
基于扩散模型生成数据重构的客户流失预测
2024-02-20 08:21王正阳程梓航赵慧英程新洲
计算机研究与发展 2024年2期
杨 斌 王正阳 程梓航 赵慧英 王 鑫 管 宇,3 程新洲
1 (中国联通研究院 北京 100048)
2 (北京邮电大学人工智能学院 北京 100876)
3 (云南省软件工程重点实验室(云南大学) 昆明 650504)
(researcher_yang@outlook.com)
数据是人工智能技术研究和应用的基础要素.但在真实的数据挖掘场景中,如客户流失、软件测试等领域[1-5]存在大量正负样本不均衡问题. 除了该类场景客观依然存在正样本天然比负样本少的原因外,更重要的是由于样本的收集、标注成本太高,获取有效的标注样本非常困难. 同时伴随业界对数据安全、隐私保护意识的提升,数据保护被广泛关注,且国内外已出台系列相关的法律法规[6-7]. 为了解决样本不平衡问题,学者们提出了多种方法,其中合成新数据是主流方法之一. 基于合成新数据对原始数据进行融合重构,可获得更多的样本,用于缓解该问题. 同时高质量的合成数据在分布上和真实数据一致,可应用于重构或替代真实样本,具有保护隐私数据的价值.
合成数据的方式常用的有2 种:数据增强和数据生成. 数据增强在图像领域应用较多[8]. 在以结构化数据为主的数据挖掘领域通常以过采样或插值的方式调整正负样本比[9-11]. 该类方法虽然简单易实现,但需要大量的人工参与,并且合成数据和真实数据分布相去甚远,无法有效应用于数据保护,且对数据挖掘预测效果提升有限. 学者们在图像领域做了很多基于生成对抗网络(generative adversarial network,GAN)的数据生成研究工作[12-13]. 在以结构化数据为主的数据挖掘领域,生成方法研究相对较少,但在近年开始被关注,出现IRGAN、CTAB-GAN 等方法[14-15].由于该领域特征类型较多,且不同维度特征独立,导致生成效果不理想,难以有效应用于对原始数据的融合重构. 近年扩散模型在图像领域大放异彩[16],但将其应用于结构化数据的研究相对较少. 考虑到客户流失预测是一个典型的正负样本不均衡且涉及用户隐私保护的场景,本文以客户流失预测为实验场景,基于扩散模型生成数据探索在真实数据挖掘场景中的应用价值.
客户流失是指已有客户放弃继续购买企业商品或服务的一种现象. 该现象在企业经营中普遍存在,如电信行业中客户连续多月停止缴费;金融行业中客户中断购买理财产品;互联网场景中客户不再活跃等[1-3]. 客户流失会导致企业失去稳定的客户和收益源,造成巨大损失. 精准的客户流失预测,可发现流失概率大的客户,可通过挽留降低流失. 学者们对客户流失预测进行了大量研究,初期以传统统计学预测方法为主,包括决策树(decision tree,DT)、逻辑回归(logistic regression,LR)、贝叶斯(Bayesian)分类器、支持向量机(support vector machine,SVM)等算法[17-19]. 随着集成学习的引入,随机森林(random forest,RF)、 梯度提升决策树( gradient boosting decision tree,GBDT)、Adaboost 和Stack 等方法被大量引入到对客户流失的预测中. 近年也有工作尝试深度学习,但由于流失客户数据量较少,深度学习模型效果不理想[20-22]. 当前主流的做法还是采用传统的统计方法和集成学习.
客户流失预测在数据方面存在2 个问题:1)数据不平衡问题. 考虑到用户习惯和适应新产品的成本,客户通常会在较长周期内处于忠诚状态,不会轻易流失. 因此流失客户在数量上相对总客户会非常少,相差几倍甚至几十倍. 2)客户流失数据直接使用真实数据,有用户隐私数据泄露风险. 客户数据通常采集了用户的基础属性和行为数据. 涉及用户隐私的数据需要保护起来,防止泄露对客户造成损失和伤害. 生成数据对不平衡和用户隐私保护都有帮助,但将生成数据应用于客户流失的研究非常少. 本文基于扩散模型生成样本进行数据重构,验证扩散模型在缓解数据不平衡和保护数据隐私的可能性.
本文主要贡献有3 点:
1)首次提出一种基于扩散模型生成数据重构客户流失数据的方法. 基于扩散模型生成结果针对不同模型设计了多种融合重构策略,充分挖掘扩散模型在缓解数据不平衡问题上的价值.
2)采用扩散模型生成客户流失数据,生成结果在模型效果上和数据分布上与真实数据非常接近.因此生成数据可作为客户真实数据的替代,在客户流失的用户隐私保护问题上具有很大的潜在价值.
3)在电信、银行、互联网等多个数据集上进行客户流失预测实验. 通过大量的实验和分析,证明基于扩散模型生成的数据有助于提升客户流失模型效果,且能被应用于用户隐私保护.
1 相关工作
本节主要介绍数据生成方法和客户流失预估的相关研究工作.
1.1 数据生成
数据生成常用方法有简单数据合成和GAN、扩散模型等方法. 在图像领域以Mixup 为代表的样本插值方法有着不错的效果[8]. 在数据挖掘领域,Wu 等人[23]采用改进的SMOTE(synthetic minority over-sampling technique) 解决流失数据的不平衡问题,应用于电子商务客户流失预测.
随着GAN 的发展,在数据挖掘领域有人将GAN应用于数据生成. IRGAN[14]将视觉领域中广泛应用的GAN 引入到信息检索,探索了GAN 在离散领域的适用问题. TableGAN[24]使用GAN 生成表格数据用于用户隐私保护. CTAB-GAN[15]在GAN 的基础上针对含连续变量和类别变量的数据生成进行优化. 近年,扩散模型被应用于生成领域,通过对样本的加噪和去噪过程,有效实现图像生成[25-26].
1.2 客户流失预估
在过去的研究中,学者们对客户流失预测在多种领域的应用进行了大量的探索,包括电信、银行、互联网等行业. 预测方法也逐渐成熟,发展历程主要分为2 个阶段:
第1 阶段是传统统计学预测方法,主要包括决策树、逻辑回归、贝叶斯分类器、支持向量机等算法[17-19]. Qiu 等人[3]使用逻辑回归来预测电子商务场景下的客户流失. Nie 等人[27]分别使用决策树和逻辑回归对银行信用卡用户流失做预测.
第2 阶段是集成学习算法的垄断和深度学习的初步探索. 随着集成学习的引入,随机森林、GBDT、Adaboost 和Stack 等方法被引入到对客户流失的预测中. 特别是GBDT,由于其优秀的性能而被广泛应用.Xie 等人[28]提出了一种改进的平衡随机森林,并将其应用于银行客户流失预测. Wu 等人[20]在电子商务数据集上提出PCA-AdaBoost 模型,并证明模型的有效性. Liang 等人[29]提出基于GBDT 和逻辑回归算法的模型预测移动用户流失. 第2 阶段的客户流失预测方法主要为集成学习,应用最多的是GBDT 算法.
2 方法介绍
客户流失数据多为表格类数据,通常包含2 类特征,分别为数值型特征,包括年龄、收入等;类别型特征,包括性别、省份等. 本文的研究路线如图1 所示,为了能够生成客户流失数据,我们基于高斯扩散模型和多项式扩散模型分别处理数值型和类别型特征数据. 扩散生成模型通常包括前向扩散和逆向生成2个阶段[25-26]. 其中,高斯扩散模型用于数值型数据的前向扩散阶段,多项式扩散模型用于类别型的前向扩散阶段;在逆向阶段,我们对这2 种模型进行结合,通过神经网络实现逆向生成过程.
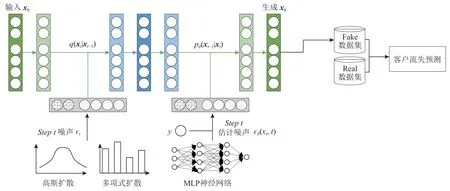
Fig. 1 The schematic diagram of customer churn prediction based on the diffusion model图1 基于扩散模型的客户流失预测示意图
2.1 数据预处理
流失客户特征主要分为数值和类别2 种类型,在进入模型之前通常需要进行数据预处理,主要包括对数值型特征进行归一化处理和对类别型特征进行独热编码处理. 图1 中的输入数据x0为预处理后的数据,包括归一化处理的xnum和独热编码处理的xcat.
2.2 扩散模型框架
去噪扩散概率模型(denoising diffusion probabilistic model,DDPM)是一种概率生成模型,包含前向和逆向2 个阶段. 通常假设其前向阶段和逆向阶段均为马尔可夫过程. 前向过程也称前向扩散过程、前向加噪过程等;逆向过程也称逆向生成过程、逆向去噪过程等[30].
前向扩散过程是一个逐步加噪的过程,向样本x0逐步添加噪声,得到原始数据的每一次扩散后的状态. 当最终加噪步数T足够大时,可以使得原有的样本数据分布xT最终转换为预先定义好的噪声分布,通常选择各向同性的高斯分布,即q(xT|x0)~N(0,I).
逆向生成过程是一个逐步去噪过程. 整个过程中,若逆向过程中的每一步t能够精确求得条件概率分布p(xt−1|xt),则可以通过逆向迭代不断采样恢复加噪之前的数据p(x0),完成生成任务. 但是由于分布p(xt−1|xt)通常是未知的,所以无法直接求得p(x0),通常采用神经网络来近似估计其分布.
2.3 基于高斯扩散模型的数值型数据处理
高斯扩散模型是最常用的扩散模型,其针对连续样本空间(xt∈Rn)如数值型样本进行处理[16,31]. 其前向和逆向阶段均将样本数据分布预定义为高斯分布.其前向过程用式(1)(2)表示. 其中,q()表示前向扩散过程,通过加噪声,直到第T步q(xT)满足高斯分布采样. 其中 β用于控制添加噪声的强度.
逆向过程p()通常采用构建由 θ参数化的神经网络来近似估计其分布. 假设pθ(xt−1|xt)是逆向过程的概率分布,且服从于高斯分布,考虑到从xt去第t步噪声估计xt−1,其均值 µθ和方差均可看作xt和t的函数,即式(3). 为便于后续计算和减少神经网络训练难度,将方差设定为不需要参与神经网络训练且与时间相关的常数,因此在训练时,仅使用神经网络训练均值 µθ即可. 如式(4)所示,µθ(xt,t)可以看成xt和ϵθ(xt,t)的函数. 其中ϵθ(xt,t)为xt的估计噪声, α和 β都是常数.
在实际计算中,误差公式多被简化为噪声的估计误差,如式(5)所示,其中 ϵ是前期加的噪声,假定其符合高斯分布.
2.4 基于多项式扩散模型的类别型数据处理
多项式扩散模型是近年被提出用于处理类别型数据的扩散模型[32-33]. 多项式扩散模型需要类别特征用独热方式进行编码. 假定类别数据xt∈{0,1}K用独热方式表示,K表示该类别特征有K个值.
多项式前向扩散过程,定义扩散采样分布q(xt|xt−1)为一个类别分布CAT,在原始数据基础上通过均匀增加噪声的方式进行扩散. 如式(6)所示,可以看出每一步扩散对应的K个类分别引入很小的均匀噪声( β),在上一步状态xt−1上以很大概率(1−β)进行采样,保留上一步的信息. 待t步扩散之后,可以得到xt如式(7)所示. 其中
和高斯扩散模型类似,xt−1的逆向估计分布p(xt−1|xt)无法直接计算,但其可用后验概率q(xt−1;xt,x0)表示,如式(8)所示. 因此,逆向分布pθ(xt−1|xt)可以被参数化为q(xt−1|xt,(xt,t)),其中表示估计的x0,可以通过神经网络进行估计.
2.5 扩散模型噪声估计
本文结合高斯扩散模型和多项式扩散模型建模数值型和类别特征,在前向加噪声过程中分别通过高斯和多项式扩散进行采样. 在逆向生成过程中,考虑到输入信息除了输入数据x0,还应包括扩散步数t和类别信息y,二者对噪声分布都有影响,如式(9)~(11)所示. 其中扩散步数信息采用传统的正弦时间嵌入方法[11,16,34].
由于深度学习中多层感知机(multilayer perceptron,MLP)多被应用于拟合输出,本文逆向去噪生成过程采用MLP 进行噪声分布估计,如式(12)(13)所示,输出和输入相同维度的特征作为估计噪声.
在训练阶段,为了能够同时对高斯扩散模型和多项式扩散模型进行优化,我们基于2 种模型的损失函数设计了联合损失函数如式(14)所示,其中式(14)右侧为高斯扩散模型损失和类别特征的平均KL 散度(Kullback–Leibler divergence,KLD),为每个多项式扩散项的KL 散度,C为类别特征数目.
2.6 流失预测方法
为了能够验证基于扩散生成模型在客户流失场景下的预测效果和隐私保护能力,本文在客户流失预测中选择了2 种模式,分别是弱分类器模式和强分类器模式,包括经典的分类算法和GBDT[2,21]. 其中,对于弱分类器本文选择了客户流失预测场景中的经典算法,包括决策树、贝叶斯、支持向量机和逻辑回归等. 我们选择了客户流失场景中被广泛应用的GBDT作为强分类器,其中,Catboost 是一种主流的GBDT实现方法,能够在大部分数据上达到最好效果[21].
3 实验设置
3.1 数据集
为了能够对不同场景的客户流失进行建模,我们选择了3 种不同场景的客户流失数据,分别为:
1)电信客户流失数据集①https://www.kaggle.com/datasets/blastchar/telco-customer-churn. 该数据集来自Kaggle的电信流失用户预测数据. 其共有7 043 条电信客户数据,其中客户流失数据有1869 条. 每条数据包括21 个特征,其中3 个数值特征和18 个类别特征. 在实验时我们过滤了用户ID 特征“customer ID”,保留了其他17 个类别特征.
2)银行流失数据集②https://www.kaggle.com/datasets/sakshigoyal7/credit-card-customers. 该数据来自Kaggle 的银行信用卡流失数据集. 该数据集共有10 127 条银行客户数据,其中客户流失数据有1 627 条. 每条数据包括23 个特征,其中16 个数值特征和7 个类别特征.在实验时我们过滤了用户ID 特征“CLIENTNUM”,并按照数据说明删去了最后2 个无关特征,只保留14 个数值特征和6 个类别特征.
3)互联网产品流失数据集③https://tianchi.aliyun.com/dataset/124814. 该数据是来自阿里云天池比赛的直播电商用户流失行为预测数据集.该数据集共有5 630 条直播电商相关客户数据,其中客户流失数据有948 条. 每条数据包括19 个特征,其中9 个数值特征和10 个类别特征,在实验时我们过滤了用户ID 特征“Customer ID”,保留了其他9 个类别特征.
在训练时,每个数据集都按照8∶2 的原则分为训练集和测试集.
3.2 实验环境及超参设置
实验以Pytorch 为基础框架,在NVIDIA GPU 3050Ti 上进行训练. 根据经验设置,实验中扩散模型的总步数设置为1 000,Batchsize 设置为4 096,Epoch设置为30 000,优化器采用Adam 算法,学习率设置为0.001. 实验中,Catboost 算法的学习率设置为0.03,计算叶子节点值时候的迭代次数设置为8. Logistic Regression 算法的正则化项的类型设置为l2,其正则化强度的倒数设置为10,模型的最大迭代次数设置为1 000.
3.3 评估指标
实验中,为了评估最终的模型分类效果,本文采用了AUC(area under curve)、ACC(accuracy)、Logloss以及F1 值等指标进行评估,其相关计算方式可参考文献[35].
4 实验结果及分析
4.1 生成数据展示
我们通过扩散模型DDPM 在电信、银行、互联网数据集上生成了新的客户流失数据. 以电信数据集为例,真实数据(REAL)和DDPM、SMOTE 以及CTAB-GAN 的生成结果如表1 所示. 从表1 可以看出,DDPM、SMOTE,CTAB-GAN 这3 种方法均能生成与REAL 相似的结果. 但比较具体生成的特征细节,可以发现DDPM 生成的数据和REAL 更接近,特别是数值型特征;SMOTE 和CTAB-GAN 则存在大量的整型数据生成后成为浮点型的问题;从随机抽取的样本上看,CTAB-GAN 的生成数据相对比较发散,和REAL 差异较大,这也比较符合GAN 的算法特点.

Table 1 Generation Results Presentation for Telco Customer Churn Datasets表1 电信客户流失数据集生成结果展示
4.2 生成结果对比分析
为了研究在客户流失场景下扩散模型和其他生成方法的生成数据效果对比,我们对REAL 以及不同方法生成的数据进行采样,并在单个独立特征和多个联合特征分布上分别进行展示.
1)独立特征对比. 我们对单个独立特征进行采样,针对3 个不同场景数据集分别随机挑选2 个特征,包括1 个数值型和1 个类别型. 生成数据和REAL 的分布统计结果如图2 所示. 我们可以看出DDPM 相对其他方法和REAL 分布更相似. 对于数值型特征,在3 个场景上CTAB-GAN 的效果最不理想,和真实分布差异较明显. 在类别型特征上,SMOTE 效果最不理想,在某些类别上生成数据与REAL 分布差异较明显,且在生成数量比较少的类别值时可能会出现生成数据量远小于REAL 量的问题,这与其算法进行插值有关.
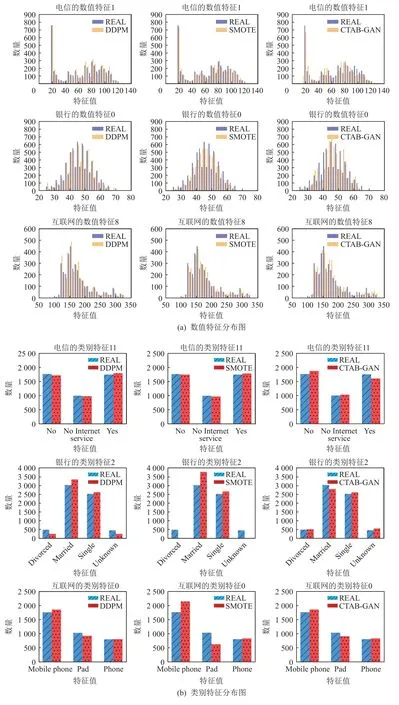
Fig. 2 Distribution of independent features in generated data and real data图2 关于生成数据和真实数据的独立特征分布
2)联合特征对比. 我们对特征相关性也进行了研究. 对数值型特征我们统计了生成数据和REAL 的皮尔逊相关系数;对类别型特征计算Theil’s U 统计量;对数值与类别间特征关系计算Correlation Ratio[15],合成数据与REAL 的特征相关性矩阵差异结果如图3 所示. 图中颜色深浅代表对应生成数据和REAL在特征相关性上的差异,颜色越深代表差距越大. 我们可以看出和其他生成方法相比,DDPM 的生成结果更加接近REAL,生成效果更显著,CTAB-GAN 的生成效果相对最差.
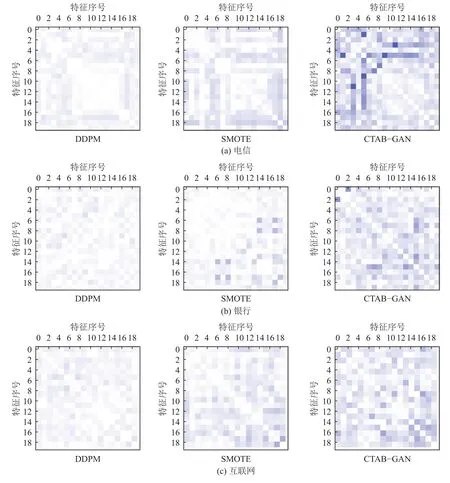
Fig. 3 Difference of correlation matrix between generated data and real data图3 生成数据与真实数据的相关性矩阵差异
4.3 数据重构预测效果对比
为了验证生成数据对客户流失预测的重构效果,本文分别在电信、银行、互联网3 个场景进行对比.本文设计了4 种训练集数据重构方式:1)用生成数据等量代替真实训练集集,记为Fake±;2)只用生成数据等量代替正样本,负样本仍为真实数据,记为Fake+;3)对第2 种融合方式的负样本数据进行欠采样,使得正负样本量比为1:1,记为Fake+_1:1;4)只用生成的正样本数据和所有真实数据融合,使得正样本数据量增加至和真实负样本数据量相当,正负样本量比为1:1,记为Merged+_1:1.
考虑到弱分类器和强分类器对客户流失模型的预测效果不一样,本文选择了决策树、贝叶斯分类器、支持向量机和逻辑回归4 种弱分类器,对其结果取平均值;同时选择GBDT 作为强分类器,采用广泛应用的Catboost 算法实现. 我们采用这种模式验证扩散模型在弱分类器和强分类器上的预测效果,实验结果如表2 和表3 所示.
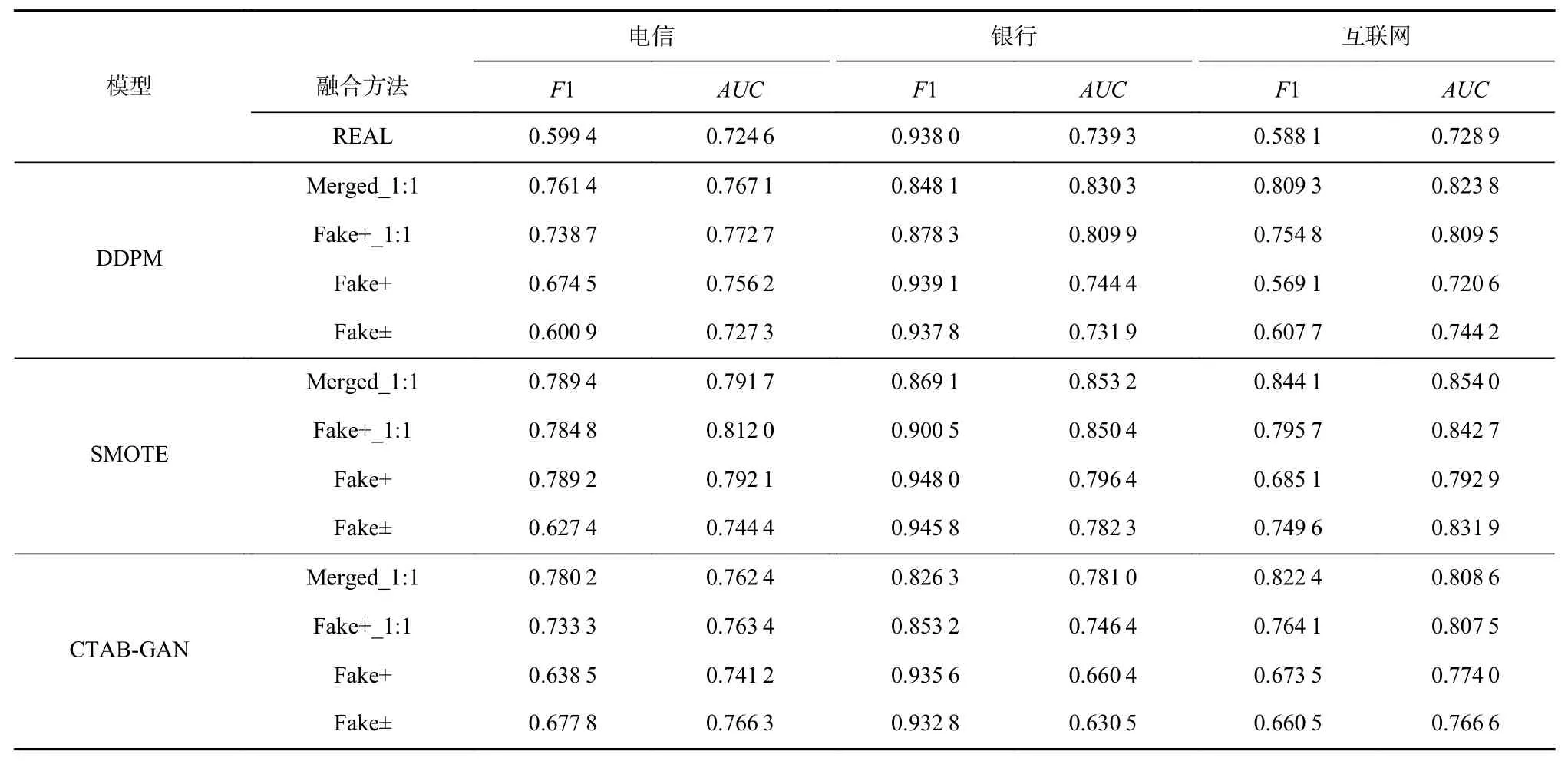
Table 2 Effect of Data Reconstruction Based on Week Classifiers Algorithm表2 基于弱分类器算法的数据重构效果

Table 3 Effect of Data Reconstruction Based on Catboost Algorithm表3 基于Catboost 算法的数据重构效果
从表2 可以看出,弱分类器的实验在电信、银行、互联网3 个场景中,生成数据重构的数据集的模型效果均有所提升. 针对不同训练集融合重构方式,我们发现DDPM 在Fake±方式下(用生成数据全量等比例替换真实数据)和REAL 效果一致,其他方法则是提升. 这说明针对弱分类器,DDPM 生成的数据更接近REAL 分布.
强分类器Catboost 的实验结果如表3 所示. DDPM生成的数据重构后的效果基本和REAL 的效果一样,这个结论和弱分类器实验保持一致. 说明DDPM 生成的数据和REAL 分布非常接近,并且与分类器无关.其他方法如CTAB-GAN 和SMOTE 均略逊于REAL的效果. 由于银行数据集在强分类器上的分类实验效果非常理想,接近上限,因此DDPM、SMOTE,CTABGAN 这3 种方法在该数据集上的表现也非常接近.
4.4 基于误分样本的数据重构
在分类问题中,相较于易分类的样本,误分样本对提升模型性能更有价值. 因此鉴于Catboost 在生成数据集上的效果和真实数据效果持平,没有明显提升,我们提出基于误分样本提升模型效果的重构策略. 该方法基于生成数据的误分类样本重构真实数据,增加误分类样本的数量和多样性.
考虑到基于扩散模型生成的数据与真实数据分布一致,我们应用真实数据训练的Catboost 对基于扩散模型生成的数据进行预测,选出误分类的生成样本,然后将误分的生成样本与真实数据进行融合得到重构数据集. 重构数据集中误分样本的比例和多样性都得到了提升. 基于重构数据集进行训练并在真实的测试集上进行评估,结果如表4 所示. 其中Fake_Best 是表3 中未加入误分样本策略的基于生成数据在测试集上表现最好的重构效果;REAL+是真实数据增加了误分样本重构后的数据集. 可以看出基于误分样本进行数据重构的策略在3 个数据集上均对强分类器Catboost 效果有提升,说明基于扩散模型的误分样本的数据重构对强分类器Catboost 是可行的.

Table 4 Effect of the Fusion of Real Samples and Misclassified Generated Samples for Catboost表4 基于融合真实样本和误分生成样本的Catboost 效果
5 讨 论
5.1 生成数据规模对模型效果的影响
为了探索基于扩散模型的生成数据规模对模型分类效果的影响,本文基于扩散模型生成真实训练集数据量1,10,30,50,70 和100 倍的合成数据(fakeall)用于训练Catboost 模型,结果如表5 所示.在3 个数据集中,增大样本规模都可以使分类器的性能得以提升. 在电信和互联网数据集中,当数据样本增加至原训练样本的70 倍时模型效果最优,且均高于REAL 的训练结果. 银行数据集的生成数据量从1 倍增加到100 倍的过程中,模型效果持续提升.由于扩散模型生成的数据在整体分布上更符合真实样本的分布规律. 当样本数量增加时,数据的多样性也会随之提升,因此可以获得更好的预测效果. 实验表明通过增大生成数据规模提升模型效果是可行的.

Table 5 Effect of Generated Amount of Data on Effectiveness表5 生成数据量对效果的影响
5.2 用户隐私保护能力分析
客户流失数据涉及到大量的用户数据,建模时被直接暴露,未对用户隐私数据进行保护,存在对客户造成伤害和损失的风险. 本文探索了将生成数据应用于用户隐私保护的潜力. 我们设计了2 种指标用于定量研究生成数据和真实数据之间的差异,评估生成数据用于隐私保护的能力[15].
1)最近样本距离(distance to closest record,DCR).对于每条生成数据,计算其与真实数据间的欧氏距离,将其中最近的距离作为DCR,其值越小代表生成数据和真实数据越接近,复制真实数据的信息越多,数据隐私信息保护的能力也就越弱. 反之,DCR 值越大代表生成的数据和真实数据的差异也就越大,表明生成数据越接近新数据,而不是简单地复制原始数据的信息,因此想要通过这种生成数据的方式复原原始数据的难度也越大,隐私信息保护能力越强.
2)最邻近距离比例(nearest neighbour distance ratio,NNDR)是度量最近的距离和第二近的距离的比例,其取值范围为[0,1]. 和DCR 一样,NNDR 值越大表示有更好的隐私保护能力;越小的NNDR 值意味着和真实数据越接近,保护性越差.
我们计算了生成数据的隐私指标,结果如表6 所示. 可以看出,在3 个数据集中,和SMOTE 相比,DDPM生成的数据在DCR 和NNDR 上在3 个客户流失场景下均要优于SMOTE,说明DDPM 的数据更适合应用到隐私保护中. 但和CTAB-GAN 相比,DDPM 在这2个隐私指标上要略逊一筹. 经过分析,CTAB-GAN 在生成结果上和真实数据分布差异较大,导致了其客户流失模型预测效果较差. 但由于生成数据与真实数据不一致,会造成很难通过生成数据复原原始数据,保护能力更好. 由此可以看出,DDPM 生成的数据在生成质量和隐私保护2 个方面具有更好的平衡.
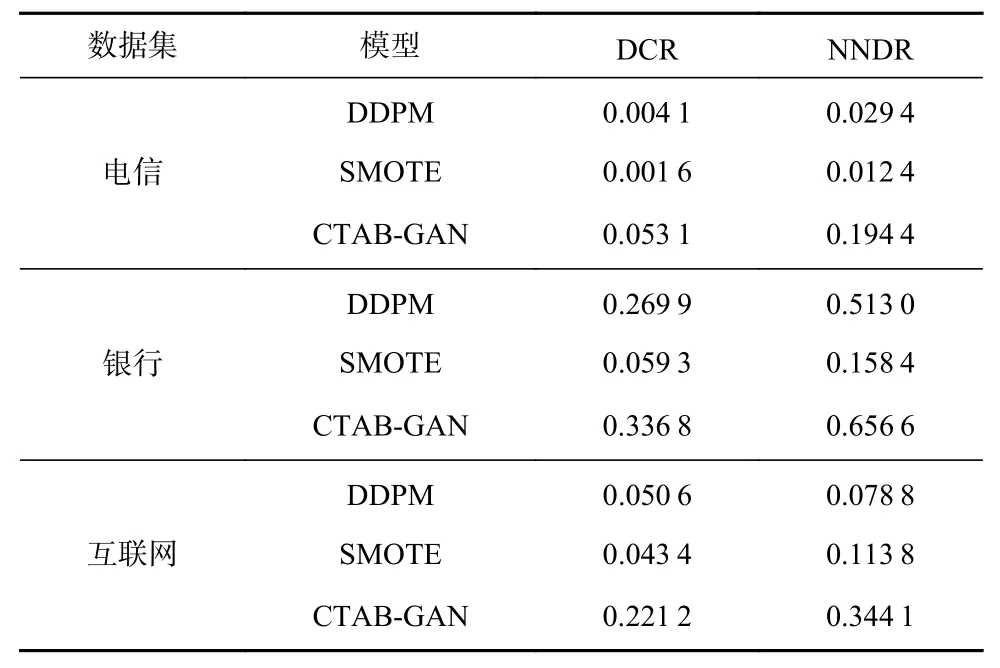
Table 6 Analysis of Privacy Protection Capability表6 隐私保护能力分析
为了能够展示生成数据和隐私保护的关系,如图4 所示我们统计了生成结果与原始数据的平均欧式距离作为生成数据与真实数据的相似度指标. 分别就所有样本、正样本和负样本统计,平均距离越大,相似性越小;平均距离越小,相似性越大.
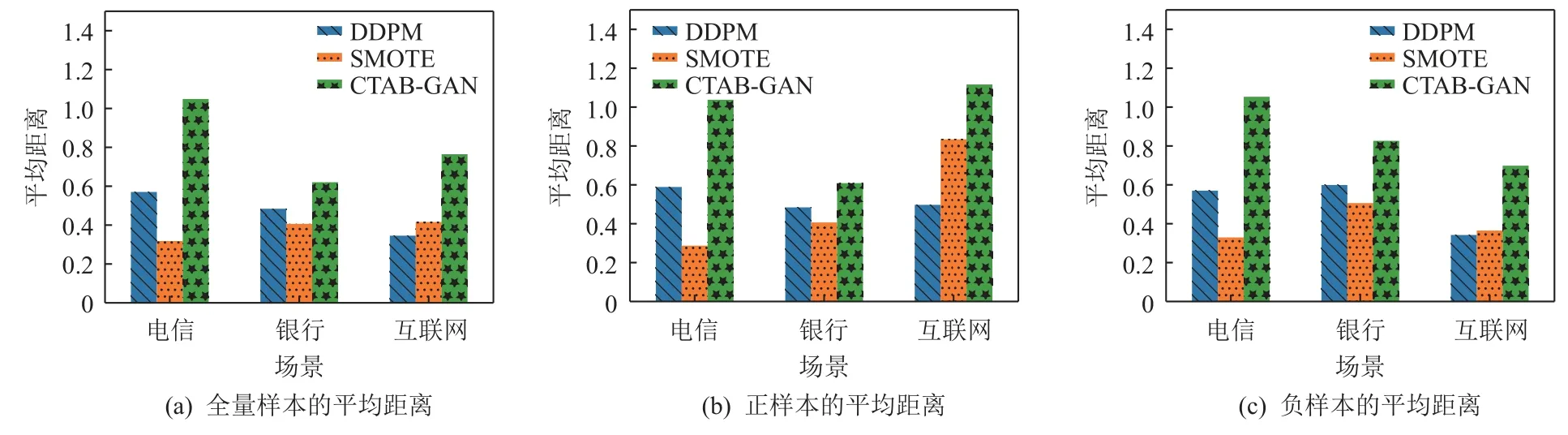
Fig. 4 Average distance between generated data and real data图4 生成数据与真实数据的平均距离
从图4 可以看出,基于SMOTE 生成的结果与真实数据的平均距离最小,即相似度最大;CTAB-GAN则反之,其相似度最小. DDPM 的平均距离在数据整体上和不同子类别上均处于中游水平,其相似度水平居中. 我们分析认为:SMOTE 有直接插值的思想,会保留较多的真实样本信息,CTAB-GAN 则是生成了大量不太相关的信息. 相对而言,DDPM 生成的数据更符合真实分布,且具有一定的隐私保护能力. 这个结论也符合基于DCR 和NNDR 的评估结果. 综上所述,DDPM 相对其他方法在模型效果和隐私保护2个方面做到了比较理想的平衡.
5.3 生成数据解释性分析
本文选择电信数据集中的真实样本和生成样本,通过模型解释性的方式对模型决策机制进行剖析,基于SHAP(SHapley Additive exPlanations)实现[36]. 通过Shapley 值判断特征对模型决策的贡献进而实现决策解释. 本文设计2 种模式:1)通过全局解释性方法,对比真实数据和生成数据在重要特征选择上的相似度. 2)通过局部解释性方法,对比单个生成流失样本和其最接近的真实样本在模型决策上的相似性.
我们对生成的所有样本和真实样本集进行Global 级别的全局解释,计算了全部样本的Shapley值的绝对平均值. 图5 直观地展示了在真实和生成数据集上特征对模型决策的重要程度. 在一共19 个特征的数据中Top 9 的特征重叠度非常高,只有1 个特征不同,且特征排序也几乎一致. 这说明基于DDPM生成的数据在全局上和真实数据非常接近,在模型决策时的表现和真实数据几乎一致.
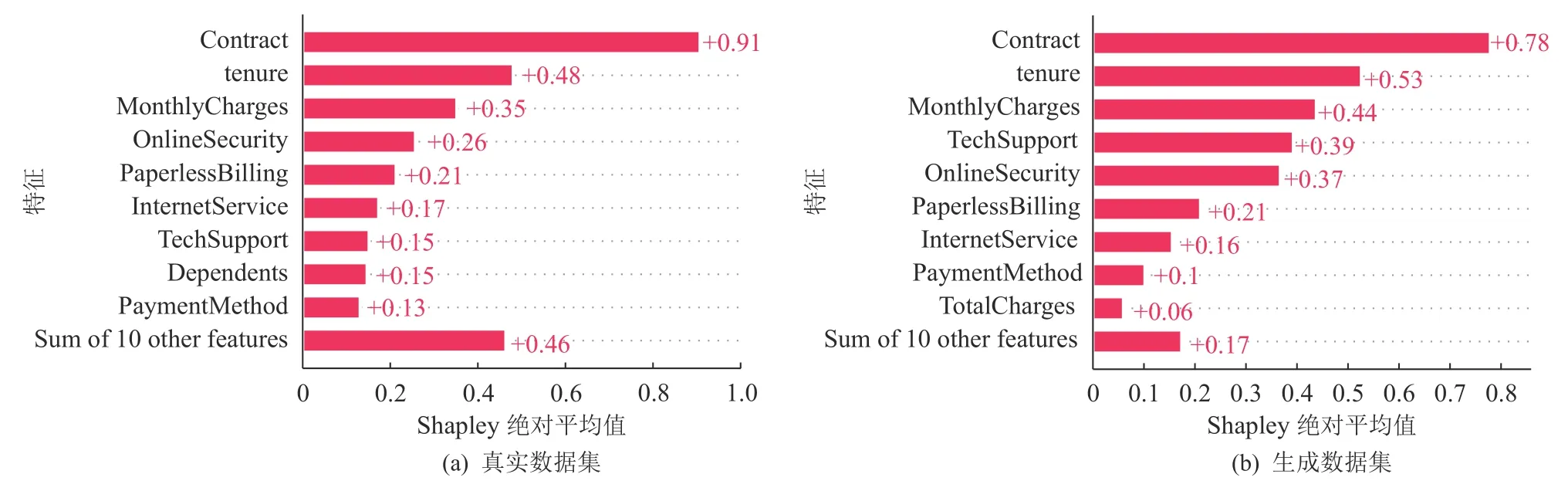
Fig. 5 Global mode: Comparison of the importance of features for the different datasets图5 全局模式:不同数据集中特征重要性对比
对于Local 模式下的解释性,本文首先使用计算最近样本距离方法随机挑出原始样本,并找到生成数据集对应的最近生成样本,分别计算这2 个样本的Shapley 值,生成瀑布图如图6 所示. 瀑布图中,图标长度说明特征的影响大小,可以看出对应单个样本级别,生成数据和真实数据与全局解释性上的表现非常统一,在重要的特征上几乎完全一致,仅在特征的顺序上有一些区别,这也能反映出生成数据和其最相似的真实数据的区别.

Fig. 6 Local mode: Comparison of the importance of features for a single Sample图6 局部模式:单个样本特征重要性对比
总之,由解释性分析结果可知,Shapley 值度量的特征重要性符合人工判断,说明模型解释是合理的.同时,生成数据与原始数据的特征分布具有高度一致性,且各特征对预测模型的影响也非常相似,说明基于扩散模型生成数据能够作为补充样本应用于流失预测模型中.
6 结论与展望
本文以客户流失预测为典型场景,研究了基于扩散模型探索数据不平衡改进和用户隐私数据保护等问题. 我们结合高斯和多项式扩散模型对客户流失数据进行生成,获得和真实流失客户数据分布接近的生成数据,并对生成数据的质量进行展示和定量评估. 本文还对生成数据和真实数据的融合方式进行研究,分析了生成数据在不同性能的分类器下的表现和客户隐私保护能力. 本文在多个领域的客户流失数据上进行实验,结果表明扩散模型可生成高质量数据,与真实数据分布一致,且生成数据对客户流失预测模型效果均有一定的提升. 考虑到基于扩散模型的生成数据与真实数据的分布一致,我们认为基于扩散模型生成的数据可以达到完全替换真实数据的目的,可应用于用户隐私数据保护.
基于本文研究,未来我们会对不同的数据融合重构方式进行探索,寻找更加通用的融合策略. 同时会对生成数据的隐私保护潜力进行深入挖掘.
作者贡献声明:杨斌提出了算法思路和实验方案,并撰写论文;王正阳和程梓航负责完成实验并撰写论文;赵慧英、王鑫和管宇参与文献调研和讨论;程新洲提出指导意见并修改论文.
猜你喜欢
摄影世界(2022年1期)2022-01-21
知识经济·中国直销(2018年12期)2018-12-29
电子测试(2018年1期)2018-04-18
商周刊(2017年6期)2017-08-22
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
山东大学法律评论(2016年0期)2016-08-16
新校长(2016年8期)2016-01-10
商事法论集(2014年1期)2014-06-27
电测与仪表(2014年15期)2014-04-04
