基于像素对比学习的图像超分辨率算法
2024-02-03 10:41周登文刘子涵刘玉铠
自动化学报 2024年1期
周登文 刘子涵 刘玉铠
单图像超分辨率(Single image super-resolution,SISR)[1]是计算机视觉中一个基本任务,旨在从低分辨率(Low-resolution,LR)图像,恢复出对应的高分辨率(High-resolution,HR)图像,在诸如遥感成像[2]、视频监控[3]和医学成像[4]中,应用广泛.SISR 是一个病态的逆问题,因为许多HR 图像可退化为相同的LR 图像,需要提供图像的先验知识,约束超分辨率(Super-resolution,SR)图像的解空间.SISR 仍然是计算机视觉中开放性的研究问题,重建的SR 图像往往会出现模糊、纹理细节丢失和失真等问题.
早期的SISR 是基于插值的方法,如双线性插值和双三次(Bicubic)插值.基于插值的方法仍被广泛使用,具有很低的计算复杂度,但不能恢复LR图像中丢失的图像细节.基于实例学习的方法[5-7]旨在通过训练图像,学习LR 图像和HR 图像之间的映射关系,改进了基于插值的方法.但是,基于实例学习的方法往往优化困难,并具有较高的推理复杂度.目前,深度卷积神经网络(Convolutional neural networks,CNN)技术[8-13]直接端到端地学习LR和HR 图像之间的映射关系,显著提高了SISR 性能,并主导了目前SISR 技术的研究.基于CNN 的SISR 方法研究主要是探索新的SR 网络架构,损失函数广泛使用均方误差(Mean squared error,MSE)[12]和平均绝对误差(Mean absolute error,MAE)[8],但这些传统的逐像素损失生成的SR 图像是潜在SR输出图像的平均[14],导致输出的图像被过度平滑.为了解决这个问题,Johnson 等[15]提出感知损失.感知损失不是在图像空间度量逐像素的损失,而是在预训练的VGG (Oxford visual geometry group)网络[16]特征空间度量逐像素损失.感知损失能改进SR 图像的感知质量,但降低了SR 图像保真度.重要的是,感知损失也不能阻止SR 图像的模糊.Wang等[17]提出一个对比自蒸馏(Contrastive self-distillation,CSD)网络,引入一个基于对比学习的损失函数.CSD 损失与感知损失类似,也在预训练VGG网络的特征空间逐像素比较损失.以教师子网络输出的SR 图像作为正样本,学生子网络输出的SR图像作为锚,从同一个批次中采样K个图像(除锚外),通过双三次上采样到与输出SR 图像相同的分辨率作为负样本.CSD 损失使锚更靠近正样本,并远离负样本,进一步改进了学生子网络输出的SR图像的视觉质量.与感知损失相比,CSD 损失除限制了学生子网络输出的上界(正样本)外,也限制了下界(负样本),以减小解空间.但CSD 损失也有与感知损失类似的保真度低问题.另外,CSD 损失使用双三次上采样图像作为负样本,是一个较弱的下界.受CSD 启发,提出一个新的基于对比学习的逐像素损失函数Lcntr.Lcntr作用在图像空间,原HR图像与输出的SR 图像对应的像素分别作为正样本和锚,HR 图像上正样本邻近的像素作为负样本.类似地,Lcntr也让锚更靠近正样本,远离负样本.常用损失及其组合的峰值信噪比(Peak signal to noise ratio,PSNR)[18]、结构相似性(Structural similarity,SSIM)[18]和视觉效果见图1,其中L1为MAE 损失,Lperc为感知损失[15],Ltex为纹理损失[19],LCSD为CSD 损失[17],Ladv为对抗损失[20].原LCSD正样本是教师网络输出的SR 图像,本文替换为HR 图像.计算Ltex的图像块大小为 48×48 像素.可以看出,本文的逐像素损失函数Lcntr可与其他损失组合使用,显著改进SR 图像保真度和视觉质量.另外,本文提出一个新的网络架构,称为渐进残差特征融合网络(Progressive residual feature fusion network,PRFFN).PRFFN 应用扩张卷积[21],扩展极深残差通道注意力网络(Very deep residual channel attention network,RCAN)[11]的基本构件 ——残差通道注意力块(Residual channel attention block,RCAB)[11],不增加参数并融合多尺度特征,称为多尺度残差通道注意力块(Multi-scale residual channel attention block,MRCAB).PRFFN 以MRCAB 为基本构件,并运用空间注意力机制[22],渐进地融合MRCAB 的输出特征.本文的Lcntr损失与PRFFN 网络架构组合,能够获得先进的SR性能,一些代表性方法的PSNR 和参数量见图2.Lcntr是通用的,可与其他SR 网络架构协作使用.
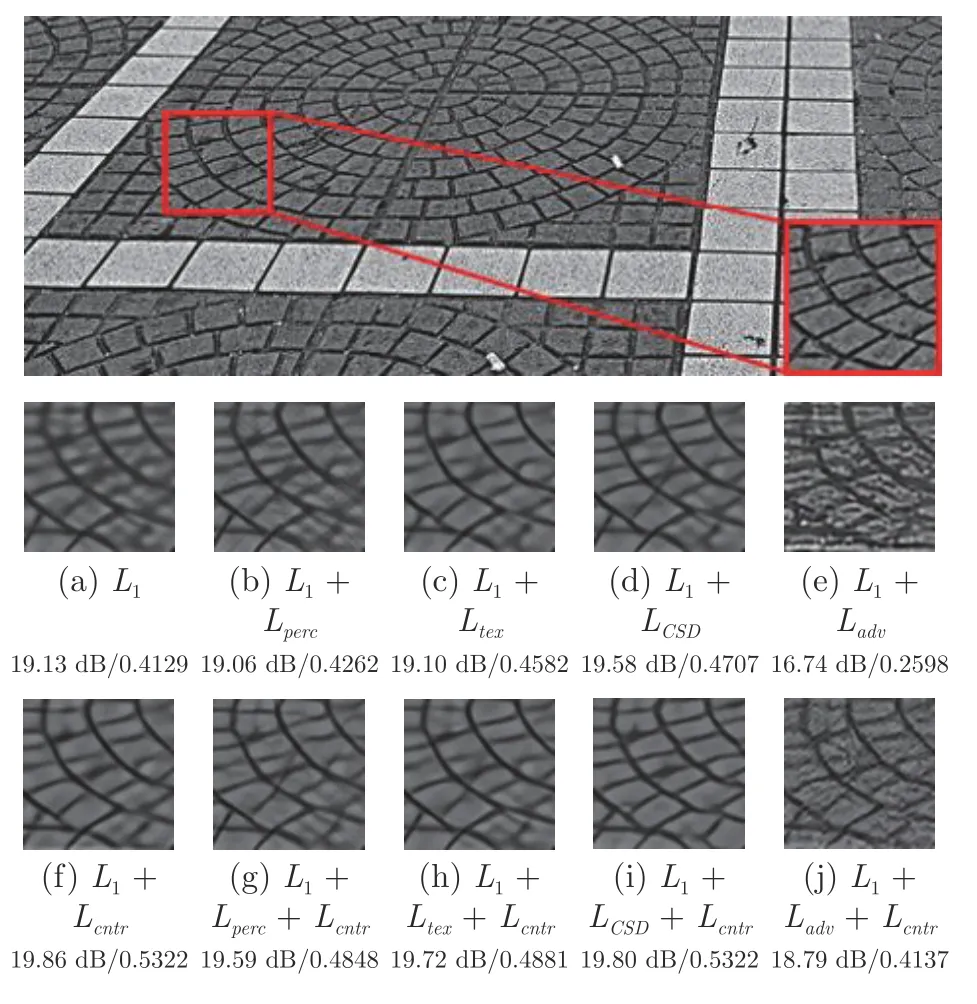
图1 不同损失及其组合的PSNR/SSIM 和视觉效果Fig.1 PSNR/SSIM and visual effects for different losses and their combinations
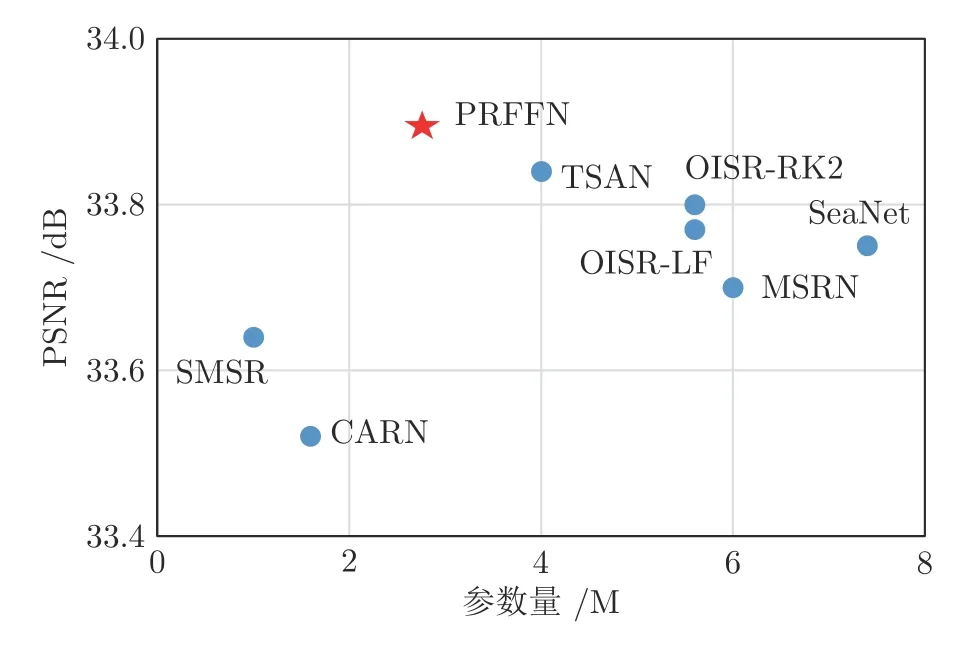
图2 在Set14 数据集上,不同SISR 方法2 倍SR 结果的平均PSNR 值和参数量Fig.2 Average PSNRs and parameter counts for 2 times SR models for each state-of-the-art SISR method on the Set14 dataset
本文的主要贡献有: 1)提出一个通用的基于对比学习的逐像素损失函数Lcntr,能够显著改进SR图像的视觉质量;2) 提出一个新的SR 网络架构PRFFN,主要组件是MRCAB 和空间注意力融合块(Spatial attention fuse block,SAFB),MRCAB可以更好地提取和利用多尺度特征信息,而SAFB可以更好地利用邻近特征的相关性;3) 实验结果表明,PRFFN 组合Lcntr取得了有竞争力的SR 性能.
1 相关工作
1.1 图像超分辨率的网络架构
2015 年,Dong 等[8]提出第1 个基于CNN 的SISR 方法 ——超分辨率卷积神经网络(Super-resolution convolutional neural network,SRCNN)后,深度卷积神经网络技术已主导了当前SR 技术研究.SRCNN 只有3 个卷积层,Kim 等[9]提出极深超分辨率网络(Very deep super-resolution network,VDSR),通过引入残差学习,加深了网络(有20 个卷积层),改进了性能.Lim 等[10]提出增强的深度超分辨率网络(Enhanced deep super-resolution network,EDSR),通过堆积残差块,进一步加深了网络(有65 个卷积层),改进了性能.Zhang 等[11]提出RCAN 方法,在残差块中引入通道注意力(Channel attention,CA)机制,有超过400 个卷积层,显著改进了SISR 方法性能.Tong 等[12]提出超分辨率稠密连接网络,使用了稠密连接.Zhang 等[23]提出残差稠密网络,同时使用残差稠密连接.稠密连接和残差稠密连接比残差连接可以更好地利用深度卷积层的分层特征.同样,注意力机制在SR 网络中也得到了广泛关注,通道注意力机制[11]考虑不同通道特征之间的依赖,显著提高了模型的表示能力和SR 性能.Zhang 等[13]提出一种非局部注意力块,以建模长距离像素之间的依赖,可以很好地捕捉空间注意力,进一步增强特征的表示能力.Niu 等[24]提出整体注意力网络,进一步组合了层注意力、通道和空间注意力,以建模层、通道和空间位置之间的整体依赖.Li等[25]提出多尺度残差网络(Multiscale residual network,MSRN),采用局部多路径学习,同时提取多个尺度特征,改进了特征的表示能力.视觉Transformer 能够建模全局像素之间的依赖,在图像分类、物体检测和分割等高级视觉任务中,取得了巨大的成功.Liang 等[26]将Swin Transformer[27]引入图像恢复,取得了最先进的性能.这些代表性的SISR 方法虽然有好的SR 性能,但模型参数量较大,需要较大的内存和较强的计算能力,限制了它们在资源受限设备上的应用.目前,网络架构设计的趋势是设计更轻量的网络模型,找到网络模型复杂度和性能之间最优的平衡[28].本文模型的基本构件设计受Zhang 等[11]和Li 等[25]启发,相较于RCAN 的基本构件RCAB,通过引入扩张卷积,可以提取多尺度特征[25]且不增加参数量;同时,设计一个空间注意力融合块,可以有效地融合这些多尺度的特征.
1.2 图像超分辨率的损失函数
目前,基于CNN 的SR 技术研究大多聚焦于网络架构设计,但合适的损失函数对SR 模型的性能也至关重要.最广泛使用的损失函数是逐像素的L1损失(即平均绝对误差) 和L2损失(即均方误差).这些逐像素的误差度量返回许多可能解的平均值[14],会导致SR 图像出现模糊、过度平滑和不自然的外观等问题,尤其是在信息丰富的区域.为了改进SR 图像的感知质量,Johnson 等[15]提出感知损失,使用预训练的图像分类网络,在特征空间度量高级感知和语义差异.与L1等像素损失不同,感知损失鼓励输出的SR 图像与目标图像具有相似特征表示,而不是迫使其像素匹配.考虑到SR 图像应与目标图像具有相同的纹理,Sajjadi 等[19]提出一种基于块的纹理损失,图像纹理视为不同特征通道之间的相关性,其定义基于预训练分类网络特征的Gram矩阵.纹理损失迫使SR 图像应与目标图像之间局部纹理相似.Ledig 等[20]提出对抗性损失,鼓励SR图像逼近自然图像流形.这些损失函数改进SR 图像的视觉质量,但是保真度低,仍不能阻止图像模糊.
1.3 对比学习
对比学习[29-30]旨在学习一个嵌入的空间,使得相似的样本彼此靠近,不同的样本彼此远离.对比学习可用于监督的学习环境,也可用于无监督的学习环境,在图像分类和图像聚类等高级视觉任务中,应用非常成功,但很少用于低级视觉任务.高级视觉任务的对比学习技术可能不适用于低级视觉任务,因为前者更需要全局视觉表示,而后者更需要丰富的纹理细节[31].对比学习需要考虑度量相似性的隐空间和正/负样本的选取两个重要因素.在低级视觉任务中,使用的隐空间大都是预训练网络(例如VGG)的特征空间.采用简单方法选取正/负样本,例如以输入的低质量图像作为负样本,以输入的高质量图像作为正样本.Wu 等[32]提出图像去雾方法,使用VGG 特征空间真实图像作为正样本,退化的雾图像作为负样本,估计的图像作为锚.在VGG 特征空间中,让锚靠近正样本,远离负样本.Wang 等[17]提出一个对比自蒸馏SR 网络,同时使用VGG 特征空间,其中教师子网络输出的SR 图像作为正样本,学生子网络输出的SR 图像作为锚,从同一个批次中采样K个图像(除锚外),通过双三次插值上采样到与输出SR 图像相同的分辨率,作为负样本.在盲SR 中,Wang 等[33]使用一个编码器子网络,学习不同退化的抽象表示.假定相同图像中的块退化相同,不同图像中的块退化不同,以分别选择为正/负样本.Wu 等[31]提出一个基于对比学习的SR 框架,以判别器子网络的特征空间作为隐空间.通过对真实图像施加一些轻微的模糊,生成多个难的负样本并简单锐化真实图像,生成多个信息丰富的正样本.Wu 等[31]的隐空间对退化更敏感,其负样本试图促使SR 图像远离平滑的结果,而其正样本试图迫使SR 图像吸收更多的细节信息.本文受到CSD 的启发,CSD 虽能改进视觉结果,但保真度低,正/负样本限定的上/下界距离大,即上/下界较弱.本文直接使用图像空间训练HR 图像和输出的SR 图像对应的像素,分别作为正样本和锚;HR图像上正样本邻近的像素,作为负样本.
2 本文方法
本文的渐进残差特征融合网络架构如图3 中模块1)所示,主要包括浅层特征提取块(Shallow feature extraction block,SFEB)、特征映射块(Feature mapping block,FMB)和上采样块三部分.其中,SFEB 仅包含一个 3×3 的卷积层,提取浅层特征信息;FMB 包含N(实验中,N=10)个渐进特征融合组(Progressive feature fuse group,PFFG);上采样块使用亚像素卷积[34],使用L1损失和本文的像素级对比损失Lcntr.假定输入的LR 图像为ILR,首先,经过SFEB 提取浅层特征:
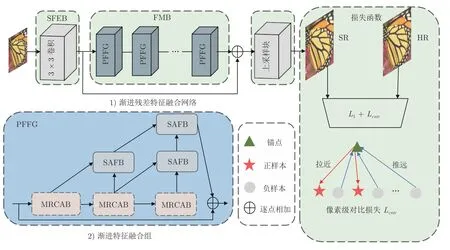
图3 网络架构细节Fig.3 Network architecture details
式中,f SF EB(·) 是浅层特征提取函数,F0是其输出.然后,F0再通过FMB 进行深层特征提取:
式中,f UP(·) 是上采样块函数.最后,输出SR 图像ISR.
2.1 渐进特征融合组
FMB 包含多个PFFG,PFFG 中特征融合设计主要受到Liu 等[35]启发.他们的研究表明,网络中不同深度的残差特征逐渐集中于输入图像的不同方面,对于重建空间细节非常有用.基于CNN 的SISR 模型大都只是将残差学习作为缓解训练难度的策略.SISR 模型堆叠残差块,残差特征传播到下一个块之前,与恒等特征融合,致使后面的残差块只馈入了复杂的融合特征,忽略了充分利用更清洁的残差特征.Liu 等[35]设计的残差模块包含多个残差块,并把各个残差块输出的特征拼接在一起,馈入 1×1 卷积层进行融合.
PFFG 由MRCAB 和SAFB 组成,每个MRCAB 的输出特征是下一个MRCAB 的输入,且与后续所有MRCAB 输出特征,通过SAFB 进行分层融合,以强化中间残差特征,见图3 中模块2).每个PFFG 使用了3 个MRCAB,残差分支的特征融合可以分为3 个步骤: 1)从左到右,每两个相邻的MRCAB 输出特征通过SAFB 进行融合;2)步骤1)输出的融合特征从左到右使用SAFB,对每两个相邻的特征进行融合,其余类推;3)步骤2)输出的融合特征作为PFFG 的残差分支输出,与PFFG的输入特征求和.每个PFFG 有3 个MRCAB,第n个PFFG 中第m(m=1,2,3)个MRCAB 的输出为则第n个PFFG 中第1 个MRCAB 的输入是前一个PFFG 的输出Fn-1(第1 个PFFG中,第1 个MRCAB 的输入为SFEB 的输出F0);第n个PFFG 中第m(m=2,3)个MRCAB 的输入为前一个MRCAB 的输出Fn可表示为:
式中,f MRCAB(·) 是MRCAB 函数;是第n(n=1,2,···,N)个PFFG 中,第m(m=1,2,3)个MRCAB 的输出:
式中,f SAF B(·) 是SAFB 块函数.
2.2 多尺度残差通道注意力块
本文的MRCAB 主要受Zhang 等[11]和Li 等[25]启发.Li 等[25]开发了一个多尺度的残差块(Multiscale residual block,MSRB).MSRB 包含两个分支,一个分支使用 3×3 卷积,另一个分支使用5×5卷积.两个分支输出的不同尺度特征拼接在一起,再分别通过 3×3 和 5×5 卷积.通过实验可以发现,更多尺度可以更好地利用特征信息,因此本文的MRCAB 使用三个分支,如图4 所示.为了减少参数量,一个分支使用 3×3 卷积,其余两个分支使用3×3扩张卷积,扩张率分别为2 和4.另外,为了简化MSRB,本文把三个分支输出的不同尺度特征简单地求和,进行融合.在MRCAB 的后部,引入了Zhang 等[11]的通道注意力机制,通过自适应地伸缩各个通道,以建模各个通道之间的依赖性.第n个PFFG 中,第m(m=1,2,···,M) 个MRCAB 的第k个分支(k=1,2,3)可表示为:
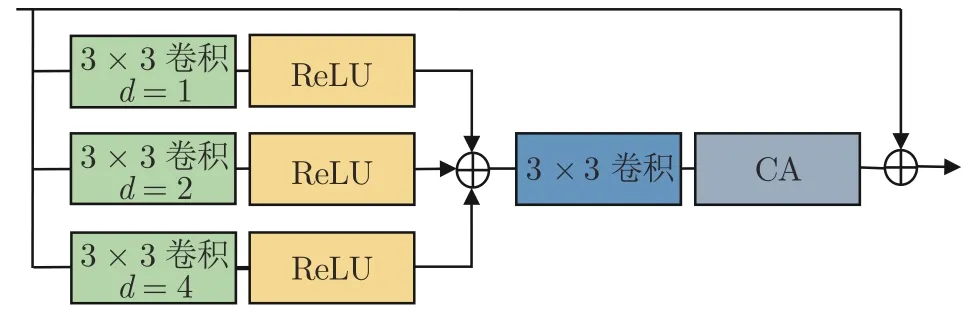
图4 多尺度残差通道注意力块Fig.4 Multi-scale residual channel attention block
第n个PFFG 中,第m(m=1,2,···,M) 个MRCAB 的输出可表示为:
式中,C A(·) 是RCAN 中通道注意力函数.
2.3 空间注意力融合块
考虑到MRCAB 中使用了Zhang 等[11]的通道注意力建模特征通道之间的依赖关系,在融合两个MRCAB 的输出特征时,使用空间注意力,进一步建模特征像素之间的依赖关系.两个MRCAB 的输出特征拼接在一起,使用 1×1 卷积进行融合,生成两个特征通道,再使用Sigmoid 函数,将通道像素值转换到(0,1)之间,作为输入特征的权重.学习输入特征像素之间的依赖关系,如图5 所示.假定输入的特征分别为FA和FB,SAFB 中特征融合过程可表示为:
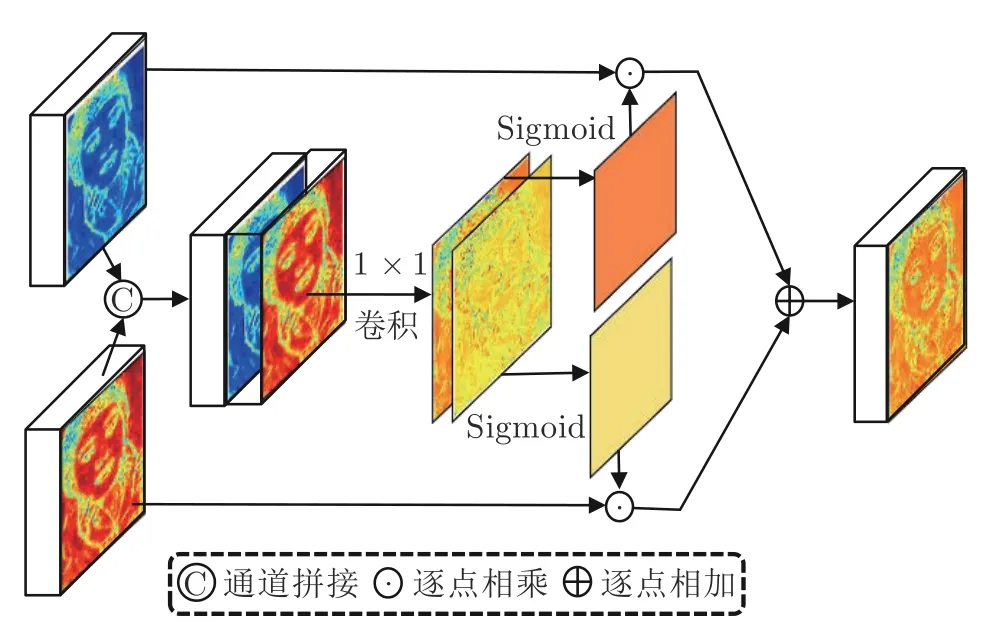
图5 空间注意力融合块Fig.5 Spatial attention fusion block
式中,Ffuse为SAFB 输出的融合特征,Conv1×1(·)为 1×1 卷积函数,f split(·) 把两个通道分裂为矩阵WA和WB,S igmoid(·) 为Sigmoid 函数,“·”为逐像素相乘.
SAFB 利用空间注意力机制,渐进地融合分层的特征信息,可以更好地利用和融合多样化的特征信息.
3 损失函数
本文的核心工作是引入像素级对比损失,使被恢复的像素更靠近原HR 图像中对应像素,远离其他邻近像素,以提高SR 图像的保真度和清晰度.对比学习框架[29,32,36-37]主要是为高层语义理解任务设计的,在低级视觉中应用的潜力还没有得到充分探索.对于给定的锚点,对比学习的目标是将锚点拉向正样本,远离负样本.基于CNN 的SISR 方法虽然显著改进了之前的SISR 方法,但如何恢复SR图像中丢失、模糊或失真的细节,仍然是有待解决的问题.目前,已有一些损失函数(如感知损失Lperc[15]、纹理损失Ltex[19]和对抗损失Ladv[20]等)改进了被广泛使用的L1或L2损失,但仍不能令人满意.Lperc和Ltex仍然不能阻止模糊,Ladv虽然能生成清晰的细节,但生成的细节严重失真和不自然.为了解决这个问题,本文提出像素级对比损失Lcntr.Lcntr可以与L1、L2、Lperc、Ltex和Ladv等一个或多个结合使用,进一步改进SR 图像的保真度和清晰度.
优化L1或L2损失函数是将待恢复的SR 图像中,每个像素逐渐逼近原HR 图像中对应的像素.遗憾的是,SR 图像恢复是一个病态逆问题,同一个低分辨率图像可以对应多个高分辨率图像,恢复的SR 图像是许多高分辨率图像的平均,导致过度平滑.本文的像素级对比损失Lcntr将SR 图像中的像素作为锚点,HR 图像中对应的像素作为正样本,与该正样本像素值相同的像素也作为正样本,其他像素作为负样本.Lcntr与L1或L2损失函数联合使用,增加一个附加的约束,让锚点接近正样本,远离负样本,具体过程见图6.不同的负样本可以自适应地推远锚点.Lcntr的形式类似于InfoNCE[38]损失,它是基于Softmax 的分类损失,在小批量样本中,分类正样本和负样本.原HR 图像分为许多大小相等的区域(假定共有Q个区域),在每个局部区域计算对比损失.在给定HR 图像中,第q个局部区域假定包含S个像素,第i个像素(记为xqHR,i)视为正样本,其他具有相同值的像素,也视为正样本,该区域对比损失计算为:

图6 像素级对比损失Fig.6 Pixel-wise contrastive loss
网络模型总损失计算为:
式中,λ C是系数,以平衡Lcntr和L1损失.
4 实验分析
4.1 实验设置
本文使用DIV2K 数据集[39]训练模型,其中800 个图像作为训练图像,5 个图像用于验证集,标记为DIV2K_val5.为了增强训练图像,训练图像进行了 9 0°旋转和随机的水平翻转.测试中,使用Set5[40]、Set14[6]、B100[41]、Urban100[42]和Manga-109[43]5 个标准测试数据集;对原HR 图像进行双三次下采样,以获得对应的LR 图像.与其他方法类似,使用PSNR 和SSIM 评估模型的客观性能,PSNR和SSIM 均在YCbCr 空间[23]的Y 通道上进行计算.训练中,批大小设置为16,LR 图像片尺寸设置为 4 8×48 像素.使用ADAM 优化器,设置β1=0.9,β2=0.999,ε=10-8.初始学习率设置为 1 0-4,每200 个迭代周期减半.使用PyTorch 框架实现模型,并在NVIDIA GeForce RTX 2080Ti GPU 上训练.
4.2 实验分析
4.2.1 消融实验
为了验证本文网络架构和像素级对比损失的有效性,进行了5 组对比实验: 1) 把网络架构中的MRCAB 替换为RCAB,仅使用L1损失,不包含SAFB 块和像素级对比损失Lcntr,以该模型作为基准,称为PRFFN0;2)在PRFFN0 基础上,增加类似于残差特征聚合(Residual feature aggregation,RFA)[35]的特征融合方法,与RFA 块的区别是将其残差子块替换为RCAB,这个模型称为PRFFN1;3) 将PRFFN1 中的RFA 特征融合方法替换为SAFB,进行特征融合,这个模型称为PRFFN2;4)将PRFFN2 中的RCAB 替换为MRCAB,这个模型称为PRFFN3;5)在PRFFN3 中,增加像素级对比损失Lcntr,这个模型称为PRFFN 即本文模型.训练1 000 个迭代周期,5 个模型在DIV2K_val5 验证集上3 倍超分辨率的平均PSNR 和参数量如表1 所示.表1 中,“✓”表示在训练时使用该损失,“—”表示训练时不使用该损失.由表1 可以看出,基准模型PRFFN0 的平均PSNR 为32.259 dB;RFA 特征融合改进了PRFFN0 的PRFFN1,平均PSNR 增加了0.048 dB.相较于RFA,本文SAFB 使用了空间注意力机制,增强了特征空间依赖关系之间的建模,优于RFA 中特征图的简单拼接,使PRFFN2 较PRFFN1 模型,参数量减少了55 K,平均PSNR却增加了0.035 dB;相较于RCAB,本文MRCAB使用了扩张卷积,在不增加模型参数量的情况下,扩大了特征感受野,且融合了多个尺度扩张卷积特征,使PRFFN3 较PRFFN2,平均PSNR 增加了0.022 dB;在L1损失的基础上,增加像素级对比损失Lcntr,提高了SR 图像的保真度,使PRFFN 较PRFFN3,平均PSNR 增加了0.087 dB.

表1 DIV2K_val5 验证集上,不同模型,3 倍SR 的平均PSNR 和参数量Table 1 The average PSNRs and parameter counts of 3 times SR for different models on the DIV2K_val5 validation data set
4.2.2 对比损失的设计与分析
1)对比损失的有效性.为了验证对比损失的有效性,实验比较了L1、Lperc、LCSD和Lcntr损失及其组合对应的PSNR 和学习的感知图像块相似性(Learned perceptual image patch similarty,LPIPS)[44]度量.LPIPS 被认为更符合人类的视觉感知,视觉感知质量随LPIPS 的降低而增加,而PSNR 值越高,则图像的保真度越高.训练1 000 个迭代周期,实验结果如表2 所示,表2 中“✓”表示在训练时,使用该损失;“—”表示训练时,不使用该损失.Lcntr与其他损失组合时,可改进PSNR 和LPIPS 值.当Lcntr与L1组合时,获得了最好的PSNR值(32.451 dB);当Lcntr与L1、LCSD组合时,获得了最好的LPIPS 值(0.0613).由表2 可知,LCSD作用于图像特征空间,获得了更好的LPIPS;Lcntr作用于像素空间,获得了更好的PSNR,即保真度更高.Lcntr组合LCSD虽获得了最好的LPIPS,但PSNR 有所降低.
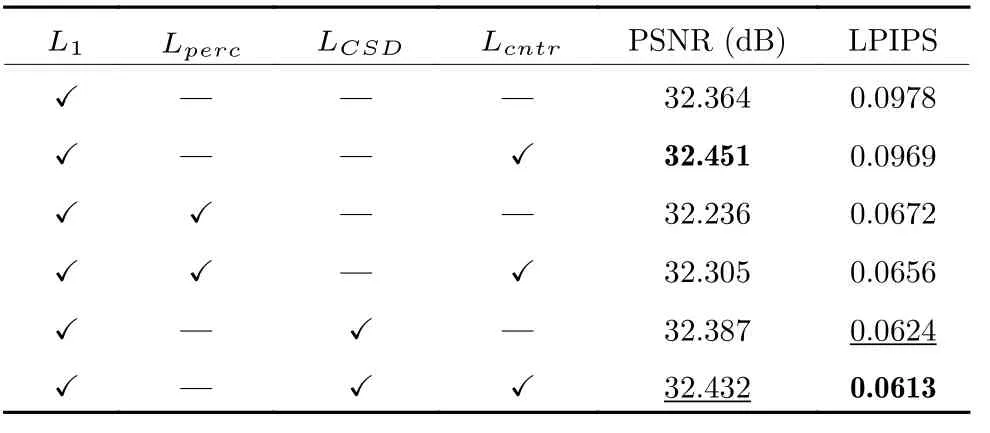
表2 DIV2K_val5 验证集上,不同损失函数及其组合,3 倍SR 的平均PSNR 和LPIPS 结果Table 2 The average PSNRs and LPIPSs of 3 times SR for different losses and their combinations on the DIV2K_val5 validation data set
2)不同比例对比损失影响.如式(11)所示,比例系数λ C可以调节对比损失的比例.训练1 000 个迭代周期,在DIV2K_val5 验证集上,不同λ C,3倍SR 的平均PSNR 结果见表3.由表3 可以看出,过大或过小的λ C使PSNR 结果恶化.当λC=10-1时,获得了最好的PSNR 性能.

表3 DIV2K_val5 验证集上,不同 λ C,3 倍SR 的平均PSNR 结果Table 3 The average PSNRs of 3 times SR for different λC on the DIV2K_val5 validation data set
3) 对比损失的通用性.本文的对比损失Lcntr可以与L1、Lperc和LCSD等损失组合使用,从而改进SR 图像的保真度.Lcntr也可用于其他模型,可以改进SR 的性能.以著名的EDSR、RCAN 和SwinIR-light[26]为例,训练1 000 个迭代周期,原模型和增加Lcntr损失后的平均PSNR 和SSIM 结果如表4 所示,表4 中“✓”表示在训练时使用该损失,“—”表示训练时不使用该损失,“↑”代表指标提升.由表4 可以看出,Lcntr损失可以显著改进SR 图像视觉效果.SwinIR-light 增加Lcntr后,在Urban-100 数据集中,img004 图像的3 倍SR 结果如图7所示.由图7 可以看出,使用Lcntr损失后,SR 图像的视觉质量得到显著改进.
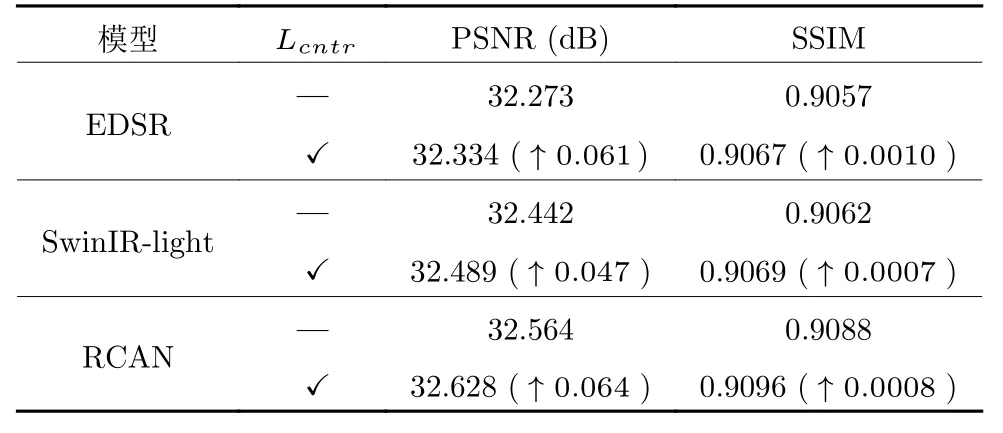
表4 DIV2K_val5 验证集上,不同模型包含与不包含Lcntr 损失,3 倍SR 的平均PSNR 和SSIM 结果Table 4 The average PSNRs and SSIMs of 3 times SR for different models with and without Lcntr loss on the DIV2K_val5 validation data set

图7 Urban100 数据集中,SwinIR-light 使用不同损失函数,img004 图像的3 倍SR 结果Fig.7 The 3 times SR results of SwinIR-light using different losses on the img004 image in the Urban100 data set
4)不同大小局部区域对对比损失的影响.计算对比损失的方形局部区域,可用区域中像素个数S度量.本文考虑 4×4 像素、8×8 像素和 1 6×16 像素的局部区域,S分别为16、64 和256.在DIV2K_val5 验证集上,训练1 000 个迭代周期,不同S值的3 倍SR 的平均PSNR 结果见表5.可以看出,更大的局部区域(即更大的S值)负样本更多,有利于改进PSNR 性能.但在训练时,更大的S值需要更多的时间和更大的内存量(见表6).考虑到相较于S=64,在S=256 时,PSNR 改进很小,因此本文选择S=64.

表5 DIV2K_val5 验证集上,不同大小局部区域,3 倍SR 的平均PSNR 结果Table 5 The average PSNRs of 3 times SR for different size local regions on the DIV2K_val5 validation data set

表6 3 倍SR 训练10 个迭代周期,训练占用的内存和使用的训练时间Table 6 For 3 times SR,10 epochs,comparing the memory and time used by training
5)对比学习训练的计算代价.4 组对比实验分别为不使用Lcntr损失以及S=16、64 和256 三种情形.对于3 倍SR 训练10 个迭代周期,训练占用的内存和使用的训练时间如表6 所示.表6 中,“✓”表示在训练时使用该损失,“—”表示训练时不使用该损失.由表6 可以看出,计算代价没有显著增加.当S=64 时,内存增加了约21%,计算时间仅增加了约11%.
4.2.3 PFFG 实验
在网络架构中,共由10 个PFFG 组成,每个PFFG 包含3 个MRCAB 和3 个SAFB,见图3 中模块2).
1) 扩张卷积的不同扩张率对性能的影响.与RCAN 中的RCAB 相比,MRCAB 没有增加参数,并且通过多分支提取了多尺度特征信息,并通过扩张卷积(或空洞卷积)扩大了感受野.MRCAB 中,3 个分支扩张卷积的扩张率组合分别设为1,2,3、1,2,4 和1,2,5.考虑只有1 个分支使用常规卷积即扩张率为1,此时MRCAB 退化为RCAB;考虑2 个分支,扩张率组合为1,2 的情形,训练1 000 个迭代周期,不同分支和不同扩张率组合,3 倍SR 的平均PSNR 结果见表7.由表7 可见,不同尺度的特征融合可以改进性能.扩张率更大,特征感受野大,对性能有益.但过大的扩张率,也是有害的.MRCAB 三个分支的扩张率设置为1,2,4 较为合理.

表7 DIV2K_val5 验证集上,MRCAB 不同分支和不同扩张率组合,3 倍SR 的平均PSNR 结果Table 7 The average PSNRs of 3 times SR for the different branches of MRCAB with different dilation rate combinations on the DIV2K_val5 validation data set
4.3 与先进方法比较
1)客观比较.本文与代表性的双三次上采样、快速超分辨率卷积神经网络(Fast super-resolution convolutional neural network,FSRCNN)[45]、稀疏掩码超分辨率网络(Sparse mask super-reolution,SMSR)[46]、自适应级联注意力网络(Adaptive cascading attention network,ACAN)[47]、权重自适应超分辨率网络(Adaptive weighted super-resolution network,AWSRN)[48]、深度递归卷积网络(Deeply-recursive convolutional network,DRCN)[49]、级联残差网络(Cascading residual network,CARN)[50]、OISR-RK2 (Apply ODE-inspired schemes to super-resolution network designs-Runge-Kutta)[51]、OISR-LF (Apply ODE-inspired schemes to superresolution network designs-leapfrog)[51]、MSRN、软边缘辅助网络(Soft-edge assisted network,SeaNet)[52]和两阶段注意力网络(Two-stage attentive network,TSAN)[53]方法进行比较.在5 个标准测试数据集上,2 倍、3 倍和4 倍SR 的平均PSNR 和SSIM 结果见表8.与最先进的TSAN 相比,本文模型参数和计算量大约减少了1/3,推理时间大约减少了一半,但性能更好.例如,对于2 倍SR,本文方法与TSAN 相当;对于3 倍和4 倍SR,在所有测试数据集上,本文方法均优于TSAN.特别是在Urban100数据集上,平均PSNR 最大改进分别为0.1 dB 和0.16 dB.
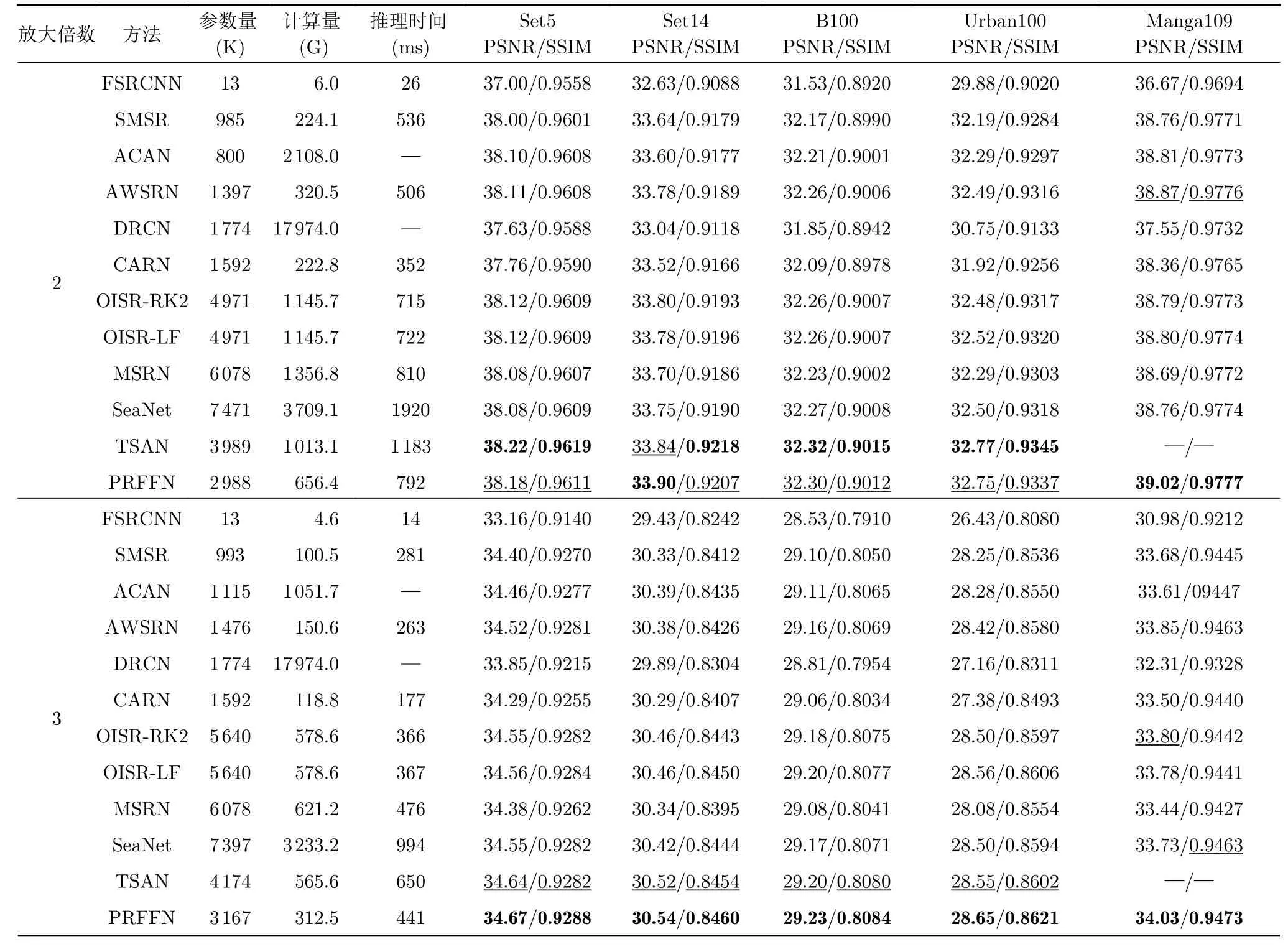
表8 5 个标准测试数据集上,不同SISR 方法的2 倍、3 倍和4 倍SR 的平均PSNR 和SSIM 结果Table 8 The average PSNRs and SSIMs of 2 times,3 times,and 4 times SR for different SISR methods on five standard test data sets
2)主观效果比较.各种方法SR 的视觉效果比较见图8~10.可以看出,本文方法恢复的SR 图像视觉质量优于其他方法.例如,对于Urban100 数据集中的图像img076,其他方法恢复的SR 图像存在过度模糊或条纹方向错误,本文方法恢复出的SR 图像接近于原HR 图像;其他图像的恢复结果也类似.

图8 2 倍SR 的视觉效果比较Fig.8 Visual comparison for 2 times SR

图9 3 倍SR 的视觉效果比较Fig.9 Visual comparison for 3 times SR
5 结束语
本文提出一个通用的基于对比学习的逐像素损失函数Lcntr,以恢复出的SR 图像像素作为锚样本,原HR 图像对应的像素作为正样本,其他像素作为负样本.Lcntr使锚样本尽可能接近正样本,并远离负样本,可以显著改进SR 图像的保真度和视觉质量.为了验证Lcntr的性能,本文提出一个SR 的网络架构PRFFN.实验结果表明,本文的PRFFN 组合Lcntr取得了很有竞争力的SR 性能.
猜你喜欢
艺术家(2023年8期)2023-11-02
小哥白尼(军事科学)(2022年2期)2022-05-25
网络安全与数据管理(2022年3期)2022-05-23
数学小灵通·3-4年级(2021年5期)2021-07-16
北京航空航天大学学报(2020年10期)2020-11-14
红领巾·萌芽(2019年8期)2019-08-27
自动化学报(2019年6期)2019-07-23
今日农业(2019年15期)2019-01-03
CHIP新电脑(2016年3期)2016-03-10
广西民族大学学报(自然科学版)(2015年3期)2015-12-07