提高的。

图8 不同模型的训练性能
3.5 不同算法模型实验对比
将利用不同模型分割的裂缝结果进行可视化,分割效果如图9所示。由图9中(A)和(B)可以看出,对于一些纹理简单、背景单一的裂缝,四种模型均具有很好的分割效果,均能准确提取图像特征信息;但是对于裂缝纹理复杂、背景模糊的图像来说,PSPNet、U-Net和Deeplabv3+均存在漏检或过检现象,对于裂缝细节切分存在不足,如图9中(C)和(D)所示,而本文改进后的模型能够准确地对复杂裂缝进行细节切分,效果较好,说明本文改进模型具有很好的鲁棒性和抗干扰能力。

(a)原图(b) PSPNet(c)U-Net(d)Deeplabv3+ (e)本文图9 裂缝分割效果
4 结论
1)本文提出的基于改进Deeplabv3+和多分支卷积块的桥梁裂缝语义分割算法,使用轻量级网络Mobilenetv2作为主干特征提取网络,提高了模型的分割速度。
2)替换模型原有的卷积方式并增加一次对底层特征的融合,提高了模型的分割精度与细节切分效果;在原有模型基础上加入RFB多分支卷积模块,更好地平衡了模型分割的精度与速度。
3)通过实验证明,改进后的模型具有更好的细节切分效果,对于背景复杂的图像受噪声干扰较小,具有更高的鲁棒性, 过检、漏检现象得到明显改善。经过改进后的分割模型MIoU较原始Deeplabv3+模型提高了约4.07%,模型推理速度略有提高。在后续研究中要进一步提高裂缝分割精度,对裂缝进行量化。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
石油与天然气地质(2021年3期)2021-06-29
鸭绿江(2021年35期)2021-04-19
电子制作(2019年11期)2019-07-04
湖南教育·A版(2019年4期)2019-05-10
小学生学习指导(低年级)(2019年4期)2019-04-22
意林·全彩Color(2018年7期)2018-08-13
北京航空航天大学学报(2018年1期)2018-04-20
山东工业技术(2016年15期)2016-12-01
电视技术(2014年19期)2014-03-11
