
车联网POI查询中的位置隐私和查询隐私联合保护机制
2024-01-27 06:55赵国锋王杉杉唐雯钰
电子与信息学报 2024年1期
赵国锋 吴 昊 王杉杉 徐 川 唐雯钰
(重庆邮电大学通信与信息工程学院 重庆 400065)
1 引言
基于位置的服务(Location-Based Services,LBS)作为流行的位置感知应用,被广泛应用于车联网(Internet of Vehicle, IoV)[1,2]。其中,兴趣点(Point of Interest, POI)查询是应用最广泛的服务之一[3,4]。在POI查询中,车载用户需提交真实位置和真实查询内容,如查询阳光小区附近的医院。然而这一查询可以披露两种隐私,即位置隐私(阳光小区)和查询隐私(附近的医院)。当攻击者获取车辆的位置、查询内容以及额外信息,结合背景知识,很容易推断出用户的隐私信息,造成隐私泄露[4]。可见,位置隐私和查询隐私保护都是车联网LBS服务中重要的安全问题。
近年来,研究者提出了多种LBS隐私保护机制,对位置隐私和查询隐私分别保护[5]。Farouk等人[6]提出了一种基于同态加密的位置隐私保护方案。该方案先使用高级加密标准(Advanced Encryption Standard, AES)对位置加密,然后让LBS服务提供商对经AES加密后的数据执行全同态对称加密,最后将加密后的位置数据外包给云服务器,以获取服务。Shaham等人[7]设计了一种基于虚拟的位置隐私保护算法(Robust Dummy Generation, RDG)。该算法中的虚假位置能抵御维特比攻击,同时拥有较高的网格熵和转移熵。Xu等人[1]提出了一种基于差分隐私的位置隐私保护方案,根据用户的个性化隐私需求,对不同位置分配相应的隐私预算,添加对应的噪声,提供差异化的位置隐私保护。Pingley等人[8]提出了一种基于虚拟的查询隐私保护方案(DUMMY-Q)。其关键在于将多个具有不同虚拟查询内容但相同位置的虚拟查询和真实查询一同请求服务,来迷惑攻击者。虽然上述的隐私保护机制在一定程度上防止了LBS隐私泄露,但位置隐私和查询隐私并不是独立的,而是密切相关的。一方面,如果用户被定位或跟踪(位置隐私泄露),那么他容易被去匿名(查询隐私泄露);另一方面,如果用户的真实查询内容被识别(查询隐私泄露),那么可通过挖掘查询历史暴露他的位置(位置隐私泄露)[4]。因此,在对车载用户的LBS隐私保护时,亟需对位置隐私和查询隐私进行联合保护。
目前,对位置隐私和查询隐私进行联合保护的研究处于起步阶段[9],主要分为两类:加密方式[5]和虚拟序列[10]。Li等人[5]通过结合k匿名技术、伪随机函数和Paillier密码系统,提出了一种LBS隐私保护方案。该方案通过k匿名技术和伪随机函数来保护位置隐私和查询隐私。同时,基于Paillier密码系统,设计了一种增强的单轮盲过滤协议(enhanced One-Round Blind Filter Protocol, ORBFe),使查询对服务器不可见。Wu等人[10]从特征分布的相似性和隐私暴露程度两种因素出发,构建虚拟序列来掩盖位置和查询内容,以保护位置隐私和查询隐私,并分析得出位置隐私和查询隐私的语义相关性。然而采用加密方式的联合保护机制,由于费用消耗大,计算复杂度高并不符合车载用户的服务需求;采用虚拟序列的联合保护机制,虽然考虑到位置隐私和查询隐私的语义相关性,但忽略了检索区域(Area of Retrieval, AOR)半径和查询时间对位置隐私和查询隐私的影响,即忽略位置隐私和查询隐私在单个时刻和长期查询中的联系,容易遭受语义范围攻击[10]、时间关联攻击[3]和长期观察攻击[11],造成位置隐私和查询隐私泄露。
针对上述问题,本文提出了一种基于虚拟序列的位置隐私和查询隐私联合保护机制。具体工作如下:
(1)为了刻画位置隐私和查询隐私的相关性,考虑到POI查询对位置隐私和查询隐私的限制,将两类隐私的相关性分为语义相关性、时间相关性和时空属性相关性,并运用欧几里得距离和关联规则算法分别对这3种相关性进行建模分析,最后整合得到相关性判断模型。
(2)为了将两类隐私的相关性引入到联合保护中,基于虚拟序列,将联合保护转化为虚拟序列的选择问题,并整合相关参数,如匿名程度、分散程度以及真实查询的相关性值等,建立联合保护优化模型,得到匿名程度高且匿名区域大的匿名查询集,防止攻击者识别出真实查询。
(3)通过安全分析,证明了本文方案能抵御推断攻击和针对位置隐私和查询隐私的联合攻击;同时,基于真实数据集,与现有方案进行实验对比,验证了本文方案能更有效地保护车载用户的LBS隐私。
2 相关定义和问题分析
2.1 LBS隐私
定义1(POI查询) POI查询是指在ti时刻下,用户u向LBS服务器发送位置和查询内容,以请求服务。同时,由于本文方案采用虚拟序列的思想,POI查询可以简化为
定义2(POI查询服务流程[12]) LBS服务流程可分为3步:(1)用户将当前位置和查询内容提交给LBS服务器;(2)LBS服务器根据提交的和在半径为R的AOR内搜索POI;(3)搜索完毕后,LBS服务器将结果返回给用户,用户再过滤并获得半径为r的感兴趣区域(Area Of Interest, AOI)中的POI。
定义3(虚拟序列[10]) 虚拟序列由多个虚拟查询构建,每个虚拟查询里面包含一个虚假位置和一个虚拟查询内容,则定义为
其中,D Si是ti时刻的虚拟序列;是虚拟查询;是虚假位置;是虚拟查询内容;j=1,2,...,ki-1;ki是ti时刻匿名查询集的大小。最终虚拟序列DSi将同真实查询组成匿名查询集seti,提交给服务器,使攻击者或不受信任的服务器难以推断出用户的真实查询。
2.2 攻击模型
一般来说,在LBS中存在两类攻击者:主动攻击者和被动攻击者[13]。主动攻击者能通过攻击LBS服务器来获取背景知识,如路网环境、用户查询历史等,而被动攻击者能在通信信道中窃取用户跟LBS服务器的交互信息。此外,LBS服务器通常对于用户是不可信的[4]。因此,本文假设的攻击者有以下3种类型:(1)攻击者攻击LBS服务器,获取背景知识和用户的匿名查询集;(2)攻击者在通信信道中拦截用户的匿名查询集;(3)LBS服务器本身不可信。提出的联合保护机制不仅需要抵御这3类攻击者的推断攻击,还需抵御针对位置隐私和查询隐私的联合攻击,如语义范围攻击[10]、时间关联攻击[3]和长期观察攻击[11]。
2.3 问题描述
车联网中LBS系统如图1所示,在一段时间内(t1到t3),车载用户从位置行驶到位置。当车载用户不定时请求服务时,车辆首先跟GPS卫星获取当前位置的经纬度,然后向LBS服务器发送经过隐私保护后的匿名查询集seti(),LBS服务器会对此进行答复。显然直接发送真实查询会泄露用户的隐私,需要对用户的位置隐私()和查询隐私()加以保护。

图1 车联网中LBS系统场景
3 系统模型
3.1 位置隐私和查询隐私相关性刻画
3.1.1 语义相关性
本文结合定义2对文献[10]的语义相关性进行延伸。在POI查询服务中,一个位置在半径为R的AOR内可支持查询的POI种类是有限的。如图2所示,存在两种情况:一是用户在位置loc1查询附近的餐厅。在此时的AOR中,位置loc1支持查询的POI种类有餐厅和便利店,则服务器能满足用户的服务需求;二是用户在位置loc2查询附近的餐厅。在此时的AOR中,位置loc2支持查询的POI种类有宾馆和便利店,则服务器会返回“范围内没有餐厅”的答复,不能满足用户的服务需求。则语义相关性定义为
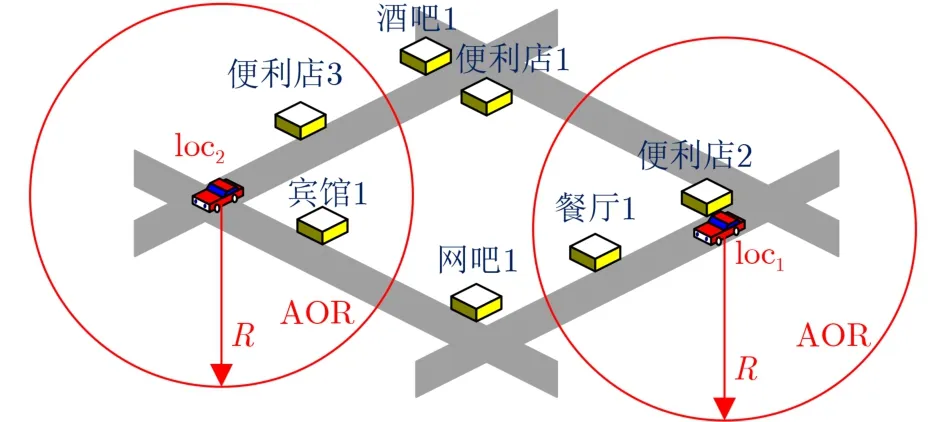
图2 语义相关性
其中,C1(loc,q)=1表明位置loc和查询内容q具有语义相关性;C1(loc,q)=0表明不具有语义相关性;dis(loc,POIs)是位置loc和离其最近POIs之间的距离;POIs是一个具体位置,其语义属于q,可从地图中统计获得;R是AOR的半径。
3.1.2 时间相关性
现有方案没有考虑到在单个时刻下,查询时间对位置和查询内容的影响,即在不同时段,某位置和不同查询内容的关联强度会有不同。如在早上8点,车载用户发出查询:在小区查询附近的早餐店。结合现实生活的规律,可知早上8点在小区查询附近早餐店的概率高,表明在早上8点,小区和附近早餐店的关联强;而早上8点在小区查询附近酒吧的概率低,表明在早上8点,小区和附近酒吧的关联弱。此外,关联规则算法可在数据集中挖掘出项与项之间的关联关系。在关联算法中,一条关联规则只有同时满足最小支持度、最小置信度和评估标准,才能称为有效的强关联规则。因此,本文利用关联规则算法中的FP-Growth算法[14]来挖掘出不同时段位置和查询内容的关联强度,得到时间相关性。
本文采用纽约出租车数据集[15],充当用户的查询历史集,来挖掘时间相关性,其具体介绍在5.1.1节,里面包含3项数据:时间、位置和查询内容。另外,为了提高挖掘效率,以时间段t为分隔标准,如早上8点到9点为一个时间段。则根据定义1和关联规则算法,在t时段的支持度定义为
其中,sup(t,loci,qj)是在t时段,位置loci发出查询内容qj的概率,即支持度;i=1,2,...,n;n是查询历史集中位置总数;j=1,2,...,m;m是查询历史集中查询内容POI种类总数;number(A)是A在查询历史集中出现的次数。在t时段下的置信度定义为
对于评估标准,本文采用的是提升度,则在t时段的提升度定义为
本文设定最小支持度minsup=3/number(All(t,loci,qj))、最小置信度mincon=3/number(All(t,loci))和最小提升度minlift=1.2,那么位置隐私和查询隐私的时间相关性定义为
其中,C2(t,loci,qj) = 1表明在t时段位置loci和查询内容qj关联较强;C2(t,loci,qj) = 0表明在t时段位置loci和查询内容qj关联较弱; sup是支持度; con是置信度; lift是提升度。
3.1.3 时空属性相关性
现有方案没有考虑到在长期查询中位置和查询内容更新时相互的影响,即在多个时刻中,当前时刻的真实位置的语义有很大概率属于以前时刻的真实查询内容,具有很强的时间伴随性。如图3所示,用户首先t1时刻在位置loc1查询附近的医院,然后在去医院途中,t2时刻在位置loc2查询附近的加油站,t3时刻加完油后继续前往医院,最后在医院看完病后,t4时刻在位置loc3请求服务。那么在t1-t4这个过程中,对于当前时刻t4,从查询记录来看,存在3种情况:位置loc3若是在医院的范围内,能和t1时刻的查询内容(附近的医院)联系起来;位置loc3若是在医院的附近,能和t1时刻的查询内容(附近的医院)联系起来;位置loc3若不在医院和加油站附近,不能和t1-t2时刻的查询内容联系起来。因此,在进行联合保护时,需要考虑在不同的查询时间下,位置和查询内容之间的联系。
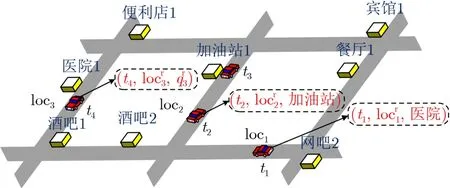
图3 时空属性相关性
由于本文采用虚拟序列的方法,当前时刻的真实位置可能会和以前某个时刻的虚拟查询内容对应上。此时也需要将虚拟查询内容当作真实查询内容进行处理,使相关联时刻中的每个位置和每个查询内容一一对应,以提高匿名查询集的不确定性。则根据欧几里得距离,时空属性相关性定义为
其中,CRi是第i时刻的匿名查询内容集,包含真实查询内容和虚拟查询内容,即CRi={qi,1,qi,2,...,qi,ki};ki是i时刻匿名查询集的大小;POICRi是当前时刻now下离当前位置locnow最近的POI,其语义属于CRi中某个查询内容;i=1,2,...,now-1;dsafe是安全距离;C3(locnow,CRi)=2表明locnow的语义属于CRi中某个查询内容,具有时空属性相关性;C3(locnow,CRi)=1表明用户此时在POICRi附近的locnow请求服务,具有时空属性相关性;C3(locnow,CRi)=0表明不具有时空属性相关性;dis(locnow,POICRi) 是locnow和POICRi之间的距离;max(,)是求一段时间内时空属性相关性的最大值;m是使C3,i(locnow,CRi)最大的时刻索引,如果m有多个,则取离当前时刻最近的m。
3.1.4 相关性判断模型
根据3.1.1节、3.1.2节和3.1.3节,可知真实查询中的真实位置和查询位置之间具有相关性。所以在构建虚拟序列时,需要保证虚拟查询中的虚假位置和虚拟查询内容跟真实查询中的真实位置和真实查询内容保持相同的相关性,以提高匿名查询集的匿名程度。则相关性判断模型为
其中,C1(,)是语义相关性,C2(,,)是时间相关性,C3(,)是时空属性相关性。
3.2 基于虚拟序列的位置隐私和查询隐私联合保护机制
3.2.1 联合保护的相关参数
(1)匿名程度
由2.2节可知,攻击者能获取车载用户的查询历史,并通过统计查询历史中位置访问概率、查询内容访问概率,来识别虚拟查询。因此,在基于虚拟的方法中,虚拟查询和真实查询的概率偏差影响着匿名程度,攻击者更愿意相信用户在查询概率高的地方发出查询[16]。而信息熵被广泛用于衡量匿名查询集的匿名程度,即当匿名查询集获得更高的信息熵时,真实查询更难被揭示,匿名程度更大。则信息熵定义为
其中,c=1,2;当c=1时,H1是位置熵,Pi,1是位置loci的访问概率;当c=2时,H2是查询内容熵,Pi,2是查询内容qi的访问概率;i=1,2,...,k;k为匿名查询集的大小。
(2)分散程度
(a)位置距离和。在选择虚假位置时,为了最大化匿名区域,需要将各个位置尽量分散得远,使真实位置和虚假位置扩展到更大的隐蔽区域[17]。因此,不仅需要考虑虚假位置和真实位置的距离,还要考虑虚假位置之间的距离。本文采用位置距离和来描述匿名查询集中位置的分散程度,定义为
其中,loci,locj是匿名查询集中的位置。
(b)查询内容语义距离和。基于POI分类目录[18]和分叉树,如图4所示,将车载用户的历史查询内容映射到兴趣模型中。在兴趣模型中,用C表示每个主题,用A表示每个属性。其中,属性A7到属性A8最短的路径距离为A7→A2→C2→A3→A8,等于4[19]。因此,语义距离定义为

图4 兴趣模型
与位置距离和类似,也需要将查询内容的语义分散得远,则查询内容语义距离和定义为
其中,qi,qj为匿名查询集中的查询内容。
(3)真实查询的相关性值和虚拟查询的相关性值
在构建虚拟序列中的虚拟查询时,应选择与真实位置和真实查询内容具有相同相关性的虚假位置和虚拟查询内容,以提高匿名查询集的不确定性,防止攻击者推断出真实查询。则根据式(10)可得
3.2.2 联合保护优化模型
为了最大化车载用户的利益,需要确定一个最优匿名查询集来有效地为车载用户提供隐私保护。因此,基于虚拟序列,将联合保护转化为虚拟序列的选择问题,结合联合保护的相关参数,建立一个多目标优化模型。此外,在多目标优化中,目标函数越多,优化模型越难满足所有目标。故而考虑到各个目标函数的关联性和重要程度,本文将虚拟序列的选择分为两步:一是在查询历史中寻找2k个位置熵最大和查询内容熵最大且满足相关性和其他约束条件的匿名查询集(可行解),其中每个匿名查询集由1个真实查询和k-1个虚拟查询组成;二是在2k个匿名查询集中,寻找1个位置距离和最大以及查询内容语义距离和最大的匿名查询集(最终解)。因此,虚拟序列选择的第1步针对信息熵的优化模型具体为
目的是得到2k个位置熵最大和查询内容熵最大的查询匿名集seta;locs是用户设定的敏感位置集;locim是不可能发送LBS请求的位置集;qs是用户设定的敏感查询内容集;该公式最后3行表明虚拟查询必须与真实查询保持相同的相关性。然后第2步针对位置距离和以及查询内容语义距离和的优化模型为
目的是在第1步的seta中,选择1个位置距离和最大以及查询内容语义距离和最大的匿名查询集setb。此外,NSGA-II[20]算法引入快速非支配排序、拥挤度、拥挤度比较算子和精英策略,能更快地得到使各目标函数尽量达到最优的可行解集。故而对于每次选择,本文使用NSGA-II算法求解得到最优的匿名查询集。
4 安全分析
4.1 抵御推断攻击
推断攻击[3]指攻击者或LBS服务器通过相关背景知识(查询历史中的位置访问频率、查询内容访问频率和匿名查询集等),可以在匿名查询集中进行推断,识别用户的真实查询。
定理1提出的联合保护机制能抵御推断攻击。
证明假设用户t1时刻在位置loc1请求查询内容q1,用户对loc1的访问频率为P1,1,攻击者或LBS服务器在获取经过本文方案保护后的匿名查询集{ (t1,loc1,q1),(t1,loc2,q2),...,(t1,lock,qk)}后,试图根据查询概率对其分析。对于本文方案生成的k-1个虚假位置,其访问概率分别记作P2,1,P3,1,...,Pk,1。但是,本文方案总是在查询历史中选择与位置loc1访问概率相等的k-1 个虚假位置,即P2,1=P3,1=...=Pk,1=P1,1,以获取最大位置熵。因此,攻击者即使有用户在某位置访问频率的背景知识,也无法推断和识别出真实位置。此外,对于匿名查询集中查询内容集抵御推断攻击的证明,与证明匿名查询集中位置集抵御推断攻击的思路类似。 证毕
4.2 抵御联合攻击
联合攻击指攻击者或LBS服务器利用相关背景知识(位置隐私和查询隐私的相关性)来排除虚拟查询。其中语义范围攻击[10]指攻击者或LBS服务器掌握某位置可支持检索POI的种类范围这一关系,从匿名查询集中排除部分虚拟查询;时间关联攻击[3]指攻击者或LBS服务器掌握在特定时段,某位置和某查询内容的时间关联程度这一关系,从匿名查询集中排除部分虚拟查询;长期观察攻击[11]指攻击者或LBS服务器会收集一段时间内的匿名查询集,执行推理攻击来排除部分虚拟查询。
定理2提出的联合保护机制能抵御语义范围攻击、时间关联攻击和长期观察攻击。
证明假设攻击者或LBS服务器在收集一段时间(t1到ti时刻)经过本文方案保护后的多个匿名查询集{ set1:{ (t1,loc1,1,q1,1) , (t1,loc1,2,q1,2),...,(t1,loc1,k1,q1,k1)},...,seti:{(ti,loci,1,qi,1) ,(ti,loci,2,qi,2),...,(ti,loci,ki,qi,ki)}}后,试图对其进行位置和查询内容的地理对应关系分析,或对其进行位置和查询内容的时间关联分析,或寻找在不同时刻下位置和查询内容的联系,从匿名查询集中排除虚拟查询。但是,根据式(15),本文方案总是选择与真实查询具有相同语义相关性、相同时间相关性和相同时空属性相关性的位置和查询内容作为虚拟查询,即在每个虚拟查询中,位置和查询内容的地理对应关系、时间关联程度和时空对应关系与真实查询一致,服从均匀分布。因此,本文方案能抵御针对位置隐私和查询隐私的联合攻击。 证毕
5 实验分析
5.1 实验场景
5.1.1 实验数据
实验仿真数据集源于TLC[15](Taxi and Limousine Commission)的纽约黄色出租车数据集,其中记录了2009年到2022年纽约黄色出租车的轨迹数据。该数据集包括上车和下车日期/时间、上车和下车位置(经纬度)、行程距离等信息。本文从2016年黄色出租车数据集中选取前500 000次记录来模拟不同用户的查询请求,并将上车时间作为查询时间,上车位置作为请求位置,以及通过百度地图API[18]将下车位置转换为POI,作为查询内容。
本文采用Python语言在Windows 10操作系统中上实现提出的位置隐私和查询隐私联合保护机制,运行硬件环境为3.1 GHz Intel Core i5 4核处理器,运行内存为16 GB。实验具体参数见表1。

表1 仿真参数
5.1.2 实验评价指标
本文主要从相关性和隐私保护效果两个方面来综合评价方案的性能。在实验中,本文采用泄露概率、信息熵以及位置距离和来评估位置集的匿名程度和分散程度;采用泄露概率、信息熵以及语义距离和来评估查询内容集的匿名程度和分散程度。信息熵、位置距离和以及语义距离和的定义如前文所述。而泄露概率,由文献[16]可知,用于衡量信息的泄露风险,泄露概率越小,隐私保护效果越好,其定义为
其中,Ai是当前匿名查询集中的位置或者查询内容;U是当前匿名查询集;C是用户的查询历史集。
5.2 实验结果
为了验证本文联合保护机制的有效性,将本文方案与现有的分开保护机制(enhanced-DLS[16]+Dummy-Q[8]和RDG[7]+DQD[21])以及现有联合保护机制(CDQS[10])进行比较。enhanced-DLS+Dummy-Q、RDG+DQD和CDQS都是基于虚拟的方案。
5.2.1 相关性分析
在本小节中,设定k值范围为[3,21],步长为3,并从查询历史中选出具有3种相关性的真实查询。在相同的k值下,比较了匿名查询集中具有3种相关性的查询个数与k值的关系。
从图5中可以分析得出,在相同的k值下,本文方案的匿名查询集中具有3种相关性的个数大于其余3种方案。这是由于本文方案在构建匿名查询集时,考虑到位置隐私和查询隐私的相关性,使得各个虚拟查询和真实查询保持相同的相关性,能够抵御语义范围攻击、时间关联攻击和长期观察攻击。此外,随着k值的增加,且在本文方案中具有3个相关性的查询个数始终是k,所以本文方案呈线性增加。而CDQS未考虑到AOR半径和查询时间对位置隐私和查询隐私的影响,不能有效抵御语义范围攻击以及无法抵御时间关联攻击和长期观察攻击,导致具有相关性的个数小于k;enhanced-DLS+Dummy-Q和RDG+DQD没有考虑到位置隐私和查询隐私具有相关性,无法抵御上述3种攻击,导致具有相关性的查询个数更少。

图5 k值对具有3种相关性的查询个数的影响
5.2.2 隐私保护效果分析
本节基于图5进一步实验,比较了k值与位置泄露概率(查询内容泄露概率)以及k值与位置熵(查询内容熵)之间的关系。此外,理想情况(Optimal)下能达到最优的泄露概率(1/k)和最大的信息熵值。
从图6(a)-图6(d)可以分析得出:一是在相同k值下,本文方案的隐私保护效果(信息熵和泄露概率)优于其余3种方案。如k值等于21时,本文方案的位置泄露概率(查询内容泄露概率)比enhanced-DLS(Dummy-Q)低18.8%(20.2%),比RDG(DQD)低14.6%(13.8%),比CDQS低8.9%(3.2%),并且位置熵(查询内容熵)比e n h a n c e d-D L S(Dummy-Q)高10.6%(10.5%),比RDG(DQD)高7.9%(8.2%),比CDQS高3.9%(4.1%)。其原因在于enhanced-DLS+Dummy-Q和RDG+DQD忽视了位置隐私和查询隐私的相关性,并且CDQS忽略了AOR半径和查询时间对位置隐私和查询隐私的影响,导致这3种方案的匿名查询集中含有kd个不满足相关性的虚拟查询,使得能保护LBS隐私的虚拟查询个数变成k-kd-1。而本文方案综合考虑到位置隐私和查询隐私的相关性,导致攻击者无法根据相关性去排除部分虚拟查询,使得能保护LBS隐私的虚拟查询个数为k-1。二是k 值越大,其余3种方案的信息熵和泄露概率跟本文方案的差距慢慢减小,但我们方案仍优于其他方案。这是由于 k 值越大,导致每个方案符合3种相关性的查询个数增加,则根据式(11),信息熵的值也会增加,但增长趋势会越来越缓慢;根据式(18),泄露概率的值会减小,但降低趋势会越来越缓慢,并且本文方案最终能保护 LBS 隐私的虚拟查询个数等于 k-1,其余3种方案都小于k-1。因此,验证了本文方案能很好地保护用户的LBS隐私。
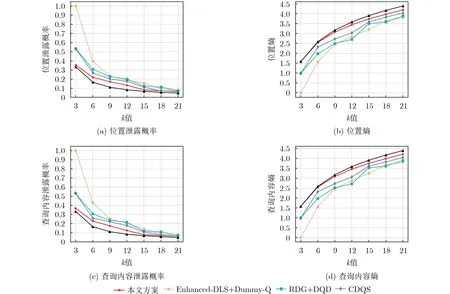
图6 k值对匿名查询集匿名程度的影响
此外,在不同k值下,本文还比较了和其余3种方案的分散程度。由图7(a)、图7(b)可以分析得出,随着k值的增加,本文的位置距离和(查询内容语义距离和)大于其余3种方案,并且差距逐渐增大。这主要是由3个方面造成的,一是由于位置隐私和查询隐私的相关性,其余3种方案真正能保护LBS隐私的虚拟查询个数比本文方案的虚拟查询个数少;二是有的方案(RDG和CDQS)没有考虑到虚假位置之间的距离。同时,3种方案没有考虑到虚拟查询内容之间的语义距离;三是,随着k值增大,由式(12)和式(14)可知,对每个位置(查询内容)的计算次数会增多,使得位置距离和(查询内容语义距离和)急剧增加。因此,验证了本文方案能很好地将匿名查询集中的各个位置(查询内容)分散到更大的匿名区域中。

图7 k值对匿名查询集分散程度的影响
6 结束语
为了联合保护位置隐私和查询隐私,本文提出了一种基于虚拟序列的位置隐私和查询隐私联合保护机制。考虑到位置隐私和查询隐私具有相关性,本文首先采用欧几里得距离和关联规则算法,对位置隐私和查询隐私的相关性进行建模,得到语义相关性、时间相关性以及时空属性相关性,并整合得到相关性判断模型。然后将联合保护转化为虚拟序列的选择问题,考虑匿名程度、分散程度以及位置隐私和查询隐私的相关性等因素,建立联合保护优化模型,求解得到匿名程度高且匿名区域大的匿名查询集,以联合保护位置隐私和查询隐私。实验结果表明,与其他现有的LBS隐私保护方案相比,本文方案能够更好地保护用户的LBS隐私。未来,将从轨迹隐私入手,去思考位置隐私、查询隐私和轨迹隐私之间的相关性,去设计一种更加完善的LBS隐私保护机制,以提高车载用户的服务体验。
猜你喜欢
环球人物(2022年4期)2022-02-22
新世纪智能(数学备考)(2021年9期)2021-11-24
自动化学报(2021年8期)2021-09-28
小资CHIC!ELEGANCE(2021年32期)2021-09-18
当代陕西(2019年15期)2019-09-02
爱你(2018年16期)2018-06-21
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
指挥与控制学报(2015年4期)2015-11-01
爆笑show(2015年4期)2015-06-24
