
基于Lattice LSTM 的中医药古文献命名实体识别与应用研究
2024-01-29 08:43曾江峰庞雨静高鹏钰冯昌扬
情报工程 2023年5期
曾江峰 庞雨静 高鹏钰 冯昌扬,
1. 华中师范大学信息管理学院 湖北 武汉 430079;
2. 北京理工大学管理与经济学院 北京 100081;
3. 富媒体数字出版内容组织与知识服务重点实验室 北京 100038
引言
中医学凝集着古老深奥的哲学思想和华夏千年来的养生之道,在我国漫长的历史长河中具有不可替代的地位,对世界人类健康作出了突出贡献,其传承和创新近年来受到党和政府的极大关注。习总书记曾在讲话中多次强调:要最大程度上利用和发挥中医药的独特优势,建设健康中国;《“十四五”中医药发展规划》指出,开展中医药振兴的重大工程,推进中医药与现代科学结合。中医药古文献是古中医思维成果的载体,承载了中医基础理论和临床核心知识,极具医学研究价值。近年来,人工智能、物联网等现代技术为中医药产业注入了新鲜活力,利用现代化手法发掘中医古文献资源,能够促进中医学的传承与创新。
中医术语识别是中医文本挖掘的重要方向,而基于自然语言处理的命名实体识别技术是信息化背景下术语识别的主流方法。命名实体识别是知识推荐、智能问答、机器翻译等场景的核心环节,在金融、医疗、教育等多个行业受到广泛关注,是计算机和人工智能领域的热点话题,术语的识别精度极大影响着后继任务的完成质量。然而中医数据量大而繁杂,特别是中医药古文献多为非结构化的文言形式,常存在一词多义及实体边界模糊的问题,相比现代文本识别难度更大,常规模型效果并不理想。探索适用于中医古文献的命名实体识别方法,提升中医术语的识别准确性,十分必要。
本文提出一种中医药古文献命名实体识别的Lattice LSTM 模型,将字符信息和词汇信息共同输入,实现信息的充分利用且避免了分词错误,大大提升了中医术语识别的准确性,补充完善了自然语言处理技术在中医古籍文本挖掘中的相关理论;实现了现代化信息技术与传统中医学的有效结合,促进了中医学的传承与创新。另外,本文构建的中医药知识图谱,将非结构化的古籍文本以结构化方式存储,便于大规模数据的检索、更新与共享;辅助现代中医学者与临床医师进行医学诊断与临床决策,为广大患者提供更加快捷、优质的中医诊疗服务。
1 国内外研究现状
1.1 国外医学领域命名实体识别现状
命名实体识别[1](Named Entity Recognition, NER)指挑选出给定句子中含义特殊的字或词语,如姓名、地区、职业单位等,是自然语言处理的基础性任务。近年来,国外医学领域的NER 研究主要聚焦于深度学习。Gligic 等[2]通过迁移学习引导神经网络,在大量未注释的电子健康记录数据集上进行预训练词嵌入,证实了迁移学习和无监督学习可以提升稀疏数据下神经网络的性能;Mulyar 等[3]针对临床记录特定任务间信息不共享导致单个方案性能下降的问题,开发了基于深度学习的Multitask-Clinical BERT 系统,同时执行实体抽取、模式识别等八项任务,显著提升了计算速度,证实了多任务学习在临床信息提取上的可行性;Kang 等[4]结合统一医学语言系统(UMLS)知识,提出医学术语识别的数据增强方法UMLS-EDA,改善了句子分类模型的性能,识别效果优于BERT 预训练分类器;Kormilitzin 等[5]开发了开源的NER 模型Med7,同时引入改进方法sense2vec,利用MIMIC-III 数据集证实该模型可用于NER 任务;Weber 等[6]将HUNER标记器集成到Flair NLP 框架中,提出HunFlair医学实体识别模型,在不同数据集的跨语料库评估中性能优于BioBERT、SciSpacy 等现有工具;Ma 等[7]提出集成两种弱监督学习方法的投票机制,在CCKS2017 数据集上的实验效果优于监督学习,缓解了医学标注过少和标注困难的问题。
1.2 我国中医药领域命名实体识别现状
近年来,我国中医药领域的命名实体识别,按照研究对象可分为电子病历、在线医疗社区问答文本、临床医案、中医古籍等。电子病历方面,陈美杉等[8]针对数据标注稀缺的情况,提出KNN-BERT-BiLSTM-CRF,证实知识迁移可以改善小数据集下智能模型的识别效果。临床医案方面,肖瑞等[9]使用BiLSTM-CRF 识别部分老中医医案中的术语。中医古籍方面,高甦等[10]以《黄帝内经》为实验材料,提出结合字向量的深度学习模型,解决了古籍实体识别困难的问题;屈倩倩[11]基于BERT-BiLSTMCRF 识别《伤寒论》实体,为后续任务提供了高质量的数据来源;卢克治[12]将Word2vec、ELMo、BERT 词嵌入模型引入BiLSTM-CRF,对662 本中医古籍进行实体抽取,发现BERT参与的模型获得了最佳识别效果。
综上可知,中医药领域的命名实体识别以电子病历和临床医案为主要研究对象,对于中医药古籍的研究相对较少,且主流方法为BiLSTM-CRF。Zhang 等[13]针对中文NER 任务首次提出混合字符和词汇信息的Lattice LSTM 模型,证实其在现代中文数据集上的卓越性能;崔丹丹等[14]在《四库全书》的古汉语研究中首次运用这一模型,F1 值比BiLSTM-CRF 提升了3.95%,证实其可用于古籍研究;张笑天[15]将Lattice LSTM 用于四川省肿瘤医院病程记录的实体识别,证实其在医学领域NER 任务上表现良好,但这一模型目前还未应用于中医领域古文献的研究。基于此,本文提出一种面向中医药古文献术语识别的Lattice LSTM 模型,并对其进行实证研究。
2 Lattice LSTM 模型
Lattice LSTM 在基于字符的LSTM 模型基础上加入了词汇的输入和额外的门控单元以调控信息流动,其结构见图1。对于输入的句子s,既可看作是由单个字组成的字符序列,即s=c1,c2,...,cm,其中cj表示s的第j个字;也可看作是以词为单位的词序列,即s=w1,w2,...,wn,其中wi表示s的第i个词。以本文的研究材料《伤寒论》文本数据为例,设t(i,k) 表示句子中第i个词的第k个字的位置,如“太阳病发热汗出”一句中的“发”字,其位置可用t(3,1)=4 表示。
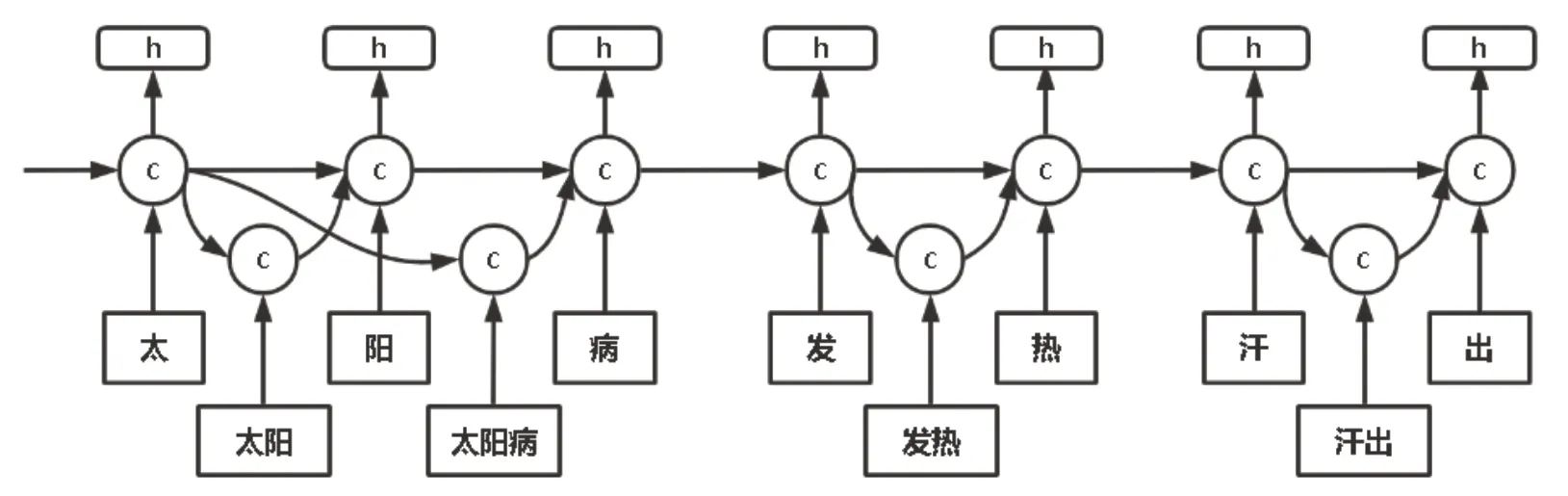
图1 Lattice LSTM 结构图
Lattice LSTM 包含两种结构:基于字符的结构和基于词的结构。在基于字符的结构中,每个字cj通过字符嵌入矩阵ec表示为输入字向量xjc=ec(cj),然后依次通过输入门ijc、遗忘门fjc和输出门ojc,得到单元向量cjc和隐藏向量hjc,前者控制句子的历史信息,后者作为CRF 的输入,基于字符结构的计算如式(1)、式(2)和式(3)所示:
其中wcT和bc是模型参数。
Lattice LSTM 的优势在于将潜在词汇信息融合进上述基于字符的结构,从而使得模型在获得字信息的同时,也可以有效地利用词的先验信息。基于词的结构中,每个词通过词嵌入矩阵ew得到输入词向量其中表示索引从b到e的字符组成的词汇。因标记仅在字符级别执行,所以基于词的结构没有输出门,其余与基于字符的结构相似,计算如式(4)、式(5)所示:
其中wwT和bw是模型参数。
得到所有输出的隐藏向量h1,h2,...,hl,其中l是句子包含的字数,通过CRF 层得到标记序列y=l1,l2, ...,lτ的概率,使用Viterbi 算法计算得到最大概率值,其对应的标记即为预测标记。标记序列概率的表示方法如式(11)所示:
3 中医药古文献命名实体识别实验过程及结果分析
3.1 研究流程
基于Lattice LSTM 的中医药古文献命名实体识别研究可分为三个阶段:数据预处理阶段,对《伤寒论》文本数据进行规范化和实体标记,构建中医药主题词典,结合词典进行分词及去停用词处理;字词向量训练阶段,使用python的gensim 包对文本进行Word2vec 训练;命名实体识别阶段,通过实验评估模型性能。
3.2 实验环境及超参数设置
本实验部署于Windows 系统,选取深度学习Pytorch 框架开发,实验环境及模型的最优超参数设置见表1、表2。
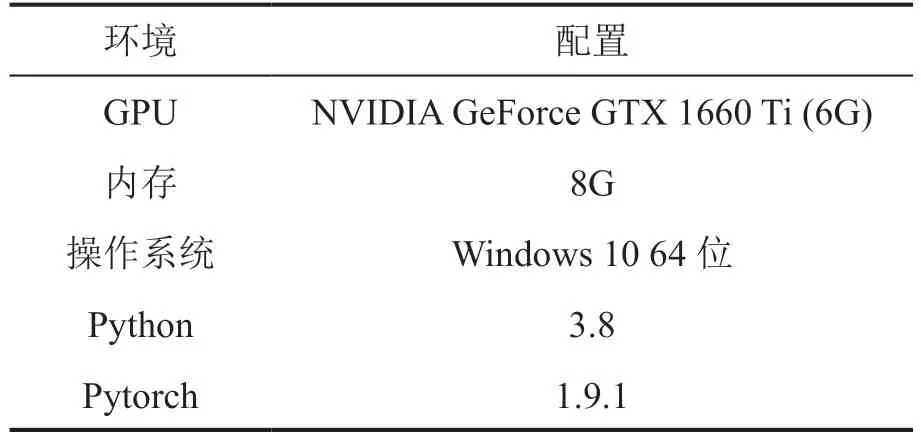
表1 实验环境

表2 模型超参数
3.3 数据预处理
本研究的数据集采用明代赵开美翻刻的宋本《伤寒论》[11],原作者为东汉医圣张仲景,全书原12 卷,现存10 卷22 篇,共398 条,条文共包含464 句。
用python 读取《伤寒论》全文,去除多余符号后,根据BIOES 规则,使用基于Linux 系统的brat[16]软件标记文本中的五类实体:疾病(disease)、 证候(syndrome)、 方剂(prescription)、症状(symptom)、药材(medicine),其中单字符实体标注为S,多字符实体首字标记为B,中部标记为I,末尾标记为E,非实体标记为O。如条文第224 条可标注为:“阳/B-dis明/I-dis病/E-dis,/O汗/B-sym出/I-sym多/E-sym而/O渴/S-sym者/O,/O不/O可/O与/O猪/B-pre苓/I-pre 汤/E-pre。/O”,标注示例见图2。

图2 数据标注示例
以句为单位,将处理后的《伤寒论》数据按照60%、20%、20%的占比随机分配得到实验所用的训练集、验证集和测试集,具体情况统计见表3。

表3 实体类别统计
为进一步提高术语识别的准确性,本研究基于《中医病证分类与代码》(GB/T 15657—1995)、《中药方剂编码规则及编码》(GB/T 31773—2015)[17]等国家标准文件,同时以中草药专业知识服务系统(http://zcy.ckcest.cn/tcm/)提供的数据资源为补充,构建中医药领域实体词典,共包含5960 个实体,涉及疾病、方剂、证候、药材、症状等类别。利用词典对中医药古籍文本进行分词及去停用词处理。
3.4 实验结果分析
将Lattice LSTM 与NER 任务的多个经典模型进行对比,实验结果见表4。可观察到如下特点:首先,深度学习的各模型整体表现出更好的性能;其次,BiLSTM 加入CRF 层后各评价指标有了明显提升,这是因为CRF 可以自动学习标记间的约束,进而修正模型的输出,保证了预测结果的合理性。再者,根据F1 值对各模型性能进行排序:Lattice LSTM>BiLSTM-CRF>CRF>BiLSTM>HMM,可知Lattice LSTM 性能最优,比BiLSTM-CRF 总体提升了1.68%,这是因为该模型在基于字的模型基础上实现了潜在词汇信息的充分利用,解决了语义缺失的问题,避免了分词错误,极大提升了识别效果。

表4 模型效果对比
探究模型在不同类别实体识别上的表现,各类实体数量及F1 值见图3。可观察到如下特点:首先,深度学习模型对证候的识别效果比浅层机器学习模型差,主要是因为可供模型学习的实体数过少,导致其优势无法体现;其次,各模型对方剂和药材的识别效果较好,主要是因为二者的数据特征较强,在文本中方剂均以“方”字结尾,而药材的名称全文统一、易于识别。疾病和症状的识别情况却不尽相同:疾病实体虽然数量少,但因其名称较为统一,所以识别效果很好;而症状实体虽然数量最多,但因其组成复杂、形式多样,所以识别效果较差。另外,Lattice LSTM 模型在除证候外的其他实体上识别效果均最佳,可用于中医药古文献术语识别。
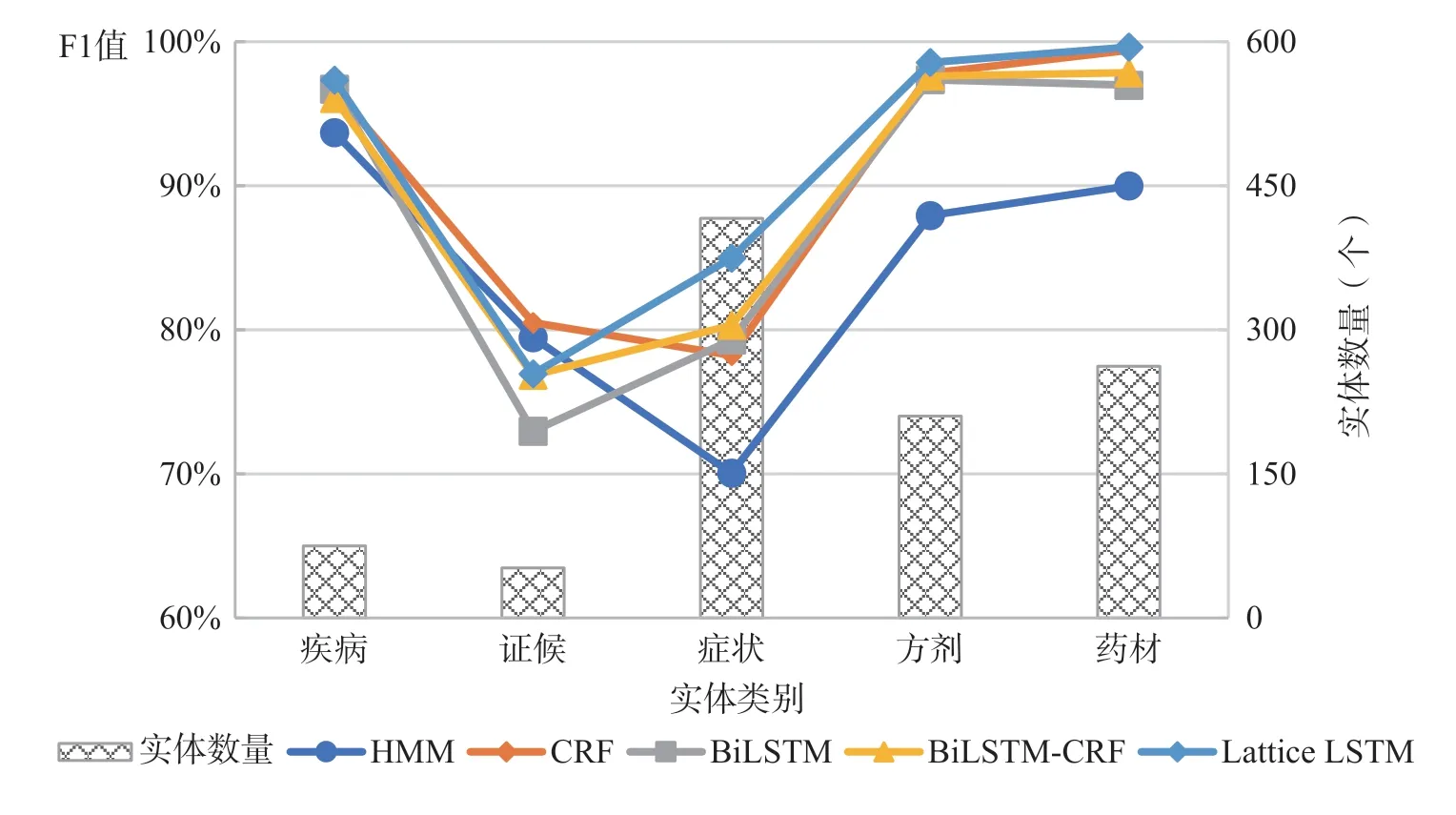
图3 各类实体的数量及F1 值
3.5 参数敏感性分析
字( 词) 向量维度(char/word_emb_dim)、隐含层维度(hidden_dim)和丢弃率(dropout)是Lattice LSTM 模型的重要参数,评估参数变化对模型性能的影响,有利于发掘最佳参数组合,使模型表现出最优效果,结果见图4。
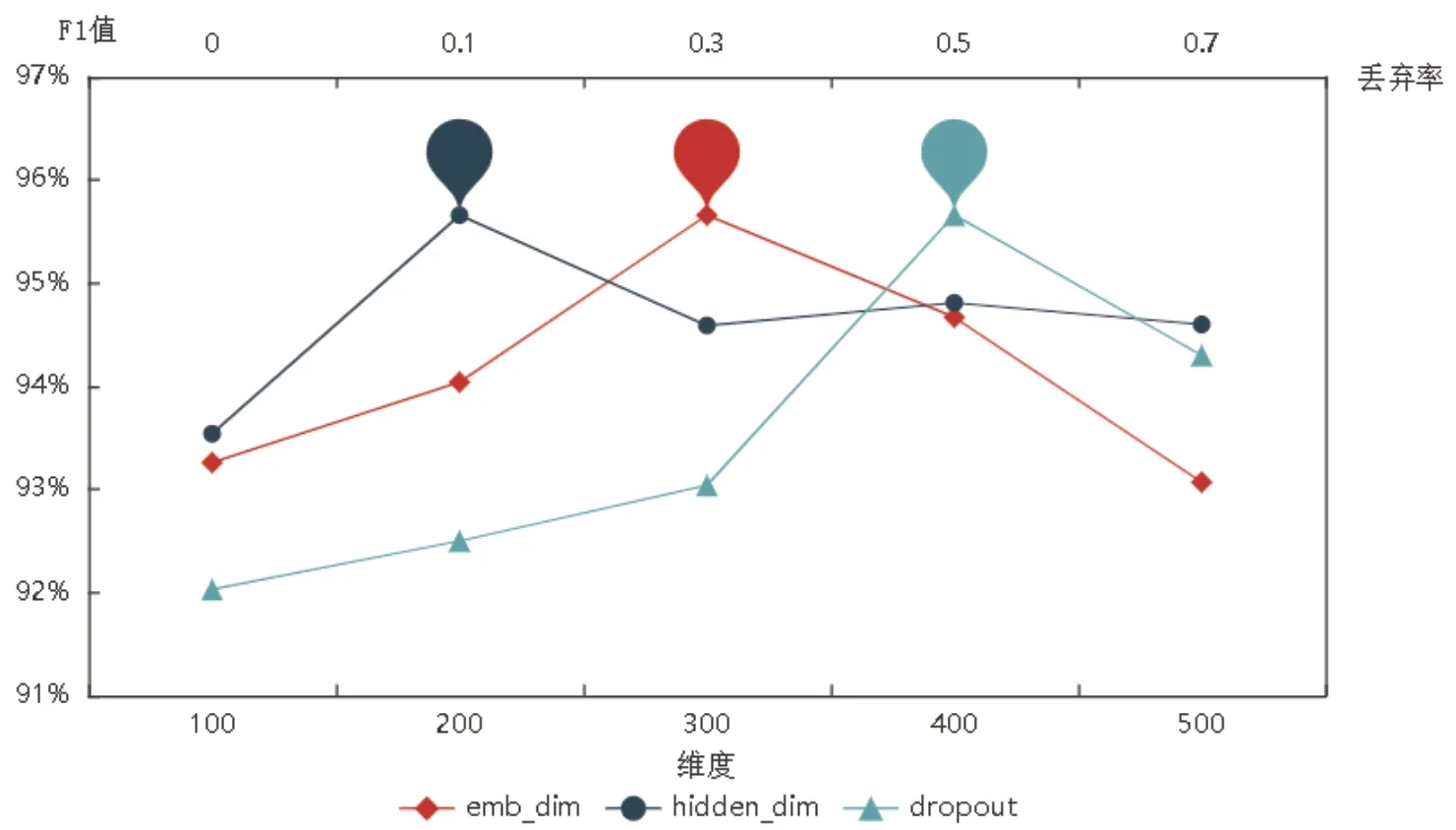
图4 各参数对模型性能的影响
当不改变其他参数值,字(词)向量维度为300 时模型的表现最佳;控制其他参数不变,加入dropout 后模型的性能得到了较大提升,这是因为该技术在训练中将神经网络单元以某概率值暂时丢弃,可以防止模型出现过拟合的情况;当丢弃率值为0.5 时,模型在实验中获得了最佳的效果,此后随着丢弃率值的增大,模型性能呈下降趋势。控制其他参数不变,改变hidden_dim 后模型的性能受到较大影响;当hidden_dim 值为200 时,模型性能最优,此后随着hidden_dim 值的增大,模型性能总体呈下降趋势。综上可知,本文的Lattice LSTM 模型应选用char/word_emb_dim 值为300,hidden_dim 值为200,dropout 值为0.5 的参数组合。
4 中医药领域知识图谱及案例分析
4.1 模式构建
为检验本文提出模型的现实应用效果,本文在实验抽取出的实体基础上,构建了中医药知识图谱。知识图谱可以将零散、非结构化的知识以结构化形式存储,实现了知识的有效连接,提高了知识的管理和利用效率。构建知识图谱的核心环节是命名实体识别和实体关系抽取[18],首先是模式构建[19]。本文的中医药知识图谱模式见图5。

图5 中医药知识图谱模式图
4.2 实体关系抽取
实体关系抽取即提取不同实体间存在的语义联系。本研究涉及疾病(disease)、证候(syndrome)、方剂(prescription)、症状(symptom)、药材(medicine)五类实体,定义实体间存在如下四类关系:疾病_证候(DIS_SYN)、证候_方剂(SYN_PRE)、方剂_症状(PRE_SYM)、方剂_药材(PRE_MED),对《伤寒论》文本进行人工关系抽取。如原文第31 条的“项背强、无汗、恶风,葛根汤主之,葛根、麻黄、桂枝……”一句,“项背强”“无汗”“恶风”与“葛根汤”构成PRE_SYM 关系,“葛根汤”与“葛根”“麻黄”“桂枝”等构成PRE_MED 关系。
4.3 知识图谱构建
本研究使用Neo4j[20]构建中医药知识图谱。在Neo4j 中,知识主要以节点和边的形式存储,节点代表意义特殊的实体,边代表实体间的关系。将《伤寒论》的实体及关系文件通过LOAD CSV 语句导入Neo4j 图数据库,生成300 个节点和825 条边,具体情况统计见表5。
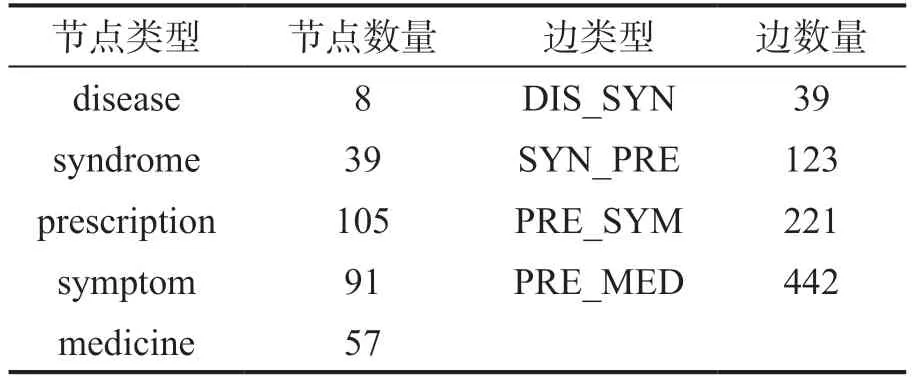
表5 中医药知识图谱的节点及边统计
4.4 案例分析
“大疫出良方”,面对2019 年底席卷全球、来势汹汹的新冠肺炎疫情,中医药通过临床试验筛选出对疾病治疗起关键作用的“三药三方”,其中“清肺排毒汤”作为疫情期间临床首选的治疗药物在多省患者的实际治疗中有效率超过了90%。该汤剂由《伤寒论》的麻杏石甘汤(即麻黄杏仁甘草石膏汤)、小柴胡汤、五苓散等经典名方组成,包含麻黄、杏仁、桂枝等21 味中药,主要功效是宣肺透邪、清热化湿、健脾化饮,能够改善患者出现的发热、咳嗽、乏力、咽痛等症状。
在中医药知识图谱中,检索清肺排毒汤三大方剂的相关信息,结果见图6。节点中橙色代指疾病,蓝色代指证候,绿色代指症状,红色代指方剂,浅褐色代指药材。可以看到,清肺排毒汤在《伤寒论》中涉及4 种疾病、6 种证候、11 种症状和14 味药材,如小柴胡汤包含柴胡、半夏、人参等药材,与少阳病、阴阳易差后劳复病有关,可用于治疗咽干、呕吐、不欲饮食等症状。此类查询展现了各中医实体间的关系,帮助医师迅速找到所需信息,为中医药智能问答及推荐奠定了基础。

图6 清肺排毒汤的相关检索结果
新冠肺炎的常见症状有:发热、呼吸不畅(对应《伤寒论》的“胸满”“胸中窒”)、咳、腹泻(对应《伤寒论》的“下利”)、头痛、头晕(对应《伤寒论》的“头眩”)、恶心(对应《伤寒论》的“呕”),在知识图谱中查询各症状对应的治疗方剂,结果见图7。节点中绿色代指症状,红色代指方剂。可以看到,对于发热患者,可以使用调胃承气汤、大青龙汤、真武汤等治疗;对于发热和头痛兼具者,可以使用麻黄汤、理中丸、桂枝汤等治疗。此类查询为中医药医疗诊断提供了清晰的药方参考,有利于对症下药,辅助医师进行临床决策。
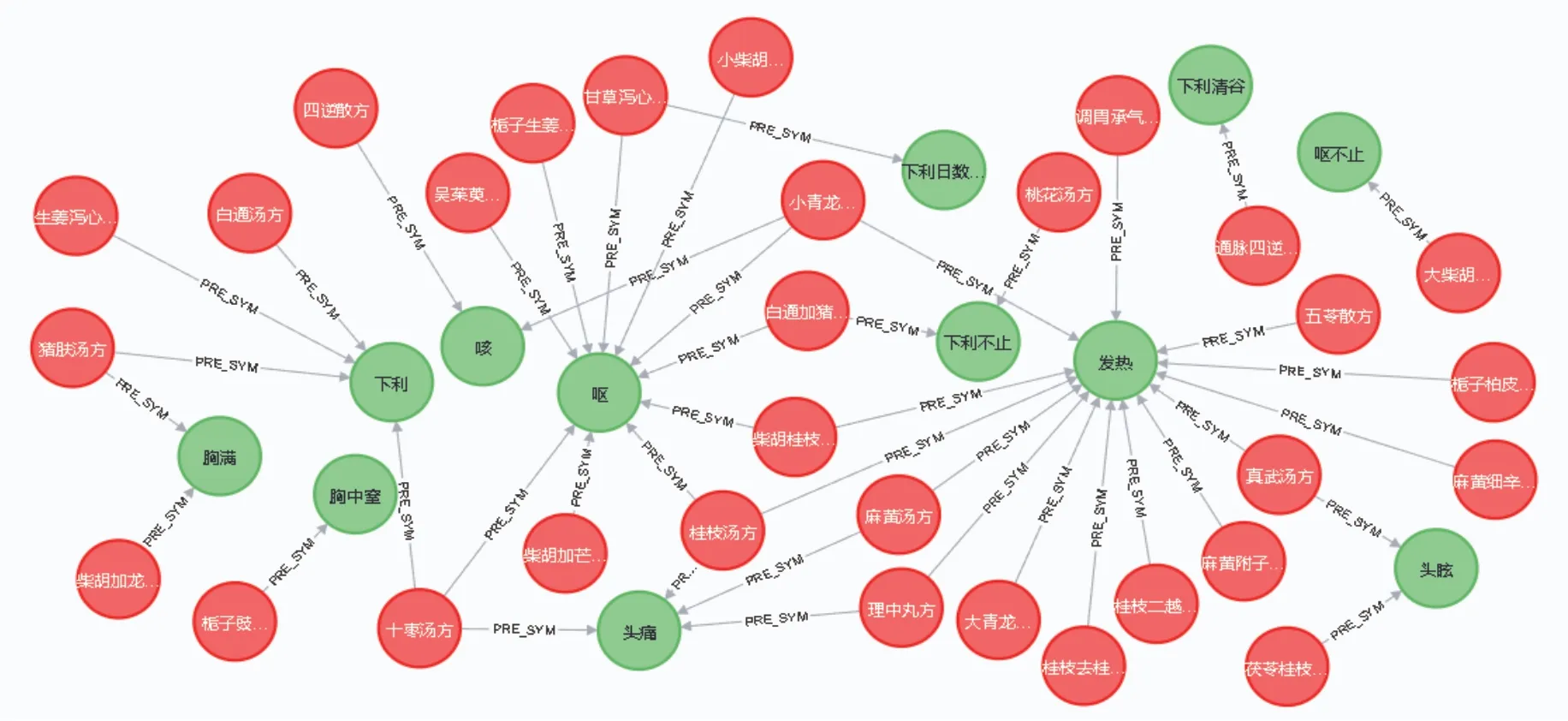
图7 新冠肺炎症状及方剂的检索结果
5 总结与展望
5.1 研究总结
本文创造性将Lattice LSTM 模型应用于中医药古文献的命名实体识别任务中,以《伤寒论》为研究对象,对疾病、证候、方剂、症状和药材五类实体进行识别。研究发现,实体数量及构成的复杂程度均会影响模型的识别效果;实验结果表明:Lattice LSTM 性能最优,F1 值达95.66%,比主流模型BiLSTM-CRF 提升了1.68%,可用于中医药古文献的命名实体识别。此外,本文在提取出的实体基础上,人工抽取了实体间的四类关系,利用Neo4j 搭建了中医药知识图谱;以新冠肺炎的中医诊疗方案为例,使用图谱进行了相关检索,证实了理论模型在实际应用中的效果。
5.2 未来展望
本文仍存在不完善和可改进之处,在今后的研究中将继续优化:
(1)用于中医古籍专业术语识别的语料库较小。本文仅使用《伤寒论》文本进行实证研究,数据量较小,难以充分发挥Lattice LSTM 模型的优势。未来可以进一步扩充中医古文献的语料库,探究模型在大规模数据集上的表现;也可以进一步丰富图谱内容,如添加实体的属性描述(如各方剂中药材的配比),完善实体及关系类别。
(2)换用古汉语分词专用工具包。本文在jieba 分词时使用了自定义的中医药领域主题词典,该工具一般用于现代汉语的分词,在古文分词方法的调研中发现了专注于古汉语分词的NLP 工具包jiayan[21](https://github.com/jiaeyan/Jiayan),未来可将jiayan 与jieba 对比,检验其能否有效改善中医药古籍的分词质量。
(3)实体关系抽取和数据审核不够智能化。本文在实体关系抽取时主要采取人工匹配,没有使用自然语言处理技术,耗费了一定时间和人力,未来可以考虑引入关系抽取模型提高抽取效率;同时在知识图谱的数据审核方面也主要采用人工核对,工作量较大,未来可以通过属性矫正、实体对齐等减少相应成本。
猜你喜欢
基层中医药(2022年4期)2022-07-22
中国民间疗法(2021年13期)2021-08-30
中国民间疗法(2021年1期)2021-04-20
少先队活动(2020年12期)2021-01-14
中国民间疗法(2020年22期)2021-01-07
中成药(2018年6期)2018-07-11
中成药(2017年3期)2017-05-17
长春中医药大学学报(2017年1期)2017-04-16
