
基于目标检测的临边洞口安全隐患识别研究
2024-01-19 06:52湖北兴发化工集团股份有限公司湖北宜昌443711
安徽建筑 2024年1期
万 勇 (湖北兴发化工集团股份有限公司,湖北 宜昌 443711)
建筑生产行业中,高处作业、洞口作业等作业形式十分常见,这导致了施工场地的风险性系数极高,安全生产形势十分严峻[1]。2019 年,住建部通报显示,全国房屋市政工程生产安全事故按照类型划分,发生415 起高处坠落事故,占总数的53.69%。统计数据表明,高处坠落在安全事故总量中占据的比重最大[2]。因此,如何通过科学的手段预防高坠事故的发生,是建筑安全管理行业有待解决的重要研究问题。
针对高空作业事故的原因分析,部分学者用相关理论进行了研究。李钰等[3]通过高处坠落事故致因网络分析,得出高坠事故发生的主要原因是临边洞口安全防护措施不到位;覃海松等[4]通过事故作业场景及存在安全问题分析,提出简易安全防护措施设计,加强临边洞口防护与监控成为降低高坠事故的根本之策。对高空作业的安全性影响最大的因素是洞口防护不到位,而在目前技术与管理方面的预防措施中,对存在的安全隐患仍是采用安全检查的方式进行排查,并未使用人工智能识别临边洞口存在的安全隐患,从此切口入手,展开对临边洞口安全隐患的相关研究,以达到预防高空作业坠落事故的目的。
随着人工智能的发展,人工智能在目标检测与识别这一方面的研究越来越深入[5-6],但人工智能目前尚未使用于识别临边洞口方面。目前,目标检测方法主要分为以下三种:第一种方法是传统的计算机视觉目标检测方法[8],主要利用数字图像处理方向的知识进行识别[9];第二种方法是深度学习目标检测方法,主要利用神经网络对图像进行训练[10],以达到要求的精度;第三种方法结合了深度学习和传统方法来完成识别[11]。
目前主流的基于深度学习的检测方法主要有以下两类。①基于区域检测目标并进行判断,如Fast R -CNN、Faster R-CNN 和R-FCN 等。徐守坤等[12]在传统的Faster R-CNN 基础上,采取多尺度训练和增加标注框锚点等方式,提高了检测的准确率,但由于没有分析两个目标之间的空间拓扑关系,该方法容易产生误检。②将检测问题转化为回归问题进行求解,在图片的不同位置均匀地进行密集采样,采用不同的长宽比进行采样,然后利用CNN 提取特征后,根据特征进行分类与回归,刘博等[13]提出基于Darknet 网络模型结合YOLOv3 算法实时对多目标跟踪检测。基于YOLO 改进方法的优势,具有速度快的优点,但是得到的目标框准确度不高。
通过对高坠事故原因的分析,预留洞口仍是事故高发场地。从减少危险源、消除安全隐患的角度出发[2],本文针对预留洞口与防护栏检测展开研究。分析众多目标识别算法特点并进行比较后,本文将对YOLOv3 模型[11]进行优化,得到更高精度、更高速度的目标检测模型。通过对临边洞口数据库的深度学习,实现对临边洞口及其防护栏的识别,同时集成临边洞口安全隐患识别系统,实时监控临边洞口不安全的现场环境,并对工人发出预警,可以有效地减少临边洞口的安全隐患,提高企业安全管理能力。
1 隐患目标检测方法
1.1 预警流程设计
本论文设计的YOLOv3目标检测算法主要是以Darknet-53 网络为网络基础,通过对不安全预留洞口进行检测,识别安全隐患,通过连接警报器发出警报[14],以此减少高坠事故。预警算法的流程图如图1所示。
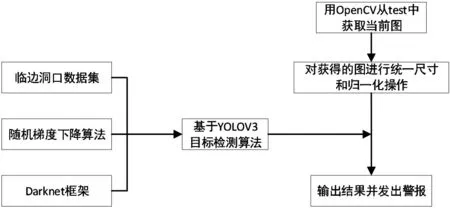
图1 预警算法流程图
1.2 YOLOv3模型构建
本文的YOLOv3 借鉴了Resnet,引入了多个Resnet 模块,并设计了一个具有更多层和更高分类精度的新网络。YOLOv3 采用Darknet-53[15]网络结构,借鉴残差神经网络设置残差单元[16],将网络深化为53 个卷积层,基于YOLOv2的passthrough 结构,检测出细粒度特征。根据检测目标情况,采用三种不同尺度的特征图进行目标检测,并对目标检测精度做出计算。构建系统后,对目标检测模型性能进行评价,建立评价函数,并以此和之前模型性能进行对比。
1.2.1 边界框设计
本文模型构建在边界框设计中,采用k 均值聚类得到Anchor,并将Anchor的个数增加到9,为每个尺度特征图分配3 个不同的Anchor,大大提高网络对小尺寸目标的检测能力,同时将预测层的Softmax函数改为Logistic函数[17],支持多标签对象的输出。
YOLOv3 的整体网络,将三种不同尺度的YOLOv3 网络特性输出为图,并将每一个特征图对应的输入图像输入到Si×Si个单元中,如果检测目标以一个单位为中心,该单位负责目标检测并预测各个边框和置信度得分,该得分能反映该边框内包含目标的可信程度,公式如下:
式中:Confidence表示边框置信度分数;Pr(object) 表示边框内是否包含目标,若不包含则为0,若包含则为1;IoU表示预测边框和真实边框的交并比;Detection表示系统预测值;GroundTruth表示真实值。
在目标位置预测方面[18],YOLOv3引入了在faster R-CNN 中使用锚点框(anchor box)[5],并在每个特征图上预测了三个锚点框。对于输入图像,YOLOv3 算法将其划分为13×13 个块,并预测每块3 个目标的边界帧。YOLOv3引入多尺度融合方法对目标的三尺度边界框架进行预测,大大提高了小目标检测的精度,avg IoU达到78.42%。
1.2.2 评价函数
在目标检测领域,准确性和召回率通常用于衡量目标检测系统的性能。准确率是指真正正确的目标在所有被判断为正确的目标中所占的比例。召回率是指系统正确检测到的所有真实目标的总和,即准确率衡量查准率,召回率衡量查全率,公式表示为:
式中:Precision代表准确性;Recall代表召回率;TP代表系统正确检测到的目标数量;FP代表系统错误检测到的目标数量;FN代表系统错过的正确目标数量。
实际上,这两个参数往往彼此相反,很难共同拥有。因此,通常会考虑AP值以确定模型的性能,AP值的公式为:
式中:N为测试集中所有图片的个数;Precision(k)表示在能识别出k个图片时Precision值;ΔRecall(k)表示识别图片个数从k-1 变化到k时Recall值的变化情况。
针对多个分类C,一般用平均AP 值mAP作为模型整体评价结果。
1.3 模型检测对比
相比于之前的模型,基于YOLOv3的改进模型复杂了很多,但是速度与精度是能够通过改变模型结构的大小来弥补的。
YOLOv3 的先验检测系统重新应用分类器或定位器来执行检测任务。在检测图片上多个位置和尺度运用模型,选取分数最高的区域作为输出结果。此外,与其他目标检测方法相比,其采用了一种完全不同的方法,在整个图像中应用单个神经网络,图像被分割成多个不同的区域,预测每个区域的边界框和概率,这些边界框根据预测概率加权。YOLOv3[19]模型与基于分类器的系统相比有更多优势。R-CNN 识别出一个目标,需要一个目标的数千张图像,它是通过一个单一的网络评估来预测的。而本方法在测试时查看整个图像,其预测是基于整个图片而言,更加完整。这使得YOLOv3 非常快,通常比R-CNN 快1000倍,比Fast R-CNN快100倍[8]。
YOLOv3 使用一个53 层的卷积网络结构,称为DarkNet-53。本网络设计借用了ResNet[20]的残网思想,仅使用3×3和1×1的卷积层。在ImageNet上,basenet的256×256分类精度Top-5分类准确率为93.5%,与ResNet-152 相同;Top-1 准确率为77.2%,只比ResNet-152 低0.4%。与此同时,darknet-53 的计算复杂度仅为ResNet-152 的75%,实际检测速度(FPS)是ResNet-152的2倍,在保证准确度的前提下,能够达到实时监测的效果。
2 识别算法设计
2.1 算法设计
2.1.1 算法设计流程(见图2)

图2 算法设计逻辑图
2.1.2 非极大值抑制模块设计
为实现设计的先检验系统功能,对本模块进行设计。非极大值抑制(Non-Maximum Suppression,NMS),在检测图片上多个位置和尺度运用模型,选取分数最高的区域作为输出结果,抑制非最大值的元素可以理解为局部最大搜索。这个局部表示一个具有两个可变参数的邻域,其中一个可变参数是邻域的维度,另一个是邻域的面积大小。例如,在临边洞口的检测中,每一个滑动窗口会根据检测图片的物体给出一个评价分数,滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。在这种情况下,NMS 能够选择得分最高(洞口概率最高)的邻域,并抑制得分最低的窗口,输出分数最高的区域作为结果。
2.2 数据集整理
训练的前提是大量的数据样本,并且需要预先确定训练样本分类,而检测临边洞口与护栏两类数据则需要两个训练样本分类即可。数据样本的正确与否决定了训练的效果,本文通过手动选择的方式来选择训练数据集,通过人为的判断来选择目标。收集到足够的数据集后即可开始整理与清洗,从原始图像中清洗出特征数据和标注数据,最终生成的数据主要是供模型训练使用。
目前在临边洞口识别领域没有公开的大型数据集,本实验所用数据集为自制数据集。主要包括预留洞口、预留洞口防护栏、基坑、基坑防护四类,总共包含200 张图像,其中150 张作为训练图像,50 张作为测试图像,在训练集中随机选取5 张图像作为验证集。图像使用Darknet Mark Tool 进行图像标记,数据集图像由实拍图像和网络图像组成。
2.3 模型训练
2.3.1 终端输出
通过可视化中间参数,得到模型训练最佳效果的loss需要用到训练时保存的log文件。
利用extract_log.py 脚本,格式化log,用生成的新log 文件使得可视化工具能够绘图,随后使用脚本绘制变化曲线。运行之后,解析log文件的loss行得到一个关于loss 的txt文件,并会在脚本所在路径生成avg_loss.png,如图3 所示。由图可知,曲线趋近于平稳,代表训练误差小,效果好。
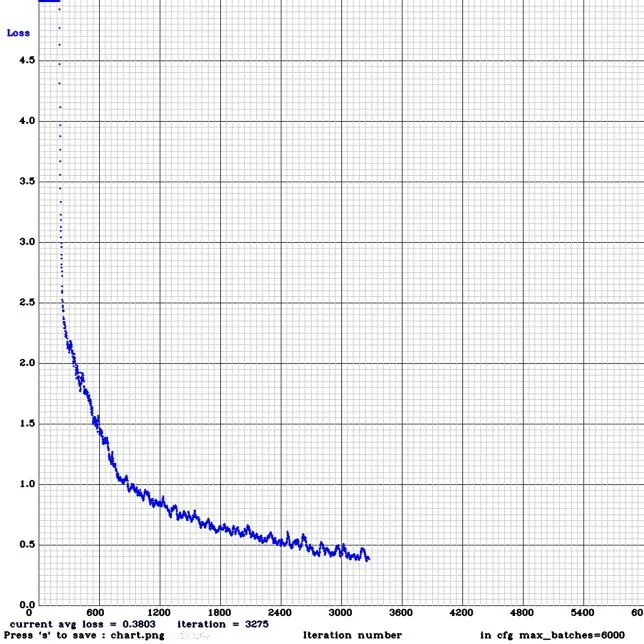
图3 Loss下降图

图4 预留洞口防护识别效果(一)
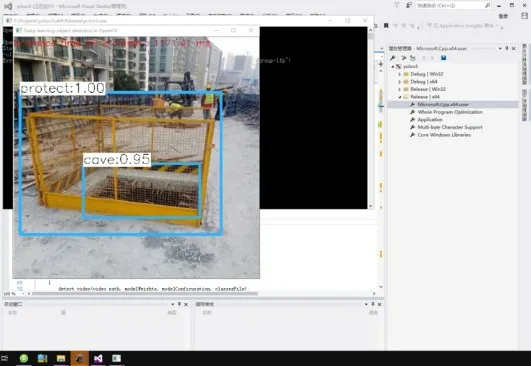
图5 预留洞口防护识别效果(二)

图6 预留洞口识别效果图

图7 视频监控实时识别效果
通过分析训练过程中终端输出的数据可知,本次训练最终迭代次数为3292次,停止训练时avg—average loss(error)—趋于0.397466,逐步稳定并开始收敛。
2.4 训练结果
输入测试集,全部进行检测后共输入50 张图片,共检测出47 张图片中的预留洞口与围栏,其中1 张图片预留洞口识别错误,1 张图片中的预留洞口未识别出来,召回率为97.87%,准确率为97.91%。
3 案例应用
以某建筑施工现场为例,对存在的预留洞口与防护进行识别,在案例中,共检测18 个预留洞口与防护,3 段视频实时监控,平均检测识别时间为0.3s,能够达到实时监控的目的,召回率与准确率均达到100%。
4 结论
通过采用Darknet-53 网络结构对YOLOv3 模型进行优化,在保持原有高准确率的同时,将计算复杂度降低为原来的75%,计算速度提升为原来的两倍,保证了检测的高实时性。
通过施工现场调研分析近十年高处坠落事故发生的原因,高处作业场所临边洞口缺少安全防护是高处坠落事故发生的主要影响因素。
建立临边洞口安全隐患识别系统,通过系统对临边洞口无防护围栏的安全隐患进行识别,对有临边洞口而无防护措施的图像进行筛选,以此排查临边洞口隐患之处,实现视频监控实时识别,召回率为97.87%,准确率为97.91%。后期将深入探究如何实现实时报警,并尝试设计临边洞口安全隐患识别系统与报警装置交互系统。
猜你喜欢
建材发展导向(2021年16期)2021-10-12
汉语世界(The World of Chinese)(2021年4期)2021-09-05
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
青少年科技博览(中学版)(2019年1期)2019-04-25
好日子(2018年9期)2018-10-12
中国交通信息化(2018年5期)2018-08-21
中国工程咨询(2016年1期)2016-02-14
作文周刊·小学一年级版(2015年43期)2015-05-30
