
融合BERT和VGG模型多模态虚假新闻检测方法研究
2024-01-20 12:19曾江峰
知识管理论坛 2023年6期
王蕊 黎欣雨 马霄
摘要:[目的/意义]旨在通过融合BERT和VGG模型解决当前虚假新闻泛滥、虚假新闻自动检测准确度较低、智能化较低问题。[方法/过程]使用预训练模型BERT和VGG将新闻中的图文分离并转化为特征向量集,并进行特征融合,运用SVM模型设计分类器实现多模态虚假新闻检测识别。[结果/结论] 实证结果表明,实验数据集F1值达到93%,相较于单独使用BERT和VGG模型提升7%与9%,该方法具有较高的准确率和召回率,能够有效地检测虚假新闻。
关键词:虚假新闻检测;特征提取;特征融合;多模态分析
分类号:TP391
引用格式:曾江峰, 王蕊, 黎欣雨, 等. 融合BERT和VGG模型多模态虚假新闻检测方法研究[J/OL]. 知识管理论坛, 2023, 8(6): 502-513[引用日期]. http://www.kmf.ac.cn/p/367/.
习近平总书记在二十大报告中强调,要加强全媒体传播体系建设,推动形成良好网络生态[1]。互联网的普及推动了信息传播的发展,覆盖了更为广泛的受众,但这些信息的真实性、准确性有待考量。“虚假新闻”一词在2016年美国总统大选期间成为主流,当时数百家网站发布了虚假或带有严重偏见的报道,其中许多是为了从社交媒体广告收入中获利[2]。2020年初,面对新冠肺炎疫情,恐惧与不安充斥全国,每天新闻产出量剧增,针对“辟谣”的百度搜索指数(2020年1月19—25日)与2019年春节期间相比,增长了5.4倍;中国科学院计算技术研究所研发的虚假新闻自动检测平台“AI识谣”平均每天发现具有争议性的疫情新闻200条;腾讯开发的以人工审核为主的事实查证平臺“较真”的疫情新闻特别版上线24小时,用户已超过4 000万,服务次数超过1亿。虚假新闻的存在严重威胁着人们的生活和社会秩序,对虚假新闻的检测已然成为一个备受关注的热门研究领域。随着多媒体技术的发展和社交媒体的广泛应用,新闻不再仅仅局限于文字形式,而是包括图片、视频和语音等多种形式。鉴于此,针对多模态的虚假新闻检测成为一个新的研究方向。
目前学界对虚假新闻检测方法的研究主要集中于以下几个方面:①针对文本形式的虚假新闻,通常采用自然语言处理技术,如词袋模型、词向量等,对新闻文本的特征进行分析和提取[3]。②针对图片形式的虚假新闻,采用计算机视觉技术,如卷积神经网络等,对图片的内容、色调、尺寸等特征进行分析和提取。③由于虚假新闻往往包含多种形式的信息,学者开始探索多模态特征融合的方法,将不同形式的特征进行整合,提高虚假新闻检测的准确率和鲁棒性。④对于虚假新闻的传播路径分析,研究者致力于了解虚假新闻的来源、传播规律和受众群体,以提高虚假新闻检测的精度和效率。⑤针对虚假新闻检测模型受到的对抗性攻击,学者提出系列防御方法,以提高虚假新闻检测模型的鲁棒性。总之,学界对于虚假新闻检测方法的研究涵盖了自然语言处理、计算机视觉、机器学习等多个领域,是一个具有挑战性和复杂性的研究方向。
虚假新闻带来社会恐慌、舆情肆意泛滥等严重的社会影响,检测并打击虚假新闻具有现实性和紧迫性[4]。目前大多虚假新闻检测要依靠读者检举揭发,并让相关专家和机构来证实。但这种方式时效性不强,检测效率不高,相比识别新闻的复杂过程,谣言的传播成本相对较低,制作虚假新闻的简单与检测虚假新闻的困难形成强烈反差。因此,构建自动化程度高、响应速度快的虚假新闻检测模型及系统是产学研界关注的焦点,如何高效检测虚假新闻这一问题迫在眉睫[5]。
在此背景下,本研究提出融合预训练BERT(Bidirectional Encoder Representations From Transformers)和VGG(Visual Geometry Group Network)模型的多模态虚假新闻检测算法。首先搜集的虚假信息数据集,用BERT模型提取文本特征向量;其次利用VGG模型提取图片特征向量;最后进行特征融合,将这两部分向量拼接在一起,用于训练最终的分类器。通过融合文本和图像两个单模态模型中的隐层特征,最终得到多模态融合特征和其对应的真假标签。这些特征和标签将作为下游分类器的输入,经过进一步的特征组合训练实现对真假新闻概率上的判别。最后将未被训练的数据集输入到训练好的分类模型,从而得到测试集的分类精度,完成对多模态新闻真假的检测。
1 相关研究
虚假新闻也可以被称为虚假信息,它被定义为故意捏造和已经被核实的虚假信息[6]。虚假信息通常表现为各种形式,如谣言、绯闻、流言、伪科学等[7]。目前学界对虚假新闻的研究主要聚焦于检测方法。首先,虚假新闻的检测主要采用机器学习方法,如基于深层次和集成分类器的微博谣言检测方法、提取Twitter中谣言的文本特征、行为特征,构建贝叶斯分类器。P. Zhou等[8]提出一个双流的 Faster R-CNN模型,将 RGB流和噪声流中丰富的篡改特征进行了很好的利用,以此实现多种类型虚假图片的检测。C. Boididou等[9]将取证特征用在虚假新闻检测领域,以块效应网格和分块离散余弦变换(DCT)系数等作为特征,取得不错的反馈结果。Z. Jin等[10]基于多媒体数据集分析新闻、文章的图像进行虚假新闻检测,探讨了视觉和统计图像特征,以预测各自文章的准确性,并提出了利用从文章中提取的冲突观点构建的可信度传播网络的虚假新闻检测方法。Y. Liu等[11]利用多元时间序列对新闻传播路径进行分类,提出了一种由传播路径构建与转换、基于循环神经网络的传播路径表示、基于卷积神经网络传播路径表示和传播路径分类四个主要部分构成的虚假新闻早期检测模型。
随着互联网技术飞速发展,虚假新闻呈现出多元化趋势,基于虚假新闻自身语言特性的虚假新闻检测模型出现很多局限性[12],因此,基于多模态特征的虚假新闻检测算法的研究颇多。刘鹏飞等[13]提出的模型利用多核异步长卷积神经网络对新闻标题作者及链接信息中隐含的辨别特征进行充分提取,根据新闻图片语义和物理级别的联系,利用注意力机制来提取带有权重的特征。P. Qi等[14]设计基于CNN和CNN-RNN的网络来捕捉频域和像素域的视觉特征,并使用注意力机制来动态融合特征表示,以检测虚假新闻。陶霄等人[15]提取文本、视觉和用户三个模态的特征向量,在词语和视觉的双向匹配、前期融合和后期融合中均加入注意力机制,实现特征和决策的自动加权,并基于 Dempster组合规则进行混合融合。R K. Kaliyar等[16]提出一个深度卷积神经网络模型(FNDNet),它包含一个预先训练好的名为 GloVe的单词嵌入和一个具有多个隐藏层的 CNN,在每一层提取用于分类假新闻的判别性特征。S. Deepak等[17]在神经网络中加入在线数据挖掘,从互联网上获得与所考虑的新闻文章相对应的知识特征。M. H. Goldani等[18]使用边际损失(Margin Loss),在 CNN上进行虚假新闻检测,这是第一个将边际损失用于文本分类工作的模型,并在 ISOT和 LIAR数据集上获得较好表现。S. R. Sahoo等[19]提出一种 chrome环境下 Facebook的自动假新闻检测方法。这些模型收集并分析多个特征,这些特征与 Facebook账户和一些新闻内容特征相关,并使用机器学习和深度学习将其输入分类器,然后选择匹配度最高的分类器,通过chrome扩展来检测假新闻。S. HAKAK等[20]从虚假新闻数据集中提取重要特征,然后使用由随机森林决策树和非线性分类器组成的集合模型对提取的特征进行分类。
MVAE和MVNN代表了在多模态信息处理领域的最新研究进展。这两个模型都致力于将不同模态的数据(如文本和图像)融合到一个统一的表示空间中,从而为任务提供更多元化和丰富的信息。MVAE采用了一种变分自编码器的结构,包括编码器、解码器和假新闻检测器模块。通过学习概率潜变量模型,MVAE能够将不同模态的信息编码成潜在的表示,这为任务提供了更灵活的信息表达方式。尽管相对于BERT+VGG+SVM,MVAE的精确率、召回率和F1值稍低,但它仍然表现出令人印象深刻的性能,尤其是在多模态任务中[21]。MVNN采用了不同的方法,它利用频域子网络和像素域子网络的特征来对输入图像进行分类。这种方法使MVNN在图像分类任务上表现出色,其精确率、召回率和F1值都达到了90%以上。这显示出了MVNN在图像相关任务上的强大性能[22]。
尽管MVAE和MVNN是多模态模型,它们提供了更丰富的输入数据表示,但在某些情况下,需要更复杂的模型结构和训练策略,以便充分发挥它们的潜力。相反,BERT+VGG+SVM虽然只是串联了文本信息和图像信息,但它在性能上仍然胜过了这两个多模态模型。这突显了模型选择的重要性,以确保最适合特定任务和数据集的性能。
综上,虚假新闻检测方式主要是基于用户行为可信度的方法以及基于网络传播的方法,具体而言是利用手工特征、深度学习、循环神经网络等研究方法。由于虛假新闻的形式多样化,仅基于虚假新闻自身语言特性的虚假新闻检测模型不足以满足现状,文本和图片为虚假新闻检测提供相对侧重、相辅相成的信息。在过去的研究中,已有学者使用单模态的方式进行虚假新闻检测。但单模态方法往往忽略了多模态信息之间的相互作用。虚假新闻的传播往往涉及多元化的信息,因此,为更加全面地评估虚假新闻的真实性,学界开始探索多模态虚假新闻检测的方法。鉴于此,基于多模态的虚假新闻检测方法备受关注[23],如何有效提取各个模态的特征并进行有效的融合是多模态虚假新闻检测的核心。针对现有研究的局限性,笔者提出了一种基于BERT和VGG模型的多模态虚假新闻检测方法。其中,BERT模型用于处理文本信息,VGG模型用于处理图片信息,笔者将 BERT和 VGG两个模型融合,提取虚假新闻的文本、图像特征,以解决虚假新闻检测问题。
2 研究框架
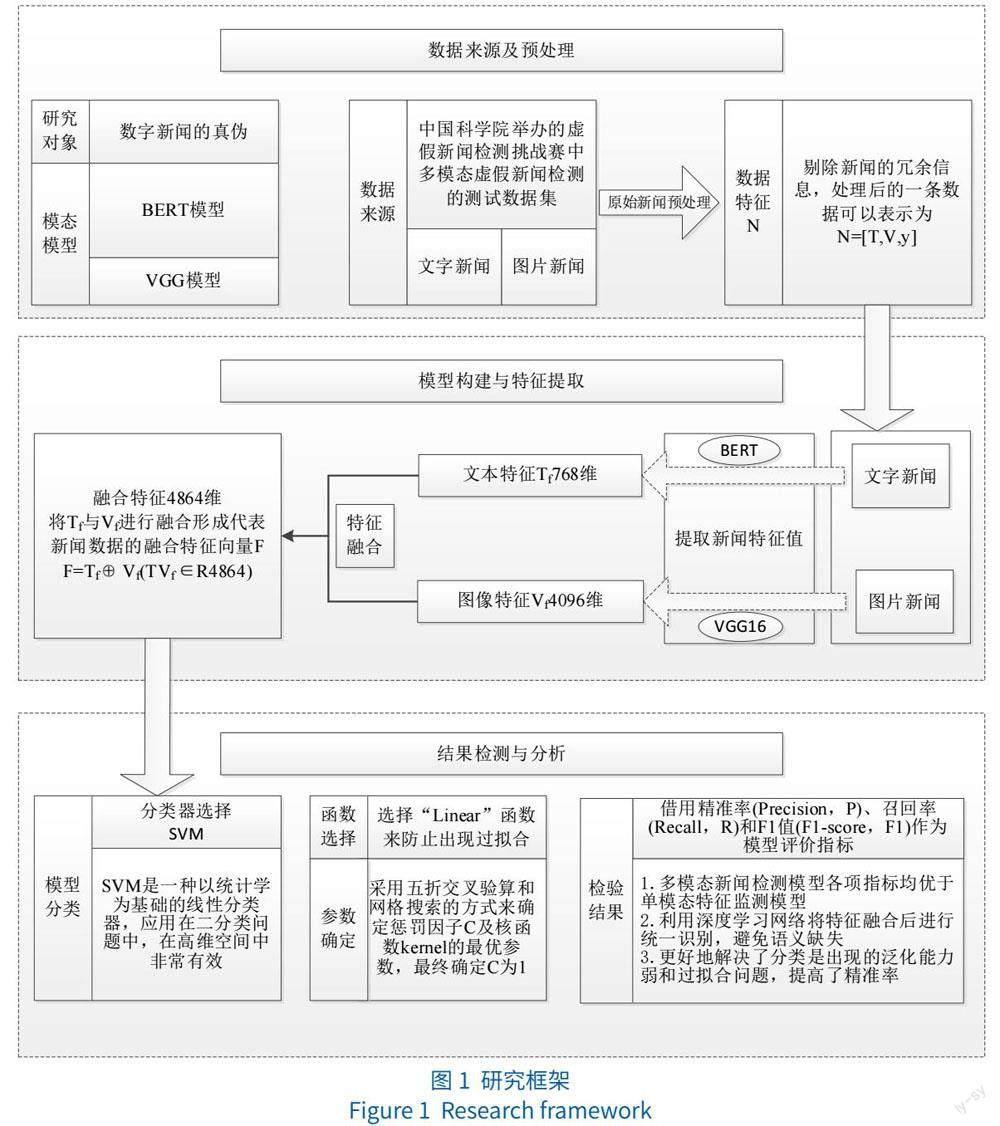
BERT直接引用Transformer架构中的Encoder模块,舍弃Decoder模块,自动拥有双向编码能力和强大的特征提取能力。VGG16采用连续的几个小卷积核(3×3)代替Alex Net中的较大卷积核(11×11,7×7,5×5),卷积的固定步长为1,并在图像的边缘填充1个像素,这样卷积后保持图像的分辨率不变,在保证具有相同感知野的条件下,在一定程度上提升神经网络的效果。基于此,对于搜集的虚假信息数据集,利用VGG模型生成图片特征向量;利用BERT模型生成文本特征向量;通过向量拼接的方式将文本和图片特征进行特征融合后基于SVM模型设计分类器来自动鉴别新闻的真伪,实现多模态虚假新闻检测。使用初步完成的多模态检测模型进行数据测试,分析测试效果,并根据效果对模型进一步优化。具体研究过程分为三个部分,如图1所示:
(1)数据来源与处理。数据来源于中国科学院计算技术研究所举办的虚假新闻检测挑战赛中多模态虚假新闻检测的测试集数据,并将数据中包含的发布人信息、发布时间等冗余信息剔除。经处理后的一条数据设为N=[T,V,Y],T代表新闻文本数据,V代表新闻图片数据,Y为该条新闻的真实性标签,取值为{0,1},0表示真实新闻,1表示虚假新闻。
(2)模型构建与特征提取。分别使用BERT模型和VGG16模型对处理后的文字新闻和图片新闻进行特征提取并融合,形成代表新闻数据的融合特征向量。
(3)结果检测与分析。将获得的新闻特征向量输入SVM分类器实现多模态虚假新闻检测,并选用精确率、召回率和F1值作为模型的评价指标,判断建立的bert-vgg-svm多模态新闻检测模型的优劣,并对检测结果进行分析。
3 模型构建
本研究旨在基于社交媒体新闻中的文字和图像数据使用,运用深度学习方法构建虚假新闻检测模型,以此识别虚假新闻。该模型将 BERT与 VGG16相结合,融合文本和图片特征对虚假新闻进行识别,其中使用 BERT提取文本特征向量,VGG16提取图片特征向量特征,经过向量拼接后输入 SVM中进行虚假新闻判别,输出为对应的真假新闻标签,TRUE为真实新闻,FALSE为虚假新闻。
3.1 特征提取
3.1.1 文本特征提取
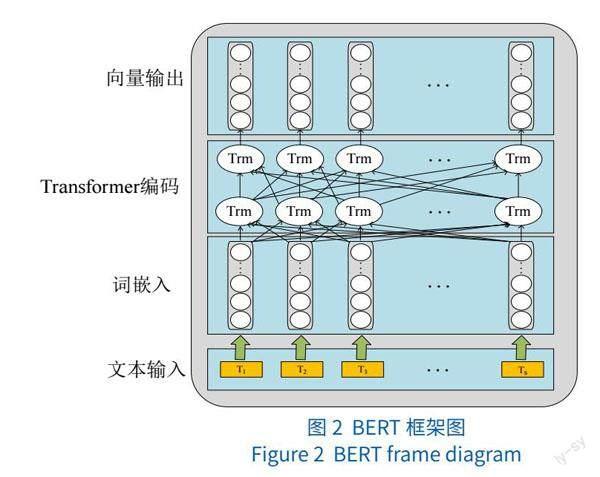
文本特征在文本分析中起到重要作用,直接影响虚假新闻检测的准确率。对每一条新闻文本进行预处理后,使用 BERT模型来提取文本特征,以捕捉文本中潜在的依存关系。BERT框架见图2,通过查询字向量表将文本中的每个字转换为词嵌入向量、句向量和位置向量的拼接结果,然后将其通过多层双向Transformer编码器,模型输出则是输入各字对应的融合全文语义信息后的向量表示。
BERT 引入自注意力机制,联合 Next Sentence Prediction和 Masked-LM进行训练。模型在提取文本特征时,读取 csv文件,输入包含 s个词汇的新闻文本数据 T=(T1,T2,…,Ts),在倒数第二层输出处理后的整个句子语义向量Tf,过程表示如公式(1)所示:
Tf=BERT(T)
Tf为 BERT模型在倒数第二层的向量输出,也是文本数据最终的表示特征,共有 768维。
3.1.2 图像特征提取
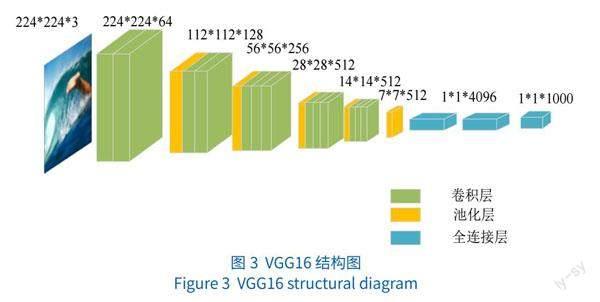
人类大脑处理视觉信息的速度是处理文字信息的 6 000倍,视觉信息可以缩小沟通差距、帮助理解信息内容、增强人类记忆。因此,模型同时融合图像特征,采用在 ImageNet数据库上训练的 VGG16模型提取图像特征。由图 3所示,VGG16由 13层卷积层和 3个全连接层组成,可以有效提取图像特征。
由于新闻图像数据大小不一,对其统一缩放后裁剪成规格为 224*224的区域,转换成符合输入的三通道图片格式Vimg,再输入 VGG16模型中进行特征提取。过程表示如公式(2)所示:
Vf=VGG16(Vimg)
Vf为 VGG16模型在 fc7层的向量输出,也是图像数据最终的表示特征,共有4 096维。
3.2 特征融合
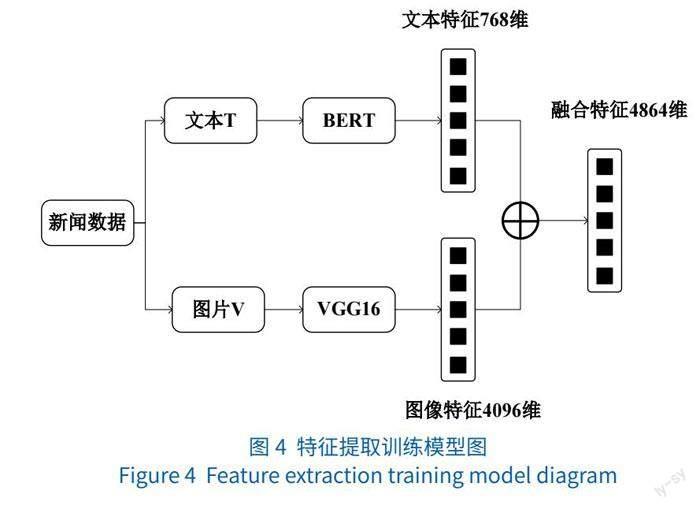
特征融合即输入两个模态的特征向量,输出融合后的向量。本模型采用向量拼接的方式,用Tf表示文本特征,用Vf表示图像特征,融合后的新闻特征用F表示。过程表示如公式(3)所示:
F=Tf⊕Vf (TVf∈R4864)
如图4所示,将提取出的新闻文本数据的特征向量Tf与新闻图像数据的特征向量Vf 进行融合,形成代表新闻数据的融合特征向量F。为了稳定获取新闻数据特征,将新闻数据分为真实新闻数据集和虚假新闻数据集,根据数据对应的标签分别进行训练,融合后的特征输出至csv文件中储存。
3.3 模型分类
通过融合文本和图像两个单模态模型中的隐层特征,得到4 864维的多模态融合特征D'={TVf1, TVf2, …, TVfn}和其对应的真假标签Label=[L1, L2, …, Ln]。这些特征和标签将作为下游分类器的输入,经过进一步的特征组合训练实现对真假新闻概率上的判别。最后将未被训练的数据集输入到训练好的分类模型,从而得到测试新闻的分类精度,完成对多模态新闻真假的检测。在分类器模型的选择中,优先选择scikit-learn包中的SVM(支持向量机)作为特征融合后的分类器。
SVM是一种以统计学为基础的线性分类器,被频繁地应用在二分类问题中。同时其表现出优秀的泛化能力,在高维空间中非常有效。尤其是在特征维数大于样本的情况下,可以将向量从低维空间映射到高维空间,效果要优于其他传统分类算法。它的主要思想是找到一个最优的超平面来划分不同类别的数据点。为了验证SVM的优越性,同时选取GBDT(Gradient Boosting Decision Tree)分类模型进行结果比对。
GBDT是一种基于决策树的集成学习算法,它通过迭代的方式训练多个决策树,并将它们组合成一个强分类器。GBDT算法的主要思想是通过迭代的方式训练多个弱分类器,每个弱分类器都尝试去纠正之前分类器的误差。在每一轮迭代中,GBDT算法都会新增一棵决策树,并将它的预测结果与之前的分类器进行加权组合,得到最终的预测结果。
在本文中,选择GBDT作为对比算法的依据是因为GBDT算法在处理非线性数据上具有很好的性能,并且可以自动进行特征选择。通过与SVM进行对比,可以更全面地评估SVM算法在高维稀疏数据上的优越性。同时,选取适当的对比算法也有助于验证实验结果的可靠性。
4 实验与分析
4.1 数据集
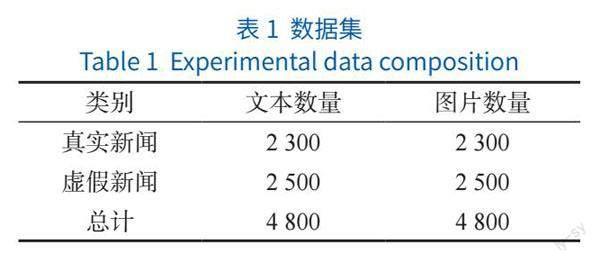
为保证数据的真实可靠,对新闻数据标记真假;作为多模态的数据集,需要同时包含文本和图片的新闻数据。数据集经过筛选和初步实验,确定选择中国科学院计算技术研究所举办的虚假新闻检测挑战赛中多模态虚假新闻检测赛道的数据。
虚假新闻多模态检测任务中,包含文本和图片两种模态的数据。图片模态包括“piclist”字段,表示该文本对应的图片,如果没有,则该字段为空;如果有多张,则使用“ \ t ”进行分隔。原始数据集由新闻文本数据以及相关的新闻图像数据构成。对于原始文本数据,由于原始数据信息的复杂性和无序性,在數据处理过程中,会将其携带的冗余信息进行剔除,可使用表情符号、URL、账号信息和发布时间作为标签替换,对空白字符和繁体字符等其他特殊字符做转换,保留剩余文字信息。对于新闻图片数据,新闻文本对应的图片类型不一,有GIF、JPG等,本文对新闻图片数据的处理方法是将文本对应的图片统一为JPG格式,因为新闻中的图片有可能不止一个,本文统一将第一个图片作为对应的数据。
由于融合后的数据特征维数过大,为了防止数据集过小出现模型过拟合的风险,因此训练数据集的大小应和特征维数同量级。这里选择2 200条真实数据和2 200条虚假数据,共4 400条数据作为训练集;另选择100条真实数据和300条虚假数据,共400条数据作为测试集,如表1所示:
4.2 SVM模型参数调优
由于本次实验的训练集维数即特征数很大,并接近于样本数,理论上应该选择线性核函数“Linear”来防止出现过拟合。为了保证实验结果的精准性,采用五折交叉验算和网格搜索的方式来确定惩罚因子C及核函数kernel的最优参数。惩罚因子C决定了分类器对误分类样本的惩罚程度,较小的C表示允许一些误分类,较大的C表示不允许误分类。网格搜索是一种通过在一定范围内不断调整参数来寻找最优参数的方法,而交叉验证则是一种通过将数据集划分为训练集和测试集来评估模型性能的方法。通过设定一组候选的惩罚因子C和核函数kernel的参数组合,对于每一组参数组合,都使用五折交叉验证来评估该组合下的SVM模型的性能,最终选择在验证集上表现最好的一组参数组合作为最优参数。
具体实现过程为:定义惩罚因子C和核函数kernel的参数范围,C=[0.01,0.1,1,10],kernel=[‘linear’, ‘rbf’, ‘sigmoid’]。将训练集数据分为5份。对于每一组参数组合,使用五折交叉验证来训练SVM模型,计算模型在验证集上的精度。将所有参数组合在五折交叉验证中的平均精度计算出来,选取平均精度最高的一组参数作为最优参数。使用最优参数训练SVM模型,并使用测试集来测试模型的性能。
最终,本次实验确定SVM模型的最佳核函数为预测的“Linear”,C为1。将 400条测试集输入到训练好的分类模型中。随着训练集样本数由 2 000条增加至 4 400条,准确度也逐渐提高。训练集所训练的模型测试分类精度由 0.84提高至0.93,效果远优于 GBDT分类模型的分类精度 0.735。
4.3 实验基线
本研究选择4种基线模型来进行虚假新闻检测的任务。这4种基线模型包括:
BERT+SVM(单文本特征):笔者使用BERT预训练模型提取文本特征,并使用SVM分类器进行分类。该模型只考虑了文本信息,并使用了SVM分类器进行分类。
VGG+SVM(单图片特征):笔者使用VGG预训练模型提取图片特征,并使用SVM分类器进行分类。该模型只考虑了图片信息,并使用了SVM分类器进行分类。
BERT+VGG+SVM(多模态分类):笔者使用BERT模型提取文本特征,使用VGG模型提取图片特征,将两个模型的特征向量拼接起来作为SVM模型的输入,并使用SVM分类器进行分类。该模型综合了文本和图片信息,并使用了SVM分类器进行分类。
BERT+VGG+GBDT(多模态分类):笔者使用BERT预训练模型提取文本特征,使用VGG预训练模型提取图片特征,并将两者合并后使用GBDT分类器进行分类。该模型综合了文本和图片信息,并使用了GBDT分类器进行分类。
这4种基线模型的选择是基于其代表性和效果评估。其中,BERT和VGG是当前在文本和图像领域最为流行和有效的预训练模型,而SVM和GBDT是分类问题中表现较为优秀的分类器。笔者希望通过对这4种模型的对比,能够更好地了解不同模型在虚假新闻检测任务中的表现。
4.4 评价指标
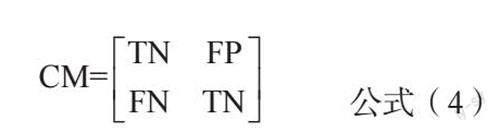
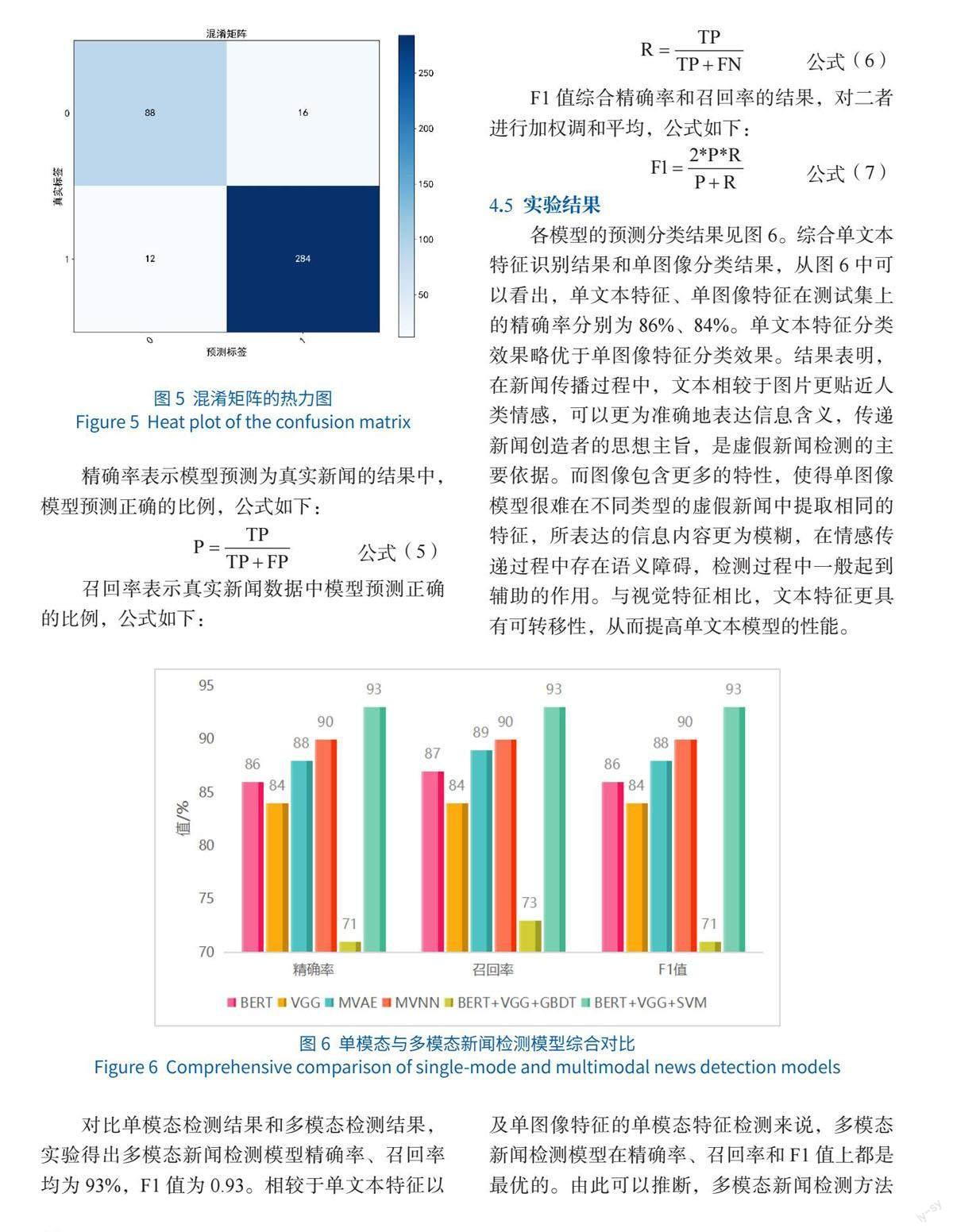
为了检验笔者提出的基于 ERT-VGG-SVM的多模态新闻检测模型的优劣,采用混淆矩阵(Confusion Matrix,CM)作为模型实验结果的评判指标。混淆矩阵见公式(4)。0是真实新闻,1是虚假新闻。TP表示虚假新闻被预测为虚假新闻的数量;FN表示虚假新闻被预测为真实新闻的数量;FP表示真实新闻被预测为虚假新闻的数量;TN表示真实新闻被预测为真实新闻的数量。如图5所示,TP和TN较大,FN和FP较小。
通过构建单文本特征、单图像特征以及 gdbt分类模型的基线模型,在同样的数据集下,如公式(5)—(7)所示,通过混淆矩阵得到TP、TN、FP和FN,得出精确率(Precision,P)、召回率(Recall,R)和F1值(F1-score,F1)。
精确率表示模型预测为真实新闻的结果中,模型预测正确的比例,公式如下:
召回率表示真实新闻数据中模型预测正确的比例,公式如下:
F1值综合精确率和召回率的结果,对二者进行加权调和平均,公式如下:
4.5 实验结果
各模型的预测分类结果见图 6。综合单文本特征识别结果和单图像分类结果,从图6中可以看出,单文本特征、单图像特征在测试集上的精确率分别为86%、84%。单文本特征分类效果略优于单图像特征分类效果。结果表明,在新闻传播过程中,文本相较于图片更贴近人类情感,可以更为准确地表达信息含义,传递新闻创造者的思想主旨,是虚假新闻检测的主要依据。而图像包含更多的特性,使得单图像模型很难在不同类型的虚假新闻中提取相同的特征,所表达的信息内容更为模糊,在情感传递过程中存在语义障碍,检测过程中一般起到辅助的作用。与视觉特征相比,文本特征更具有可转移性,从而提高单文本模型的性能。
对比单模态检测结果和多模态检测结果,实验得出多模态新闻检测模型精确率、召回率均为93%,F1值为0.93。相较于单文本特征以及单图像特征的单模态特征检测来说,多模态新闻检测模型在精确率、召回率和F1值上都是最优的。由此可以推断,多模态新闻检测方法可以提高虚假新闻检测的准确性,对于文本和图片表达情感有较大差异的情况,仅分析文本或仅分析图片,都可能对检测结果带来干扰。在这种情况下,将文本与图像的特征相结合,便能更加准确识别新闻的真假。
此外,在多模态新闻检测模型中,使用gdbt分类器的模型精确率结果为71%,使用SVM分类器精确率结果为93%,相较于gdbt分类器的基线模型高出22%。这也验证针对多样本、高维数特征所选的分类器是合适的,在数据分类方面有更好的表现。综合来看,多模态新闻检测模型均优于基准模型,其优点主要在于利用深度学习网络将提取的文本特征和图像特征融合后进行统一识别,避免单一模态语义缺失的缺点。同时,利用支持向量机有效处理高维数据的特点,增强分类器的泛化能力,解决了模型过拟合的问题,提高模型分类的精确率。
5 结语
虚假新闻的泛滥传播已成为一个全球性的社会问题,对公众的认知、社会舆论和政治经济等方面产生了重要影响。多模态虚假新闻检测是一个新兴的研究领域,其重要性和研究价值正在逐步被认识和认可,多模态虚假新闻检测技术的研究和应用,可有效地帮助公众识别和避免虚假新闻的误导,维护社会公正、公平和稳定。本研究基于多模态信息融合的思想,提出一种融合BERT和VGG模型的虚假新闻检测方法。该方法将文本和图像信息进行有机结合,同时利用BERT模型学习文本特征和VGG模型学习图像特征,以实现更加准确和可靠的虚假新闻检测。通过实验验证,本研究所提出的多模态虚假新闻检测方法准确率、召回率和F1值都优于基准模型,证明了该方法的有效性和可行性。
尽管本研究所提出的多模态虚假新闻检测方法在性能和可解释性方面都表现出较好的优势,但是仍存在一定的改进空间。①由于图片提取特征维数过多,可能存在一些冗余信息,延缓模型运行速度,如何在兼顾准确度和性能的条件下降低特征向量的维数是后续研究的重点之一。②文本特征与图片特征的普通拼接很可能难以充分利用多模态之间的关联,从而对分类产生一定的干扰。在后续的研究中,将采用不同的特征融合方法,揭示其对模型性能的影响,更近一步地提高新聞检测的准确率。
未来可以从以下几个方面进行深入探究:①优化模型的训练和调参方法,以进一步提高检测性能;②考虑更多的模态信息,如视频和音频等,以实现更全面的虚假新闻检测;③结合领域知识,以更好地应对虚假新闻检测中的特殊场景和问题。
參考文献:
[1] 新华社.中国共产党第二十次全国代表大会在京开幕 习近平代表第十九届中央委员会向大会作报告[EB/OL]. [2023-01-22]. http: //www.gov.cn/xinwen/2022-10/16/content_5718884.htm. (Xinhua News Agency. Twentieth National Congress of the Communist Party of China opens in Beijing Xi Jinping reports to the Congress on behalf of the 19th Central Committee [EB/OL]. [2023-01-22]. http: //www.gov.cn/xinwen/2022-10/16/content_5718884.htm.)
[2] ALLCOTTH, GENTZKOW M. Social media and fake news in the 2016 election[J]. Journal of economic perspectives, 2017, 31(2): 211-36.
[3] 刘赏, 沈逸凡.基于新闻标题—正文差异性的虚假新闻检测方法[J]. 数据分析与知识发现, 2023, 7(2): 97-107. (LIU S, SHEN Y F. Fake news detection method based on news title-text variability[J]. Data analysis and knowledge discovery, 2023, 7(2): 97-107.)
[4] VOSOUGHIS, ROY D, ARAL S. The spread of true and false news online[J]. science, 2018, 359(6380): 1146-1151.
[5] GUO C, CAO J, ZHANG X, et al. Dean: learning dual emotion for fake news detection on social media[J]. arXiv e-prints, 2019: arXiv: 1903.01728.
[6] RUCHANSKY N, SEOS, LIU Y. CSI: a hybrid deep model for fake news detection[C]//Proceedings of the 2017 ACM on conference on information and knowledge management. New York: ACM, 2017: 797-806.
[7] 刁海伦, 王树义, 王楠.基于多主体的微博网络虚假信息的集中甄别方法研究[J]. 情报科学, 2016, 34(2): 37-44. (DIAO H L, WANG S Y, WANG N. Research on centralised screening method of microblogging network false information based on multi-subjects[J]. Information science, 2016, 34(2): 37-44.)
[8] ZHOU P, HAN X, MORARIU VI, et al. Learning rich features for image manipulation detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. Salt Lake City: IEEE, 2018: 1053-1061.
[9] BOIDIDOU C, READOU K, PAPADOPOULOS S, et al. Verifying multimedia use at mediaeval 2015[M]//MediaEval 2015. Wurzen: CEUR-WS, 2015: 1436.
[10] JIN Z, CAO J, ZHANG Y, ET AL. Novel visual and statistical image features for microblogs news verification[J]. IEEE transactions on multimedia, 2016, 19(3): 598-608.
[11] LIU Y, WU Y F. Early detection of fake news on social media through propagation path classification with recurrent and convolutional networks[C]//Proceedings of the AAAI conference on artificial intelligence. New Orleans: AAAI, 2018: 354-361.
[12] MIAN A, KHAN S. Coronavirus: the spread of misinformation[J]. BMC medicine, 2020, 18(1): 1-2.
[13] 汪超.基于多模态融合的虚假新闻检测算法研究[D]. 安徽: 安徽理工大学, 2022. (WANG C. Research on false news detection algorithm based on multimodal fusion[D]. Anhui: Anhui University of Science & Technology, 2022.)
[14] PENG Q, JUAN C, TIANYUN Y, et al. Exploiting multi-domain visual information for fake news detection[C]//2019 IEEE international conference on data mining (ICDM). Beijing: IEEE, 2019: 518-527.
[15] 陶霄, 朱焱, 李春平.基于注意力与多模态混合融合的谣言检测方法[J]. 计算机工程, 2021, 47(12): 71-77. (TAO X, ZHU Y, LI C R. Rumour detection method based on attention and multimodal hybrid fusion[J]. Computer engineering, 2021, 47(12): 71-77.)
[16] KALIYAR R K, GOSWAMI A, NARANG P, et al. FNDNet–A deep convolutional neural network for fake news detection[J]. Cognitive systems research, 2020, 61: 32-44.
[17] DEEPAK S, CHITTURI B. Deep neural approach to Fake-News identification[J]. Procedia computer science, 2020, 167: 2236-2243.
[18] GOLDANI M H, SAFABAKHSH R, MOMTAZI S. Convolutional neural network with margin loss for fake news detection[J]. Information processing & management, 2021, 58(1): 102418.
[19] SAHOO S R, Gupta B B. Multiple features based approach for automatic fake news detection on social networks using deep learning[J]. Applied soft computing, 2021, 100: 106983.
[20] HAKAK S, ALAZAB M, KHAN S, et al. An ensemble machine learning approach through effective feature extraction to classify fake news[J]. Future generation computer systems, 2021, 117: 47-58.
[21] KHATTAR D, GOUD J S, GUPTA M, et al. Mvae: Multimodal variational autoencoder for fake news detection[C]//The world wide Web conference. New York: Association for Computing Machinery, 2019: 2915-2921.
[22] QI P, CAO J, YANG T, et al. Exploiting multi-domain visual information for fake news detection[C]//2019 IEEE international conference on data mining (ICDM). Beijing: IEEE, 2019: 518-527.
[23] 亓鹏, 曹娟, 盛强.语义增强的多模态虚假新闻检测[J]. 计算机研究与发展, 2021, 58(7): 1456-1465. (QI P, CAO J, SHENG Q. Semantic enhancement for multimodal fake news detection[J]. Journal of computer research and development, 2021, 58(7): 1456-1465.)
作者贡献说明:
曾江峰:提出研究思路,设计研究方案;
王 蕊:撰写论文;
黎欣雨:爬取、采集、清洗和分析数据;
马 霄:负责进行实验。
Research on Multimodal Fake News Detection Method Based on BERT and VGG Models
Zeng Jiangfeng1 Wang Rui1 Li Xinyu2 Ma Xiao2
1School of Information Management, Central China Normal University, Wuhan 430079
2School of Information and Security Engineering, Zhongnan University of Economics and Law, Wuhan 430073
Abstract: [Purpose/Significance] The aim is to solve the current problems of the proliferation of fake news, low accuracy and low intelligence of automatic fake news detection by integrating BERT and VGG models. [Method/Process] BERT and VGG models were uesd to separate the graphics and texts in the news and convert them into feature vector sets, and the feature fusion was carried out. The SVM model was used to design a classifier to achieve multi-modal fake news detection and identification. [Result/Conclusion] The empirical result shows that the F1 value of the experimental dataset reaches 93%, which is 7 percentage points and 9 percentage points higher than that of the BERT and VGG models alone, indicating that the combination of the two models has good detection accuracy and recall rate, and can effectively detect fake news.
Keywords: fake news detection feature extraction feature fusion multimodal analysis
基金項目:教育部人文社会科学研究项目青年基金项目“情境大数据驱动的社交媒体虚假信息识别模型与治理策略研究”(项目编号:21YJC870002)、湖北省自然科学基金一般面上项目“基于多层语义融合的多模态社交媒体虚假信息检测研究”(项目编号:2023AFB1018)和武汉市知识创新专项项目曙光计划项目“多源知识驱动的社交媒体虚假新闻检测研究”(项目编号:2022010801020287)研究成果之一。
作者简介:曾江峰,讲师,博士;王蕊,博士研究生,通信作者,E-mail:471133151@qq.com;黎欣雨,硕士研究生;马霄,讲师,博士。
收稿日期:2023-08-29 发表日期:2023-12-21 本文责任编辑:刘远颖
猜你喜欢
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
软件导刊(2017年7期)2017-09-05
无线互联科技(2017年12期)2017-07-18
科技资讯(2017年11期)2017-06-09
电子技术与软件工程(2017年5期)2017-04-23
现代电子技术(2017年7期)2017-04-14
中国生物医学工程学报(2017年6期)2017-02-10
广西科技大学学报(2016年1期)2016-06-22
教育教学论坛(2016年12期)2016-03-30
