
基于递进式模型结构和时间信息嵌入的非侵入式负荷分解
2024-02-27 02:46孙睿晨赵剑锋毛妍纯
智慧电力 2024年2期
孙睿晨,董 坤,赵剑锋,2,毛妍纯
(1.东南大学电气工程学院,江苏南京 210096;2.南京林业大学信息科学技术学院,江苏南京 210037;3.国网江苏南京供电公司,江苏南京 210019)
0 引言
为实现电网与用户的互动性以及用电管理的信息化,智能配电网对电力负荷监测的颗粒度提出了新的要求[1-3]。对于居民用电,电器级细粒度的负荷运行信息可用于计算需求侧响应资源、引导居民合理用电以及辅助负荷建模等[4]。非侵入式负荷监测(Non-intrusive Load Monitoring,NILM)是获取负荷电器级运行信息的关键技术,整个过程仅依赖于单点测量,以总电表记录的功率、电压、电流为特征,识别单个设备的运行状态,估计其功率消耗[5-6]。
基于传统机器学习的NILM 主要由隐马尔科夫模型(Hidden Markov Model,HMM)[7-9]实现,这类算法通常依赖于较为严格的假设条件,对负荷状态变化的描述并不符合所有电器的实际运行特性。2015年Kelly 首次将深度学习算法引入负荷分解领域[10],显著提高了分解准确度和模型泛化能力。循环神经网络(Recurrent Neural Network,RNN)[11]是一类适合处理序列数据的深度学习体系结构。为解决RNN 的长期依赖问题,NILM 问题多采用基于长短期记忆(Long Short-term Memory,LSTM)网络[12-13]和门控循环单元(Gated Recurrent Unit,GRU)[14-15]的方法。卷积神经网络(Convolutional Neural Networks,CNN)也在序列问题上表现突出[16],文献[17]利用基于多层CNN 的网络结构对比了Seq2Point 和Seq2Seq 2 种功率映射方式。谷歌于2017 年提出了Transformer 架构[18],其序列建模能力和信息感知能力显著超越了RNN 和CNN。随后,一系列工作将Transformer 模型的网络结构和数据嵌入方式应用于NILM[19-21],分解效果得到有效提升。
基于RNN 的NILM 利用模型本身的循环结构捕获时间序列模式,基于Transformer 的方法通常采用位置编码捕捉位置信息。这类模型可以一定程度上挖掘某负荷事件与前后事件之间的关系,但是由于没有描述长期时序信息的全局时间标签,所关注的范围仅限于序列内部,对用户行为偏好的捕捉十分有限。部分研究工作对电器的日用电模式进行了提取,但是忽略了更长时间尺度的行为规律[22-23]。
另外,NILM 的问题模型涉及2 个方面:(1)确定电器是否处于运行状态,对应分类问题;(2)还原电器的具体运行功率,对应回归问题。现存的NILM 算法通常将这2 个复杂任务直接交由1 个网络完成,因此模型预测的准确度受到了一定限制。
本文提出了一种基于递进式模型结构和时间信息嵌入的负荷分解方法。模型由2 个基于Transformer架构的模块构成,递进地解决判断电器开关状态与预测功率值2 个子问题,通过设置不同的损失函数,2 个模块能够侧重于不同的功能。另外,本文在模型输入部分引入多尺度的时间信息,提高了模型对用电行为特征的捕捉能力。在参考能量分解数据集(Reference Energy Disaggregation Dataset,REDD)和英国家用电器电力(UK Domestic Appliance-level Electricity,UKDALE)数据集上进行跨家庭测试,本文模型在4 项评价指标的表现均优于所对比的6 种NILM 方法,尤其显著降低了平均绝对误差。
1 算法设计
1.1 递进式模型结构
本文方法的神经网络部分基于特征抽取能力极强的Transformer 模型设计。Transformer 使用多层编码器和解码器叠加提取特征,但基于文献[19]所述NILM 架构,本文通过实验发现,在负荷分解问题中编码器堆叠到2 层以上时网络表现就会趋于饱和,甚至出现网络退化。
因此,为了有效利用深层网络,本文借鉴残差网络和级联策略的思想提出一种递进式模型结构。残差网络以跳连接的方式实现不同神经网络层之间的信息传递,显著提高了可有效训练的网络深度。级联网络是处理复杂任务的有效方法,其主要思想是“由粗到细”(Coarse-to-fine),通过逐级精细化迭代推理得到最终结果[24-27]。文献[26]使用从粗检测到微调特征点的级联结构实现了人脸检测。文献[27]通过粗粒度网络和细粒度网络的顺序连接实现了疾病严重程度的精确分类。
受此启发,结合负荷分解任务分类与回归问题共存且后者依赖于前者的本质,本文设计了一种两级的递进式模型结构,使模型逐渐细化对功率消耗情况的推理。通过如图1 所示的信息传递机制提高模型对任务的整体理解能力:预分解模块的输入为总功率信号和时间信息,功率预测模块的输入为总功率信号、时间信息和预分解模块初步预测的目标电器状态。预分解模块主要负责判断目标电器的开关状态,功率预测模块基于前者的分解结果精确还原目标电器的功率曲线。

图1 递进式模型结构图Fig.1 Architecture of progressive model
图2 为单个模块结构图。图2 中预分解模块和功率预测模块均由3 部分网络组成:信息嵌入层、核心分解层和输出层。两模块的核心分解层与输出层结构完全一样,信息嵌入层因输入信息的不同而有所差异。图2 中L和H分别表示输入及输出序列长度和嵌入数据维数,l和h分别表示核心分解层中的编码器层数和自注意力头数。

图2 单个模块结构图Fig.2 Structure of single module
1.2 网络结构
1.2.1 信息嵌入层
本文所提方法的输入信息分为时间信息、总功率和预分解模块输出状态3 类。为捕捉这些数据中与目标电器功率相关的信息,采用卷积核大小为k的一维卷积层对序列进行特征提取,同时增加维度,然后通过池化层将序列长度缩短至一半,最后以求和计算融合多种嵌入信息。具体网络结构如图3 所示。

图3 信息嵌入层网络结构图Fig.3 Network structure of information embedding layer
1)总功率数据嵌入。负荷分解的实现主要依赖于神经网络学习到全屋总功率与目标电器功率曲线的映射关系,因此总功率数据作为最重要的判断依据,被同时输入预分解模块和功率预测模块。
2)时间信息嵌入。传统的负荷分解方法仅通过聚合功率特征判断单个电器的状态,一定程度上忽略了家庭用户的用电规律性。例如洗碗机通常在午餐和晚餐之后使用,微波炉和洗碗机在工作日中午使用概率较低,冰箱在天气炎热的季节启动更加频繁。不同时段电器的活跃度差异可以成为判断电器使用情况的有力依据。然而由于一次送入模型的数据长度有限,模型难以自动捕捉长时间尺度的规律特征。因此本文将多尺度时间信息直接提取并显式地输入模型,以提高模型对用电规律的敏感性。
本文借鉴文献[28]提出的全局时间标签编码方法,设计了适用于NILM 问题的多尺度时间信息的表示及嵌入结构。时间信息的描述方法见图4。为确保模型精准捕捉与家庭用电规律关联最紧密的时间特征,避免冗余信息的干扰,本文对每个时间标签提取3 个关键特征:1 d 中的小时数、1 周中的星期数、1 a 中的月份数,并将这3 个特征分别线性编码为[-0.5,0.5]区间内的值。例如:对于2011-04-18 13:22:12 这一时间标签,其小时数、星期数和月份数分别为13、1 和4,故得[0.065 2,-0.500 0,-0.326 1]作为表示。

图4 时间戳处理示意图Fig.4 Schematic diagram of timestamp processing
3)状态数据嵌入。利用设备开启阈值(即表1中电器运行合理功率范围的下限值)计算预分解模块输出功率对应的开关状态序列,用0/1 状态量编码。由于电器开启的稀疏性,状态序列的均值接近于0,因此无需对状态数据进行标准化操作。

表1 电器基本参数设定Table 1 Basic parameter settings of electric appliances
1.2.2 核心分解层
核心分解层参考基于Transformer 的双向编码表示(Bidirectional Encoder Representation from Transformers,BERT)模型设计,由l层编码器堆叠形成,每个编码器由h头的自注意力网络和前馈神经网络构成。
1)多头自注意力机制。注意力机制模拟了人脑的信息处理能力,与仅根据位置决定权重的全连接层相比,注意力机制根据向量内容来学习权重,因此能够将有限的注意力集中到最重要的局部特征。注意力机制的实现依赖于3 个向量:Q(Query),K(Key),V(Value)。V为表示输入特征的向量,Q,K为用于计算注意力权重的向量,都由对嵌入数据进行线性运算得到。对Q和K之间的相似度进行计算,然后通过softmax 获取向量的权重值,并与V进行加权计算,最后将带权重的V向量求和,得到该位置的自注意力输出YAttn(Q,K,V):
式中:dK为向量K的维度。
多头自注意力机制为注意力机制的变体,从结构上使多个注意力并行地关注到数据的不同特征部分,帮助网络捕捉到更丰富的信息。多头自注意力本质上是多个独立的注意力计算,对于第i个头的自注意力机制,用独立学习得到的第i个线性投影WQ,WK和WV来变换Q,K和V,其中i=1,2,…,h为总头数。然后将h组变换结果并行地池化并进行拼接,最后通过一个学习得到的线性变换WO获得最终的注意力输出。多头自注意力计算结果YMultiHead(Q,K,V)可描述为:
其中第i个注意力头的输出hi按式(3)计算:
2)前馈神经网络。注意力输出被送入前馈神经网络,将注意力值转换为下一层更易处理的形式。前馈神经网络使用两层全连接和GELU 激活处理输入元素,之后利用残差连接防止网络退化和梯度消失,然后进行层归一化稳定前向输入分布。
1.2.3 输出层
输出层部分将核心分解层所提取的功率特征映射为与总功率序列长度相同的单个电器功率序列。使用卷积核为的反卷积操作扩展数据长度,2个全连接层将特征矩阵转换为长度为L的一维数据,然后根据表1 所示电器运行的合理功率范围对输出值进行调整,获得最终的预测功率。
1.3 损失函数
本文采用多种损失函数联合引导模型的优化方向[19],所提方法涉及以下4 种损失函数:
1)均方误差(Mean Square Error,MSE)。该函数曲线连续光滑,收敛效率高,但是对离群点较为敏感。MSE 损失函数LMSE(yt,)表达式为:
2)推土距离(Earth Mover’s Distances,EMD)误差。将离散分布想象为2 个土堆,则推土距离可以直观地理解为将1 个土堆转换为另1 个土堆所需的最小工作量。与以KL(Kullback-Leibler)散度作损失函数相比,推土距离能够为模型的参数更新提供更平滑的结果[29]。EMD 损失函数LEMD(yt,)表达式为:
3)骰子损失(Dice Loss)。该损失函数用于提高模型对设备开关状态的判断效果。骰子损失在图像分割领域有着广泛的应用,能够大大缓解样本不平衡问题[30],但是正样本为小目标时可能会引起震荡。骰子损失函数LDice(st,)表达式为:
4)平均绝对误差(Mean Absolute Error,MAE)。这一项的目的是拉近电器开启期间预测功率与真实值的距离,因此计算范围并非整个序列,而仅为目标电器实际状态为开启和状态预测错误的时序点。MAE 损失函数LMAE(yt,t)表达式为:
式中:O为电器实际开启或状态预测错误的时序点。
不同损失函数对误差衡量的侧重点不同,为实现全面模型优化,根据每个模块的优化目标将其损失函数设置为多项组合。预分解模块对最终输出的贡献在于向功率预测模块提供较为准确的分类信息,因此其损失函数由MSE、推土距离和骰子损失3 项组成,骰子损失发挥主导作用,引导网络对目标电器的开关状态做出正确的判断。在获得状态信息的基础上,功率预测模块需拟合出电器运行的功率曲线,因此其损失函数由MSE、推土距离和MAE3 项组成,MAE 损失项对电器开启时的功率值进行校正。复合损失函数可描述为:
式中:L1和L2分别为预分解模块和功率预测模块的损失函数。
本文对其他损失项同样添加权重进行实验,发现其他权重值对模型结果的影响可忽略不计,因此仅对MAE 项设置权重。
另外,使用组合损失函数的优势还体现在模型可解释性的提高。通过观察每个损失函数的变化,可以更深入地理解模型对不同方面的关注和响应,有助于模型调试。
2 数据集及数据处理
2.1 数据集选取
本文使用REDD 和UKDALE 数据集中的低频数据进行模型的训练与测试。REDD 是非侵入式负荷分解领域的第1 个也是使用最广泛的公开数据集,包括了6 个美国家庭住宅的总电表和负荷分表的数据,记录时长约为4 个月。UKDALE 是2014年帝国理工学院发布的公开数据集,其数据量极大,包含5 个英国家庭的电器级消耗数据,其中,1 号房屋的功率采集时间长达3 年,其他房屋为数月。
2.2 数据预处理
1)合并分相电表数据。由于北美家庭常使用两相供电方式,因此对于REDD 数据集,需将两电表功率数据求和得实际总功率。
2)对功率数据以6 s 为间隔进行重新采样。
3)对少于3 min 的数据缺失通过前向填充来补值,对超过3 min 的数据缺失用0 填充。
4)删除总功率低于5 W 的数据,认为没有设备开启,无分解必要。
5)给数据集添加状态标记。根据表1 所示的电器基本参数设定,电器功率在运行合理功率范围内且运行时长大于最小持续时间,则认为设备开启,状态值标记为1,否则标记为0。
6)对功率数据按式(9)进行标准化处理,其中y为原始功率数据,y*为标准化后的功率数据,μ为样本均值,σ为样本方差。经处理的数据符合标准正态分布,即均值为0,标准差为1,该过程能够提高模型精度和训练收敛速度。
2.3 训练及测试数据划分
对某个房屋进行负荷分解时,该房屋电器的耗电历史数据通常是未知的,因此要求模型对新鲜样本具有一定泛化能力,使用已知房屋数据训练的模型在未知的房屋上也能够准确地分解。
本文在REDD 数据集中选取微波炉、洗衣机、洗碗机、冰箱作为研究对象,在UKDALE 数据集中选取微波炉、洗衣机、水壶、冰箱作为研究对象,进行跨家庭的训练与测试,如表2 划分训练集与测试集。

表2 训练集及测试集选取Table 2 Selection of training set and testing set
3 算例分析
3.1 实验环境及配置
在Python 编程平台中使用Pytorch 深度学习框架进行模型的训练和测试。采用Adam 优化器加速梯度下降,其中一阶和二阶矩估计的指数衰减率分别为0.9 和0.999。神经网络参数设置如表3 所示。

表3 神经网络参数设置Table 3 Parameter settings of neural network
3.2 评价指标
为衡量算法对负荷开关状态的判断能力和对负荷功率消耗的还原能力,需要选取合适的性能评价指标。NILM 任务既是二分类问题,也是回归问题,因此算法的性能可以用两类指标来评价。
1)分类性能评价指标。式(10)中的分类指标可用于评价算法对电器开关状态的识别能力,其中,NTP,NTN,NFP,NFN分别表示电器实际开启且分解结果也为开启、电器实际开启且分解结果也为开启、电器实际关闭而分解结果为开启、电器关闭且分解结果也为关闭的序列点的数量。NP和NN分别表示电器实际开启和关闭的数量。准确率(A)为最直观的分类指标,但不适用于不平衡数据集,对于电器开启较为稀疏的情况,该指标并不是1 个很好的度量。F分数(F)综合考虑精确率(P)和召回率(R)的值,可根据负荷分解的具体应用场景,通过改变权衡参数β的值赋予精确率和召回率不同的权重,以在各种具体问题中评价负荷分解算法的好坏。一般认为精确率和召回率同样重要,因此令β=1,此时的F分数为两者的调和平均,称为F1分数(F1),1.3 节所述骰子损失对该项指标有直接的优化作用。
2)回归性能评价指标。为了评估模型对负荷功率消耗的还原效果,使用常用于回归问题的平均绝对误差(Mean Absolute Error,MAE)和平均相对误差(Mean Relative Error,MRE)来衡量算法的分解性能。MAE 和MRE 的值分别用EMA和EMR表示,计算公式为:
3.3 实验结果
将所提方法与6 种NILM 算法进行对比,其中包括因子隐马尔科夫模型(Factorial Hidden Markov Model,FHMM)[8]、基于RNN 架构的双向GRU 和双向LSTM 模型[14]、基于CNN 架构的Seq2Seq 模型[17]、基于Transformer 架构的BERT4NILM 模型[19]和ELECTRIcity 模型[20]。为了确保对比实验的客观性,对每种算法采用相同的数据处理方式,且固定输入序列长度,模型均训练至收敛。由于F1分数综合了召回率和精确率的结果,本文对比准确率和F1分数两项分类指标及MAE 和MRE 两项回归指标。7 种分解方法在REDD 和UKDALE 数据集上的性能指标分别如表4 和表5 所示,其中加粗项为最优指标,符号↑和↓分别表示该项指标越大越优和越小越优。

表4 REDD数据集模型表现Table 4 Model performance on REDD dataset
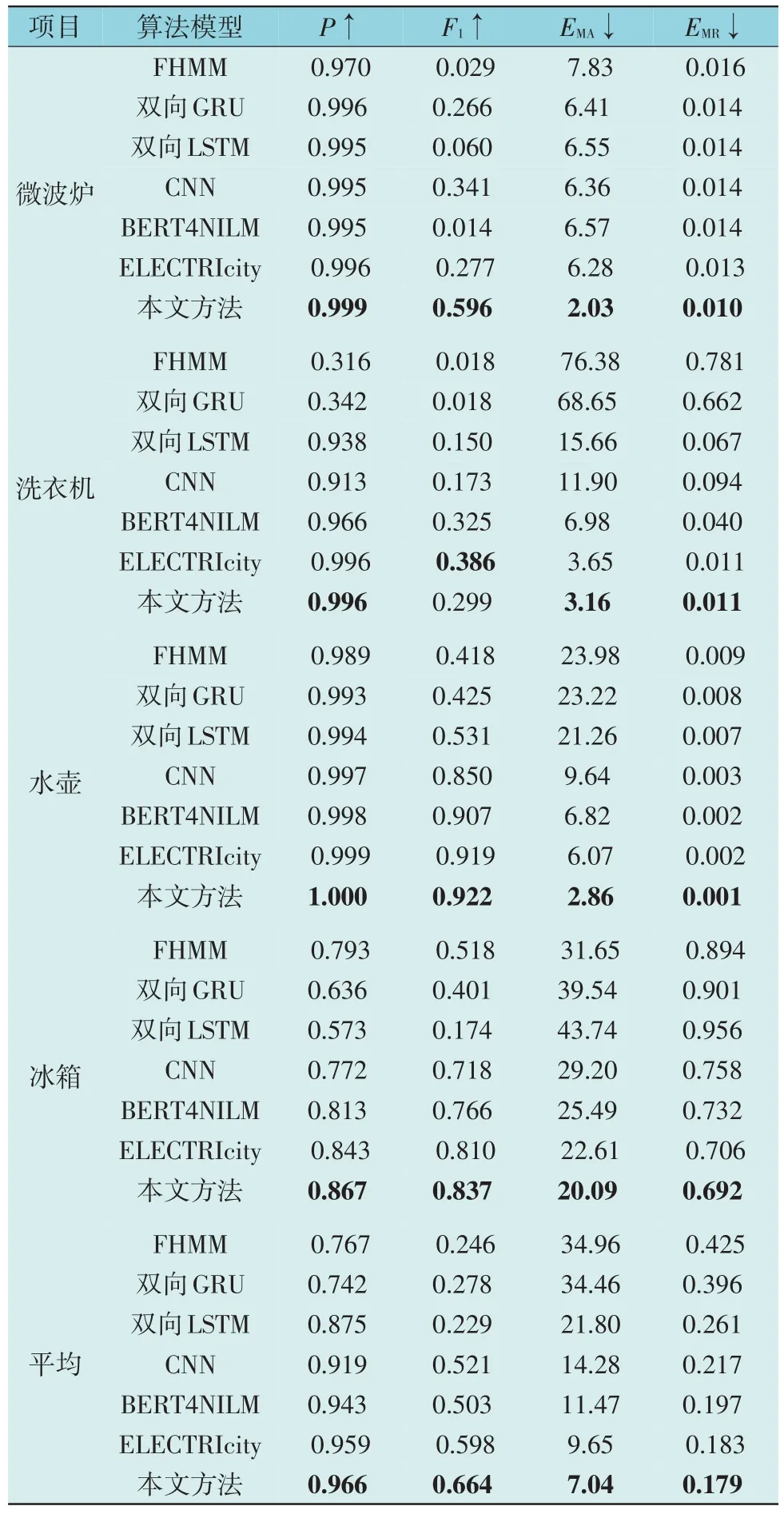
表5 UKDALE数据集模型表现Table 5 Model performance on UKDALE dataset
从表4 和表5 数据可以看出,在两数据集上,5种基于深度学习模型的NILM 方法均整体优于基于FHMM 的方法,且本文方法4 项指标的平均值均优于基准模型,对于大部分电器,负荷分解的综合性能也具有优势。尤其在MAE 指标上,本文所提方法在所测试的每个电器上均显著优于其他算法。MAE 的平均值在REDD 和UKDALE 上比所对比的最优方法(BERT4NILM)分别降低了24.7% 和27.0%,UKDALE 数据集中3 个电器的MAE 比该方法降低超过50%。这是由于递进式模型结构使单个模块能够专注于单个任务,因此对于开启功率还原这一任务的完成效果具有明显提升。另外,对于F1分数,本文方法在REDD 和UKDALE 上分别比BERT4NILM 算法提高了7.9%和32.0%。
图5 为REDD 数据集4 种电器的分解结果局部图,大部分图中蓝色实线与橙色虚线都能够基本吻合,说明本文所提方法对大功率电器和小功率电器的消耗曲线都具有很好的拟合效果。然而对于洗碗机,尽管4 项评价指标都高于基准方法,但是从结果曲线图上看,分解效果仍不够理想。模型将电器运行功率较小的时段判断为电器处于关闭状态,未能完整还原出洗碗机使用期间的功率消耗情况。这是因为洗碗机的运行特性较为复杂,开启期间具有多个模式(如预冲洗、蒸汽洗、烘干等),因此对模型的特征捕获能力要求更高。且从图5(c)中可以看出,预测的电器功率曲线一定程度上跟踪了总功率曲线的形态,受到总功率中噪声信号的影响,分解结果不够平滑。

图5 REDD数据集各电器分解曲线局部图Fig.5 Local decomposition curve for each electric appliance on REDD dataset
4 结论与展望
本文针对传统非侵入式负荷分解方法精度欠缺的问题,基于深度学习框架,提出了1 种基于递进式模型结构和时间信息嵌入的非侵入式负荷分解方法,主要结论如下:
1)提出递进式的模型结构,将NILM 问题拆解出的2 个子任务递进地通过2 个模块完成,增强了模型对复杂任务的消化和处理能力。
2)提出一种适用于负荷分解问题的时间标签编码方法及嵌入结构,利用时间信息辅助模型做出功率预测。
3)提出复合损失函数,根据特定的网络任务联合不同的损失函数,目标明确地引导模型优化。
本文所提模型在REDD 和UKDALE 数据集上进行测试,准确率、F1分数、MAE 和MRE 4 项指标均优于所对比的6 种基于深度学习的NILM 方法,尤其在电器功率曲线还原任务上表现显著提升,确保算法在电器故障检测等对功率曲线拟合要求较高的应用场景中能够提供可靠的负荷分解结果。且本文算法在跨家庭测试中展现出良好的效果,说明算法在家庭电器设备配置存在较大差异的多样化居民用电场景中的具有较强的泛化能力。
基于本文的研究成果,未来将考虑进一步提高模型对运行状态复杂的多模式设备的识别能力。
猜你喜欢
文萃报·周五版(2022年14期)2022-04-12
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通·3-4年级(2021年5期)2021-07-16
中国品牌(2019年10期)2019-10-15
今日农业(2019年15期)2019-01-03
电子制作(2018年17期)2018-09-28
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
