
二次聚类的无监督行人重识别方法
2024-01-18 16:52熊明福肖应雄胡新荣
计算机工程与应用 2024年1期
熊明福,肖应雄,陈 佳,胡新荣,彭 涛
1.武汉纺织大学 计算机与人工智能学院,武汉 430200
2.武汉大学 国家网络安全学院,武汉 430072
行人重识别是针对同行人在不同时间地点下摄像机所采集的图片进行检索和匹配的技术,即给定一张特定的行人图像,行人重识别的目的是匹配出该行人在其他不同摄像头(相机)下所出现的图像[1-4]。其在视频监控、智能安防等领域有着极其重要的应用。本质上行人重识别可以视作为一项图像检索和匹配任务,其特点在于训练集和测试集是由不同的行人所组成的。一般来说,行人重识别主要分为有监督和无监督的方法[5],其中有监督行人重识别主要利用了有标签标注的训练集数据对模型进行训练,使得模型在未知的测试集上也具有一定的预测能力。此类方法在早期的科学研究中取得了不错的效果,然而其由于数据的标注工作费时耗力,从而限制了行人重识别在实际中的进一步应用。
近年来,无监督的行人重识别方法得到了越来越多学者的关注[6-9],其主要思想为利用一个预训练好的基础网络来聚类生成伪标签并根据伪标签做有监督学习。无监督行人重识别领域通常可分为两类:域自适应的行人重识别(unsupervised domain adaptation person Re-ID)[10-13]和纯无监督行人重识别(purely unsupervised learning person Re-ID)[14-16]。其中在域自适应行人重识别中,通常给定一个有标签的源域来训练网络,再使其迁移到目标域中并取得良好的效果,两个域有着不同的数据种类与数据风格[5]。而纯无监督行人重识别无需借助任何标注信息而仅仅只需要一个预先训练好的预训练模型,从而使得其在行人重识别任务中更具有挑战性。由于其不需要事先进行大量的数据标注,在领域内得到越来多的学者关注[17-18]。
因此,本文也主要关注纯无监督行人重识别方法。当前最先进的无监督行人重识别方法[8-9,17]大多都是同时利用聚类算法聚类得到的伪标签和内存字典中的特征实例做对比学习,从而能够以有监督的方式进行训练,在每个训练批次的开始前,所有训练集图像的特征都由当前网络进行特征提出,并由聚类算法类似DBScan[19]或者K-means[20]聚类生成伪标签,算法将聚类ID作为个人身份ID 被分配给每个图像。与此同时,大多数方法[8,17]都将初始化一个内存字典,由神经网络进行基于内存字典的对比损失[21]训练。此类方法在一定程度上都取得了不错的效果,被广大学习者所接受。但由于行人重识别本身就是一个复杂的问题[22],由于其本身从数据获取和目标检索都有其独特的性质,导致现有方法还有进一步提升的空间,主要表现在以下两个方面:
(1)现有行人重识别数据集大多数都由6至12台摄像机采集而成,不同的摄像机采集地点不同,因而也导致了其图像的光照环境也不尽相同,其相应的灰暗程度也不同。如图1(a)所示,针对同一数据集Market-1501[23],所抽取的6 张图像均来源于同一行人,由于拍摄视角、光照强度等因素的影响,其中第一排三张图像明显暗于第二排的三张图像,这种图像风格的差异性会影响后期聚类的精度,从而影响最终的模型准确性。同时,针对不同的数据集DukeMTMC-ReID[24]和Market-1501,如图1(b)所示,前者采集于冬季国外校园,行人多着厚重的冬装,色彩相对沉暗;而后者采集于夏天国内校园,其行人多穿短袖,色彩相对鲜明。这种显著的着装风格差异,降低了模型在这两个数据集之间跨域使用的鲁棒性,使得模型的泛化能力进一步减弱,从而导致行人重识别效果的下降。同时上述问题会产生伪标签噪声,所谓伪标签噪声,即聚类算法不能保证样本内的伪标签生成与真实身份的真实对应,从而在训练过程中会累积伪标签的噪声误差,从而阻碍模型的准确性。

图1 行人在不同相机下呈现照片风格不同Fig.1 Person showing different styles of photos under different cameras
(2)在利用伪标签进行有监督学习训练的过程中,因为每个聚类里实例的数量并不平衡,这是由数据集本身的数据分布特点和聚类算法的固有缺陷所带来的客观问题,实例少的聚类会比实例多的聚类更新更快。现有基于字典更新的方法由于内存字典的大小并不能无限制地增大,模型很容易向实例占比较小的样本标签偏移,因此内存字典的初始化与更新策略在模型的训练中起着至关重要的作用。
为了解决上述问题,本文提出了一种基于二次聚类的无监督行人重识别框架来解决当前方法存在的一些问题。针对聚类伪标签问题和更新速率不一致的问题,本文提出的框架主要包含两个部分,即基于全局的二次聚类模块以及基于聚类结果的有监督学习模块。前者主要解决跨相机间图像风格不一致的问题,后者主要解决网络更新速率不一致的问题。两个子模块协同并行优化,共同抑制因跨摄像机和环境因素的差异而导致行人重识别精度不高的问题,并且在公开数据集上相对于传统方法取得了不错的效果。
总结来说,该框架由两个模块组成,首先通过基于全局的二次聚类模块来分别以相机ID 和行人ID 聚类,然后通过基于聚类结果的有监督学习模块进行有监督学习,双模块协同训练以共同抑制跨摄像头间采集的图像所产生错误伪标签的问题。本文的创新工作主要表现在以下几个方面:
(1)提出了一种基于二次重聚类的无监督行人重识别方法,来解决因硬件差异和光照等因素带来样本错误伪标签生成的问题。
(2)提出的方法包括无监督聚类和有监督训练学习模块,前者基于全局二次聚类分别对相机ID 和行人身份ID 进行无监督分析,解决了同一行人在不同摄像机视角下的统一成像风格问题;后者则采用有监督学习方式改进了内存字典的初始化与更新方式,解决了模型在训练中偏移的问题。
(3)本文提出方法的两个子模块协同优化,共同抑制因跨摄像机和环境因素的差异而导致行人重识别精度不高的问题,并且在公开数据集上相对于传统方法取得了不错的效果。
1 相关工作
1.1 无监督行人重识别
根据是否利用有标注的源数据集,无监督行人重识别可分为两类:域自适应的无监督行人重识别(unsupervised domain adaptation,UDA)以及纯无监督行人重识别(purely unsupervised learning,USL)[14]。UDA尝试利用有标记的源域数据和没有标记的目标域数据来综合训练出一个在目标域表现良好的行人重识别模型,其目标是将从源域(source domain)学习到的知识迁移到目标域(target domain),从而提升模型在真实部署环境下的性能表现。而USL 其在模型训练之中不需要借助任何有标注的图片信息,因此其在模型的训练之中更具有挑战性。
虽然训练是在不同的数据条件下进行的,但UDA和USL的大多数方法采用相似的学习策略:通过聚类算法生成伪标签,然后利用内存字典进行对比学习。Zhong等[25]提出了一种基于相机到相机的风格转移来对齐目标样本的训练数据,Ge等[11]提出了一种基于域自适应的教师学生模型来应对域转换的无监督行人重识别,其利用了教师模型与学生模型两个模型来共同训练抑制聚类中产生的标签不一致问题。Yang 等[9]提出了一种动态和对称交叉熵损失来处理嘈杂的样本,并提出一种相机感知元学习算法来适应相机偏移。
在本文中,主要关注的是USL 方法,提出的框架其针对的是无监督行人重识别中的伪标签噪声以及内存字典[12]的更新问题,在下文中将详细介绍这两块内容。
1.2 伪标签噪声
所谓伪标签噪声,即聚类算法不能保证样本内的伪标签生成与真实身份的真实对应,从而在训练过程中会累积伪标签的噪声误差,从而阻碍模型的准确性。
在最近的研究中,减少因为聚类算法而带来的伪标签噪声问题主要有以下几种方法:伪标签更正法[18,26]和损失函数重设计法[27]。在训练过程中,他们重新加权计算权重以生成更为准确的伪标签。Li 等[28]试图通过训练一个额外的网络来重新加权伪标签样本。然而在网络的优化过程中,它需要额外干净的数据作为测试集,这在实际应用中是难以实现的。
面对伪标签噪声问题,提出了基于全局的二次聚类模块来抑制伪标签噪声问题,其核心思想是对数据进行二次聚类:以相机ID 为单位进行全局间的一次聚类和在相机内以行人ID为单位进行二次聚类。详细过程将在2.2节展开描述。
1.3 内存字典
当前大多数无监督对比学习方法都会初始化一个内存字典,由神经网络进行基于内存字典的对比损失训练,通过内存字典的不断动态更新从而促进对比无监督学习。与无监督的对比学习类似,当前最先进的USL方法也利用对比学习[8-9,17]构建记忆字典。在训练过程中,内存字典中的实例特征由同一个聚类中的实例特征动态更新。
然而由于每个聚类中的实例数目并不相同,实例数目较小的聚类更新得较快,实例数目较多的聚类更新得慢,模型很容易向实例占比较大的样本标签偏移。基于此,提出了基于二次聚类结果的有监督学习模块,灵感来源于文献[29],不再以实例特征为基准而是以聚类特征为基准来初始化与更新内存字典,可以有效地防止网络训练偏向实例数目较大的聚类,详细过程将在2.3 节展开描述。
2 本文方法
针对以往的工作没有考虑到不同相机对同一个行人所采集的图片可能会出现较大反差继而产生错误的聚类伪标签,以及每个聚类里的实例数量不平衡导致的网络更新速率不一致的问题,本文提出了一种基于二次聚类的无监督行人重识别网络框架。该框架主要包含两个部分,基于全局的二次聚类模块以及基于聚类结果的有监督学习模块。前者主要解决跨相机间图像风格不一致的问题,后者主要解决网络更新速率不一致的问题。两个模块协同训练配合,使得网络逐渐收敛,最终得到一个效果良好、泛化能力较强的行人重识别网络。
2.1 整体结构
本文使用ResNet 50[22]网络作为本文的基础网络(Backbone),其所用到的Resnet50 核心层主要用到5 个卷积层,第一个卷积层的输出为112×112,其内部配置为7×7大小的卷积核,所设的步长为2。
图2给出了本文所提出的整体网络框架,主要是由基于全局的二次聚类模块(global quadratic clustering module)以及基于聚类结果的有监督学习模块(supervised learning module based on quadratic clustering results)组成,为了方便描述,下文简称其GQCM模块以及SLM模块。
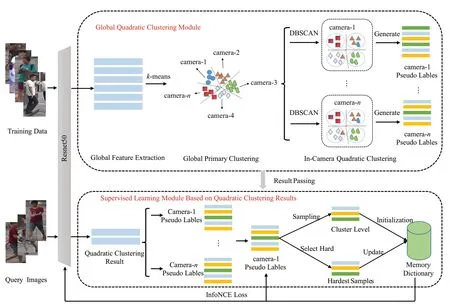
图2 基础网络框架Fig.2 Basic network framework
首先,初始化了一个预训练好的ResNet50 网络作为基础网络提取所有训练样本特征,GQCM作为二次聚类模块,针对所有特征做一次k-means 的均值聚类,主要作用为将图片根据不同的相机成像风格聚类为同一个簇心。将同一个簇心下的所有特征视为同一相机所采集到的图片所生成的特征并为其生成相机ID 伪标签。接下来,对同一相机下的所有图片特征做DBSCAN二次聚类并为其分配行人ID 伪标签。这样,就得到了以相机为分类的带有行人ID 伪标签的图片特征,就可以有效地解决因跨相机成像风格不统一而带来的聚类伪标签噪声问题。最后,GQCM模块将带有伪标签的图片特征传递给SLM模块,供其利用该伪标签做有监督学习。
2.2 基于全局的二次聚类模块(GQCM)
当前大多方法普遍采用聚类算法生成伪标签,然而,对同一个行人不同相机所采集的图像可能会出现较大反差继而易产生错误的聚类伪标签,即伪标签噪声问题,聚类算法不能保证样本内的伪标签生成与真实身份的准确对应。
为了抑制伪标签的噪声问题,本文提出基于全局的二次聚类模块(GQCM),该模块主要是针对全局图像进行二次聚类,即生成相机ID 伪标签与行人身份ID 伪标签,由于同一个相机所采集风格相似的图像,因此对此风格相似的图像进行DBSCAN 聚类,相对会产生较少的伪标签噪声,从而能有效地抑制因跨相机采集图像而带来的伪标签噪声问题,该观点会在后续的消融实验中得到验证。
基于此,对所有的训练样本进行二次聚类。在每个epoch 训练的开始,对所有的图片进行图片增强然后输入到基础网络中去提取所有的特征向量,然后对得到的特征进行二次聚类,如图3 所示:首先进行一次聚类(primary clustering)得到相机伪标签ID,再根据相机ID对同一个相机内的所有图片特征进行二次聚类(quadratic clustering)得到行人伪标签ID。

图3 相机ID聚类与行人ID聚类Fig.3 Camera ID clustering and person ID clustering
针对相机内的一次聚类,采用了k-means 聚类算法,选择的原因是行人重识别系统无论是在真实环境中应用还是数据集测验,采集数据的相机个数是已知的,而k-means算法需要初始化k个聚类中心,这与本文的要求相符,其具体过程为给定数据样本,包含了n个对象其中每个对象都具有m个维度的属性。k-means 算法的目标是将n个对象依据对象间的相似性聚集到指定的k个类簇中。每个对象属于且仅属于一个其到类簇中心距离最小的类簇中,然后通过计算每一个对象到每一个聚类中心的欧式距离,如下式所示:
式中,Xi表示第i个对象,Cj表示第j个聚类的中心,Xit表示第i个对象的第t个属性。Cjt表示第j个聚类中心的第t个属性。依次比较每一个对象到每一个聚类中心的距离,将对象分配到距离最近的聚类中心的类簇中,得到k个类簇,类簇中心就是类簇内所有对象在各个维度的均值,其计算公式如下:
式中,Cl表示第l个聚类的中心,Sl表示第l个聚类簇中对象的个数,Xi表示第l个类簇中第i个对象。算法的主要流程可以简化为两步:计算每一个对象到类簇中心的距离,依据类簇内的对象计算新的簇类中心。
根据一次聚类得到的相机ID 伪标签结果,对每个相机ID 内的图片特征用DBSCAN 进行轮巡二次聚类,为了防止同一目标在不同相机中聚类ID不一致的情况,可采取以下两种解决方案:(1)采取渐进式策略,前20 epoch采用单次聚类,后40 epoch采用二次聚类,并且其更新memory dictionary 的特征系数为0.01。可一定程度地避免少量目标在不同相机中聚类ID不一致所带来的准确率影响。(2)对模型进行微调,更改聚类顺序,即先进性全局聚类得到行人伪标签ID,后进行二次聚类得到相机伪标签ID,从根源上解决目标在不同相机中聚类ID 不一致的情况。经过实验验证比较,本文在后续实验中采用方案1。
DBSCAN算法需要两个超参数,一个参数为聚类的相邻样本间最大距离x,其表示聚类中的边界点与聚类核心Core point的最大距离;另外一个参数min samples是邻域中最小的样本个数,若聚类簇心中的样本值小于min samples,则识别为噪声数据或异常值。在本文的实验中,分别将x设置为0.4,min samples设置为4。通过二次聚类,可以将聚类得到的结果分配给每个将要训练的图片作为行人ID伪标签。
所有特征在经过GQCM 模块后,将得到的相机伪标签ID和行人伪标签ID传输到SLM模块,进行下一步处理。
2.3 基于聚类结果的有监督学习模块(SLM)
每个聚类中的实例数量不平衡,这是由数据集本身的数据分布特点和聚类算法的固有缺陷所带来的客观问题。针对该问题,本文所采用的解决方法是以聚类级特征[29]来做内存字典的初始化与更新。基于聚类结果的有监督学习模块(SLM)的主要作用是基于伪标签下的有监督学习,该模块的核心思想是,模块采用聚类级实例来初始化和更新内存字典,即在每个聚类的簇内选择一个特征作为该行人的ID样本特征来初始化和更新内存字典,基于此,使得实例少的聚类和实例多的聚类更新速率一致,避免模型在训练中偏向更新快的类别。
所谓聚类级实例,即每个聚类的簇内选择一个特征作为该行人的ID 样本特征来初始化和更新内存字典。关于同一个簇内的样本特征选择问题,灵感来源于最难样本挖掘[30],本文针对初始化和更新内存字典采用了最难样本选取,后文将做详细介绍。
如图4所示,针对同一相机下,在开始每个epoch训练前,将每个聚类级特征存入内存字典对内存字典进行初始化,n代表的是聚类簇心的个数。由于网络是实时更新的,n会随着网络的不断更新而变化最终区域稳定。随机选取n个聚类级特征来初始化内存字典,也就是从每个聚类的簇中随机选一个特征作为该行人ID的对应的内存字典。也可以选择离簇心最远的N个聚类特征样本来更新内存字典,但是在后续的实验中发现这样并不会带来准确率的提高,为了方便起见,本文选择随机选取,公式如下:

图4 有监督学习模块Fig.4 Supervised learning module
其中,U是一个简单的选择函数,而Xi则表示第i个聚类中所有特征样本,Ci表示内存字典中对应的行人ID特征。
在每个mini batch 开始前,选择P个人员身份,每个身份选取K张样本,就可以获得一个P×K总共为q的查询样本(query images)图片,将增强过后的训练图片数据输入进基础网络就可以得到q个实例样本的特征,此时使用InfoNCE loss[31]将其与内存字典中的所有集群特征进行比较,计算出对比损失,其计算过程如下:
其中,s为输入样本特征,c+为内存字典中的正样本特征,ci为内存字典中的负样本特征,当s与其正样本特征相似且与其他负样本不相似时,损失值较低。通俗地说,该损失函数在模拟的空间中会无限地拉近s的正样本并推远s的负样本,使得网络朝目标方向收敛。
在每个mini batch结束前,从n个行人身份中选择n张最难实例样本来动量更新内存字典。具体地来说,每个行人ID 都对应K张照片,从K张照片中选取一张照片作为最难实例样本来更新内存字典,更新过程如下:
ci如公式(3)所示,其含义相同。m是滑动平均更新参数,qdif是张图片中的一张最难样本,也就是在一个聚类中与聚心特征相似度最小的样本特征。
3 实验结果
3.1 数据集与评价方式
在四个常用的行人重识别数据集上评估了本文方法,分别为Market-1501[23]、DukeMTMC-ReID[24]、MSMT17[32]和PersonX[33]。同时为了证明本文模型的泛化能力,在一个常用的车辆重识别数据集VeRi-77[34]进行了实验。其具体信息如表1所示。

表1 数据集基本信息统计Table 1 Basic statistics of datasets
对于上述数据集,本文采用mAP 和rank 1/5/10 的精度进行评估。
3.2 实验细节
本文实验使用在ImageNet[35]上预训练ResNet-50作为骨干来提取特征,其所用到的ResNet-50 核心层主要用到5个卷积层,第一个卷积层的输出为112×112,其内部配置为7×7 大小的卷积核,所设的步长为2。同时使用SGD 用于优化模型。ResNet-50 基本层的学习率为0.000 5[36],其他层的学习率为0.005。
与DBSCAN 论文中阐述的聚类方法一样,使用DBSCAN和杰卡德距离(Jaccard distance)与邻近的k个样本特征进行聚类,在使用中选择k=30。对于DBSCAN中的超参数,两个样本之间的最大距离设置为0.4,聚类簇中的最小样本数设置为4。
本文所提出框架的实验平台是基于RTX 2080Ti(显存11 GB),算力为54.1 MH/s对应功耗180 W。因考虑到跨相机间图像风格不一致的问题,本文所提出方法需对全局图像进行二次聚类,与传统单次聚类的无监督行人重识别方法相比,其算法复杂度有所增加。具体表现为,从空间复杂度上来看:单次聚类与二次聚类,显卡显存占用无明显波动;从时间复杂度上来看:单次聚类每个epoch时间为32 min,而本文所提方法为47 min,时间多数消耗在二次聚类上即GQCM模块。
3.3 与当前最先进的方法比较
将本文方法与Market-1501、DukeMTMC-ReID、MSMT17、PersonX 和VeRi-776 上最近的USL 方法进行了比较,包括IICS[8]、ACT[17]、JNL[9]等方法。表2显示了本文提出的框架与近些年其他的方法在Market-1501 与DukeMTMC-ReID数据集上的比较结果。表中的Source列表项用来区分该方法是USL方法还是UDA方法。
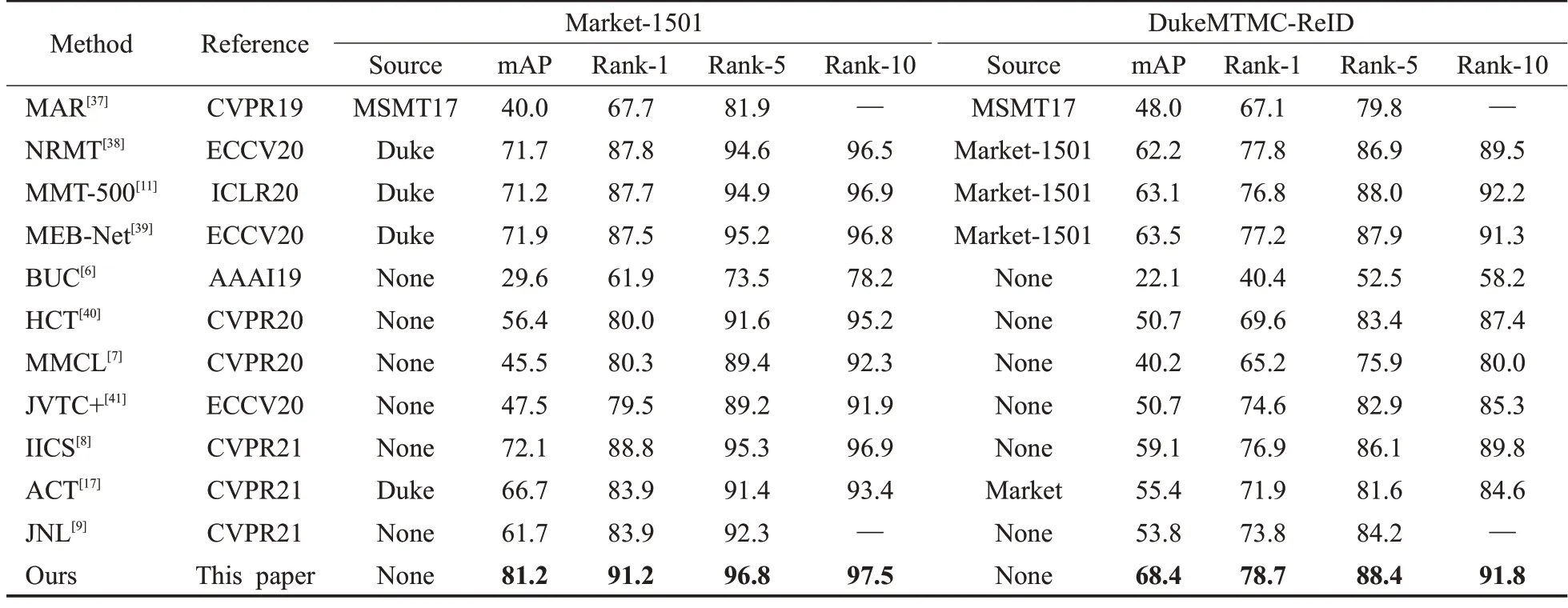
表2 与Market-1501和DukeMTMC-ReID数据集的性能比较Table 2 Performance comparison on Market-1501 and DukeMTMC-ReID datasets 单位:%
结果如表2所示,不仅将本文方法与传统的USL方法进行了比较,也与近期的一些UDA方法进行了比较,由于UDA方法使用了额外的有标签数据进行源域的训练,在大多数情况下,UDA方法比USl方法表现得要好,然而,本文提出的USL 方法却超越了这些UDA 方法。在Market-1501数据集上,本文方法取得了mAP=81.2%和rank-1=91.2%的准确率,在DukeMTMC-ReID 数据集上,本文方法取得了mAP=68.4%和rank-1=78.7%的准确率,当前最先进的方法较分别提高了2.4和1.8个百分点的rank-1准确率。
上述实验证明本文所提出的方法在很大程度上优于当前最先进的方法,本文所提出的方法实现了当前的最佳性能。这一显著的改进主要是由于本文方法考虑了不同相机间的成像风格差异,有效地抑制了因聚类而产生的伪标签噪声,并改进了内存字典的初始化与更新方式。
为了进一步验证本文所提出方法的有效性,在一个更大、更具挑战性的数据集MSMT17 和一个较为小众的数据集PersonX上进行了实验。令人感到惊喜的是,所提出的方法在这些数据集上表现依旧稳定,如表3、表4所示:在MSMT17和PersonX上,所提出的方法分别完成了mAP=31.1%,rank-1=60.4%的准确率和mAP=88.3%,rank-1=93.6%的准确率,与当前最先进的方法较分别提高了6.0 和2.5 个百分点。上述实验清楚地证明了所提出方法的优越性能。

表3 与MSMT17数据集的性能比较Table 3 Performance comparison on MSMT17 单位:%

表4 与PersonX数据集的性能比较Table 4 Performance comparison on PersonX 单位:%
同时为了证明所提出模型的泛化能力,在一个车辆重识别的数据集上进行了实验,如表5所示,在VeRi-776上,mAP=68.4%和rank-1=78.7%的准确率,其实验结果表明所提出的方法同样可适用于车辆重识别任务中。

表5 与VeRi-776数据集的性能比较。Table 5 Performance comparison on VeRi-776 单位:%
3.4 消融实验
本节在Market-1501上进行了消融实验来研究本文所提出的基于全局的二次聚类模块(GQCM)与基于聚类结果的有监督学习模块(SLM)对实验结果的影响,同时验证不同的内存字典初始化与更新机制对结果的影响,以全面衡量所提出方法的性能。
3.4.1 模块间消融实验
如前文中所提到,本文所提出的网络框架主要由两个模块组成:GQCM 模块与SLM 模块。全局图片特征经过GQCM模块得到了以相机为分类的带有行人ID伪标签的图片特征,就可以有效的解决因跨相机成像风格不统一而带来的聚类伪标签噪声问题。最后,GQCM模块将带有伪标签的图片特征传递给SLM 模块,供其利用该伪标签做有监督学习。
为了证明本文所提出的网络框架可以有效地降低伪标签噪声对结果的影响,设计实验如下:实验中分两次进行,第一次实验中使用单次聚类只生成行人ID 伪标签,即只使用SLM 模块。第二次实验即使用完整的网络框架即生成相机ID 伪标签又生成行人ID 伪标签,即使用GQCM 模块+SLM 模块,结果如表6 所示,其mAP和rank-1分别提高了2.1和2.8个百分点。

表6 模块间消融实验Table 6 Inter module ablation experiment 单位:%
为了进一步说明所提出的网络框架对伪标签噪声有很好的抑制效果,从Market-1501 数据集中随机选择10张训练集样本进行聚类实验,实验过程如下:第一次实验中使用单次聚类,第二次实验即使用完整的网络框架进行二次聚类,既生成相机ID 伪标签又生成行人ID伪标签,如图5所示,该图中,蓝色条状图代表单次聚类结果中,正确的伪标签数量。而红色的条状图则表示使用本文所提出的网络框架进行二次聚类所得到的正确结果数量。从实验结果看,本文所提出的二次聚类模块可大幅度提高聚类伪标签生成的准确率。
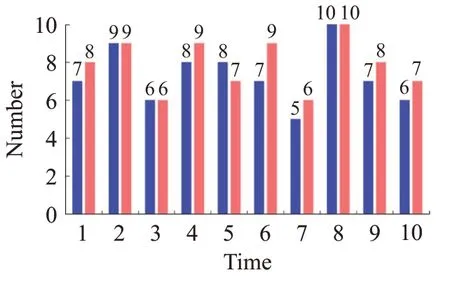
图5 单次聚类与二次聚类的结果对比Fig.5 Comparison of results between single clustering and double clustering
从上述实验结果可知,GQCM模块对样本特征进行二次聚类确实可以有效地降低伪标签噪声对结果的影响,从而使得准确率进一步提高。
3.4.2 内存字典的更新机制
SLM 模块采用聚类特征为基准来初始化与更新内存字典,其目的防止网络训练偏向实例数目较大的聚类从而影响模型最终的准确率。为了进一步探究SLM模块对本文网络框架影响,消融实验设计如下,分别以常规的实例级特征和SLM模块的聚类级特征更新初始化内存字典,其结果如表7所示。

表7 不同的更新机制比较Table 7 Performance comparison on PersonX 单位:%
实验结果表明,SLM模块的聚类级特征,即每个聚类的簇内选择一个特征作为该行人的ID样本特征来初始化和更新内存字典,可以有效地提高网络的准确率。
4 结论
本文提出了一种基于二次聚类的无监督行人重识别框架,该框架采用了二次聚类模块来抑制因跨相机采集数据而带来的伪标签噪声问题,并在内存字典的更新初始化机制上做出改进。证明该框架可解决跨相机采集数据而带来的伪标签噪声问题,通过大量实验并在多个数据集上验证表明,本文方法在无监督行人重识别研究中的有效性。
猜你喜欢
家教世界(2023年28期)2023-11-14
家教世界(2023年25期)2023-10-09
高技术通讯(2021年5期)2021-07-16
意林(2021年5期)2021-04-18
当代陕西(2019年13期)2019-08-20
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
创新作文(小学版)(2016年19期)2016-08-22
读者(2016年14期)2016-06-29
测绘科学与工程(2014年5期)2014-02-27
